
Maison >Périphériques technologiques >IA >Résumé de six méthodes courantes d'apprentissage continu : adapter les modèles ML aux nouvelles données tout en conservant les performances des anciennes données
Résumé de six méthodes courantes d'apprentissage continu : adapter les modèles ML aux nouvelles données tout en conservant les performances des anciennes données

- PHPzavant
- 2023-04-11 23:25:061550parcourir
L'apprentissage continu fait référence à un modèle qui apprend un grand nombre de tâches de manière séquentielle sans oublier les connaissances acquises lors des tâches précédentes. Il s'agit d'un concept important car, dans le cadre de l'apprentissage supervisé, les modèles d'apprentissage automatique sont formés pour être la meilleure fonction pour un ensemble de données ou une distribution de données donnée. Dans les environnements réels, les données sont rarement statiques et peuvent changer. Les modèles ML typiques peuvent subir une dégradation des performances lorsqu'ils sont confrontés à des données invisibles. Ce phénomène est appelé oubli catastrophique.

Une façon courante de résoudre ce type de problème consiste à recycler l'intégralité du modèle sur un nouvel ensemble de données plus grand contenant des données anciennes et nouvelles. Mais cette approche est souvent coûteuse. Il existe donc un domaine de recherche en ML qui se penche sur ce problème. Sur la base des recherches dans ce domaine, cet article discutera de 6 méthodes afin que le modèle puisse s'adapter aux nouvelles données tout en conservant les anciennes performances et en évitant d'avoir à effectuer le modèle. ensemble de données complet (ancien + nouveau) à recycler.
Prompt
Prompt L'idée découle de l'idée que les indices (courtes séquences de mots) dans GPT 3 peuvent aider les modèles à raisonner et à mieux répondre. Donc Prompt est traduit par invite dans cet article. Le réglage des indices consiste à utiliser de petits indices apprenables et à les alimenter en entrées du modèle avec des entrées réelles. Cela nous permet de former uniquement un petit modèle qui fournit des indications sur de nouvelles données sans recycler les poids du modèle.
Plus précisément, j'ai choisi l'exemple de l'utilisation d'invites pour la récupération intensive basée sur du texte, qui est adapté de l'article de Wang « Apprendre à inviter pour un apprentissage continu ».
Les auteurs de l'article décrivent leur idée à l'aide du diagramme suivant :
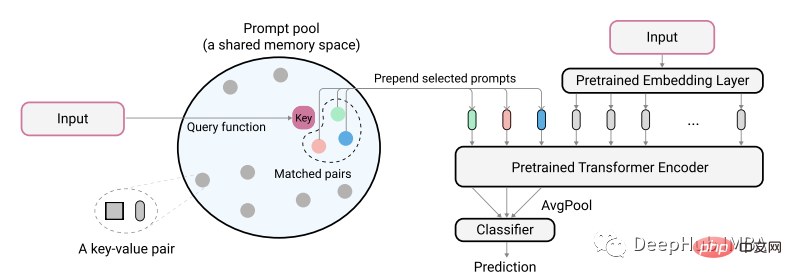
La saisie de texte codée réelle est utilisée comme clé pour identifier la plus petite paire correspondante du pool d'indices. Ces indices identifiés sont d'abord ajoutés aux intégrations de texte non codées avant d'être introduites dans le modèle. Le but est d'entraîner ces indices pour qu'ils représentent de nouvelles tâches tout en gardant l'ancien modèle inchangé. Les indices ici sont très petits, peut-être seulement 20 jetons par invite.
class PromptPool(nn.Module):
def __init__(self, M = 100, hidden_size = 768, length = 20, N=5):
super().__init__()
self.pool = nn.Parameter(torch.rand(M, length, hidden_size), requires_grad=True).float()
self.keys = nn.Parameter(torch.rand(M, hidden_size), requires_grad=True).float()
self.length = length
self.hidden = hidden_size
self.n = N
nn.init.xavier_normal_(self.pool)
nn.init.xavier_normal_(self.keys)
def init_weights(self, embedding):
pass
# function to select from pool based on index
def concat(self, indices, input_embeds):
subset = self.pool[indices, :] # 2, 2, 20, 768
subset = subset.to("cuda:0").reshape(indices.size(0),
self.n*self.length,
self.hidden) # 2, 40, 768
return torch.cat((subset, input_embeds), 1)
# x is cls output
def query_fn(self, x):
# encode input x to same dim as key using cosine
x = x / x.norm(dim=1)[:, None]
k = self.keys / self.keys.norm(dim=1)[:, None]
scores = torch.mm(x, k.transpose(0,1).to("cuda:0"))
# get argmin
subsets = torch.topk(scores, self.n, 1, False).indices # k smallest
return subsets
pool = PromptPool()Ensuite, nous utilisons l'ancien modèle de données entraîné pour entraîner les nouvelles données. Ici, nous entraînons uniquement le poids de la partie invite.
def train():
count = 0
print("*********** Started Training *************")
start = time.time()
for epoch in range(40):
model.eval()
pool.train()
optimizer.zero_grad(set_to_none=True)
lap = time.time()
for batch in iter(train_dataloader):
count += 1
q, p, train_labels = batch
queries_emb = model(input_ids=q['input_ids'].to("cuda:0"),
attention_mask=q['attention_mask'].to("cuda:0"))
passage_emb = model(input_ids=p['input_ids'].to("cuda:0"),
attention_mask=p['attention_mask'].to("cuda:0"))
# pool
q_idx = pool.query_fn(queries_emb)
raw_qembedding = model.model.embeddings(input_ids=q['input_ids'].to("cuda:0"))
q = pool.concat(indices=q_idx, input_embeds=raw_qembedding)
p_idx = pool.query_fn(passage_emb)
raw_pembedding = model.model.embeddings(input_ids=p['input_ids'].to("cuda:0"))
p = pool.concat(indices=p_idx, input_embeds=raw_pembedding)
qattention_mask = torch.ones(batch_size, q.size(1))
pattention_mask = torch.ones(batch_size, p.size(1))
queries_emb = model.model(inputs_embeds=q,
attention_mask=qattention_mask.to("cuda:0")).last_hidden_state
passage_emb = model.model(inputs_embeds=p,
attention_mask=pattention_mask.to("cuda:0")).last_hidden_state
q_cls = queries_emb[:, pool.n*pool.length+1, :]
p_cls = passage_emb[:, pool.n*pool.length+1, :]
loss, ql, pl = calc_loss(q_cls, p_cls)
loss.backward()
optimizer.step()
optimizer.zero_grad(set_to_none=True)
if count % 10 == 0:
print("Model Loss:", round(loss.item(),4),
"| QL:", round(ql.item(),4), "| PL:", round(pl.item(),4),
"| Took:", round(time.time() - lap), "secondsn")
lap = time.time()
if count % 40 == 0 and count > 0:
print("model saved")
torch.save(model.state_dict(), model_PATH)
torch.save(pool.state_dict(), pool_PATH)
if count == 4600: return
print("Training Took:", round(time.time() - start), "seconds")
print("n*********** Training Complete *************")Une fois la formation terminée, le processus d'inférence ultérieur doit combiner l'entrée avec les indices récupérés. Par exemple, cet exemple a obtenu des performances de -93 % pour le nouveau pool d'indices de données et de -94 % pour la formation complète (ancienne + nouvelle). Ceci est similaire aux performances mentionnées dans l’article original. Mais la mise en garde est que les résultats peuvent varier en fonction de la tâche, et vous devriez tenter des expériences pour savoir ce qui fonctionne le mieux.
Pour que cette méthode vaille la peine d'être envisagée, elle doit être capable de préserver >80 % des performances de l'ancien modèle sur les anciennes données, tandis que les astuces doivent également aider le modèle à obtenir de bonnes performances sur les nouvelles données.
L'inconvénient de cette méthode est qu'elle nécessite l'utilisation d'un pool d'indices, ce qui ajoute du temps supplémentaire. Il ne s’agit pas d’une solution permanente, mais elle est réalisable pour l’instant et peut-être que de nouvelles méthodes apparaîtront à l’avenir.
Distillation de données
Vous avez peut-être entendu parler du terme distillation des connaissances, qui est une technique qui utilise les poids d'un modèle d'enseignant pour guider et former des modèles à plus petite échelle. La distillation des données fonctionne de la même manière, en utilisant des pondérations à partir de données réelles pour former des sous-ensembles plus petits de données. Étant donné que les signaux clés de l'ensemble de données sont affinés et condensés en ensembles de données plus petits, notre formation sur les nouvelles données n'a besoin que de quelques données affinées pour maintenir les anciennes performances.
Dans cet exemple, j'applique la distillation de données à une tâche de récupération dense (texte). Personne d'autre n'utilise actuellement cette méthode dans ce domaine, les résultats ne sont donc peut-être pas les meilleurs, mais si vous utilisez cette méthode pour la classification de texte, vous devriez obtenir de bons résultats.
Essentiellement, l'idée de la distillation des données textuelles est issue d'un article de Li intitulé Data Distillation for Text Classification, qui s'inspire de la distillation des ensembles de données de Wang, où il distillait des données d'image. Li décrit la tâche de distillation des données textuelles avec le diagramme suivant :
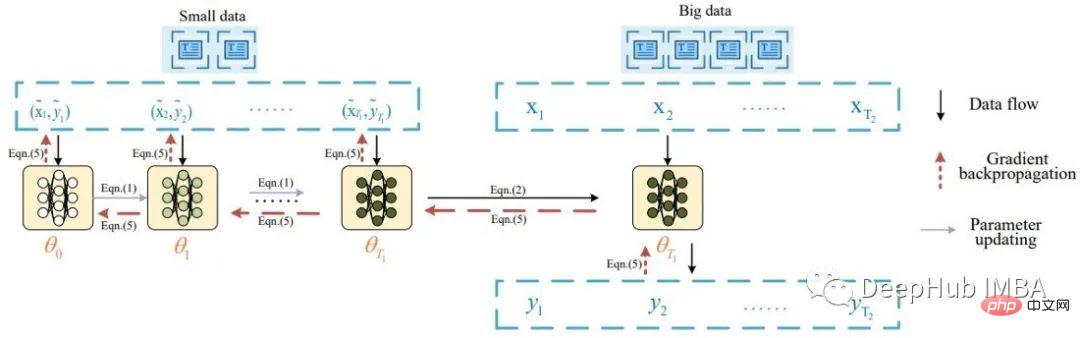
Selon l'article, un lot de données distillées est d'abord introduit dans le modèle pour mettre à jour ses pondérations. Le modèle mis à jour est ensuite évalué à l'aide de données réelles et le signal est rétropropagé à l'ensemble de données distillé. L'article rapporte de bons résultats de classification (précision > 80 %) sur 8 ensembles de données de référence publics.
Suite aux idées proposées, j'ai apporté quelques modifications mineures et utilisé un lot de données distillées et plusieurs données réelles. Voici le code pour créer des données distillées pour un entraînement intensif à la récupération :
class DistilledData(nn.Module):
def __init__(self, num_labels, M, q_len=64, hidden_size=768):
super().__init__()
self.num_samples = M
self.q_len = q_len
self.num_labels = num_labels
self.data = nn.Parameter(torch.rand(num_labels, M, q_len, hidden_size), requires_grad=True) # i.e. shape: 1000, 4, 64, 768
# init using model embedding, xavier, or load from state dict
def init_weights(self, model, path=None):
if model:
self.data.requires_grad = False
print("Init weights using model embedding")
raw_embedding = model.model.get_input_embeddings()
soft_embeds = raw_embedding.weight[:, :].clone().detach()
nums = soft_embeds.size(0)
for i1 in range(self.num_labels):
for i2 in range(self.num_samples):
for i3 in range(self.q_len):
random_idx = random.randint(0, nums-1)
self.data[i1, i2, i3, :] = soft_embeds[random_idx, :]
print(self.data.shape)
self.data.requires_grad = True
if not path:
nn.init.xavier_normal_(self.data)
else:
distilled_data.load_state_dict(torch.load(path), strict=False)
# function to sample a passage and positive sample as in the article, i am doing dense retrieval
def get_sample(self, label):
q_idx = random.randint(0, self.num_samples-1)
sampled_dist_q = self.data[label, q_idx, :, :]
p_idx = random.randint(0, self.num_samples-1)
while q_idx == p_idx:
p_idx = random.randint(0, self.num_samples-1)
sampled_dist_p = self.data[label, p_idx, :, :]
return sampled_dist_q, sampled_dist_p, q_idx, p_idxC'est le code pour extraire le signal sur les données distillées
def distll_train(chunk_size=32):
count, times = 0, 0
print("*********** Started Training *************")
start = time.time()
lap = time.time()
for epoch in range(40):
distilled_data.train()
for batch in iter(train_dataloader):
count += 1
# get real query, pos, label, distilled data query, distilled data pos, ... from batch
q, p, train_labels, dq, dp, q_indexes, p_indexes = batch
for idx in range(0, dq['input_ids'].size(0), chunk_size):
model.train()
with torch.enable_grad():
# train on distiled data first
x1 = dq['input_ids'][idx:idx+chunk_size].clone().detach().requires_grad_(True)
x2 = dp['input_ids'][idx:idx+chunk_size].clone().detach().requires_grad_(True)
q_emb = model(inputs_embeds=x1.to("cuda:0"),
attention_mask=dq['attention_mask'][idx:idx+chunk_size].to("cuda:0")).cpu()
p_emb = model(inputs_embeds=x2.to("cuda:0"),
attention_mask=dp['attention_mask'][idx:idx+chunk_size].to("cuda:0"))
loss = default_loss(q_emb.to("cuda:0"), p_emb)
del q_emb, p_emb
loss.backward(retain_graph=True, create_graph=False)
state_dict = model.state_dict()
# update model weights
with torch.no_grad():
for idx, param in enumerate(model.parameters()):
if param.requires_grad and not param.grad is None:
param.data -= (param.grad*3e-5)
# real data
model.eval()
q_embs = []
p_embs = []
for k in range(0, len(q['input_ids']), chunk_size):
with torch.no_grad():
q_emb = model(input_ids=q['input_ids'][k:k+chunk_size].to("cuda:0"),).cpu()
p_emb = model(input_ids=p['input_ids'][k:k+chunk_size].to("cuda:0"),).cpu()
q_embs.append(q_emb)
p_embs.append(p_emb)
q_embs = torch.cat(q_embs, 0)
p_embs = torch.cat(p_embs, 0)
r_loss = default_loss(q_embs.to("cuda:0"), p_embs.to("cuda:0"))
del q_embs, p_embs
# distill backward
if count % 2 == 0:
d_grad = torch.autograd.grad(inputs=[x1.to("cuda:0")],#, x2.to("cuda:0")],
outputs=loss,
grad_outputs=r_loss)
indexes = q_indexes
else:
d_grad = torch.autograd.grad(inputs=[x2.to("cuda:0")],
outputs=loss,
grad_outputs=r_loss)
indexes = p_indexes
loss.detach()
r_loss.detach()
grads = torch.zeros(distilled_data.data.shape) # lbl, 10, 100, 768
for i, k in enumerate(indexes):
grads[train_labels[i], k, :, :] = grads[train_labels[i], k, :, :].to("cuda:0")
+ d_grad[0][i, :, :]
distilled_data.data.grad = grads
data_optimizer.step()
data_optimizer.zero_grad(set_to_none=True)
model.load_state_dict(state_dict)
model_optimizer.step()
model_optimizer.zero_grad(set_to_none=True)
if count % 10 == 0:
print("Count:", count ,"| Data:", round(loss.item(), 4), "| Model:",
round(r_loss.item(),4), "| Time:", round(time.time() - lap, 4))
# print()
lap = time.time()
if count % 100 == 0:
torch.save(model.state_dict(), model_PATH)
torch.save(distilled_data.state_dict(), distill_PATH)
if loss < 0.1 and r_loss < 1:
times += 1
if times > 100:
print("Training Took:", round(time.time() - start), "seconds")
print("n*********** Training Complete *************")
return
del loss, r_loss, grads, q, p, train_labels, dq, dp, x1, x2, state_dict
print("Training Took:", round(time.time() - start), "seconds")
print("n*********** Training Complete *************")Le code tel que le chargement des données est omis ici. Après avoir entraîné les données distillées, nous pouvons. transmettre Entraînez un nouveau modèle à l'utiliser, par exemple en le combinant avec de nouvelles données.
Selon mes expériences, un modèle entraîné sur des données distillées (contenant seulement 4 échantillons par étiquette) a obtenu la meilleure performance de 66 %, tandis qu'un modèle entraîné entièrement sur les données originales a également obtenu la meilleure performance de 66 %. Le modèle normal non entraîné a atteint une performance de 45 %. Comme mentionné ci-dessus, ces chiffres ne conviennent peut-être pas aux tâches de récupération intensives, mais seront bien meilleurs pour les données catégorielles.
Pour que cette méthode soit utile lors de l'ajustement du modèle à de nouvelles données, il faut pouvoir extraire un ensemble de données beaucoup plus petit que les données d'origine (c'est-à-dire ~ 1 %). Des données affinées peuvent également vous offrir une performance légèrement inférieure ou égale aux méthodes d'apprentissage actif.
L'avantage de cette méthode est qu'elle peut créer des données distillées pour une utilisation permanente. L’inconvénient est que les données extraites ne sont pas interprétables et nécessitent un temps de formation supplémentaire.
Curriculum/Formation active
La formation par programme est une méthode dans laquelle il devient progressivement plus difficile de fournir des échantillons de formation au modèle pendant la formation. Lors de la formation sur de nouvelles données, cette méthode nécessite un étiquetage manuel des tâches, une classification des tâches en faciles, moyennes ou difficiles, puis un échantillonnage des données. Pour comprendre ce que signifie pour un modèle qu'il soit facile, moyen ou difficile, je prends cette photo comme exemple :
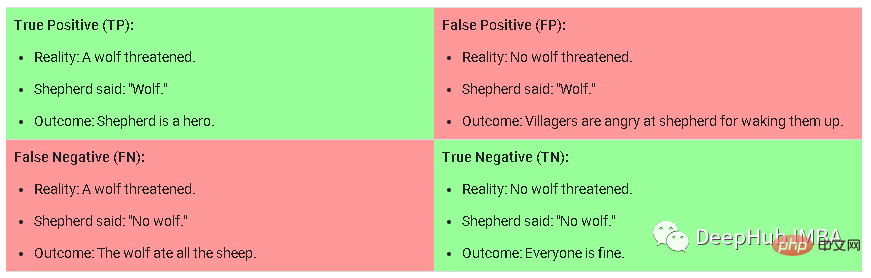
C'est la matrice de confusion dans la tâche de classification. Les échantillons difficiles sont des faux positifs, qui font référence au modèle. prédictions La probabilité d'être vrai est élevée, mais ce n'est pas réellement un échantillon qui est vrai. Les échantillons moyens sont ceux qui ont une probabilité moyenne à élevée d'être corrects mais qui sont vrais négatifs en dessous du seuil de prédiction. Les échantillons simples sont ceux qui ont la plus faible probabilité d'être vrais positifs/négatifs.
Récupération avec interférence maximale
Il s'agit d'une méthode introduite par Rahaf dans un article (1908.04742) intitulé "Apprentissage continu en ligne avec récupération avec interférence maximale". L'idée principale est que pour chaque nouveau lot de données en cours de formation, si vous mettez à jour les pondérations du modèle pour des données plus récentes, vous devrez identifier les échantillons plus anciens qui sont les plus affectés en termes de valeurs de perte. Une mémoire de taille limitée composée d'anciennes données est conservée et les échantillons les plus perturbants sont récupérés avec chaque nouveau lot de données pour s'entraîner ensemble.
Cet article est un article bien établi dans le domaine de l'apprentissage continu et comporte de nombreuses citations, il peut donc s'appliquer à votre cas.
Augmentation de récupération
L'augmentation de récupération fait référence à la technique d'augmentation des entrées, des échantillons, etc. en récupérant des éléments d'une collection. Il s’agit d’un concept général plutôt que d’une technologie spécifique. La plupart des méthodes dont nous avons discuté jusqu'à présent sont dans une certaine mesure des opérations liées à la récupération. L'article d'Izacard intitulé Few-shot Learning with Retrieval Augmented Language Models utilise des modèles plus petits pour obtenir d'excellentes performances dans l'apprentissage en quelques étapes. L'amélioration de la récupération est également utilisée dans de nombreuses autres situations, telles que la génération de mots ou la réponse à des questions factuelles.
L'extension du modèle pour utiliser des couches supplémentaires pendant l'entraînement est la méthode la plus courante et la plus simple, mais elle n'est pas nécessairement efficace, elle ne sera donc pas discutée en détail ici. Un exemple ici est l'apprentissage efficace en quelques étapes sans invites. L’utilisation de couches supplémentaires est souvent le moyen le plus simple, mais éprouvé, d’obtenir de bonnes performances sur les anciennes et les nouvelles données. L'idée principale est de garder les poids du modèle fixes et d'entraîner une ou plusieurs couches sur de nouvelles données avec une perte de classification.
Résumé Dans cet article, j'ai présenté 6 méthodes que vous pouvez utiliser lors de la formation d'un modèle sur de nouvelles données. Comme toujours, il faut expérimenter et décider quelle méthode fonctionne le mieux, mais il est important de noter qu'il existe de nombreuses méthodes en plus de celles que j'ai citées ci-dessus, par exemple la distillation des données est un domaine actif en vision par ordinateur et vous pouvez en trouver beaucoup sur papier. . Une dernière remarque : pour que ces méthodes soient utiles, elles doivent atteindre de bonnes performances sur les données anciennes et nouvelles.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Tendances technologiques à surveiller en 2023
- Comment l'intelligence artificielle apporte un nouveau travail quotidien aux équipes des centres de données
- L'intelligence artificielle ou l'automatisation peuvent-elles résoudre le problème de la faible efficacité énergétique des bâtiments ?
- Co-fondateur d'OpenAI interviewé par Huang Renxun : les capacités de raisonnement de GPT-4 n'ont pas encore atteint les attentes
- Bing de Microsoft surpasse Google en termes de trafic de recherche grâce à la technologie OpenAI