
Maison >Périphériques technologiques >IA >Le développement de l'IA ouvrira-t-il la voie à l'unification dans 70 ans ? Ma Yi, Cao Ying et la dernière revue de l'IA de Shen Xiangyang : exploration des principes de base et du « modèle standard » de génération de renseignement
Le développement de l'IA ouvrira-t-il la voie à l'unification dans 70 ans ? Ma Yi, Cao Ying et la dernière revue de l'IA de Shen Xiangyang : exploration des principes de base et du « modèle standard » de génération de renseignement

- 王林avant
- 2023-04-18 12:52:031119parcourir
L'intelligence artificielle se développe depuis soixante-dix ans. Bien que les indicateurs techniques aient été continuellement actualisés, il n'y a toujours pas de réponse sur ce qu'est exactement « l'intelligence » et comment elle est apparue et développée.
Récemment, le professeur Ma Yi s'est associé à l'informaticien Dr Shen Xiangyang et au professeur Cao Ying, neuroscientifique, pour publier une revue de recherche sur l'émergence et le développement de l'intelligence, dans l'espoir d'unifier la recherche sur l'intelligence en théorie et d'améliorer la compréhension de modèles d’intelligence artificielle. compréhension et interprétabilité.

Lien papier : http://arxiv.org/abs/2207.04630
L'article introduit deux principes de base : la parcimonie et l'auto-cohérence.
L'auteur estime que c'est là la pierre angulaire de l'essor de l'intelligence, artificielle ou naturelle. Bien qu’il existe de nombreuses discussions et élaborations sur chacun de ces deux principes dans la littérature classique, cet article réinterprète ces deux principes de manière totalement mesurable et calculable.
Sur la base de ces deux premiers principes, les auteurs dérivent un cadre informatique efficace : la transcription compressée en boucle fermée, qui unifie et explique l'évolution des réseaux profonds modernes et de nombreuses pratiques d'intelligence artificielle.
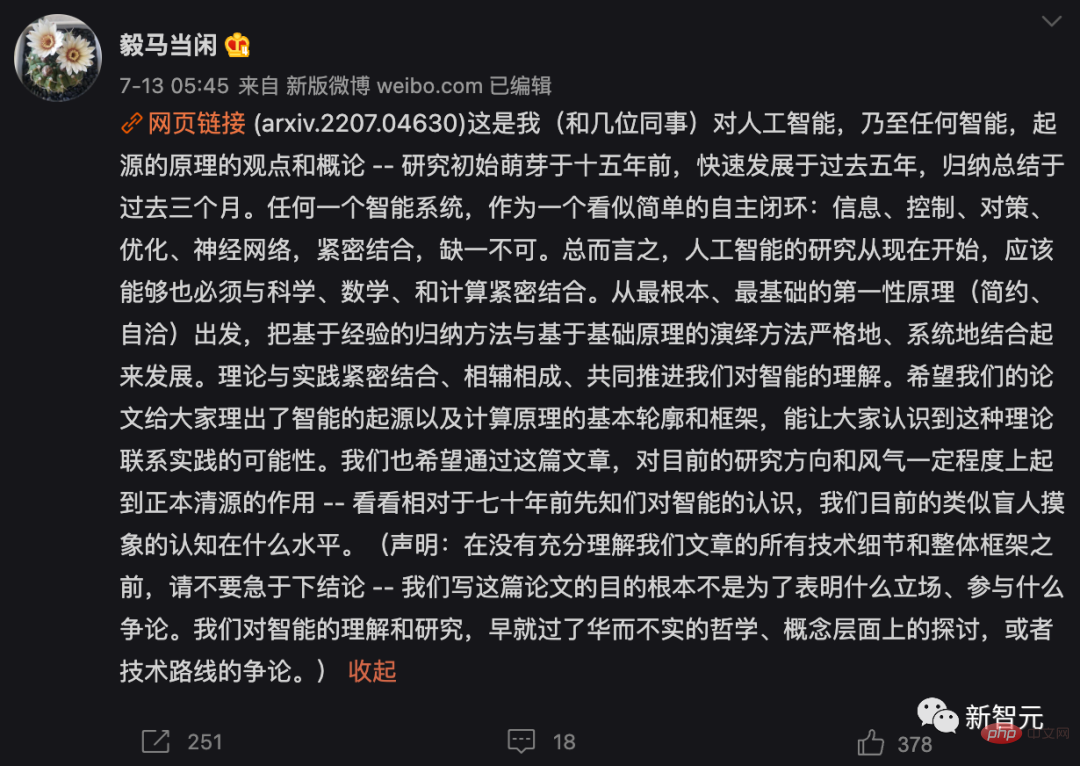
Deux principes de base : simplicité et auto-cohérence
Avec la bénédiction du deep learning, les progrès réalisés en intelligence artificielle au cours de la dernière décennie reposent principalement sur la formation de modèles de boîtes noires homogènes, à l'aide de bruts Méthodes d'ingénierie pour la formation de réseaux de neurones à grande échelle.
Bien que les performances aient été améliorées et qu'il ne soit pas nécessaire de concevoir manuellement les fonctionnalités, la représentation des fonctionnalités apprise à l'intérieur du réseau neuronal est ininterprétable et les grands modèles posent d'autres problèmes, tels que le coût croissant de la collecte et du calcul des données. les représentations apprises manquent de richesse, de stabilité (effondrement des modes), d'adaptabilité (sujets à des oublis catastrophiques), manque de robustesse à la déformation ou aux attaques adverses, etc.
L'auteur estime que l'une des raisons fondamentales de ces problèmes dans la pratique actuelle des réseaux profonds et de l'intelligence artificielle est le manque de compréhension systématique et complète des fonctions et des principes d'organisation des systèmes intelligents.
Par exemple, la formation d'un modèle discriminant pour la classification et d'un modèle génératif pour l'échantillonnage ou la relecture sont fondamentalement distinctes en pratique. Les modèles formés de cette manière sont généralement appelés systèmes en boucle ouverte et nécessitent une formation de bout en bout par supervision ou auto-supervision.
Dans la théorie du contrôle, de tels systèmes en boucle ouverte ne peuvent pas corriger automatiquement les erreurs de prédiction et ne sont pas adaptables aux changements de l'environnement ; c'est précisément à cause de ce problème que dans les systèmes contrôlés, nous utilisons largement le « feedback en boucle fermée » " pour permettre au système de corriger les erreurs de manière autonome.
Des expériences similaires s'appliquent également à l'apprentissage : une fois que les modèles discriminatifs et génératifs sont combinés pour former un système complet en boucle fermée, l'apprentissage peut devenir autonome (sans supervision externe), plus efficace, plus stable et plus adaptable.
Afin de comprendre les composants fonctionnels qui peuvent être nécessaires dans un système intelligent, tels que les discriminateurs ou les générateurs, nous devons comprendre l'intelligence d'un point de vue plus « fondé sur des principes » et « unifié ».
L'article propose deux principes de base : Parcimonie et Auto-cohérence, qui répondent respectivement à deux questions fondamentales sur l'apprentissage.
- Que retenir : Que retenir des données et comment mesurer la qualité de l'apprentissage ?
- Comment apprendre : Comment atteindre un tel objectif d'apprentissage grâce à un cadre informatique efficient et efficace ?
Concernant la première question de "quoi apprendre", le principe de simplicité veut que :
L'objectif d'apprentissage d'un système intelligent est de trouver des structures de basse dimension à partir des données d'observation du monde extérieur, et utilisez le plus compact et le plus sommatif. Réorganisez-les et représentez-les de manière structurée.
C'est le principe du « rasoir d'Occam » : n'ajouter d'entités que si nécessaire.
Sans ce principe, l'intelligence ne serait pas possible ! Si les données d’observation du monde extérieur n’ont pas de structure de faible dimension, il n’y aura rien qui vaille la peine d’être appris ou mémorisé, et une bonne généralisation ou prédiction ne sera pas possible.
Et les systèmes intelligents doivent économiser autant que possible les ressources, comme l'énergie, l'espace, le temps et la matière. Dans certains cas, ce principe est également appelé « principe de compression ». Cependant, la parcimonie de l’intelligence n’est pas d’obtenir la meilleure compression, mais d’obtenir l’expression la plus compacte et la plus structurée des données d’observation grâce à des moyens informatiques efficaces.
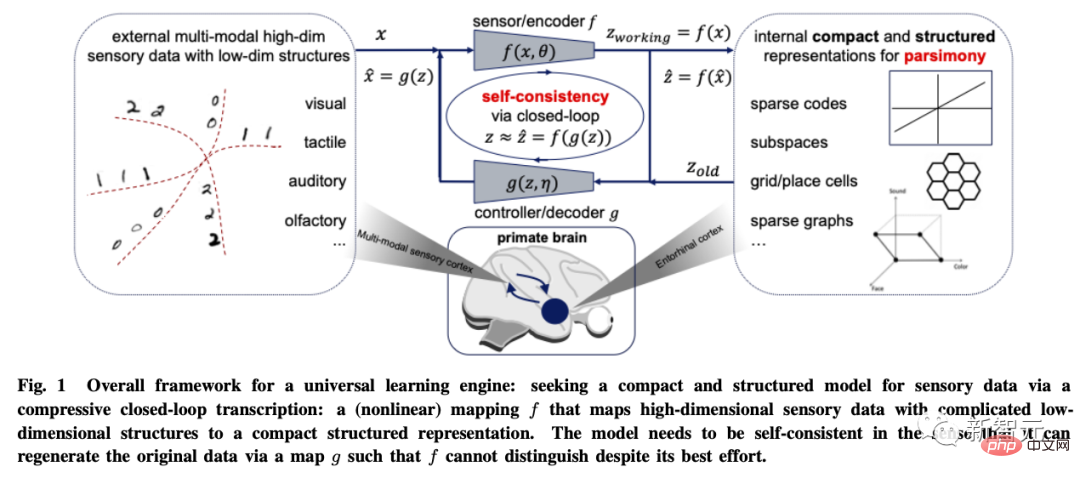
Alors comment mesurer la simplicité ?
Pour les modèles généraux de grande dimension, le coût de calcul de nombreuses « mesures » mathématiques ou statistiques couramment utilisées est exponentielle, voire indéfinie pour les distributions de données avec des structures de faible dimension. Par exemple, le maximum de vraisemblance, la divergence KL, les informations mutuelles. , distance Jensen-Shannon et Wasserstein, etc.
L'auteur estime que le but de l'apprentissage est en fait d'établir une cartographie (généralement non linéaire) pour obtenir une représentation de basse dimension à partir de l'entrée originale de haute dimension.
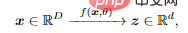
De cette façon, la distribution de la caractéristique z obtenue doit être plus compacte et structurée signifie un stockage plus économique signifie un accès et une utilisation plus efficaces : en particulier les structures linéaires, qui sont interpolées ou idéales ; pour extrapolation.
À cette fin, l'auteur introduit la représentation discriminante linéaire (LDR) pour atteindre trois sous-objectifs :
- Compression : mapper des données sensorielles de haute dimension x à une représentation z de basse dimension ; : Mappez chaque type d'objet distribué dans la sous-surface non linéaire à un sous-espace linéaire ;
- Sparsification : mappez différentes catégories à des sous-espaces mutuellement indépendants ou les moins pertinents.
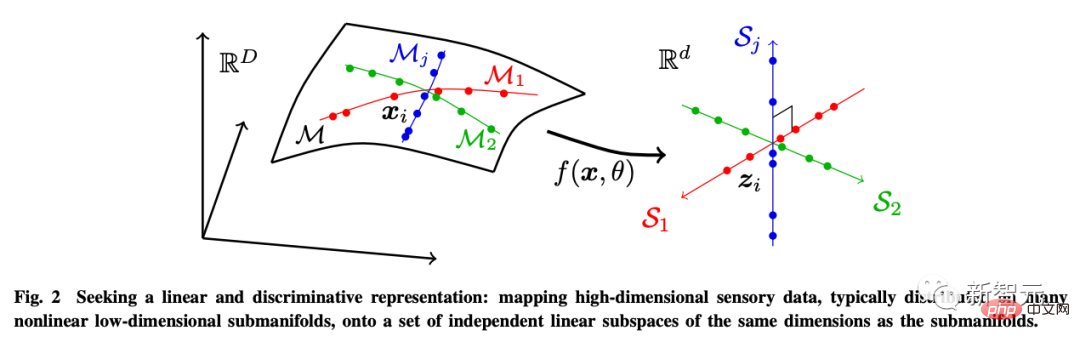
Ces objectifs peuvent être atteints grâce à une réduction maximale du taux de codage (réduction du taux) pour garantir que le modèle LDR appris a les performances parcimonieuses optimales.
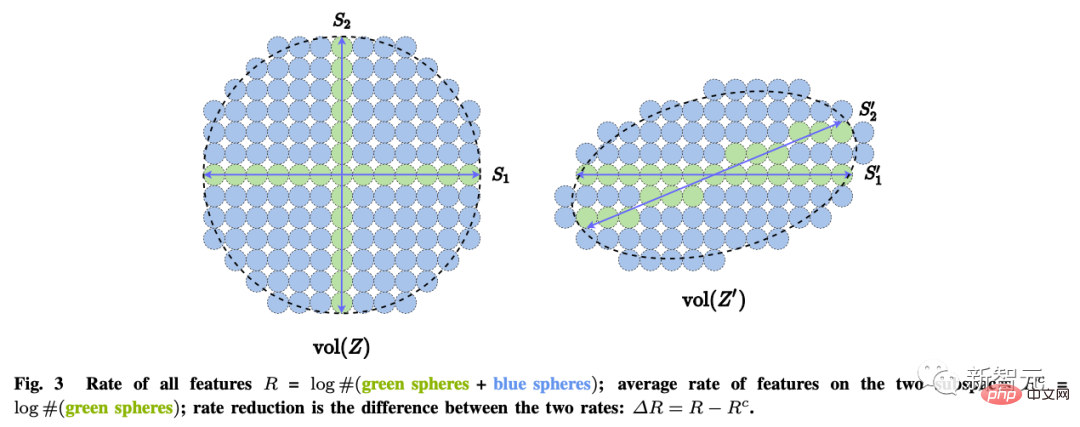
Un système intelligent autonome s'exprime en interne en minimisant les données observées et les données régénérées pour trouver le. modèle le plus cohérent pour l’observation du monde extérieur.
Le principe de parcimonie à lui seul ne garantit pas que le modèle appris capture toutes les informations importantes sur les données sur le monde extérieur. Par exemple, mapper chaque catégorie sur un vecteur chaud unidimensionnel en minimisant l’entropie croisée peut être considérée comme une forme de parcimonie.
Il peut apprendre un bon classificateur, mais les caractéristiques apprises peuvent également s'effondrer en un singleton, également connu sous le nom d'effondrement neuronal. Ces fonctionnalités apprises ne contiendront plus suffisamment d’informations pour régénérer les données d’origine.
Même si l'on considère le modèle LDR plus général, la maximisation de la différence de taux de codage à elle seule ne peut pas déterminer automatiquement les dimensions correctes de l'espace des fonctionnalités de l'environnement.
Si la dimensionnalité de l'espace des fonctionnalités est trop faible, le modèle appris ne correspondra pas aux données ; si elle est trop élevée, le modèle peut sur-correspondre.
Plus généralement, nous considérons l'apprentissage perceptuel comme distinct de l'apprentissage de tâches spécifiques. Le but de la perception est d’apprendre tout ce qui est prévisible sur ce qui est perçu.
Comme l'a dit Einstein : "Les choses doivent rester simples, mais pas trop simples."
Universal Learning Engine
Basé sur ces deux principes, l'article est modélisé avec des données d'images visuelles. À titre d'exemple, le cadre de transcription compressif en boucle fermée est dérivé.
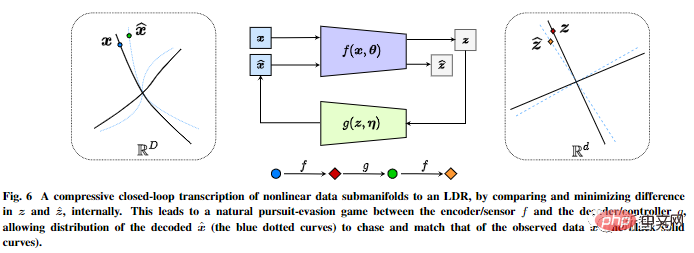
Il effectue une transcription compressée en boucle fermée de modèles de sous-flux de données non linéaires en interne pour obtenir un LDR en comparant et en minimisant les différences dans les représentations internes.
Le jeu de poursuite et de vol entre l'encodeur/capteur et le décodeur/contrôleur permet à la distribution des données générées par la représentation décodée de poursuivre et de correspondre à la distribution des données réelles observées.
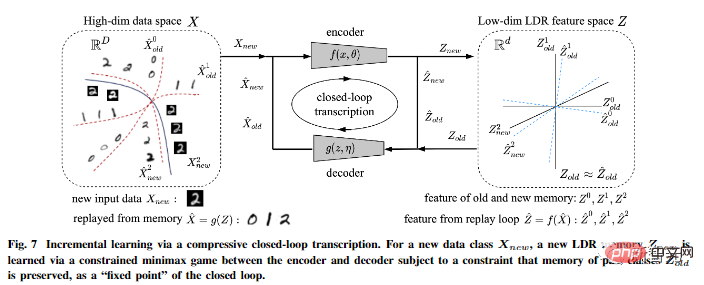
De plus, l'auteur a souligné que la transcription compressée en boucle fermée peut effectuer efficacement un apprentissage incrémentiel.
Un modèle LDR pour une nouvelle classe de données peut être appris grâce à un jeu contraint entre l'encodeur et le décodeur : la mémoire des classes apprises passées peut être naturellement conservée comme contraintes dans le jeu, c'est-à-dire comme un « point fixe » " pour la transcription en boucle fermée.
L'article avance également des idées plus spéculatives sur l'universalité de ce cadre, l'étend à la vision tridimensionnelle et à l'apprentissage par renforcement, et prédit son impact sur les neurosciences, les mathématiques et l'intelligence avancée.
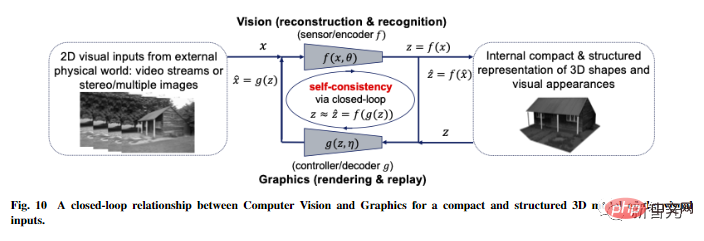
Grâce à ce cadre dérivé des premiers principes : les concepts de théorie du codage de l'information, de contrôle par rétroaction en boucle fermée, d'optimisation/réseaux profonds et de théorie des jeux sont tous organiquement intégrés dans un ensemble complet, une composante essentielle de l'autonomie. systèmes intelligents.

Il convient de mentionner que l'architecture compressée en boucle fermée est omniprésente chez toutes les créatures intelligentes dans la nature et à différentes échelles : du cerveau (informations sensorielles compressées) aux circuits spinaux (mouvements musculaires compressés), Jusqu'à l'ADN (informations fonctionnelles compressées des protéines) et ainsi de suite.
L'auteur estime donc que la transcription compressive en boucle fermée devrait être le « moteur d'apprentissage universel » derrière tous les comportements intelligents. Il permet aux systèmes d'intelligence naturelle ou artificielle de découvrir et d'affiner des structures de faible dimension à partir de données sensorielles apparemment complexes, en les convertissant en expressions internes concises et régulières pour faciliter un jugement et une prédiction corrects du monde extérieur dans le futur.
C'est la base de calcul et le mécanisme pour l'apparition et le développement de toute intelligence.
Référence : http://arxiv.org/abs/2207.04630
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Tendances technologiques à surveiller en 2023
- Comment l'intelligence artificielle apporte un nouveau travail quotidien aux équipes des centres de données
- L'intelligence artificielle ou l'automatisation peuvent-elles résoudre le problème de la faible efficacité énergétique des bâtiments ?
- Co-fondateur d'OpenAI interviewé par Huang Renxun : les capacités de raisonnement de GPT-4 n'ont pas encore atteint les attentes
- Bing de Microsoft surpasse Google en termes de trafic de recherche grâce à la technologie OpenAI