
Maison >Périphériques technologiques >IA >Pratique de mise en œuvre de la technologie de reconnaissance vocale dans la station B
Pratique de mise en œuvre de la technologie de reconnaissance vocale dans la station B

- 王林avant
- 2023-04-15 10:40:021809parcourir
La technologie de reconnaissance vocale automatique (ASR) a été mise en œuvre à grande échelle dans des scénarios commerciaux connexes de Bilibili, tels que l'examen de la sécurité du contenu audio et vidéo, les sous-titres IA (côté C, must-cut, diffusion en direct S12, etc.), compréhension de la vidéo (recherche en texte intégral) )attendez.
De plus, le moteur ASR de Bilibili a également remporté la première place lors de la dernière évaluation à grande échelle du benchmark industriel SpeechIO (https://github.com/SpeechColab/Leaderboard) en novembre 2022 (https://github.com/ SpeechColab/Leaderboard#5-ranking), et l'avantage est plus évident dans l'ensemble de tests privés.
Classement de tous les ensembles de tests | ||
Classement |
Fabricant |
Taux d'erreur |
1 |
Station B | 2,82% |
2 |
Alibaba Cloud |
2,85% |
3 |
Y itu |
3.16% |
4 | Microsoft |
3,28% |
5 |
Tencent |
3,85% |
6 |
iFlytek |
4. 05% |
7 |
VITESSE |
5,19% |
8 |
Baidu |
8,14% |
- Sous-titres AI (face C chinoise et anglaise, must-cut, diffusion en direct S12, etc.)
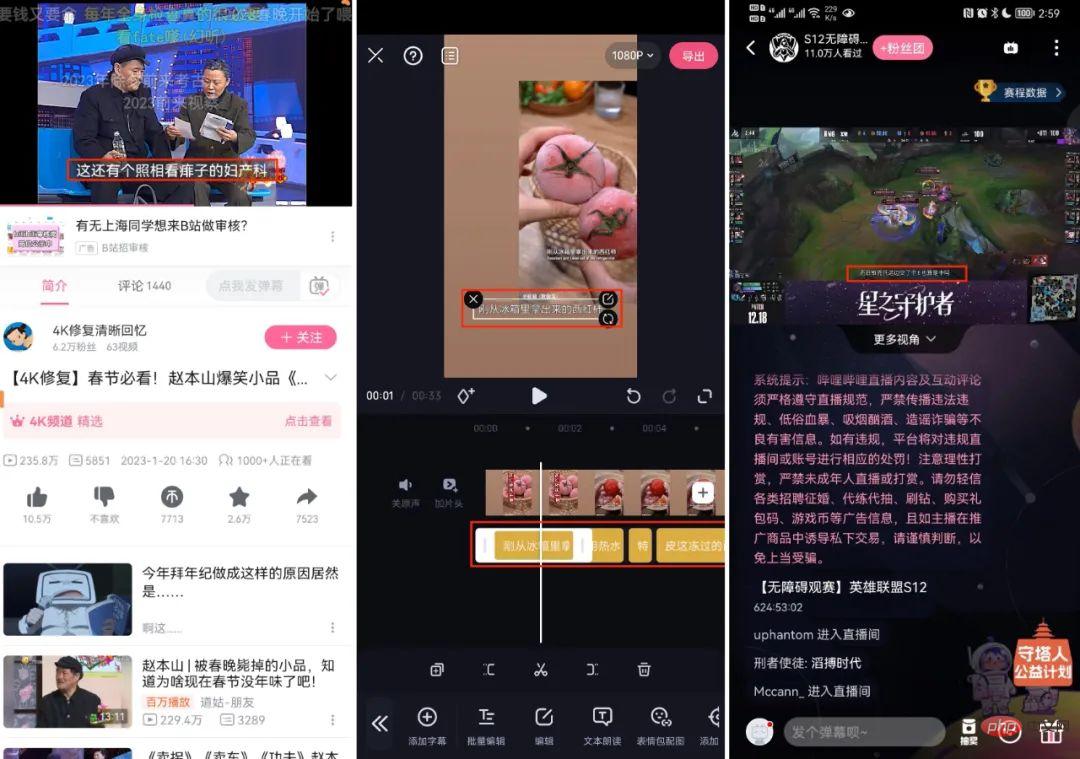
- Recherche en texte intégral
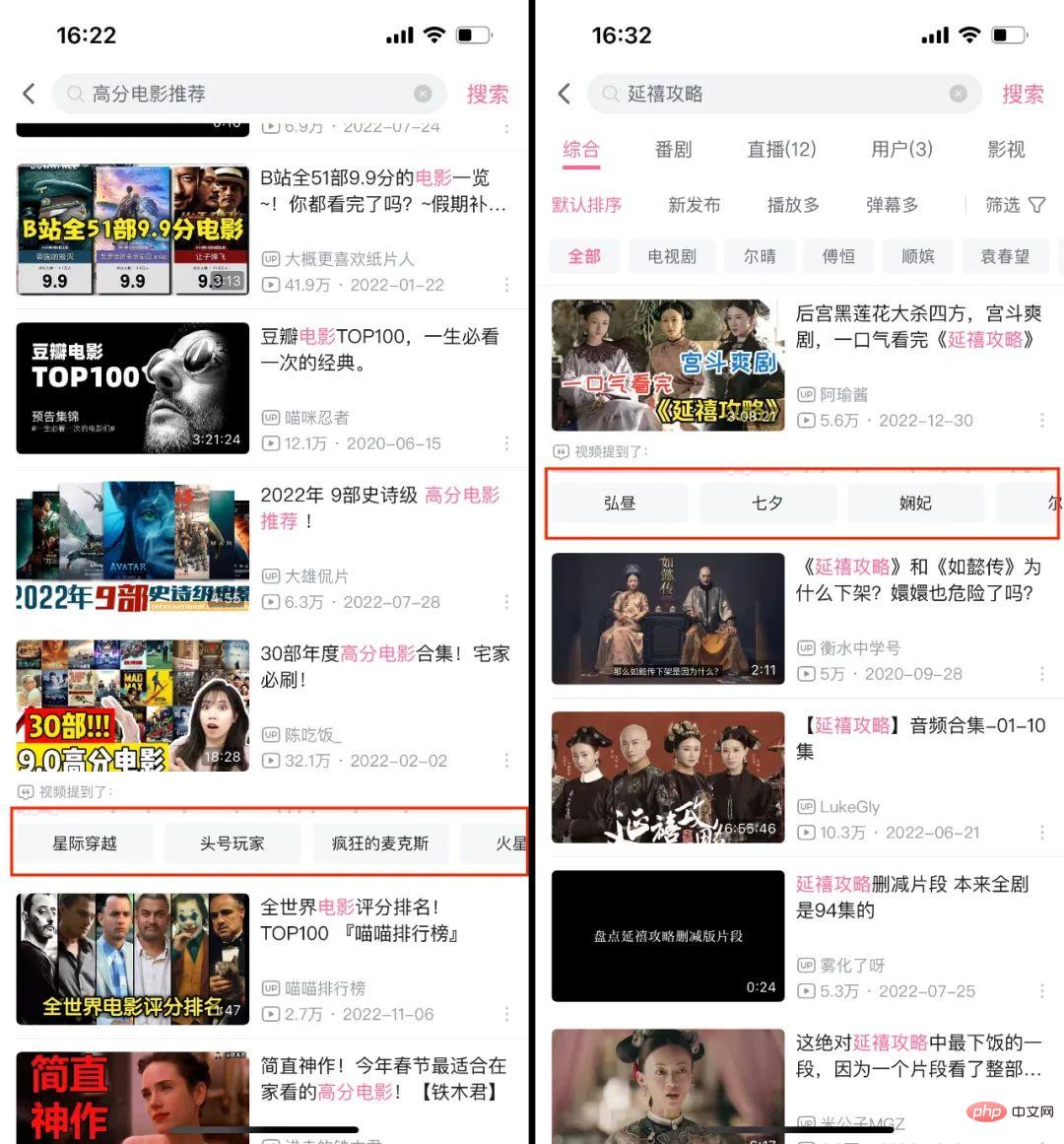
Cet article présentera le processus, nous avons accumulé et exploré des données et des algorithmes.
Moteur ASR de haute qualité
Un moteur ASR de haute qualité (rentable) adapté à la production industrielle, il doit avoir les caractéristiques suivantes :
| Explication |
Haute précision |
Haute précision et bonne robustesse dans des scénarios commerciaux pertinents |
Haute performance |
Industrie le déploiement Rial a une faible latence, une vitesse rapide et consomme ressources informatiques Moins |
Haute évolutivité |
Peut prendre en charge efficacement la personnalisation des itérations métier et répondre aux besoins de mise à jour rapide de l'entreprise |
Ce qui suit présentera notre exploration et notre pratique associées dans les aspects ci-dessus, basées sur le scénario commercial de la station B.
Démarrage à froid des données
La tâche de reconnaissance vocale consiste à identifier complètement le contenu du texte à partir d'un morceau de discours (parole à texte).
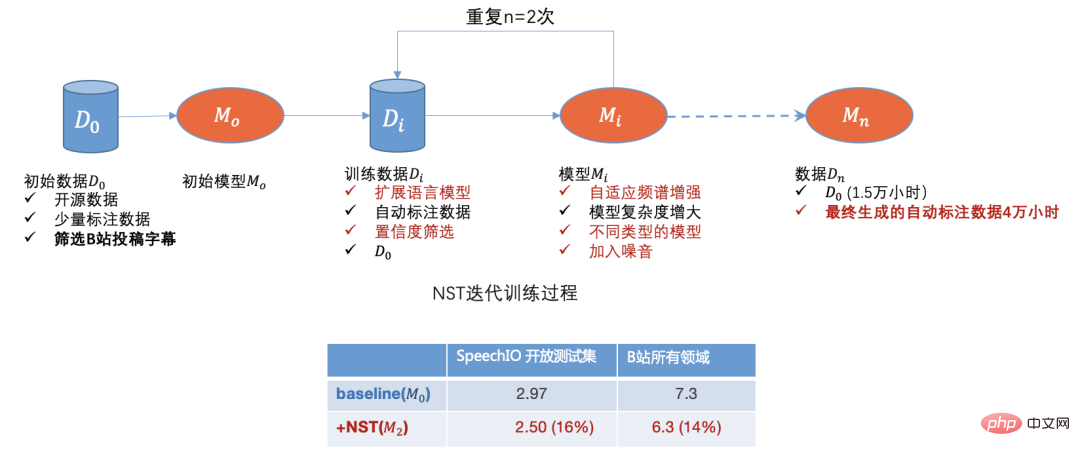
Le système ASR qui répond aux besoins de la production industrielle moderne s'appuie sur une quantité importante et diversifiée de données d'entraînement. Ici, la « diversité » fait référence à des données non homogènes telles que l'environnement de l'intervenant, le contexte de la scène (terrain) et. l'accent de l'orateur.
Pour le scénario commercial de Bilibili, nous devons d'abord résoudre le problème du démarrage à froid des données d'entraînement vocal. Nous rencontrerons les défis suivants :
- Démarrage à froid : il n'y a qu'une très petite quantité de données open source au niveau. début, et les données achetées correspondent au scénario commercial. Le degré est très faible.
- Large gamme de scénarios commerciaux : Les scénarios commerciaux audio et vidéo de la Station B couvrent des dizaines de domaines, qui peuvent être considérés comme un domaine général et ont des exigences élevées en matière de « diversité » des données.
- Mélange de chinois et d'anglais : la station B compte plus de jeunes utilisateurs et il existe davantage de vidéos de culture générale mélangées en chinois et en anglais.
Pour les problèmes ci-dessus, nous avons adopté les solutions de données suivantes :
Filtrage des données d'entreprise
Le site B a un petit nombre de sous-titres (sous-titres cc) soumis par les propriétaires ou les utilisateurs d'UP, mais il Il y a aussi quelques problèmes :
- Les horodatages de début et de fin des phrases se trouvent souvent au milieu du premier et du dernier mot ou après quelques mots
- Il n'y a pas de correspondance complète entre la voix et le texte ; il y a trop de mots, trop peu de mots, de commentaires ou de traductions, et il y a des interprétations basées sur le sens La situation de génération de sous-titres
- Conversion numérique, comme les sous-titres en 2002 (prononciation réelle de 2002, 2002, etc.) ;
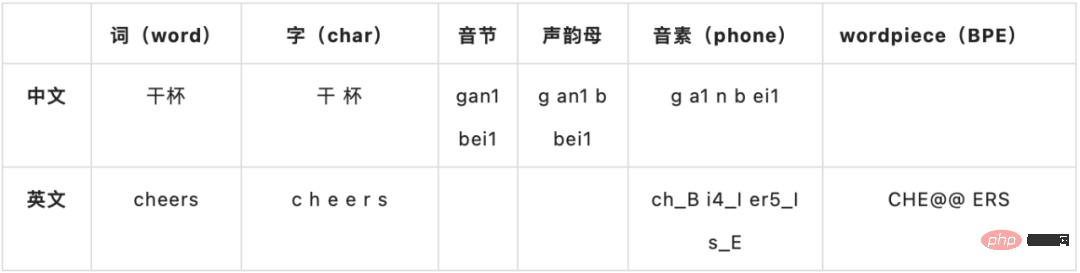
Hybride ou E2E
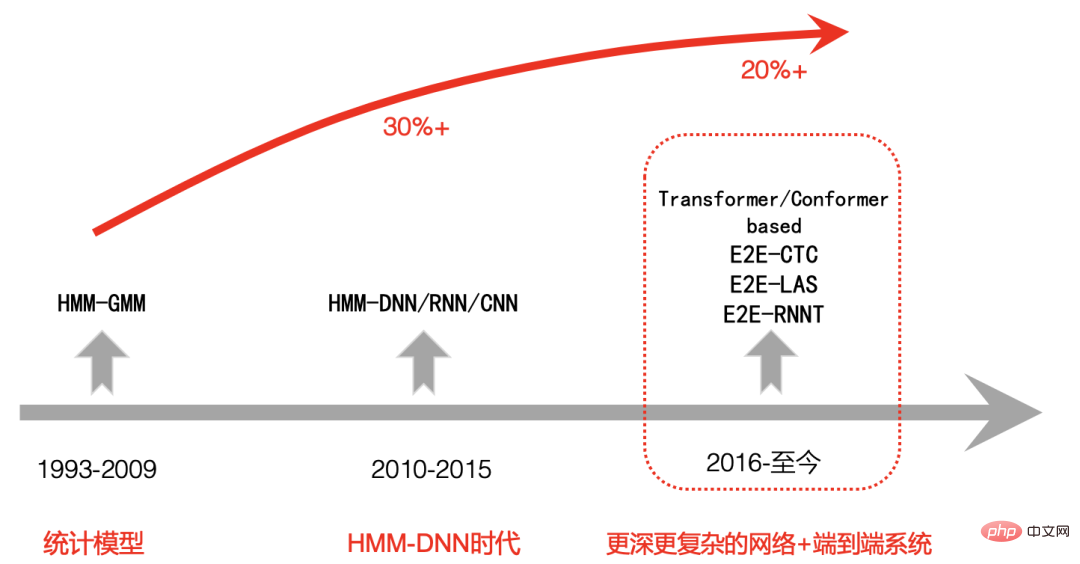
La deuxième étape du cadre hybride basé sur un réseau neuronal HMM-DNN présente une énorme amélioration de la précision de la reconnaissance vocale par rapport à la première étape du système HMM-GMM. Cela a également été reconnu par tout le monde.
Cependant, la troisième phase de comparaison du système de bout en bout (E2E) avec la deuxième phase a également été controversée dans l'industrie pendant un certain temps [4] avec le développement de la technologie de l'IA, en particulier l'émergence des transformateurs. modèles associés, La capacité de représentation du modèle devient de plus en plus forte.
Dans le même temps, avec l'amélioration significative de la puissance de calcul du GPU, nous pouvons ajouter davantage de formation sur les données. La solution de bout en bout montre progressivement ses avantages, et de plus en plus d'entreprises choisissent un plan de bout en bout.
Nous comparons ici ces deux solutions basées sur le scénario commercial de Bilibili :
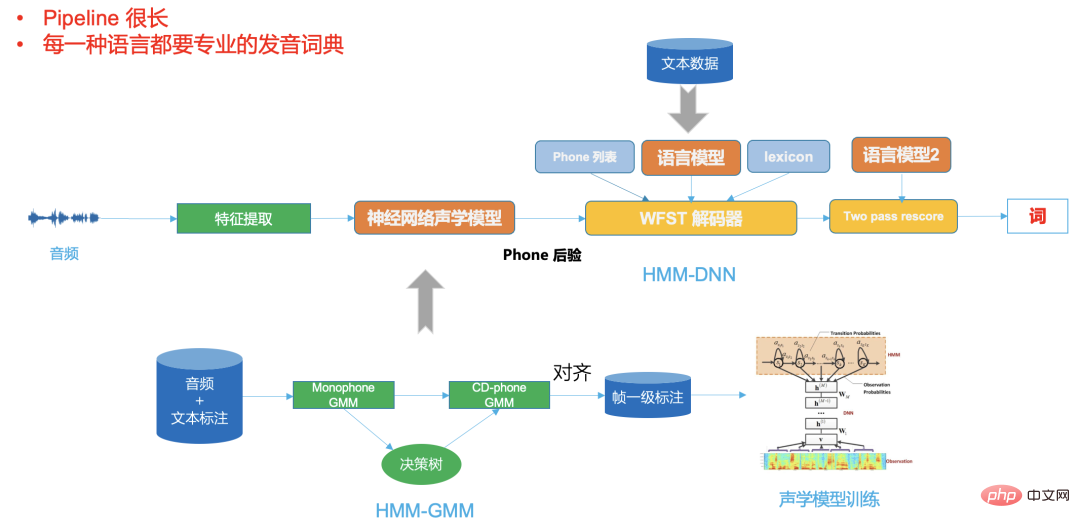
Figure 3
La figure 2 est un framework DNN-HMM typique. On peut voir que son pipeline est très long et dans différentes langues . nécessite une expertise professionnelle. Dictionnaire de prononciation,
Et le système de bout en bout de la figure 3 place tout cela dans un modèle de réseau neuronal. L'entrée du réseau neuronal est l'audio (ou les fonctionnalités), et la sortie est le résultat de la reconnaissance. nous voulons.
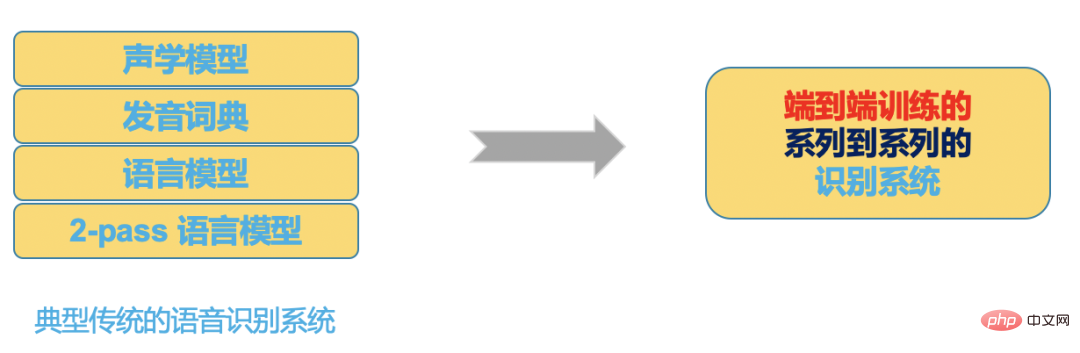
Figure 4
Avec le développement de la technologie, les avantages des systèmes de bout en bout en termes d'outils de développement, de communautés et de performances deviennent de plus en plus évidents :
- Comparaison des outils et des communautés représentatifs
Cadre hybride (hybride) |
Cadre de bout en bout (E2E) |
|
Représentatif ouvert outils sources et communautés |
HTK, Kaldi |
Espnet, Wenet, DeepSpeech, K2, etc. |
Langages de programmation |
C/C++, Shell |
Python, Shell |
Extensibilité |
|
TensorFlow /Pytorch |
- Comparaison des performances
Le tableau suivant est le résultat optimal (CER) d'ensembles de données typiques basés sur des outils représentatifs :
| Kaldi | Espnet | |
| signifie technologie | tdnn+chain+rnnlm rescoring G igaSpeech | 14.84 |
10.80 |
Aishell-1 | 7.43 |
4.72 | ||
WenetSpeech |
12.83 |
8.80 |
En bref, en choisissant un système de bout en bout, par rapport au cadre hybride traditionnel, compte tenu de certaines ressources, nous pouvons développer un système ASR de haute qualité plus rapidement et mieux.
Bien sûr, sur la base du cadre hybride, si nous utilisons également des modèles tout aussi avancés et des décodeurs hautement optimisés, nous pouvons obtenir des résultats proches de bout en bout, mais nous devrons peut-être investir plusieurs fois la main-d'œuvre et les ressources pour développer et optimiser ce système.
Sélection de solutions de bout en bout
Bilibili dispose de centaines de milliers d'heures d'audio qui doivent être transcrites chaque jour, ce qui nécessite un débit et une vitesse élevés du système ASR. La précision de la génération de l'IA. Les exigences en matière de sous-titres sont également élevées et la couverture des scènes de la station B est également très étendue. Il est très important pour nous de choisir un système ASR raisonnable et efficace.
Système ASR idéal
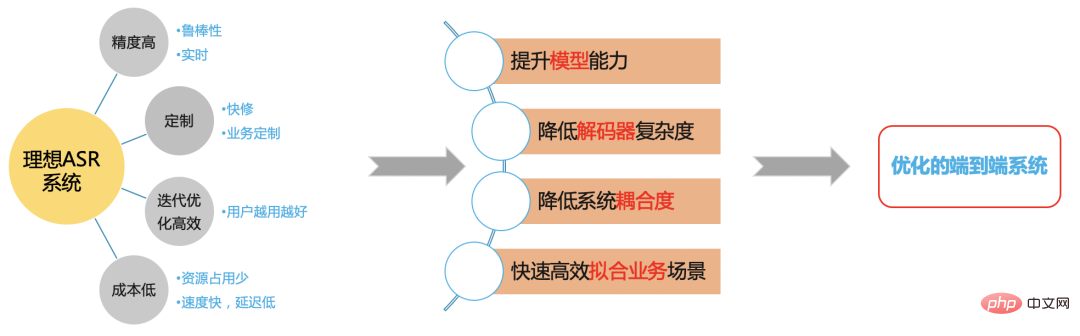
Figure 5
Nous espérons construire un système ASR efficace basé sur le cadre de bout en bout pour résoudre les problèmes du scénario de la station B.
Comparaison des systèmes de bout en bout
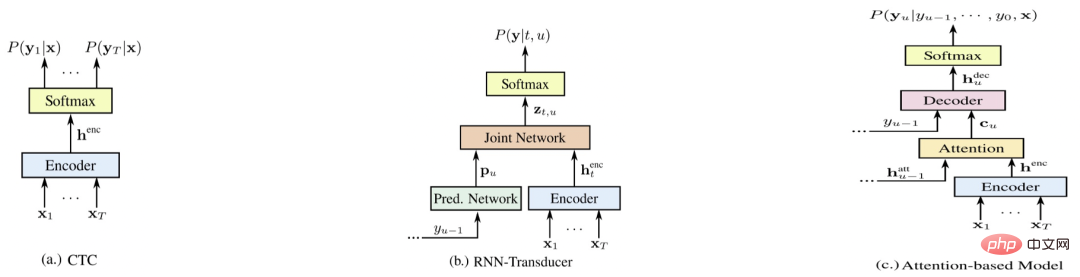
Figure 6
La figure 4 représente les trois systèmes de bout en bout représentatifs [5], à savoir E2E-CTC, E2E-RNNT et E2E-AED. ce qui suit provient de Comparez les avantages et les inconvénients de chaque système sous divers aspects (plus le score est élevé, mieux c'est)
- E2E-RNNT
|
5 |
6 |
En temps réel (streaming) |
3 |
5 |
5 |
Coût et rapidité | 4 |
3 |
5 |
Résolution rapide |
3 |
3 |
6 |
Itération rapide et efficace |
6 |
4 |
5 |
- Comparaison de précision sans streaming (CER)
2000 heures |
15000 heures |
|
| Modèle chaîne Kaldi+LM
|
13.7 | -- |
| E2E-AED | 11.8 | 6.6 |
| E2E-RNNT | 12.4 | --
|
| E2E-CTC(gourmand) | 13.1 | 7.1 |
| E2E-CTC+LM optimisé | 1 0.2 | 5.8 | 6.63 |
E2E LFMMI DT |
6.13 |
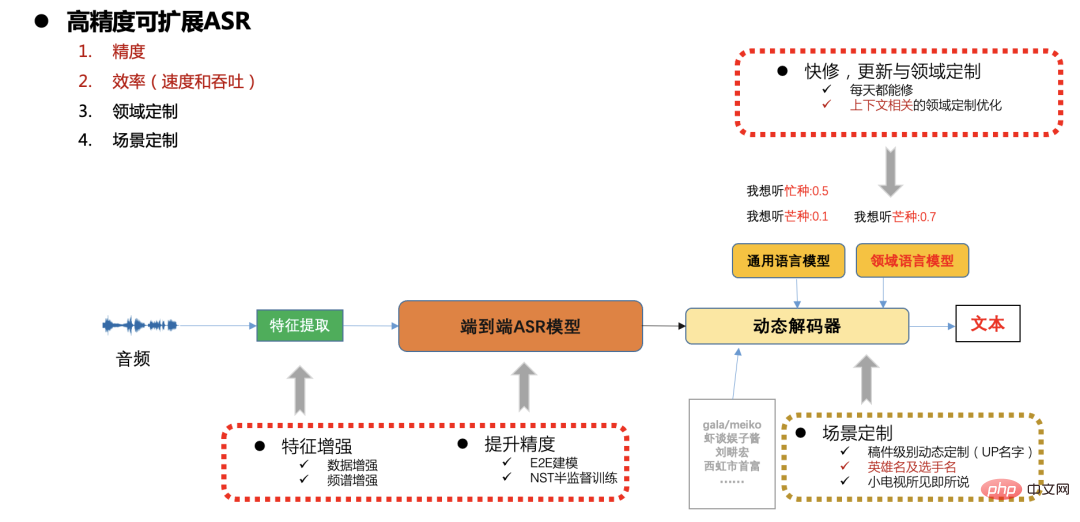
 b. Pendant l'entraînement, chaque mini-lot calcule respectivement le numérateur et le treillis à partir du pré-généré ; alignement et treillis. Dénominateur et mise à jour du modèle
b. Pendant l'entraînement, chaque mini-lot calcule respectivement le numérateur et le treillis à partir du pré-généré ; alignement et treillis. Dénominateur et mise à jour du modèle 
Par rapport aux systèmes hybrides, les horodatages des résultats de décodage du système de bout en bout ne sont pas très précis. La formation AED ne s'aligne pas de manière monotone avec le temps. Le modèle formé par CTC est beaucoup plus précis que les horodatages AED, mais il existe également un problème de pointe. Chaque mot La durée est inexacte ;
Après un entraînement discriminant de bout en bout, la sortie du modèle deviendra plus plate et les limites d'horodatage des résultats de décodage seront plus précises
Décodeur CTC de bout en bout
;Dans le développement de la technologie de reconnaissance vocale Dans le processus, qu'il s'agisse de la première étape basée sur GMM-HMM ou de la deuxième étape basée sur le cadre hybride DNN-HMM, le décodeur est un composant très important.
Les performances du décodeur déterminent directement la vitesse et la précision du système ASR final. L'expansion et la personnalisation des activités reposent également principalement sur des solutions de décodeur flexibles et efficaces. Les décodeurs traditionnels, qu'il s'agisse de décodeurs dynamiques ou de décodeurs statiques basés sur WFST, sont très complexes. Ils reposent non seulement sur de nombreuses connaissances théoriques, mais nécessitent également une conception en ingénierie logicielle professionnelle. Le développement d'un moteur de décodage traditionnel avec des performances supérieures nécessite non seulement une conception en ingénierie logicielle professionnelle. beaucoup de développement de main-d'œuvre au début, et les coûts de maintenance ultérieurs sont également très élevés.
Un décodeur WFST traditionnel typique doit compiler hmm, le contexte triphone, le dictionnaire et le modèle de langage dans un réseau unifié, à savoir HCLG, dans un espace de recherche de réseau FST unifié, ce qui peut améliorer la vitesse et la précision du décodage.
Avec la maturité de la technologie des systèmes de bout en bout, l'unité de modélisation du système de bout en bout a une plus grande granularité, comme les mots chinois ou les mots anglais, car la structure de transfert HMM traditionnelle, le contexte triphone et le dictionnaire de prononciation sont supprimés. , cela rend l'espace de recherche de décodage ultérieur beaucoup plus petit, nous choisissons donc un décodeur dynamique simple et efficace basé sur la recherche de faisceaux. Par rapport au décodeur WFST traditionnel, le décodeur dynamique de bout en bout a. les avantages suivants :
- Occupe peu de ressources, généralement 1/5 des ressources de décodage WFST ;
- Son faible degré de couplage facilite la personnalisation du business et l'intégration du décodage avec différents modèles de langage ; chaque modification ne nécessite pas de recompilation des ressources de décodage ; La vitesse de décodage est rapide, grâce au décodage synchrone des mots [8], qui est généralement 5 fois plus rapide que la vitesse de décodage WFST
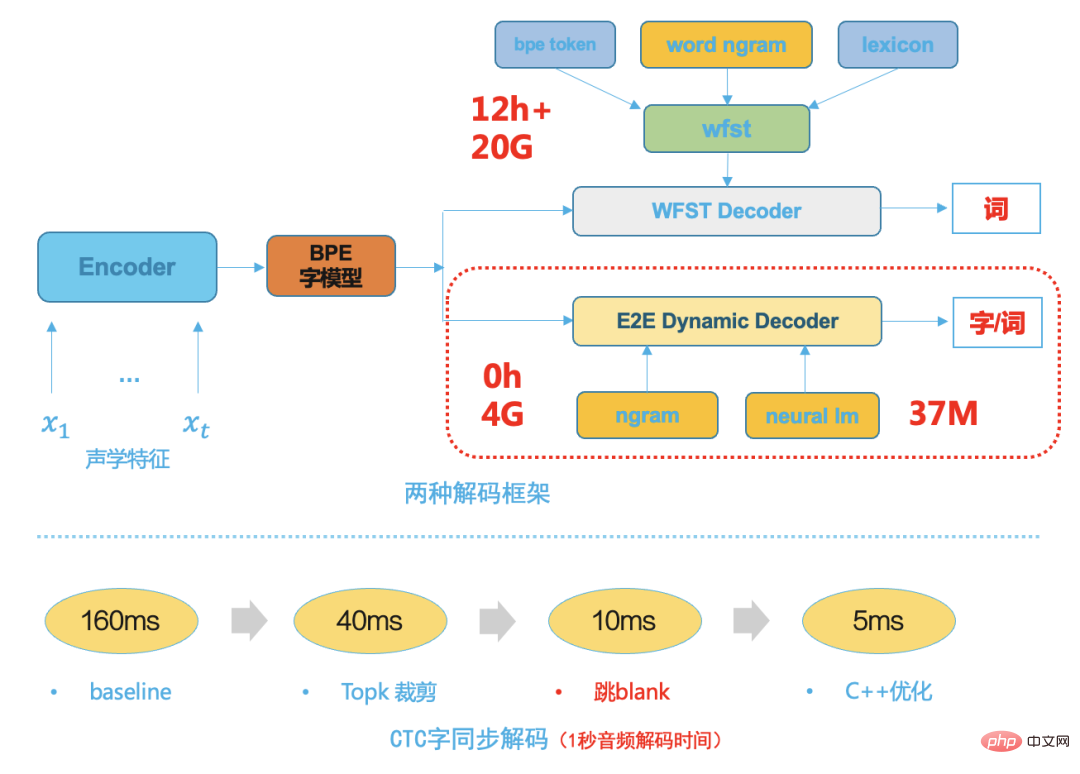 Figure 8
Figure 8
dans un cadre raisonnable et efficace ; Pour terminer le cadre ASR, la partie avec la plus grande quantité de calcul devrait être l'inférence du modèle de réseau neuronal, et cette partie à forte intensité de calcul peut utiliser pleinement la puissance de calcul du GPU. Nous optimisons le déploiement de l'inférence du modèle à partir de l'inférence. service, structure du modèle et quantification du modèle :
Le modèle utilise l'inférence demi-précision F16
- Le modèle est converti en FasterTransformer[9], basé sur le transformateur hautement optimisé de nvidia
- Utilisation de triton pour déployer automatiquement le modèle d'inférence ; regroupement de lots, améliorant pleinement l'efficacité d'utilisation du GPU ;
- Sur un seul GPU T4 La vitesse est augmentée de 30 %, le débit est multiplié par 2 et 3 000 heures d'audio peuvent être transcrites en une heure
Résumé ;
Cet article présente principalement la mise en œuvre de la technologie de reconnaissance vocale dans la scène de Bilibili Comment résoudre le problème des données de formation à partir de zéro, la sélection de la solution technique globale, l'introduction et l'optimisation de chaque sous-. module, comprenant la formation du modèle, l'optimisation du décodeur et le déploiement de l'inférence de service, etc. À l'avenir, nous améliorerons encore l'expérience utilisateur dans les scénarios d'atterrissage pertinents, tels que l'utilisation de la technologie de mots chauds instantanés pour optimiser l'exactitude des mots d'entité pertinents au niveau du manuscrit, combinée à la technologie liée au streaming ASR, une prise en charge personnalisée plus efficace pour le réel ; transcription temporelle sous-titrée de jeux et d'événements sportifs.
Références
[1] A Baevski, H Zhou, et al. wav2vec 2.0 : Un cadre pour l'apprentissage auto-supervisé des représentations de la parole
[2] A Baevski, W Hsu, et al. Apprentissage auto-supervisé de la parole, de la vision et du langage
[3] Daniel S, Y Zhang, et al. Formation améliorée des étudiants bruyants pour la reconnaissance automatique de la parole
[4] C Lüscher, E Beck, et al. LibriSpeech : Hybride vs Attention - sans augmentation des données
[5] R Prabhavalkar, K Rao, et al, Une comparaison des modèles séquence à séquence pour la reconnaissance vocale
[6] D Povey, V Peddinti1, et al, Réseaux de neurones purement entraînés en séquence pour l'ASR basés sur MMI sans réseau
[7] H Xiang, Z Ou, MODÉLISATION ACOUSTIQUE EN UNE ÉTAPE BASÉE SUR CRF AVEC TOPOLOGIE CTC
[8] Z Chen, W Deng, et al, Décodage synchrone téléphonique avec réseau CTC
[9]
https://www.php.cn/link/2ea6241cf767c279cf1e80a790df1885L'auteur de ce numéro : Deng WeiIngénieur senior en algorithmes
Responsable de la direction reconnaissance vocale chez Bilibili
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Tendances technologiques à surveiller en 2023
- Comment l'intelligence artificielle apporte un nouveau travail quotidien aux équipes des centres de données
- L'intelligence artificielle ou l'automatisation peuvent-elles résoudre le problème de la faible efficacité énergétique des bâtiments ?
- Co-fondateur d'OpenAI interviewé par Huang Renxun : les capacités de raisonnement de GPT-4 n'ont pas encore atteint les attentes
- Bing de Microsoft surpasse Google en termes de trafic de recherche grâce à la technologie OpenAI