
Maison >Périphériques technologiques >IA >La pratique des algorithmes d'apprentissage contrastifs à Zhuanzhuan
La pratique des algorithmes d'apprentissage contrastifs à Zhuanzhuan

- 王林avant
- 2023-04-11 21:25:122014parcourir
- 1 Qu'est-ce que l'apprentissage contrastif
- 1.1 Définition de l'apprentissage contrastif
- 1.2 Principe de l'apprentissage contrastif
- 1.3 Série d'algorithmes d'apprentissage contrastif classiques
- 2 Application de l'apprentissage contrastif
- 3 L'apprentissage contrastif en transformation La pratique du Zhuan
- 3.1 La pratique du CL en recommandation et en rappel
- 3.2 La planification future du CL à Zhuanzhuan
1 Qu'est-ce que l'apprentissage contrastif
1.1 La définition de l'apprentissage contrastif
L'apprentissage contrastif (AC) est un nouveau concept ces dernières années Une direction de recherche populaire dans le domaine de l'IA a attiré l'attention de nombreux chercheurs. Sa méthode d'apprentissage auto-supervisé a été désignée comme l'avenir de l'IA par de grands noms tels que Bengio et LeCun à l'ICLR 2020, et l'a depuis été. répertorié dans NIPS, ACL et KDD, CIKM et d'autres conférences majeures, Google, Facebook, DeepMind, Alibaba, Tencent, Byte et d'autres grands fabricants y ont également investi. Les travaux liés au CL ont également maximisé le CV, et même SOTA. sur certaines questions de PNL, dans le cercle de l'IA, on peut dire que les feux de la rampe sont sans précédent. La source technique de
CL vient de l'apprentissage métrique. L'idée générale est de définir les exemples positifs et négatifs de l'échantillon, ainsi que la relation de cartographie (mapper l'entité vers un nouvel espace). L'objectif d'optimisation est de créer les exemples positifs. correspond à l'échantillon cible dans l'espace. La distance est plus proche, tandis que l'exemple négatif est relativement éloigné. Pour cette raison, CL ressemble beaucoup à l'idée du rappel vectoriel, mais en fait, il existe des différences essentielles entre les deux. Le rappel vectoriel est un type d'apprentissage supervisé, avec des données d'étiquette claires et un accent accru sur la sélection des négatifs. échantillons ( Connu sous le nom de « doctrine » selon laquelle les échantillons négatifs sont rois) ; et CL est une branche de l'apprentissage auto-supervisé (un paradigme d'apprentissage non supervisé) qui ne nécessite pas d'informations d'étiquette manuelle et utilise directement les données elles-mêmes comme informations de supervision pour apprendre échantillons Expression caractéristique des données, puis référencés dans les tâches en aval. De plus, la technologie de base de CL est l’augmentation des données, qui se concentre davantage sur la façon de construire des échantillons positifs. L'image ci-dessous est un organigramme global abstrait du CL

Les informations d'étiquette de l'apprentissage contrastif proviennent des données elles-mêmes, et le module de base est l'amélioration des données. La technologie d'amélioration des données dans le domaine de l'image est relativement intuitive. Par exemple, des opérations telles que la rotation de l'image, l'occlusion, l'extraction partielle, la coloration et le flou peuvent produire une nouvelle image généralement similaire à l'image originale mais partiellement différente (c'est-à-dire la nouvelle image améliorée). Image), l'image ci-dessous fait partie de la méthode d'amélioration des données d'image (de SimCLR[1]).

1.2 Principes de l'apprentissage contrastif
En ce qui concerne les principes du CL, nous devons mentionner l'apprentissage auto-supervisé. Il évite le coût élevé de l'annotation manuelle et la rareté de la faible couverture des étiquettes, ce qui facilite l'apprentissage. apprendre les caractéristiques générales express. L’apprentissage auto-supervisé peut être divisé en deux grandes catégories : les méthodes génératives et les méthodes contrastives. Le représentant typique de la méthode générative est l'auto-encodeur, et le représentant classique de l'apprentissage contrastif est SimCLR de l'ICLR 2020, qui apprend les représentations de caractéristiques grâce à la comparaison d'échantillons positifs et négatifs (améliorés) dans l'espace de caractéristiques. Par rapport aux méthodes génératives, l'avantage des méthodes contrastives est qu'elles n'ont pas besoin de reconstruire des échantillons au niveau des pixels, mais seulement d'apprendre la distinction dans l'espace des caractéristiques, ce qui simplifie l'optimisation associée. L'auteur estime que l'efficacité du CL se reflète principalement dans la différentiabilité de l'apprentissage de la représentation des éléments, et que l'apprentissage de la différentiabilité repose sur les idées de construction d'échantillons positifs et négatifs, ainsi que sur la structure spécifique du modèle et les objectifs d'optimisation. Combiné au processus de mise en œuvre du CL,
Dr Zhang[2] résume trois questions auxquelles le CL doit répondre, qui sont aussi ses caractéristiques typiques qui le distinguent de l'apprentissage métrique, à savoir (1) comment construire du positif exemples et exemples négatifs Par exemple, comment l'amélioration des données est mise en œuvre spécifiquement ; (2) Comment construire la fonction de mappage de l'encodeur, non seulement pour conserver autant d'informations originales que possible, mais également pour éviter les problèmes d'effondrement ; pour concevoir la fonction de perte, la perte NCE actuellement couramment utilisée, comme le montre la formule suivante. Il n’est pas difficile de voir que ces trois questions fondamentales correspondent aux trois éléments de la modélisation : échantillon, modèle et algorithme d’optimisation.
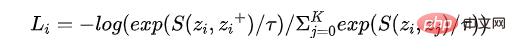 Il ressort de la formule de perte que la partie numérateur souligne que plus la distance à l'exemple positif est proche, meilleure est la fonction S qui mesure la similarité. Le dénominateur souligne que plus on s'éloigne de l'exemple négatif, mieux c'est. Plus la perte est faible, plus la distinction correspondante est élevée.
Il ressort de la formule de perte que la partie numérateur souligne que plus la distance à l'exemple positif est proche, meilleure est la fonction S qui mesure la similarité. Le dénominateur souligne que plus on s'éloigne de l'exemple négatif, mieux c'est. Plus la perte est faible, plus la distinction correspondante est élevée.
Parmi ces trois problèmes fondamentaux, l'amélioration des données est l'innovation fondamentale de l'algorithme CL. Différentes méthodes d'amélioration sont la garantie de base de l'efficacité de l'algorithme et l'identité des principaux algorithmes CL est généralement implémentée à l'aide de ; réseaux de neurones ; à l'exception de la perte NCE. De plus, il existe d'autres variantes de perte, telles que Google[3] qui proposait une perte de contraste supervisée.
1.3 Série d'algorithmes d'apprentissage contrastés classiques
CL est un algorithme d'apprentissage auto-supervisé. Lorsqu'il s'agit d'apprentissage auto-supervisé, Bert est probablement un sujet incontournable dans le domaine de la PNL. Le modèle est utilisé dans de nombreux problèmes. Une percée a été réalisée dans la solution Puisque l'auto-supervision peut réussir en PNL, la vision par ordinateur ne peut-elle pas également réussir ? En fait, le succès de Bert dans le domaine de la PNL a également directement stimulé l'apparition et le développement de la CL dans le domaine des images. Compte tenu du fait que l'amélioration des données peut être effectuée de manière intuitive dans le domaine de l'image, CL est également le premier à progresser dans le domaine du CV. Par exemple, l'opportunité de développement de l'algorithme CL - SimCLR, ses points d'innovation comprennent principalement (. 1) explorer la combinaison de plusieurs technologies différentes d'amélioration des données, la meilleure est sélectionnée ; (2) Un projecteur de cartographie non linéaire est ajouté après l'encodeur, principalement parce que la représentation vectorielle apprise par l'encodeur inclura des informations améliorées, tandis que le projecteur vise à supprimer cette partie de l’influence et revenir à l’essence des données. Plus tard, les étudiants de Hinton ont implémenté SimCLR v2 basé sur SimCLR. La principale amélioration concernait la structure du réseau de l'encodeur. Ils se sont également inspirés de l'idée de la banque de mémoire utilisée par MoCo pour améliorer davantage SOTA.
En fait, avant SimCLR, Kaiming Il a proposé fin 2019 un autre algorithme classique d'apprentissage contrastifMoCo[4] L'idée principale est que puisque la comparaison est effectuée entre des échantillons positifs et négatifs, alors. augmenter le nombre d'échantillons négatifs peut augmenter la difficulté de la tâche d'apprentissage, améliorant ainsi les performances du modèle est une idée classique pour résoudre ce problème, mais cela ne peut pas éviter le problème de représentation incohérente. Compte tenu de cela, l'algorithme MoCo. propose d'utiliser l'élan pour mettre à jour les paramètres de l'encodeur, résolvant ainsi le problème du codage incohérent des anciens et des nouveaux échantillons candidats. Plus tard, Kaiming He a proposé MoCo v2 sur la base de MoCo (après la proposition de SimCLR). Le cadre principal du modèle n'a pas été modifié et des détails tels que la méthode d'amélioration des données, la structure de l'encodeur et le taux d'apprentissage ont été optimisés.
2 Application de l'apprentissage contrastif
L'apprentissage contrastif n'est pas seulement une direction de recherche populaire dans le milieu universitaire dans de nombreux domaines tels que les images, le texte et la multimodalité, mais a également été appliqué dans l'industrie représentée par les systèmes de recommandation.
Google applique CL au système de recommandationGoogle SSL[5] Le but est d'apprendre des représentations vectorielles de haute qualité pour les éléments impopulaires et de niche, aidant ainsi à résoudre le problème de démarrage à froid des recommandations. Sa technologie d'amélioration des données utilise principalement les méthodes de masquage de caractéristiques aléatoires (RFM) et de masquage de caractéristiques corrélées (CFM) (CFM résout le problème selon lequel RFM peut construire des variantes invalides dans une certaine mesure), puis CL est combiné avec les tours jumelles sous la forme de une tour auxiliaire. Les tâches principales de rappel sont entraînées ensemble. Le processus global est illustré dans la figure ci-dessous

Pendant le processus d'entraînement du modèle, les éléments de la tâche principale proviennent principalement du journal d'exposition, donc il est également respectueux des éléments populaires dans la tête. Afin d'éliminer l'effet Matthew, l'impact de la construction de l'échantillon dans la tâche auxiliaire doit prendre en compte une répartition différente de celle de la tâche principale. Les CL ultérieures se sont également appuyées sur cette réflexion dans le processus de pratique. de Zhuanzhuan pour assurer une couverture complète des résultats d’apprentissage du modèle.
L'amélioration des données ne se limite pas au côté article, Alibaba-Seq2seq[6] applique l'idée de CL au problème de recommandation de séquence, c'est-à-dire saisir la séquence de comportement de l'utilisateur et prédire le prochain élément interactif possible. Plus précisément, son amélioration des données s'applique principalement aux caractéristiques des séquences de comportement de l'utilisateur. La séquence de comportement historique de l'utilisateur est divisée en deux sous-séquences selon des séries temporelles. En tant que représentation de l'utilisateur après l'amélioration des données, elle est introduite dans le jumeau. modèle de tour. Plus les résultats finaux sont similaires, mieux c'est. Dans le même temps, afin de modéliser explicitement les multiples intérêts des utilisateurs, cet article extrait plusieurs vecteurs dans la partie Encoder au lieu de les compresser en un seul vecteur utilisateur. Car avec le découpage des sous-séquences et la construction d'exemples positifs et négatifs, les utilisateurs disposent naturellement de représentations vectorielles de plusieurs séquences de comportement. Dans les exemples positifs, le vecteur de la partie précédente du comportement historique de l'utilisateur est proche du vecteur de la dernière partie de. le comportement historique. , et dans l'exemple négatif, la distance entre les différents utilisateurs est relativement grande, et même pour un même utilisateur, les représentations vectorielles des produits dans les différentes catégories sont relativement éloignées.
CL peut également être appliqué en combinaison avec d'autres paradigmes d'apprentissage, Apprentissage par comparaison de graphiques[7], le cadre global est présenté dans la figure ci-dessous

GCL améliore généralement les données du graphique en supprimant de manière aléatoire des points ou des arêtes du graphique, tandis que l'auteur de cet article préfère conserver les structures et attributs importants inchangés, et des perturbations se produisent sur des arêtes ou des nœuds sans importance.
3 L'apprentissage contrastif a réussi dans la pratique du Zhuanzhuan
dans le domaine de l'image, et il est également possible dans le domaine du texte, comme l'algorithme Meituan-ConSERT[8], dans des expériences sur tâches de correspondance sémantique de phrases, il a été comparé Il est 8 % plus élevé que le SOTA précédent (BERT-flow) et peut toujours montrer une bonne amélioration des performances avec un petit nombre d'échantillons. Cet algorithme applique l'amélioration des données à la couche d'intégration et utilise la méthode de génération implicite d'échantillons améliorés. Plus précisément, quatre méthodes d'amélioration des données sont proposées : attaque contradictoire, mélange de jetons, coupure et abandon, ces quatre méthodes sont toutes obtenues en ajustant la matrice d'intégration. ce qui est plus efficace que la méthode d’amélioration explicite.
3.1 Pratique de CL en matière de recommandation de rappels
La plateforme Zhuanzhuan s'engage à promouvoir le meilleur développement d'une économie circulaire à faible émission de carbone et peut couvrir toutes les catégories de biens. Ces dernières années, elle a obtenu de bons résultats dans le domaine de la téléphonie mobile. 3C. La pratique de CL dans le système de recommandation Zhuanzhuan choisit également une idée d'application basée sur du texte. Compte tenu des attributs uniques des transactions d'occasion, les problèmes à résoudre incluent (1) l'attribut orphelin des biens d'occasion, qui constitue le vecteur. de la classe ID ne s'applique pas ; (2) Comment l'amélioration des données est mise en œuvre ; (3) Comment les exemples positifs et négatifs sont construits (4) Quelle est la structure du modèle de l'encodeur (y compris les problèmes de conception de perte ); Pour résoudre ces quatre problèmes, nous les expliquerons en détail en conjonction avec l'organigramme global ci-dessous
Compte tenu du problème des attributs orphelins des produits d'occasion, nous utilisons des vecteurs textuels comme représentation du produit. nous utilisons la description textuelle de la collection de produits (y compris le titre et le contenu), formons le modèle word2vec et obtenons la représentation vectorielle du produit grâce à une mise en commun basée sur le vecteur de mots.
L'algorithme Auto Encoder est l'une des méthodes d'amélioration des données couramment utilisées dans le domaine de l'apprentissage par comparaison de textes (en outre, il existe différentes idées telles que la traduction automatique et le CBERT. Nous utilisons également l'algorithme AE pour entraîner le modèle et apprendre). vecteurs de produit et utilisez le vecteur intermédiaire de l'algorithme comme représentation vectorielle améliorée du produit, et il existe un exemple positif.
Le principe de production d'exemples négatifs consiste à sélectionner au hasard des produits différents dans le lot. La base de jugement des produits similaires est calculée en fonction du comportement de clic postérieur de l'utilisateur. Dans les résultats de rappel des systèmes de recommandation représentés par CF (filtrage collaboratif), les combinaisons de produits qui peuvent être rappelées via un comportement de clic commun sont considérées comme similaires, sinon elles sont considérées comme différentes. La raison pour laquelle la base comportementale est utilisée pour déterminer la similarité est, d'une part, pour introduire le comportement de l'utilisateur et obtenir une combinaison organique de texte et de comportement, et d'autre part, pour correspondre autant que possible aux objectifs commerciaux.
Spécifiquement pour la partie Encoder, nous utilisons une structure à deux tours similaire au réseau jumeau. Nous alimentons respectivement les vecteurs de texte des échantillons (positifs ou positifs ou négatifs) pour entraîner le modèle de classification. couche de réseau neuronal entièrement connecté. Les tours partagent les paramètres de ce réseau et optimisent les paramètres du modèle en optimisant la perte d'entropie croisée. Dans l'industrie actuelle, l'objectif de formation du modèle à deux tours dans la plupart des systèmes de recommandation est le comportement postérieur de l'utilisateur (clics, collections, commandes, etc.), et notre objectif de formation est de savoir si les échantillons sont similaires ou non. nous adoptons la forme d'un réseau jumelé, c'est aussi parce que cela peut garantir la couverture des résultats d'apprentissage.
Selon les idées conventionnelles de CL, le vecteur d'entrée de la partie finale de l'encodeur est extrait sous forme de représentation vectorielle du produit, qui peut être ensuite appliquée dans le rappel, le classement approximatif et même le classement fin du système de recommandation. Actuellement, le module de rappel du système de recommandation Zhuanzhuan a été mis en œuvre, ce qui a augmenté le taux de commande en ligne et de sacs de plus de 10 %.
3.2 Plan futur de CL à Zhuanzhuan
Grâce à une évaluation manuelle et à des expériences AB en ligne, l'efficacité de la représentation vectorielle apprise de CL a été pleinement confirmée. Une fois le module de rappel implémenté, il peut être utilisé dans d'autres modules du système de recommandation et même. autres scénarios d'algorithme Par extension. L'apprentissage de la représentation vectorielle du produit de manière préalable à la formation (bien sûr, vous pouvez également apprendre la représentation vectorielle de l'utilisateur) n'est qu'un chemin d'application. CL fournit davantage un cadre d'apprentissage ou une idée d'apprentissage grâce à l'amélioration et à la comparaison des données. différenciabilité des éléments.Cette idée peut être naturellement introduite dans le module de classement du système de recommandation, car le problème de classement peut également être compris comme le problème de différenciabilité des éléments.
À propos de l'auteur
Li Guangming, ingénieur senior en algorithmes. Participé à la construction de systèmes d'algorithmes pour l'algorithme de recherche Zhuanzhuan, l'algorithme de recommandation, le portrait d'utilisateur et d'autres systèmes, et a des applications pratiques dans le GNN, l'apprentissage de petits échantillons, l'apprentissage comparatif et d'autres domaines connexes.
Références
[1]SimCLR : A_Simple_Framework_for_Contrastive_Learning_of_Visual_Representations
[2]Zhang Junlin https://www.php.cn/link/be7ec : aca 534f98c4ca134e527b12d4c8
[ 3]Google : Supervised_Contrastive_Learning
[4]MoCo : Momentum_Contrast_for_Unsupervised_Visual_Representation_Learning
[5]SSL : Self-supervised_Learning_for_Large-scale_Item_Recommendations
[6 ]Ali-Seq2seq : Disentangled_Self-Supervision_in_Sequential_Recommenders
[7] GCL : Graph_contrastive_learning_with_adaptive_augmentation
[8]ConSERT : ConSERT:_A_Contrastive_Framework_for_Self-Supervised_Sentence_Representation_Transfer
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Tendances technologiques à surveiller en 2023
- Comment l'intelligence artificielle apporte un nouveau travail quotidien aux équipes des centres de données
- L'intelligence artificielle ou l'automatisation peuvent-elles résoudre le problème de la faible efficacité énergétique des bâtiments ?
- Co-fondateur d'OpenAI interviewé par Huang Renxun : les capacités de raisonnement de GPT-4 n'ont pas encore atteint les attentes
- Bing de Microsoft surpasse Google en termes de trafic de recherche grâce à la technologie OpenAI