
Maison >Périphériques technologiques >IA >Apprentissage multimodal auto-supervisé : exploration des fonctions objectives, de l'alignement des données et de l'architecture des modèles - en prenant comme exemple la dernière revue d'Édimbourg
Apprentissage multimodal auto-supervisé : exploration des fonctions objectives, de l'alignement des données et de l'architecture des modèles - en prenant comme exemple la dernière revue d'Édimbourg

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBavant
- 2023-04-26 10:04:081294parcourir
L'apprentissage multimodal vise à comprendre et analyser des informations provenant de multiples modalités, et des progrès substantiels ont été réalisés dans les mécanismes de supervision ces dernières années.
Cependant, une forte dépendance aux données associée à des annotations manuelles coûteuses entrave la mise à l'échelle du modèle. Dans le même temps, compte tenu de la disponibilité de données non étiquetées à grande échelle dans le monde réel, l’apprentissage auto-supervisé est devenu une stratégie intéressante pour atténuer le goulot d’étranglement de l’étiquetage.
Basé sur ces deux directions, l'apprentissage multimodal auto-supervisé (SSML) fournit une méthode pour exploiter la supervision à partir de données multimodales originales.

Adresse papier : https://arxiv.org/abs/2304.01008
Adresse du projet : https://github. com/ys-zong/awesome-self-supervised-multimodal-learning
Dans cette revue, nous proposons un examen complet de l'état de l'art en SSML, que nous classons selon trois axes orthogonaux : Fonction objectif, alignement des données et architecture du modèle. Ces axes correspondent aux caractéristiques inhérentes aux méthodes d'apprentissage auto-supervisé et aux données multimodales.
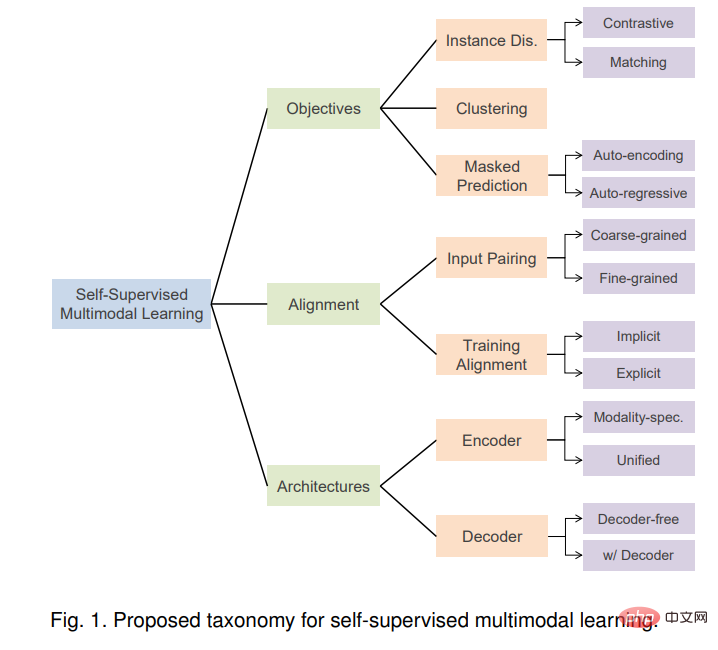
Plus précisément, nous divisons les objectifs de formation en catégories de discrimination d'instance, de clustering et de prédiction de masque. Nous discutons également des stratégies d’appariement et d’alignement des données d’entrée multimodales pendant la formation. Enfin, l'architecture du modèle est passée en revue, y compris la conception des encodeurs, des modules de fusion et des décodeurs, qui sont des composants importants des méthodes SSML.
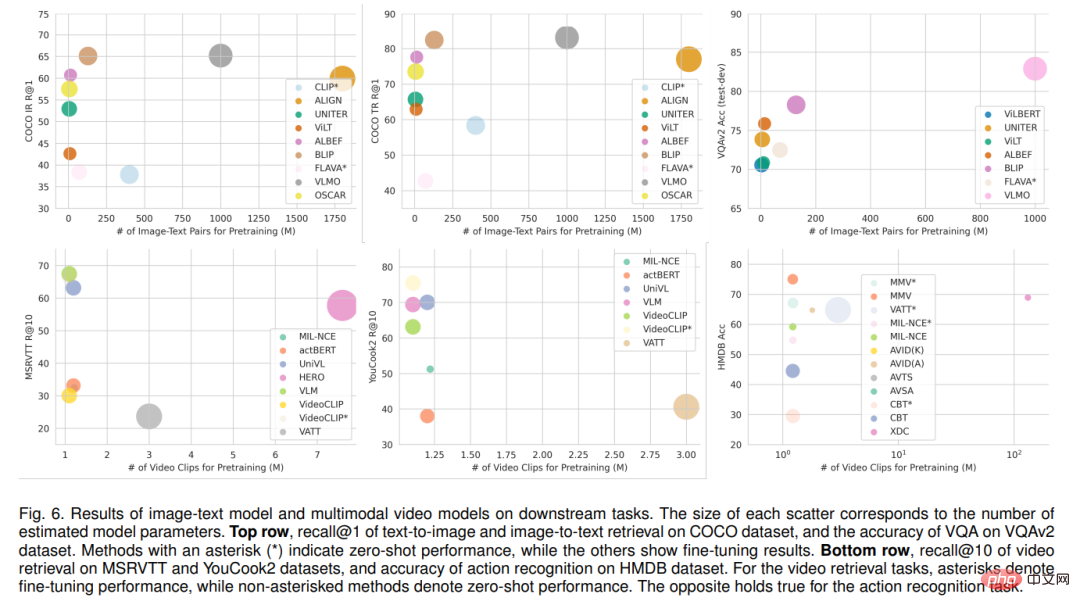
Examine les tâches d'application multimodales en aval, rapporte les performances spécifiques des modèles image-texte de pointe et des modèles vidéo multimodaux, et examine également les applications pratiques des algorithmes SSML dans différents domaines, tels que les soins de santé. , télédétection et traduction automatique. Enfin, les défis et les orientations futures de SSML sont discutés.
1. Introduction
Les humains perçoivent le monde à travers divers sens, notamment la vision, l'ouïe, le toucher et l'odorat. Nous acquérons une compréhension globale de notre environnement en tirant parti des informations complémentaires de chaque modalité. La recherche en IA s’est concentrée sur le développement d’agents intelligents qui imitent le comportement humain et comprennent le monde de la même manière. À cette fin, le domaine de l’apprentissage automatique multimodal [1], [2] vise à développer des modèles capables de traiter et d’intégrer des données provenant de plusieurs modalités différentes. Ces dernières années, l’apprentissage multimodal a fait des progrès significatifs, conduisant à une série d’applications dans l’apprentissage visuel et linguistique [3], la compréhension vidéo [4], [5], la biomédecine [6], la conduite autonome [7] et d’autres domaines. Plus fondamentalement, l’apprentissage multimodal fait progresser des problèmes fondamentaux de longue date dans l’intelligence artificielle [8], nous rapprochant d’une intelligence artificielle plus générale.
Cependant, les algorithmes multimodaux nécessitent encore souvent une annotation manuelle coûteuse pour un entraînement efficace, ce qui entrave leur expansion. Récemment, l'apprentissage auto-supervisé (SSL) [9], [10] a commencé à atténuer ce problème en générant une supervision à partir de données annotées facilement disponibles. L'autosupervision dans l'apprentissage monomodal est assez bien définie et dépend uniquement des objectifs de formation et de l'utilisation ou non de l'annotation humaine pour la supervision. Cependant, dans le contexte de l’apprentissage multimodal, sa définition est plus nuancée. Dans l’apprentissage multimodal, une modalité agit souvent comme un signal de supervision pour une autre modalité. En ce qui concerne l’objectif de mise à l’échelle ascendante en éliminant le goulot d’étranglement des annotations manuelles, une question clé dans la définition de la portée de l’auto-supervision est de savoir si les appariements multimodaux sont librement acquis.
L'apprentissage multimodal auto-supervisé (SSML) améliore considérablement les capacités des modèles multimodaux en exploitant des données multimodales librement disponibles et des objectifs auto-supervisés. Dans cette revue, nous passons en revue les algorithmes SSML et leurs applications. Nous décomposons les différentes méthodes selon trois axes orthogonaux : fonction objectif, alignement des données et architecture du modèle. Ces axes correspondent aux caractéristiques des algorithmes d'apprentissage auto-supervisé et aux considérations spécifiques requises pour les données multimodales. La figure 1 donne un aperçu de la taxonomie proposée. Sur la base de la pré-tâche, nous divisons les objectifs de formation en catégories de discrimination d'instance, de clustering et de prédiction de masque. Les approches hybrides combinant deux ou plusieurs de ces approches sont également discutées.
Le problème du couplage de données multimodales est unique à l'auto-supervision multimodale. Les appariements, ou plus généralement les alignements, entre modalités peuvent être exploités par les algorithmes SSML en entrée (par exemple lors de l'utilisation d'une modalité pour assurer la supervision d'une autre), mais aussi en sortie (par exemple, apprendre à partir de données non appariées et induire un appariement en tant que un sous-produit). Nous discutons des différents rôles de l'alignement à des niveaux à granularité grossière qui sont souvent supposés être librement disponibles dans l'auto-supervision multimodale (par exemple, les images et les légendes explorées sur le Web [11]) ; , correspondance entre les mots du titre et les patchs d'image [12]). De plus, nous explorons l’intersection des fonctions objectives et des hypothèses d’alignement des données.
analyse également la conception de l'architecture de modèle SSML contemporaine. Plus précisément, nous considérons l'espace de conception des modules d'encodeur et de fusion, en comparant les encodeurs spécifiques à un mode (sans fusion ou avec fusion tardive) et les encodeurs unifiés avec fusion précoce. Nous examinons également les architectures avec des conceptions de décodeurs spécifiques et discutons de l'impact de ces choix de conception.
Enfin, les applications de ces algorithmes dans plusieurs domaines du monde réel, notamment la santé, la télédétection, la traduction automatique, etc., ainsi que les défis techniques et l'impact social de SSML est discuté. Une discussion approfondie a lieu et des orientations de recherche futures potentielles sont soulignées. Nous résumons les avancées récentes en matière de méthodes, d’ensembles de données et de mises en œuvre pour fournir un point de départ aux chercheurs et aux praticiens du domaine.
Les articles de synthèse existants se concentrent uniquement sur l'apprentissage multimodal supervisé [1], [2], [13], [14] ou sur un seul -apprentissage modal auto-supervisé [9], [10], [15], ou un certain sous-domaine de SSML, comme la pré-formation en langage visuel [16]. La revue la plus pertinente est [17], mais elle se concentre davantage sur les données temporelles et ignore les considérations clés de l'autosupervision multimodale de l'alignement et de l'architecture. En revanche, nous fournissons un aperçu complet et à jour des algorithmes SSML et proposons une nouvelle taxonomie couvrant les algorithmes, les données et l'architecture.
2. Connaissances de base
en apprentissage multimodal -supervisé
Nous décrivons d'abord la portée du SSML considéré dans cette enquête, car ce terme a été utilisé de manière incohérente dans la littérature précédente. Définir l'auto-supervision dans un contexte monomodal est plus simple en invoquant la nature sans étiquette de différentes tâches prétextes, par exemple, la discrimination d'instance bien connue [20] ou la cible de prédiction masquée [21] mettent en œuvre l'auto-supervision. En revanche, la situation dans l’apprentissage multimodal est plus compliquée car les rôles de la modalité et de l’étiquette deviennent flous. Par exemple, dans le sous-titrage d’images supervisé [22], le texte est généralement traité comme une étiquette, mais dans l’apprentissage multimodal auto-supervisé des représentations visuelles et linguistiques [11], le texte est traité comme une modalité de saisie.
Dans le contexte multimodal, le terme auto-supervision a été utilisé pour désigner au moins quatre situations : (1) à partir de données multimodales automatiquement appariées Apprentissage sans étiquette – par exemple des films avec des pistes vidéo et audio [23], ou des données d'image et de profondeur provenant de caméras RGBD [24]. (2) Apprentissage à partir de données multimodales, dans lesquelles une modalité a été annotée manuellement, ou deux modalités ont été appariées manuellement, mais cette annotation a été créée dans un but différent et peut donc être considérée comme gratuite pour la pré-formation SSML. Par exemple, la mise en correspondance de paires image-légende extraites du Web, telle qu'utilisée dans le CLIP fondateur [11], est en fait un exemple d'apprentissage métrique supervisé [25], [26] où l'appariement est supervisé. Cependant, comme les modèles et les appariements sont disponibles gratuitement à grande échelle, ils sont souvent décrits comme auto-supervisés. Ces données non conservées et créées accidentellement sont souvent de moindre qualité et plus bruyantes que les ensembles de données spécialement conservés tels que COCO [22] et Visual Genome [27]. (3) Apprenez à partir de données multimodales annotées de haute qualité (par exemple, des images sous-titrées manuellement dans COCO [22]), mais avec un objectif de style auto-supervisé tel que Pixel-BERT [28]. (4) Enfin, il existe des méthodes « auto-supervisées » qui utilisent un mélange de données multimodales libres et étiquetées manuellement [29], [30]. Pour les besoins de cette enquête, nous suivons l'idée d'autosupervision et visons à passer à l'échelle en brisant le goulot d'étranglement de l'annotation manuelle. Par conséquent, nous incluons les deux premières catégories et la quatrième catégorie de méthodes en termes de possibilité de s'entraîner sur des données disponibles gratuitement. Nous excluons les méthodes présentées uniquement pour les ensembles de données organisés manuellement, car elles appliquent des objectifs typiques d'« auto-supervision » sur les ensembles de données organisés (par exemple, prédiction masquée).
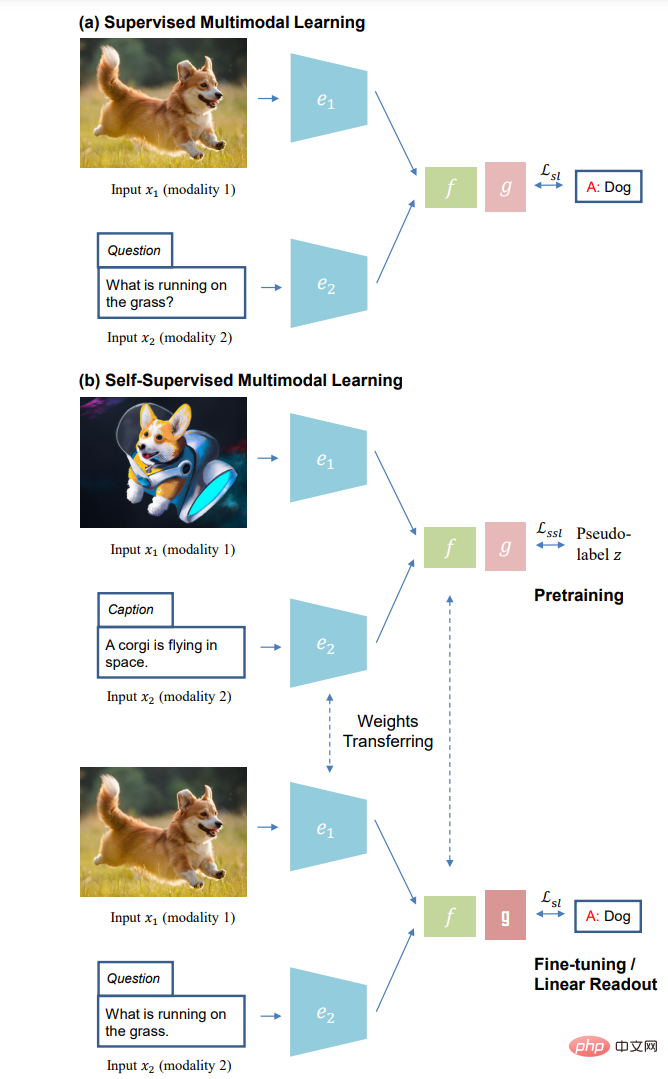
(a) Apprentissage multimodal supervisé et (b) auto-supervisé Paradigme d'apprentissage de l'apprentissage multimodal : pré-formation auto-supervisée sans annotation manuelle (en haut) réglage fin supervisé des tâches en aval (); bas) ).
3. Fonction objectif
Dans cette section, nous présenterons la fonction objectif utilisée pour entraîner trois catégories d'algorithmes multimodaux auto-supervisés : la discrimination d'instance, le clustering et la prédiction de masque. Enfin, nous avons également discuté des cibles hybrides.
3.1 Discrimination d'instance
Dans l'apprentissage monomode, la discrimination d'instance (ID) traite chaque instance dans les données d'origine comme une classe distincte et entraîne le modèle à distinguer différentes instances. Dans le contexte de l'apprentissage multimodal, la discrimination d'instance vise généralement à déterminer si les échantillons de deux modalités d'entrée proviennent de la même instance, c'est-à-dire appariés. Ce faisant, il tente d’aligner l’espace de représentation des paires de modèles tout en éloignant davantage l’espace de représentation des différentes paires d’instances. Il existe deux types d'objectifs de reconnaissance d'instance : la prédiction contrastive et la prédiction correspondante, en fonction de la manière dont l'entrée est échantillonnée.
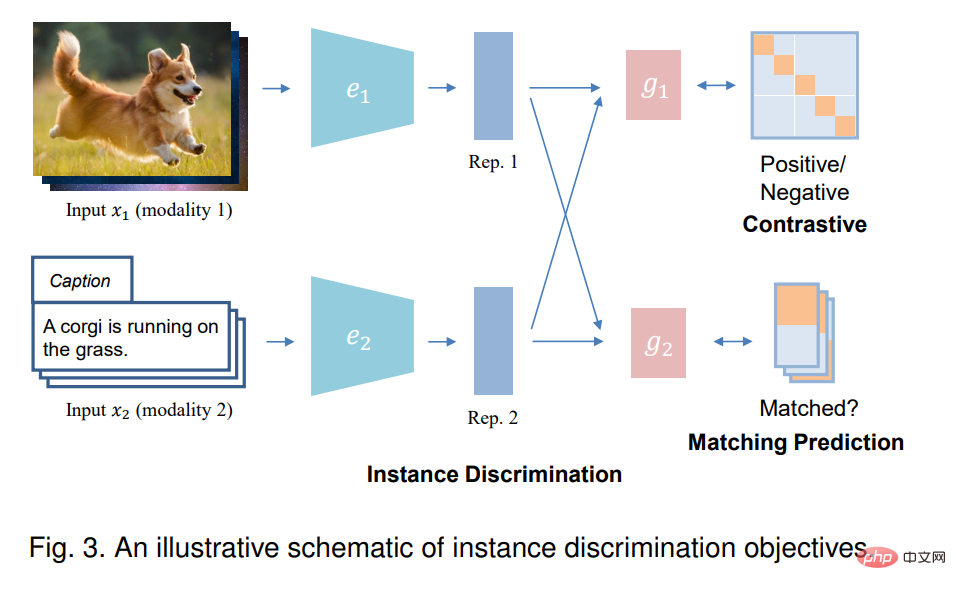
3.2 Clustering
Les méthodes de clustering supposent que l'application d'un clustering de bout en bout entraîné entraînera un regroupement des données en fonction de caractéristiques sémantiquement importantes. En pratique, ces méthodes prédisent de manière itérative les affectations de clusters de représentations codées et utilisent ces prédictions (également appelées pseudo-étiquettes) comme signaux de supervision pour mettre à jour les représentations de fonctionnalités. Le clustering multimodal offre la possibilité d'apprendre les représentations multimodales et également d'améliorer le clustering traditionnel en supervisant d'autres modalités à l'aide de pseudo-étiquettes pour chaque modalité.
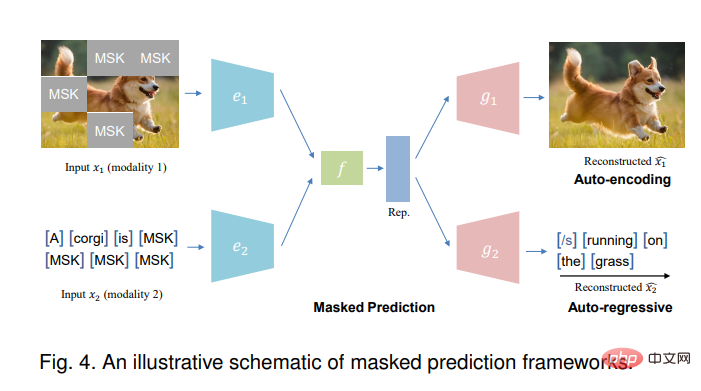
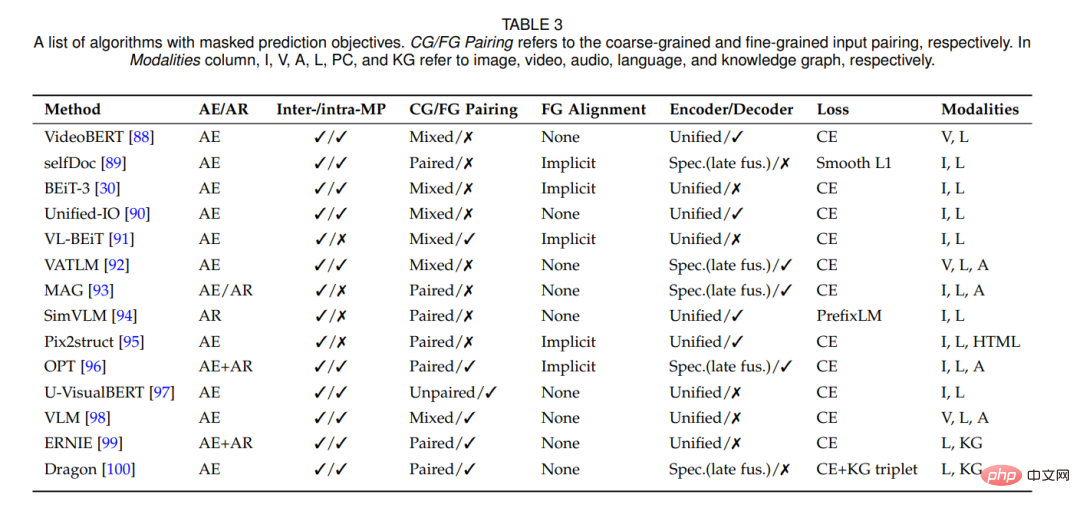
3.3 Prédiction de masque
La tâche de prédiction de masque peut être effectuée en utilisant un codage automatique (similaire à BERT [101]) ou des méthodes de régression automatique (similaires à GPT [102]).
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Tendances technologiques à surveiller en 2023
- Comment l'intelligence artificielle apporte un nouveau travail quotidien aux équipes des centres de données
- L'intelligence artificielle ou l'automatisation peuvent-elles résoudre le problème de la faible efficacité énergétique des bâtiments ?
- Co-fondateur d'OpenAI interviewé par Huang Renxun : les capacités de raisonnement de GPT-4 n'ont pas encore atteint les attentes
- Bing de Microsoft surpasse Google en termes de trafic de recherche grâce à la technologie OpenAI