
Maison >développement back-end >Tutoriel Python >Partagez de bons exemples pour apprendre la visualisation de données Python !
Partagez de bons exemples pour apprendre la visualisation de données Python !

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBavant
- 2023-04-25 23:04:051078parcourir

Bonjour à tous, je suis Frère J. (Envoyer un livre à la fin de l'article)
Utiliser la visualisation pour explorer les graphiques
1 Visualisation des données et graphiques d'exploration
La visualisation des données fait référence. à l'utilisation de graphiques ou de tableaux pour présenter les données. Les graphiques peuvent présenter clairement la nature des données et les relations entre les données ou les attributs, ce qui facilite l'interprétation du graphique. Grâce au graphique exploratoire, les utilisateurs peuvent comprendre les caractéristiques des données, trouver des tendances dans les données et abaisser le seuil de compréhension des données.
2. Exemples de graphiques courants
Ce chapitre utilise principalement Pandas pour dessiner des graphiques au lieu d'utiliser le module Matplotlib. En fait, Pandas a intégré les méthodes de dessin de Matplotlib dans DataFrame, donc dans les applications pratiques, les utilisateurs peuvent terminer le travail de dessin sans référencer directement Matplotlib.
1. Graphique linéaire
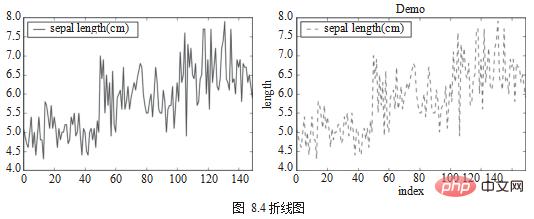
Le graphique linéaire est le graphique le plus basique, qui peut être utilisé pour montrer la relation entre les données continues dans différents domaines. La méthode plot.line() est utilisée pour dessiner un graphique linéaire et des paramètres tels que la couleur et la forme peuvent être définis. En termes d'utilisation, la méthode de dessin du diagramme en lignes divisées hérite complètement de l'utilisation de Matplotlib, le programme doit donc également appeler plt.show() à la fin pour générer le diagramme, comme le montre la figure 8.4.
df_iris[['sepal length (cm)']].plot.line() plt.show() ax = df[['sepal length (cm)']].plot.line(color='green',title="Demo",style='--') ax.set(xlabel="index", ylabel="length") plt.show()
2. Le diagramme à nuages de points
est utilisé pour afficher les différences entre les données discrètes dans différentes relations de champs. Les nuages de points sont dessinés à l'aide de df.plot.scatter(), comme le montre la figure 8.5.
df = df_iris
df.plot.scatter(x='sepal length (cm)', y='sepal width (cm)')
from matplotlib import cm
cmap = cm.get_cmap('Spectral')
df.plot.scatter(x='sepal length (cm)',
y='sepal width (cm)',
s=df[['petal length (cm)']]*20,
c=df['target'],
cmap=cmap,
title='different circle size by petal length (cm)')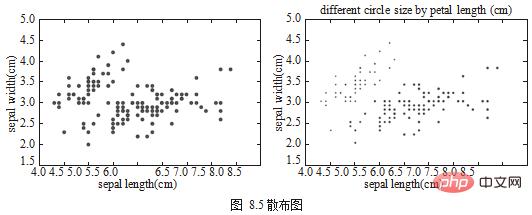
3. Histogramme et graphique à barres
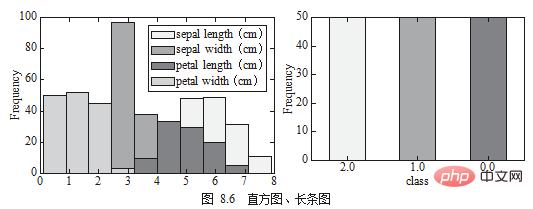
L'histogramme est généralement utilisé dans la même colonne présentant la distribution continue. données, un autre graphique similaire à un histogramme est un graphique à barres, utilisé pour afficher la même colonne, comme le montre la figure 8.6.
df[['sepal length (cm)', 'sepal width (cm)', 'petal length (cm)','petal width (cm)']].plot.hist() 2 df.target.value_counts().plot.bar()
4. Graphique à secteurs, graphique à cases
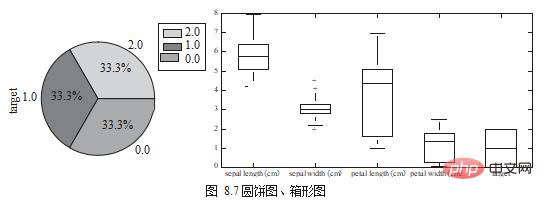
Le graphique à secteurs peut être utilisé pour afficher la même proportion de chaque catégorie. dans le champ, et le diagramme en boîtes (Box Chart) est utilisé pour visualiser le même champ ou comparer les différences de distribution des données dans différents champs, comme le montre la figure 8.7.
df.target.value_counts().plot.pie(legend=True) df.boxplot(column=['target'],figsize=(10,5))
Partage pratique d'exploration de données
Cette section utilise deux ensembles de données réels pour démontrer réellement plusieurs techniques d'exploration de données.
1. Enquête sur la communauté américaine de 2013
Dans l'enquête sur la communauté américaine (American Community Survey), environ 3,5 millions de ménages sont interrogés chaque année sur qui ils sont et quelles sont leurs questions détaillées. sur la façon de vivre. L'enquête couvre un certain nombre de sujets, notamment l'ascendance, l'éducation, le travail, les transports, l'utilisation d'Internet et la résidence.
Source des données : https://www.kaggle.com/census/2013-american-community-survey.
Nom des données : 2013 American Community Survey.
Observez d'abord l'apparence et les caractéristiques des données, ainsi que la signification, le type et la portée de chaque champ.
# 读取数据
df = pd.read_csv("./ss13husa.csv")
# 栏位种类数量
df.shape
# (756065,231)
# 栏位数值范围
df.describe()Connectez d'abord les deux ss13pusa.csv. Ces données contiennent un total de 300 000 données, avec 3 champs : SCHL (School Level), PINCP (Revenu) et ESR (Work Status, Work Status).
pusa = pd.read_csv("ss13pusa.csv") pusb = pd.read_csv("ss13pusb.csv")
# 串接两份数据
col = ['SCHL','PINCP','ESR']
df['ac_survey'] = pd.concat([pusa[col],pusb[col],axis=0)Regroupez les données en fonction des diplômes universitaires, observez la proportion de nombres ayant des diplômes universitaires différents, puis calculez leur revenu moyen.
group = df['ac_survey'].groupby(by=['SCHL']) print('学历分布:' + group.size())
group = ac_survey.groupby(by=['SCHL']) print('平均收入:' +group.mean())2. Ensemble de données sur les prix des maisons de Boston
L'ensemble de données sur les prix des maisons de Boston contient des informations sur le logement dans la région de Boston, dont 506 échantillons de données et 13 dimensions.
Source des données : https://archive.ics.uci.edu/ml/machine-learning-databases/housing/.
Nom des données : Ensemble de données sur les prix des maisons à Boston.
Observez d'abord l'apparence et les caractéristiques des données, ainsi que la signification, le type et la portée de chaque champ.
La distribution des prix de l'immobilier (MEDV) peut être tracée sous la forme d'un histogramme, comme le montre la figure 8.8.
df = pd.read_csv("./housing.data")
# 栏位种类数量
df.shape
# (506, 14)
#栏位数值范围df.describe()
import matplotlib.pyplot as plt
df[['MEDV']].plot.hist()
plt.show()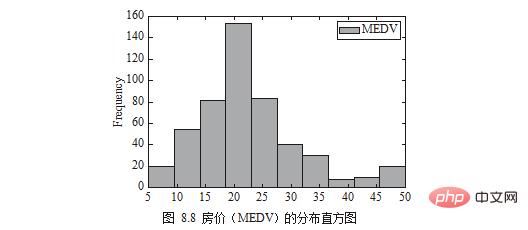
Remarque : L'anglais dans l'image correspond aux noms spécifiés par l'auteur dans le code ou les données. En pratique, les lecteurs peuvent les remplacer par. les mots dont ils ont besoin.
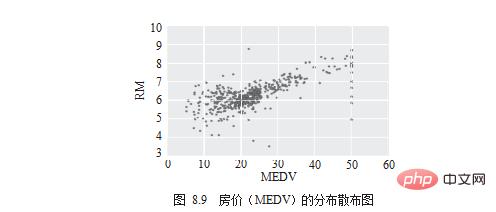
La prochaine chose que vous devez savoir est quelles dimensions sont évidemment liées aux « prix de l'immobilier ». Observez-le d’abord à l’aide d’un diagramme de dispersion, comme le montre la figure 8.9.
# draw scatter chart df.plot.scatter(x='MEDV', y='RM') . plt.show()
最后,计算相关系数并用聚类热图(Heatmap)来进行视觉呈现,如图 8.10 所示。
# compute pearson correlation corr = df.corr() # drawheatmap import seaborn as sns corr = df.corr() sns.heatmap(corr) plt.show()
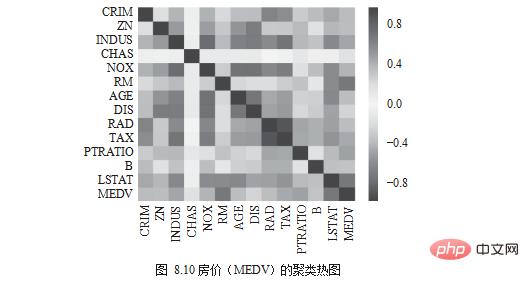
颜色为红色,表示正向关系;颜色为蓝色,表示负向关系;颜色为白色,表示没有关系。RM 与房价关联度偏向红色,为正向关系;LSTAT、PTRATIO 与房价关联度偏向深蓝, 为负向关系;CRIM、RAD、AGE 与房价关联度偏向白色,为没有关系。
声明:本文选自清华大学出版社的《深入浅出python数据分析》一书,略有修改,经出版社授权刊登于此。
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!