
Maison >Périphériques technologiques >IA >Utilisation de la visualisation logicielle et de l'apprentissage par transfert dans la prévision des défauts logiciels
Utilisation de la visualisation logicielle et de l'apprentissage par transfert dans la prévision des défauts logiciels

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBavant
- 2023-04-13 14:43:031638parcourir
La motivation de l'article est d'éviter la représentation intermédiaire du code source, de représenter le code source sous forme d'image et d'extraire directement les informations sémantiques du code pour améliorer les performances de prédiction des défauts.
Tout d’abord, consultez l’exemple de motivation ci-dessous. Bien que les deux exemples de File1.java et File2.java contiennent 1 instruction if, 2 instructions for et 4 appels de fonction, la sémantique et les caractéristiques structurelles du code sont différentes. Afin de vérifier si la conversion du code source en images peut aider à distinguer différents codes, l'auteur a mené une expérience : mapper le code source en pixels selon le nombre décimal ASCII des caractères, les organiser dans une matrice de pixels et obtenir une image de le code source. L'auteur souligne qu'il existe des différences entre les différentes images de code source.

Fig. 1 Exemple de motivation
Les principales contributions de l'article sont les suivantes :
Convertir le code en image et en extraire des informations sémantiques et structurelles
Proposer un cadre de bout en bout qui ; combine un mécanisme d'auto-attention et un apprentissage de migration pour mettre en œuvre la prédiction des défauts.
Le cadre de modèle proposé dans l'article est présenté dans la figure 2, qui est divisée en deux étapes : la visualisation du code source et la modélisation de l'apprentissage par transfert profond.
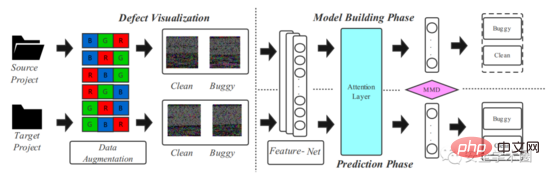
Fig. 2 Framework
1. Visualisation du code source
L'article convertit le code source en 6 images et le processus est illustré dans la figure 3. Convertissez les codes ASCII décimaux des caractères du code source en vecteurs entiers non signés de 8 bits, organisez ces vecteurs par lignes et colonnes et générez une matrice d'image. Les entiers 8 bits correspondent directement aux niveaux de gris. Afin de résoudre le problème du petit ensemble de données original, l'auteur a proposé dans l'article une méthode d'expansion de l'ensemble de données basée sur l'amélioration des couleurs : les valeurs des trois canaux de couleur de R, V et B sont disposées et combinés pour générer 6 images couleur. Cela semble assez déroutant ici. Après avoir modifié la valeur du canal, les informations sémantiques et structurelles devraient changer, n'est-ce pas ? Mais l’auteur l’explique dans une note de bas de page, comme le montre la figure 4.
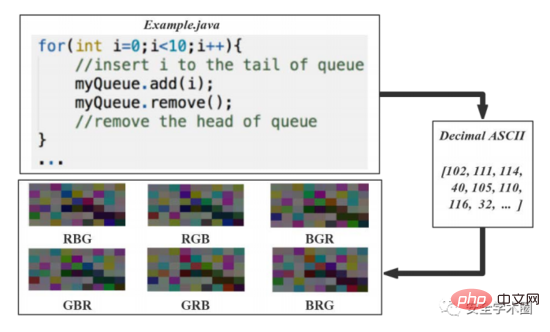
Fig. 3 Processus de visualisation du code source

Fig. 4 Note de bas de page 2
2. Modélisation de l'apprentissage par transfert profond
L'article utilise le réseau DAN pour capturer les informations sémantiques et structurelles du code source. Afin d'améliorer la capacité du modèle à exprimer des informations importantes, l'auteur a ajouté une couche Attention à la structure DAN originale. Le processus de formation et de test est illustré à la figure 5, dans laquelle conv1-conv5 provient d'AlexNet et quatre couches entièrement connectées fc6-fc9 sont utilisées comme classificateurs. L'auteur a mentionné que pour un nouveau projet, la formation d'un modèle d'apprentissage profond nécessite une grande quantité de données étiquetées, ce qui est difficile. Par conséquent, l'auteur a d'abord formé un modèle pré-entraîné sur ImageNet 2012 et a utilisé les paramètres du modèle pré-entraîné comme paramètres initiaux pour affiner toutes les couches convolutives, réduisant ainsi la différence entre les images de code et les images dans ImageNet 2012.
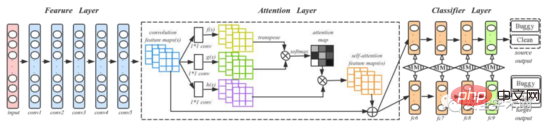
Fig. 5 Processus de formation et de test
3. Formation et prédiction du modèle
Générez des images de code pour le code étiqueté dans le projet Source et le code non étiqueté dans le projet Target, et envoyez-les au modèle. en même temps ; ils sont partagés entre la couche convolutionnelle et la couche d’attention pour extraire leurs caractéristiques respectives. Calculez MK-MDD (Multi Kernel Variant Maximum Mean Discrepancy) entre la source et la cible dans la couche entièrement connectée. Puisque Target n’a pas d’étiquette, l’entropie croisée n’est calculée que pour Source. Le modèle est entraîné le long de la fonction de perte en utilisant une descente de gradient stochastique en mini-lots. Pour chaque
Dans la partie expérimentale, l'auteur a sélectionné tous les projets Java open source dans l'entrepôt de données PROMISE et a collecté leurs numéros de version, leurs noms de classe et s'il y avait des balises de bug. Téléchargez le code source depuis github en fonction du numéro de version et du nom de la classe. Enfin, les données de 10 projets Java ont été collectées. La structure de l'ensemble de données est illustrée à la figure 6.
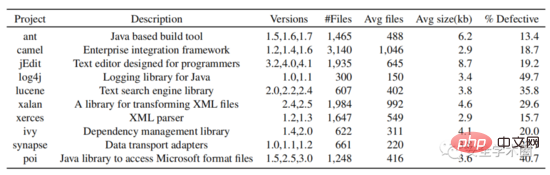
Fig. 6 Structure de l'ensemble de données
Pour la prédiction des défauts intra-projet, l'article sélectionne le modèle de base suivant à des fins de comparaison :

Pour la prédiction des défauts entre projets, l'article sélectionne le modèle de base suivant à des fins de comparaison :

Pour résumer, même s'il s'agissait d'un article il y a deux ans, l'idée est encore relativement nouvelle et évite une série de représentations intermédiaires de code telles que comme AST. Convertissez le code directement en images pour extraire des fonctionnalités. Mais je suis toujours confus. L'image convertie à partir du code contient-elle vraiment les informations sémantiques et structurelles du code source ? Cela ne semble pas très explicable, haha. Nous devrons faire une analyse expérimentale plus tard.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Tendances technologiques à surveiller en 2023
- Comment l'intelligence artificielle apporte un nouveau travail quotidien aux équipes des centres de données
- L'intelligence artificielle ou l'automatisation peuvent-elles résoudre le problème de la faible efficacité énergétique des bâtiments ?
- Co-fondateur d'OpenAI interviewé par Huang Renxun : les capacités de raisonnement de GPT-4 n'ont pas encore atteint les attentes
- Bing de Microsoft surpasse Google en termes de trafic de recherche grâce à la technologie OpenAI