
Maison >Périphériques technologiques >IA >Les êtres humains ne disposent pas d'un corpus de qualité suffisant pour que l'IA puisse apprendre, et ils seront épuisés en 2026. Internautes : Un projet de génération de texte humain à grande échelle a été lancé !
Les êtres humains ne disposent pas d'un corpus de qualité suffisant pour que l'IA puisse apprendre, et ils seront épuisés en 2026. Internautes : Un projet de génération de texte humain à grande échelle a été lancé !

- PHPzavant
- 2023-04-16 17:49:031416parcourir
L’appétit de l’IA est trop grand et les données sur le corps humain ne suffisent plus.
Un nouvel article de l'équipe Epoch montre que l'IA utilisera tous les corpus de haute qualité en moins de 5 ans.

Il faut savoir qu'il s'agit d'un résultat prédit prenant en compte le taux de croissance des données du langage humain, même si tous les nouveaux articles et codes écrits par les humains au cours des dernières années sont alimentés par l'IA, ce ne sera pas suffisant.
Si ce développement se poursuit, les grands modèles de langage qui s'appuient sur des données de haute qualité pour améliorer leur niveau seront bientôt confrontés à un goulot d'étranglement.
Certains internautes sont déjà incapables de rester assis :
C'est tellement ridicule. Les humains peuvent s’entraîner efficacement sans tout lire sur Internet.
Nous avons besoin de meilleurs modèles, pas de plus de données.
Certains internautes ont ridiculisé le fait qu'il vaut mieux laisser l'IA manger ce qu'elle crache :
Vous pouvez transmettre à l'IA le texte généré par l'IA elle-même sous forme de données de mauvaise qualité.

Jetons un coup d’oeil : combien de données les humains laissent-ils ?
Que diriez-vous de « l’inventaire » des données texte et image ?
L'article prédit principalement les données de texte et d'image.
Le premier concerne les données textuelles.
La qualité des données varie généralement de bonne à mauvaise. Les auteurs ont divisé les données textuelles disponibles en parties de mauvaise qualité et de haute qualité en fonction des types de données utilisés par les grands modèles existants et d'autres données.
Le corpus de haute qualité fait référence aux ensembles de données de formation utilisés par de grands modèles de langage tels que Pile, PaLM et MassiveText, notamment Wikipédia, les actualités, les codes sur GitHub, les livres publiés, etc.
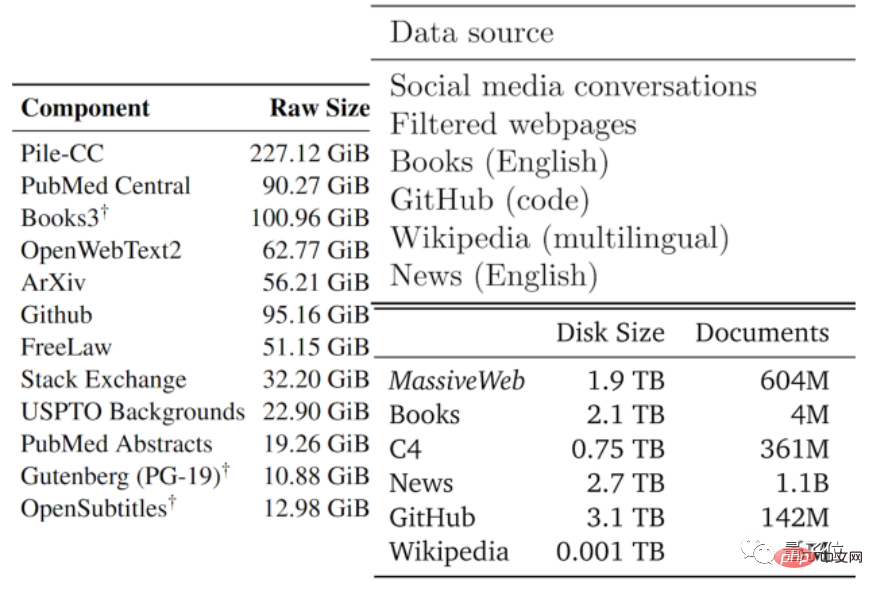
Le corpus de mauvaise qualité provient de tweets sur les réseaux sociaux tels que Reddit et de fan fiction non officielles (fanfic).
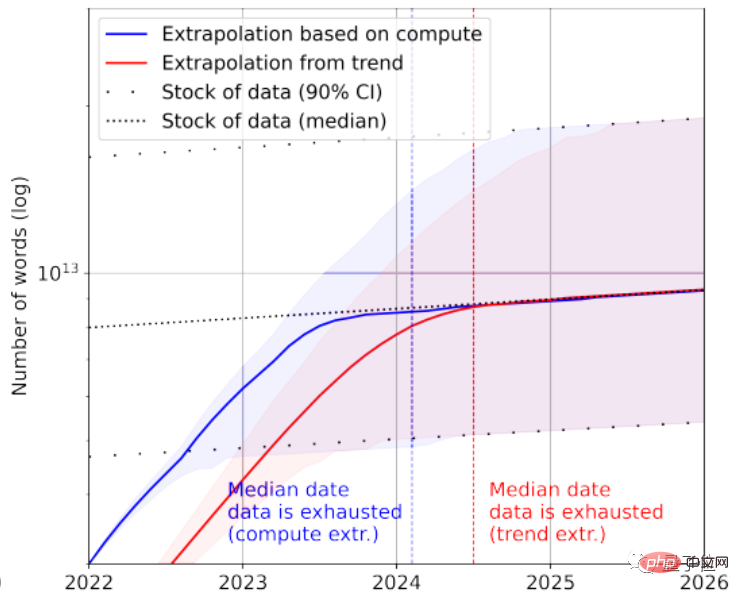
Selon les statistiques, il ne reste qu'environ 4,6 × 10 ^ 12 ~ 1,7 × 10 ^ 13 mots dans le stock de données linguistiques de haute qualité, ce qui est moins d'un ordre de grandeur plus grand que le plus grand ensemble de données textuelles actuel.
Combiné au taux de croissance, le document prédit que les données textuelles de haute qualité seront épuisées par l'IA entre 2023 et 2027, et que le nœud estimé se situe vers 2026.
Cela semble un peu rapide...
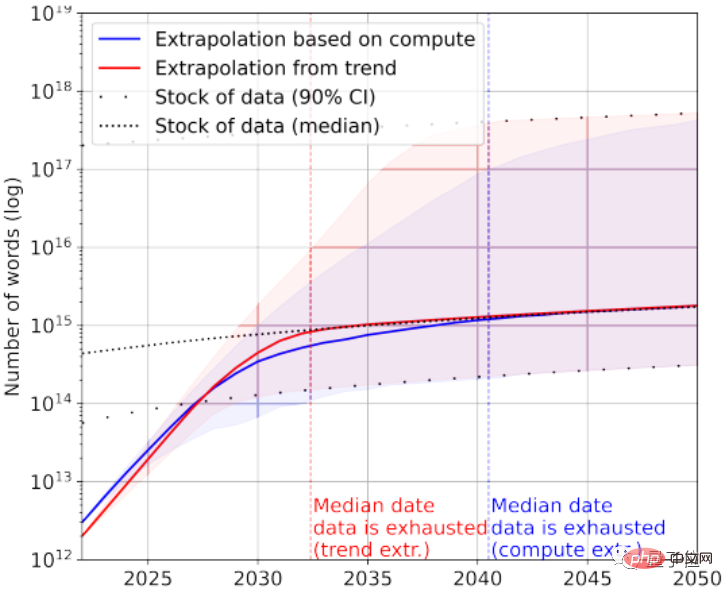
Bien sûr, des données textuelles de mauvaise qualité peuvent être ajoutées à la rescousse. Selon les statistiques, il reste actuellement 7 × 10 ^ 13 ~ 7 × 10 ^ 16 mots dans le stock global de données textuelles, soit 1,5 à 4,5 ordres de grandeur plus grands que le plus grand ensemble de données.
Si les exigences en matière de qualité des données ne sont pas élevées, alors l'IA utilisera toutes les données textuelles entre 2030 et 2050.
En regardant à nouveau les données d'image, l'article ici ne fait pas de différence entre la qualité de l'image.
Le plus grand ensemble de données d'images contient actuellement 3 × 10 ^ 9 images.
Selon les statistiques, le nombre total actuel d'images est d'environ 8,11 × 10 ^ 12 ~ 2,3 × 10 ^ 13, soit 3 à 4 ordres de grandeur plus grand que le plus grand ensemble de données d'image.
Le journal prédit que l’IA manquera de ces images entre 2030 et 2070.
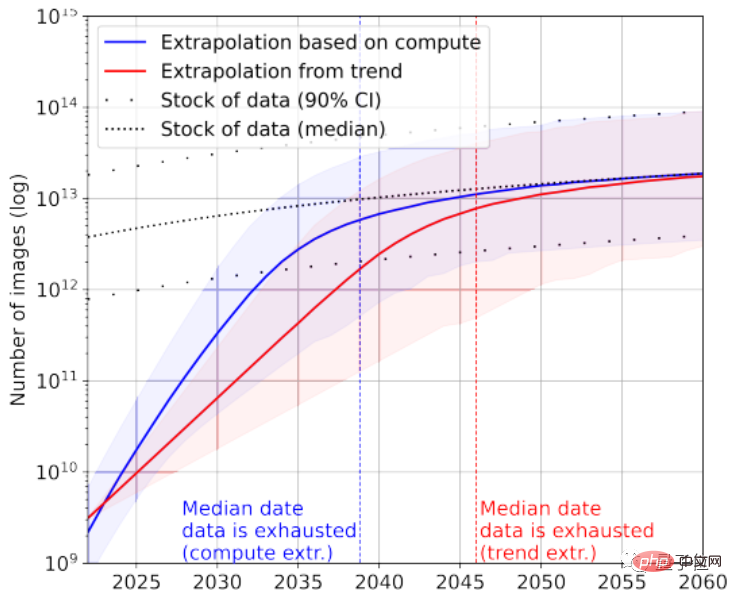
De toute évidence, les grands modèles de langage sont confrontés à une situation de « manque de données » plus grave que les modèles d'image.
Alors, comment est-on arrivé à cette conclusion ?
Calculez le nombre quotidien moyen de messages publiés par les internautes
Le document analyse l'efficacité de la génération de données d'image texte et la croissance de l'ensemble de données de formation sous deux angles.
Il convient de noter que les statistiques présentées dans l'article ne sont pas toutes des données étiquetées. Étant donné que l'apprentissage non supervisé est relativement populaire, des données non étiquetées sont également incluses.
Prenons l'exemple des données textuelles. La plupart des données seront générées à partir de plateformes sociales, de blogs et de forums.
Pour estimer la vitesse de génération de données textuelles, trois facteurs sont à prendre en compte, à savoir la population totale, le taux de pénétration d'Internet et la quantité moyenne de données générées par les internautes.
Par exemple, voici la tendance estimée de la croissance future de la population et des utilisateurs d'Internet basée sur les données historiques de la population et le nombre d'utilisateurs d'Internet :
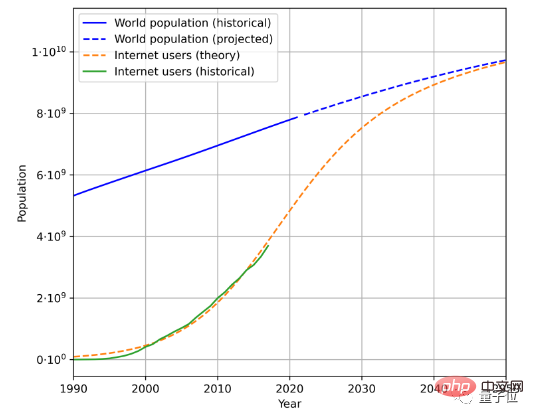
Combiné avec la quantité moyenne de données générées par les utilisateurs, le taux de génération de données peut être calculé. (En raison de changements géographiques et temporels complexes, le document simplifie la méthode de calcul de la quantité moyenne de données générées par les utilisateurs)
Selon cette méthode, on calcule que le taux de croissance des données linguistiques est d'environ 7%, mais cette croissance le taux diminuera progressivement au fil du temps.
On s'attend à ce que d'ici 2100, le taux de croissance de nos données linguistiques diminue à 1 %.
Une méthode similaire est utilisée pour analyser les données d'image. Le taux de croissance actuel est d'environ 8 %. Cependant, le taux de croissance des données d'image ralentira également jusqu'à environ 1 % d'ici 2100.
Le document estime que si le taux de croissance des données n'augmente pas de manière significative ou si de nouvelles sources de données émergent, qu'il s'agisse d'un grand modèle d'image ou de texte formé avec des données de haute qualité, cela pourrait inaugurer une période de goulot d'étranglement à un certain stade.
Certains internautes ont plaisanté à ce sujet, et quelque chose comme un scénario de science-fiction pourrait se produire dans le futur :
Afin de former l'IA, les humains ont lancé des projets de génération de texte à grande échelle, et tout le monde travaille dur pour écrire des choses pour l'IA.
Il appelle cela une sorte d'« éducation à l'IA » :
Nous envoyons chaque année entre 140 000 et 2,6 millions de mots de données textuelles à l'IA. Cela semble-t-il plus cool que d'utiliser des humains comme batteries ?
Qu'en pensez-vous ?
Adresse papier : https://arxiv.org/abs/2211.04325
Lien de référence : https://twitter.com/emollick/status/1605756428941246466
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Tendances technologiques à surveiller en 2023
- Comment l'intelligence artificielle apporte un nouveau travail quotidien aux équipes des centres de données
- L'intelligence artificielle ou l'automatisation peuvent-elles résoudre le problème de la faible efficacité énergétique des bâtiments ?
- Co-fondateur d'OpenAI interviewé par Huang Renxun : les capacités de raisonnement de GPT-4 n'ont pas encore atteint les attentes
- Bing de Microsoft surpasse Google en termes de trafic de recherche grâce à la technologie OpenAI