
Maison >Périphériques technologiques >IA >L'IA a appris à jouer à 'Minecraft' à partir de zéro, DeepMind AI a fait une percée dans la généralisation
L'IA a appris à jouer à 'Minecraft' à partir de zéro, DeepMind AI a fait une percée dans la généralisation

- PHPzavant
- 2023-04-15 18:07:031717parcourir
L'intelligence générale doit résoudre des tâches dans plusieurs domaines. On pense que les algorithmes d’apprentissage par renforcement ont ce potentiel, mais il a été entravé par les ressources et les connaissances nécessaires pour les adapter à de nouvelles tâches. Dans une nouvelle étude de DeepMind, les chercheurs démontrent DreamerV3, un algorithme général et évolutif basé sur un modèle mondial qui surpasse les méthodes précédentes dans un large éventail de domaines avec des hyperparamètres fixes.
DreamerV3 se conforme à des domaines comprenant les actions continues et discrètes, les entrées visuelles et de faible dimension, les mondes 2D et 3D, les volumes de données variables, les fréquences de récompense et les niveaux de récompense. Il convient de mentionner que DreamerV3 est le premier algorithme à collecter des diamants dans Minecraft à partir de zéro, sans données humaines ni éducation active. Les chercheurs affirment qu’un tel algorithme général pourrait permettre des applications généralisées de l’apprentissage par renforcement et pourrait potentiellement être étendu à des problèmes de prise de décision difficiles.
Les diamants sont l'un des objets les plus populaires du jeu "Minecraft". Ils sont l'un des objets les plus rares du jeu et peuvent être utilisés pour fabriquer la plupart des outils, armes et armures les plus puissants du jeu. Comme les diamants ne se trouvent que dans les couches rocheuses les plus profondes, leur production est faible.
DreamerV3 est le premier algorithme permettant de collecter des diamants dans Minecraft sans avoir besoin de démonstrations humaines ou de création manuelle de cours. Cette vidéo montre le premier diamant collecté, qui s'est produit dans les 30 millions d'étapes d'environnement / 17 jours de jeu.
Si vous n'avez aucune idée de l'IA jouant à Minecraft, Jim Fan, scientifique en IA de NVIDIA, a déclaré que par rapport à AlphaGo jouant à Go, le nombre de tâches Minecraft est illimité, les changements d'environnement sont illimités et les connaissances contiennent également des informations cachées.
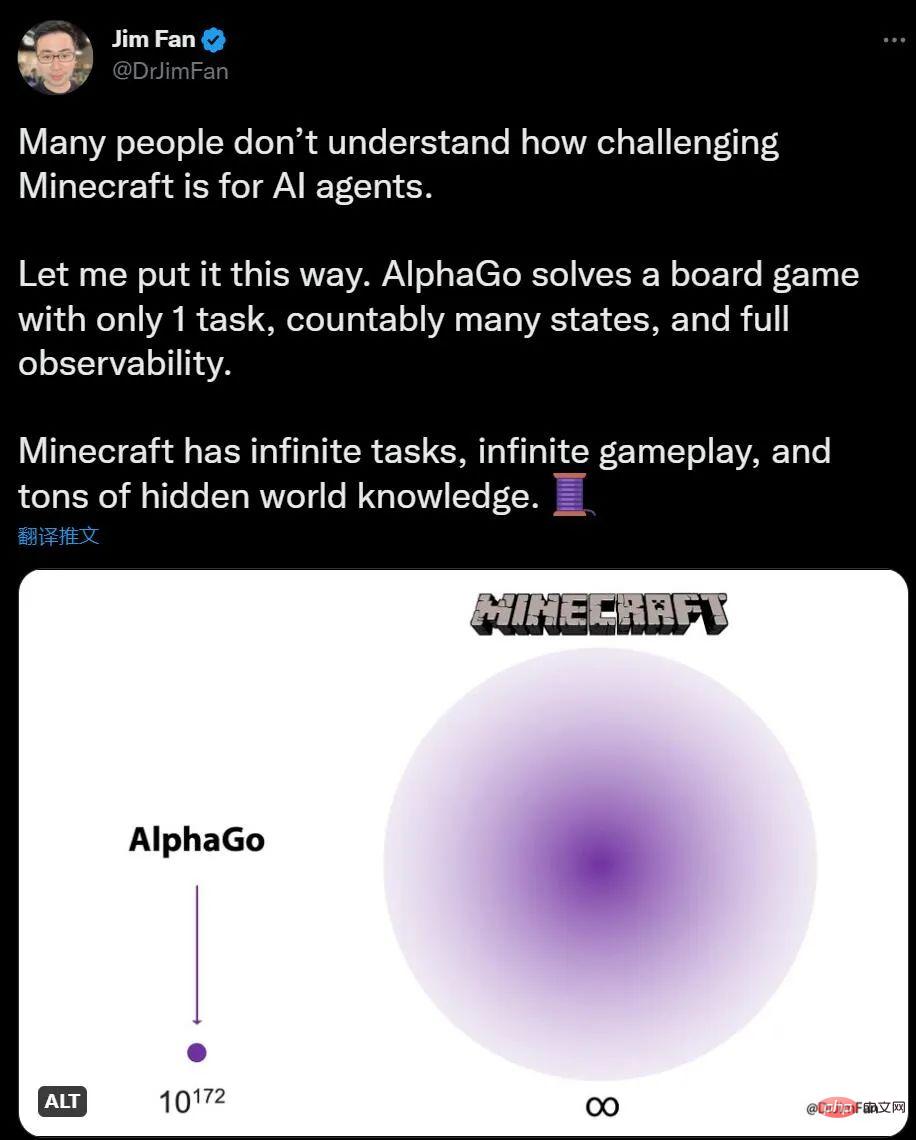
Pour les humains, explorer et construire dans Minecraft est amusant, tandis que Go semble un peu compliqué pour l'IA, la situation est tout le contraire. AlphaGo a vaincu le champion humain il y a 6 ans, mais il n'existe désormais aucun algorithme capable de rivaliser avec les maîtres humains de Minecraft.
Dès l'été 2019, la société de développement de Minecraft a proposé le "Diamond Challenge", offrant une récompense pour un algorithme d'IA capable de trouver des diamants dans le jeu jusqu'à NeurIPS 2019, parmi les plus de 660 candidatures soumises. , Aucune IA n’est à la hauteur.
Mais l'émergence de DreamerV3 a changé cette situation. Les diamants sont une tâche hautement combinée et à long terme qui nécessite une exploration et une planification complexes. Le nouvel algorithme peut collecter des diamants sans aucune aide de données artificielles. Il y a peut-être encore beaucoup à faire en termes d'efficacité, mais le fait que l'agent IA puisse désormais apprendre à collecter des diamants à partir de zéro est une étape importante .
Présentation de la méthode DreamerV3
Article "Maîtriser divers domaines à travers des modèles mondiaux" :

Lien article : https://arxiv.org/abs/2301.04104v1
L'algorithme DreamerV3 est propulsé par Il se compose de trois réseaux de neurones, à savoir le modèle mondial, le critique et l'acteur. Les trois réseaux de neurones sont formés simultanément sur la base de l'expérience de relecture sans partager de gradients. La figure 3 (a) ci-dessous montre l'apprentissage du modèle mondial et la figure (b) montre l'apprentissage de l'acteur critique.
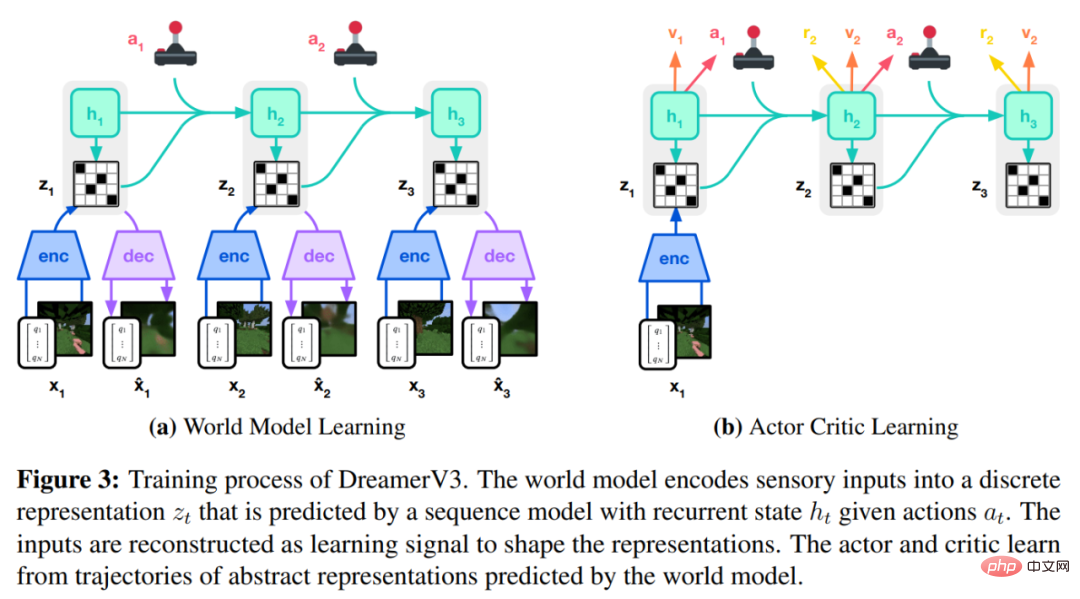
Pour réussir dans tous les domaines, ces composants doivent s'adapter à différentes amplitudes de signal et équilibrer de manière robuste les termes sur leurs cibles. Cela constitue un défi car l’apprentissage est requis non seulement pour des tâches similaires au sein du même domaine, mais également dans différents domaines à l’aide d’hyperparamètres fixes.
DeepMind explique d'abord des transformations simples pour prédire des ordres de grandeur inconnus, puis présente les modèles du monde, les critiques, les acteurs et leurs objectifs d'apprentissage solides. Il a été constaté que la combinaison de l'équilibre KL et des bits libres permet d'apprendre le modèle mondial sans ajustement et d'obtenir un régulateur d'entropie politique fixe en réduisant les rendements importants sans exagérer les petits rendements.
Prédictions Symlog
Reconstruire les entrées et prédire les récompenses et les valeurs est un défi car leur échelle peut varier d'un domaine à l'autre. L’utilisation de la perte carrée pour prédire des cibles importantes conduit à une divergence, tandis que la perte absolue et la perte de Huber bloquent l’apprentissage. En revanche, les objectifs de normalisation basés sur des statistiques d'exploitation introduisent de la non-stationnarité dans l'optimisation. Par conséquent, DeepMind propose la prédiction symlog comme solution simple à ce problème.
Pour ce faire, un réseau de neurones f (x, θ) avec l'entrée x et le paramètre θ apprend à prédire une version transformée de sa cible y. Pour lire la prédiction du réseau y^, DeepMind utilise une transformation inverse, comme le montre l'équation (1) ci-dessous.
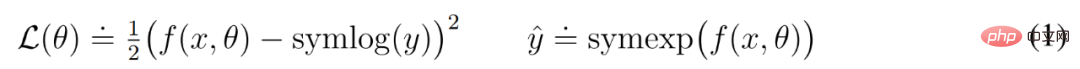
Comme vous pouvez le voir sur la figure 4 ci-dessous, les cibles avec des valeurs négatives ne peuvent pas être prédites en utilisant le logarithme (logarithme) comme transformation.

Par conséquent, DeepMind sélectionne une fonction de la famille des logarithmes bisymétriques, nommée symlog, comme transformation, et utilise la fonction symexp comme fonction inverse. La fonction
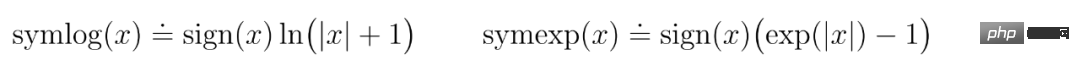
symlog compresse la taille des grandes valeurs positives et négatives. DreamerV3 utilise la prédiction symlog dans le décodeur, le prédicteur de récompense et le critique, et utilise également la fonction symlog pour compresser l'entrée de l'encodeur.
Apprentissage du modèle mondial
Le modèle mondial apprend une représentation compacte des entrées sensorielles grâce à l'auto-encodage et permet la planification en prédisant les représentations futures et les récompenses pour les actions potentielles.
Comme le montre la figure 3 ci-dessus, DeepMind implémente le modèle mondial en tant que modèle spatial à états récurrents (RSSM). Tout d’abord, un encodeur mappe l’entrée sensorielle x_t à une représentation aléatoire z_t, puis un modèle de séquence avec des états récurrents h_t prédit une séquence de ces représentations étant donné une action passée a_t−1. La concaténation de h_t et z_t forme l'état du modèle à partir duquel la récompense r_t et l'indicateur de continuité d'épisode c_t ∈ {0, 1} sont prédits et l'entrée est reconstruite pour garantir la représentation des informations, comme le montre l'équation (3) ci-dessous.
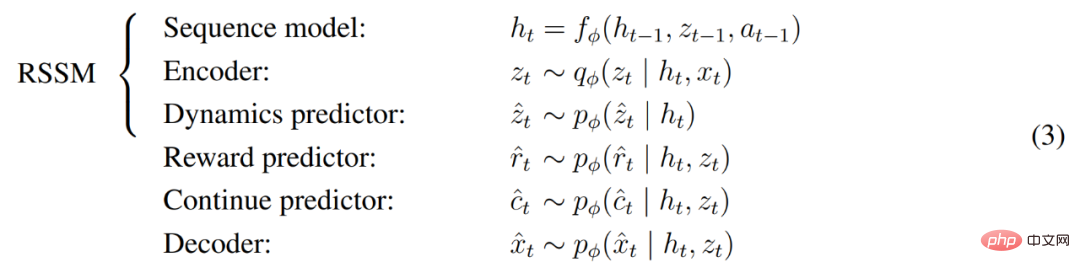
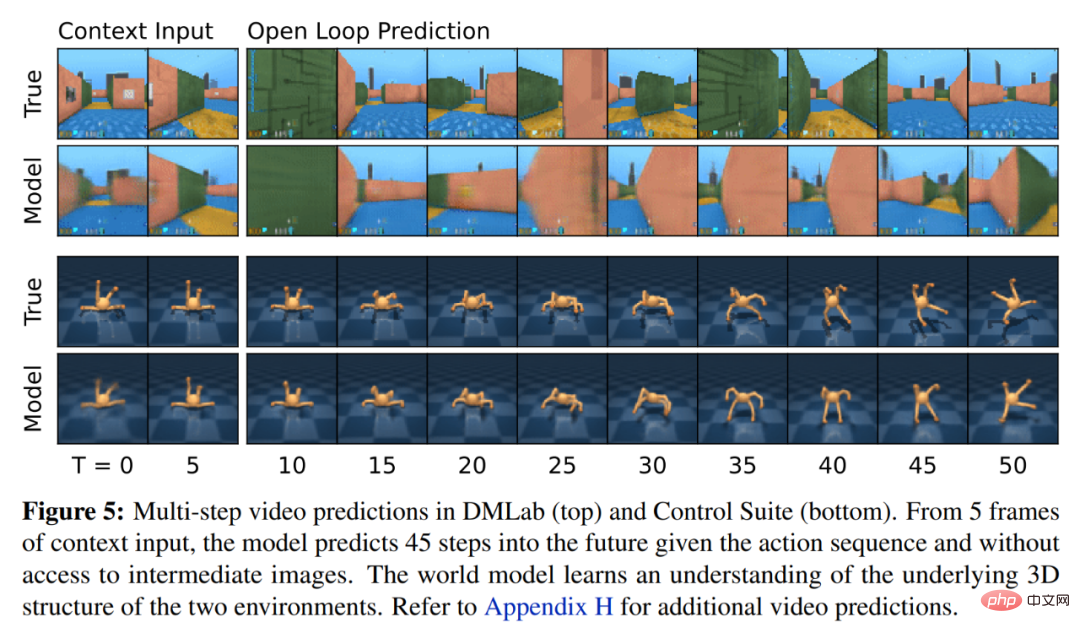
La figure 5 ci-dessous visualise la prédiction vidéo à long terme du monde mondial. L'encodeur et le décodeur utilisent un réseau neuronal convolutif (CNN) pour l'entrée visuelle et un perceptron multicouche (MLP) pour l'entrée de faible dimension. Les prédicteurs de dynamique, de récompense et de persistance sont également des MLP, et ces représentations sont échantillonnées à partir de vecteurs de distributions softmax. DeepMind utilise des gradients pass-through dans l'étape d'échantillonnage.
Apprentissage des critiques d'acteurs
Les réseaux neuronaux des critiques d'acteurs apprennent le comportement entièrement à partir de séquences abstraites prédites par un modèle mondial. Lors des interactions avec l'environnement, DeepMind sélectionne les actions par échantillonnage dans le réseau d'acteurs, sans nécessiter de planification préalable.
acteur et critique opèrent dans un état modèle 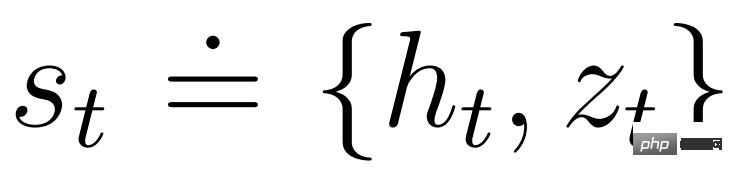 et peuvent bénéficier de la représentation markovienne apprise par le modèle mondial. L'objectif de l'acteur est de maximiser le rendement attendu
et peuvent bénéficier de la représentation markovienne apprise par le modèle mondial. L'objectif de l'acteur est de maximiser le rendement attendu 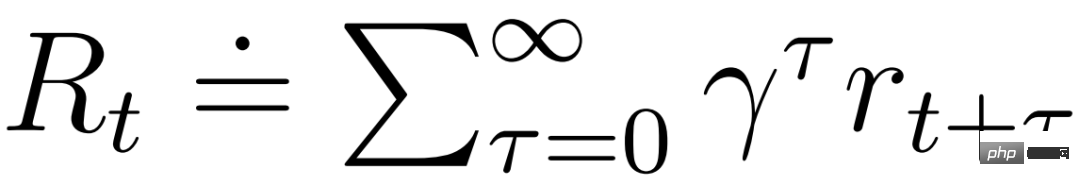 avec un facteur d'actualisation γ = 0,997 pour chaque état modèle. Pour tenir compte des récompenses au-delà de la plage de prédiction T = 16, le critique apprend à prédire la récompense pour chaque état en fonction du comportement actuel de l'acteur.
avec un facteur d'actualisation γ = 0,997 pour chaque état modèle. Pour tenir compte des récompenses au-delà de la plage de prédiction T = 16, le critique apprend à prédire la récompense pour chaque état en fonction du comportement actuel de l'acteur.
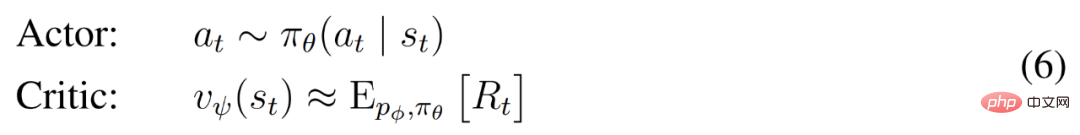
À partir d'une représentation de l'entrée rejouée, les prédicteurs et acteurs dynamiques produisent une séquence d'états de modèle attendus s_1:T , d'actions a_1:T , de récompenses r_1:T et d'indicateurs de continuation c_1:T . Pour estimer les rendements des récompenses en dehors de l'horizon prévu, DeepMind calcule les rendements λ bootstrapés, qui intègrent les rendements et la valeur attendus.
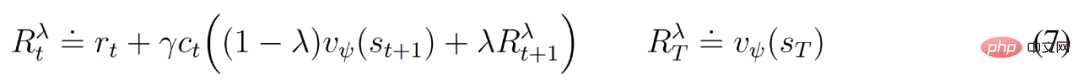
Résultats expérimentaux
DeepMind a mené une étude empirique approfondie pour évaluer la généralité et l'évolutivité de DreamerV3 dans différents domaines (plus de 150 tâches) sous des hyperparamètres fixes et par rapport aux méthodes SOTA existantes dans la littérature. DreamerV3 a également été appliqué au jeu vidéo stimulant Minecraft.
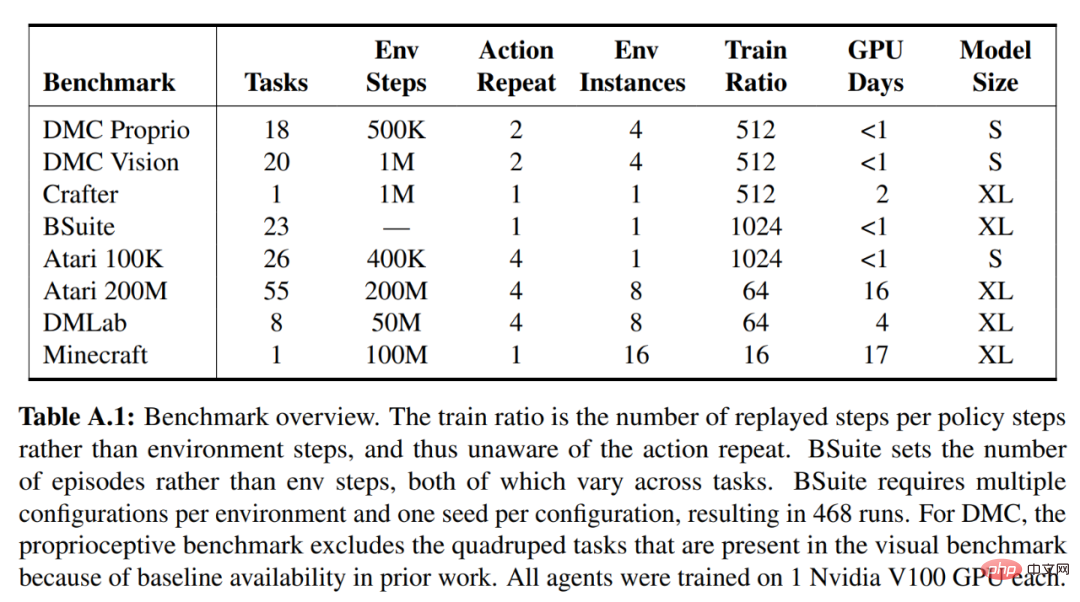
Pour DreamerV3, DeepMind simplifie la configuration en signalant directement les performances des stratégies de formation stochastiques et en évitant des évaluations séparées avec des stratégies déterministes. Tous les agents DreamerV3 sont formés sur un GPU Nvidia V100. Le tableau 1 ci-dessous donne un aperçu des critères de référence.
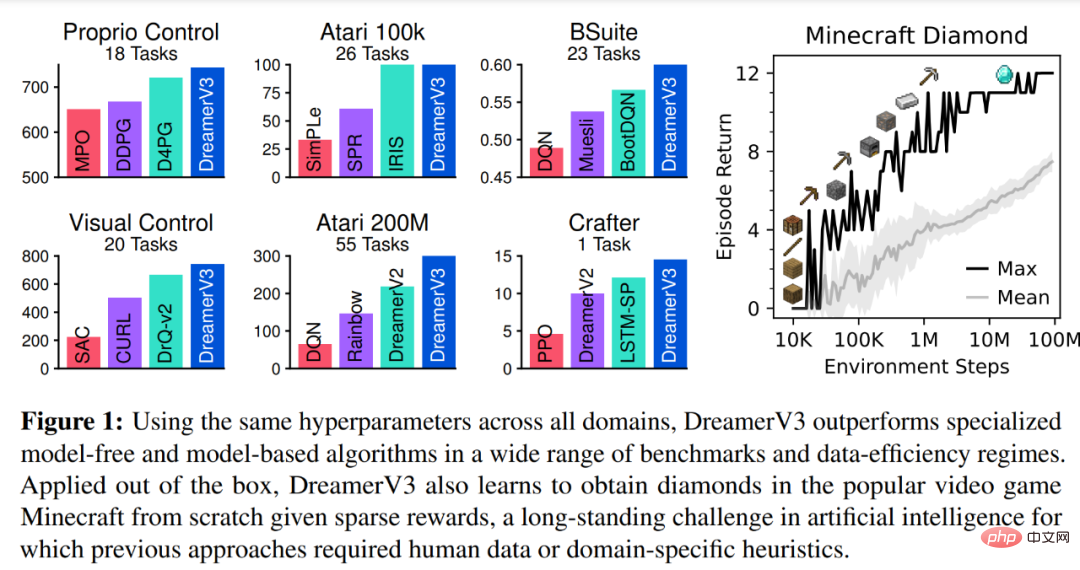
Pour évaluer la généralité de DreamerV3, DeepMind a mené des évaluations empiriques approfondies dans sept domaines, notamment les actions continues et discrètes, les entrées visuelles et de faible dimension, les récompenses denses et clairsemées, différentes échelles de récompense, le monde 2D et 3D et génération procédurale. Les résultats de la figure 1 ci-dessous montrent que DreamerV3 atteint de solides performances dans tous les domaines et surpasse tous les algorithmes précédents dans 4 d'entre eux, tout en utilisant des hyperparamètres fixes dans tous les benchmarks.
Veuillez vous référer à l'article original pour plus de détails techniques et de résultats expérimentaux.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Tendances technologiques à surveiller en 2023
- Comment l'intelligence artificielle apporte un nouveau travail quotidien aux équipes des centres de données
- L'intelligence artificielle ou l'automatisation peuvent-elles résoudre le problème de la faible efficacité énergétique des bâtiments ?
- Co-fondateur d'OpenAI interviewé par Huang Renxun : les capacités de raisonnement de GPT-4 n'ont pas encore atteint les attentes
- Bing de Microsoft surpasse Google en termes de trafic de recherche grâce à la technologie OpenAI