
Maison >Périphériques technologiques >IA >Huang Bin, expert en R&D sur la plateforme d'algorithmes NetEase Cloud Music : pratiques et réflexions sur le système de prédiction en ligne NetEase Cloud Music
Huang Bin, expert en R&D sur la plateforme d'algorithmes NetEase Cloud Music : pratiques et réflexions sur le système de prédiction en ligne NetEase Cloud Music

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBavant
- 2023-04-10 19:21:011370parcourir
Invité | Huang Bin
Compilation | Tu Chengye
Récemment, lors de la conférence mondiale sur la technologie de l'intelligence artificielle AISummit organisée par 51CTO, Huang Bin, un expert en recherche et développement de la plate-forme d'algorithmes musicaux NetEase Cloud, a prononcé un discours d'ouverture "Le Pratique du système de prévision en ligne NetEase Cloud Music "et réflexions", du point de vue de la recherche et du développement technologique, il partage des pratiques et des réflexions pertinentes sur la façon de créer un système de prévision hautes performances, facile à utiliser et riche en fonctionnalités.
Le contenu du discours est désormais organisé comme suit, en espérant vous inspirer.
Architecture globale du système
Tout d'abord, examinons l'architecture de l'ensemble du système de prédiction, comme le montre la figure ci-dessous :
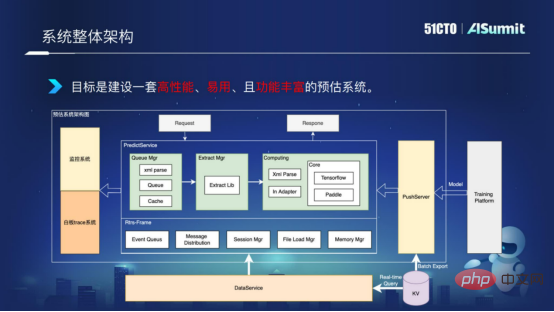
Architecture globale du système
Le serveur Predict au milieu est le composant principal de le système de prédiction, y compris le composant de requête, le composant de traitement des caractéristiques et le composant de calcul de modèle. Le système de surveillance de gauche est utilisé pour surveiller les services du réseau de ligne afin d'assurer le bon déroulement du réseau du système. Le PushServer sur la droite est utilisé pour le push de modèle, en poussant le dernier modèle dans le système de prédiction en ligne à des fins de prédiction.
L'objectif est de créer un système de prévision performant, facile à utiliser et riche en fonctionnalités.
Calcul Haute Performance
Comment améliorer les performances informatiques ? Quels sont nos problèmes courants de performances informatiques ? Je vais les développer sous trois aspects.
- Traitement des fonctionnalités
Dans la solution générale, notre calcul de fonctionnalités et notre calcul de modèle sont déployés dans des processus distincts, ce qui entraînera le transfert d'un grand nombre de fonctionnalités entre services et langues, entraînant de multiples encodages et décodages et copies de mémoire. , ce qui entraîne une surcharge de performances relativement importante.
- Mise à jour du modèle
Nous savons que lorsque le modèle est mis à jour, de gros blocs de types seront appliqués et publiés. Cependant, dans certaines solutions générales, il n'est pas fourni avec une solution de préchauffage du modèle, ce qui entraînera une instabilité relativement longue dans le processus de mise à jour du modèle et ne pourra pas prendre en charge la mise à jour en temps réel du modèle.
- Ordonnancement informatique
Les frameworks généraux utilisent un mécanisme de synchronisation, qui a une concurrence insuffisante et une faible utilisation du processeur, et ne peut pas répondre aux besoins informatiques à forte concurrence.
Alors, comment résoudre ces goulots d'étranglement de performances dans le système de prédiction ?
1. Intégration transparente des bibliothèques d'apprentissage automatique
Pourquoi devrions-nous faire une telle chose ? Parce que dans les solutions traditionnelles, nous savons tous que le traitement des caractéristiques et le calcul du modèle sont déployés dans des processus distincts, ce qui entraînera des transmissions inter-réseaux plus spécifiques, une sérialisation, une désérialisation et des applications et versions de mémoire fréquentes. Surtout lorsque le nombre de fonctionnalités de la scène recommandée est particulièrement important, cela entraînera une surcharge de performances significative. Dans la figure ci-dessous, l'organigramme en haut montre la situation spécifique de la solution générale.
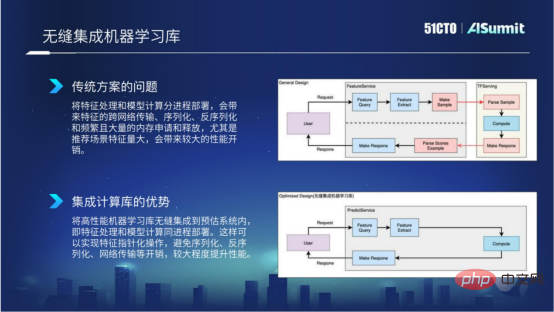
Intégration transparente de la bibliothèque d'apprentissage informatique
Afin de résoudre les problèmes ci-dessus, nous intégrons le cadre d'apprentissage du calcul haute performance dans le système de prédiction. L'avantage est que nous pouvons assurer le traitement des caractéristiques et les modèles de calcul. peut être déployé dans le même processus, et le fonctionnement des fonctionnalités peut être implémenté sous forme de pointeurs, évitant ainsi la surcharge de sérialisation, de désérialisation et de transmission réseau, apportant ainsi une meilleure amélioration des performances de calcul dans le calcul et le traitement des fonctionnalités. intégrant l’apprentissage automatique.
2. Considérations sur la conception de l'architecture
Tout d'abord, l'ensemble du système adopte une conception d'architecture entièrement asynchrone. L'avantage de l'architecture asynchrone est que les appels externes ne sont pas bloquants et sont en attente, de sorte que le mécanisme asynchrone peut garantir que la stabilité fastidieuse du service réseau est toujours maintenue sous une charge CPU élevée, par exemple 60 % à 70 %.
Deuxièmement, l'optimisation de l'accès à la mémoire. L'optimisation de l'accès à la mémoire repose principalement sur l'architecture NUMA du serveur et nous adoptons une méthode de fonctionnement liée au cœur. De cette façon, nous pouvons résoudre le problème de l'accès à la mémoire à distance qui existait dans la précédente architecture NUMA, améliorant ainsi les performances informatiques de notre service.
Troisièmement, le calcul parallèle. Nous segmentons les tâches informatiques et utilisons la concurrence multithread pour effectuer des calculs, ce qui peut réduire considérablement la consommation de temps de service et améliorer l'utilisation des ressources.
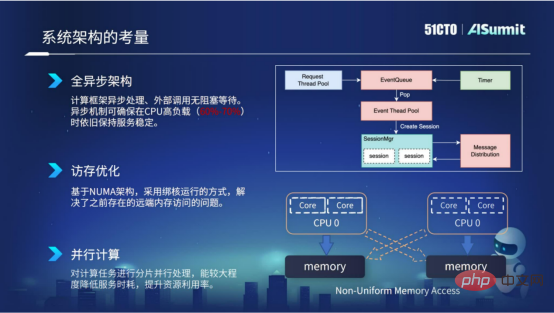
Considérations de conception architecturale
Ce qui précède est notre pratique dans l'estimation des considérations d'architecture système du système.
3. Mise en cache multi-niveaux
La mise en cache multi-niveaux est principalement utilisée dans l'étape de requête de fonctionnalités et l'étape primaire. Le mécanisme de mise en cache que nous encapsulons peut, d'une part, réduire les appels externes aux requêtes, et d'autre part, il peut également réduire les calculs invalides répétés causés par l'extraction de fonctionnalités.
Grâce à la mise en cache, l'efficacité des requêtes et de l'extraction peut être considérablement améliorée. Surtout au stade de la requête, nous encapsulons une variété de composants en fonction de l'importance des fonctionnalités et de l'ampleur des fonctionnalités, tels que la requête synchrone, la requête asynchrone et l'importation par lots de fonctionnalités.
La première est la requête synchrone, qui convient principalement à certaines fonctionnalités plus importantes. Bien entendu, les performances de la requête synchrone ne sont pas si efficaces.
La seconde est la requête asynchrone, qui cible principalement certaines fonctionnalités de la « dimension Aite ». Ces fonctionnalités peuvent ne pas être si importantes, vous pouvez donc utiliser cette méthode de requête asynchrone.
La troisième méthode est l'importation par lots de fonctionnalités, qui convient principalement aux données de fonctionnalités dont la taille des fonctionnalités n'est pas particulièrement grande. En important ces fonctionnalités dans le processus par lots, nous pouvons implémenter une requête localisée de fonctionnalités et les performances sont très efficaces.
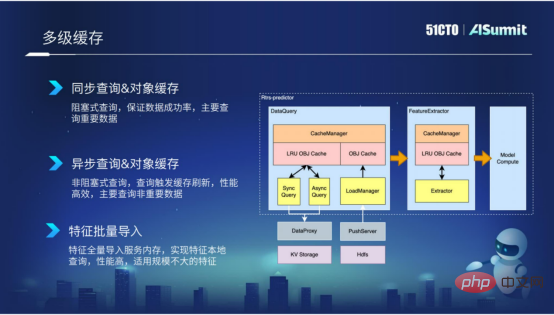
Mise en cache multi-niveaux
4. Optimisation du calcul du modèle
Après avoir présenté le mécanisme de mise en cache, examinons l'optimisation du comportement du calcul du modèle. Pour le calcul du modèle, nous optimisons principalement sous trois aspects : l'optimisation des entrées du modèle, l'optimisation du chargement du modèle et l'optimisation du noyau.
- Optimisation de l'entrée du modèle
Dans la zone de saisie du modèle, tout le monde sait que TF Servering utilise l'entrée de l'exemple. L'entrée de l'exemple comprendra la construction de l'exemple, la sérialisation et la désérialisation de l'exemple, ainsi que l'appel à Parse Sample à l'intérieur du modèle, ce qui prendra relativement du temps.
Dans l'image ci-dessous, nous regardons la capture d'écran de [Avant l'optimisation] pour afficher les statistiques des données avant le calcul et l'optimisation du modèle. Nous pouvons voir qu'il existe un exemple d'analyse relativement long qui prend beaucoup de temps à analyser, et avant que l'exemple d'analyse ne soit analysé, les autres opérations ne peuvent pas effectuer de planification parallèle. Afin de résoudre le problème de performances des arbres modèles, nous avons encapsulé une solution d'entrée de modèle hautes performances dans le système de prédiction. Grâce à la nouvelle solution, nous pouvons obtenir une copie nulle de l'entrée des fonctionnalités, réduisant ainsi la construction et l'analyse fastidieuses de cet exemple.
Dans l'image ci-dessous, nous regardons la capture d'écran de [Après optimisation] pour afficher les statistiques des données après l'optimisation du calcul du modèle. Nous pouvons voir qu'il n'y a plus le temps d'analyse de l'exemple d'analyse, il ne reste que le temps d'analyse de l'exemple. .

Optimisation du calcul du modèle
- Optimisation du chargement du modèle
Après avoir présenté l'optimisation des entrées du modèle, jetons un coup d'œil à l'optimisation du chargement du modèle. Le chargement du modèle de Tensorflow est un mode de chargement paresseux. Une fois le modèle chargé en interne, il ne préchauffera pas le modèle jusqu'à ce qu'une demande formelle du réseau arrive. sera une gigue qui prendra beaucoup de temps.
Afin de résoudre ce problème, nous avons implémenté une fonction de préchauffage automatique du modèle au sein du système de prédiction, une commutation à chaud entre l'ancien et le nouveau modèle, ainsi qu'un déchargement asynchrone et une libération de mémoire de l'ancien modèle. De cette manière, grâce à certaines méthodes d'optimisation de chargement de ces modèles, la capacité de mise à jour infime du modèle est obtenue.
- Optimisation du noyau
Ensuite, jetons un coup d'œil à l'optimisation du noyau du modèle. À l'heure actuelle, nous effectuons principalement une optimisation de la synchronisation du noyau sur le noyau Tensorflow, et nous ajusterons certains pools de threads entre les opérations et au sein des opérations en fonction du modèle, etc.
Ci-dessus sont quelques-unes de nos tentatives pour optimiser les performances dans les calculs de modèles.
Après avoir présenté la solution d'optimisation des performances ci-dessus, examinons les résultats finaux de l'optimisation des performances.
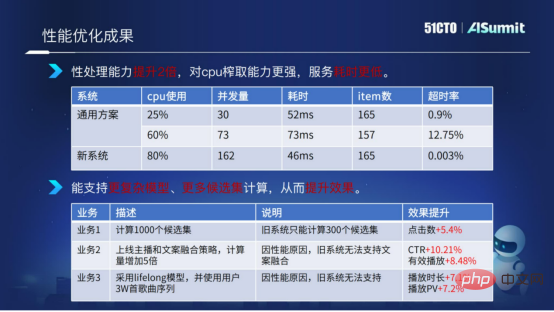
Résultats de l'optimisation des performances
Ici, nous faisons une comparaison entre le système d'estimation et le système de solution général. Nous pouvons voir que lorsque l'utilisation du processeur du système estimé atteint 80 %, le temps de calcul et le taux de timeout de l'ensemble du service sont très stables et très faibles. Par comparaison, nous pouvons conclure que la nouvelle solution (système de prédiction) a deux fois plus de performances en termes de calcul et de traitement, a des capacités d'extraction de CPU plus fortes et un temps de service inférieur.
Grâce à notre optimisation du système, nous pouvons fournir plus de calculs de complexité de modèle et plus de calculs d'ensembles candidats pour les algorithmes métier.
La figure ci-dessus donne un exemple. L'ensemble de candidats a été étendu des 300 ensembles de candidats précédents à 1 000 ensembles de candidats. Dans le même temps, nous avons augmenté la complexité du calcul du modèle et utilisé des fonctionnalités plus complexes, qui ont apporté du succès. plusieurs entreprises. De meilleurs résultats ont été obtenus.
Ce qui précède est une introduction à l'optimisation des performances et aux résultats d'optimisation des performances du système d'estimation.
Comment améliorer l'efficacité du développement
1. Conception en couches du système
Le système adopte une conception d'architecture en couches. Nous divisons l'ensemble du système d'estimation en trois couches, dont la couche d'architecture sous-jacente, la couche de modèle intermédiaire et la couche de structure supérieure.
La couche d'architecture sous-jacente fournit principalement un mécanisme asynchrone, une file d'attente de tâches, une planification simultanée, une communication réseau, etc.
La couche intermédiaire du modèle fournit principalement des composants liés au calcul du modèle, notamment la gestion des requêtes, la gestion du cache, la gestion du chargement du modèle et la gestion du calcul du modèle.
La couche d'interface supérieure fournit principalement des interfaces de haut niveau. Les entreprises n'ont qu'à implémenter cette interface de couche, ce qui réduit considérablement le développement de code.
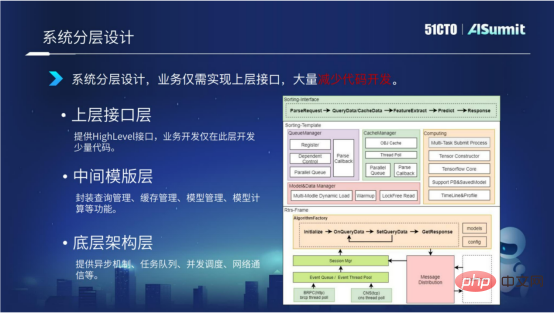
Grâce à la conception de l'architecture en couches du système, le code des couches inférieures et intermédiaires peut être réutilisé entre différentes entreprises. Le développement ne doit se concentrer que sur le développement d'une petite quantité de code sur la couche supérieure. Dans le même temps, nous réfléchissons également plus loin. Existe-t-il un moyen de réduire davantage le développement de code de la couche d'interface supérieure ? Présentons-le en détail ci-dessous.
2. Encapsulation universelle des requêtes
En encapsulant une solution générale basée sur une requête de fonctionnalités et une analyse de fonctionnalités basée sur la technologie pb dynamique, les fonctionnalités ne peuvent être implémentées que via le nom de la table de configuration XML, la clé de requête, le temps de cache, la dépendance de la requête, etc. tout le processus de requête, d'analyse et de mise en cache.
Comme le montre la figure ci-dessous, nous pouvons implémenter une logique de requête complexe avec quelques lignes de configuration. Dans le même temps, l’efficacité des requêtes est améliorée grâce à l’encapsulation des requêtes.

3. Package de calcul de fonctionnalités
Le calcul de fonctionnalités peut être considéré comme le module avec la complexité de développement de code la plus élevée de tout le système de prédiction.
Le calcul des fonctionnalités inclut le processus hors ligne et le processus en ligne. Le processus hors ligne consiste en fait à utiliser des échantillons hors ligne, qui sont traités pour obtenir certains formats requis par la plateforme de formation hors ligne, tels que le format TF Recocd. Le processus en ligne effectue principalement certains calculs de caractéristiques sur les demandes en ligne et obtient certains formats requis par la plateforme de prédiction en ligne grâce au traitement. En fait, la logique de calcul pour le traitement des fonctionnalités est exactement la même entre le processus hors ligne et le processus en ligne. Cependant, étant donné que les plates-formes informatiques du processus hors ligne et du processus en ligne sont différentes et que les langages utilisés sont différents, plusieurs ensembles de codes doivent être développés pour mettre en œuvre le calcul des caractéristiques, il existe donc les trois problèmes suivants.
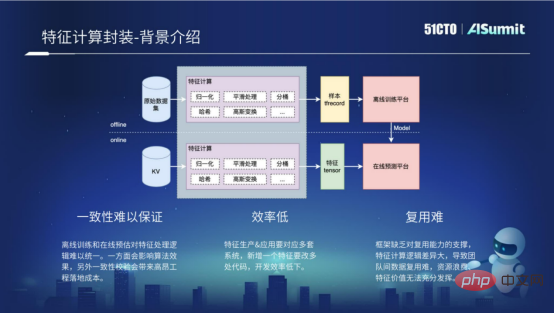
- La cohérence est difficile à garantir
La raison fondamentale pour laquelle la cohérence est difficile à garantir est qu'il est difficile d'unifier la logique de traitement des fonctionnalités de la formation hors ligne et de la prédiction en ligne. D'une part, cela affectera l'effet de l'algorithme et, d'autre part, cela entraînera des coûts de vérification ponctuels relativement élevés pendant le processus de développement.
- Faible efficacité
Si vous souhaitez ajouter une nouvelle fonctionnalité, vous devez développer plusieurs ensembles de codes impliquant des processus hors ligne et des processus en ligne, ce qui entraîne une très faible efficacité de développement.
- Difficulté de réutilisation
Difficulté de réutilisation. La raison principale est que le framework ne prend pas en charge les capacités de réutilisation, ce qui rend très difficile la réutilisation des calculs de fonctionnalités entre différentes entreprises.
Ci-dessus sont quelques problèmes avec le cadre de calcul des caractéristiques.
Afin de résoudre ces problèmes, nous allons les résoudre progressivement selon les quatre points suivants.
Tout d'abord, nous proposons le concept d'opérateurs et de calculs de fonctionnalités abstraites dans l'encapsulation d'opérateurs. Deuxièmement, une fois l'opérateur encapsulé, nous construisons une bibliothèque d'opérateurs, qui peut offrir la possibilité de réutiliser les opérateurs entre entreprises. Ensuite, nous définissons le langage de description de calcul de fonctionnalités DSL en fonction des opérateurs. Grâce à ce langage de description, nous pouvons compléter l'expression de configuration du calcul des fonctionnalités. Enfin, comme mentionné précédemment, étant donné qu'il existe plusieurs ensembles de logiques dans les processus en ligne et hors ligne, ce qui entraînera des incohérences logiques, nous devons résoudre le problème des fonctionnalités ponctuelles.
Les quatre points ci-dessus sont nos idées sur la façon d'encapsuler le cadre de calcul des fonctionnalités.

- Abstraction de l'opérateur
Afin de réaliser l'abstraction de l'opérateur, le protocole de données doit d'abord être unifié. Nous utilisons la technologie pb dynamique pour traiter n'importe quelle fonctionnalité selon des données unifiées basées sur les informations de données originales de la fonctionnalité. Cela fournit une base de données pour l'encapsulation de notre opérateur. Ensuite, nous échantillonnons et encapsulons le processus de traitement des fonctionnalités, résumons le processus de calcul des fonctionnalités en analyse, calcul, assemblage et gestion des exceptions, et unifions l'API du processus de calcul pour réaliser l'abstraction des opérateurs.
- Créer une bibliothèque d'opérateurs
Après avoir l'abstraction des opérateurs, nous pouvons construire une bibliothèque d'opérateurs. La bibliothèque d'opérateurs est divisée en bibliothèque d'opérateurs générale de plate-forme et bibliothèque d'opérateurs personnalisée par entreprise. La bibliothèque générale des opérateurs de la plateforme est principalement utilisée pour réaliser une réutilisation au niveau de l'entreprise. La bibliothèque d'opérateurs personnalisés métier est principalement destinée à certains scénarios et caractéristiques personnalisés de l'entreprise pour permettre une réutilisation au sein du groupe. Grâce à l'encapsulation des opérateurs et à la construction de bibliothèques d'opérateurs, nous réalisons la réutilisation des calculs de fonctionnalités dans plusieurs scénarios et améliorons l'efficacité du développement.
- Langage de description de calcul DSL
L'expression configurée du calcul de caractéristiques fait référence au langage configuré qui définit l'expression de calcul de caractéristiques appelée DSL. Grâce au langage de configuration, nous pouvons réaliser une expression imbriquée à plusieurs niveaux d'opérateurs, quatre opérations arithmétiques, etc. La première capture d'écran ci-dessous montre la syntaxe spécifique de la langue configurée.

Quels avantages pouvons-nous apporter grâce au langage de configuration du calcul des caractéristiques ?
Tout d'abord, nous pouvons effectuer l'intégralité du calcul des fonctionnalités via la configuration, améliorant ainsi l'efficacité du développement.
Deuxièmement, nous pouvons réaliser des mises à jour à chaud des calculs de caractéristiques en publiant des expressions configurées de calculs de caractéristiques.
Troisièmement, l'entraînement et la prédiction utilisent la même configuration de calcul de fonctionnalités pour obtenir une cohérence en ligne et hors ligne.
C'est l'avantage apporté par l'expression du calcul des caractéristiques.
- Cohérence des fonctionnalités
Comme mentionné précédemment, le calcul des fonctionnalités est divisé en processus hors ligne et processus en ligne. En raison des raisons multiplateformes hors ligne et en ligne, le calcul logique est incohérent. Afin de résoudre ce problème, nous avons implémenté la capacité d'exécution multiplateforme du framework de calcul de fonctionnalités dans le framework de calcul de fonctionnalités. La logique de base est développée en C++, et l'interface C++ et l'interface Java sont exposées au monde extérieur. Dans le processus d'empaquetage et de construction, la bibliothèque C++ so et le package jar peuvent être implémentés en un seul clic, garantissant ainsi que le calcul des fonctionnalités peut exécuter la plateforme C++ pour le calcul en ligne et la plateforme Spark ou la plateforme Flink hors ligne, et qu'il peut être exprimé avec calcul des fonctionnalités pour garantir que le calcul des fonctionnalités atteint la cohérence de la logique en ligne et hors ligne.
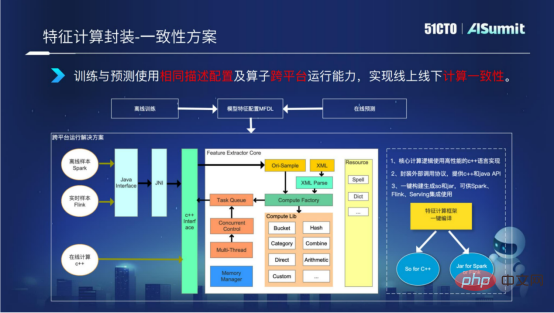
Ce qui précède décrit la situation spécifique du calcul des caractéristiques. Jetons un coup d'œil à certains des résultats obtenus jusqu'à présent par le Feature Computing.
Nous avons désormais accumulé des opérateurs de 120 entreprises. Grâce au langage DSL de calcul des fonctionnalités, nous pouvons réaliser la configuration et compléter l'intégralité du calcul des fonctionnalités. Grâce aux capacités opérationnelles multiplateformes que nous proposons, le problème de l'incohérence logique en ligne et hors ligne est résolu.
La capture d'écran ci-dessous montre qu'avec une petite quantité de configuration, l'ensemble du processus de calcul des fonctionnalités peut être réalisé, ce qui améliore considérablement l'efficacité du développement du calcul des fonctionnalités.

Ce qui précède présente notre exploration de l'amélioration de l'efficacité du développement. En général, nous pouvons améliorer la réutilisabilité du code grâce à la conception hiérarchique du système et réaliser un processus de développement configurable en encapsulant les requêtes, les extractions et les calculs de modèles.
4. Encapsulation du calcul du modèle
Le calcul du modèle prend également la forme d'une encapsulation. Grâce à la forme d'expression de configuration, le chargement du modèle, la structure d'entrée du modèle, le calcul du modèle, etc. sont réalisés en utilisant quelques lignes de configuration, le processus d'expression de l'ensemble du calcul du modèle est réalisé.

Implémentation en temps réel du modèle
Jetons un coup d'œil à un cas d'implémentation en temps réel du modèle.
1. Contexte du projet en temps réel
Pourquoi voulons-nous réaliser un tel projet modèle en temps réel ?
La raison principale est que le système de recommandation traditionnel est un système qui met à jour quotidiennement les résultats des recommandations des utilisateurs. Ses performances en temps réel sont très médiocres et ne peuvent pas répondre à de tels scénarios avec des exigences en temps réel élevées, tels que nos scénarios de diffusion en direct. , ou d'autres scénarios en temps réel avec des exigences relativement élevées.
Une autre raison est que la méthode traditionnelle de production d'échantillons pose le problème du croisement de caractéristiques. Qu’est-ce que le croisement de fonctionnalités ? La figure suivante montre la raison fondamentale du croisement des caractéristiques. Dans le processus d'épissage des échantillons, nous utilisons la structure estimée du modèle au moment « T-1 » et la raccordons aux caractéristiques au moment « T ». un croisement surviendra. Le croisement de fonctionnalités affectera grandement l’effet de la recommandation du réseau de lignes. Afin de résoudre le problème du temps réel et le problème du croisement d'échantillons, nous avons implémenté une telle solution modèle en temps réel dans le système de prédiction.
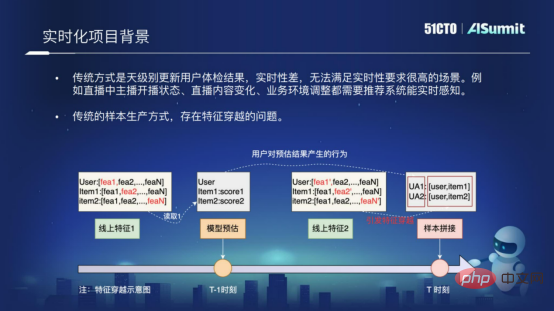
2. Introduction à la solution temps réel
La solution modèle temps réel est expliquée en trois dimensions.
- Génération d'échantillons en temps réel
- Entraînement de modèles incrémentaux
- Système de prédiction en temps réel
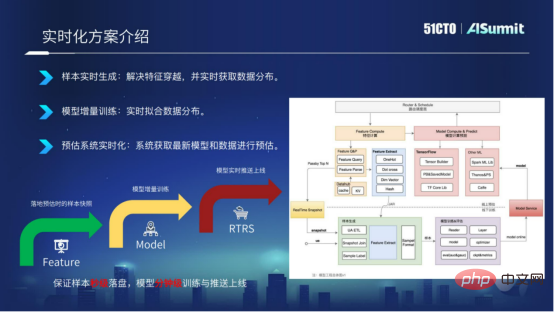
Les échantillons sont générés en temps réel. Sur la base du système de prédiction en ligne, nous implémentons les fonctionnalités du système de prédiction dans Kafka en temps réel et les associons sous la forme d'un RACE ID. De cette façon, nous pouvons garantir que les échantillons sont placés sur le disque en quelques secondes et résoudre le problème de. croisement de caractéristiques.
Modéliser une formation incrémentale. Une fois les échantillons placés sur le disque en quelques secondes, nous pouvons modifier le module de formation pour mettre en œuvre une formation incrémentielle du modèle et réaliser des mises à jour infimes du modèle.
Le système de prédiction est en temps réel. Après avoir exporté le modèle au niveau minute, nous transmettons le dernier modèle au système de prédiction en ligne via le service push de modèles Push Server, qui permet au système de prédiction sur site d'utiliser le dernier modèle pour la prédiction.
En général, la solution du modèle en temps réel consiste à réaliser le placement d'échantillons en quelques secondes, une formation au niveau de la minute et des mises à jour en ligne du modèle au niveau de la minute.
Notre solution modèle en temps réel actuelle a été implémentée dans plusieurs scénarios. Grâce à la solution de modélisation en temps réel, les résultats commerciaux ont été considérablement améliorés.
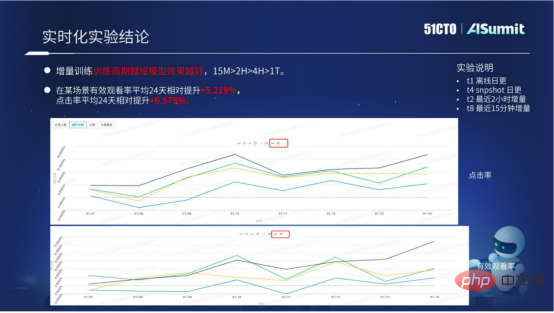
La figure ci-dessus montre principalement les données expérimentales spécifiques de la solution modèle en temps réel. Nous pouvons constater une formation progressive : plus la période de formation est courte, mieux c'est. Grâce à des données spécifiques, nous pouvons savoir que l’effet d’un cycle de 15 minutes est bien supérieur à celui de 2 heures, 10 heures ou une journée. La solution modèle en temps réel actuelle dispose déjà d'un processus d'accès standardisé, qui peut apporter de meilleurs résultats à l'entreprise par lots.
Ce qui précède présente l'exploration et les tentatives sous trois aspects : comment le système de prédiction améliore les performances informatiques, comment améliorer l'efficacité du développement et comment améliorer les algorithmes du projet grâce à des moyens d'ingénierie.
La valeur de la plate-forme de l'ensemble du système de prévision, ou l'objectif de la plate-forme de l'ensemble du système de prévision, peut être résumée en trois mots, qui sont « rapide, bon et économique ».
« Rapide » fait référence à la construction appliquée introduite précédemment. Nous espérons que grâce à la construction continue d’applications, l’itération commerciale pourra être plus efficace.
« Bon » signifie que nous espérons que grâce à des moyens d'ingénierie, tels que des solutions de modèles en temps réel et des solutions de cohérence logique en ligne et hors ligne grâce au calcul des caractéristiques, nous pourrons apporter de meilleurs résultats à l'entreprise.
« Enregistrer » signifie utiliser les performances plus élevées du système estimé, ce qui peut économiser davantage de ressources informatiques et réduire les coûts de calcul.
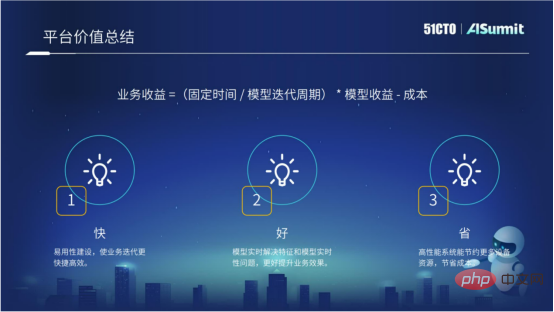
À l'avenir, nous continuerons à travailler vers ces trois objectifs.
Ce qui précède est mon introduction au système de prédiction musicale cloud. Mon partage se termine ici, merci à tous !
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Tendances technologiques à surveiller en 2023
- Comment l'intelligence artificielle apporte un nouveau travail quotidien aux équipes des centres de données
- L'intelligence artificielle ou l'automatisation peuvent-elles résoudre le problème de la faible efficacité énergétique des bâtiments ?
- Co-fondateur d'OpenAI interviewé par Huang Renxun : les capacités de raisonnement de GPT-4 n'ont pas encore atteint les attentes
- Bing de Microsoft surpasse Google en termes de trafic de recherche grâce à la technologie OpenAI