
Maison >Périphériques technologiques >IA >Construction d'un graphe de connaissances automobile pour recommandation
Construction d'un graphe de connaissances automobile pour recommandation

- PHPzavant
- 2023-04-14 10:01:021227parcourir
Contexte
1. Introduction
Le concept de graphe de connaissances a été proposé pour la première fois par Google en 2012, dans le but de créer un moteur de recherche plus intelligent, et a commencé à être popularisé dans le monde universitaire et l'industrie après 2013. À l'heure actuelle, avec le développement rapide de la technologie de l'intelligence artificielle, les graphiques de connaissances ont été largement utilisés dans la recherche, la recommandation, la publicité, le contrôle des risques, la planification intelligente, la reconnaissance vocale, les robots et d'autres domaines.
2. État de développement
En tant que moteur technologique de base de l'intelligence artificielle, le graphe de connaissances peut atténuer le problème de l'apprentissage en profondeur en s'appuyant sur des données de formation massives et une puissance de calcul à grande échelle. de bonnes explications. Par conséquent, les grandes sociétés Internet du monde entier déploient activement leurs propres graphes de connaissances.
Par exemple, en 2013, Facebook a lancé Open Graph, utilisé pour la recherche intelligente sur les réseaux sociaux ; en 2014, Baidu a lancé le knowledge graph, qui était principalement utilisé dans les scénarios commerciaux de recherche, d'assistant et de ToB ; en 2015, Alibaba ; a lancé le Product Knowledge Graph, qui a été utilisé dans les guides d'achat front-end. Il joue un rôle clé dans la gouvernance de la plateforme et les services intelligents de questions et réponses ; le Tencent Cloud Knowledge Graph lancé par Tencent en 2017 aide efficacement la recherche financière, la prévision des risques d'entité et d'autres scénarios ; le Meituan Brain Knowledge Graph lancé par Meituan en 2018 a déjà été mis en œuvre dans plusieurs entreprises telles que les recommandations de recherche intelligentes et les opérations commerciales intelligentes.
3. Objectifs et avantages
À l'heure actuelle, les cartes de domaines sont principalement concentrées dans des domaines commerciaux tels que le commerce électronique, les soins médicaux et la finance, mais il manque des conseils systématiques pour la construction de réseaux sémantiques et cartes de connaissances sur les connaissances automobiles. Cet article prend comme exemple les connaissances dans le domaine automobile, en se concentrant sur les entités et les relations telles que les séries de voitures, les modèles, les concessionnaires, les fabricants, les marques, etc., pour fournir une idée pour créer une carte de domaine à partir de zéro, et détaille les étapes et méthodes pour créer une carte de connaissances et présente plusieurs applications typiques basées sur cette carte.
Parmi eux, la source de données est le site Web Autohome. Autohome est une plateforme de services automobiles composée de plusieurs sections telles que le guide d'achat, l'information, l'évaluation et le bouche-à-oreille. Elle a accumulé une grande quantité de données automobiles dans le domaine. dimensions de visualisation, d'achat et d'utilisation. En construisant un graphique de connaissances, nous organisons et exploitons le contenu centré sur l'automobile, fournissons des informations riches en connaissances, structurons et décrivons avec précision les intérêts, et prenons en charge plusieurs dimensions telles que le démarrage à froid, le rappel, le tri et l'affichage. des utilisateurs recommandés, apportant des effets à l'amélioration de l'entreprise.
2. Construction de graphiques
1. Défis de construction
Le graphe de connaissances est une représentation sémantique du monde réel, et son unité de base est le triplet de [entité-relation-entité] et [entité-attribut-valeur d'attribut] ( Triplet), les entités sont reliées entre elles par des relations, formant ainsi un réseau sémantique. La construction de graphiques présentera de plus grands défis, mais après la construction, elle peut montrer une riche valeur d'application dans plusieurs scénarios tels que l'analyse des données, le calcul des recommandations et l'interprétabilité.
Défis de la construction :
- Le schéma est difficile à définir : il n'existe actuellement aucun processus de construction d'ontologies unifié et mature, et la définition d'une ontologie dans des domaines spécifiques nécessite généralement la participation d'experts
- Types de données hétérogènes : généralement une connaissance ; le graphique est en cours de construction Les sources de données auxquelles vous serez confronté ne seront pas d'un seul type, y compris des données structurées, semi-structurées et non structurées. Face à des données avec des structures différentes, le transfert de connaissances et l'exploration sont plus difficiles
- Dépend des connaissances professionnelles : domaine ; Les graphes de connaissances s'appuient généralement sur de solides connaissances professionnelles, telles que les méthodes de maintenance correspondant aux modèles de véhicules, impliquant des connaissances dans de multiples domaines tels que la mécanique, l'électrotechnique, les matériaux, la mécanique, etc., et de telles relations ont des exigences élevées en matière de précision, et il est nécessaire pour garantir que les connaissances sont suffisamment correctes. Cela nécessite également une combinaison de meilleurs experts et d'algorithmes pour une construction de carte efficace.
- La qualité des données n'est pas garantie : l'extraction ou l'extraction d'informations nécessite une fusion des connaissances ou une vérification manuelle avant de pouvoir être utilisée comme connaissance ; pour aider les applications en aval.
Avantages :
- Représentation unifiée des connaissances du graphe de connaissances : former une vue unifiée en intégrant des données hétérogènes multi-sources
- Informations sémantiques riches : de nouveaux bords de relation peuvent être découverts grâce au raisonnement relationnel et des informations sémantiques plus riches peuvent être obtenu ;
- Forte interprétabilité : les chemins de raisonnement explicites sont plus interprétables que les résultats de l'apprentissage profond ;
- Haute qualité et accumulation continue : concevez des solutions de stockage de connaissances raisonnables basées sur des scénarios commerciaux pour réaliser la mise à jour et l'accumulation des connaissances.
2. Conception de l'architecture graphique
L'architecture technique est principalement divisée en trois couches : la couche de construction, la couche de stockage et la couche d'application. Le schéma d'architecture est le suivant :
- Couche de construction : inclut la définition de schéma, la transformation des données structurées, l'exploration de données non structurées et la fusion des connaissances ;
- Couche de stockage : comprend le stockage et l'indexation des connaissances, la mise à jour des connaissances, la gestion des métadonnées et prend en charge les requêtes de connaissances de base ;
- Couche de service : y compris raisonnement intelligent, requête structurée et autres couches d'applications en aval liées à l'entreprise.

3. Étapes et processus de construction spécifiques
Selon le schéma d'architecture, le processus de construction spécifique peut être divisé en quatre étapes : la conception de l'ontologie, l'acquisition de connaissances, l'entreposage des connaissances et la conception et l'utilisation des services d'application.
3.1 Construction d'ontologie
L'ontologie est un ensemble reconnu de concepts La construction d'ontologie fait référence à la construction de la structure de l'ontologie et du cadre de connaissances du graphe de connaissances basé sur la définition de l'ontologie.
Les principales raisons de construire un graphe basé sur une ontologie sont les suivantes :
- Des termes professionnels, des relations et des axiomes de domaine clairs Lorsqu'une donnée doit répondre aux objets et types d'entité prédéfinis par Schema, elle est autorisée. à mettre à jour avec les connaissances de la carte.
- Séparez les connaissances du domaine et les connaissances opérationnelles. Grâce à Schema, vous pouvez avoir une compréhension macroscopique de la structure du graphique et des définitions associées, sans avoir besoin de résumer et d'organiser à partir de triplets.
- Atteindre un certain degré de réutilisation des connaissances du domaine. Avant de construire une ontologie, vous pouvez d'abord vérifier si une ontologie pertinente a été construite, afin de pouvoir améliorer et développer sur la base de l'ontologie existante pour obtenir deux fois le résultat avec la moitié de l'effort.
- La définition basée sur l'ontologie peut éviter la situation dans laquelle le graphique est déconnecté de l'application, ou le coût de modification du schéma du graphique est plus élevé que celui de sa reconstruction. Par exemple, le stockage de « BMW x3 » et « 2022 BMW x3 » en tant qu'entités de voiture peut entraîner une confusion dans les relations d'instance et une mauvaise utilisation lorsqu'ils sont appliqués. Cette situation peut être résolue en convertissant « voiture » dans l'étape de conception de l'ontologie. subdivisant les sous-catégories « séries de voitures » et « modèles » en « entités de classe ».
Selon la couverture des connaissances, les graphiques de connaissances peuvent être divisés en graphiques de connaissances générales et en graphiques de connaissances de domaine. Actuellement, il existe de nombreux cas de graphiques de connaissances générales, tels que le Knowledge Graph de Google, Satori et Probase de Microsoft, etc. les graphiques de domaine sont les suivants : Cartes d'industries spécifiques telles que la finance et le commerce électronique. Les graphes généraux accordent plus d'attention à l'étendue et mettent l'accent sur l'intégration d'un plus grand nombre d'entités, mais n'ont pas d'exigences élevées en matière de précision. Il est difficile de raisonner et d'utiliser des axiomes, des règles et des contraintes à l'aide de bibliothèques d'ontologies tout en couvrant les connaissances des graphes de domaine. est plus petit, mais la profondeur des connaissances est plus profonde et se construit souvent dans un certain domaine professionnel.
Compte tenu des exigences de précision, la construction d'ontologies de domaine a tendance à être effectuée manuellement, comme la méthode représentative en sept étapes, la méthode IDEF5, etc. [1]. données structurées, effectuer une analyse d'ontologie, résumer et construire une ontologie qui répond à l'objectif et à la portée de l'application, puis optimiser et vérifier l'ontologie pour obtenir la première version de la définition de l'ontologie. Si vous souhaitez obtenir une ontologie de domaine plus large, vous pouvez la compléter à partir d'un corpus non structuré. Considérant que le processus de construction manuelle est relativement vaste, cet article prend le domaine automobile comme exemple pour fournir une méthode de construction d'ontologie semi-automatique. sont les suivants :
- Premièrement, une grande quantité de corpus automobile non structuré est collectée (comme des consultations automobiles, des articles de guides d'achat de voitures neuves, etc.) en tant qu'ensemble initial de concepts individuels, et des méthodes statistiques ou des modèles non supervisés (TF- IDF, BERT, etc.) sont utilisés pour obtenir des caractéristiques de caractères et de mots.
- Deuxièmement, l'algorithme de clustering BIRCH est utilisé pour diviser les concepts en hiérarchies, construire initialement la relation hiérarchique entre les concepts et effectuer une vérification et une induction manuelles des concepts ; les résultats du clustering pour obtenir les concepts équivalents, supérieurs et subordonnés de l'ontologie
- Enfin, utilisez le volume Le réseau neuronal cumulatif est combiné avec la méthode de supervision à distance pour extraire les relations d'entité des attributs de l'ontologie, et est complété par une identification manuelle des concepts de classes et d'attributs dans l'ontologie pour construire l'ontologie du domaine automobile.
La méthode ci-dessus peut utiliser efficacement des technologies d'apprentissage en profondeur telles que BERT pour mieux capturer les relations internes entre les corpus, utiliser le clustering pour construire hiérarchiquement chaque module de l'ontologie et le compléter par une intervention manuelle pour terminer rapidement et avec précision les préliminaires. ontologie. L'image ci-dessous est un diagramme schématique de la construction d'ontologies semi-automatisée :
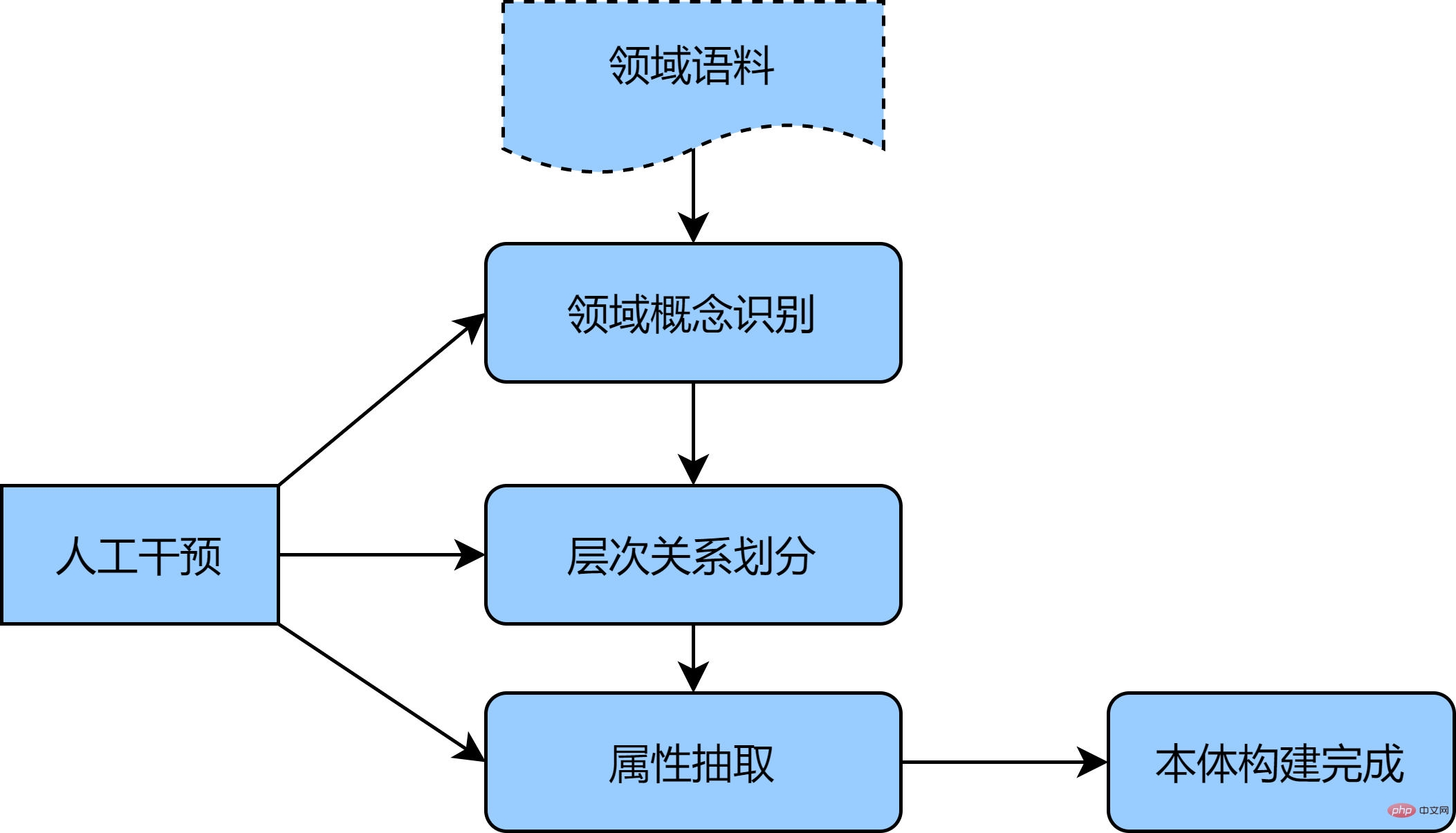
À l'aide de l'outil de construction d'ontologie Protégé [2], vous pouvez construire des classes de concepts, des relations, des attributs et des instances d'ontologie. est un exemple visuel de construction d'ontologie. :
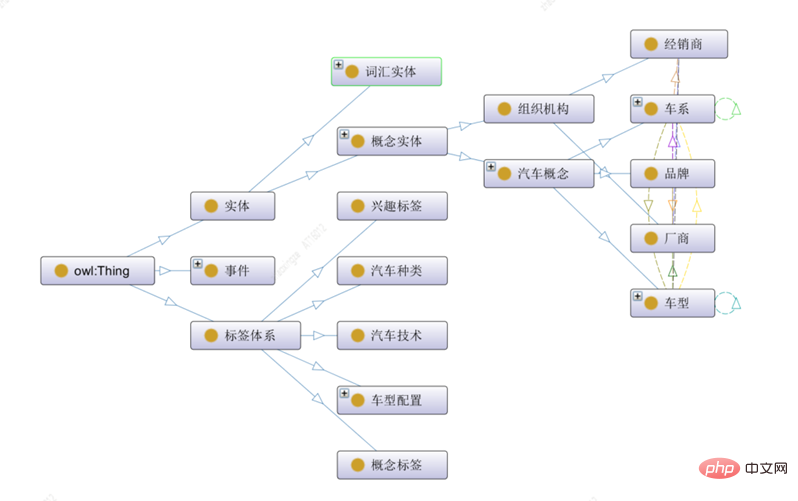
Cet article divise les concepts d'ontologie de haut niveau dans le domaine automobile en trois catégories, entités, événements et systèmes d'étiquettes :
1) La classe d'entité représente des entités conceptuelles avec des significations spécifiques, y compris les entités de vocabulaire et les entités automobiles, parmi lesquelles les entités automobiles incluent des types de sous-entités telles que les organisations et les concepts automobiles
2) Le système d'étiquettes représente le système d'étiquettes de chaque dimension ; , Y compris la classification de contenu, les balises de concept, les balises d'intérêt et autres balises décrites dans la dimension matérielle
3) La classe d'événements représente les faits objectifs d'un ou plusieurs rôles, et il existe une relation évolutive entre différents types d'événements ;
Protégé peut exporter différents types de fichiers de configuration de schéma, parmi lesquels le fichier de configuration de structure hibou.xml est comme indiqué dans la figure ci-dessous. Ce fichier de configuration peut être directement chargé et utilisé dans MYSQL et JanusGraph pour réaliser la création automatique de schéma.

3.2 Acquisition de connaissances
Les sources de données des graphiques de connaissances comprennent généralement trois types de structures de données, à savoir les données structurées, les données semi-structurées et les données non structurées. Pour différents types de sources de données, les technologies clés impliquées dans l'extraction des connaissances et les difficultés techniques à résoudre sont différentes.
3.2.1 Transformation des connaissances structurées
Les données structurées sont la source de connaissances la plus directe pour les graphiques. Elles peuvent être utilisées essentiellement par conversion préliminaire. Par rapport à d'autres types de données, le coût est le plus bas, donc les données généralement structurées le sont. priorité aux données graphiques. Les données structurées peuvent impliquer plusieurs sources de base de données et doivent généralement être converties à l'aide de méthodes ETL. ETL signifie extraire, transformer et charger. L'extraction consiste à lire les données de divers systèmes d'entreprise d'origine, ce qui est la prémisse de tout travail de conversion. convertir les données extraites selon des règles prédéfinies afin que les formats de données initialement hétérogènes puissent être unifiés ; le chargement consiste à importer les données converties progressivement ou entièrement dans les données comme prévu dans l'entrepôt.
Grâce au processus ETL ci-dessus, les données provenant de différentes sources peuvent être déposées dans des tables intermédiaires, facilitant ainsi le stockage ultérieur des connaissances. La figure suivante est un exemple de diagramme d'attributs d'entités de séries de voitures et de tables de relations :
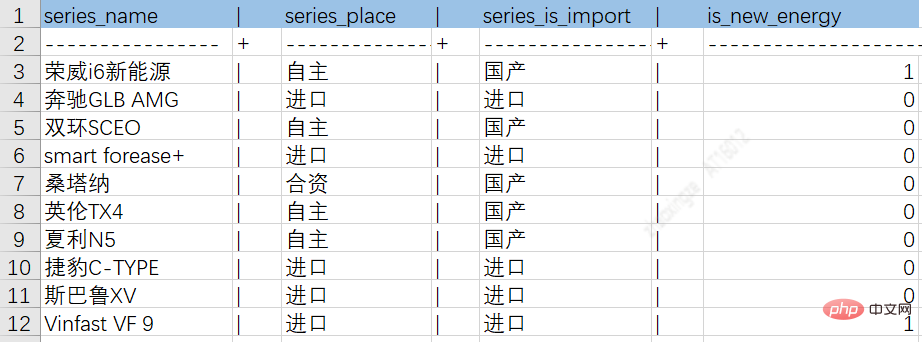
Tableau de relations entre les séries de voitures et les marques :
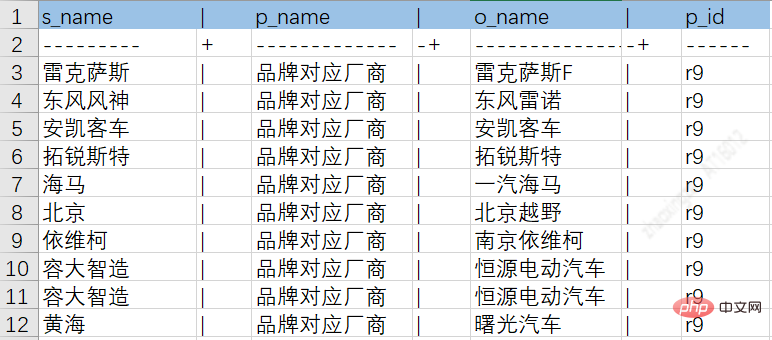
3.2.2 Extraction de connaissances non structurées - Triple extraction
En plus des tables de relations structurées Les données, il existe également une quantité massive d'informations de connaissances (triples) dans les données non structurées. D'une manière générale, la quantité de données non structurées dans une entreprise est bien plus importante que les données structurées. L'exploitation de connaissances non structurées peut considérablement étendre et enrichir le graphe de connaissances.
Défis de l'algorithme de triple extraction
Problème 1 : Au sein d'un même domaine, le contenu et le format des fichiers sont divers, nécessitant une grande quantité de données annotées, et le coût est élevé
Problème 2 : L'effet de migration entre Les domaines ne sont pas suffisants. L'expansion évolutive entre domaines est coûteuse. Les modèles sont essentiellement conçus pour des scénarios spécifiques dans des secteurs spécifiques. Si le scénario est modifié, l'effet sera considérablement réduit.
Idée de solution, le paradigme de Pré-entraînement + Finetune, pré-entraînement : la base lourde permet au modèle de « voir plus » et d'utiliser pleinement les documents non étiquetés à grande échelle et multi-industries pour former un pré-unifié. base de formation. Améliorer la capacité du modèle à représenter et à comprendre différents types de documents.
Réglage fin : algorithme léger de structuration de documents. Basé sur une pré-formation, un algorithme structuré léger orienté document est construit pour réduire les coûts d'étiquetage.
Méthode de pré-formation pour les documentsIl existe des modèles de pré-formation pour les documents si le texte est court, Bert peut encoder complètement l'intégralité du document alors que nos documents réels sont généralement plus longs, la plupart des valeurs d'attribut. qui doivent être extraits dépassent 1024 caractères, et l'encodage de Bert entraînera la troncature des valeurs d'attribut.
Visant les avantages et les inconvénients des méthodes de pré-formation sur les textes longsLa méthode Sparse Attention optimise le calcul de O(n2) à O(n) en optimisant l'auto-attention, ce qui améliore considérablement la longueur du texte saisi. . Bien que la longueur du texte du modèle ordinaire ait été augmentée de 512 à 4 096, il ne peut toujours pas résoudre complètement le problème de fragmentation du texte tronqué. Baidu a proposé ERNIE-DOC [3] en utilisant la méthode Recurrence Transformer, qui peut théoriquement modéliser un texte illimité. Étant donné que la modélisation nécessite la saisie de toutes les informations textuelles, cela prend beaucoup de temps.
Les deux méthodes de pré-formation ci-dessus basées sur un texte long ne prennent pas en compte les caractéristiques du document, telles que les informations spatiales (Spartial), visuelles (Visual) et autres. Et la PretrainTask basée sur la conception du texte est conçue pour le texte pur dans son ensemble, sans la conception de la structure logique du document.
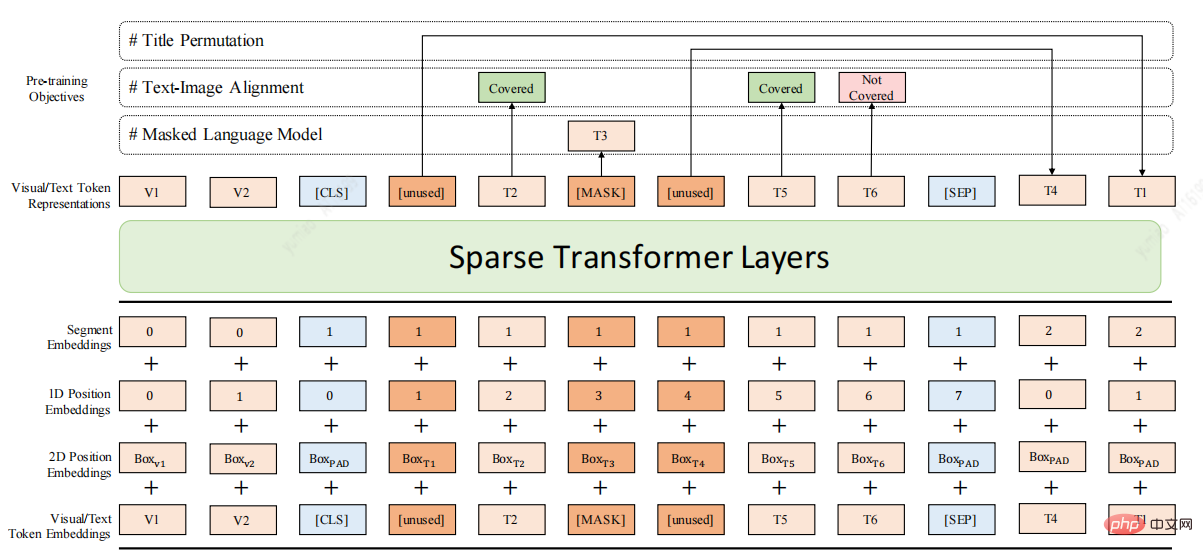
Compte tenu des lacunes ci-dessus, voici un document de pré-formation modèle DocBert [4], conception du modèle DocBert :
Utilisez des données de document non étiquetées à grande échelle (des millions de niveaux) pour la pré-formation et créez des tâches d'apprentissage auto-supervisées basées sur la sémantique du texte (Texte), les informations de mise en page (Mise en page) et les caractéristiques visuelles (Visuel) du document pour activer Le modèle comprend mieux la sémantique du document et les informations structurelles.
1.MLM prenant en compte la mise en page : tenez compte des informations sur la position et la taille de la police du texte dans le modèle de langage Mask pour obtenir une compréhension sémantique tenant compte de la mise en page du document.
2.Alignement texte-image : fusion des caractéristiques visuelles du document, reconstruction du texte masqué dans l'image, aidant le modèle à apprendre la relation d'alignement entre les différents modes de texte, de mise en page et d'image.
3.Permutation de titre : Construisez la tâche de reconstruction de titre de manière auto-supervisée pour améliorer la capacité du modèle à comprendre la structure logique du document.
4.Sparse Transformer Layers : utilisez la méthode Sparse Attention pour améliorer la capacité du modèle à traiter des documents longs.
3.2.3 Exploration de concepts, de balises de mots d'intérêt, liées aux séries et entités de voitures
En plus d'obtenir des triples à partir de textes structurés et non structurés, Autohome exploite également des balises de classification et de concept contenues dans des matériaux et des balises de mots-clés d'intérêt, et établir des associations entre les matériaux et les entités du véhicule, apportant de nouvelles connaissances au graphe de connaissances automobile. Ce qui suit présente une partie du travail de compréhension du contenu et de la réflexion effectuée par Autohome du point de vue de la classification, des balises conceptuelles et des balises de mots d'intérêt.
Le système de classification sert de base à la description du contenu et à la classification grossière des matériaux. Le système de contenu unifié établi est davantage basé sur une définition manuelle et est divisé par des modèles d'IA. En termes de méthodes de classification, nous utilisons l'apprentissage actif pour étiqueter les données difficiles à classer. Nous utilisons également l'amélioration des données, la formation contradictoire et la fusion de mots clés pour améliorer l'effet de classification.
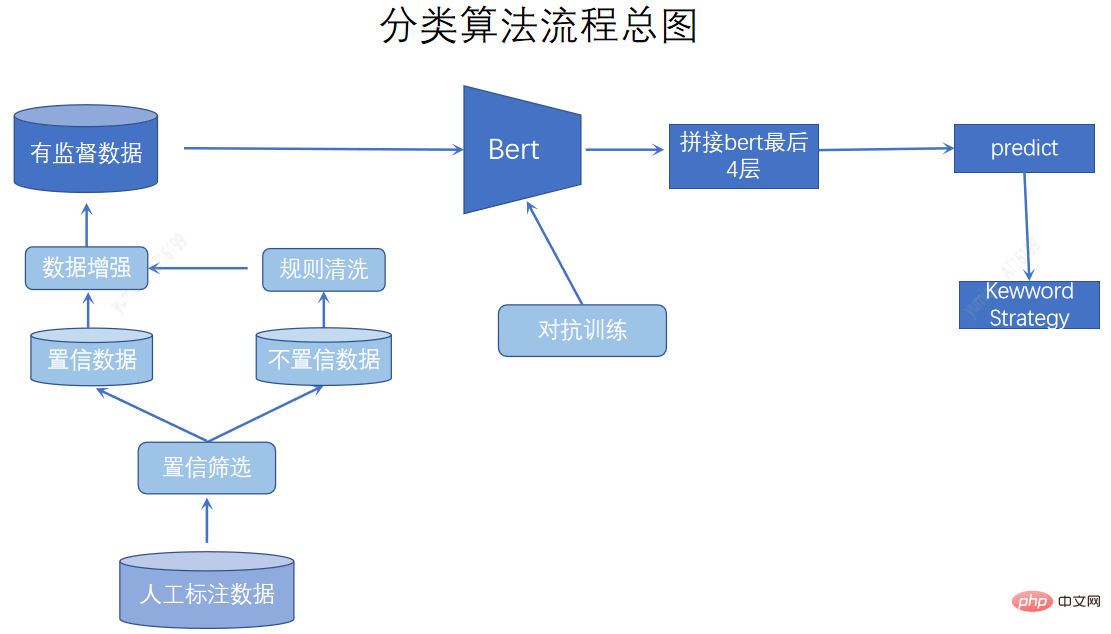
La granularité des balises conceptuelles se situe entre la classification et les balises de mots d'intérêt. Elle est plus fine que la granularité de la classification et plus complète que les mots d'intérêt dans la description des points d'intérêt. Nous avons établi trois dimensions : la vision automobile, la vision humaine et le contenu. vision. Les dimensions de l’étiquette sont enrichies et la granularité de l’étiquette est affinée. Les balises matérielles riches et spécifiques facilitent la recherche et la recommandation d'une optimisation de modèle basée sur les balises, et peuvent être utilisées pour la diffusion des balises afin d'attirer les utilisateurs et le trafic secondaire. L'exploration de balises conceptuelles combine l'utilisation de méthodes d'exploration automatique sur des données importantes telles que les requêtes et l'analyse de généralisation. Grâce à un examen manuel, nous obtenons un ensemble de balises conceptuelles et utilisons un modèle multi-étiquettes pour la classification.
Les balises de mots d'intérêt sont les balises les plus fines, mappées aux intérêts des utilisateurs et peuvent fournir de meilleures recommandations personnalisées basées sur les différentes préférences d'intérêt des utilisateurs. L'exploration de mots clés utilise une combinaison de plusieurs méthodes d'exploration de mots d'intérêt, y compris Keybert pour extraire les sous-chaînes clés, et combine TextRank, positionRank, singlerank, TopicRank, MultipartiteRank, etc. + des méthodes d'analyse syntaxique pour générer des mots candidats d'intérêt.
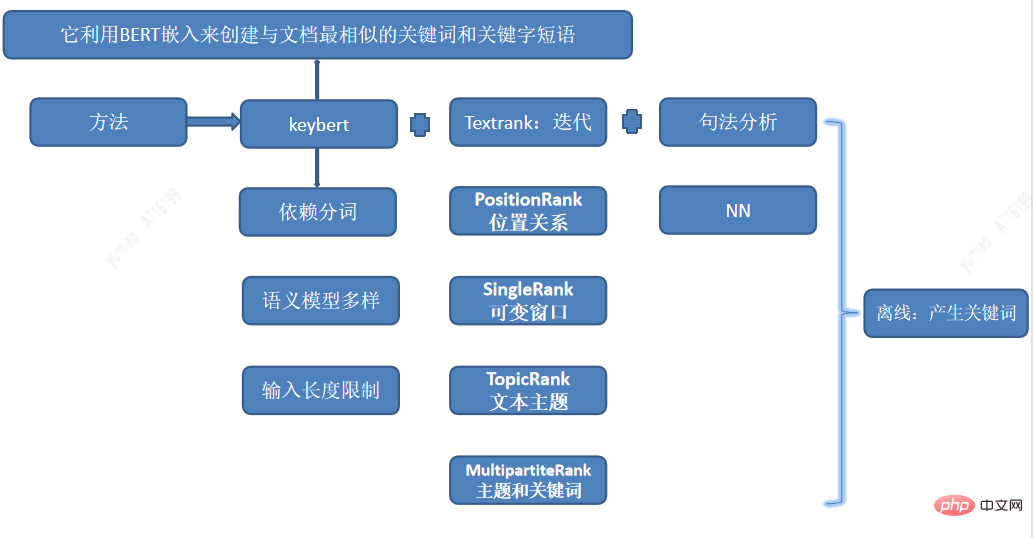
Les mots extraits ont une similarité relativement élevée, les synonymes doivent donc être identifiés et l'efficacité manuelle doit être améliorée. Par conséquent, nous effectuons également une identification automatique de la similarité sémantique via le clustering. Les fonctionnalités utilisées pour le clustering incluent word2vec, bert emding et d'autres fonctionnalités artificielles. Ensuite, en utilisant la méthode de clustering, et enfin par correction manuelle, nous avons généré hors ligne un lot de mots-clés de haute qualité.
Pour les balises avec des granularités différentes ou au niveau matériel, nous devons associer les balises aux voitures. Tout d'abord, nous calculons les balises de l'article titre, puis identifions les entités dans l'article titre et obtenons plusieurs balises - pseudo entité. tags , et enfin sur la base d'une grande quantité de corpus, les étiquettes avec une forte probabilité de cooccurrence seront marquées comme l'étiquette de l'entité. Grâce aux trois tâches ci-dessus, nous avons obtenu des labels riches et massifs. L'association de ces balises à des séries et entités de voitures enrichira considérablement notre carte automobile et établira des balises de voiture qui attireront l'attention des médias et des utilisateurs.
3.2.4 Amélioration de l'efficacité humaine :
Avec des échantillons de formation à plus grande échelle, comment obtenir une meilleure qualité de modèle, comment résoudre le coût élevé de l'étiquetage et le long cycle d'étiquetage sont devenus des problèmes urgents à résoudre. Premièrement, nous pouvons utiliser l’apprentissage semi-supervisé pour utiliser des données massives non étiquetées pour la pré-formation. Ensuite, une méthode d'apprentissage actif est utilisée pour maximiser la valeur des données annotées et sélectionner de manière itérative des échantillons à haute information pour l'annotation. Enfin, la supervision à distance peut être utilisée pour valoriser les connaissances existantes et découvrir la corrélation entre les tâches. Par exemple, après avoir obtenu la carte et le titre, vous pouvez utiliser la méthode de supervision à distance pour construire des données de formation NER basées sur la carte.
3.3 Stockage des connaissances
Les connaissances dans le graphe de connaissances sont représentées à travers la structure RDF, et son unité de base est un fait. Chaque fait est un triplet (S, P, O). Dans les systèmes actuels, selon différentes méthodes de stockage, le stockage des graphes de connaissances peut être divisé en stockage basé sur la structure de table RDF et stockage basé sur la structure de graphe d'attributs. Les galeries d'images sont principalement stockées à l'aide de structures de graphiques d'attributs. Les systèmes de stockage courants incluent Neo4j, JanusGraph, OritentDB, InfoGrid, etc.
Sélection de la base de données graphique
En comparant JanusGraph avec les bases de données graphiques traditionnelles telles que Neo4J, ArangoDB et OrientDB, nous avons finalement choisi JanusGraph comme base de données graphique pour le projet. Les principales raisons du choix de JanusGraph sont les suivantes :
- Basé sur. Apache 2 Le contrat de licence est open source et présente une bonne ouverture.
- Prend en charge l'utilisation du framework Hadoop pour l'analyse globale des graphiques et le traitement des graphiques par lots.
- Prend en charge le traitement de transactions simultanées importantes et le traitement des opérations graphiques. En ajoutant des machines pour étendre horizontalement les capacités de traitement des transactions de JanusGraph, des requêtes complexes sur de grands graphiques peuvent être traitées au niveau de la milliseconde.
- Prise en charge native du modèle de données de graphique de propriété actuellement populaire décrit par Apache TinkerPop.
- Prise en charge native du langage de traversée de graphes Gremlin.
- L'image suivante est une comparaison des bases de données graphiques traditionnelles :
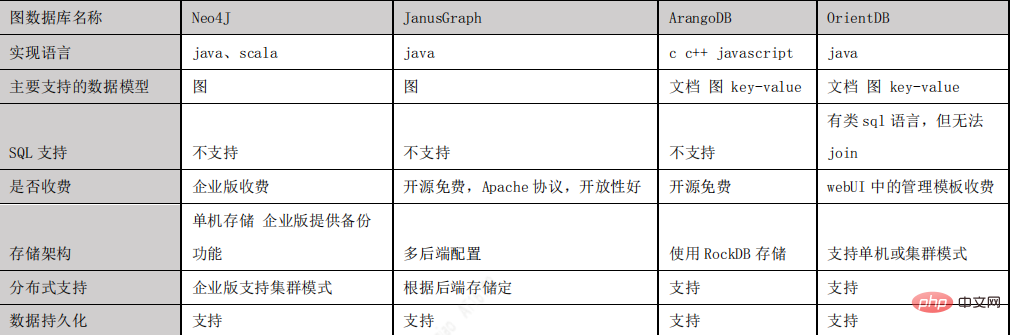
Introduction à Janusgraph
JanusGraph[5] est un moteur de base de données graphique. Il se concentre sur la sérialisation de graphiques compacts, la modélisation de données graphiques riches et l'exécution efficace des requêtes. La composition du schéma de la galerie peut être exprimée par la formule suivante :
schéma janusgraph = étiquette de sommet + étiquette de bord + clés de propriété
Il convient de noter ici que les clés de propriété sont généralement utilisées pour l'index du graphique.
Afin d'obtenir de meilleures performances de requête graphique, janusgraph a établi un index. L'index est divisé en index graphiques et index centrés sur les sommets. L'index graphique comprend un index composite et un index mixte.
L'index combiné est limité à la recherche égale. (L'index combiné n'a pas besoin de configurer un backend d'index externe, il est pris en charge par le backend de stockage principal (bien sûr, hbase, Cassandra, Berkeley peuvent également être configurés))
Exemple :
<span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">mgmt</span>.<span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">buildIndex</span>(<span style="color: rgb(102, 153, 0); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">'byNameAndAgeComposite'</span>, <span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">Vertex</span>.<span style="color: rgb(215, 58, 73); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">class</span>).<span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">addKey</span>(<span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">name</span>).<span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">addKey</span>(<span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">age</span>).<span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">buildCompositeIndex</span>() <span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">#构建一个组合索引“name</span><span style="color: rgb(215, 58, 73); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">-</span><span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">age”</span><br><span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">g</span>.<span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">V</span>().<span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">has</span>(<span style="color: rgb(102, 153, 0); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">'age'</span>, <span style="color: rgb(0, 92, 197); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">30</span>).<span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">has</span>(<span style="color: rgb(102, 153, 0); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">'name'</span>, <span style="color: rgb(102, 153, 0); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">'小明'</span>)<span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">#查找</span> <span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">名字为小明年龄30的节点</span>
L'index hybride nécessite ES comme backend index pour prendre en charge une requête multi-conditions autre qu'égale (la requête égale est également prise en charge, mais la requête égale et l'index combiné sont plus rapides). Selon que la segmentation des mots est nécessaire ou non, elle est divisée en recherche en texte intégral et recherche de chaînes
Modèle de stockage de données JanusGraph
Comprendre la façon dont Janusgraph stocke les données nous aidera à mieux utiliser la bibliothèque. JanusGraph stocke les graphiques sous forme de liste de contiguïté, ce qui signifie que le graphique est stocké sous la forme d'une collection de sommets et de leurs listes de contiguïté.
La liste de contiguïté d'un sommet contient toutes les arêtes incidents (et attributs) du sommet.
JanusGraph stocke chaque liste de contiguïté sous forme de ligne dans le backend de stockage sous-jacent. L'ID de sommet (64 bits) (attribué de manière unique à chaque sommet par JanusGraph) est la clé pointant vers la ligne contenant la liste de contiguïté du sommet.
Chaque bord et attribut sont stockés sous forme de cellule distincte dans la ligne, permettant une insertion et une suppression efficaces. Par conséquent, le nombre maximum de cellules autorisées par ligne dans un backend de stockage particulier correspond également au degré maximum de sommets que JanusGraph peut prendre en charge pour ce backend.
Si le backend de stockage prend en charge l'ordre des clés, la liste de contiguïté sera triée par identifiant de sommet et JanusGraph peut attribuer des identifiants de sommet pour partitionner efficacement le graphique. Attribuez des identifiants de sorte que les sommets fréquemment visités aient des identifiants avec de petites différences absolues.
3.4 GraphQuery Service
Janusgraph utilise le langage gremlin pour la recherche de graphiques. Nous fournissons un service de requête de graphiques unifié. Les utilisateurs externes n'ont pas besoin de se soucier de l'implémentation spécifique du langage gremlin et d'utiliser une interface commune pour les requêtes. Nous le divisons en trois interfaces : une interface de recherche conditionnelle, une requête sortante centrée sur le nœud et une interface de requête de chemin inter-nœuds. Voici plusieurs exemples de mise en œuvre de Gremlin :
- Recherche conditionnelle : Requête d'environ 100 000 voitures avec le volume de ventes le plus élevé :
<span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">g</span>.<span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">V</span>().<span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">has</span>(<span style="color: rgb(102, 153, 0); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">'price'</span>,<span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">gt</span>(<span style="color: rgb(0, 92, 197); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">8</span>)).<span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">has</span>(<span style="color: rgb(102, 153, 0); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">'price'</span>,<span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">lt</span>(<span style="color: rgb(0, 92, 197); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">12</span>)).<span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">order</span>().<span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">by</span>(<span style="color: rgb(102, 153, 0); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">'sales'</span>,<span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">desc</span>).<span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">valueMap</span>().<span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">limit</span>(<span style="color: rgb(0, 92, 197); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">1</span>)
Sortie :
<span style="color: rgb(215, 58, 73); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">==></span>{<span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">name</span><span style="color: rgb(215, 58, 73); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">=</span>[<span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">xuanyi</span>], <span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">price</span><span style="color: rgb(215, 58, 73); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">=</span>[<span style="color: rgb(0, 92, 197); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">10</span>], <span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">sales</span><span style="color: rgb(215, 58, 73); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">=</span>[<span style="color: rgb(0, 92, 197); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">45767</span>]}
Sylphy a le volume de ventes le plus élevé, soit 45767
- Avec des nœuds Requête vers l'extérieur à partir du centre : Interrogez le nœud à 2 degrés centré sur Xiao Ming
<span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">g</span>.<span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">V</span>(<span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">xiaoming</span>).<span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">repeat</span>(<span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">out</span>()).<span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">times</span>(<span style="color: rgb(0, 92, 197); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">2</span>).<span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">valueMap</span>()
- Interrogez le chemin entre les nœuds : Recommandez deux articles à Xiao Ming, ces deux articles sont introduits séparément C'est Corolle et Sylphy. Interrogez les chemins de Xiao Ming et ces deux articles :
<span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">g</span>.<span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">V</span>(<span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">xiaoming</span>).<span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">repeat</span>(<span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">out</span>().<span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">simplePath</span>()).<span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">until</span>(<span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">or</span>(<span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">has</span>(<span style="color: rgb(102, 153, 0); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">"car"</span>,<span style="color: rgb(102, 153, 0); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">'name'</span>, <span style="color: rgb(102, 153, 0); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">'kaluola'</span>),<span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">has</span>(<span style="color: rgb(102, 153, 0); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">"car"</span>, <span style="color: rgb(102, 153, 0); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">'name'</span>,<span style="color: rgb(102, 153, 0); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">'xuanyi'</span>))).<span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">path</span>().<span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">by</span>(<span style="color: rgb(102, 153, 0); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">"name"</span>)
Sortie
<span style="color: rgb(215, 58, 73); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">==></span><span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">path</span>[<span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">xiaoming</span>, <span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">around</span> <span style="color: rgb(0, 92, 197); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">10</span><span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">w</span>, <span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">kaluola</span>]<br><span style="color: rgb(215, 58, 73); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">==></span><span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">path</span>[<span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">xiaoming</span>, <span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">around</span> <span style="color: rgb(0, 92, 197); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">10</span><span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">w</span>, <span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">xuanyi</span>]
On constate qu'il y a un nœud "environ 100 000" entre Xiao Ming et ces deux articles
3. Graphique de connaissances dans les applications recommandées
Il existe une grande quantité de données non européennes dans le graphique de connaissances. Les applications de recommandation basées sur KG utilisent efficacement des données non européennes pour améliorer la précision du système de recommandation, permettant ainsi le système de recommandation pour obtenir ce que les systèmes traditionnels ne peuvent pas obtenir. Les recommandations basées sur KG peuvent être divisées en trois catégories, basées sur la technologie de représentation KG (KGE), la méthode basée sur le chemin et le réseau neuronal graphique. Ce chapitre présentera les applications et les articles de KG sous trois aspects : le démarrage à froid, la raison et le classement dans les systèmes de recommandation.
3.1 Application du graphe de connaissances pour recommander un démarrage à froid
Le graphe de connaissances peut modéliser les relations d'ordre supérieur cachées dans KG à partir des interactions utilisateur-élément, ce qui peut bien résoudre la rareté des données causée par les utilisateurs invoquant un nombre limité de propriétés de comportement. , et peut être appliqué pour résoudre le problème du démarrage à froid. Il existe également des études connexes sur cette question dans l’industrie.
Sang et al. [6] ont proposé une méthode d'interaction neuronale à double canal appelée Knowledge Graph Enhanced Residual Recurrent Neural Collaborative Filtering (KGNCF-RRN), qui exploite les dépendances relationnelles à long terme du contexte KG et des interactions utilisateur-élément recommandées. .
(1) Pour le canal d'interaction contextuelle KG, un réseau récurrent résiduel (RRN) est proposé pour construire une intégration de chemin basée sur le contexte, et l'apprentissage résiduel est intégré dans le réseau neuronal récurrent (RNN) traditionnel pour coder efficacement le long terme. de KG Dépendance relationnelle. Les réseaux d’auto-attention sont ensuite appliqués aux intégrations de chemins pour capturer l’ambiguïté des divers comportements d’interaction des utilisateurs.
(2) Pour le canal d'interaction utilisateur-élément, les intégrations d'utilisateurs et d'éléments sont saisies dans le nouveau graphique d'interaction 2D.
(3) Enfin, en plus de la matrice d'interaction neuronale à double canal, un réseau neuronal convolutif est utilisé pour apprendre la corrélation complexe entre les utilisateurs et les éléments. Cette méthode peut capturer des informations sémantiques riches et également capturer des relations implicites complexes entre les utilisateurs et les éléments à recommander.
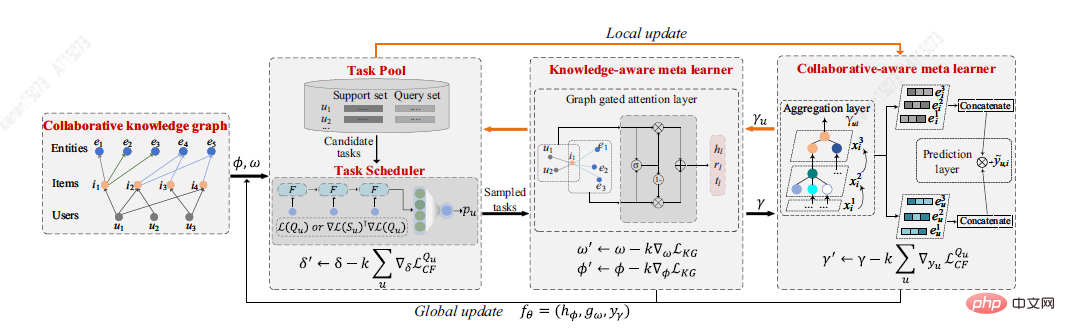
Du Y et al. [7] ont proposé une nouvelle solution au problème du démarrage à froid basée sur le cadre de méta-apprentissage MetaKG, comprenant un méta-apprenant collaboratif et un méta-apprenant conscient des connaissances, capturant les préférences de l'utilisateur et les connaissances de démarrage à froid de l'entité. . La tâche d'apprentissage collaborative du méta-apprenant vise à regrouper la représentation des connaissances préférée de chaque utilisateur. En revanche, la tâche d’apprentissage du méta-apprenant conscient des connaissances consiste à généraliser globalement différentes représentations de connaissances préférées par l’utilisateur. Sous la direction de deux apprenants, MetaKG peut capturer efficacement des relations collaboratives et des représentations sémantiques de haut niveau, et peut facilement s'adapter aux scénarios de démarrage à froid. En outre, l'auteur a également conçu une tâche adaptative capable de sélectionner de manière adaptative les informations KG à des fins d'apprentissage afin d'éviter que le modèle ne soit interféré par les informations de bruit. L'architecture MetaKG est présentée dans la figure ci-dessous.
3.2 Application du graphe de connaissances dans la génération de raisons de recommandation
Les raisons de recommandation peuvent améliorer l'interprétabilité du système de recommandation, permettant aux utilisateurs de comprendre le processus de calcul de génération des résultats de recommandation, et peuvent également expliquer les raisons de la popularité des articles. Les utilisateurs comprennent le principe de génération de résultats recommandés via des raisons de recommandation, ce qui peut renforcer la confiance des utilisateurs dans les résultats recommandés du système et les rendre plus tolérants aux résultats incorrects en cas d'erreurs de recommandation.
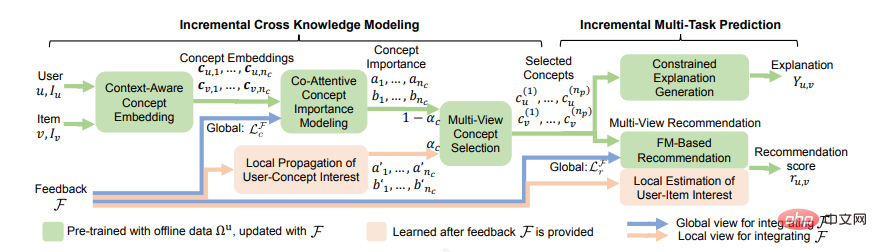
Les premières recommandations interprétables étaient basées sur des modèles. L'avantage des modèles est qu'ils garantissent une lisibilité et une grande précision. Cependant, les modèles doivent être triés manuellement et ils ne sont pas très généraux, ce qui donne aux utilisateurs un sentiment de répétitivité. Plus tard, une forme libre qui ne nécessitait pas de préréglages a été développée et un graphique de connaissances a été ajouté, utilisant l'un des chemins comme explication, et avec des annotations, certaines méthodes génératives ont été combinées avec chaque point ou bord sélectionné. dans le modèle se trouve un processus de raisonnement qui peut être démontré à l'utilisateur. Récemment, Chen Z [8] et d'autres ont proposé un cadre d'apprentissage multitâche incrémentiel ECR, qui peut réaliser une collaboration étroite entre la prédiction des recommandations, la génération d'explications et l'intégration des commentaires des utilisateurs. Il se compose de deux parties. La première partie, Modélisation incrémentielle des connaissances croisées, apprend les connaissances croisées transférées dans la tâche de recommandation et la tâche d'explication, et explique comment utiliser les connaissances croisées à mettre à jour en utilisant l'apprentissage incrémentiel. La deuxième partie, prédiction multitâche incrémentale, explique comment générer des explications basées sur des connaissances croisées et comment prédire les scores de recommandation en fonction des connaissances croisées et des commentaires des utilisateurs.
3.3 Application du graphique de connaissances dans le tri des recommandations
KG peut établir une interaction entre les éléments utilisateur en reliant les éléments avec différents attributs et combiner le graphique des éléments uesr et KG en une seule grande image. relations entre les éléments. La méthode de recommandation traditionnelle consiste à modéliser le problème comme une tâche d'apprentissage supervisé. Cette méthode ignore la relation intrinsèque entre les éléments (telle que la relation de produit concurrentiel entre Camry et Accord) et ne peut pas obtenir de signaux synergiques du comportement de l'utilisateur. Ce qui suit présente deux articles sur l'application de KG dans le classement des recommandations.
Wang[9] et d'autres ont conçu l'algorithme KGAT. Premièrement, ils utilisent GNN pour propager et mettre à jour l'intégration de manière itérative, afin de pouvoir capturer rapidement les connexions d'ordre élevé. Deuxièmement, ils utilisent le mécanisme d'attention lors de l'agrégation pour apprendre les caractéristiques de. le poids de chaque voisin pendant le processus de propagation reflète l'importance des connexions d'ordre supérieur ; enfin, N représentations implicites de l'élément utilisateur sont obtenues grâce à des mises à jour de propagation d'ordre N, et différentes couches représentent différents ordres d'informations de connexion. KGAT peut capturer des connexions d’ordre supérieur plus riches et non spécifiques.
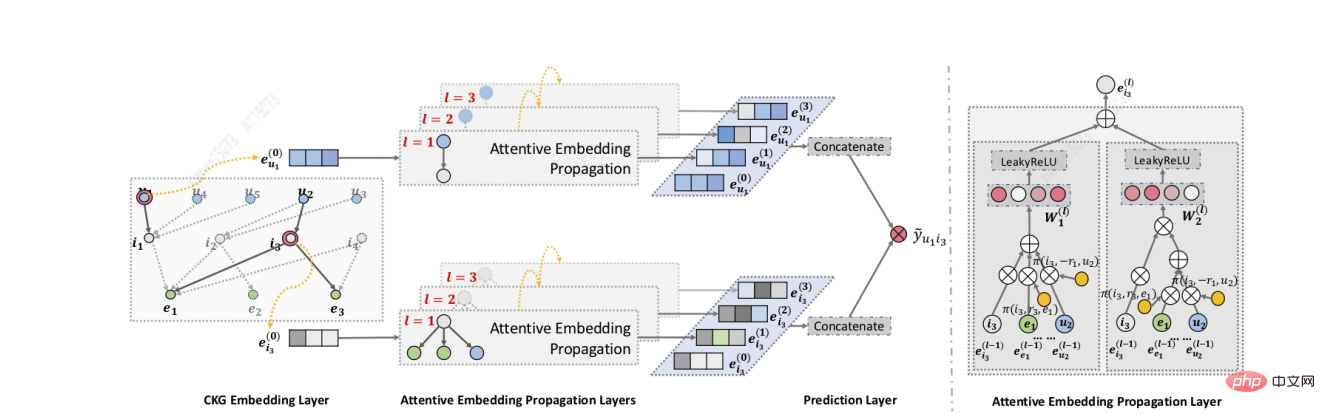
Zhang[20] et d'autres ont proposé le modèle RippleNet, dont l'idée clé est la propagation des intérêts : RippleNet utilise les intérêts historiques de l'utilisateur comme un ensemble de graines dans KG, puis étend les intérêts de l'utilisateur vers l'extérieur le long des connexions. du KG, formant la répartition des intérêts de l’utilisateur sur KG. Le plus grand avantage de RippleNet est qu'il peut automatiquement extraire les chemins possibles depuis les éléments sur lesquels les utilisateurs ont cliqué dans l'historique jusqu'aux éléments candidats, sans aucune conception manuelle de méta-chemins ou de méta-graphiques.
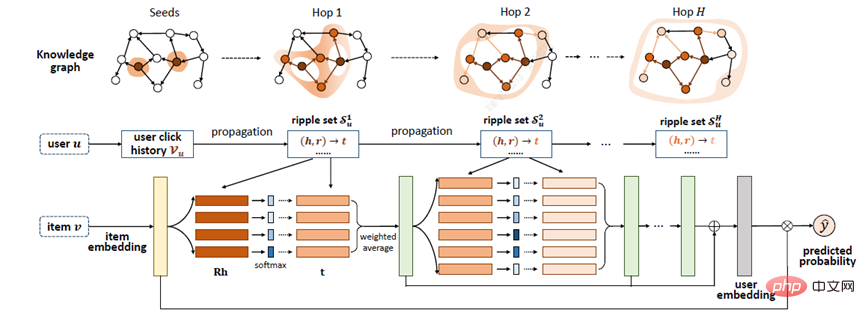
RippleNet prend l'utilisateur U et l'élément V en entrée et génère la probabilité prédite que l'utilisateur U clique sur l'élément V. Pour l'utilisateur U, prenant son intérêt historique V_{u} comme graine, on peut voir sur la figure que le point de départ initial est deux, puis continue de se propager aux environs. Étant donné itemV et chaque triple gauche (h_{i},r_{i},t_{i}right) dans l'ensemble d'ondulations à 1 saut V_{u_{}^{1}} de l'utilisateur U, en comparant V Attribuer les probabilités associées aux nœuds h_{i} et aux relations r_{i} en triplets.
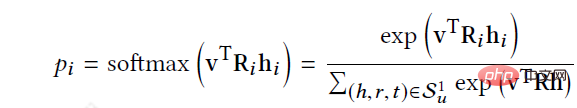
Après avoir obtenu les probabilités pertinentes, multipliez les queues des triplets dans V_{u_{}^{1}} par les probabilités pertinentes correspondantes pour une somme pondérée pour obtenir l'intérêt historique de premier ordre de l'utilisateur U par rapport à V En réponse, l'intérêt de l'utilisateur est transféré de V_{u} à o_{u}^{1}, qui peut être calculé comme o_{u}^{2}, o_{u}^{3}... o_{u}^{n }, puis les caractéristiques de U concernant l'élément V peuvent être calculées pour fusionner toutes ses réponses à la commande.
IV. Résumé
Pour résumer, nous nous sommes principalement concentrés sur les recommandations, avons présenté le processus détaillé de construction de graphiques et analysé les difficultés et les défis impliqués. En même temps, il résume également de nombreux travaux importants et donne des solutions, des idées et des suggestions spécifiques. Enfin, l'application incluant le graphe de connaissances est présentée, en particulier le rôle et l'utilisation du graphe de connaissances dans le domaine de la recommandation, y compris le démarrage à froid, l'interprétabilité et le classement des rappels.
Citation :
[1] Kim S, Oh S G. Extraction et application de critères d'évaluation pour l'évaluation de la qualité des ontologies[J]. Library Hi Tech, 2019.
[2]Protégé : https://www.php.cn/link/9d405c24be657bbf7a5244815a908922
[3] Ding S , Shang J , Wang S , et al ERNIE-DOC : Le transformateur de modélisation rétrospective de documents longs[J].
[4]DocBert,[1] Adhikari A, Ram A, Tang R, et al. 2019.
[5]JanusGraph,https://www.php.cn/link/fc0de4e0396fff257ea362983c2dda5a
[6] Sang L, Xu M, Qian S et al. filtrage collaboratif neuronal avec réseau récurrent résiduel[J]. Neurocomputing, 2021, 454 : 417-429.
[7] Du Y , Zhu X , Chen L , et al. Recommandation [J] arXiv e-prints, 2022.
[8] Chen Z , Wang X , Xie X , et al. Vers une recommandation conversationnelle explicable [C]// Vingt-neuvième Conférence internationale conjointe sur l'intelligence artificielle et le dix-septième Pacifique. Conférence internationale Rim sur l'intelligence artificielle {IJCAI-PRICAI-20. 2020.
[9] Wang X, He X, Cao Y, et al. KGAT : Knowledge Graph Attention Network for Recommendation[J, 2019.
]. [10]Wang H, Zhang F, Wang J et al. RippleNet : propagation des préférences utilisateur sur le Knowledge Graph pour les systèmes de recommandation [J, 2018.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Tendances technologiques à surveiller en 2023
- Comment l'intelligence artificielle apporte un nouveau travail quotidien aux équipes des centres de données
- L'intelligence artificielle ou l'automatisation peuvent-elles résoudre le problème de la faible efficacité énergétique des bâtiments ?
- Co-fondateur d'OpenAI interviewé par Huang Renxun : les capacités de raisonnement de GPT-4 n'ont pas encore atteint les attentes
- Bing de Microsoft surpasse Google en termes de trafic de recherche grâce à la technologie OpenAI