
Maison >Périphériques technologiques >IA >Un examen des progrès de la recherche sur l'apprentissage profond dans la prédiction et la classification des séries chronologiques en 2022
Un examen des progrès de la recherche sur l'apprentissage profond dans la prédiction et la classification des séries chronologiques en 2022

- PHPzavant
- 2023-04-13 12:25:021161parcourir
Le déclin des transformateurs dans la prédiction des séries chronologiques et la montée en puissance des méthodes d'intégration de séries chronologiques, ainsi que la détection et la classification des anomalies ont également fait des progrès
L'ensemble du domaine a progressé sous plusieurs aspects différents en 2022. Cet article tentera de présenter certains des développements de l'année écoulée, les articles les plus prometteurs et les plus critiques publiés au cours de la dernière année, ainsi que le cadre de prévision Flow Forecast [FF].

Prévision des séries chronologiques
1. Les transformateurs sont-ils vraiment efficaces pour la prévision des séries chronologiques ?
https://www.php.cn/link/bf4d73f316737b26f1e860da0ea63ec8
Recherche liée aux transformateurs Comparez Autoformer, Pyraformer, Fedformer, etc., leurs effets et problèmes
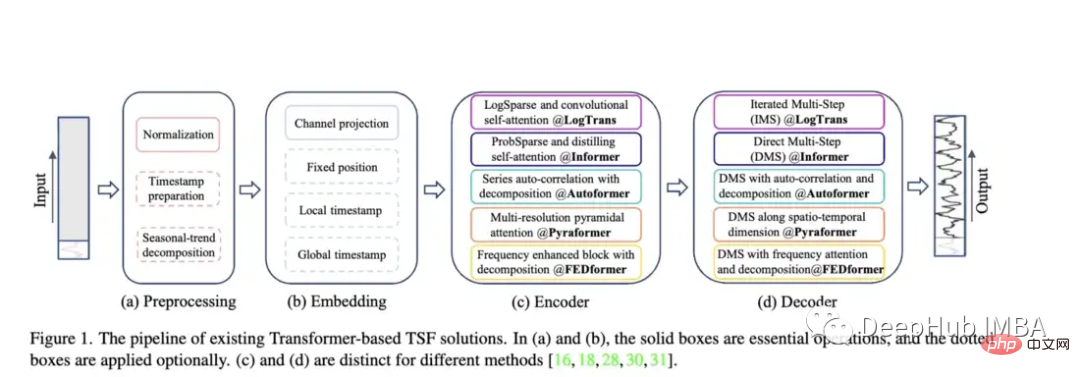
Avec Autoformer (Neurips 2021), Pyraformer (ICLR 2022), Fedformer (ICML 2022), EarthFormer (Neurips 2022) et Non-Stationary Transformer (Neurips ) et d'autres modèles, la série Transformer d'architecture de prédiction de séries chronologiques continue de croître). Mais la capacité de ces modèles à prédire avec précision les données et à surpasser les méthodes existantes reste remise en question, notamment à la lumière de nouvelles recherches (dont nous parlerons plus tard).
Autoformer : performances étendues et améliorées du modèle Informer. Autoformer dispose d'un mécanisme de corrélation automatique qui permet au modèle d'apprendre les dépendances temporelles mieux que l'attention standard. Il vise à décomposer avec précision les composantes tendancielles et saisonnières des données temporelles.
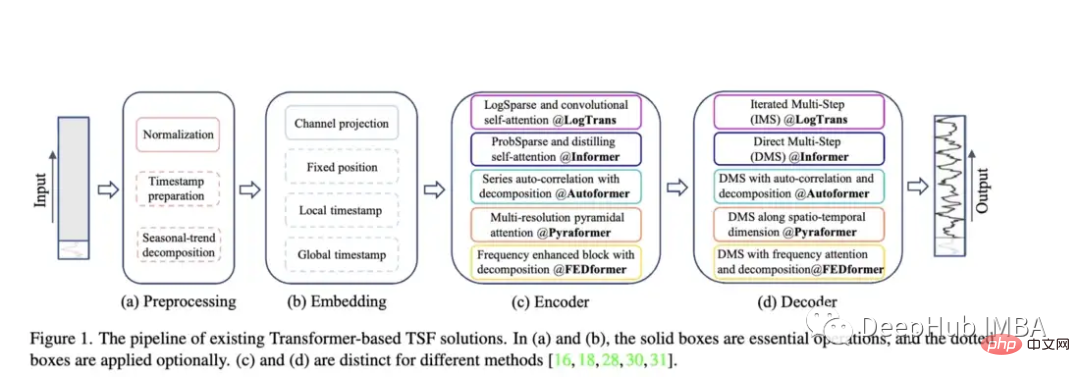
Pyraformer : L'auteur présente le "Module d'attention pyramidale (PAM), dans lequel la structure arborescente inter-échelles résume les caractéristiques à différentes résolutions et les connexions voisines intra-échelle modélisent la dépendance temporelle des différentes plages."
Fedformer : ce modèle se concentre sur la capture des tendances mondiales dans les données de séries chronologiques. Les auteurs proposent un module de décomposition des tendances saisonnières conçu pour capturer les caractéristiques globales des séries chronologiques. Earthformer : probablement le plus unique de ces articles, il se concentre spécifiquement sur la prévision des systèmes terrestres tels que la météo, le climat et l'agriculture. Une nouvelle architecture d'attention cuboïde est introduite. Cet article devrait avoir un grand potentiel, car de nombreux Transformers classiques ont échoué dans la recherche sur la prévision des rivières et des crues soudaines. Transformateur non stationnaire : il s'agit du dernier article utilisant un transformateur pour la prédiction. Les auteurs visent à mieux régler le Transformer pour gérer les séries chronologiques non stationnaires. Ils emploient deux mécanismes : une attention déstabilisatrice et une série de mécanismes stabilisateurs. Ces mécanismes peuvent être connectés à n'importe quel modèle Transformer existant, et l'auteur a testé que leur connexion à Informer, Autoformer et Transformer traditionnel peut améliorer les performances (en annexe, il est également montré que cela peut améliorer les performances de Fedformer). Méthodologie d'évaluation de l'article : Semblable à Informer, tous ces modèles (à l'exception d'Earthformer) sont évalués sur des ensembles de données sur l'électricité, les transports, les finances et la météo. Principalement évalué sur la base des indicateurs d'erreur quadratique moyenne (MSE) et d'erreur absolue moyenne (MAE) :
En tant que personne qui valorise les méthodes de pointe et les modèles innovants dans la pratique, lorsque j'ai passé des mois à essayer de faire fonctionner un soi-disant « bon » modèle, j'ai finalement découvert que ce n'était pas le cas. aussi performant qu’une simple régression linéaire, à quoi ça sert ces mois-là ? Quel est l’intérêt de ce soi-disant bon modèle ?
Tous les documents de transformation souffrent du même problème d’évaluation limitée. Nous devrions exiger des comparaisons plus rigoureuses et une explication claire des lacunes dès le début. Un modèle complexe n’est peut-être pas toujours le cas au départ. mieux que de simples modèles, mais cela doit être explicitement indiqué dans le document, plutôt que de passer sous silence ou de simplement supposer que ce n'est pas le cas
Mais le document est toujours bon, comme Earthformer sur l'ensemble de données MovingMNIST et N- L'évaluation a été effectué sur l'ensemble de données corporelles MNIST, et les auteurs l'ont utilisé pour vérifier l'efficacité de l'attention cuboïde et évaluer sa prévision instantanée des précipitations et sa prévision du cycle El Niño. Je pense que c'est un bon exemple d'intégration des connaissances physiques dans l'architecture du modèle d'attention, et Puis concevez de bons tests. capacité des Transformers à prédire les données par rapport aux méthodes de base. Les résultats réaffirment dans une certaine mesure que les Transformers fonctionnent généralement moins bien que les modèles plus simples et sont difficiles à régler. Point intéressant :
a remplacé l'auto-attention par des couches linéaires de base et a trouvé : "Les performances. d'Informer se développe avec une simplification progressive, indiquant qu'au moins pour les benchmarks LTSF existants, les schémas d'auto-attention et autres modules complexes sont inutiles" ont exploré si les intégrations positionnelles capturaient vraiment bien l'ordre temporel des séries chronologiques. Ils l'ont fait en mélangeant aléatoirement la séquence d'entrée dans un transformateur. Ils ont découvert sur plusieurs ensembles de données que ce brassage n'affectait pas les résultats (cet encodage est très gênant). .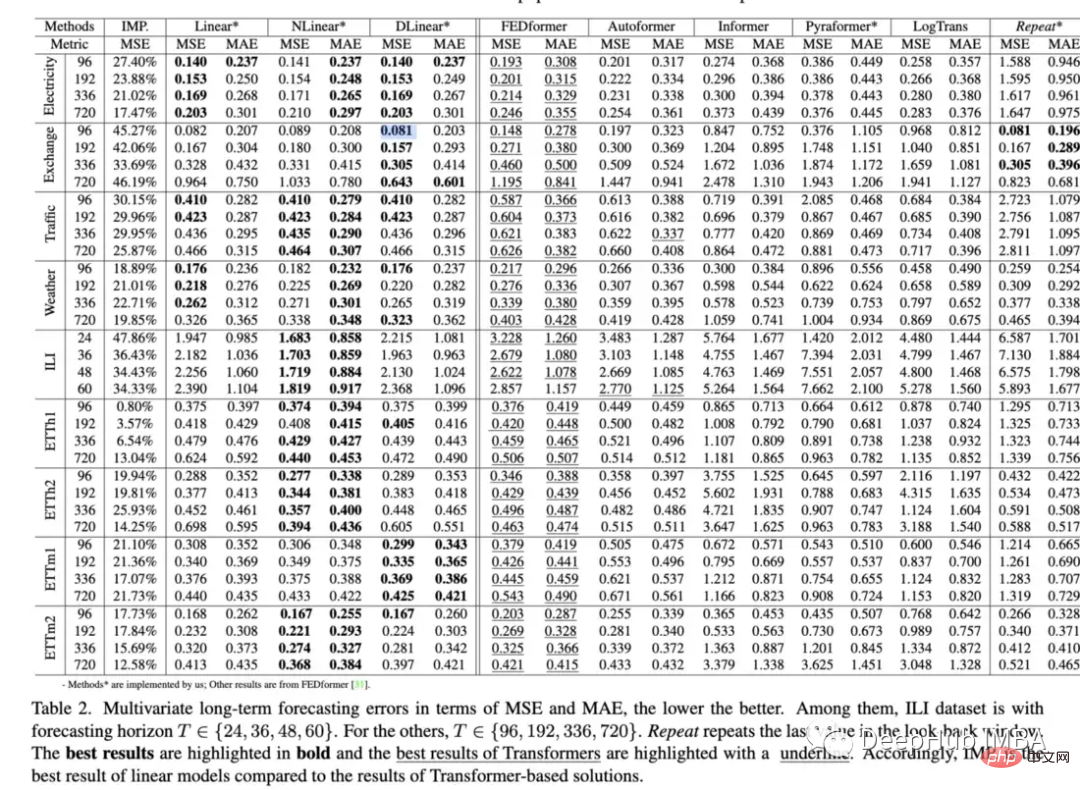
-
- Des recherches considérables se sont concentrées sur l'application de transformateurs aux prédictions, mais relativement peu de recherches ont été effectuées sur la détection des anomalies. Cet article présente un transformateur (non supervisé) pour détecter les anomalies à l'aide d'un modèle spécialement construit. la mécanique et la stratégie minmax
- .
Cet article évalue les performances du modèle sur cinq ensembles de données du monde réel, notamment Server Machine Dataset, Pooled Server Metrics, Soil Moisture Active Passive et NeurIPS-TS (qui lui-même se compose de cinq ensembles de données différents). Bien que l'on puisse être sceptique à l'égard de ce modèle, notamment en ce qui concerne le point de vue du deuxième article, cette évaluation est assez rigoureuse. Neurips-TS est un ensemble de données récemment créé spécialement conçu pour fournir une évaluation plus rigoureuse des modèles de détection d'anomalies. Ce modèle semble améliorer les performances par rapport aux modèles de détection d'anomalies plus simples.
Les auteurs proposent un transformateur non supervisé unique qui fonctionne bien sur une pléthore d'ensembles de données de détection d'anomalies. Il s'agit de l'un des articles les plus prometteurs dans le domaine des transformateurs de séries chronologiques de ces dernières années. Parce que la prédiction est plus difficile que la classification ou même la détection d'anomalies, car vous essayez de prédire une vaste gamme de valeurs possibles à plusieurs intervalles de temps dans le futur. Tant de recherches se sont concentrées sur la prédiction, tout en ignorant la classification ou la détection d’anomalies. Faut-il commencer simplement pour Transformer ?
4. WaveBound : limites d'erreur dynamiques pour la prévision de séries chronologiques stables (Neurips 2022) :
https://www.php.cn/link/ae95296e27d7f695f891cd26b4f37078
Le document introduit un nouveau formulaire de régularité. , ce qui peut améliorer la formation de modèles de prédiction de séries chronologiques approfondies (en particulier les transformateurs mentionnés ci-dessus).
Les auteurs évaluent en le branchant sur un transformateur existant + modèle LSTNet. Ils ont constaté que cela améliorait considérablement les performances dans la plupart des cas. Bien qu'ils n'aient testé que le modèle Autoformer et non les modèles plus récents comme Fedformer.
Les nouvelles formes de fonctions de régularisation ou de perte sont toujours utiles car elles peuvent généralement être connectées à n'importe quel modèle de série chronologique existant. Si vous combinez Fedformer + mécanisme non stationnaire + Wavebound, vous pouvez probablement battre la simple régression linéaire en termes de performances :).
Représentation de séries chronologiques
Bien que le Transformer ne fonctionne pas bien dans le sens de la prédiction, le Transformer a fait de nombreux progrès dans la création de représentations de séries chronologiques utiles. Je pense qu’il s’agit d’un nouveau domaine impressionnant dans le domaine de l’apprentissage profond des séries chronologiques qui devrait être exploré plus en profondeur.
5. TS2Vec : Vers une représentation universelle des séries temporelles (AAAI 2022)
https://www.php.cn/link/7690dd4db7a92524c684e3191919eb6b
TS2Vec est un outil universel pour apprendre la représentation des séries temporelles/ cadre d'intégration. L'article lui-même est quelque peu daté, mais il a lancé une tendance aux articles d'apprentissage sur la représentation de séries chronologiques.
Évalué à l'aide de représentations pour la prédiction et la détection d'anomalies, le modèle surpasse de nombreux modèles tels que Informer et Log Transformer.
6. Apprentissage des représentations de tendances saisonnières latentes pour la prévision de séries chronologiques (Neurips 2022)
https://www.php.cn/link/0c5534f554a26f7aeb7c780e12bb1525

L'auteur a créé un modèle ( LAST), qui utilise l'inférence variationnelle pour créer des représentations séparées de la saisonnalité et des tendances.
Les auteurs ont évalué leur modèle sur la tâche de prédiction en aval, ce qu'ils ont fait en ajoutant un prédicteur à la représentation (voir B dans la figure ci-dessus). Ils fournissent également des tracés intéressants pour montrer la visualisation de la représentation. Le modèle surpasse Autoformer sur plusieurs tâches de prédiction ainsi que TS2Vec et le coût. Il semble également qu'elle pourrait être plus performante que la simple régression linéaire mentionnée ci-dessus sur certaines tâches de prédiction.
Bien que je reste sceptique quant aux modèles qui évaluent uniquement les tâches de prédiction standard, ce modèle brille vraiment car il se concentre sur la représentation plutôt que sur la tâche de prédiction elle-même. Si nous examinons certains des graphiques présentés dans le document, nous pouvons voir que le modèle semble apprendre à faire la distinction entre la saisonnalité et les tendances. Les représentations visuelles de différents ensembles de données sont également intégrées dans le même espace, et il serait intéressant qu’elles présentent des différences substantielles. C7, Coût : Apprentissage contractif de représentations de tendances saisonnières démêlées pour la prévision de séries chronologiques (ICLR 2022) 200DCECA07F99ddd178
Nous sommes début 2022 Un article publié à l'ICLR il y a quelque temps est très similaire à LaST en termes d'apprentissage des représentations saisonnières et des tendances. Puisque LaST a largement remplacé ses performances, il ne sera pas trop décrit ici. Mais le lien est ci-dessus pour ceux qui veulent le lire.Autres articles intéressants
8. Adaptation de domaine pour la prévision de séries chronologiques via le partage d'attention (ICML 2022)
https://www.php.cn/link/d4ea5dacfff2d8a35c0952291779290d
Quand la Prédiction de cing est un défi pour DNN lors de la formation des données. Ce document utilise une couche d'attention partagée pour les domaines contenant des données riches, puis des modules séparés pour les domaines cibles.
Le modèle proposé est évalué à l'aide d'ensembles de données synthétiques et réels. Dans un environnement synthétique, l'apprentissage par démarrage à froid et l'apprentissage en quelques étapes ont été testés et leurs modèles se sont avérés surpasser les simples Transformer et DeepAR. Pour l'ensemble de données réel, l'ensemble de données de vente au détail Kaggle a été adopté et le modèle a largement surpassé la référence dans ces expériences.
Le démarrage à froid, peu d'échantillons et l'apprentissage fini sont des sujets extrêmement importants, mais peu d'articles couvrent les séries chronologiques. Ce modèle constitue une étape importante vers la résolution de certains de ces problèmes. Cela signifie qu'ils peuvent être évalués sur des ensembles de données réels limités et plus diversifiés et comparés à davantage de modèles de base. L'avantage d'un réglage fin ou d'une régularisation est qu'il peut être ajusté à n'importe quelle architecture.
9. Quand intervenir : apprendre les politiques d'intervention optimales en cas d'événements critiques (Neurips 2022)
https://www.php.cn/link/f38fef4c0e4988792723c29a0bd3ca98
Bien que ce ne soit pas un "article typique" " " article de série chronologique, mais j'ai choisi de l'inclure dans cette liste car l'objectif de cet article est de trouver le meilleur moment pour intervenir avant qu'une machine ne tombe en panne. C'est ce qu'on appelle OTI ou Optimum Time to Intervention
L'un des problèmes liés à l'évaluation de l'OTI est l'exactitude de l'analyse de survie sous-jacente (si elle est incorrecte, l'évaluation sera également incorrecte). Les auteurs ont évalué leur modèle par rapport à deux seuils statiques, ont constaté qu'il fonctionnait bien et ont tracé les performances attendues et le taux d'échec pour différentes politiques.
Il s'agit d'un problème intéressant et les auteurs proposent une nouvelle solution, comme l'a noté un commentateur sur Openreview : « L'expérience pourrait être plus convaincante s'il existait un graphique montrant le compromis entre la probabilité de défaillance et la force de temps d'intervention attendue, de sorte que on peut voir visuellement la forme de cette courbe de compromis. »
Ensembles de données/références récents
Le dernier est la référence de l'ensemble de données
Archive de prévisions de séries chronologiques Monash (Neurips 2021) : le but de cette archive dans la formation. une « liste principale » de différents ensembles de données de séries chronologiques et fournissant une référence plus fiable. Le référentiel contient plus de 20 ensembles de données différents couvrant plusieurs secteurs, notamment la santé, la vente au détail, le covoiturage, la démographie, etc.
https://www.php.cn/link/5d7009220a974e94404889274d3a9553
Subseasonal Forecasting Microsoft (2021) : il s'agit d'un ensemble de données rendu public par Microsoft, conçu pour promouvoir l'utilisation de l'apprentissage automatique pour améliorer les prévisions sous-saisonnières. (par exemple, les deux à six prochaines semaines). Les prévisions sous-saisonnières aident les agences gouvernementales à mieux se préparer aux événements météorologiques et aux décisions des agriculteurs. Microsoft a inclus plusieurs modèles de référence pour cette tâche et, en général, les modèles d'apprentissage profond fonctionnent assez mal par rapport aux autres méthodes. Le meilleur modèle DL est un simple modèle à action directe, et Informer fonctionne très mal.
https://www.php.cn/link/c3cbd51329ff1a0169174e9a78126ee1
Revisiting Time Series Outlier Detection : Cet article passe en revue de nombreux ensembles de données de détection d'anomalies/outliers existants et en propose 35 nouveaux. Un ensemble de données synthétiques et 4 réels. -Les ensembles de données mondiaux sont utilisés à des fins d'analyse comparative.
https://www.php.cn/link/03793ef7d06ffd63d34ade9d091f1ced
Cadre de prévision de séries chronologiques open source FF
Flow Forecast est un cadre de prévision de séries chronologiques open source, qui comprend les modèles suivants :
Vanilla LSTM (LSTM), SimpleTransformer, Multi-Head Attention, Transformer avec un décodeur linéaire, DARNN, Transformer XL, Informer, DeepAR, DSANet, SimpleLinearModel, etc.
C'est un bon modèle de code pour apprendre à utiliser deep apprentissage pour la prédiction du temps Source, si vous êtes intéressé, vous pouvez la consulter.
https://www.php.cn/link/fea33a31df7d05a276193d32621ecbe4
Résumé
Au cours des deux dernières années, nous avons assisté à la montée et au déclin possible des transformateurs dans la prévision des séries chronologiques et à la montée en puissance de des méthodes d'intégration de séries chronologiques et des avancées supplémentaires dans la détection et la classification des anomalies.
Mais pour les séries temporelles de deep learning : les méthodes d'interprétabilité, de visualisation et d'analyse comparative font encore défaut, car il est très important de savoir où le modèle est exécuté et où se produisent les échecs de performances. De plus, d’autres formes de régularisation, de prétraitement et d’apprentissage par transfert visant à améliorer les performances pourraient apparaître à l’avenir.
Peut-être que Transformer est bon pour la prédiction de séries chronologiques (peut-être pas). Tout comme VIT, Transformer peut toujours être considéré comme inutile sans l'émergence de Patch. Nous continuerons également à prêter attention au développement ou au remplacement de Transformer dans les séries chronologiques.



Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Tendances technologiques à surveiller en 2023
- Comment l'intelligence artificielle apporte un nouveau travail quotidien aux équipes des centres de données
- L'intelligence artificielle ou l'automatisation peuvent-elles résoudre le problème de la faible efficacité énergétique des bâtiments ?
- Co-fondateur d'OpenAI interviewé par Huang Renxun : les capacités de raisonnement de GPT-4 n'ont pas encore atteint les attentes
- Bing de Microsoft surpasse Google en termes de trafic de recherche grâce à la technologie OpenAI