
Maison >Périphériques technologiques >IA >Un GPU exécute le modèle de volume ChatGPT et ControlNet est un autre artefact pour le dessin AI.
Un GPU exécute le modèle de volume ChatGPT et ControlNet est un autre artefact pour le dessin AI.

- 王林avant
- 2023-04-15 22:49:011818parcourir
Un catalogue
Modèles TransFormer : Une INTRODUACTION et un CATALOGUE
- Génération sophistiquée de grands modèles de langage avec un seul GPUMPORAL DMAIN avec des réseaux de neurones dynamiques sensibles à la dérive
- Modélisation physiquement précise à grande échelle de véritable pile à combustible à membrane échangeuse de protons avec apprentissage profond
- Une enquête complète sur les modèles de base pré-entraînés : une histoire de BERT à ChatGPT
- Ajout d'un contrôle conditionnel aux modèles de diffusion texte-image
- EVA3D : 3D compositionnelle Génération humaine à partir de collections d'images 2D
- Radiostation hebdomadaire ArXiv : PNL, CV, ML Plus d'articles sélectionnés (avec audio)
- Article 1 : Modèles de transformateur : une introduction et un catalogue
Author: Xavier Amatriin
- Paper Adresse: https://arxiv.org/pdf/2302.07730.pdf
- abstract: Since 2017 Depuis son introduction en 2016, le modèle de transformateur a démontré une force sans précédent dans d'autres domaines tels que le traitement du langage naturel et la vision par ordinateur, et a déclenché des percées technologiques telles que ChatGPT. Les gens ont également proposé diverses variantes basées sur le modèle original.
Alors que le monde universitaire et l'industrie continuent de proposer de nouveaux modèles basés sur le mécanisme d'attention Transformer, il nous est parfois difficile de résumer cette direction. Récemment, un article de synthèse de Xavier Amatriain, responsable de la stratégie produit IA chez LinkedIn, pourrait nous aider à résoudre ce problème.
Recommandation :
L'objectif de cet article est de fournir un catalogue et une classification relativement complets mais simples des modèles Transformer les plus populaires. Il présente également les aspects et innovations les plus importants des modèles Transformer. 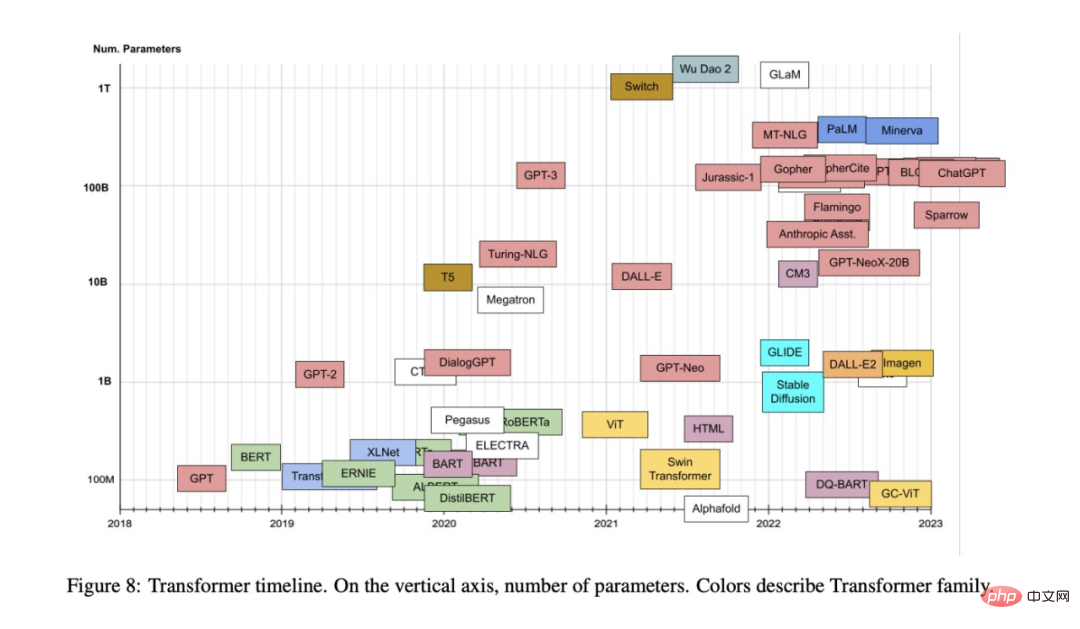
Article 2 : Inférence générative à haut niveau de modèles de langage volumineux avec un seul GPU
Auteur : Ying Sheng et al
- Adresse de l'article : https://github.com / FMInference/FlexGen/blob/main/docs/paper.pdf
- Résumé : Traditionnellement, les exigences élevées en matière de calcul et de mémoire de l'inférence de grands modèles de langage (LLM) ont nécessité l'utilisation de plusieurs IA haut de gamme. accélérateurs pour la formation . Cette étude explore comment réduire les exigences de l'inférence LLM à un GPU grand public et obtenir des performances pratiques. ,
Récemment, de nouvelles recherches de l'Université de Stanford, de l'UC Berkeley, de l'ETH Zurich, de Yandex, de l'École supérieure d'économie de Moscou, de Meta, de l'Université Carnegie Mellon et d'autres institutions ont proposé FlexGen, une méthode pour exécuter une génération limitée à haut débit. moteur pour LLM sur la mémoire GPU. La figure ci-dessous montre l'idée de conception de FlexGen, qui utilise la planification par blocs pour réutiliser les poids et chevaucher les E/S avec les calculs, comme le montre la figure (b) ci-dessous, tandis que d'autres systèmes de base utilisent une planification ligne par ligne inefficace, comme illustré dans la figure (a) ci-dessous.
Recommandation :Exécutez le modèle de volume ChatGPT, et n'avez désormais besoin que d'un seul GPU : voici la méthode pour accélérer cent fois.
Article 3 : Généralisation du domaine temporel avec des réseaux de neurones dynamiques sensibles à la dérive
Auteur : Guangji Bai et al
- Adresse de l'article : https://arxiv.org/pdf/ 2205.106 64 .pdf
- Résumé : Dans la tâche de généralisation de domaine (DG), lorsque la distribution du domaine change continuellement avec l'environnement, il est très important de capturer avec précision le changement et son impact sur le modèle . Mais c’est aussi un problème très difficile.
- Auteur : Ying Da Wang et al
- Adresse de l'article : https:/ / www.nature.com/articles/s41467-023-35973-8
- Auteur : Ce Zhou et al
- Adresse du papier : https://arxiv. org /pdf/2302.09419.pdf
- Auteur : Lvmin Zhang et al
- Adresse de l'article : https://arxiv.org/pdf / 2302.05543.pdf
- Auteur : Fangzhou Hong et al
- Adresse de l'article : https://arxiv.org/abs/ 2210.0 4888
À cette fin, l'équipe du professeur Zhao Liang de l'Université Emory a proposé un cadre de généralisation du domaine temporel DRAIN basé sur la théorie bayésienne, qui utilise des réseaux récursifs pour apprendre la dérive de la distribution du domaine dimensionnel temporel, et utilise des réseaux neuronaux dynamiques et une technologie de génération de graphes. La combinaison maximise la capacité d'expression du modèle et permet la généralisation et la prédiction du modèle dans des domaines inconnus à l'avenir.
Ce travail a été sélectionné dans l'ICLR 2023 Oral (Top 5% parmi les articles acceptés). Ce qui suit est un diagramme schématique du cadre global de DRAIN.
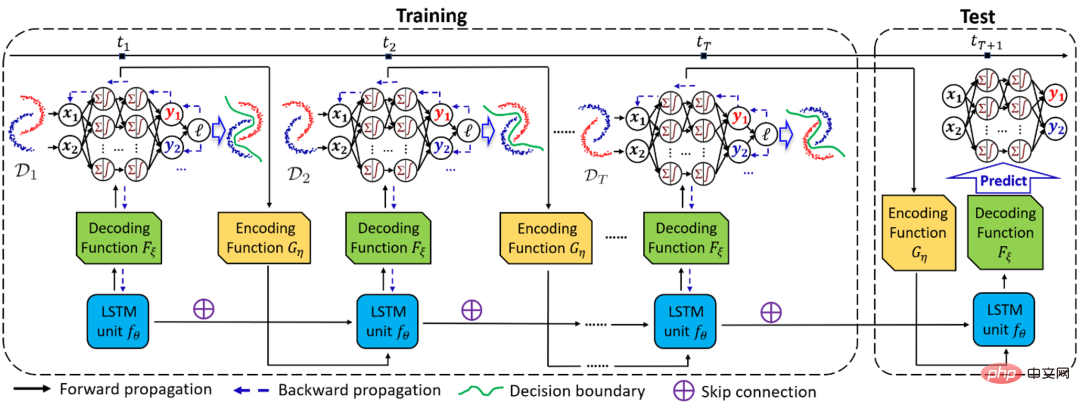
Recommandé : Bénédiction du réseau neuronal dynamique sensible à la dérive, le nouveau cadre de généralisation du domaine temporel dépasse de loin les méthodes de généralisation et d'adaptation du domaine.
Article 4 : Modélisation physiquement précise à grande échelle d'une véritable pile à combustible à membrane échangeuse de protons avec apprentissage en profondeur
Résumé : Afin de garantir l'approvisionnement en énergie et de lutter contre le changement climatique, l'attention des gens s'est déplacée des combustibles fossiles vers les énergies propres et renouvelables, et l'hydrogène a une densité énergétique élevée et des attributs énergétiques propres et à faibles émissions de carbone qui peuvent jouer un rôle important dans la transition énergétique. Les piles à combustible à hydrogène, en particulier les piles à combustible à membrane échangeuse de protons (PEMFC), sont la clé de cette révolution verte en raison de leur rendement de conversion énergétique élevé et de leur fonctionnement sans émission.
PEMFC convertit l'hydrogène en électricité par un processus électrochimique, et le seul sous-produit de la réaction est l'eau pure. Cependant, les PEMFC peuvent devenir inefficaces si l’eau ne peut pas s’écouler correctement de la cellule et « inonde » ensuite le système. Jusqu’à présent, il était difficile pour les ingénieurs de comprendre la manière précise dont l’eau s’écoule ou s’accumule à l’intérieur des piles à combustible en raison de leur petite taille et de leur complexité.
Récemment, une équipe de recherche de l'Université de Nouvelle-Galles du Sud à Sydney a développé un algorithme d'apprentissage profond (DualEDSR) pour améliorer la compréhension des conditions internes du PEMFC et peut générer des images haute résolution à partir de rayons X de basse résolution. Numérisations de tomodensitométrie. Images de modélisation de résolution. Le processus a été testé sur une seule pile à combustible à hydrogène, permettant de modéliser avec précision son intérieur et d’améliorer potentiellement son efficacité. La figure ci-dessous montre les domaines PEMFC générés dans cette étude.
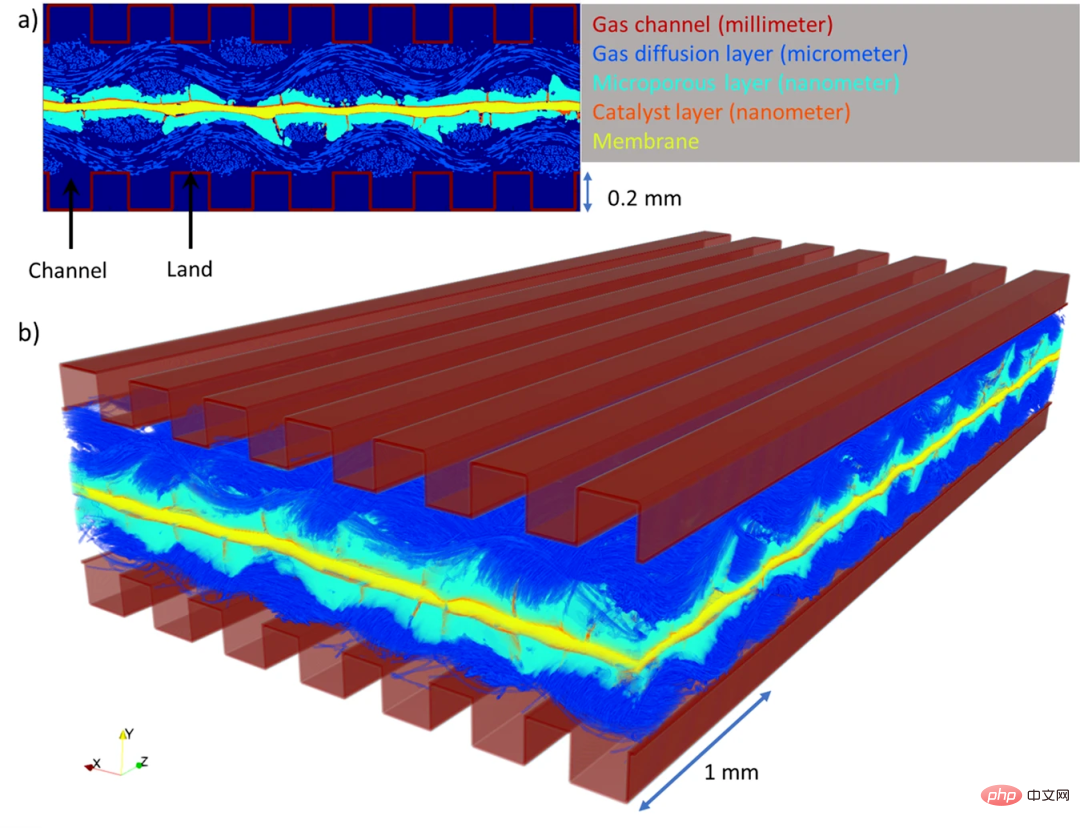
Recommandation : Le Deep Learning effectue une modélisation physique et précise à grande échelle de l'intérieur des piles à combustible pour aider à améliorer les performances de la batterie.
Papier 5 : Une enquête complète sur les modèles de base pré-entraînés : Une histoire de BERT à ChatGPT
Résumé : Cette revue de près de 100 pages passe en revue l'historique de l'évolution du modèle de base pré-entraîné, nous permettant de voir comment ChatGPT a réussi étape par étape.
Recommandation : De BERT à ChatGPT, une revue d'une centaine de pages passant au peigne fin l'historique de l'évolution des grands modèles pré-entraînés.
Article 6 : Ajout d'un contrôle conditionnel aux modèles de diffusion texte-image
Résumé : Cet article propose une architecture de réseau neuronal de bout en bout ControlNet, qui peut contrôler le modèle de diffusion (tel que Stable Diffusion) en ajoutant des conditions supplémentaires pour améliorer la génération de graphiques effet. Il peut générer des images en couleur à partir de dessins au trait, générer des images avec la même structure de profondeur et optimiser la génération manuelle à travers les points clés de la main.
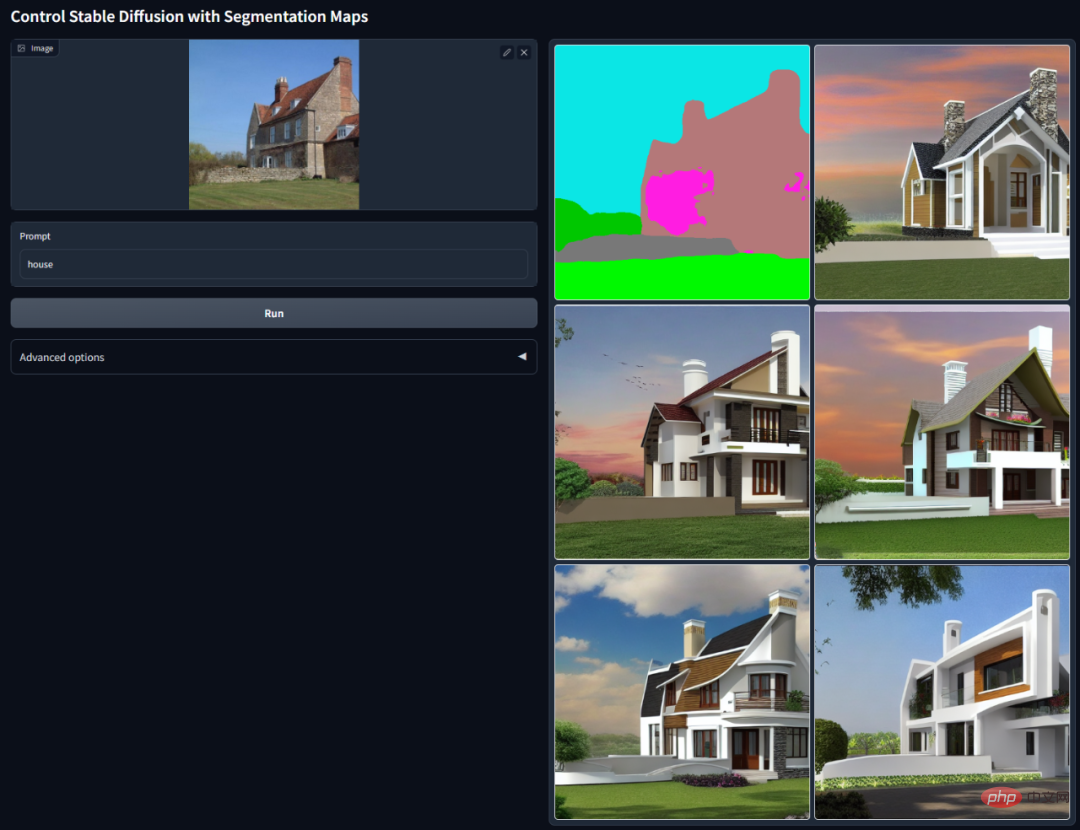
Recommandation : L'IA réduit la dimensionnalité pour vaincre les peintres humains, introduit ControlNet dans les graphiques vincentiens et réutilise entièrement les informations de profondeur et de bord.
Article 7 : EVA3D : Génération humaine compositionnelle en 3D à partir de collections d'images 2D
Résumé : Lors de l'ICLR 2023, l'équipe S-Lab du Centre de recherche commun SenseTime de l'Université technologique de Nanyang a proposé EVA3D, la première méthode d'apprentissage de la génération de corps humain tridimensionnel haute résolution à partir d'une collection de images en deux dimensions. Grâce au rendu différenciable fourni par NeRF, les modèles génératifs 3D récents ont obtenu des résultats époustouflants sur des objets stationnaires. Cependant, dans une catégorie plus complexe et déformable comme le corps humain, la génération 3D pose encore de grands défis.
Cet article propose une représentation NeRF combinée efficace du corps humain, permettant d'obtenir une génération de corps humain 3D haute résolution (512x256) sans utiliser de modèle de super-résolution. EVA3D a largement surpassé les solutions existantes sur quatre ensembles de données du corps humain à grande échelle, et le code est open source.

Recommandé : ICLR 2023 Spotlight | Image 2D brainstorming du corps humain 3D, vous pouvez mettre les vêtements avec désinvolture et vous pouvez également modifier les mouvements.
ArXiv Weekly Radiostation
Heart of Machine coopère avec ArXiv Weekly Radiostation initiée par Chu Hang, Luo Ruotian et Mei Hongyuan, et sélectionne des articles plus importants cette semaine sur la base de 7 articles, dont NLP, CV, ML 10 articles sélectionnés dans chaque domaine, et des introductions abstraites des articles sous forme audio sont fournies. Les détails sont les suivants :
7 Articles PNL
Les 10 articles PNL sélectionnés cette semaine sont :
1 . Invite active avec chaîne de pensée pour les grands modèles linguistiques (de Tong Zhang)
2. Les fonctionnalités prosodiques améliorent la segmentation et l'analyse des phrases auto-supervisées (d'Emmanuel Dupoux)
4. Exploration des médias sociaux pour la détection précoce de la dépression chez les patients COVID-19 (de Jie Yang)
5. Traduction automatique du voisin le plus proche fédéré (d'Enhong Chen)
6. Termes avec attention graphique. (de Michael Moortgat)
7. Un modèle de reconnaissance d'entités nommées continue basé sur l'étendue neuronale (de Qingcai Chen)
10 articles de CV
Cette semaine. Les 10 articles sélectionnés par CV sont :
1. MERF : Memory-Efficient Radiance Fields for Real-time View Synthesis in Unbounded Scenes (de Richard Szeliski, Andreas Geiger)
2. Modèles texte-image. (de Daniel Cohen-Or)
3. Enseigner CLIP à compter jusqu'à dix (de Michal Irani)
4. Simulation des pores du visage. (de Weisi Lin)
5. Détection des dommages en temps réel dans les cordes de levage de fibres à l'aide de réseaux neuronaux convolutifs (de Moncef Gabbouj)
6. Amélioration de l'image lumineuse (de Chen Change Loy)
7. Diffusion adaptée à la région pour une édition d'images basée sur le texte sans prise de vue. (de Changsheng Xu)
8. Réseau d'adaptateurs latéraux pour la segmentation sémantique à vocabulaire ouvert. (de Xiang Bai)
9. VoxFormer : transformateur de voxel clairsemé pour la réalisation de scènes sémantiques 3D basées sur une caméra. (de Sanja Fidler)
10. Prédiction vidéo centrée sur les objets via le découplage de la dynamique et des interactions des objets. (de Sven Behnke)
10 ML Papers
本周 10 篇 ML 精选论文是:
1. normflows : un package PyTorch pour normaliser les flux. (de Bernhard Schölkopf)
2. Apprentissage conceptuel pour un apprentissage par renforcement multi-agent interprétable. (de Katia Sycara)
3. Les enseignants aléatoires sont de bons enseignants. (de Thomas Hofmann)
4. Alignement des modèles texte-image à l'aide de la rétroaction humaine. (de Craig Boutilier, Pieter Abbeel)
5. Le changement est difficile : un examen plus approfondi du changement de sous-population. (de Dina Katabi)
6. AlpaServe : multiplexage statistique avec parallélisme de modèles pour le service d'apprentissage profond. (de Zhifeng Chen)
7. Optimisation de politiques diverses pour un espace d'action structuré. (de Hongyuan Zha)
8. La géométrie de la mixabilité. (de Robert C. Williamson)
9. Le Deep Learning apprend-il à faire abstraction ? Un cadre de sondage systématique. (de Nanning Zheng)
10. Minimisation séquentielle des risques contrefactuels. (de Julien Mairal)
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Tendances technologiques à surveiller en 2023
- Comment l'intelligence artificielle apporte un nouveau travail quotidien aux équipes des centres de données
- L'intelligence artificielle ou l'automatisation peuvent-elles résoudre le problème de la faible efficacité énergétique des bâtiments ?
- Co-fondateur d'OpenAI interviewé par Huang Renxun : les capacités de raisonnement de GPT-4 n'ont pas encore atteint les attentes
- Bing de Microsoft surpasse Google en termes de trafic de recherche grâce à la technologie OpenAI