
Maison >Périphériques technologiques >IA >Stanford, Meta AI Research : Sur la route de l'AGI, l'élagage des données est plus important que nous le pensons
Stanford, Meta AI Research : Sur la route de l'AGI, l'élagage des données est plus important que nous le pensons

- PHPzavant
- 2023-04-17 19:04:031242parcourir
Dans de nombreux domaines de l'apprentissage automatique, notamment la vision, le langage et la parole, la loi de mise à l'échelle neuronale stipule que l'erreur de test diminue généralement avec les données d'entraînement, la taille du modèle ou le nombre de calculs. Cette amélioration proportionnelle a permis au deep learning d’obtenir des gains de performances substantiels. Cependant, ces améliorations obtenues grâce à la seule mise à l’échelle ont un coût considérable en termes de calcul et d’énergie.
Cette échelle proportionnelle n’est pas tenable. Par exemple, la quantité de données, de calculs ou d'énergie nécessaire pour réduire l'erreur de 3 % à 2 % augmente de façon exponentielle. Certaines recherches antérieures ont montré que la réduction de la perte d'entropie croisée de 3,4 à 2,8 dans la modélisation du langage avec de grands Transformers nécessite 10 fois plus de données de formation. De plus, pour les grands transformateurs visuels, 2 milliards de points de données pré-entraînés supplémentaires (à partir de 1 milliard) n'ont entraîné qu'un gain de précision de quelques points de pourcentage sur ImageNet.
Tous ces résultats mettent en lumière la nature des données dans le deep learning, tout en montrant que la pratique consistant à collecter d’énormes ensembles de données peut s’avérer inefficace. La discussion ici est de savoir si nous pouvons faire mieux. Par exemple, pouvons-nous parvenir à une mise à l’échelle exponentielle avec une bonne stratégie de sélection des échantillons d’apprentissage ?
Dans un article récent, des chercheurs ont découvert que l'ajout de seulement quelques échantillons d'entraînement soigneusement sélectionnés peut réduire l'erreur de 3 % à 2 % sans avoir à collecter 10 fois plus d'échantillons aléatoires. En bref, « La vente n’est pas tout ce dont vous avez besoin ».

Lien papier : https://arxiv.org/pdf/2206.14486.pdf
En général, les contributions de cette recherche sont :
1 En utilisant la mécanique statistique, une nouvelle méthode d'élagage des données a été développée selon. Selon la théorie de l'analyse de branche, dans l'environnement d'apprentissage du perceptron enseignant-élève, les échantillons sont élagués en fonction de leurs marges d'enseignant, et les grandes (petites) marges correspondent chacune à des échantillons simples (difficiles). La théorie est quantitativement en accord avec les expériences numériques et révèle deux prédictions surprenantes :
a La stratégie d'élagage optimale change avec la quantité de données initiales ; si les données initiales sont abondantes (rares), seules les plus difficiles doivent être retenues (faciles).
b. Si un score d'élagage Pareto-optimal croissant est choisi en fonction de la taille initiale de l'ensemble de données, alors une mise à l'échelle exponentielle est possible pour la taille de l'ensemble de données élagué.

2. La recherche montre que ces deux prédictions se vérifient dans la pratique dans des contextes plus généraux. Ils valident les caractéristiques de mise à l'échelle exponentielle des erreurs par rapport à la taille de l'ensemble de données élagué pour les ResNets formés à partir de zéro sur SVHN, CIFAR-10 et ImageNet, et pour un transformateur visuel affiné sur CIFAR-10.
3. Nous avons mené une étude de référence à grande échelle sur 10 métriques d'élagage de données différentes sur ImageNet et avons constaté que la plupart des métriques fonctionnaient mal, à l'exception des plus gourmandes en calcul.
4. Une nouvelle métrique d'élagage non supervisée à faible coût est développée à l'aide d'un apprentissage auto-supervisé qui, contrairement aux métriques précédentes, ne nécessite pas d'étiquettes. Nous démontrons que cette mesure non supervisée est comparable aux meilleures mesures d’élagage supervisé, qui nécessitent des étiquettes et davantage de calculs. Ce résultat révèle la possibilité d'utiliser un modèle de base pré-entraîné pour élaguer de nouveaux ensembles de données.
Est-ce que l'échelle est tout ce dont vous avez besoin ?
La théorie de l'élagage des données par perceptron du chercheur propose trois prédictions surprenantes, qui peuvent être testées dans un environnement plus général, comme les réseaux de neurones profonds entraînés sur des benchmarks :
(1) Par rapport à l'élagage aléatoire des données, lorsque l'ensemble de données initial est relativement grand, il est avantageux de ne conserver que les échantillons les plus difficiles, mais lorsque l'ensemble de données initial est relativement petit, cela est nuisible
(2) À mesure que la taille de l'ensemble de données initial augmente, en conservant les échantillons les plus difficiles. Élagage des données avec un la fraction fixe f des échantillons devrait produire une mise à l'échelle en loi de puissance avec une exponentielle égale à un élagage aléatoire ;
(3) L'erreur de test optimisée sur la taille de l'ensemble de données initial et la fraction de données conservées peuvent être améliorées en mettant à l'échelle une valeur initiale plus grande. Plus un élagage agressif est effectué sur l'ensemble de données pour suivre une enveloppe inférieure Pareto-optimale, brisant la relation de fonction de mise à l'échelle de la loi de puissance entre l'erreur de test et la taille de l'ensemble de données élagué.
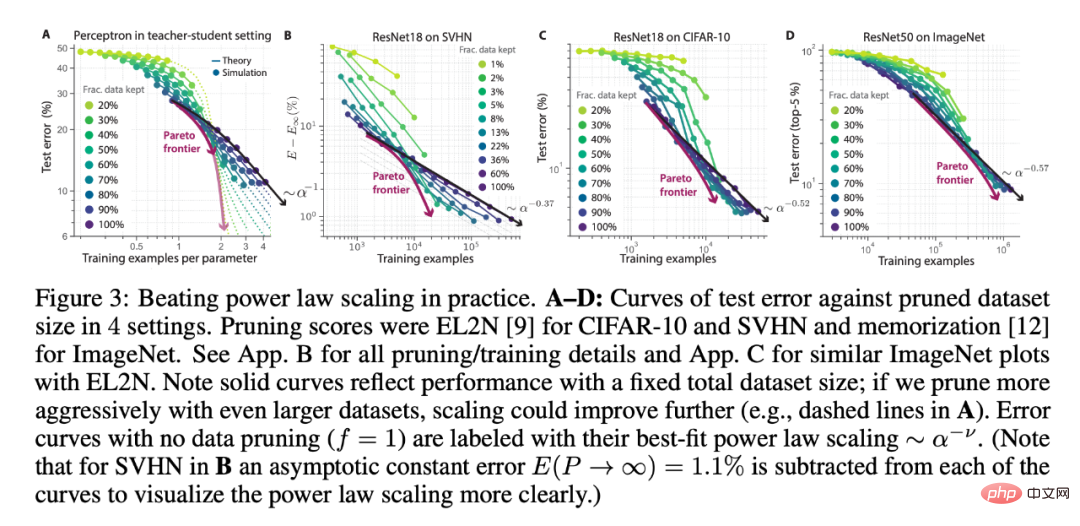
Les chercheurs ont utilisé différents nombres de tailles d'ensembles de données initiales et de fractions de données enregistrées lors de l'élagage des données (théorie de la figure 3A par rapport à l'expérience d'apprentissage en profondeur de la figure 3BCD), la formation sur SVHN, CIFAR-10 et ImageNet ResNets a vérifié la au-dessus de trois prédictions. Dans chaque contexte expérimental, on peut constater qu’un ensemble de données initial plus grand et un élagage plus agressif fonctionnent mieux que la mise à l’échelle de la loi de puissance. De plus, un ensemble de données initial plus important peut bénéficier d’une meilleure mise à l’échelle (Figure 3A).
De plus, les chercheurs ont découvert que l'élagage des données peut améliorer les performances de l'apprentissage par transfert. Ils ont d’abord analysé ViT pré-entraîné sur ImageNet21K, puis affiné sur différents sous-ensembles élagués de CIFAR-10. Il est intéressant de noter que le modèle pré-entraîné a permis un élagage plus agressif des données ; seulement 10 % des réglages fins du CIFAR-10 correspondaient ou dépassaient les performances obtenues par tous les réglages fins du CIFAR-10 (Figure 4A). De plus, la figure 4A fournit un exemple de rupture de mise à l’échelle de la loi de puissance dans un réglage précis.

Nous avons examiné l'efficacité de l'élagage des données pré-entraînées en pré-entraînant ResNet50 sur différents sous-ensembles élagués d'ImageNet1K (illustré dans la figure 3D), puis les avons peaufinées sur CIFAR-10. Comme le montre la figure 4B, le pré-entraînement sur un minimum de 50 % d'ImageNet est capable d'égaler ou de dépasser les performances CIFAR-10 obtenues par le pré-entraînement sur tous les ImageNet.
Par conséquent, l'élagage des données de pré-entraînement des tâches en amont peut toujours maintenir des performances élevées sur différentes tâches en aval. Dans l’ensemble, ces résultats montrent la promesse d’un élagage de l’apprentissage par transfert pendant les phases de pré-formation et de mise au point.
Analyse comparative des métriques d'élagage supervisé sur ImageNet
Les chercheurs ont remarqué que la plupart des expériences d'élagage des données ont été menées sur des ensembles de données à petite échelle (c'est-à-dire des variantes du MNIST et du CIFAR). Par conséquent, les quelques mesures d’élagage proposées pour ImageNet sont rarement comparées aux lignes de base conçues sur des ensembles de données plus petits.
Ainsi, on ne sait pas comment la plupart des méthodes d'élagage s'adaptent à ImageNet et quelle méthode est la meilleure. Pour étudier l'impact théorique de la qualité des mesures d'élagage sur les performances, nous avons décidé de combler ce manque de connaissances en effectuant une évaluation systématique de 8 mesures d'élagage supervisées différentes sur ImageNet.

Ils ont observé des différences de performances significatives entre les métriques : la figure 5BC montre les performances du test lorsqu'une partie des échantillons les plus difficiles sous chaque métrique a été conservée dans l'ensemble d'entraînement. De nombreuses métriques réussissent sur des ensembles de données plus petits, mais lorsque l'on choisit un sous-ensemble de formation nettement plus petit (comme 80 % d'Imagenet), seules quelques-unes obtiennent encore des performances comparables lorsqu'elles sont entraînées sur l'ensemble de données complet.
Néanmoins, la plupart des mesures surpassent encore l’élagage aléatoire (Figure 5C). Les chercheurs ont découvert que toutes les mesures d’élagage amplifient le déséquilibre des classes, entraînant une dégradation des performances. Pour résoudre ce problème, les auteurs ont utilisé un simple taux d’équilibre des classes de 50 % dans toutes les expériences ImageNet.
Élagage de données auto-supervisé via des métriques prototypes
Comme le montre la figure 5, de nombreuses métriques d'élagage de données ne s'adaptent pas bien à ImageNet, et certaines d'entre elles nécessitent en effet beaucoup de calculs. De plus, toutes ces métriques nécessitent des annotations, ce qui limite leurs capacités d'élagage des données pour former des modèles de base à grande échelle sur des ensembles de données massifs non étiquetés. Par conséquent, nous avons clairement besoin de mesures d’élagage simples, évolutives et auto-supervisées.

Pour évaluer si les clusters découverts par la métrique sont cohérents avec les classes ImageNet, nous avons comparé leur chevauchement dans la figure 6A. Les performances des mesures auto-supervisées et supervisées sont similaires lorsque l’on conserve plus de 70 % des données, ce qui montre la promesse d’un élagage auto-supervisé.
Pour plus de détails sur la recherche, veuillez vous référer à l'article original.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Tendances technologiques à surveiller en 2023
- Comment l'intelligence artificielle apporte un nouveau travail quotidien aux équipes des centres de données
- L'intelligence artificielle ou l'automatisation peuvent-elles résoudre le problème de la faible efficacité énergétique des bâtiments ?
- Co-fondateur d'OpenAI interviewé par Huang Renxun : les capacités de raisonnement de GPT-4 n'ont pas encore atteint les attentes
- Bing de Microsoft surpasse Google en termes de trafic de recherche grâce à la technologie OpenAI