
Maison >Périphériques technologiques >IA >Un long article de 10 000 mots, vulgarisation scientifique sur les algorithmes et systèmes de reconnaissance faciale
Un long article de 10 000 mots, vulgarisation scientifique sur les algorithmes et systèmes de reconnaissance faciale

- 王林avant
- 2023-04-13 08:16:112077parcourir

L'objectif de la reconnaissance faciale
Pour résumer deux points, premièrement, pour reconnaître la même personne, peu importe la façon dont votre statut change, vous pouvez savoir que vous êtes vous. Deuxièmement, distinguez différentes personnes. Peut-être que les deux personnes se ressemblent beaucoup, ou qu'elles se maquillent toutes les deux, mais peu importe la façon dont le statut change, la reconnaissance faciale peut savoir qu'il s'agit de deux personnes différentes.
La reconnaissance faciale elle-même est un type de technologie biométrique, fournissant principalement un moyen d'authentification de l'identité. En termes de précision, la reconnaissance faciale n'est pas la plus élevée. La reconnaissance faciale est affectée par de nombreuses autres conditions, telles que l'éclairage. L'avantage de la reconnaissance faciale est qu'elle ne nécessite généralement pas beaucoup de coopération de la part de l'utilisateur. De nos jours, les caméras de surveillance situées à divers endroits, notamment les caméras d'ordinateur, les périphériques d'entrée vidéo des téléphones portables et les équipements de caméra, sont devenues très populaires. peut Peut faire la reconnaissance faciale. Par conséquent, lorsque la reconnaissance faciale est introduite, le nouvel investissement peut être très faible, ce qui constitue son avantage.
Processus de reconnaissance faciale
Le processus de base de la reconnaissance faciale Le soi-disant processus de base signifie que quel que soit le type de système de reconnaissance faciale, ce processus est fondamentalement là. La première étape est la détection des visages, la deuxième étape est l'alignement des visages et la troisième étape est l'extraction des caractéristiques. Ce sont les trois étapes qui doivent être effectuées pour chaque photo, comparez les caractéristiques extraites, puis déterminez si les deux. les visages appartiennent à la même personne.
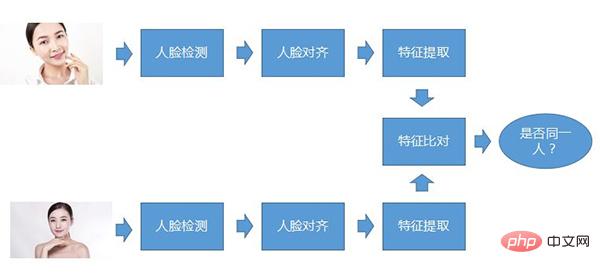
Détection de visage
La détection de visage consiste à déterminer s'il y a un visage dans une grande scène, à trouver la position du visage et à le découper. Il s’agit d’un type de technologie de détection d’objets et constitue la base de toute la tâche de perception des visages. La méthode de base de détection de visage consiste à faire glisser la fenêtre sur la pyramide d'images, à utiliser un classificateur pour sélectionner les fenêtres candidates et à utiliser un modèle de régression pour corriger la position.
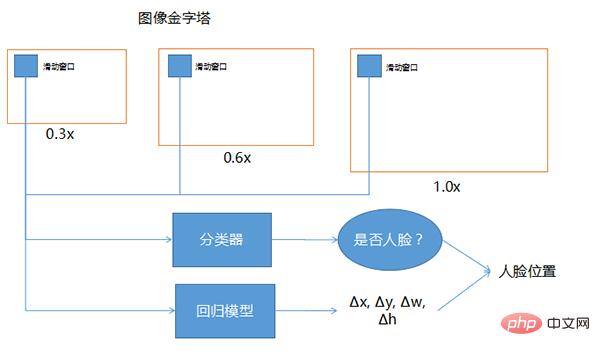
Les trois fenêtres dessinées ci-dessus, l'une correspond à 0,3 fois, 0,6 fois et 1,0 fois. Lorsque la position du visage est incertaine et que la taille ne peut pas être identifiée, cette technologie peut être utilisée pour rendre l'image elle-même différente. Les tailles et la fenêtre coulissante sont de la même taille. La taille de l'image entrée dans le réseau profond est généralement fixe, donc la fenêtre coulissante devant est fondamentalement fixe. Afin de permettre à la fenêtre coulissante fixe de couvrir différentes plages, la taille de l'image entière est adaptée à différentes proportions. Les 0,3, 0,6 et 1,0 présentés ici ne sont que des exemples. Il peut y avoir de nombreux autres multiples différents en utilisation réelle.
Le classificateur fait référence à l'examen de chaque position de la fenêtre coulissante pour déterminer s'il s'agit d'un visage humain, car la position dans laquelle la fenêtre coulissante coulisse peut ne pas inclure tout le visage, ou elle peut être plus grande que tout le visage. Afin de trouver des visages plus précis, l'insertion de la fenêtre glissante dans le modèle de régression peut aider à corriger la précision de la détection des visages.
L'entrée est une fenêtre coulissante. S'il y a une face pendant la sortie, quelle direction doit être corrigée et dans quelle mesure elle doit être corrigée, donc Δx, Δy, Δw, Δh sont ses coordonnées et quelle est sa largeur et sa largeur. la hauteur doit être corrigée. Après avoir effectué la correction et utilisé le classificateur pour déterminer qu'il s'agit d'une fenêtre d'un visage humain, en combinant ces deux éléments, une position plus précise du visage humain peut être obtenue.
Ce qui précède est le processus de détection de visage, et il peut également être appliqué à d'autres détections d'objets
Indicateurs d'évaluation de la détection de visage
Quel que soit le type de modèle, il est divisé en deux aspects : la vitesse et la précision
1 . Vitesse
(1) La vitesse est la vitesse de détection à la résolution spécifiée. La raison pour laquelle la résolution est spécifiée est que chaque fois que la fenêtre coulissante glisse vers une position, un jugement de classification et de régression doit être effectué. l'image est plus grande, un jugement de détection doit être effectué. Plus il y a de fenêtres, plus la détection complète du visage prendra du temps.
Donc pour évaluer la qualité d'un algorithme ou d'un modèle, il faut regarder sa vitesse de détection à une résolution fixe. D'une manière générale, quelle sera la valeur de cette vitesse de détection ? Il peut s'agir du temps nécessaire pour détecter le visage d'une image, par exemple 100 millisecondes, 200 millisecondes, 50 millisecondes, 30 millisecondes, etc.
Une autre façon d'exprimer la vitesse est le fps. De nos jours, les caméras Web générales fonctionnent souvent à 25 ou 30 ips, ce qui signifie combien d'images peuvent être traitées par seconde. L'avantage du fps peut être utilisé pour juger si la détection des visages peut permettre une détection en temps réel. , tant que le nombre d'ips de détection de visage est supérieur au nombre d'ips de la caméra, cela peut être réalisé en temps réel, sinon cela ne peut pas être réalisé.
(2) La vitesse est-elle affectée par le nombre de visages dans la même image ? D'après notre fonctionnement réel, la plupart d'entre eux ne sont pas affectés, car elle est principalement affectée par le nombre de fenêtres coulissantes et le nombre de coups. particulièrement lourd, mais il a un léger impact.
2. Précision
La précision est essentiellement déterminée par le taux de rappel, le taux de fausse détection et la courbe ROC. Le taux de rappel fait référence à la proportion de la photo qui est un visage humain et le modèle réel détermine qu'il s'agit d'un visage humain. Le taux de fausse détection et le taux d'erreur d'échantillonnage négatif font référence à la proportion de la photo qui n'est pas un visage humain mais. est considéré à tort comme un visage humain.
Précision ACC
L'ACC est calculé en divisant le nombre correct d'échantillons par le nombre total d'échantillons. Par exemple, si vous prenez 10 000 photos pour la détection de visages, certaines de ces 10 000 photos auront des visages, et d'autres non. . de. Déterminez ensuite quel est le rapport correct.
Mais il y a un problème avec cette précision. Si vous l'utilisez pour juger, cela n'a absolument aucun rapport avec le rapport entre les échantillons positifs et négatifs, c'est-à-dire qu'il ne se soucie pas du taux correct dans les échantillons positifs et du taux correct dans les échantillons positifs. échantillons négatifs, uniquement Care en général. Lorsque la précision de ce modèle est de 90 %, d’autres ne connaissent pas la différence entre les échantillons positifs et négatifs. Y compris la classification, y compris la régression, d'une manière générale, le modèle de classification utilisera d'abord une régression pour obtenir ce qu'on appelle le niveau de confiance. Lorsque le niveau de confiance est supérieur à une certaine valeur, il est considéré comme tel, puis lorsque le niveau de confiance est supérieur à une certaine valeur. inférieur à la même valeur, il est considéré comme non.
Le modèle statistique ACC est réglable, c'est-à-dire que l'ajustement du niveau de confiance modifiera la précision.
La valeur ACC elle-même est donc fortement affectée par la proportion de l'échantillon, il est donc un peu problématique de l'utiliser pour caractériser la qualité d'un modèle lorsque l'indicateur de test indique qu'il a atteint 99,9%, en regardant cette seule valeur. est une comparaison crédule ou cette statistique est biaisée. Afin de résoudre ce problème, une courbe appelée ROC est généralement utilisée pour caractériser la précision de ce modèle
Courbe caractéristique de fonctionnement du récepteur ROC
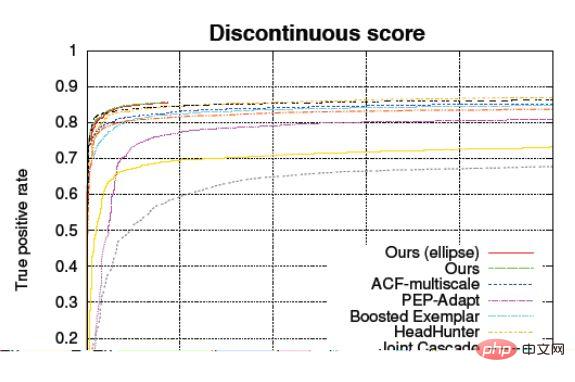
Abscisse : FPR (False Positive Rate), qui est l'erreur d'échantillonnage négative taux
Coordonnée verticale : TPR (True Positive Rate), le taux correct d'échantillons positifs
permet de distinguer les performances de l'algorithme sur les échantillons positifs et les échantillons négatifs, et la forme de la courbe n'a rien à voir avec le rapport des positifs et des échantillons négatifs.
La courbe ROC (Receiver Operating Characteristic) consiste à marquer l'abscisse et l'ordonnée avec le taux d'erreur d'échantillon négatif et le taux de correction d'échantillon positif. Dans ce cas, le même modèle ne verra pas de point sur ce graphique, ou ce n'est pas A. une seule donnée, mais une ligne. Cette ligne constitue le seuil de confiance. Plus vous l’ajustez à un niveau élevé, plus il est strict, et plus il est bas, moins il est strict. Au-delà, cela peut refléter l’impact des modifications du seuil de confiance.
À l'avenir, il est préférable de ne pas demander directement quelle est votre précision, mais de regarder la courbe ROC, ce qui permet de juger plus facilement des capacités du modèle.
Alignement du visage
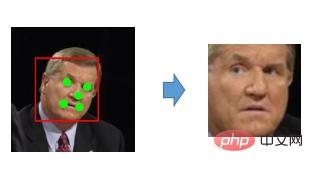
Le but de l'alignement du visage est d'ajuster autant que possible la texture du visage à la position standard et de réduire la difficulté de la reconnaissance du visage.
Afin de réduire artificiellement sa difficulté, vous pouvez d'abord l'aligner, c'est-à-dire laisser les yeux, le nez et la bouche détectés de la personne tomber tous dans la même position. De cette façon, lorsque le modèle sera comparé, il le fera. Tant que vous recherchez le même emplacement, il existe toujours une grande différence quant à savoir s'ils sont identiques ou similaires. Nous sommes donc en mesure de réaliser cette étape d'alignement. Pour cette étape, la méthode courante que nous utilisons maintenant est la méthode bidimensionnelle, qui consiste à trouver les points caractéristiques clés de cette image. Généralement, ce sont cinq points, dix-neuf points. et plus de soixante points. Il y a toutes sortes de spots, plus de 80 spots. Mais pour la reconnaissance faciale, cinq suffisent en principe.
L'image d'autres points que ces cinq points peut être considérée comme effectuant une opération similaire à l'interpolation, puis collée à cette position, une fois terminée, elle peut être envoyée au système de reconnaissance faciale derrière. Effectuez l'identification à l'intérieur. . Il s'agit d'une approche générale, mais il existe également des approches plus avancées. Certains instituts de recherche utilisent ce que l'on appelle l'alignement du visage en 3D, ce qui signifie que je vous dis à quoi ressemble un visage frontal, par exemple à quoi il ressemble lorsqu'il est tourné de 45°. degrés. Ensuite, après l'avoir entraîné avec ce genre d'image, il saura que lorsque je vois une image tournée de 45 degrés vers la gauche et la droite, c'est probablement à quoi elle ressemblera lorsqu'elle sera tournée à droite, et ce modèle peut le deviner. .
Algorithme d'extraction des caractéristiques du visage
Les méthodes traditionnelles précédentes étaient ce qu'on appelle le modèle de texture locale, le modèle de texture global, le modèle de régression de forme, etc. Ce qui est plus populaire aujourd'hui est l'utilisation de réseaux de neurones convolutifs profonds ou de réseaux de neurones récurrents, ou de réseaux de neurones convolutifs avec des paramètres 3DMM. Les paramètres dits 3DMM contiennent des informations tridimensionnelles, puis des réseaux neuronaux profonds en cascade.
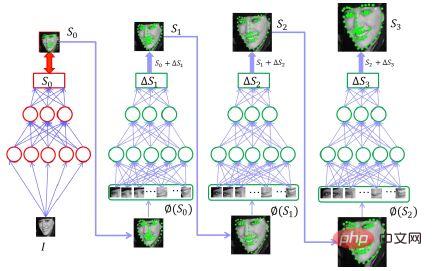
Réseaux de neurones profonds en cascade, c'est-à-dire que pour obtenir le visage, vous devez d'abord déduire les positions de cinq points. Si vous utilisez un seul modèle pour le faire à la fois, ce modèle devra être très compliqué.
Mais comment réduire la complexité de ce modèle ?
C'est-à-dire que plusieurs entrées sont effectuées. Après la première entrée dans le réseau, une supposition est acceptable et moins précise. Elle permet de savoir à peu près où se trouvent les cinq points du visage humain. Ensuite, placez ces cinq points et l'image originale dans le deuxième réseau pour obtenir le montant de correction approximatif. Après avoir obtenu cinq points de base et trouvé le montant de correction, ce sera mieux que de trouver les cinq points précis directement à partir de l'image originale. Ce point est légèrement plus simple. Par conséquent, l'utilisation de cette méthode de raffinement progressif et de mise en cascade de plusieurs réseaux peut permettre d'obtenir un meilleur équilibre entre vitesse et précision. En fait, lorsque nous le faisons maintenant, nous utilisons essentiellement deux couches et c'est à peu près la même chose.
Indice d'évaluation pour l'extraction de points caractéristiques du visage
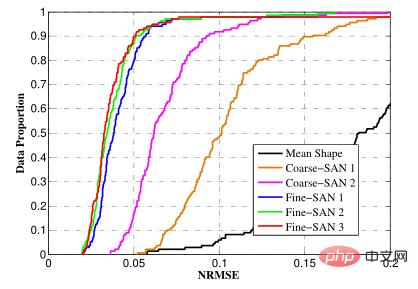
NRMSE (erreur quadratique moyenne normalisée), qui est l'erreur quadratique moyenne normalisée
, est utilisé pour mesurer la différence entre les coordonnées de chaque point caractéristique et l'étiquette étiquetée. coordonnées.
Précision
Afin de permettre de comparer des visages de différentes tailles, ce que l'on appelle statistiquement l'erreur quadratique moyenne normalisée est utilisée. Par exemple : nous dessinons cinq points sur papier, puis laissons la machine indiquer la distance entre ces cinq points. Plus la valeur donnée est proche de la distance réelle, plus la prédiction est précise. D'une manière générale, la valeur prédite aura un certain écart, alors comment exprimer cette valeur de précision ? Nous l’exprimons généralement par la valeur moyenne ou quadratique moyenne de la distance. Cependant, le problème se pose lorsque la même machine prédit des images de tailles différentes, les valeurs de précision apparaîtront différentes, car plus l'image est grande, plus la valeur absolue de l'erreur sera élevée. Le même principe s'applique aux visages de tailles différentes. Par conséquent, notre solution consiste à prendre en compte la taille originale du visage humain. Généralement, le dénominateur est la distance entre les yeux humains ou la distance diagonale du visage humain, puis à diviser la différence de distance par la distance entre les yeux, ou divisez par La diagonale du visage, dans ce cas, vous pouvez obtenir une valeur qui ne change fondamentalement pas avec la taille du visage et l'utiliser pour l'évaluation.
Comparaison de visages
(1) Objectif : Déterminer si deux visages alignés appartiennent à la même personne
(2) Difficulté : Le même visage montrera différents états dans différentes situations, comme par exemple dit être particulièrement affecté par l'éclairage, fumée, maquillage, etc. Le second est dû à différents paramètres mappés sur des photos bidimensionnelles. Ce que l'on appelle le mappage sur des paramètres bidimensionnels signifie que le visage original ressemble à ceci. Lorsque l'équipement de prise de vue prend la photo, l'angle qu'il lui présente. la distance de lui et la mise au point. Qu'elle soit précise, l'angle de prise de vue, etc., l'accumulation de lumière a toutes un impact, et le même visage apparaîtra dans des états différents. Le troisième est l’influence de l’âge et de la chirurgie plastique.
Méthode de comparaison faciale
(1) Méthode traditionnelle
1. Extraire manuellement certaines fonctionnalités telles que HOG, SIFT, transformation en ondelettes, etc. De manière générale, les fonctionnalités extraites peuvent nécessiter des paramètres fixes, c'est-à-dire aucune formation ou un apprentissage est nécessaire, utilisez simplement un algorithme fixe et comparez cette fonctionnalité.
(2) Méthode de profondeur
La méthode traditionnelle est la méthode de profondeur, c'est-à-dire le réseau neuronal convolutif profond. Ce réseau utilise généralement DCNN pour remplacer les méthodes d'extraction de caractéristiques précédentes, c'est-à-dire, sur une image, pour comprendre. En identifiant certaines caractéristiques différentes du visage d'une personne, il existe de nombreux paramètres dans DCNN. Ces paramètres sont appris et non indiqués par les gens. S'ils sont appris, ils seront meilleurs que ceux résumés par les gens.
Ensuite, l'ensemble de caractéristiques obtenu peut généralement avoir des dimensions de 128 dimensions, 256 dimensions, 512 dimensions ou 1024 dimensions, puis les comparer pour juger de la distance entre les vecteurs de caractéristiques, la distance euclidienne ou la similarité cosinusoïdale est généralement utilisée.
Les indicateurs d'évaluation de la comparaison des visages sont également divisés en vitesse et précision. La vitesse comprend le temps de calcul d'un seul vecteur de caractéristiques de visage et la vitesse de comparaison. La précision inclut ACC et ROC. Puisqu’il a déjà été introduit, nous nous concentrons ici sur la vitesse de comparaison.
La comparaison ordinaire est une opération simple, qui consiste à calculer la distance entre deux points. Vous n'aurez peut-être besoin de faire qu'une seule fois un produit interne, qui est le produit interne de deux vecteurs. Cependant, lorsque la reconnaissance faciale rencontre une comparaison 1:N, Lorsque Lorsque la bibliothèque N est très grande, lorsque vous obtenez une photo et que vous la recherchez dans la bibliothèque N, le nombre de recherches sera très important. Par exemple, si la bibliothèque N est d'un million, vous devrez peut-être en rechercher un million. fois. Cela équivaut à faire un million de comparaisons. À l'heure actuelle, il y a encore des exigences pour le temps total, il y aura donc diverses technologies pour accélérer cette comparaison.
Les autres algorithmes liés à la reconnaissance faciale
incluent principalement le suivi du visage, l'évaluation de la qualité et la reconnaissance du corps vivant.
Quantity Suivi du visage
Dans les scénarios de reconnaissance faciale vidéo tels que la surveillance, si l'ensemble du processus de reconnaissance faciale est exécuté sur chaque image de la même personne qui passe, cela gaspillera non seulement des ressources informatiques, mais pourra également entraîner une mauvaise qualité. les images provoquent une mauvaise reconnaissance, il est donc nécessaire de déterminer quels visages appartiennent à la même personne. Et sélectionnez des photos appropriées pour la reconnaissance, ce qui améliore considérablement les performances globales du modèle.
De nos jours, non seulement le suivi des visages, mais également divers suivis d'objets ou de véhicules, etc., utiliseront des algorithmes de suivi. De tels algorithmes ne s'appuient pas ou ne s'appuieront pas toujours sur la détection. Par exemple, après avoir détecté un objet au début, il ne le détectera pas du tout et utilisera uniquement l'algorithme de suivi pour le faire. Dans le même temps, afin d'obtenir une très grande précision et d'éviter les pertes, chaque suivi prend beaucoup de temps.
Afin d'éviter que le visage suivi ne corresponde à la portée du système de reconnaissance faciale, d'une manière générale, un détecteur de visage sera utilisé pour une détection. Cette méthode de détection repose sur un suivi relativement léger de la détection de visage. Dans certains scénarios, une balance. entre rapidité et qualité peut être atteint.
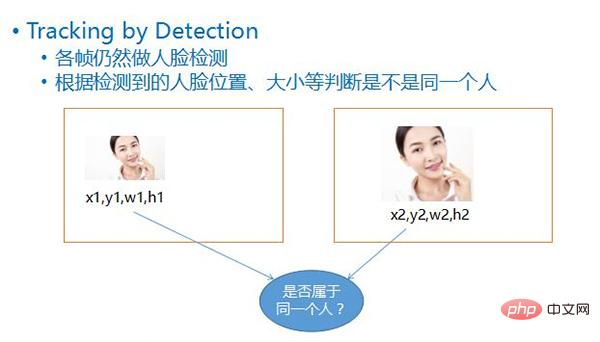
Cette méthode de détection est appelée Tracking by Detection, c'est-à-dire que la détection du visage est toujours effectuée à chaque image après avoir détecté le visage, selon les quatre valeurs de chaque visage, c'est-à-dire sa position de coordonnées. , sa largeur, High, en comparant la position et la taille du visage dans les deux images avant et après, vous pouvez probablement en déduire si les deux visages appartiennent au même objet en mouvement.
Quantity Détection plein écran à intervalle optionnel
signifie que lors du suivi par détection, une solution consiste à effectuer une détection plein écran sur les deux images avant et après. La détection dite plein écran signifie scanner la totalité de l'écran. Cependant, cette méthode prend beaucoup de temps, donc parfois une autre méthode est utilisée, qui consiste à faire un plein écran toutes les quelques images. Généralement, la position de l'image suivante ne changera pas trop. la position de l'image précédente en haut, en bas, à gauche et à droite, et si nous la détectons à nouveau, il y a souvent une forte probabilité qu'elle puisse être détectée, et la plupart des images peuvent être ignorées.
Pourquoi devons-nous effectuer une détection plein écran toutes les quelques images ?
Cela permet d'empêcher l'entrée de nouveaux objets. Si vous effectuez une recherche uniquement en fonction de la position de l'objet précédent, il peut y avoir de nouveaux objets qui ne sont pas détectés lorsqu'ils entrent. Pour éviter cela, vous pouvez attendre cinq ou dix images et réessayez. Faites un test en plein écran.
Quantity Évaluation de la qualité du visage
En raison des limites des données d'entraînement de la reconnaissance faciale, etc., il est impossible d'obtenir de bons résultats sur les visages dans tous les États. L'évaluation de la qualité déterminera dans quelle mesure le visage détecté correspond aux caractéristiques de la reconnaissance faciale. sélectionnez uniquement les visages avec un degré élevé de correspondance et envoyez-les pour reconnaissance afin d'améliorer les performances globales du système.
L'évaluation de la qualité du visage comprend les 4 éléments suivants
① La taille du visage si un visage trop petit est utilisé pour la reconnaissance, l'effet de reconnaissance sera considérablement réduit.
② La posture du visage fait référence à l'angle de rotation sur trois axes, qui est généralement lié aux données utilisées pour l'entraînement à la reconnaissance. Si la plupart des visages avec de petites postures sont utilisés pendant l'entraînement, il est préférable de ne pas choisir des visages avec de grandes déviations lors de la reconnaissance, sinon cela ne sera pas applicable.
③ Degré de flou, ce facteur est très important Si la photo a perdu des informations, il y aura des problèmes de reconnaissance.
④ Occlusion, si les yeux, le nez, etc. sont couverts, les caractéristiques de cette zone ne peuvent pas être obtenues, ou les caractéristiques obtenues sont fausses. Ce sont des caractéristiques d'un obturateur, qui auront un impact sur la reconnaissance ultérieure. S'il peut être déterminé qu'il est masqué, supprimez-le ou effectuez un traitement spécial, par exemple en ne le mettant pas dans le modèle de reconnaissance.
Quantity Reconnaissance en direct
C'est un problème que tous les systèmes de reconnaissance faciale rencontreront. Si seuls les visages sont reconnus, les photos peuvent également passer. Afin d'éviter que le système ne soit attaqué, certains jugements seront effectués pour déterminer s'il s'agit d'un vrai visage ou d'un faux visage.
Fondamentalement, il existe actuellement trois méthodes :
① La reconnaissance dynamique traditionnelle. De nombreux distributeurs automatiques de billets bancaires nécessitent une certaine coopération de l'utilisateur, par exemple en lui demandant de cligner des yeux ou de tourner la tête, afin de déterminer s'il cligne des yeux. , s'est retourné et a fait la même coopération. Par conséquent, il y a un problème avec la reconnaissance dynamique, c'est-à-dire qu'elle nécessite beaucoup de coopération de la part de l'utilisateur, donc l'expérience utilisateur sera un peu mauvaise.
② La reconnaissance statique ne signifie pas juger en fonction des actions, mais simplement juger s'il s'agit d'un vrai visage ou d'un faux visage en fonction de la photo elle-même. Il est basé sur les méthodes d'attaque couramment utilisées, qui sont relativement pratiques, par exemple prendre un téléphone portable ou un écran d'affichage et utiliser l'écran pour attaquer.
La capacité lumineuse de ce type d'écran est différente de la capacité lumineuse des visages humains dans des conditions d'éclairage réelles. Par exemple, un moniteur avec 16 millions de couleurs lumineuses ne peut pas atteindre la capacité lumineuse de la lumière visible, c'est-à-dire que toutes les bandes le sont. continu. Tout peut être envoyé. Par conséquent, lors de la prise de vue de ce type d'écran, par rapport à l'imagerie primaire dans l'environnement naturel réel, l'œil humain peut également voir qu'il y aura des changements et un certain manque de naturel. Après avoir intégré ce manque de naturel dans un modèle d'entraînement, vous pouvez toujours juger s'il s'agit d'un vrai visage sur la base de cette différence subtile.
③ Reconnaissance stéréo, si vous utilisez deux caméras ou une caméra avec des informations de profondeur, vous pouvez connaître la distance de chaque point capturé par la caméra, ce qui équivaut à l'imagerie 3D de personnes. De cette façon, vous pouvez utiliser un écran pour. tirer, et l'écran Ce doit être une personne plate. Sachez que c'est plat. La personne plate n'est certainement pas une vraie personne. Il s'agit d'utiliser une méthode de reconnaissance tridimensionnelle pour exclure les faces plates.
La composition du système de reconnaissance faciale
Faites d'abord une classification. Du point de vue de la comparaison, il existe un système de reconnaissance 1:1 et un système de reconnaissance 1:N, du point de vue des objets de comparaison, il existe des systèmes de comparaison de photos et de vidéos. système ; selon le formulaire de déploiement, il existe un déploiement privé, un déploiement cloud ou un déploiement d'appareils mobiles.
Système de reconnaissance photo 1:1
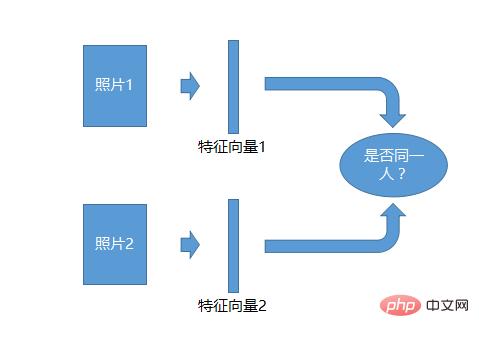
Le système de reconnaissance 1:1 est le plus simple. Prenez deux photos, générez un vecteur de caractéristiques pour chaque photo, puis comparez les deux vecteurs de caractéristiques pour voir s'ils sont identiques. Les individus peuvent être identifiés.
Photo 1 : Système de reconnaissance de N
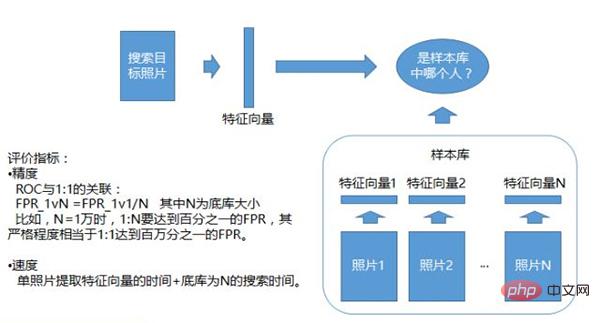
1 : Système de reconnaissance de N, qui détermine si le matériel photo se trouve dans la même bibliothèque d'échantillons. Cette bibliothèque d'échantillons est préparée à l'avance. Il peut y avoir une liste blanche ou une liste noire. Elle contient une photo de chaque personne. Une série de vecteurs de caractéristiques sont générés à partir de cette photo. Ceci est utilisé comme bibliothèque d'échantillons. Les photos téléchargées sont comparées à toutes les fonctionnalités de la bibliothèque d'échantillons pour voir laquelle ressemble le plus à la personne. Il s'agit d'un système de reconnaissance 1:N.
Système de reconnaissance vidéo 1:1
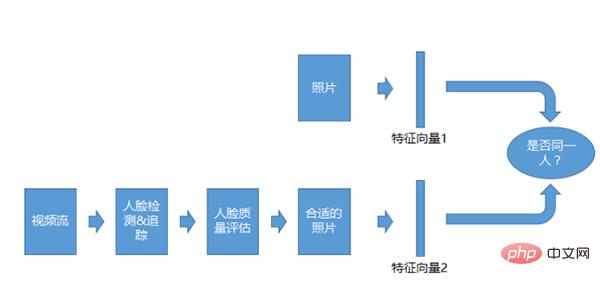
Le système de reconnaissance vidéo 1:1 est similaire au système 1:1 pour les photos, mais l'objet de comparaison n'est pas des photos, mais des flux vidéo. Après avoir obtenu le flux vidéo, nous effectuerons la détection, le suivi et l’évaluation de la qualité, puis nous le comparerons après avoir obtenu les photos appropriées.
Système de reconnaissance vidéo 1:N
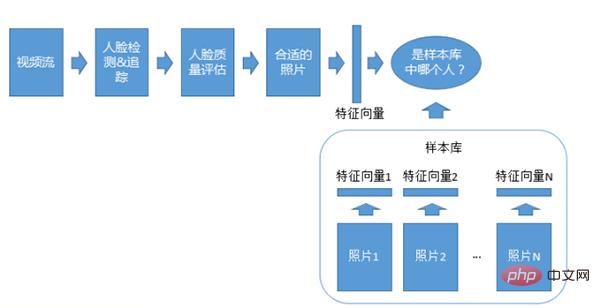
Le système d'adaptation vidéo 1:N est similaire au système photo 1:N, sauf que le flux vidéo est utilisé pour la reconnaissance et que la détection, le suivi et la qualité sont également requis. .
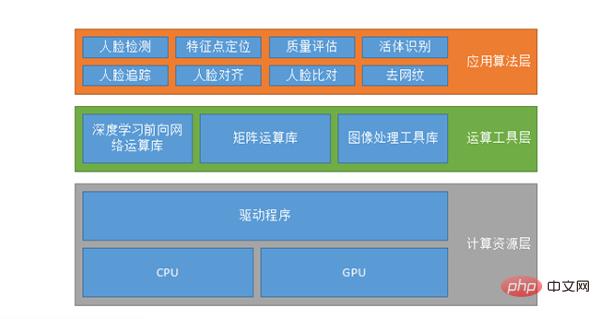
La soi-disant configuration du système n'est pas nécessairement un système de reconnaissance faciale, c'est probablement la même chose pour différents systèmes d'IA. La première est la couche de ressources informatiques, qui s'exécute sur le CPU ou le GPU exécuté sur le GPU peut également prendre en charge CUDA, CUDN, etc.
La seconde est la couche d'outils informatiques, comprenant la bibliothèque informatique de réseau avancée d'apprentissage profond, la bibliothèque de calcul matriciel et la bibliothèque d'outils de traitement d'image. Puisqu'il est impossible pour tous ceux qui créent des algorithmes d'écrire leurs propres opérations sur les données, ils utiliseront certaines bibliothèques d'opérations sur les données existantes, telles que TensorFlow, MXNET ou Caffe, etc., ou ils pourront écrire leur propre ensemble.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Tendances technologiques à surveiller en 2023
- Comment l'intelligence artificielle apporte un nouveau travail quotidien aux équipes des centres de données
- L'intelligence artificielle ou l'automatisation peuvent-elles résoudre le problème de la faible efficacité énergétique des bâtiments ?
- Co-fondateur d'OpenAI interviewé par Huang Renxun : les capacités de raisonnement de GPT-4 n'ont pas encore atteint les attentes
- Bing de Microsoft surpasse Google en termes de trafic de recherche grâce à la technologie OpenAI