
Maison >Périphériques technologiques >IA >Quelles sont les caractéristiques d'un réseau adapté au pilotage de l'AIGC ?
Quelles sont les caractéristiques d'un réseau adapté au pilotage de l'AIGC ?

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBavant
- 2023-04-22 15:43:17976parcourir
2023 est l’année où la technologie d’intelligence artificielle IA va exploser en popularité.
Les grands modèles AIGC représentés par ChatGPT, GPT-4 et Wen Xinyiyan intègrent l'écriture de texte, le développement de code, la création de poésie et d'autres fonctions en une seule, montrant de fortes capacités de production de contenu et choquant grandement les gens.
En tant que vétéran des communications, outre le modèle AIGC lui-même, Xiao Zaojun est plus préoccupé par la technologie de communication derrière le modèle. Quel type de réseau puissant soutient le fonctionnement de l’AIGC ? De plus, quels types de changements la vague de l’IA apportera-t-elle aux réseaux traditionnels ?
█ AIGC, de quelle puissance de calcul a-t-il besoin ?
Comme nous le savons tous, les données, les algorithmes et la puissance de calcul sont les trois éléments de base du développement de l'intelligence artificielle.
Les grands modèles AIGC mentionnés précédemment sont si puissants non seulement en raison des données massives qui les alimentent, mais aussi parce que les algorithmes évoluent et se mettent à jour constamment. Plus important encore, la puissance de calcul humaine s’est développée dans une certaine mesure. La puissante infrastructure informatique peut pleinement répondre aux besoins informatiques de l'AIGC.
Avec le développement de l'AIGC, les paramètres du modèle de formation sont passés de centaines de milliards à des milliards. Afin de réaliser une formation à si grande échelle, le nombre de GPU pris en charge par la couche sous-jacente a également atteint l'échelle de 10 000 cartes.
Prenons ChatGPT comme exemple. Ils ont utilisé l'infrastructure de supercalcul de Microsoft pour la formation. On dit que 10 000 GPU V100 ont été utilisés pour former un cluster à large bande passante. Une session de formation nécessite environ 3 640 jours-PF de puissance de calcul (soit 1 quadrillion de calculs par seconde, s'exécutant pendant 3 640 jours).
La puissance de calcul FP32 d'un V100 est de 0,014 PFLOPS (unité de puissance de calcul, égale à 1 quadrillion d'opérations en virgule flottante par seconde). Dix mille V100, ça fait 140 PFLOPS.
En d'autres termes, si l'utilisation du GPU est de 100 %, alors il faudra 3640÷140=26 (jours) pour terminer une session de formation.
Il est impossible que l'utilisation du GPU atteigne 100 %. Si elle est calculée à 33 % (l'utilisation supposée fournie par OpenAI), elle serait de 26 fois trois fois, ce qui équivaut à 78 jours.
On peut constater que la puissance de calcul du GPU et l'utilisation du GPU ont un grand impact sur la formation des grands modèles.
La question est alors : quel est le facteur le plus important affectant l’utilisation du GPU ?
La réponse est : Internet.
Dix mille, voire dizaines de milliers de GPU, en tant que cluster informatique, nécessitent une énorme quantité de bande passante pour interagir avec le cluster de stockage. De plus, lorsque le cluster GPU effectue des calculs d’entraînement, ceux-ci ne sont pas indépendants, mais mixtes et parallèles. Il existe un grand nombre d’échanges de données entre les GPU, ce qui nécessite également une bande passante énorme.
Si le réseau n'est pas puissant et que la transmission des données est lente, le GPU devra attendre les données, ce qui entraînera une diminution de l'utilisation. À mesure que l’utilisation diminue, le temps de formation augmentera, les coûts augmenteront et l’expérience utilisateur se détériorera.
L'industrie a déjà créé un modèle pour calculer la relation entre le débit de la bande passante du réseau, le délai de communication et l'utilisation du GPU, comme le montre la figure ci-dessous :

Comme vous pouvez le constater, plus le débit du réseau est fort, plus le GPU est élevé. Utilisation Plus l'utilisation est élevée ; plus le délai dynamique de communication est grand, plus l'utilisation du GPU est faible.
En un mot, ne jouez pas avec les gros modèles sans un bon réseau.
█ Quel type de réseau peut soutenir le fonctionnement de l'AIGC ?
Afin de faire face aux ajustements de réseau provoqués par le calcul en cluster d'IA, l'industrie a également réfléchi à de nombreuses façons.
Il existe trois principales stratégies de réponse traditionnelles : Infiniband, RDMA et les commutateurs modulaires. Jetons un bref coup d’œil à chacun d’eux.
Réseau Infiniband
Le réseau Infiniband (traduit littéralement par technologie de « bande passante infinie », en abrégé IB) devrait être familier aux enfants engagés dans la communication de données.
C'est actuellement le meilleur moyen de construire un réseau haute performance. Il dispose d'une bande passante extrêmement élevée et ne peut atteindre aucune congestion et une faible latence. Ce que ChatGPT et GPT-4 utilisent est considéré comme un réseau Infiniband.
S'il y a un inconvénient au réseau Infiniband, c'est un mot : cher. Par rapport aux réseaux Ethernet traditionnels, le coût du réseau Infiniband sera plusieurs fois plus élevé. Cette technologie est relativement fermée. Il n’existe actuellement qu’un seul fournisseur mature dans l’industrie et les utilisateurs n’ont guère de choix.
- Réseau RDMA
Le nom complet de RDMA est Remote Direct Memory Access. Il s'agit d'un nouveau type de mécanisme de communication. Dans la solution RDMA, les données des applications ne transitent plus par le CPU et le système d'exploitation complexe, mais communiquent directement avec la carte réseau, ce qui non seulement améliore considérablement le débit mais réduit également la latence.
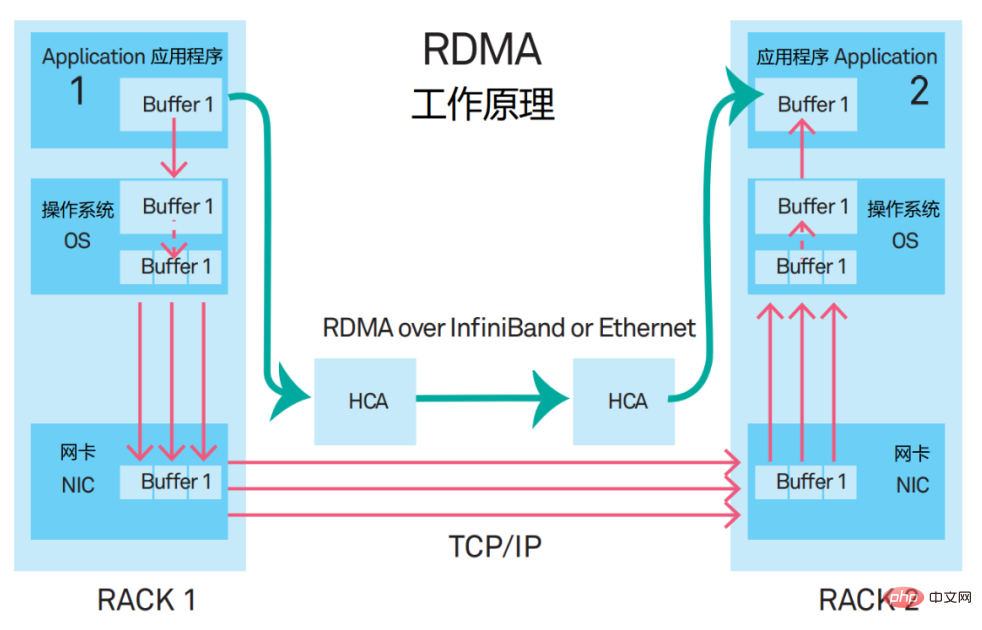
Lorsque RDMA a été proposé pour la première fois, il était diffusé sur le réseau InfiniBand. Désormais, RDMA est progressivement transplanté vers Ethernet.
À l'heure actuelle, la solution réseau dominante pour les réseaux hautes performances consiste à créer un réseau prenant en charge RDMA basé sur le protocole RoCE v2 (RDMA over Converged Ethernet, RDMA based on Converged Ethernet).
Cette solution dispose de deux technologies de correspondance importantes, à savoir PFC (Priority Flow Control, contrôle de flux basé sur la priorité) et ECN (Explicit Congestion Notification, explicite congestion notification). Ce sont des technologies créées pour éviter la congestion du lien. Cependant, si elles sont déclenchées fréquemment, elles entraîneront la suspension ou le ralentissement de l'envoi par l'expéditeur, réduisant ainsi la bande passante de communication. (Ils seront mentionnés ci-dessous)
- Commutateurs de trame
Certaines sociétés Internet étrangères espèrent utiliser des commutateurs de trame (puce DNX + technologie VOQ) pour répondre aux exigences de construction de réseaux haute performance.
DNX : une série de puces de broadcom (Broadcom)
VOQ : Virtual Output Queue, file d'attente de sortie virtuelle
Cette solution semble réalisable, mais elle est également confrontée aux défis suivants.
Tout d'abord, les capacités d'extension des commutateurs modulaires sont moyennes. La taille du châssis limite le nombre maximum de ports. Si vous souhaitez créer un cluster plus grand, vous devez l'étendre horizontalement sur plusieurs châssis.
Deuxièmement, l'équipement des interrupteurs modulaires consomme beaucoup d'énergie. Il y a un grand nombre de puces de carte de ligne, de puces de tissu, de ventilateurs, etc. dans le châssis. La consommation électrique d'un seul appareil dépasse 20 000 watts, et certaines dépassent même 30 000 watts. Les exigences relatives à la capacité d'alimentation de l'armoire sont. trop haut.
Troisièmement, les commutateurs modulaires disposent d'un grand nombre de ports pour un seul appareil et d'un vaste domaine de pannes.
Pour les raisons ci-dessus, les équipements de commutation modulaires ne conviennent qu'au déploiement à petite échelle de clusters informatiques d'IA.
█ Qu'est-ce que DDC exactement
Celles mentionnées ci-dessus sont toutes des solutions traditionnelles. Puisque ces solutions traditionnelles ne fonctionnent pas, nous devons bien sûr trouver de nouvelles voies.
Une toute nouvelle solution appelée DDC a donc fait ses débuts.
DDC, le nom complet est Châssis désagrégé distribué.
Il s'agit d'une "version divisée" du commutateur de châssis avant. Les capacités d'extension des commutateurs modulaires sont insuffisantes, nous pouvons donc simplement les démonter et transformer un appareil en plusieurs appareils, n'est-ce pas acceptable ?

Les équipements de type cadre sont généralement divisés en deux parties : la carte réseau de commutation (fond de panier) et la carte de ligne de service (carte de carte), qui sont connectées entre elles avec des connecteurs. La solution
DDC transforme les cartes réseau de commutation en équipement NCF et les cartes de ligne professionnelle en équipement NCP. Les connecteurs deviennent des fibres optiques. La fonction de gestion des appareils modulaires devient également NCC dans l'architecture DDC.
NCF : Network Cloud Fabric (Network Cloud Management Control Plan)
NCP : Network Cloud Packet Processing (Network Cloud Packet Processing)
NCC : Network Cloud Controller (Network Cloud Controller)
Après DDC Passé de centralisé à distribué, son évolutivité a été considérablement améliorée. Il peut concevoir de manière flexible l'échelle du réseau en fonction de la taille du cluster IA.
Donnons deux exemples (réseau simple POD et réseau multi-POD).
Dans le réseau POD unique, 96 NCP sont utilisés comme points d'accès, parmi eux, le NCP dispose d'un total de 18 interfaces 400G en aval, qui sont chargées de connecter les cartes réseau du cluster informatique AI. Il y a un total de 40 interfaces 200G dans la liaison montante, et un maximum de 40 NCF peuvent être connectés. La bande passante des liaisons montante et descendante à cette échelle a un rapport de survitesse de 1,1 : 1. L'ensemble du POD peut prendre en charge 1 728 interfaces réseau 400G. Calculé sur la base d'un serveur équipé de 8 GPU, il peut prendre en charge 216 serveurs informatiques IA.
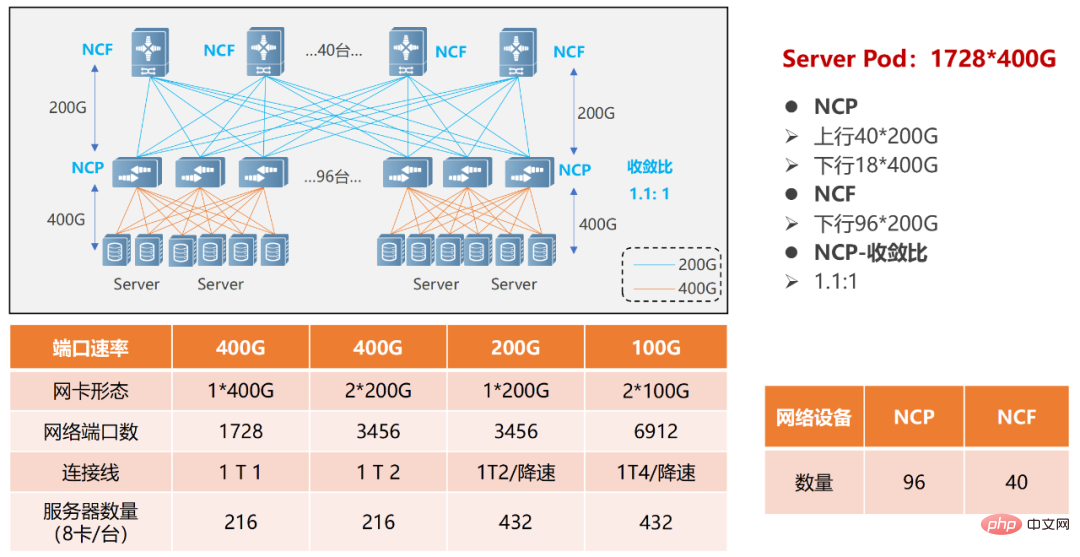
Réseau POD unique
Réseau POD à plusieurs niveaux, l'échelle peut devenir plus grande.
Dans un réseau POD multi-niveaux, l'appareil NCF doit sacrifier la moitié des SerDes pour se connecter au NCF de deuxième niveau. Par conséquent, à l’heure actuelle, un seul POD utilise 48 NCP pour l’accès, avec un total de 18 interfaces 400G dans la liaison descendante.
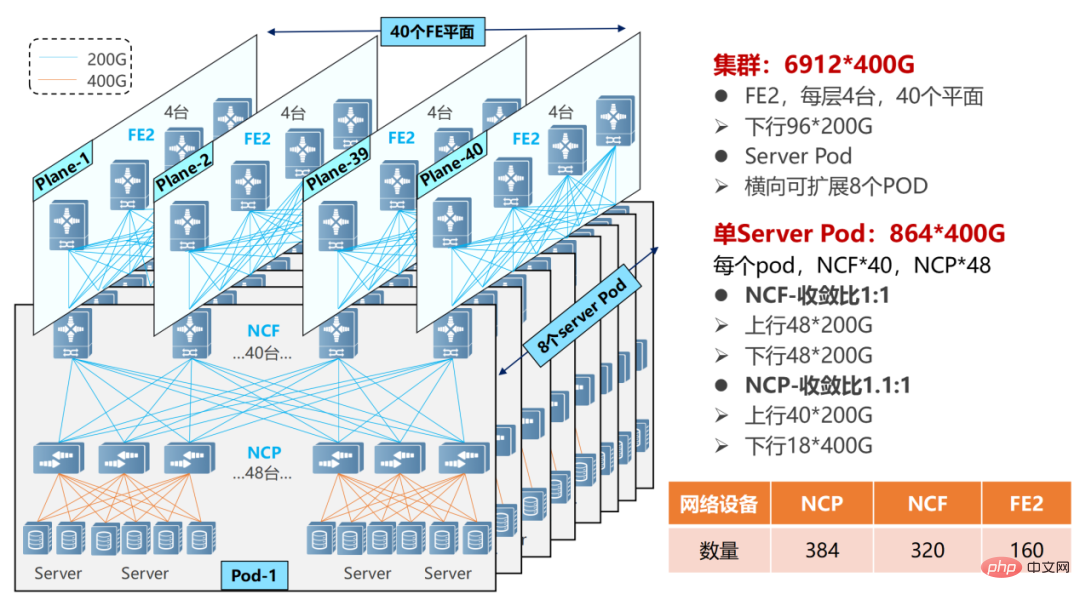
Réseau multiple POD
Un seul POD peut prendre en charge 864 interfaces 400G (48×18). En ajoutant des POD (8) horizontalement, l'échelle peut être étendue et le système global peut prendre en charge un maximum de 6 912 ports réseau 400G (864 × 8).
NCP dispose de 40 liaisons montantes 200G et se connecte à 40 NCF dans le POD. Le NCF du POD utilise 48 interfaces 200G, et les 48 interfaces 200G sont divisées en un groupe de 12 en amont du NCF de deuxième niveau. Le NCF de deuxième niveau utilise 40 avions (Plane), chaque avion possède 4 NCF-P, correspondant à 40 NCF dans le POD.
Atteint un rapport de survitesse de 1,1:1 (la bande passante en direction nord est supérieure à la bande passante en direction sud) au sein du POD de l'ensemble du réseau, tandis qu'un rapport de convergence de 1:1 (bande passante en direction sud/bande passante en direction nord) a été atteint entre le POD et la bande passante NCF secondaire).
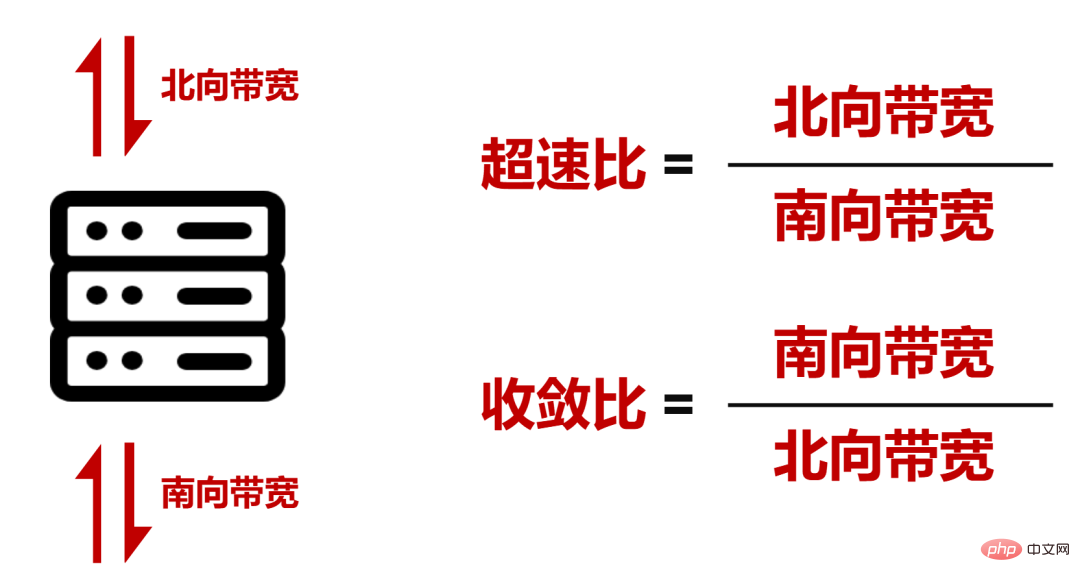
█ Caractéristiques techniques du DDC
Du point de vue de l'échelle et du débit de bande passante, DDC peut déjà répondre aux exigences réseau de la formation de grands modèles d'IA.
Cependant, le processus d'exploitation du réseau est complexe et DDC doit également s'améliorer en termes de résistance aux retards, d'équilibrage de charge et d'efficacité de gestion.
- Basé sur le mécanisme de transfert VOQ+Cell pour lutter contre la perte de paquets
Pendant le processus de fonctionnement du réseau, un trafic en rafale peut se produire, ce qui fait que l'extrémité réceptrice n'a pas le temps de le traiter, provoquant une congestion et perte de paquets.
Afin de faire face à cette situation, DDC adopte un mécanisme de transfert basé sur VOQ+Cell.
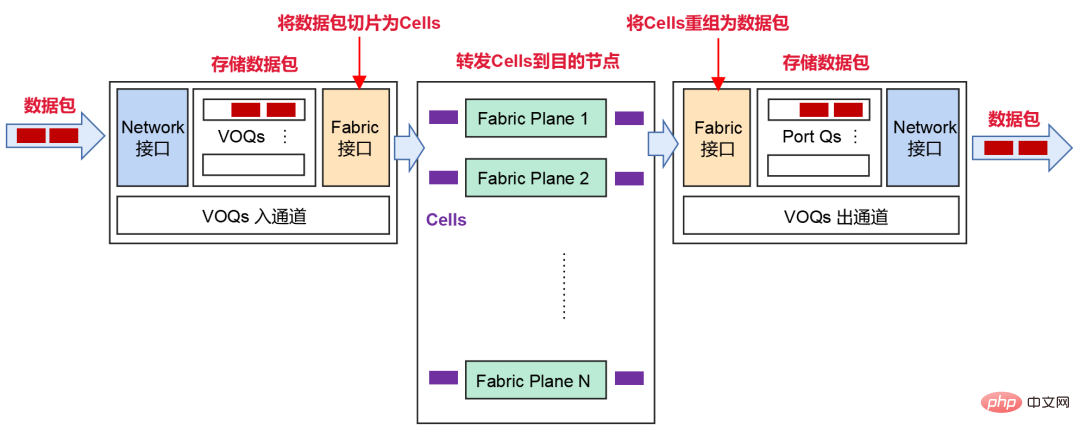
Une fois que l'expéditeur aura reçu le paquet de données du réseau, il sera classé dans VOQ (Virtual Output Queue) pour le stockage.
Avant d'envoyer un paquet de données, NCP enverra d'abord un message de crédit pour déterminer si le destinataire dispose de suffisamment d'espace tampon pour traiter ces messages.
Si l'extrémité de réception est OK, le paquet est fragmenté en cellules (petites tranches du paquet) et la charge est équilibrée dynamiquement sur le nœud Fabric intermédiaire (NCF).
Si le destinataire est temporairement incapable de traiter le message, le message sera temporairement stocké dans le VOQ de l'expéditeur et ne sera pas directement transmis au destinataire.
À la réception, ces Cellules seront réorganisées et stockées, puis transmises au réseau.
Les cellules découpées seront envoyées à l'aide d'un mécanisme d'interrogation. Il peut utiliser pleinement chaque liaison montante et garantir que la quantité de données transmises sur toutes les liaisons montantes est à peu près égale.
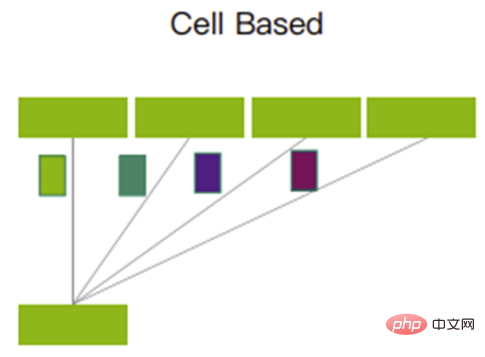
Mécanisme d'interrogation
Ce mécanisme utilise pleinement le cache et peut réduire considérablement la perte de paquets, voire provoquer une perte de paquets. Les retransmissions de données sont réduites et le délai de communication global est plus stable et plus faible, ce qui peut améliorer l'utilisation de la bande passante et ainsi améliorer l'efficacité du débit de l'entreprise.
- Déploiement PFC en un seul saut pour éviter les blocages
Comme nous l'avons mentionné précédemment, la technologie PFC (contrôle de flux basé sur la priorité) est introduite dans le réseau sans perte RDMA pour le contrôle de flux.
En termes simples, PFC consiste à créer 8 canaux virtuels sur une liaison Ethernet et à attribuer une priorité correspondante à chaque canal virtuel, permettant à l'un des canaux virtuels d'être mis en pause et redémarré indépendamment, tout en permettant à d'autres canaux virtuels de Le trafic dans le canal se déroule sans interruption.
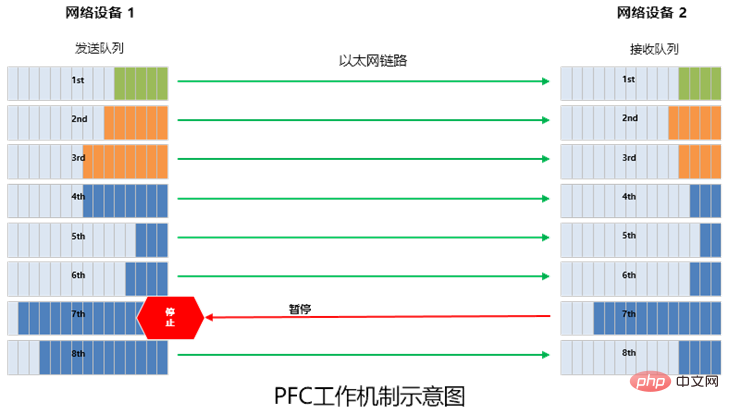
PFC peut implémenter un contrôle de flux basé sur la file d'attente, mais il a également un problème, qui est une impasse.
Le soi-disant blocage est une "impasse" causée par une congestion entre plusieurs commutateurs due à des boucles et à d'autres raisons (la consommation de cache de chaque port dépasse le seuil), et ils attendent tous que l'autre partie se libère ressources » (le trafic vers tous les commutateurs est définitivement bloqué).
Avec le réseau DDC, il n'y a pas de problème de blocage du PFC. Parce que, du point de vue de l’ensemble du réseau, tous les NCP et NCF peuvent être considérés comme un seul appareil. Pour le serveur AI, l'ensemble du DDC n'est qu'un commutateur et il n'y a pas de commutateurs à plusieurs niveaux. Il n’y a donc pas d’impasse.
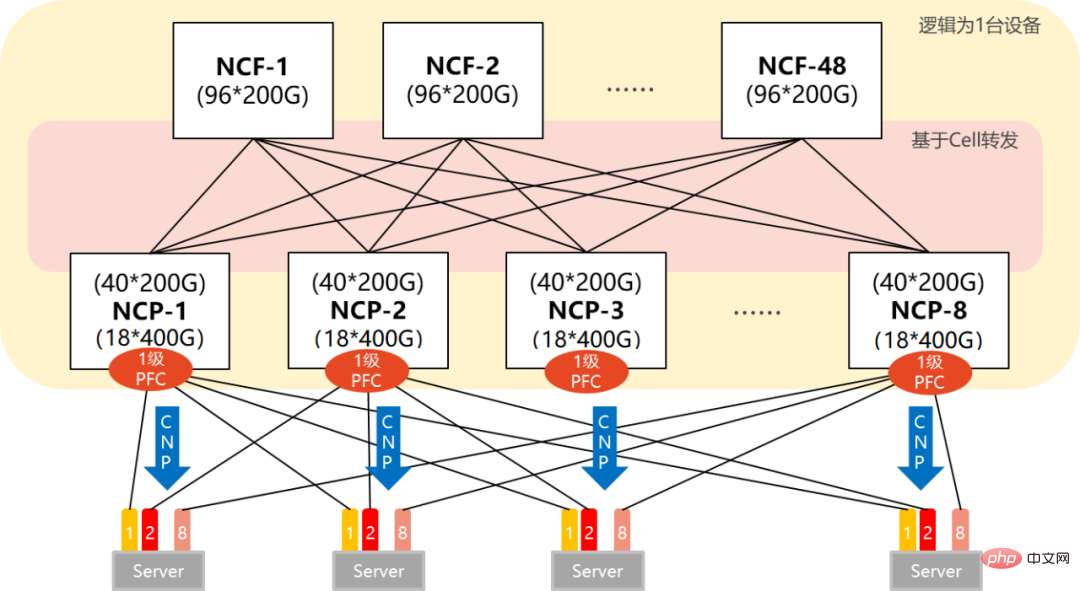
De plus, selon le mécanisme de transfert de données du DDC, ECN (Explicit Congestion Notification) peut être déployé au niveau de l'interface.
Dans le cadre du mécanisme ECN, une fois que le périphérique réseau détecte une congestion dans le trafic RoCE v2 (le mécanisme de crédit et de cache interne ne peut pas prendre en charge le trafic en rafale), il enverra des CNP (paquets de notification de congestion, messages de notification de congestion) au serveur. ), nécessitant une réduction de vitesse.
- OS distribués, améliorez la fiabilité
Enfin, regardons le plan de contrôle de gestion.
Nous avons mentionné plus tôt que dans l'architecture DDC, la fonction de gestion des appareils modulaires devient NCC (Network Cloud Controller). NCC est très important. Si une méthode à point unique est utilisée, si quelque chose ne va pas, cela entraînera la défaillance de l'ensemble du réseau.
Afin d'éviter de tels problèmes, DDC peut annuler le plan de contrôle centralisé de NCC et créer un système d'exploitation (système d'exploitation) distribué.
Basé sur un système d'exploitation distribué, il peut configurer et gérer les équipements via des interfaces standards (Netconf, GRPC, etc.) basées sur un contrôleur d'exploitation et de maintenance SDN. Dans ce cas, chaque NCP et NCF sont gérés indépendamment et disposent de plans de contrôle et de plans de gestion indépendants, ce qui améliore considérablement la fiabilité du système et facilite son déploiement.
█ Les progrès commerciaux du DDC
En résumé, par rapport aux réseaux traditionnels, le DDC présente des avantages significatifs en termes d'échelle du réseau, de capacités d'extension, de fiabilité, de coût et de vitesse de déploiement. C'est le produit des mises à niveau de la technologie réseau et fournit une idée pour renverser l'architecture réseau d'origine, qui peut réaliser le découplage du matériel réseau, l'unification de l'architecture réseau et l'expansion de la capacité de transfert.
L'industrie a utilisé la suite de tests OpenMPI pour effectuer des tests de simulation comparatifs entre les équipements de châssis et les équipements de réseau traditionnels. La conclusion du test est la suivante : dans le scénario All-to-All, par rapport aux réseaux traditionnels, l'utilisation de la bande passante des périphériques de type trame est augmentée d'environ 20 % (correspondant à une augmentation de l'utilisation du GPU d'environ 8 %).
C’est précisément grâce aux avantages significatifs en termes de capacités du DDC que cette technologie est désormais devenue l’orientation clé du développement de l’industrie. Par exemple, Ruijie Networks a pris les devants en lançant deux produits DDC livrables, à savoir le commutateur NCP 400G-RG-S6930-18QC40F1 et le commutateur NCF 200G-RG-X56-96F1. Le commutateur RG-S6930-18QC40F1 mesure 2U de hauteur et fournit 18 ports de panneau 400G, 40 ports en ligne Fabric 200G, 4 ventilateurs et 2 alimentations.
Le commutateur RG-X56-96F1 mesure 4U de hauteur et fournit 96 ports en ligne Fabric 200G, 8 ventilateurs et 4 alimentations.Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Tendances technologiques à surveiller en 2023
- Comment l'intelligence artificielle apporte un nouveau travail quotidien aux équipes des centres de données
- L'intelligence artificielle ou l'automatisation peuvent-elles résoudre le problème de la faible efficacité énergétique des bâtiments ?
- Co-fondateur d'OpenAI interviewé par Huang Renxun : les capacités de raisonnement de GPT-4 n'ont pas encore atteint les attentes
- Bing de Microsoft surpasse Google en termes de trafic de recherche grâce à la technologie OpenAI