
Maison >Périphériques technologiques >IA >Tâches courantes ! Tsinghua propose le réseau fédérateur Flowformer pour atteindre une complexité linéaire ICML2022
Tâches courantes ! Tsinghua propose le réseau fédérateur Flowformer pour atteindre une complexité linéaire ICML2022

- 王林avant
- 2023-04-16 19:25:011546parcourir
L'universalité des tâches est l'un des objectifs fondamentaux de la recherche sur les modèles fondamentaux, et c'est également le seul moyen pour la recherche sur l'apprentissage profond de conduire à une intelligence avancée. Ces dernières années, grâce aux capacités de modélisation de clés universelles du mécanisme d'attention, Transformer a obtenu de bons résultats dans de nombreux domaines et a progressivement montré une tendance à l'architecture universelle. Cependant, à mesure que la longueur de la séquence augmente, le calcul du mécanisme d’attention standard présente une complexité quadratique, ce qui entrave sérieusement son application dans la modélisation de séquences longues et les grands modèles.
À cette fin, une équipe de l'École de logiciel de l'Université Tsinghua a exploré en profondeur cette question clé et a proposé un réseau fédérateur à complexité linéaire universelle, Flowformer, qui réduit sa complexité au transformateur standard tout en conservant la polyvalence linéaire. le document a été accepté par l'ICML 2022.

Liste des auteurs: Wu Haixu, Wu Jialong, Xu Jiehui, Wang Jianmin, Long Mingsheng
link: https://arxiv.org/pdf/2202.06258.pdf
Code : https://github.com/thuml/Flowformer
Par rapport au Transformer standard, le modèle Flowformer proposé dans cet article présente les caractéristiques suivantes :
- Complexité linéaire, et peut gérer des entrées de milliers de longueurs Séquence ;
- n'introduit pas de nouvelles préférences d'induction et maintient la capacité de modélisation universelle du mécanisme d'attention d'origine
- Tâche universelle, dans séquences longues, vision, naturel ; langage, séries chronologiques, apprentissage par renforcementobtient d'excellents résultats sur cinq tâches principales.
1. Analyse du problème
L'entrée du mécanisme d'attention standard contient trois parties : requêtes(), clés() et valeurs(), et sa méthode de calcul est la suivante : où est la matrice de poids d'attention et la valeur finale le résultat du calcul est obtenu à partir d'une fusion pondérée, la complexité informatique du processus ci-dessus est. Il est à noter qu'il existe de nombreuses études sur le problème de la multiplication continue de matrices multinomiales dans les algorithmes classiques. En particulier, pour le mécanisme d'attention, nous pouvons utiliser la loi associative de multiplication matricielle pour réaliser une optimisation, par exemple, la complexité quadratique originale peut être réduite à linéaire. Mais la fonction dans le mécanisme d’attention rend impossible l’application directe de la loi associative. Par conséquent, la manière de supprimer des fonctions dans le mécanisme d’attention est la clé pour atteindre une complexité linéaire. Cependant, de nombreux travaux récents ont démontré que les fonctions jouent un rôle clé pour éviter un apprentissage attentionnel trivial. En résumé, nous attendons avec impatience une solution de conception de modèle qui atteint les objectifs suivants : (1) supprimer des fonctions ; (2) éviter une attention triviale (3) maintenir la polyvalence du modèle ;
2. Motivation
Visant l'objectif (1), dans des travaux antérieurs, la méthode du noyau est souvent utilisée pour remplacer la fonction, c'est-à-dire calculée par attention approximative (qui est une fonction non linéaire), mais en la supprimant directement suscitera une attention triviale. À cette fin, pour l'objectif (2), les travaux antérieurs ont dû introduire certaines préférences inductives, ce qui a limité la polyvalence du modèle et n'a donc pas atteint l'objectif (3), comme l'hypothèse de localité dans cosFormer.
Mécanisme de compétition dans Softmax
Afin d'atteindre les objectifs ci-dessus, nous partons des propriétés de base de l'analyse. Nous notons qu'il a été initialement proposé d'étendre l'opération maximale « le gagnant remporte tout » sous une forme différentiable. Par conséquent, Grâce à son mécanisme de « compétition » inhérent, il peut différencier les poids d'attention entre les jetons, évitant ainsi les problèmes d'attention ordinaires. Sur la base des considérations ci-dessus, nous essayons d'introduire le mécanisme de compétition dans la conception du mécanisme d'attention pour éviter les problèmes d'attention triviaux causés par la décomposition des méthodes du noyau.
Mécanisme de compétition dans le flux de réseau
Nous prêtons attention au modèle classique de flux de réseau (Flow network) dans la théorie des graphes, "Conservation" (Conservation) est un phénomène important, c'est-à-dire que l'afflux de chaque nœud est égal à la sortie. Inspiré par "Dans le cas de ressources fixes, la concurrence se produira inévitablement", dans cet article, nous essayons de réanalyser le flux d'informations dans le mécanisme d'attention classique du point de vue du flux de réseau, et d'introduire la concurrence dans le mécanisme d'attention grâce à des propriétés de conservationConception, pour éviter les problèmes d'attention banals.
3. Flowformer3.1 Mécanisme d'attention du point de vue du flux du réseauÀ l'intérieur du mécanisme d'attention : le flux d'informations peut être exprimé comme : depuis source (source, correspondant) en fonction de la capacité de flux apprise (capacité de débit, correspondant au poids d'attention) converge vers évier (évier, correspondant).
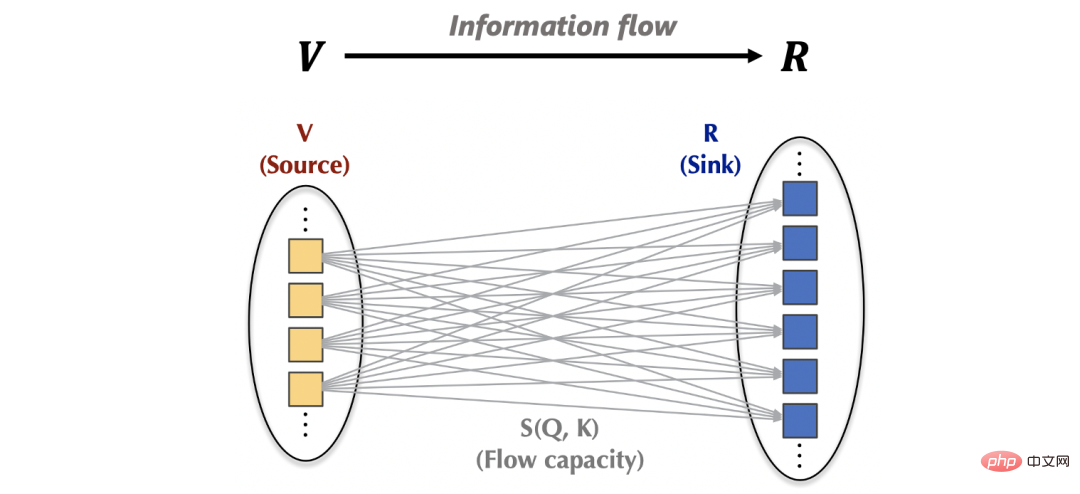
En dehors du mécanisme d'attention, les informations de la source (v) proviennent de la couche supérieure du réseau, et les informations du récepteur (R) seront également fournies à la couche de rétroaction située en dessous.
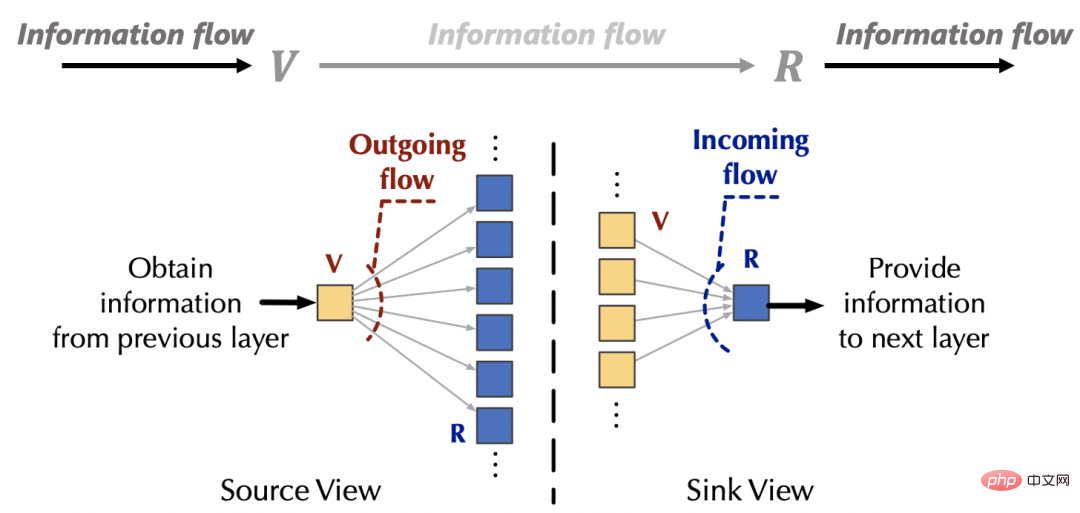
3.2 Flux-Attention
Sur la base des observations ci-dessus, nous pouvons réaliser des « ressources fixes » en contrôlant l'interaction entre le mécanisme d'attention et le réseau externe sous deux angles : l'entrée et la sortie. provoque une concurrence au sein des sources et des puits, respectivement, pour éviter une attention triviale. Sans perte de généralité, nous fixons la quantité d'informations d'interaction entre le mécanisme d'attention et le réseau externe à la valeur par défaut de 1.
(1) La conservation du flux entrant du puits (R) :
n'est pas difficile à obtenir, avant conservation, pour le ème évier, la quantité d'informations qui arrive est de : 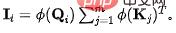 . Afin de fixer la quantité d'informations circulant dans chaque puits à l'unité 1, nous introduisons
. Afin de fixer la quantité d'informations circulant dans chaque puits à l'unité 1, nous introduisons 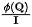 comme normalisation dans le calcul du flux d'informations (poids d'attention). Après normalisation, la quantité d'informations entrantes du ème puits est :
comme normalisation dans le calcul du flux d'informations (poids d'attention). Après normalisation, la quantité d'informations entrantes du ème puits est : 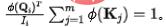
A ce moment, en raison de la conservation du flux entrant du puits, il existe une relation de compétition naturelle entre les différentes sources (V). chaque source à ce moment ( La quantité d'informations fournies par V) peut être obtenue : la quantité d'informations fournies par chaque source dans des conditions concurrentielles, qui représente également l'importance de chaque source.
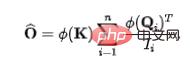
(2) Conservation du flux sortant de la source (V) : Similaire au processus susmentionné, avant conservation, pour la ème source, la quantité d'informations sortant est : 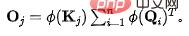 . Afin de fixer la quantité d'informations sortant de chaque source vers l'unité 1, nous présenterons le calcul du flux d'informations (poids d'attention) comme normalisation. Après normalisation, la quantité d'informations de sortie de la jème source est :
. Afin de fixer la quantité d'informations sortant de chaque source vers l'unité 1, nous présenterons le calcul du flux d'informations (poids d'attention) comme normalisation. Après normalisation, la quantité d'informations de sortie de la jème source est : 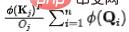 . À l'heure actuelle, en raison de la conservation des flux sortants de la source, il existe une relation de compétition naturelle entre les puits () Nous calculons la quantité d'informations reçues par chaque puits () à ce moment-là, et nous pouvons obtenir : Dans le cas. de compétition, le résultat final requis pour chaque résultat est la quantité d'informations reçues.
. À l'heure actuelle, en raison de la conservation des flux sortants de la source, il existe une relation de compétition naturelle entre les puits () Nous calculons la quantité d'informations reçues par chaque puits () à ce moment-là, et nous pouvons obtenir : Dans le cas. de compétition, le résultat final requis pour chaque résultat est la quantité d'informations reçues.
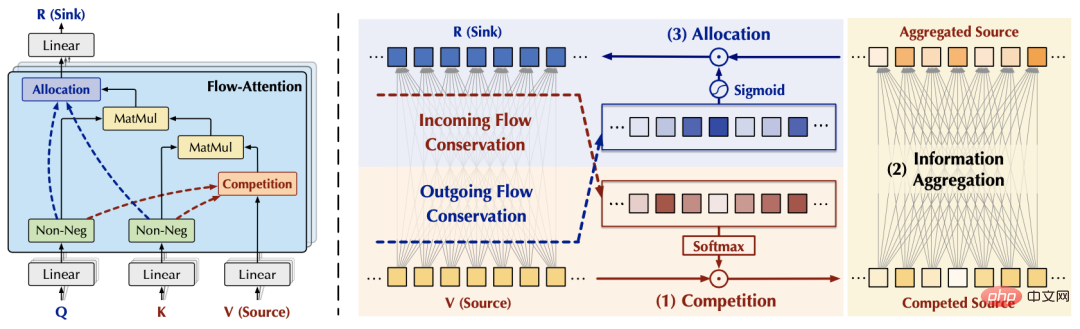
(3) Conception globale
Sur la base des résultats ci-dessus, nous concevons le mécanisme Flux-Attention suivant, qui comprend spécifiquement trois parties : Concurrence, Agrégation et Allocation : La concurrence sera en concurrence Lorsque le mécanisme est introduite, les informations importantes sont mises en évidence ; l'agrégation est basée sur la loi associative matricielle pour atteindre une complexité linéaire ; l'allocation contrôle la quantité d'informations transmises à la couche suivante en introduisant un mécanisme de concurrence. Toutes les opérations du processus ci-dessus ont une complexité linéaire. Dans le même temps, la conception de Flow-Attention repose uniquement sur le principe de conservation dans le flux réseau et réintègre le flux d'information. Elle n'introduit donc pas de nouvelles préférences inductives, garantissant la polyvalence du modèle. Flowformer est obtenu en remplaçant la complexité quadratique Attention dans le Transformer standard par Flow-Attention.
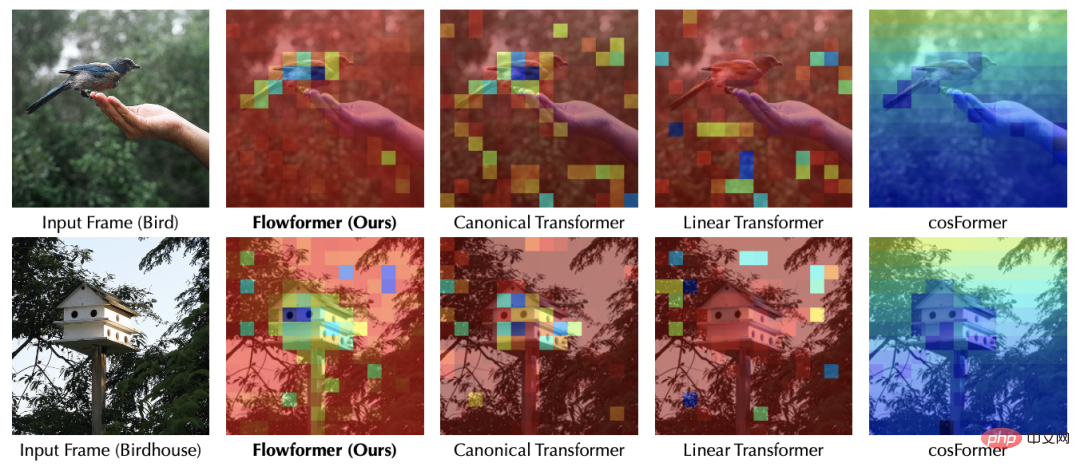
4. ExpériencesCet article a mené des expériences approfondies sur des ensembles de données standard :
- a couvert les cinq tâches principales de la séquence longue, de la vision, du langage naturel, des séries temporelles et de l'apprentissage par renforcement ; Il existe deux types de mécanismes d'attention : les tâches normales et autorégressives (causales).
- Couvre les situations de saisie de différentes longueurs de séquence (20-4000).
- Compare diverses méthodes de base telles que les modèles classiques dans divers domaines, les modèles profonds traditionnels, Transformer et ses variantes.
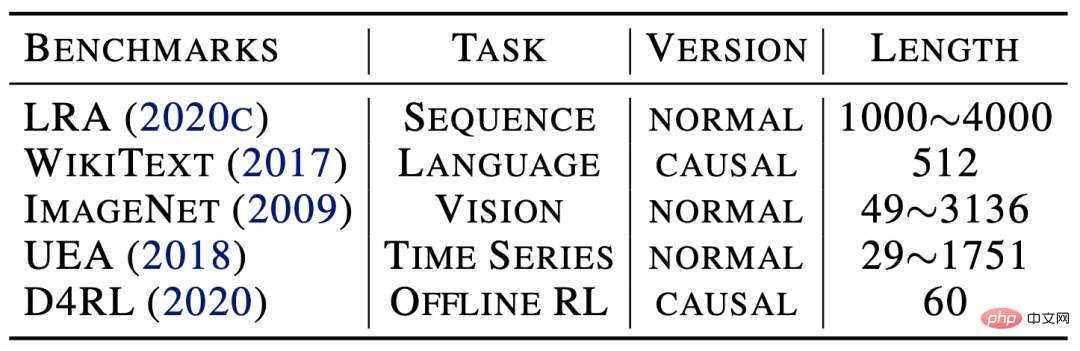
Afin d'expliquer davantage le principe de fonctionnement de Flowformer, nous avons mené une expérience visuelle sur l'attention dans la tâche de classification ImageNet (correspondant à Flow-Attention), à partir de laquelle nous pouvons retrouver : La visualisation ci-dessus montre que l'introduction de la concurrence dans la conception du mécanisme d'attention via Flow-Attention peut efficacement éviter une attention triviale. D’autres expériences de visualisation peuvent être trouvées dans l’article. Le Flowformer proposé dans cet article introduit le principe de conservation dans le flux de réseau dans la conception et introduit naturellement le mécanisme de compétition dans le calcul de l'attention, évitant ainsi le problème d'attention trivial et atteignant une complexité linéaire. en même temps, la polyvalence du transformateur standard est conservée. Flowformer a obtenu d'excellents résultats sur cinq tâches majeures : les séquences longues, la vision, le langage naturel, les séries temporelles et l'apprentissage par renforcement. En outre, le concept de conception « aucune préférence d'induction particulière » dans Flowformer est également une source d'inspiration pour la recherche sur l'infrastructure générale. Dans les travaux futurs, nous explorerons davantage le potentiel de Flowformer pour la pré-formation à grande échelle. 5. Analyse
6. Résumé
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Tendances technologiques à surveiller en 2023
- Comment l'intelligence artificielle apporte un nouveau travail quotidien aux équipes des centres de données
- L'intelligence artificielle ou l'automatisation peuvent-elles résoudre le problème de la faible efficacité énergétique des bâtiments ?
- Co-fondateur d'OpenAI interviewé par Huang Renxun : les capacités de raisonnement de GPT-4 n'ont pas encore atteint les attentes
- Bing de Microsoft surpasse Google en termes de trafic de recherche grâce à la technologie OpenAI