
Maison >Périphériques technologiques >IA >Créer un moteur de recherche vidéo à l'aide de CLIP
Créer un moteur de recherche vidéo à l'aide de CLIP

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBavant
- 2023-04-12 13:43:031057parcourir
CLIP (Contrastive Language-Image Pre-training) est une technologie d'apprentissage automatique capable de comprendre et de classer avec précision les images et les textes en langage naturel, qui a un impact profond sur le traitement de l'image et du langage et a été utilisée comme modèle de diffusion populaire. mécanisme de DALL-E. Dans cet article, nous verrons comment ajuster CLIP pour faciliter la recherche vidéo.
Cet article n'entrera pas dans les détails techniques du modèle CLIP, mais montrera une autre application pratique du CLIP (en plus du modèle de diffusion).
Nous devons d'abord savoir : CLIP utilise un décodeur d'images et un encodeur de texte pour prédire quelles images de l'ensemble de données correspondent à quel texte.

Recherche à l'aide de CLIP
En utilisant le modèle CLIP pré-entraîné de Hugging Face, nous pouvons créer un moteur de recherche vidéo simple et puissant avec des capacités de langage naturel et sans avoir besoin d'ingénierie de fonctionnalités.
Nous devons utiliser le logiciel suivant
Python≥= 3.8,ffmpeg,opencv
Il existe de nombreuses techniques pour rechercher des vidéos par texte. Nous pouvons considérer un moteur de recherche comme composé de deux parties, l’indexation et la recherche.
Indexation
L'indexation vidéo implique généralement une combinaison de processus manuels et mécaniques. Les humains prétraitent les vidéos en ajoutant des mots-clés pertinents dans les titres, les balises et les descriptions, tandis que les processus automatisés extraient des fonctionnalités visuelles et auditives telles que la détection d'objets et la transcription audio. Mesures d'interaction des utilisateurs et bien plus encore, qui enregistrent les parties de la vidéo les plus pertinentes et combien de temps elles restent pertinentes. Toutes ces étapes permettent de créer un index consultable de votre contenu vidéo.
Un aperçu du processus d'indexation est le suivant
- Diviser la vidéo en plusieurs scènes
- Échantillonnage de scènes pour les images
- Incorporation de pixels après le traitement des images
- Stockage de construction d'indexation
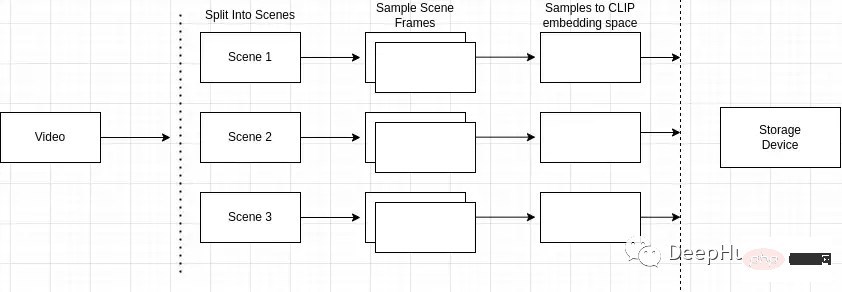
Diviser la vidéo en plusieurs scènes
Pourquoi la détection de scène est-elle importante ? Les vidéos sont composées de scènes et les scènes sont composées d'images similaires. Si nous échantillonnons uniquement des scènes arbitraires dans la vidéo, nous risquons de manquer des images clés dans toute la vidéo.
Nous devons donc identifier et localiser avec précision des événements ou des actions spécifiques dans la vidéo. Par exemple, si je recherche « chiens dans le parc » et que la vidéo que je recherche contient plusieurs scènes, comme une scène d'un homme faisant du vélo et une scène d'un chien dans le parc, la détection de scène me permet de identifiez ceux qui sont les plus pertinents pour la requête de recherche. Fermer la scène.
Vous pouvez utiliser le package python "scene detector" pour effectuer cette opération.
mport scenedetect as sd video_path = '' # path to video on machine video = sd.open_video(video_path) sm = sd.SceneManager() sm.add_detector(sd.ContentDetector(threshold=27.0)) sm.detect_scenes(video) scenes = sm.get_scene_list()
Échantillonnez les images de la scène
Ensuite, vous devez utiliser cv2 pour cadrer la vidéo.
import cv2 cap = cv2.VideoCapture(video_path) every_n = 2 # number of samples per scene scenes_frame_samples = [] for scene_idx in range(len(scenes)): scene_length = abs(scenes[scene_idx][0].frame_num - scenes[scene_idx][1].frame_num) every_n = round(scene_length/no_of_samples) local_samples = [(every_n * n) + scenes[scene_idx][0].frame_num for n in range(3)] scenes_frame_samples.append(local_samples)
Convertir les images en intégrations de pixels
Après avoir collecté les échantillons, nous devons les calculer en quelque chose d'utilisable par le modèle CLIP.
Vous devez d'abord convertir chaque échantillon en une intégration de tenseur d'image.
from transformers import CLIPProcessor
from PIL import Image
clip_processor = CLIPProcessor.from_pretrained("openai/clip-vit-base-patch32")
def clip_embeddings(image):
inputs = clip_processor(images=image, return_tensors="pt", padding=True)
input_tokens = {
k: v for k, v in inputs.items()
}
return input_tokens['pixel_values']
# ...
scene_clip_embeddings = [] # to hold the scene embeddings in the next step
for scene_idx in range(len(scenes_frame_samples)):
scene_samples = scenes_frame_samples[scene_idx]
pixel_tensors = [] # holds all of the clip embeddings for each of the samples
for frame_sample in scene_samples:
cap.set(1, frame_sample)
ret, frame = cap.read()
if not ret:
print('failed to read', ret, frame_sample, scene_idx, frame)
break
pil_image = Image.fromarray(frame)
clip_pixel_values = clip_embeddings(pil_image)
pixel_tensors.append(clip_pixel_values)L'étape suivante consiste à faire la moyenne de tous les échantillons de la même scène, ce qui peut réduire la dimensionnalité des échantillons et également résoudre le problème du bruit dans un seul échantillon.
import torch
import uuid
def save_tensor(t):
path = f'/tmp/{uuid.uuid4()}'
torch.save(t, path)
return path
# ..
avg_tensor = torch.mean(torch.stack(pixel_tensors), dim=0)
scene_clip_embeddings.append(save_tensor(avg_tensor))De cette façon, une liste de tenseurs intégrés CLIP représentant le contenu vidéo est obtenue.
Index de stockage
Pour le stockage de l'index sous-jacent, nous utilisons LevelDB (LevelDB est une bibliothèque clé/valeur maintenue par Google). L'architecture de notre moteur de recherche sera composée de 3 index distincts :
- Index de scène vidéo : quelles scènes appartiennent à une vidéo spécifique
- Index d'intégration de scène : enregistre les données de scène spécifiques
- Index de métadonnées vidéo : enregistre les métadonnées de la vidéo.
Nous allons d'abord insérer toutes les métadonnées calculées dans la vidéo et l'identifiant unique de la vidéo dans l'index des métadonnées. Cette étape est toute prête et très simple.
import leveldb
import uuid
def insert_video_metadata(videoID, data):
b = json.dumps(data)
level_instance = leveldb.LevelDB('./dbs/videometadata_index')
level_instance.Put(videoID.encode('utf-8'), b.encode('utf-8'))
# ...
video_id = str(uuid.uuid4())
insert_video_metadata(video_id, {
'VideoURI': video_path,
})Créez ensuite une nouvelle entrée dans l'index d'intégration de scène pour contenir chaque pixel incorporé dans la vidéo, nécessitant également un identifiant unique pour identifier chaque scène.
import leveldb
import uuid
def insert_scene_embeddings(sceneID, data):
level_instance = leveldb.LevelDB('./dbs/scene_embedding_index')
level_instance.Put(sceneID.encode('utf-8'), data)
# ...
for f in scene_clip_embeddings:
scene_id = str(uuid.uuid4())
with open(f, mode='rb') as file:
content = file.read()
insert_scene_embeddings(scene_id, content)Enfin, nous devons enregistrer quelles scènes appartiennent à quelle vidéo.
import leveldb
import uuid
def insert_video_scene(videoID, sceneIds):
b = ",".join(sceneIds)
level_instance = leveldb.LevelDB('./dbs/scene_index')
level_instance.Put(videoID.encode('utf-8'), b.encode('utf-8'))
# ...
scene_ids = []
for f in scene_clip_embeddings:
# .. as shown in previous step
scene_ids.append(scene_id)
scene_embedding_index.insert(scene_id, content)
scene_index.insert(video_id, scene_ids)Recherche
Maintenant que nous avons un index des vidéos, nous pouvons les rechercher et les trier en fonction de la sortie du modèle.
La première étape nécessite de parcourir tous les enregistrements de l'index de scène. Ensuite, créez une liste de toutes les vidéos et des identifiants de scène correspondants dans la vidéo.
records = []
level_instance = leveldb.LevelDB('./dbs/scene_index')
for k, v in level_instance.RangeIter():
record = (k.decode('utf-8'), str(v.decode('utf-8')).split(','))
records.append(record)L'étape suivante consiste à collecter tous les tenseurs d'intégration de scène présents dans chaque vidéo.
import leveldb
def get_tensor_by_scene_id(id):
level_instance = leveldb.LevelDB('./dbs/scene_embedding_index')
b = level_instance.Get(bytes(id,'utf-8'))
return BytesIO(b)
for r in records:
tensors = [get_tensor_by_scene_id(id) for id in r[1]]Après avoir tous les tenseurs qui composent la vidéo, nous pouvons la transmettre au modèle. L'entrée du modèle est "pixel_values", un tenseur représentant la scène vidéo.
import torch
from transformers import CLIPProcessor, CLIPModel
processor = CLIPProcessor.from_pretrained("openai/clip-vit-base-patch32")
model = CLIPModel.from_pretrained("openai/clip-vit-base-patch32")
inputs = processor(text=text, return_tensors="pt", padding=True)
for tensor in tensors:
image_tensor = torch.load(tensor)
inputs['pixel_values'] = image_tensor
outputs = model(**inputs)Accédez ensuite à "logits_per_image" dans la sortie du modèle pour obtenir la sortie du modèle.
Les logits sont essentiellement des prédictions brutes non normalisées du réseau. Puisque nous fournissons uniquement une chaîne de texte et un tenseur représentant la scène dans la vidéo, la structure du logit sera une prédiction à valeur unique.
logits_per_image = outputs.logits_per_image probs = logits_per_image.squeeze() prob_for_tensor = probs.item()
Ajoutez les probabilités pour chaque itération et divisez-les par le nombre total de tenseurs à la fin de l'opération pour obtenir la probabilité moyenne de la vidéo.
def clip_scenes_avg(tensors, text): avg_sum = 0.0 for tensor in tensors: # ... previous code snippets probs = probs.item() avg_sum += probs.item() return avg_sum / len(tensors)
最后在得到每个视频的概率并对概率进行排序后,返回请求的搜索结果数目。
import leveldb
import json
top_n = 1 # number of search results we want back
def video_metadata_by_id(id):
level_instance = leveldb.LevelDB('./dbs/videometadata_index')
b = level_instance.Get(bytes(id,'utf-8'))
return json.loads(b.decode('utf-8'))
results = []
for r in records:
# .. collect scene tensors
# r[0]: video id
return (clip_scenes_avg, r[0])
sorted = list(results)
sorted.sort(key=lambda x: x[0], reverse=True)
results = []
for s in sorted[:top_n]:
data = video_metadata_by_id(s[1])
results.append({
'video_id': s[1],
'score': s[0],
'video_uri': data['VideoURI']
})就是这样!现在就可以输入一些视频并测试搜索结果。
总结
通过CLIP可以轻松地创建一个频搜索引擎。使用预训练的CLIP模型和谷歌的LevelDB,我们可以对视频进行索引和处理,并使用自然语言输入进行搜索。通过这个搜索引擎使用户可以轻松地找到相关的视频,最主要的是我们并不需要大量的预处理或特征工程。
那么我们还能有什么改进呢?
- 使用场景的时间戳来确定最佳场景。
- 修改预测让他在计算集群上运行。
- 使用向量搜索引擎,例如Milvus 替代LevelDB
- 在索引的基础上建立推荐系统
- 等等
可以在这里找到本文的代码:https://github.com/GuyARoss/CLIP-video-search/tree/article-01。
以及这个修改版本:https://github.com/GuyARoss/CLIP-video-search。
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Tendances technologiques à surveiller en 2023
- Comment l'intelligence artificielle apporte un nouveau travail quotidien aux équipes des centres de données
- L'intelligence artificielle ou l'automatisation peuvent-elles résoudre le problème de la faible efficacité énergétique des bâtiments ?
- Co-fondateur d'OpenAI interviewé par Huang Renxun : les capacités de raisonnement de GPT-4 n'ont pas encore atteint les attentes
- Bing de Microsoft surpasse Google en termes de trafic de recherche grâce à la technologie OpenAI