
Maison >développement back-end >Tutoriel Python >Utilisez Python pour analyser 1,4 milliard de données
Utilisez Python pour analyser 1,4 milliard de données

- PHPzavant
- 2023-04-12 22:19:251794parcourir

Google Ngram Viewer est un outil amusant et utile qui utilise le vaste trésor de données numérisées de livres de Google pour tracer les changements dans l'utilisation des mots au fil du temps. Par exemple, le mot Python (sensible à la casse) :
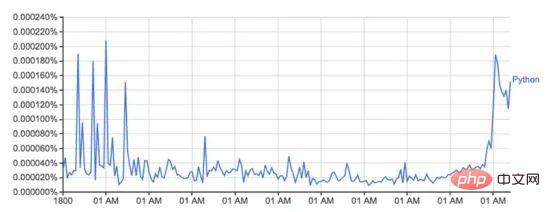
Ce graphique de books.google.com/ngrams… décrit l'utilisation du mot « Python » au fil du temps.
Il est alimenté par l'ensemble de données n-gram de Google, qui enregistre l'utilisation d'un mot ou d'une expression spécifique dans Google Books pour chaque année d'impression du livre. Cependant, ce n'est pas complet (cela n'inclut pas tous les livres jamais publiés !), il y a des millions de livres dans l'ensemble de données, couvrant la période du 16ème siècle à 2008. L'ensemble de données peut être téléchargé gratuitement à partir d'ici.
J'ai décidé d'utiliser Python et ma nouvelle bibliothèque de chargement de données PyTubes pour voir à quel point il était facile de régénérer le tracé ci-dessus.
Challenge
L'ensemble de données de 1 gramme peut être étendu à 27 Go de données sur le disque dur, ce qui représente une grande quantité de données une fois lu en python. Python peut facilement traiter des gigaoctets de données à la fois, mais lorsque les données sont corrompues et traitées, cela devient plus lent et moins efficace en termes de mémoire.
Au total, ces 1,4 milliards de données (1 430 727 243) sont dispersées dans 38 fichiers sources, avec un total de 24 millions (24 359 460) de mots (et balises de parties de discours, voir ci-dessous), calculés de 1505 à 2008. .
Lors du traitement d'un milliard de lignes de données, les choses ralentissent rapidement. Et Python natif n’est pas optimisé pour gérer cet aspect des données. Heureusement, numpy est vraiment efficace pour gérer de grandes quantités de données. En utilisant quelques astuces simples, nous pouvons rendre cette analyse réalisable en utilisant numpy.
La gestion des chaînes en python/numpy est compliquée. La surcharge de mémoire des chaînes en python est importante et numpy ne peut gérer que des chaînes de longueur connue et fixe. En raison de cette situation, la plupart des mots sont de longueurs différentes, ce n’est donc pas idéal.
Chargement des données
Tous les codes/exemples ci-dessous fonctionnent sur un Macbook Pro 2016 avec 8 Go de RAM. Si le matériel ou l'instance cloud a une meilleure configuration de RAM, les performances seront meilleures.
Les données de 1 gramme sont stockées dans le fichier sous la forme d'un formulaire délimité par des tabulations, qui se présente comme suit :

Chaque élément de données contient les champs suivants :
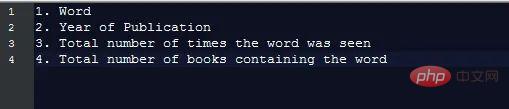
Afin de générer des graphiques comme requis, nous avons seulement besoin de connaître ces informations, c'est-à-dire :

En extrayant ces informations, le coût supplémentaire du traitement des données de chaîne de différentes longueurs est ignoré, mais nous devons quand même comparer les valeursde différentes chaînes pour distinguer les lignes de données qui correspondent aux champs qui nous intéressent. Voici ce que pytubes peut faire :
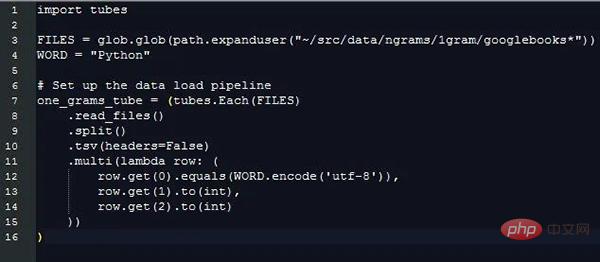
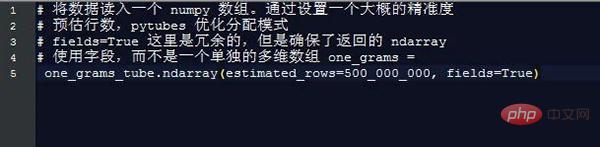
Près de 170 secondes (3 minutes) plus tard, one_grams est un tableau numpy contenant près de 1,4 milliard de lignes de données, ressemblant à ceci (en-têtes ajoutés à titre d'illustration) :
╒ ═══════════╤═══════════════╕
│ Is_Word │Année │Count │
╞══ │
├─ ──────── ──┼────────┼─────────┤
│ 0 │ 1804 │ 1 │
├──────── ───┼──── ────┼────────┤
│ 0 │ 1805 │
├──── ───────┼──── ──────┼── ───────┤
│ 0 │ 1811 │ 1 │
├───────── ──┼────────┼ ───────── ┤
│ 0 │ 1820 │ ... │
╘═══════════╧════ ════╧════ ═ ════╛
À partir de là, il suffit d'utiliser les méthodes numpy pour calculer quelque chose :
Utilisation totale des mots chaque année
Google affiche le pourcentage d'occurrences de chaque mot (le nombre de fois qu'un certain mot est apparu au cours de cette année fois/total nombre d'occurrences de tous les mots dans l'année), ce qui est plus utile que de simplement compter les mots originaux. Pour calculer ce pourcentage, nous devons connaître le nombre total de mots.
Heureusement, numpy rend cela très simple :
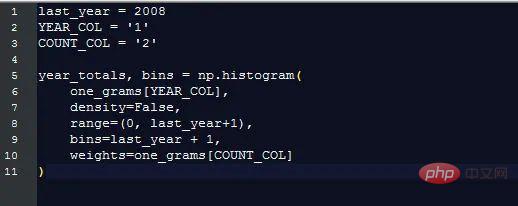
Tracé ce graphique pour montrer combien de mots Google collectait chaque année :
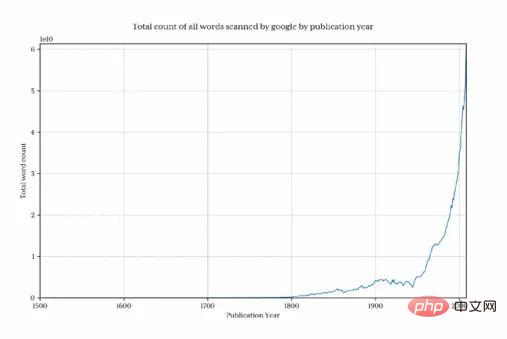
Il est clair qu'avant 1800, la quantité totale de données diminuait très rapidement, déformant ainsi le résultat final et cacher les modèles d’intérêt. Pour éviter ce problème, nous importons uniquement les données après 1800 :
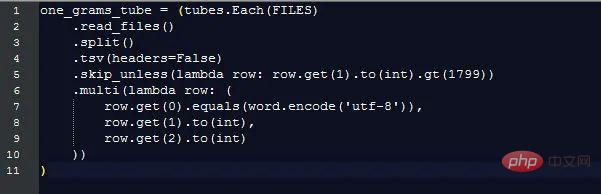
Cela renvoie 1,3 milliard de lignes de données (seulement 3,7% des données avant 1800)
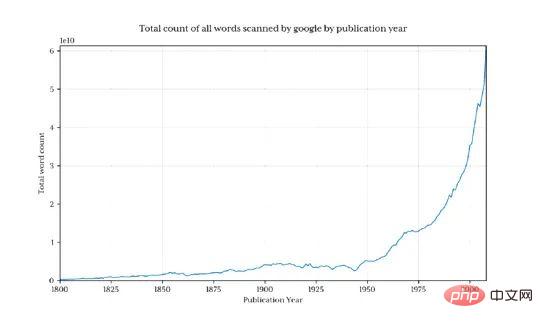
Pourcentage de Python chaque année
Obtenir le pourcentage de python chaque année est désormais particulièrement simple.
Utilisez une astuce simple pour créer un tableau basé sur l'année. La longueur de l'élément 2008 signifie que l'indice de chaque année est égal au numéro de l'année. Ainsi, par exemple, 1995 consiste simplement à obtenir l'élément de. 1995.
Cela ne vaut pas la peine d'utiliser numpy pour fonctionner :

Le résultat du traçage du nombre de mots :

La forme est presque la même que celle de la version de Google
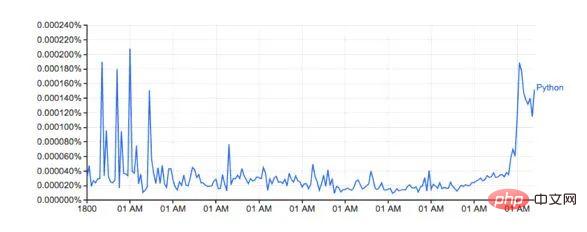
Les pourcentages réels ne correspondent pas, je Je pense que c'est parce que l'ensemble de données téléchargé contient des mots différents (par exemple : Python_VERB). Cet ensemble de données n'est pas très bien expliqué dans la page google et soulève plusieurs questions :
Comment utilise-t-on Python comme verbe ?
Le montant total du calcul de « Python » inclut-il « Python_VERB » ? Attendez
Heureusement, nous savons tous que la méthode que j'ai utilisée génère une icône qui ressemble beaucoup à Google, et les tendances associées ne sont pas affectées, donc pour cette exploration, je ne vais pas essayer de la réparer.
Performance
Google génère des images en 1 seconde environ, ce qui est raisonnable comparé aux 8 minutes pour ce script. Le backend de comptage de mots de Google fonctionne à partir d'une vue explicite de l'ensemble de données préparé.
Par exemple, calculer à l'avance l'utilisation totale des mots pour l'année précédente et la stocker dans une table de recherche distincte permettra de gagner beaucoup de temps. De même, conserver l'utilisation des mots dans une base de données/un fichier séparé, puis indexer la première colonne éliminera presque tout le temps de traitement.
Cette exploration montre vraiment qu'il est possible de charger, traiter et extraire des statistiques arbitraires à partir d'un ensemble de données d'un milliard de lignes dans un délai raisonnable en utilisant numpy et les tout nouveaux pytubes avec du matériel standard et Python,
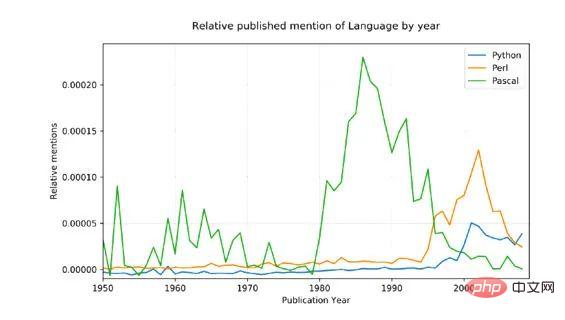
Language Wars
Pour le démontrer concept avec un exemple un peu plus complexe, j'ai décidé de comparer trois langages de programmation mentionnés de manière pertinente : Python, Pascal et Perl
Les données sources sont bruitées (elles incluent toutes les utilisations. Les mots anglais qui ont été utilisés ne sont pas seulement mentionnés dans la programmation. langages, mais aussi, par exemple, python a des significations non techniques ! ), afin d'ajuster à cet égard, nous avons fait deux choses :
Seule la première lettre du nom peut être mise en correspondance (Python, pas. python)
Le nombre total de mentions pour chaque langue a été converti en un pourcentage moyen de 1800 à 1960, ce qui devrait avoir une base raisonnable étant donné que Pascal a été mentionné pour la première fois en 1970.
Résultats :
Par rapport à Google (sans aucun ajustement de base) :
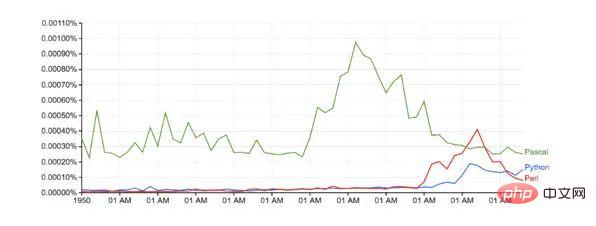
Durée d'exécution : un peu plus de 10 minutes
Futures améliorations de PyTubes
À ce stade, pytubes n'a que le concept d'un seul entier, soit 64 bits. Cela signifie que les tableaux numpy générés par pytubes utilisent des types i8 pour tous les entiers. À certains endroits (comme les données ngrams), les entiers 8 bits sont un peu excessifs et gaspillent de la mémoire (le ndarray total est de 38 Go, les dtypes peuvent facilement réduire cela de 60 %). Je prévois d'ajouter une prise en charge des entiers de niveau 1, 2 et 4 bits ( github.com/stestagg/py… )
Plus de logique de filtrage - Tube.skip_unless() est un moyen relativement simple de filtrer les lignes, mais il lui manque la capacité de combiner conditions (ET/OU/NON). Cela peut réduire plus rapidement la taille des données chargées dans certains cas d’utilisation.
Meilleure correspondance de chaînes - des tests simples tels que : commence avec, se termine avec, contient et is_one_of peuvent être facilement ajoutés pour améliorer considérablement l'efficacité du chargement des données de chaîne.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!