
Maison >Périphériques technologiques >IA >L'Université Harvard a foiré : DALL-E 2 n'est qu'un 'monstre de colle', et la précision de sa génération n'est que de 22 %
L'Université Harvard a foiré : DALL-E 2 n'est qu'un 'monstre de colle', et la précision de sa génération n'est que de 22 %

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBavant
- 2023-04-15 17:40:031221parcourir
Lors de la première sortie de DALL-E 2, les peintures générées pouvaient reproduire presque parfaitement le texte saisi. La résolution haute définition et la puissante imagination du dessin ont également amené divers internautes à le qualifier de "trop cool".

Mais un nouveau document de recherche de l'Université Harvard montre récemment que même si les images générées par DALL-E 2 sont exquises, il peut simplement coller plusieurs entités dans le texte sans même comprendre le texte pour exprimer la relation spatiale !

Lien papier : https://arxiv.org/pdf/2208.00005.pdf
Lien de données : https://osf.io/sm68h/
Par exemple, une invite de texte est donnée sous la forme "Une tasse sur une cuillère", vous pouvez voir que dans les images générées par DALL-E 2, vous pouvez voir que certaines images ne satisfont pas la relation "on".
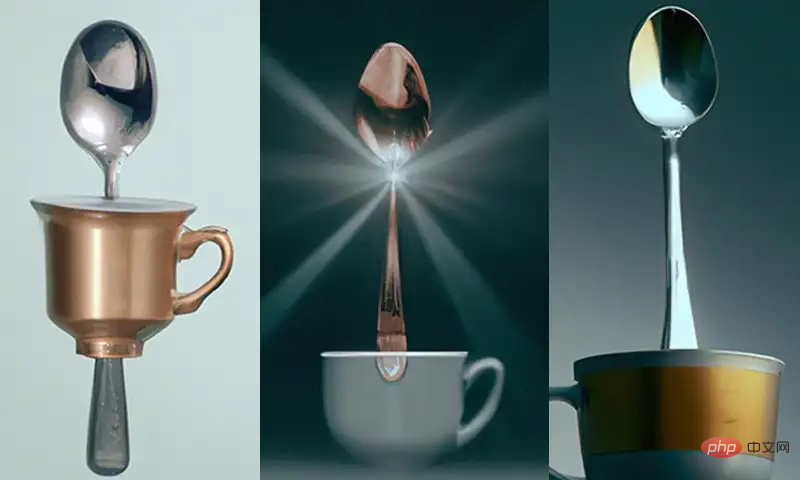
Mais dans l'ensemble d'entraînement, les combinaisons de tasses à thé et de cuillères que DALL-E 2 peut voir sont toutes "in", tandis que "on" est relativement rare, donc la précision dans la génération des deux relations n'est pas la même. . Pas pareil.

Ainsi, afin d'explorer si DALL-E 2 peut vraiment comprendre les relations sémantiques dans le texte, les chercheurs ont sélectionné 15 types de relations, dont 8 sont des relations spatiales (relations physiques), y compris dans, sur, sous , couvrant, proche, obstrué par, suspendu et lié à ; 7 relations agentiques, y compris pousser, tirer, toucher, frapper, donner des coups de pied, aider et se cacher
L'entité définie dans le texte est limitée à 12, sélectionnées. Elles sont toutes. éléments simples et communs dans chaque ensemble de données, à savoir : boîte, cylindre, couverture, bol, tasse à thé, couteau ; homme, femme, enfant, robot, singe et iguane.

Pour chaque relation de classe, créez 5 invites, au hasard. sélectionnez 2 entités à remplacer à chaque fois et générez enfin 75 invites de texte. Après soumission au moteur de rendu DALL-E 2, les 18 premières images générées ont été sélectionnées, ce qui a donné 1 350 images.
Ensuite, les chercheurs ont sélectionné 169 annotateurs sur 180 grâce à un test de raisonnement de bon sens pour participer au processus d'annotation.
Les résultats expérimentaux ont révélé que la cohérence moyenne entre les images générées par DALL-E 2 et les invites textuelles utilisées pour générer les images n'était que de 22,2 % parmi 75 invites
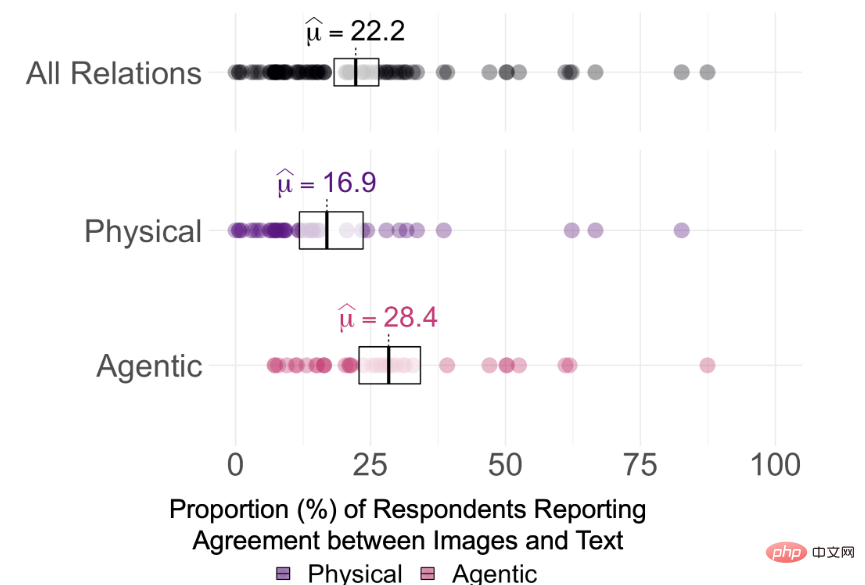
Mais il est difficile de dire ce que DALL-E 2 La question de savoir si la relation dans le texte est véritablement « comprise » est déterminée en observant les scores de cohérence des annotateurs et la signification pour un échantillon unique corrigée par Holm de chaque relation sur la base des seuils consensuels de 0 %, 25 % et 50 %. Le test montre que les taux d'accord des participants pour l'ensemble des 15 relations sont significativement supérieurs à 0 % à α = 0,95 (pHolm
Donc, même sans corriger les comparaisons multiples, le fait est que l'image générée par DALL-E 2 ne comprend pas la relation entre les deux objets dans le texte.
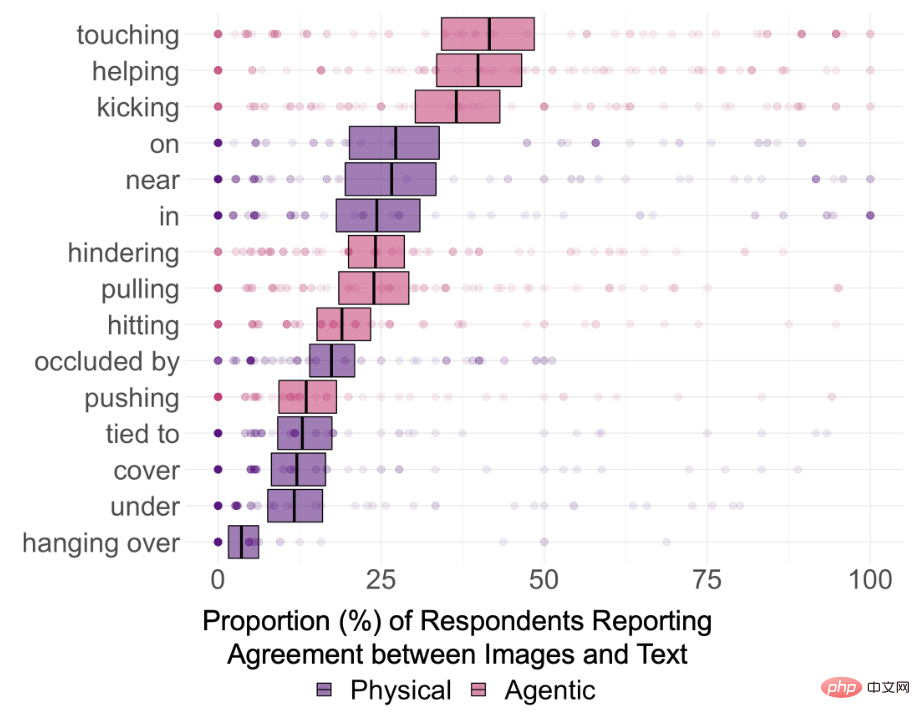
Les résultats montrent également que la capacité de DALL-E à connecter deux objets sans rapport n'est peut-être pas aussi forte qu'on l'imaginait. Par exemple, la cohérence de "Un enfant touchant un bol" a atteint 87%, car dans le monde réel. des images, des enfants et des bols apparaissent ensemble assez fréquemment.

Cependant, le taux de cohérence final de l'image générée par "Un singe qui touche un iguane" n'est que de 11%, et il peut même y avoir des erreurs d'espèces dans l'image rendue.

Ainsi, certaines catégories d'images dans DALL-E 2 sont relativement bien développées, comme les enfants et la nourriture, mais certaines catégories de données nécessitent tout de même une formation continue.
Cependant, actuellement, DALL-E 2 affiche encore principalement son style haute définition et réaliste sur le site officiel. Il n'est pas encore clair s'il « colle deux objets ensemble » ou s'il comprend réellement les informations textuelles avant de générer des images. .
Les chercheurs ont déclaré que la compréhension relationnelle est une composante fondamentale de l'intelligence humaine, et les mauvaises performances du DALL-E 2 dans les relations spatiales de base (par exemple sur, de) indiquent qu'il n'est pas encore capable de construire et de construire avec autant de flexibilité et de robustesse que les humains. Comprendre le monde.
Cependant, les internautes ont déclaré que être capable de développer de la « colle » pour coller les choses ensemble est déjà une belle réussite ! DALL-E 2 n'est pas AGI et il y a encore beaucoup de choses à améliorer dans le futur. Au moins, nous avons ouvert la porte à la génération automatique d'images !
D'autres problèmes avec DALL-E 2 ?
En effet, dès la sortie du DALL-E 2, un grand nombre de praticiens ont procédé à une analyse approfondie de ses avantages et inconvénients.

Lien du blog : https://www.lesswrong.com/posts/uKp6tBFStnsvrot5t/what-dall-e-2-can-and-cannot-do
Écrire des romans avec GPT-3 est un peu monotone, DALL -E 2 peut générer des illustrations pour des textes et même des bandes dessinées pour des textes longs.
Par exemple, DALL-E 2 peut ajouter des fonctionnalités aux images, telles que "Une femme dans un café travaillant sur son ordinateur portable et portant des écouteurs, peignant par Alphonse Mucha", qui peut générer avec précision des styles de peinture, des cafés, portant des écouteurs, et les ordinateurs portables, etc.

Mais si la description de la fonctionnalité dans le texte implique deux personnes, DALL-E 2 peut oublier quelles fonctionnalités appartiennent à quelle personne. Par exemple, le texte saisi est :
un jeune garçon aux cheveux noirs se reposant dans son lit, et une femme âgée aux cheveux gris assise sur une chaise à côté du lit sous une fenêtre avec le soleil qui traverse, art numérique de style Pixar Art numérique de style Pixar sur une chaise à côté du lit, avec la lumière du soleil qui traverse.
On peut voir que DALL-E 2 peut générer correctement des fenêtres, des chaises et des lits, mais les images générées sont légèrement confuses dans la combinaison des caractéristiques d'âge, de sexe et de couleur de cheveux. Un autre exemple est de laisser "Captain America et Iron Man côte à côte". Vous pouvez voir que le résultat généré a évidemment les caractéristiques de Captain America et Iron Man, mais les éléments spécifiques sont placés sur des personnes différentes (comme Iron L'Homme avec le bouclier de Captain America).
Un autre exemple est de laisser "Captain America et Iron Man côte à côte". Vous pouvez voir que le résultat généré a évidemment les caractéristiques de Captain America et Iron Man, mais les éléments spécifiques sont placés sur des personnes différentes (comme Iron L'Homme avec le bouclier de Captain America).
 Par exemple, le texte saisi est :
Par exemple, le texte saisi est :
Deux chiens habillés comme des soldats romains sur un bateau pirate regardant New York à travers une lunette.
Cette fois, DALL-E 2 a tout simplement cessé de fonctionner. Il a fallu une demi-heure à l'auteur pour comprendre. Au final, il lui a fallu choisir entre "La ville de New York et un bateau pirate" ou "un chien avec un télescope et". un uniforme de soldat romain".
Dall-E 2 peut générer des images en utilisant un arrière-plan générique, comme une ville ou une étagère dans une bibliothèque, mais si ce n'est pas l'objectif principal de l'image, obtenir des détails plus fins devient souvent très difficile.
Bien que DALL-E 2 puisse générer des objets courants, tels que diverses chaises fantaisie, si vous lui demandez de générer un "vélo Alto", l'image résultante sera quelque peu similaire à un vélo, mais pas exactement.
Et la recherche Otto Bicycle sous Google Images est la suivante. DALL-E 2 est également incapable d'épeler, mais épellera occasionnellement un mot correctement par coïncidence totale, par exemple en lui faisant écrire STOP sur un panneau d'arrêt

DALL-E 2 propose également une fonction d'édition. Par exemple, après avoir généré une image, vous pouvez utiliser le curseur pour mettre en surbrillance sa zone et ajouter une description complète de la modification. 

Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Tendances technologiques à surveiller en 2023
- Comment l'intelligence artificielle apporte un nouveau travail quotidien aux équipes des centres de données
- L'intelligence artificielle ou l'automatisation peuvent-elles résoudre le problème de la faible efficacité énergétique des bâtiments ?
- Co-fondateur d'OpenAI interviewé par Huang Renxun : les capacités de raisonnement de GPT-4 n'ont pas encore atteint les attentes
- Bing de Microsoft surpasse Google en termes de trafic de recherche grâce à la technologie OpenAI