
Maison >Périphériques technologiques >IA >Aperçu de l'état actuel de la technologie d'apprentissage fédéré et de ses applications en traitement d'images
Aperçu de l'état actuel de la technologie d'apprentissage fédéré et de ses applications en traitement d'images

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBavant
- 2023-04-23 12:55:111646parcourir
Ces dernières années, les graphiques ont été largement utilisés pour représenter et traiter des données complexes dans de nombreux domaines, tels que les soins médicaux, les transports, la bioinformatique et les systèmes de recommandation. La technologie d'apprentissage automatique graphique est un outil puissant pour obtenir des informations riches cachées dans des données complexes et a démontré de solides performances dans des tâches telles que la classification des nœuds et la prédiction des liens.
Bien que la technologie d'apprentissage automatique graphique ait fait des progrès significatifs, la plupart d'entre elles nécessitent que les données graphiques soient stockées de manière centralisée sur une seule machine. Cependant, avec l’accent mis sur la sécurité des données et la confidentialité des utilisateurs, le stockage centralisé des données est devenu dangereux et irréalisable. Les données graphiques sont souvent réparties sur plusieurs sources de données (silos de données) et, pour des raisons de confidentialité et de sécurité, il devient impossible de collecter les données graphiques requises à différents endroits.
Par exemple, une société tierce souhaite former des modèles d'apprentissage automatique graphiques pour certaines institutions financières afin de les aider à détecter les délits financiers potentiels et les clients frauduleux. Chaque institution financière détient des données privées sur les clients, telles que des données démographiques et des enregistrements de transactions. Les clients de chaque institution financière forment un graphe client dont les bords représentent les enregistrements de transactions. En raison de politiques de confidentialité strictes et de la concurrence commerciale, les données privées des clients de chaque organisation ne peuvent pas être partagées directement avec des sociétés tierces ou d'autres organisations. Dans le même temps, il peut également exister des relations entre institutions, qui peuvent être considérées comme des informations structurelles entre institutions. Le principal défi est donc de former des modèles d'apprentissage automatique graphiques pour la détection de la criminalité financière sur la base de graphiques de clients privés et d'informations structurelles inter-agences sans accès direct aux données des clients privés de chaque institution.
L'apprentissage fédéré (FL) est une solution d'apprentissage automatique distribué qui résout le problème de l'îlot de données grâce à une formation collaborative. Il permet aux participants (c'est-à-dire aux clients) de former conjointement des modèles d'apprentissage automatique sans partager leurs données privées. Par conséquent, combiner FL avec l’apprentissage automatique graphique devient une solution prometteuse aux problèmes ci-dessus.
Dans cet article, des chercheurs de l'Université de Virginie proposent le Federated Graph Machine Learning (FGML). De manière générale, FGML peut être divisé en deux paramètres en fonction du niveau d'informations structurelles : le premier est FL avec des données structurées. Dans FL avec des données structurées, les clients entraînent de manière collaborative des modèles d'apprentissage automatique graphiques en fonction de leurs données graphiques, tandis que les données graphiques sont conservées localement. . Le deuxième type est le FL structuré. Dans le FL structuré, il existe des informations structurelles entre les clients, formant un graphe client. Les graphes clients peuvent être exploités pour concevoir des méthodes d’optimisation conjointe plus efficaces.

Adresse papier : https://arxiv.org/pdf/2207.11812.pdf
Bien que FGML fournisse un modèle prometteur, il reste encore quelques défis :
1 . Les informations inter-clients sont manquantes. En FL avec des données structurées, un scénario courant est que chaque machine client possède un sous-graphe du graphe global et que certains nœuds peuvent avoir des voisins proches appartenant à d'autres clients. Pour des raisons de confidentialité, les nœuds peuvent uniquement regrouper les fonctionnalités de leurs voisins immédiats au sein du client, mais ne peuvent pas accéder aux fonctionnalités situées sur d'autres clients, ce qui conduit à une sous-représentation des nœuds.
2. Fuite de confidentialité de la structure graphique. Dans FL traditionnel, les clients ne sont pas autorisés à exposer les caractéristiques et les étiquettes de leurs échantillons de données. En FL avec des données structurées, la confidentialité des informations structurelles doit également être prise en compte. Les informations structurelles peuvent être exposées directement via une matrice de contiguïté partagée ou indirectement via l'intégration de nœuds de transmission.
3. Hétérogénéité des données entre clients. Contrairement au FL traditionnel où l'hétérogénéité des données provient d'échantillons de données non IID, les données graphiques dans FGML contiennent de riches informations structurelles. Dans le même temps, la structure graphique des différents clients affectera également les performances du modèle d'apprentissage automatique graphique.
4. Stratégies d'utilisation des paramètres. En FL structuré, le graphe client permet aux clients d'obtenir des informations de leurs clients voisins. Dans le FL structuré, des stratégies efficaces doivent être conçues pour exploiter pleinement les informations des voisins coordonnées par un serveur central ou complètement décentralisées.
Pour relever les défis ci-dessus, les chercheurs ont développé un grand nombre d'algorithmes. Divers algorithmes se concentrent actuellement principalement sur les défis et les méthodes du FL standard, avec seulement quelques tentatives pour résoudre des problèmes et des techniques spécifiques en FGML. Quelqu'un a publié un article de synthèse classifiant FGML, mais n'a pas résumé les principales techniques de FGML. Certains articles de synthèse ne couvrent qu'un nombre limité d'articles pertinents en FL et présentent très brièvement la technologie actuelle.
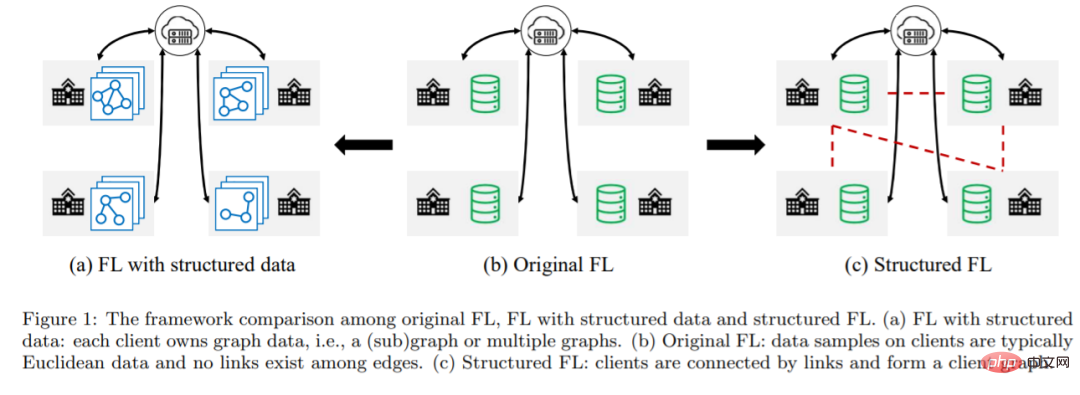
Dans l'article présenté aujourd'hui, l'auteur présente d'abord les concepts de deux conceptions de problèmes en FGML. Ensuite, les derniers progrès technologiques sous chaque shezhi sont passés en revue et les applications pratiques de FGML sont également présentées. et résume les ensembles de données graphiques accessibles et les plates-formes disponibles pour les applications FGML. Enfin, l’auteur donne plusieurs pistes de recherche prometteuses. Les principales contributions de l'article comprennent :
Taxonomie de la technologie FGML : L'article donne une taxonomie de FGML basée sur différents problèmes et résume les principaux défis dans chaque contexte.
Revue complète de la technologie : l'article fournit un aperçu complet de la technologie existante dans FGML. Par rapport à d’autres articles de synthèse existants, les auteurs étudient non seulement un plus large éventail de travaux connexes, mais fournissent également une analyse technique plus détaillée au lieu de simplement énumérer les étapes de chaque méthode.
Applications pratiques : L'article résume pour la première fois les applications pratiques de FGML. Les auteurs les classent selon les domaines d'application et présentent les travaux connexes dans chaque domaine.
Ensembles de données et plates-formes : l'article présente les ensembles de données et les plates-formes existants dans FGML, ce qui est très utile pour les ingénieurs et les chercheurs qui souhaitent développer des algorithmes et déployer des applications dans FGML.
Orientation future : L'article souligne non seulement les limites des méthodes existantes, mais donne également l'orientation future du développement de FGML.
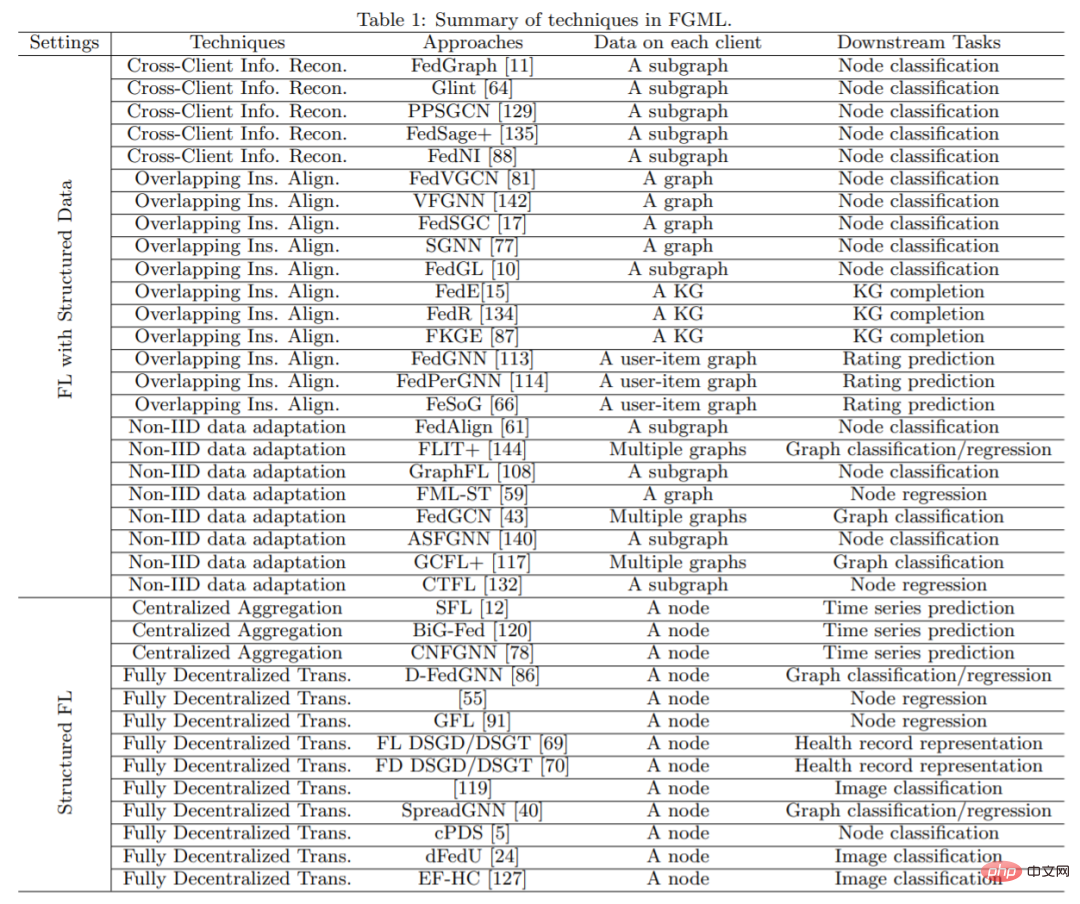
Aperçu de la technologie FGMLVoici une introduction à la structure principale de l'article.
La section 2 présente brièvement les définitions de l'apprentissage automatique des graphes ainsi que les concepts et les défis dans les deux contextes de FGML.
Les sections 3 et 4 passent en revue les technologies dominantes dans les deux contextes. La section 5 explore plus en détail les applications réelles de FGML. La section 6 présente l'ensemble de données Open Graph utilisé dans les articles FGML associés et deux plates-formes pour FGML. Des orientations futures possibles sont fournies dans la section 7 .
Enfin, la section 8 résume le texte intégral. Veuillez vous référer au document original pour plus de détails.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Tendances technologiques à surveiller en 2023
- Comment l'intelligence artificielle apporte un nouveau travail quotidien aux équipes des centres de données
- L'intelligence artificielle ou l'automatisation peuvent-elles résoudre le problème de la faible efficacité énergétique des bâtiments ?
- Co-fondateur d'OpenAI interviewé par Huang Renxun : les capacités de raisonnement de GPT-4 n'ont pas encore atteint les attentes
- Bing de Microsoft surpasse Google en termes de trafic de recherche grâce à la technologie OpenAI