
Maison >Périphériques technologiques >IA >'En utilisant la technologie de diffusion stable pour reproduire des images, des recherches connexes ont été acceptées par la conférence CVPR'
'En utilisant la technologie de diffusion stable pour reproduire des images, des recherches connexes ont été acceptées par la conférence CVPR'

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBavant
- 2023-04-26 12:43:08860parcourir
Et si l'intelligence artificielle pouvait lire votre imagination et transformer les images de votre esprit en réalité ?

Bien que cela semble un peu cyberpunk. Mais un article récemment publié a fait sensation dans le cercle de l’IA.
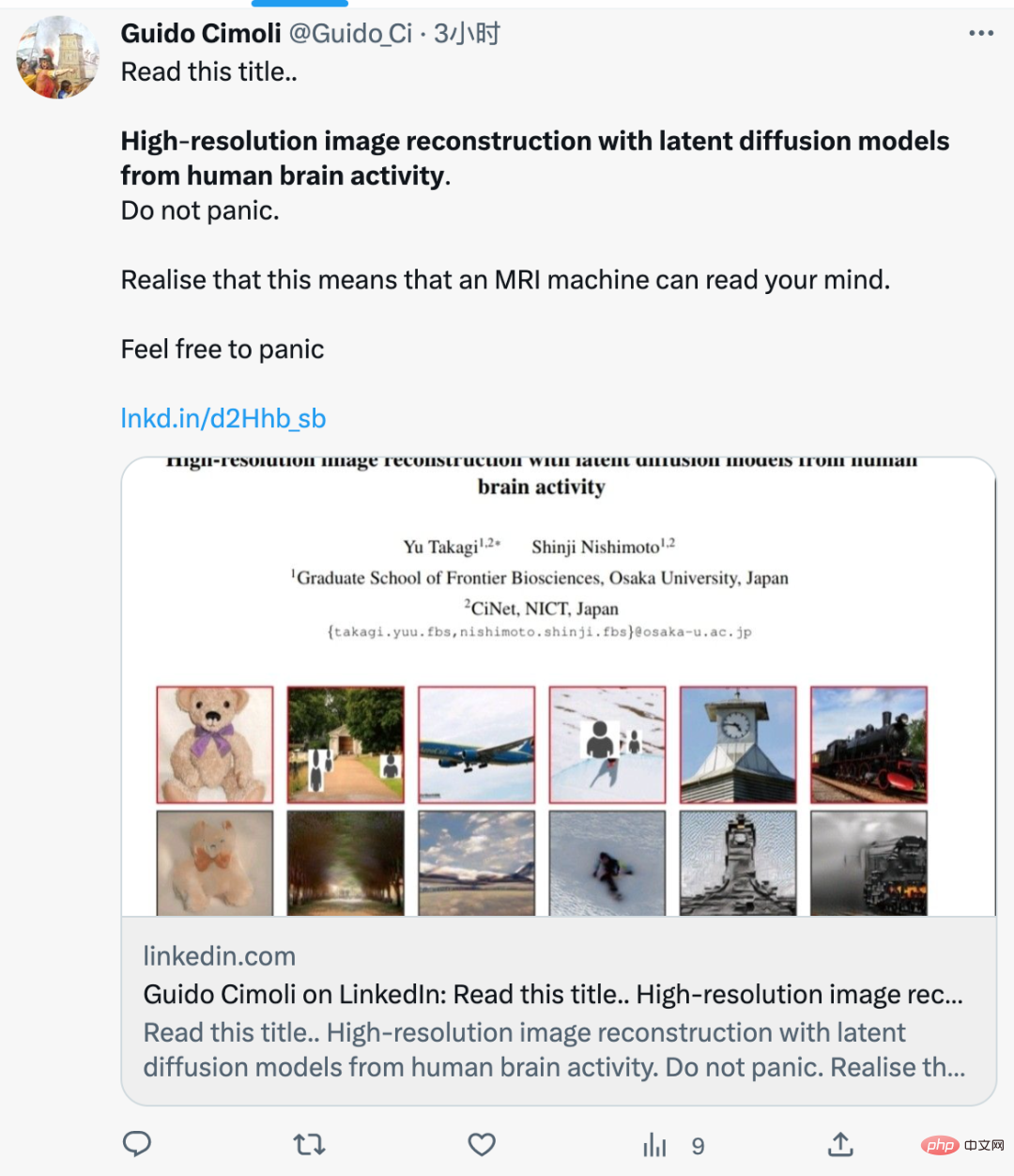
Cet article a révélé qu'ils utilisaient la méthode de diffusion stable, élevée, récemment très populaire. -des images de haute résolution et de haute précision de l’activité cérébrale peuvent être reconstruites. Les auteurs ont écrit que contrairement aux études précédentes, ils n’avaient pas besoin de former ou d’affiner un modèle d’intelligence artificielle pour créer ces images.

- # 🎜 🎜#Adresse papier : https://www.biorxiv.org/content/10.1101/2022.11.18.517004v2.full.pdf #🎜🎜 #
- Adresse de la page Web : https://sites.google.com/view/stablediffusion-with-brain/
Dans cette étude, les auteurs ont utilisé la diffusion stable pour reconstruire des images d'activité cérébrale humaine obtenues par imagerie par résonance magnétique fonctionnelle (IRMf). L'auteur a également déclaré qu'il est également utile de comprendre le mécanisme du modèle de diffusion implicite en étudiant différentes composantes des fonctions liées au cerveau (comme le vecteur latent de l'image Z, etc.).
Ce papier a également été accepté par le CVPR 2023.
Les principales contributions de cette étude comprennent :
- Prouver que son cadre simple peut be Reconstruire des images haute résolution (512 × 512) à partir de l'activité cérébrale avec une haute fidélité sémantique sans avoir besoin de former ou d'affiner des modèles génératifs profonds complexes, comme indiqué ci-dessous ;
- # 🎜 🎜#Cette étude explique quantitativement chaque composant du LDM d'un point de vue neuroscientifique en cartographiant des composants spécifiques à différentes régions du cerveau
- L'étude explique objectivement comment le texte en image ; Le processus de conversion mis en œuvre par LDM combine les informations sémantiques exprimées par le texte conditionnel tout en conservant l'apparence de l'image originale.
- Aperçu de la méthode
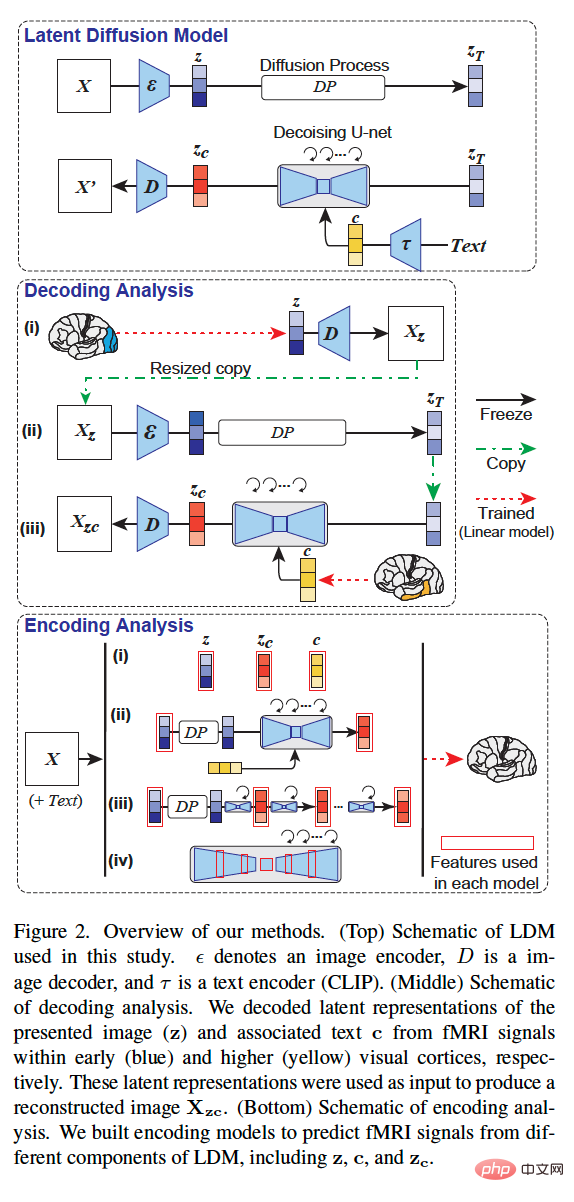
La méthodologie globale de l'étude est présentée dans la figure 2 ci-dessous. La figure 2 (en haut) est un diagramme schématique du LDM utilisé dans cette étude, où ε représente l'encodeur d'image, D représente le décodeur d'image et τ représente l'encodeur de texte (CLIP).
La figure 2 (au milieu) est un diagramme schématique de l'analyse de décodage de cette étude. Nous avons décodé la représentation sous-jacente de l'image présentée (z) et du texte associé c à partir de signaux IRMf dans le cortex visuel précoce (bleu) et avancé (jaune), respectivement. Ces représentations latentes sont utilisées comme entrée pour générer l'image reconstruite X_zc.
La figure 2 (en bas) est un diagramme schématique de l'analyse de codage de cette étude. Nous avons construit des modèles de codage pour prédire les signaux IRMf de différents composants du LDM, notamment z, c et z_c.
Results
Jetons un coup d'œil aux résultats de reconstruction visuelle de cette étude.
Décodage
La figure 3 ci-dessous montre les résultats de la reconstruction visuelle d'un sujet (subj01). Nous avons généré cinq images pour chaque image de test et sélectionné l'image avec le PSM le plus élevé. D’une part, l’image reconstruite en utilisant uniquement z est visuellement cohérente avec l’image originale mais ne parvient pas à capturer son contenu sémantique. D'un autre côté, les images reconstruites avec seulement c produisent des images avec une haute fidélité sémantique mais sont visuellement incohérentes. Enfin, l’utilisation d’images reconstruites z_c peut produire des images haute résolution avec une haute fidélité sémantique. 
La figure 4 montre les reconstructions de tous les testeurs de la même image (toutes les images générées avec z_c). Dans l’ensemble, la qualité de la reconstruction parmi les testeurs était stable et précise.

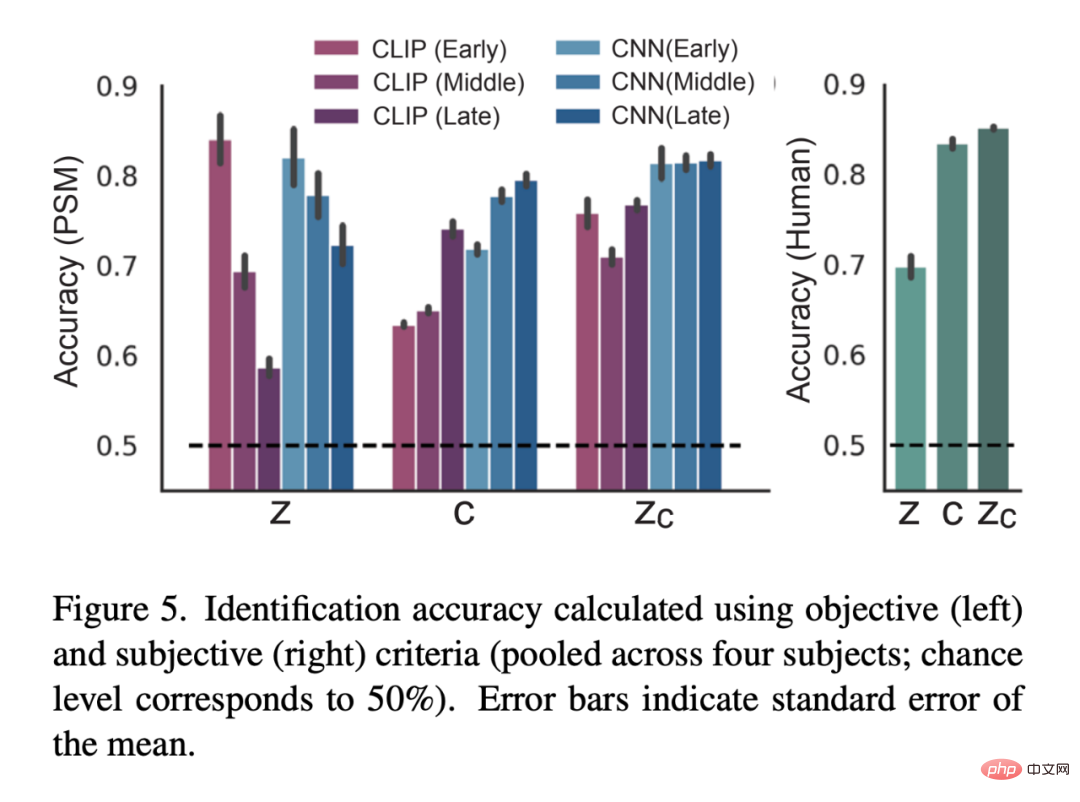
La figure 5 est le résultat de l'évaluation quantitative : 6 montre le modèle de codage pour trois types de LDM - Précision de prédiction liée aux images latentes : z, l'image latente de l'image originale ; c, l'image latente de l'annotation de texte de l'image et z_c, la représentation d'image latente bruyante de z après le processus de rétrodiffusion d'attention croisée avec c ; .
Comment la représentation sous-jacente du bruit ajouté change-t-elle au cours du processus itératif de débruitage ? La figure 8 montre que dans les premiers stades du processus de débruitage, le signal z domine la prédiction du signal IRMf. Au stade intermédiaire du processus de débruitage, z_c prédit bien mieux que z l’activité au sein du cortex visuel élevé, indiquant que la majeure partie du contenu sémantique émerge à ce stade. Les résultats montrent comment LDM affine et génère des images à partir du bruit.
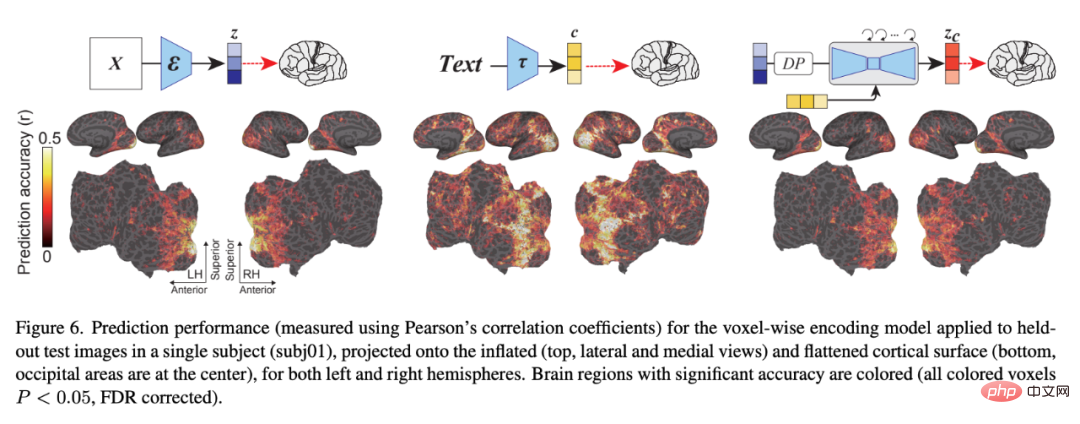
Enfin, les chercheurs ont exploré les informations traitées par chaque couche d'U-Net. La figure 9 montre les résultats des différentes étapes du processus de débruitage (précoce, intermédiaire, tardif) et le modèle de codage des différentes couches d'U-Net. Dans les premiers stades du processus de débruitage, la couche de goulot d'étranglement (orange) d'U-Net produit les performances de prédiction les plus élevées sur l'ensemble du cortex. Cependant, à mesure que le débruitage progresse, les premières couches d'U-Net (bleu) prédisent l'activité au sein du cortex visuel précoce, tandis que les couches de goulot d'étranglement passent à un pouvoir prédictif supérieur pour le cortex visuel supérieur.

Pour plus de détails sur la recherche, veuillez consulter l'article original.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Tendances technologiques à surveiller en 2023
- Comment l'intelligence artificielle apporte un nouveau travail quotidien aux équipes des centres de données
- L'intelligence artificielle ou l'automatisation peuvent-elles résoudre le problème de la faible efficacité énergétique des bâtiments ?
- Co-fondateur d'OpenAI interviewé par Huang Renxun : les capacités de raisonnement de GPT-4 n'ont pas encore atteint les attentes
- Bing de Microsoft surpasse Google en termes de trafic de recherche grâce à la technologie OpenAI