
Maison >Périphériques technologiques >IA >Comment évaluer la fiabilité des fondements théoriques du machine learning ?
Comment évaluer la fiabilité des fondements théoriques du machine learning ?

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBavant
- 2023-04-23 13:58:081154parcourir
Dans le domaine du machine learning, certains modèles sont très efficaces, mais nous ne savons pas vraiment pourquoi. En revanche, certains domaines de recherche relativement bien compris ont une applicabilité limitée dans la pratique. Cet article explore les progrès dans divers sous-domaines sur la base de l’utilité et de la compréhension théorique de l’apprentissage automatique.

L'utilité expérimentale est ici une considération globale qui prend en compte l'étendue de l'applicabilité d'une méthode, la facilité de mise en œuvre et, plus important encore, son utilité dans le monde réel. Certaines méthodes sont non seulement très pratiques, mais ont également un large éventail d'applications, tandis que d'autres, bien que très puissantes, sont limitées à des domaines spécifiques. Les méthodes fiables, prévisibles et exemptes de défauts majeurs sont considérées comme ayant une plus grande utilité.
La compréhension dite théorique consiste à considérer l'interprétabilité de la méthode du modèle, c'est-à-dire quelle est la relation entre l'entrée et la sortie, comment obtenir les résultats attendus, quel est le mécanisme interne de cette méthode et à considérer la profondeur et la littérature impliquée dans la méthode.
Les méthodes avec un faible degré de compréhension théorique utilisent généralement des méthodes heuristiques ou un grand nombre de méthodes d'essais et d'erreurs dans la mise en œuvre ; les méthodes avec un degré élevé de compréhension théorique ont souvent des implémentations formelles, avec des fondements théoriques solides et des résultats prévisibles. Les méthodes plus simples, telles que la régression linéaire, ont des limites supérieures théoriques inférieures, tandis que les méthodes plus complexes, telles que l'apprentissage profond, ont des limites supérieures théoriques plus élevées. Lorsqu'il s'agit de la profondeur et de l'exhaustivité de la littérature dans un domaine, le domaine est évalué par rapport aux limites supérieures théoriques des hypothèses du domaine, qui reposent en partie sur l'intuition.
Nous pouvons construire la matrice d'utilité en quatre quadrants, l'intersection des axes de coordonnées représentant un domaine de référence hypothétique avec une compréhension moyenne et une utilité moyenne. Cette approche nous permet d'interpréter les champs de manière qualitative selon le quadrant dans lequel ils se trouvent. Comme le montre la figure ci-dessous, les champs d'un quadrant donné peuvent avoir tout ou partie des caractéristiques de ce quadrant.
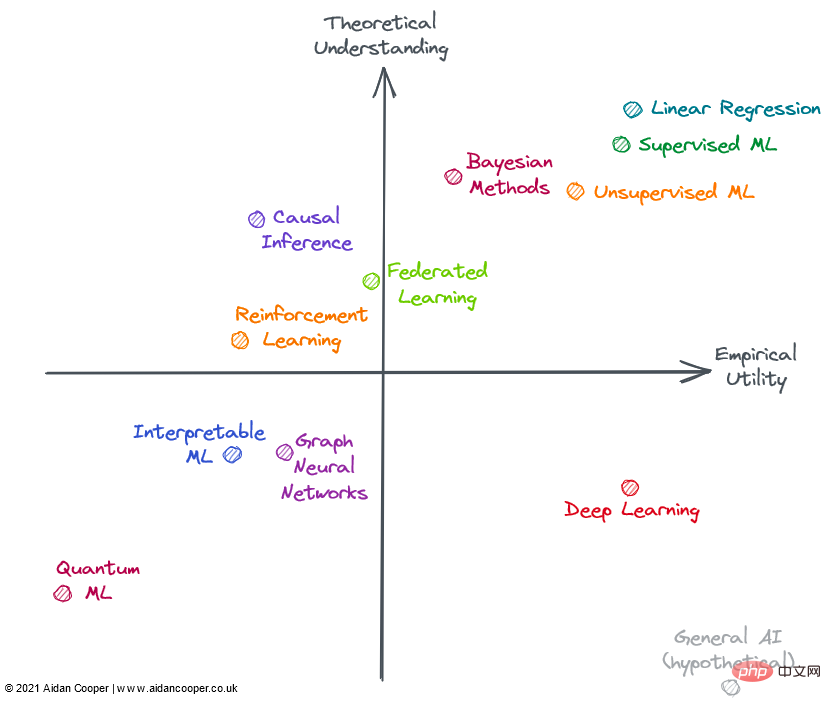
En général, nous nous attendons à ce que l'utilité et la compréhension soient vaguement liées, de sorte que les méthodes avec des niveaux élevés de compréhension théorique sont plus utiles que les méthodes avec de faibles niveaux de compréhension théorique. Cela signifie que la plupart des champs doivent se trouver dans le quadrant inférieur gauche ou dans le quadrant supérieur droit. Les zones éloignées de la diagonale inférieure gauche-supérieure droite représentent des exceptions. Souvent, l’utilité pratique est à la traîne par rapport à la théorie car il faut du temps pour traduire la théorie de la recherche naissante en applications pratiques. Par conséquent, cette diagonale doit être au-dessus de l’origine et non directement à travers celle-ci.
Domaines d'apprentissage automatique en 2022
Tous les domaines illustrés ci-dessus ne sont pas entièrement inclus dans l'apprentissage automatique (ML), mais ils peuvent tous être appliqués dans le contexte du ML ou y sont étroitement liés. De nombreux domaines évalués se chevauchent et ne peuvent pas être clairement décrits : les méthodes avancées d’apprentissage par renforcement, d’apprentissage fédéré et de ML graphique sont souvent basées sur l’apprentissage profond. Par conséquent, je considère les aspects non liés à l’apprentissage profond de leur utilité théorique et pratique.
Quadrant supérieur droit : haute compréhension, grande utilité
La régression linéaire est une méthode simple, facile à comprendre et efficace. Bien que souvent sous-estimé et ignoré. , mais son étendue d'utilisation et sa base théorique approfondie le placent dans le coin supérieur droit de la figure.
L'apprentissage automatique traditionnel est devenu un domaine hautement théorique et pratique. Il a été démontré que les algorithmes de ML complexes, tels que les arbres de décision à gradient amélioré (GBDT), surpassent souvent la régression linéaire dans certaines tâches de prédiction complexes. C’est certainement le cas des problématiques du Big Data. Il existe sans doute encore des lacunes dans la compréhension théorique des modèles surparamétrés, mais la mise en œuvre de l’apprentissage automatique est un processus méthodologique délicat et, lorsqu’il est bien exécuté, les modèles peuvent fonctionner de manière fiable au sein de l’industrie.
Cependant, la complexité et la flexibilité supplémentaires entraînent certaines erreurs, c'est pourquoi j'ai placé l'apprentissage automatique à gauche de la régression linéaire. En général, l’apprentissage automatique supervisé est plus sophistiqué et plus efficace que son homologue non supervisé, mais les deux méthodes résolvent efficacement différents domaines de problèmes.
Les méthodes bayésiennes ont un culte parmi les praticiens qui vantent leur supériorité sur les méthodes statistiques classiques plus populaires. Les modèles bayésiens sont particulièrement utiles dans certaines situations : les estimations ponctuelles seules ne suffisent pas et les estimations de l'incertitude sont importantes ; lorsque les données sont limitées ou très manquantes et lorsque vous comprenez le processus de génération de données que vous souhaitez inclure explicitement dans l'heure du modèle ; L'utilité des modèles bayésiens est limitée par le fait que, pour de nombreux problèmes, les estimations ponctuelles sont suffisamment bonnes et que les utilisateurs utilisent simplement par défaut des méthodes non bayésiennes. De plus, il existe des moyens de quantifier l'incertitude dans le ML traditionnel (ils sont rarement utilisés). Il est souvent plus facile d'appliquer simplement des algorithmes de ML aux données sans avoir à prendre en compte le mécanisme de génération de données et les priorités. Les modèles bayésiens sont également coûteux en termes de calcul et seraient plus utiles si les progrès théoriques aboutissaient à de meilleures méthodes d’échantillonnage et d’approximation.
Quadrant inférieur droit : faible compréhension, grande utilité
Contrairement aux progrès réalisés dans la plupart des domaines, l'apprentissage profond a obtenu des succès étonnants, même si les aspects théoriques se sont révélés fondamentalement difficiles à progresser. L'apprentissage profond incarne de nombreuses caractéristiques d'une approche peu connue : les modèles sont instables, difficiles à construire de manière fiable, configurés sur la base d'heuristiques faibles et produisent des résultats imprévisibles. Des pratiques douteuses telles que le « peaufinage » aléatoire des graines sont courantes et les mécanismes du modèle de travail sont difficiles à expliquer. Cependant, l’apprentissage profond continue de progresser et atteint des niveaux de performance surhumains dans des domaines tels que la vision par ordinateur et le traitement du langage naturel, ouvrant ainsi la voie à un monde de tâches autrement incompréhensibles, comme la conduite autonome.
Hypothétiquement, l’IA générale occupera le coin inférieur droit car, par définition, la superintelligence dépasse la compréhension humaine et peut être utilisée pour résoudre n’importe quel problème. Actuellement, il n’est inclus qu’à titre d’expérience de pensée.
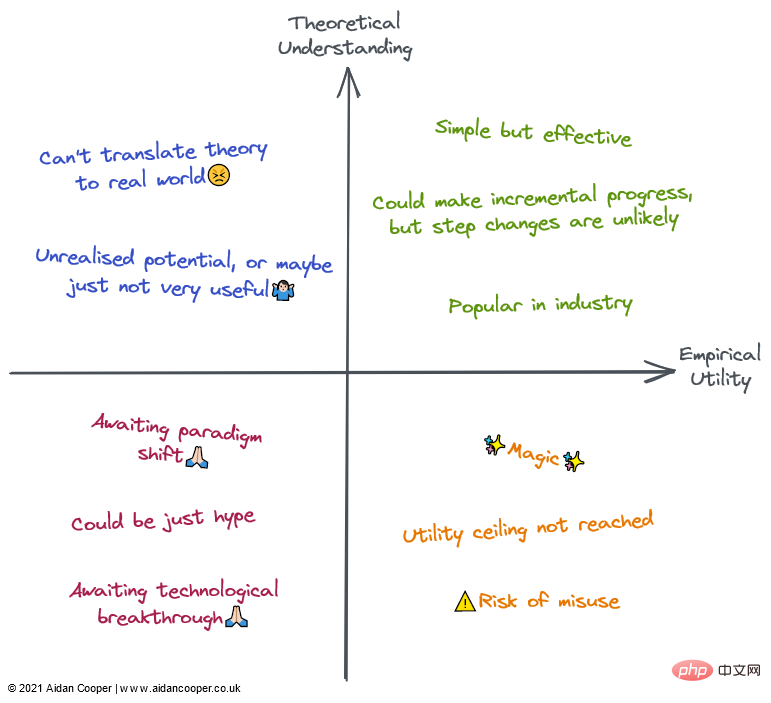
Description qualitative de chaque quadrant. Les champs peuvent être décrits par tout ou partie de leurs descriptions dans leurs régions correspondantes
Quadrant supérieur gauche : compréhension élevée, faible utilité
La plupart des formes d'inférence causale ne relèvent pas de l'apprentissage automatique, mais parfois elles le sont, et sont toujours intéressantes pour la prédictivité modèles. La causalité peut être divisée en essais contrôlés randomisés (ECR) et en méthodes plus sophistiquées d'inférence causale, qui tentent de mesurer les relations causales à partir de données d'observation. Les ECR sont théoriquement simples et donnent des résultats rigoureux, mais ils sont souvent coûteux et peu pratiques, voire impossibles, à mener dans le monde réel et ont donc une utilité limitée. Les méthodes d’inférence causale imitent essentiellement les ECR sans rien faire, ce qui les rend beaucoup plus faciles à réaliser, mais il existe un certain nombre de limitations et d’écueils qui peuvent invalider les résultats. Dans l'ensemble, la causalité reste une recherche frustrante, dans laquelle les méthodes actuelles sont souvent inadaptées aux questions que nous souhaitons poser, à moins que ces questions ne puissent être explorées au moyen d'essais contrôlés randomisés, ou qu'elles ne s'intègrent parfaitement dans un certain cadre (par exemple, en tant que résultat accidentel d'un " expérience naturelle »).
L'apprentissage fédéré (FL) est un concept intéressant qui retient très peu d'attention - probablement parce que ses applications les plus intéressantes nécessitent une distribution sur un grand nombre de smartphones, de sorte que FL ne peut être réellement étudié que par deux acteurs : Apple et Google. Il existe d’autres cas d’utilisation de FL, comme la mise en commun d’ensembles de données propriétaires, mais la coordination de ces initiatives se heurte à des défis politiques et logistiques, ce qui limite leur utilité dans la pratique. Pourtant, pour ce qui semble être un concept fantaisiste (résumé en gros par : "Mettez le modèle dans les données, plutôt que les données dans le modèle"), FL fonctionne et a des applications dans des domaines tels que la prédiction de texte au clavier et les recommandations d'actualités personnalisées Tangible. exemples de réussite. La théorie et la technologie de base qui sous-tendent la FL semblent être suffisantes pour une application plus large de la FL.
L'apprentissage par renforcement (RL) a atteint des niveaux de capacité sans précédent dans des jeux tels que les échecs, le Go, le poker et le DotA. Mais en dehors des jeux vidéo et des environnements de simulation, l’apprentissage par renforcement n’a pas encore été traduit de manière convaincante en applications concrètes. La robotique était censée être la prochaine frontière de RL, mais cela ne s'est pas produit : la réalité semblait plus difficile que l'environnement très contraint du jouet. Cela dit, les réalisations de RL jusqu'à présent sont encourageantes, et quelqu'un qui aime vraiment les échecs pourrait affirmer que son utilité devrait être encore plus grande. J'aimerais voir RL réaliser certaines de ses applications pratiques potentielles avant de le placer sur le côté droit de la matrice.
Quadrant inférieur gauche : faible compréhension, faible utilité
Le réseau neuronal graphique (GNN) est désormais un domaine très populaire dans l'apprentissage automatique et a obtenu des résultats prometteurs dans de nombreux domaines. Mais pour bon nombre de ces exemples, il n’est pas clair si les GNN sont meilleurs que les alternatives utilisant des données structurées plus traditionnelles associées à des architectures d’apprentissage en profondeur. Les problèmes où les données sont naturellement structurées sous forme de graphiques, comme les molécules en chimioinformatique, semblent avoir des résultats GNN plus convaincants (bien qu'ils soient généralement inférieurs aux méthodes non liées aux graphiques). Plus que dans la plupart des domaines, il semble y avoir un écart important entre les outils open source permettant de former des GNN à grande échelle et les outils internes utilisés dans l’industrie, ce qui limite la faisabilité de grands GNN en dehors de ces jardins clos. La complexité et l’étendue du domaine suggèrent une limite supérieure théorique élevée, de sorte qu’il devrait y avoir une marge pour que les GNN mûrissent et démontrent de manière convaincante leurs avantages pour certaines tâches, ce qui conduira à une plus grande utilité. Les GNN pourraient également bénéficier des avancées technologiques, car les graphiques ne s’adaptent actuellement pas naturellement au matériel informatique existant.
L'apprentissage automatique interprétable (IML) est un domaine important et prometteur qui continue de retenir l'attention. Des technologies telles que SHAP et LIME sont devenues des outils très utiles pour interroger les modèles ML. Cependant, en raison d’une adoption limitée, l’utilité des approches existantes n’a pas encore été pleinement exploitée : des bonnes pratiques solides et des lignes directrices de mise en œuvre doivent encore être établies. Cependant, la principale faiblesse actuelle de l’IML est qu’il ne répond pas à la question causale qui nous intéresse réellement. IML explique comment les modèles font des prédictions, mais n'explique pas comment les données sous-jacentes leur sont causalement liées (même si cela est souvent mal interprété comme ceci). Avant des avancées théoriques majeures, les utilisations légitimes de l’IML se limitaient principalement au débogage/surveillance de modèles et à la génération d’hypothèses.
L'apprentissage automatique quantique (QML) est bien en dehors de ma timonerie, mais semble actuellement être un exercice hypothétique attendant patiemment que des ordinateurs quantiques viables soient disponibles. Jusque-là, QML occupait une place insignifiante dans le coin inférieur gauche.
Progrès progressifs, sauts technologiques et changements de paradigme
Il existe trois mécanismes principaux par lesquels la compréhension théorique et la matrice d'utilité empirique (Figure 2) sont parcourues sur le terrain.
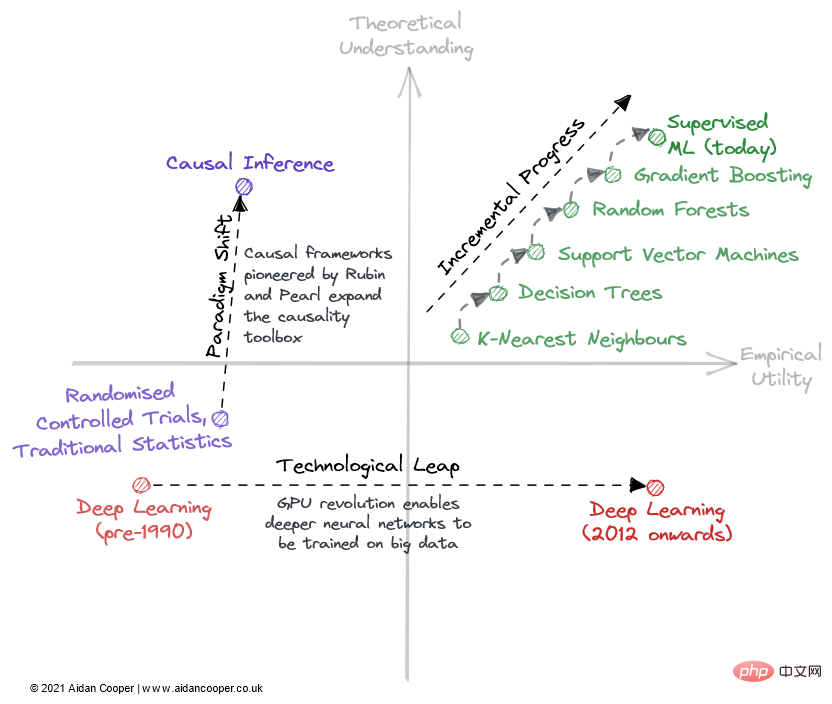
Exemple illustratif de la façon dont les champs peuvent être parcourus à travers une matrice.
La progression progressive est une progression lente et régulière qui remonte le champ en pouces sur le côté droit de la matrice. Un bon exemple en est l’apprentissage automatique supervisé au cours des dernières décennies, au cours desquelles des algorithmes prédictifs de plus en plus efficaces ont été affinés et adoptés, nous offrant ainsi la puissante boîte à outils dont nous disposons aujourd’hui. Le progrès progressif est le statu quo dans tous les domaines matures, à l’exception des périodes de mouvements plus spectaculaires dues aux sauts technologiques et aux changements de paradigme.
En raison des avancées technologiques, certains domaines ont connu des changements majeurs dans le progrès scientifique. Le domaine de l'*apprentissage profond* n'a pas été ébranlé par ses fondements théoriques, découverts plus de 20 ans avant le boom de l'apprentissage profond des années 2010 : c'est le traitement parallèle alimenté par des GPU grand public qui a alimenté sa renaissance. Les sauts technologiques apparaissent généralement comme des sauts vers la droite le long de l’axe de l’utilité empirique. Cependant, toutes les avancées technologiques ne constituent pas des pas de géant. L'apprentissage profond d'aujourd'hui se caractérise par des progrès progressifs réalisés grâce à la formation de modèles de plus en plus grands utilisant davantage de puissance de calcul et un matériel de plus en plus spécialisé.
Le mécanisme ultime du progrès scientifique dans ce cadre est le changement de paradigme. Comme le notait Thomas Kuhn dans son livre The Structure of Scientific Revolutions, les changements de paradigme représentent des changements importants dans les concepts fondamentaux et les pratiques expérimentales des disciplines scientifiques. Le cadre causal mis au point par Donald Rubin et Judea Pearl en est un exemple, élevant le domaine de la causalité des essais contrôlés randomisés et de l'analyse statistique traditionnelle à une discipline mathématique plus puissante sous la forme d'inférence causale. Les changements de paradigme se manifestent souvent par un mouvement ascendant dans la compréhension, qui peut suivre ou être accompagné d’une augmentation de l’utilité.
Cependant, un changement de paradigme peut traverser la matrice dans n’importe quelle direction. Lorsque les réseaux de neurones (et par la suite les réseaux de neurones profonds) se sont imposés comme un paradigme distinct du ML traditionnel, cela correspondait initialement à un déclin en termes de praticité et de compréhension. De nombreux domaines émergents s’écartent ainsi de domaines de recherche plus établis.
La révolution scientifique de la prédiction et du Deep Learning
Pour résumer, voici quelques prédictions spéculatives sur ce qui, je pense, pourrait arriver dans le futur (Tableau 1). Les champs du quadrant supérieur droit sont omis car ils sont trop matures pour constater des progrès significatifs.
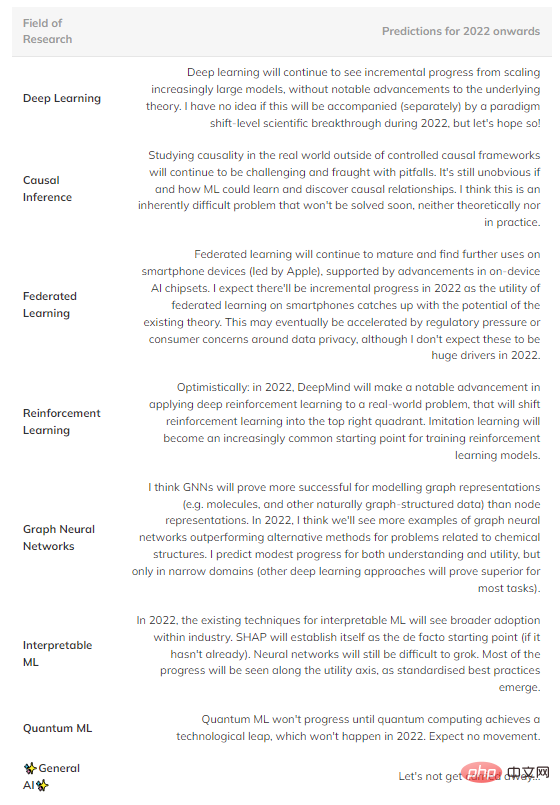
Tableau 1 : Prévisions des progrès futurs dans plusieurs domaines majeurs du machine learning.
Cependant, une observation plus importante que la façon dont les domaines individuels se développent est la tendance générale vers l'empirisme et la volonté croissante de reconnaître une compréhension théorique globale.
De l'expérience historique, généralement les théories (hypothèses) apparaissent en premier, puis les idées sont formulées. Mais l’apprentissage profond a inauguré un nouveau processus scientifique qui va à l’encontre de cette réalité. Autrement dit, les méthodes sont censées démontrer des performances de pointe avant que quiconque se concentre sur la théorie. Les résultats empiriques sont rois, la théorie est facultative.
Cela a conduit à un jeu systématique et généralisé de la recherche sur l'apprentissage automatique pour obtenir les derniers résultats de pointe en modifiant simplement les méthodes existantes et en s'appuyant sur le hasard pour dépasser la ligne de base, plutôt que de faire progresser de manière significative la théorie dans le domaine. Mais c’est peut-être le prix que nous payons pour cette nouvelle vague d’essor du machine learning.
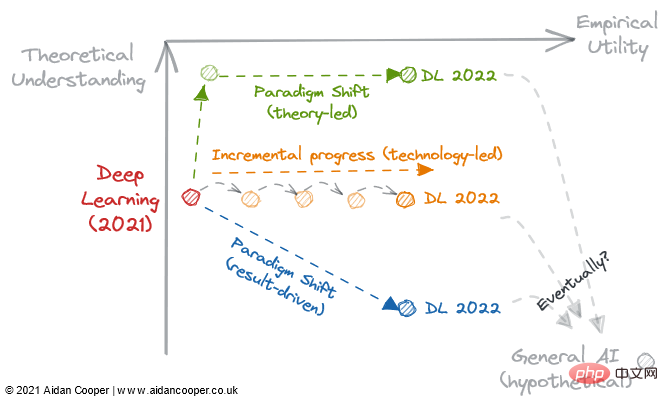
Figure 3 : 3 trajectoires potentielles pour le développement du deep learning en 2022.
2022 pourrait être un tournant si l’apprentissage profond devient de manière irréversible un processus axé sur les résultats et relègue la compréhension théorique au rang d’optionnelle. Nous devrions réfléchir aux questions suivantes :
Les avancées théoriques permettront-elles à notre compréhension de rattraper son retard sur la pratique et de transformer l'apprentissage profond en une discipline plus structurée comme l'apprentissage automatique traditionnel ?
La littérature existante sur l'apprentissage profond est-elle suffisante pour permettre à l'utilité d'augmenter indéfiniment, simplement en s'étendant à des modèles de plus en plus grands ?
Ou une avancée empirique nous mènera-t-elle plus loin dans le terrier du lapin, vers un nouveau paradigme qui améliore l’utilité, même si nous en savons moins à ce sujet ?
L'une de ces voies mène-t-elle à l'intelligence artificielle générale ? Seul le temps nous le dira.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Tendances technologiques à surveiller en 2023
- Comment l'intelligence artificielle apporte un nouveau travail quotidien aux équipes des centres de données
- L'intelligence artificielle ou l'automatisation peuvent-elles résoudre le problème de la faible efficacité énergétique des bâtiments ?
- Co-fondateur d'OpenAI interviewé par Huang Renxun : les capacités de raisonnement de GPT-4 n'ont pas encore atteint les attentes
- Bing de Microsoft surpasse Google en termes de trafic de recherche grâce à la technologie OpenAI