
Maison >Problème commun >OpenAI et Microsoft Sentinel Partie 3 : DaVinci et Turbo
OpenAI et Microsoft Sentinel Partie 3 : DaVinci et Turbo

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBavant
- 2023-04-14 21:28:011732parcourir
Bienvenue dans notre série sur les grands modèles linguistiques (LLM) d'OpenAI et Microsoft Sentinel. Dans la première partie, nous avons créé un playbook de base utilisant OpenAI et le connecteur Azure Logic Apps intégré de Sentinel pour expliquer les tactiques MITRE ATT&CK trouvées lors de l'événement, et avons discuté de certains des différents paramètres qui pourraient affecter le modèle OpenAI, tels que la température et fréquence punir. Ensuite, nous étendons cette fonctionnalité à l'aide de l'API REST de Sentinel pour rechercher des règles d'analyse planifiées et renvoyer un résumé de la logique de détection des règles.
Si vous avez prêté attention, vous avez peut-être remarqué que notre premier playbook recherche les tactiques MITRE ATT&CK des événements Sentinel, mais n'inclut aucune technique d'événement dans l'astuce GPT3. Pourquoi pas? Eh bien, lancez votre OpenAI API Playground et faisons un tour dans le terrier du lapin (avec mes excuses à Lewis Carroll). ... Les tactiques et techniques MITRE ATT&CK suivantes sont expliquées : ["DefenseEvasion"], ["T1564"]"
- Voici nos premiers résultats :
- C'est une excellente revue du MITRE ATT&CK Tactic TA0005 ,Defense Evasion Bon résumé, mais qu'en est-il de la description technique ? T1564 est Masquer les artefacts - Injection de processus (T1055) et Rootkit (T1014), entre autres techniques nommées. Essayons encore.
- Loin de là ! "Exploiter les services à distance" est la technique T1210 de la stratégie de mouvement latéral. Encore une fois :
- Alors que s'est-il passé ? ChatGPT ne devrait-il pas être meilleur que cela ? !
Eh bien, oui. ChatGPT est vraiment
génial pour résumer le code technique de MITRE ATT&CK, mais nous n'avons pas encore posé de questions à ce sujet. Nous avons utilisé l'autre modèle génératif pré-entraîné Transformer-3.5 (GPT-3.5) d'OpenAI "text-davinci-003" en mode de complétion de texte. ChatGPT utilise le modèle « gpt-3.5-turbo » en mode de complétion de chat. La différence est énorme. Voici un exemple de réponse de ChatGPT à la même requête ci-dessus : 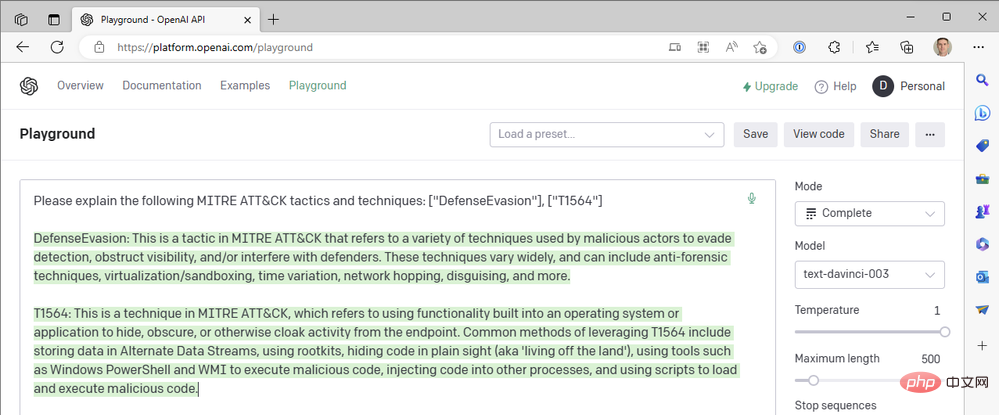
Mais le connecteur OpenAI de notre application Azure Logic ne nous fournit pas d'actions basées sur le chat et nous ne pouvons pas sélectionner le modèle Turbo, alors comment pouvons-nous introduire ChatGPT Quoi à propos de notre flux de travail Sentinel ? Tout comme nous avons fermé le connecteur Sentinel Logic App dans la partie II pour appeler directement les opérations HTTP de l'API Sentinel REST, nous pouvons faire la même chose avec l'API d'OpenAI. Explorons le processus de création d'un flux de travail Logic Apps qui utilise un modèle de discussion au lieu d'un modèle de complétion de texte. 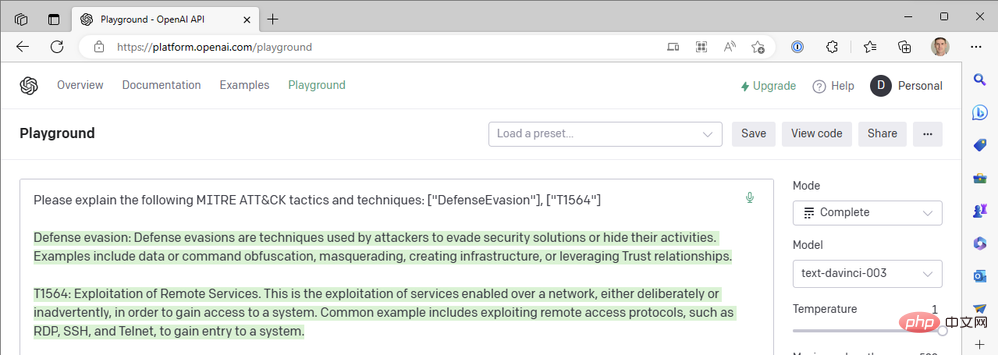
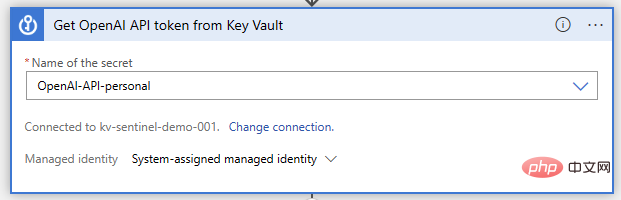
Key Vault pour stocker vos informations d'identification de l'API OpenAI 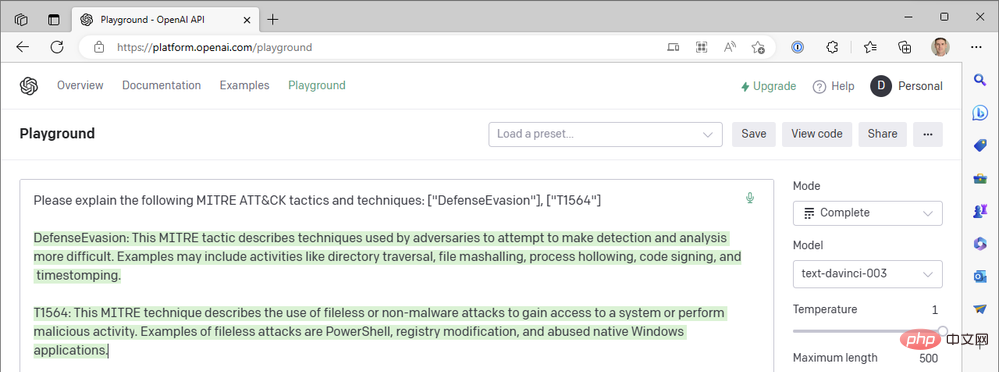
Maintenant, ouvrons notre Logic App Designer et commençons à créer des fonctionnalités. Comme auparavant, nous utilisons les déclencheurs d'événements Microsoft Sentinel. Nous exécuterons ensuite l'action Key Vault "Obtenir le secret", où nous spécifierons le nom secret où la clé API sera stockée :
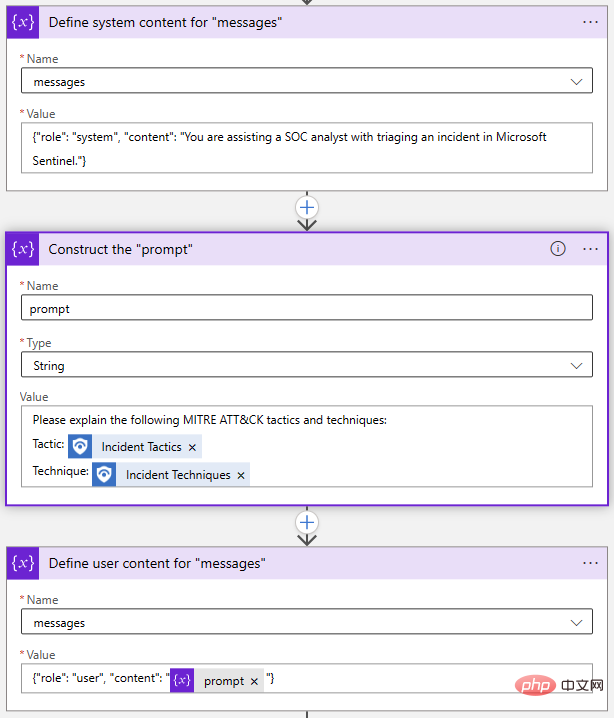
Ensuite, nous devons initialiser et définir certaines variables pour notre requête API. Ce n'est pas strictement nécessaire ; nous pourrions simplement écrire la requête dans notre action HTTP, mais cela facilitera grandement la modification ultérieure de l'invite et d'autres paramètres. Les deux paramètres requis dans l'appel de l'API OpenAI Chat sont "model" et "message". Initialisons donc une variable de chaîne pour stocker le nom du modèle et une variable de tableau pour le message.
- Le paramètre "message" est la principale entrée du modèle de chat. Il est construit comme un ensemble d'objets de message, chacun ayant un rôle, tel que « système » ou « utilisateur », et un contenu. Regardons un exemple du Playground :
-
L'objet System nous permet de définir le contexte comportemental du modèle d'IA pour cette session de chat. L'objet User est notre question et le modèle répondra avec un objet Assistant. Si nécessaire, nous pouvons inclure les réponses précédentes dans les objets Utilisateur et Assistant pour fournir au modèle d'IA un « historique des conversations ».
De retour dans notre Logic App Designer, j'ai utilisé deux actions « Ajouter à la variable du tableau » et une action « Initialiser la variable » pour créer le tableau « Messages » :

Encore une fois, tout cela fonctionne en une seule étape, mais J'ai choisi de faire exploser chaque objet séparément. Si je souhaite modifier mon invite, il me suffit de mettre à jour la variable Invite.
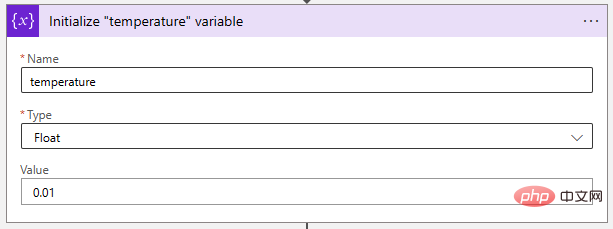
Ensuite, ajustons le paramètre de température à une valeur très faible pour rendre le modèle d'IA plus déterministe. Les variables "Float" sont idéales pour stocker cette valeur.
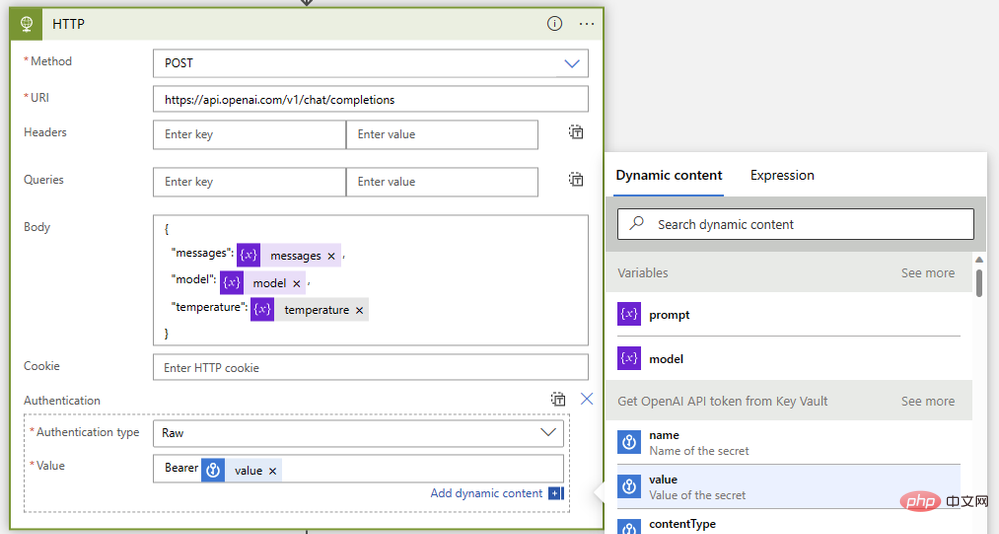
Enfin, rassemblons-les avec une opération HTTP comme celle-ci :
- Méthode : Mail
- Type : https://api.openai.com/v1/chat/completions
- Corps :
{"model": @{variables('model')},"messages": @{variables('messages')},"temperature": @{variables('temperature')}} - Authentification : Raw
- Valeur :
Bearer @{body('Get_OpenAI_API_token_from_Key_Vault')?['value']}
- Valeur :
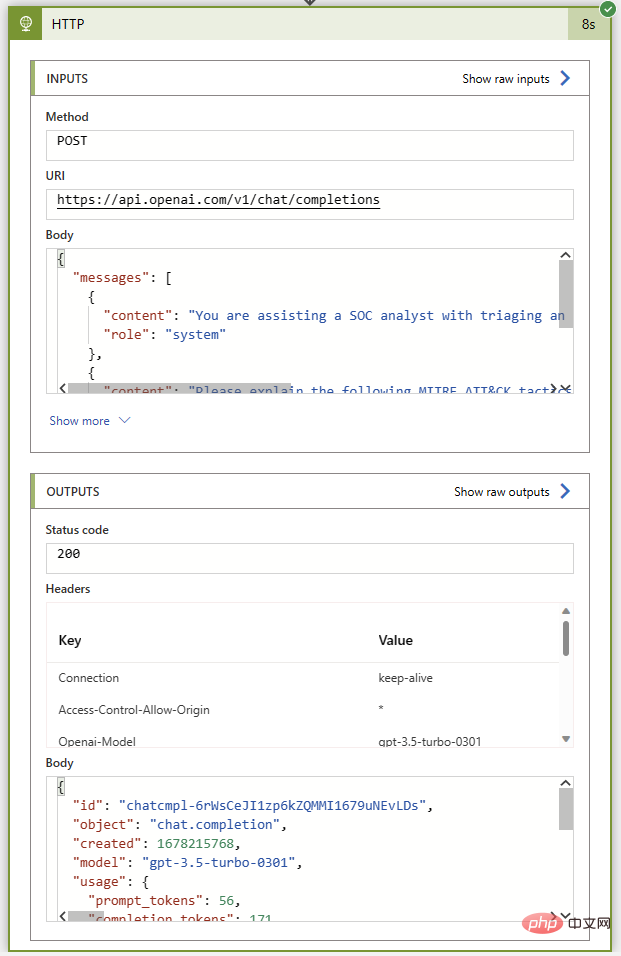
Comme avant, exécutons ce playbook sans aucune action de commentaire pour nous assurer que c'est fait avant de le reconnecter. Tout allait bien avant l'instance Sentinel. Si tout se passe bien, nous obtiendrons le code d'état 200 et un excellent résumé des tactiques et techniques de MITRE ATT&CK dans le message de l'assistant.
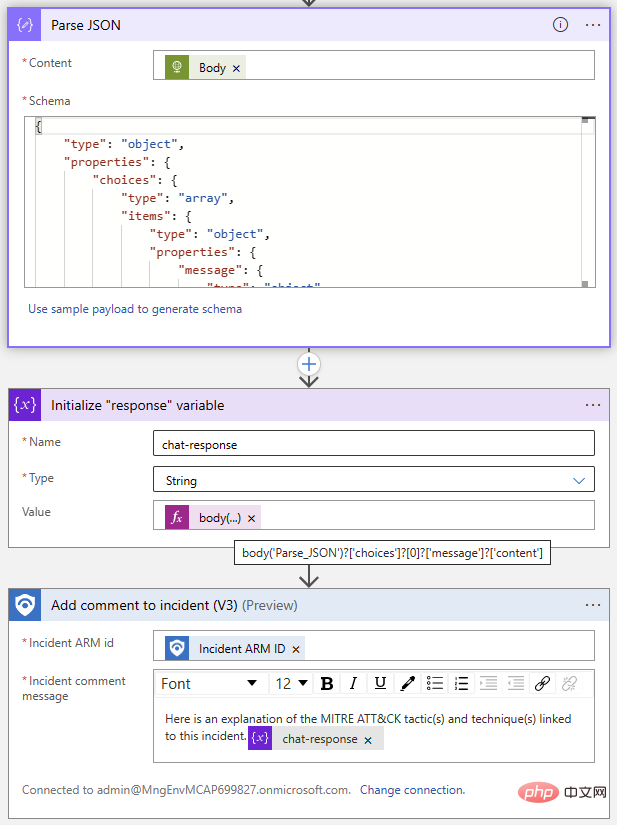
Vient maintenant la partie la plus facile : ajouter des commentaires d'événements à l'aide du connecteur Sentinel. Nous utiliserons l'opération Parse JSON pour analyser le corps de la réponse, puis initialiserons une variable avec le texte de la réponse ChatGPT. Puisque nous connaissons le format de réponse, nous savons que nous pouvons extraire la réponse de l'élément Choices à l'index 0 en utilisant l'expression suivante :
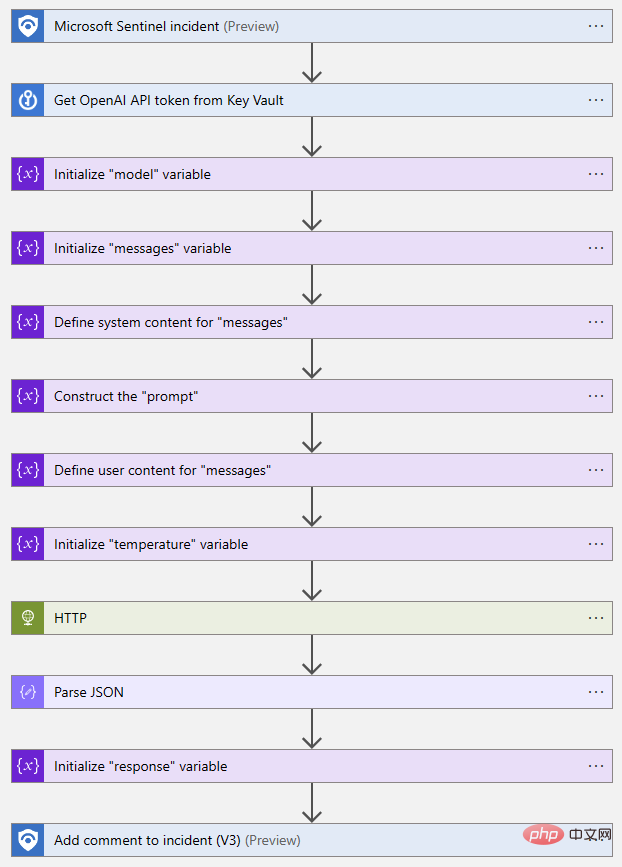
@{body('Parse_JSON')?['choices']?[0]?['message']?['content']}Voici une vue plongeante du flux Logic App terminé :
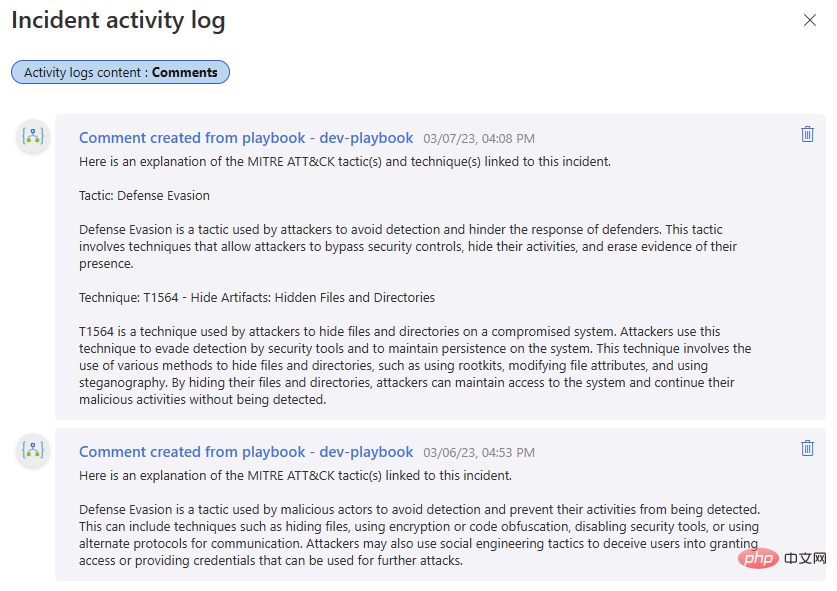
Essayons ! J'ai inclus les commentaires d'une itération précédente de ce playbook dans la première partie de cette série OpenAI et Sentinel - il est intéressant de comparer le résultat de la complétion de texte DaVinci avec l'interaction de chat du modèle Turbo.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Quels sont les établissements de formation d'ingénieur logiciel PHP ?
- Les applications Microsoft sur Windows 11 22H2 rencontrent des problèmes après la restauration du système
- Quel est le contenu de la balise canvas ?
- Quelle est la différence entre l'importation de style et le lien ?
- Que sont les éléments CSS au niveau des blocs et les éléments en ligne ?