
Maison >Périphériques technologiques >IA >Développer des systèmes de sécurité IA utilisant la biométrie de pointe
Développer des systèmes de sécurité IA utilisant la biométrie de pointe

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBavant
- 2023-04-11 20:55:141596parcourir
Traducteur | Zhu Xianzhong
Reviewer | Sun Shujuan
La sécurité de l'espace de travail peut être une perte d'argent laborieuse et chronophage dans les entreprises, en particulier celles qui gèrent des informations sensibles ou qui ont plusieurs bureaux avec des milliers d'employés. Les clés électroniques sont l'une des options standards pour automatiser les systèmes de sécurité, mais dans la pratique, il existe encore de nombreux inconvénients tels que des clés perdues, oubliées ou contrefaites.
La biométrie est une alternative fiable aux mesures de sécurité traditionnelles car elle représente le concept d'authentification « ce que vous êtes ». Cela signifie que les utilisateurs peuvent utiliser leurs caractéristiques uniques, telles que leurs empreintes digitales, leurs iris, leur voix ou leur visage, pour prouver qu'ils ont accès à un espace. L'utilisation de la biométrie comme méthode d'authentification garantit que les clés ne peuvent pas être perdues, oubliées ou contrefaites. Par conséquent, dans cet article, nous parlerons de notre expérience dans le développement de la biométrie de pointe, qui est une combinaison de dispositifs de pointe, d'intelligence artificielle et de biométrie pour mettre en œuvre un système de surveillance de sécurité basé sur la technologie de l'intelligence artificielle.
Qu'est-ce que la biométrie de pointe ?
Tout d’abord, clarifions : qu’est-ce que l’IA de pointe ? Dans l’architecture d’IA traditionnelle, il est courant de déployer des modèles et des données dans le cloud, séparés des appareils d’exploitation ou des capteurs matériels. Cela nous oblige à maintenir les serveurs cloud dans un bon état, à maintenir une connexion Internet stable et à payer pour les services cloud. Si le stockage distant n’est pas accessible en cas de perte de connexion Internet, l’ensemble de l’application IA devient inutile.
« En revanche, l'idée de l'IA de pointe est de déployer des applications d'intelligence artificielle sur l'appareil, plus proches de l'utilisateur. Les appareils Edge peuvent avoir leurs propres GPU, nous permettant de traiter les entrées localement sur l'appareil
Cela fournit. Il existe de nombreux avantages tels qu'une latence réduite puisque toutes les opérations sont effectuées localement sur l'appareil et que le coût global et la consommation d'énergie deviennent également inférieurs puisque l'appareil peut être facilement déplacé d'un endroit à un autre
Étant donné que nous ne le faisons pas. N'ayant pas besoin d'un vaste écosystème, les besoins en bande passante sont également inférieurs à ceux des systèmes de sécurité traditionnels qui reposent sur des connexions Internet stables, car les données peuvent être stockées même lorsque la connexion est fermée dans la mémoire interne de l'appareil. fiable et robuste. »
- Daniel Lyadov (Ingénieur Python chez MobiDev)
Le seul inconvénient notable est que tous les traitements doivent être effectués dans un court laps de temps, les composants matériels doivent être suffisamment puissants et doivent être opérationnels. -to-date pour activer cette fonctionnalité.
Pour les tâches d'authentification biométrique telles que la reconnaissance faciale ou vocale, la rapidité de réponse et la fiabilité du système de sécurité sont cruciales. Parce que nous voulons garantir une expérience utilisateur transparente et une sécurité appropriée, le recours aux appareils de pointe offre ces avantages.
Les informations biométriques, telles que les visages et les voix des employés, semblent suffisamment sécurisées car elles représentent des modèles uniques que les réseaux neuronaux peuvent reconnaître. De plus, ce type de données est plus facile à collecter car la plupart des entreprises disposent déjà de photos de leurs employés dans leur CRM ou ERP. De cette façon, vous pouvez également éviter tout problème de confidentialité en collectant des échantillons d’empreintes digitales de vos employés.
En combinaison avec la technologie de pointe, nous pouvons créer un système de caméra de sécurité IA flexible pour les entrées des espaces de travail. Nous verrons ci-dessous comment mettre en œuvre un tel système en nous basant sur l’expérience de développement de notre propre entreprise et à l’aide de la biométrie de pointe.
Conception d'un système de surveillance par intelligence artificielle
L'objectif principal de ce projet est d'authentifier les employés à l'entrée du bureau d'un simple coup d'œil à la caméra. Le modèle de vision par ordinateur est capable de reconnaître le visage d'une personne, de le comparer à des photos obtenues précédemment, puis de contrôler l'ouverture automatique de la porte. Comme mesure supplémentaire, un support de vérification vocale sera également ajouté pour éviter de tromper le système de quelque manière que ce soit. L'ensemble du pipeline se compose de 4 modèles, chargés d'effectuer différentes tâches, de la détection des visages à la reconnaissance vocale.
Toutes ces mesures sont réalisées via un seul appareil qui agit comme un capteur d'entrée vidéo/audio et un contrôleur qui envoie des commandes de verrouillage/déverrouillage. En tant qu'appareil de pointe, nous avons choisi d'utiliser le Jetson Xavier de NVIDIA. Ce choix a été fait principalement en raison de l'utilisation par l'appareil de la mémoire GPU (critique pour accélérer l'inférence pour les projets d'apprentissage en profondeur) et du Jetpack-SDK hautement disponible de NVIDIA, qui prend en charge les appareils basés sur les environnements Python 3 Encode. Par conséquent, il n'est pas strictement nécessaire de convertir les modèles DS dans un autre format, et presque toutes les bases de code peuvent être adaptées par les ingénieurs DS à l'appareil. De plus, il n'est pas nécessaire de réécrire d'un langage de programmation à un autre ;
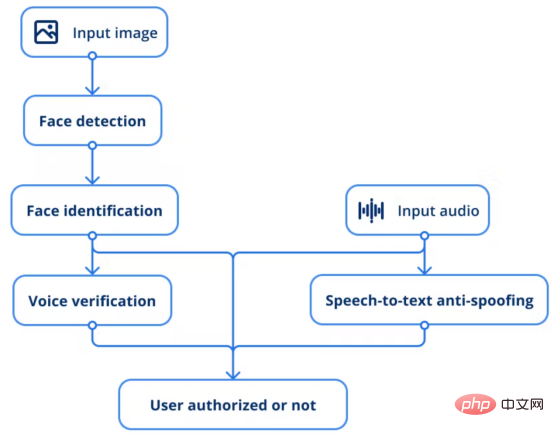
Flux de travail du système de sécurité AI
Selon la description ci-dessus, l'ensemble du processus suit le flux suivant :
1. Fournissez l'image d'entrée au modèle de détection de visage pour trouver l'utilisateur.
2. Le modèle de reconnaissance faciale effectue une inférence en extrayant des vecteurs et en les comparant avec les photos existantes des employés pour déterminer s'il s'agit de la même personne.
3. Un autre modèle consiste à vérifier la voix d'une personne spécifique à travers des échantillons de voix.
4. De plus, une solution anti-usurpation de voix en texte est adoptée pour empêcher tout type de technologie d'usurpation d'identité.
Ensuite, discutons de chaque lien de mise en œuvre et expliquons en détail le processus de formation et de collecte de données.
Collecte de données
Avant de vous plonger dans les modules du système, assurez-vous de faire attention à la base de données utilisée. Notre système repose sur la fourniture aux utilisateurs de données dites de référence ou de vérité terrain. Les données comprennent actuellement des vecteurs de visage et de parole précalculés pour chaque utilisateur, qui ressemblent à un tableau de nombres. Le système stocke également les données de connexion réussies pour une reconversion future. Compte tenu de cela, nous avons choisi la solution la plus légère, SQLite DB. Avec cette base de données, toutes les données sont stockées dans un seul fichier facile à parcourir et à sauvegarder, et la courbe d'apprentissage des ingénieurs en science des données est plus courte.
Parce que la reconnaissance faciale nécessite des photos de tous les employés pouvant entrer dans le bureau, nous utilisons des photos faciales stockées dans la base de données de l'entreprise. Les appareils Jetson placés aux portes des bureaux collectent également des échantillons de données faciales lorsque les personnes utilisent la vérification faciale pour ouvrir les portes.
Au départ, les données vocales n'étaient pas disponibles, nous avons donc organisé la collecte de données et demandé aux gens d'enregistrer des clips de 20 secondes. Nous utilisons ensuite le modèle de vérification vocale pour obtenir le vecteur de chaque personne et le stocker dans la base de données. Vous pouvez capturer des échantillons de parole à l’aide de n’importe quel périphérique d’entrée audio. Dans notre projet, nous utilisons un téléphone portable et une webcam avec un microphone intégré pour enregistrer le son.
Détection de visage
La détection de visage peut déterminer s'il y a un visage dans une scène donnée. Si tel est le cas, le modèle doit vous donner les coordonnées de chaque visage afin que vous sachiez où se trouve chaque visage sur l'image, y compris les repères du visage. Cette information est importante car nous devons recevoir un visage dans le cadre de délimitation afin d'exécuter la reconnaissance faciale à l'étape suivante.
Pour la détection des visages, nous avons utilisé le modèle RetinaFace et les composants clés MobileNet du projet InsightFace. Le modèle génère quatre coordonnées pour chaque visage détecté sur l'image ainsi que 5 étiquettes de visage. En fait, les images prises sous différents angles ou en utilisant des optiques différentes peuvent modifier les proportions du visage en raison de la distorsion. Cela peut amener le modèle à avoir des difficultés à identifier la personne.
Pour répondre à ce besoin, des repères faciaux sont utilisés pour le morphing, une technique qui réduit les différences qui peuvent exister entre ces images d'une même personne. Par conséquent, les surfaces recadrées et déformées obtenues semblent plus similaires et les vecteurs de visage extraits sont plus précis.
Reconnaissance faciale
La prochaine étape est la reconnaissance faciale. A cette étape, le modèle doit reconnaître la personne à partir de l'image donnée (c'est-à-dire l'image obtenue). L'identification se fait à l'aide de références (données de vérité terrain). Donc ici, le modèle comparera deux vecteurs en mesurant le score de distance de la différence entre eux pour déterminer s'il s'agit de la même personne se tenant devant la caméra. L’algorithme d’évaluation la comparera à une première photo que nous avons d’un employé.
La reconnaissance faciale est réalisée à l'aide du modèle d'architecture SE-ResNet-50 . Afin de rendre les résultats du modèle plus robustes, l'image sera inversée et moyennée avant d'obtenir l'entrée vectorielle du visage. À ce stade, le processus d'identification de l'utilisateur est le suivant :
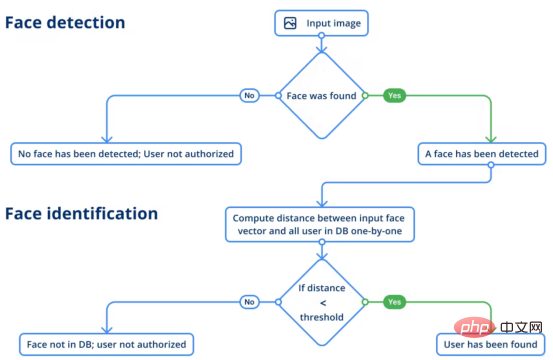
Processus de vérification faciale et vocale
Vérification vocale
Ensuite, nous passons au lien de vérification vocale. Cette étape doit être effectuée pour vérifier que les deux audios contiennent la voix de la même personne. Vous vous demandez peut-être pourquoi ne pas envisager la reconnaissance vocale ? La réponse est que la reconnaissance faciale est désormais bien meilleure que la parole, et que les images peuvent fournir plus d’informations que la parole pour identifier un utilisateur. Afin d’éviter d’identifier l’utilisateur A par le visage et l’utilisateur B par la voix, le système utilise uniquement une solution de reconnaissance faciale.
La logique de base est presque la même que celle de l'étape de reconnaissance faciale, puisque l'on compare deux vecteurs par la distance qui les sépare, à moins que l'on ne trouve des vecteurs similaires. La seule différence est que nous avons déjà une hypothèse sur qui est la personne qui tente de passer du module de reconnaissance faciale précédent.
Lors du développement actif du module de vérification vocale, de nombreux problèmes sont survenus.
Les modèles précédents utilisant l'architecture Jasper n'étaient pas en mesure de vérifier les enregistrements effectués par la même personne à partir de différents microphones. Par conséquent, nous avons résolu ce problème en utilisant l'architecture ECAPA-TDNN, qui a été formée sur l'ensemble de données VoxCeleb2du framework SpeechBrain, qui a fait un bien meilleur travail de validation des employés.
Cependant, les clips audio nécessitent encore un certain prétraitement. L’objectif est d’améliorer la qualité de l’enregistrement audio en préservant le son et en réduisant le bruit de fond actuel. Cependant, toutes les techniques de test affectent gravement la qualité des modèles de vérification vocale. Très probablement, même la moindre réduction du bruit modifiera les caractéristiques audio de la parole dans l'enregistrement, de sorte que le modèle ne sera pas en mesure d'authentifier correctement la personne.
De plus, nous avons étudié la durée de l'enregistrement audio et le nombre de mots que l'utilisateur doit prononcer. À la suite de cette enquête, nous avons formulé un certain nombre de recommandations. La conclusion est la suivante : la durée d'un tel enregistrement doit être d'au moins 3 secondes et environ 8 mots doivent être lus à haute voix.
Anti-usurpation de parole en texte
La dernière mesure de sécurité est que le système applique un anti-usurpation de parole en texte construit sur QuartzNet dans le framework Nemo. Ce modèle offre une bonne expérience utilisateur et convient aux scénarios en temps réel. Pour mesurer à quel point ce qu'une personne dit est proche des attentes du système, il faut calculer la distance de Levenshtein qui les sépare.
Obtenir des photos d'employés pour tromper le module de vérification faciale est une tâche réalisable, tout comme l'enregistrement d'échantillons vocaux. L'anti-usurpation de parole en texte ne couvre pas les scénarios dans lesquels un intrus tente d'entrer dans un bureau en utilisant des photos et des enregistrements audio du personnel autorisé. L’idée est simple : lorsque chacun s’authentifie, il prononce la phrase donnée par le système. Une phrase est constituée d'un ensemble de mots sélectionnés au hasard. Bien que le nombre de mots dans une phrase ne soit pas si grand, le nombre réel de combinaisons possibles est assez énorme. En appliquant des phrases générées aléatoirement, nous éliminons la possibilité de tromper le système, ce qui obligerait un utilisateur autorisé à prononcer un grand nombre de phrases enregistrées. Avoir une photo d’un utilisateur ne suffit pas pour tromper un système de sécurité IA avec cette protection.
Avantages du système biométrique Edge
À ce stade, notre système Edge Biometric permet aux utilisateurs de suivre un processus simple, qui les oblige à prononcer une phrase générée aléatoirement pour déverrouiller la porte. De plus, nous fournissons des services de surveillance IA pour les entrées des bureaux grâce à la détection des visages.
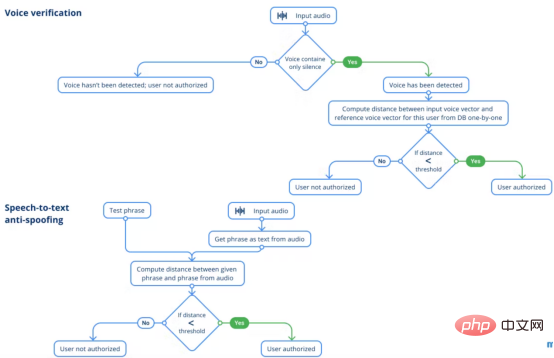
Module de vérification vocale et anti-usurpation de parole en texte
"En ajoutant plusieurs appareils périphériques, le système peut être facilement modifié pour être étendu à différents scénarios. Par rapport aux ordinateurs ordinaires, nous pouvons le configurer directement via le réseau Jetson, se connecte aux appareils de bas niveau via l'interface GPIO et est facile à mettre à niveau avec un nouveau matériel. Nous pouvons également l'intégrer à n'importe quel système de sécurité numérique doté d'une API Web
Mais le principal avantage de cette solution est que nous pouvons. collecter des données directement à partir de l'appareil pour améliorer le système, car la collecte de données à l'entrée semble très pratique sans aucune perturbation particulière. »
——Daniel Lyadov (ingénieur Python chez MobiDev)
Introduction du traducteur
Zhu Xianzhong, rédacteur de la communauté 51CTO, blogueur expert 51CTO, conférencier, professeur d'informatique dans une université de Weifang et vétéran de l'industrie de la programmation indépendante.
Titre original : Développer des systèmes de sécurité IA avec la biométrie de pointe, auteur : Dmitriy Kisil
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Tendances technologiques à surveiller en 2023
- Comment l'intelligence artificielle apporte un nouveau travail quotidien aux équipes des centres de données
- L'intelligence artificielle ou l'automatisation peuvent-elles résoudre le problème de la faible efficacité énergétique des bâtiments ?
- Co-fondateur d'OpenAI interviewé par Huang Renxun : les capacités de raisonnement de GPT-4 n'ont pas encore atteint les attentes
- Bing de Microsoft surpasse Google en termes de trafic de recherche grâce à la technologie OpenAI