
Maison >Périphériques technologiques >IA >Tan Zhongyi : Du MLOps centré sur le modèle au MLOps centré sur les données aide l'IA à être mise en œuvre plus rapidement et de manière plus rentable
Tan Zhongyi : Du MLOps centré sur le modèle au MLOps centré sur les données aide l'IA à être mise en œuvre plus rapidement et de manière plus rentable

- PHPzavant
- 2023-04-09 19:51:111495parcourir
Invité : Tan Zhongyi
Compilé par : Qianshan
Enda Ng a exprimé à plusieurs reprises que l'IA est passée d'un paradigme de recherche centré sur le modèle à un paradigme de recherche centré sur les données. Les données constituent le plus grand défi pour la mise en œuvre de l'IA. Comment garantir la fourniture de données de haute qualité est une question clé. Pour résoudre ce problème, nous devons utiliser des pratiques et des outils MLOps pour aider l'IA à être mise en œuvre rapidement, facilement et de manière rentable.
Récemment, lors de la AISummit Global Artificial Intelligence Technology Conference organisée par 51CTO, Tan Zhongyi, vice-président du TOC de l'Open Atomic Foundation, a prononcé un discours d'ouverture « Du modèle centré au centré sur les données - MLOps aide l'IA "Comment mettre en œuvre MLOps rapidement et de manière rentable" visait à partager avec les participants la définition de MLOps, les problèmes que MLOps peut résoudre, les projets MLOps courants et la manière d'évaluer les capacités MLOps et le niveau d'une équipe d'IA.
Le contenu du discours est désormais organisé comme suit, en espérant vous inspirer.
Du Model-Centric au Data-Centric
Actuellement, il existe une tendance dans l'industrie de l'IA - "du Model-Centric au Data-Centric". Qu'est-ce que cela signifie exactement ? Commençons par quelques analyses issues de la science et de l’industrie.
- Andrew NG, scientifique en IA, a analysé que la clé de la mise en œuvre actuelle de l'IA est de savoir comment améliorer la qualité des données.
- Les ingénieurs et analystes de l'industrie ont signalé que les projets d'IA échouent souvent. Les raisons de cet échec méritent une exploration plus approfondie.
Andrew Ng a un jour partagé son discours « MLOps : From Model-centric to Data-centric », qui a eu de grandes répercussions dans la Silicon Valley. Dans son discours, il a estimé que "AI = Code + Data" (où le Code inclut des modèles et des algorithmes) et a amélioré le système d'IA en améliorant les données plutôt que le code.
Plus précisément, la méthode Model-Centric est adoptée, c'est-à-dire garder les données inchangées et ajuster constamment l'algorithme du modèle, comme l'utilisation de plus de couches de réseau, plus d'ajustements d'hyperparamètres, etc. et en utilisant la méthode Data-Centric, qui est adoptée. c'est-à-dire garder le modèle Aucun changement, améliorer la qualité des données, comme l'amélioration des étiquettes de données, l'amélioration de la qualité des annotations des données, etc.
Pour le même problème d'IA, que vous amélioriez le code ou que vous amélioriez les données, l'effet est complètement différent.
Des preuves empiriques montrent que la précision peut être efficacement améliorée grâce à l'approche centrée sur les données, mais la mesure dans laquelle la précision peut être améliorée en améliorant le modèle ou en remplaçant le modèle est extrêmement limitée. Par exemple, dans la tâche suivante de détection des défauts des plaques d'acier, le taux de précision de base était de 76,2 %. Après diverses opérations de modification des modèles et d'ajustement des paramètres, le taux de précision n'a presque pas été amélioré. Cependant, l'optimisation de l'ensemble de données a augmenté la précision de 16,9 %. L'expérience d'autres projets le prouve également.
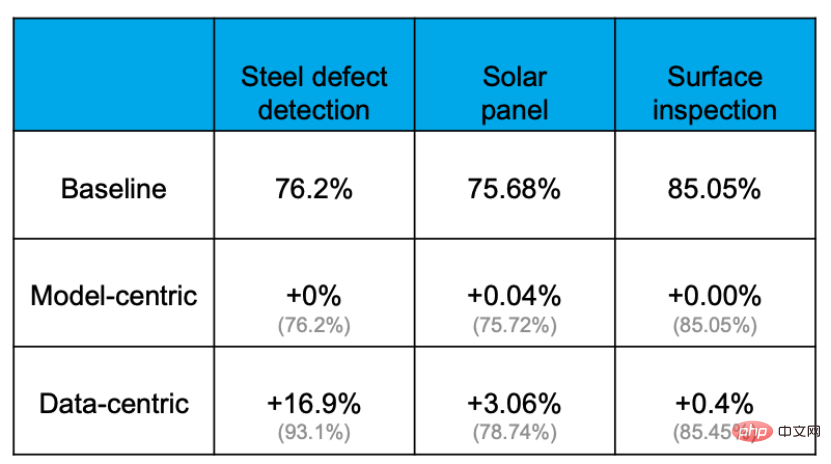
La raison pour laquelle cela se produit est que les données sont plus importantes qu'on ne l'imaginait. Tout le monde sait que « les données nourrissent l’IA ». Dans une véritable application d'IA, environ 80 % du temps est consacré au traitement du contenu lié aux données et les 20 % restants sont utilisés pour ajuster l'algorithme. Ce processus est comme la cuisine. 80 % du temps est consacré à la préparation des ingrédients, au traitement et à l'ajustement de divers ingrédients, mais la cuisson proprement dite ne peut prendre que quelques minutes lorsque le chef met la marmite dans la marmite. On peut dire que la clé pour déterminer si un plat est délicieux réside dans les ingrédients et leur transformation.
De l'avis de Ng, la tâche la plus importante du MLOps (c'est-à-dire « l'ingénierie de l'apprentissage automatique pour la production ») se situe à toutes les étapes du cycle de vie de l'apprentissage automatique, y compris la préparation des données, la formation des modèles, la mise en ligne des modèles, ainsi que la surveillance et le recyclage des modèles. Attendez chaque étape, et maintenir toujours un approvisionnement en données de haute qualité.
Ce qui précède est ce que les scientifiques en IA savent du MLOps. Examinons ensuite quelques points de vue d’ingénieurs en IA et d’analystes du secteur.
Tout d’abord, du point de vue des analystes du secteur, le taux d’échec actuel des projets d’IA est étonnamment élevé. Une enquête réalisée par Dimensional Research en mai 2019 a révélé que 78 % des projets d'IA n'étaient finalement pas mis en ligne ; en juin 2019, un rapport de VentureBeat a révélé que 87 % des projets d'IA n'étaient pas déployés dans l'environnement de production. En d’autres termes, même si les scientifiques et les ingénieurs en IA ont accompli beaucoup de travail, ils n’ont finalement pas généré de valeur commerciale.
Pourquoi ce résultat se produit-il ? L'article « Hidden Technical Debt in Machine Learning Systems » publié au NIPS en 2015 mentionnait qu'un véritable système d'IA en ligne comprend la collecte de données, la vérification, la gestion des ressources, l'extraction de fonctionnalités, la gestion des processus, la surveillance et bien d'autres contenus. Mais le code réellement lié à l'apprentissage automatique ne représente que 5 % de l'ensemble du système d'IA, et 95 % sont du contenu lié à l'ingénierie et au contenu lié aux données. Par conséquent, les données sont à la fois les plus importantes et les plus sujettes aux erreurs.
Les enjeux des données pour un véritable système d'IA résident principalement dans les points suivants :
- Échelle : la lecture de données massives est un défi ;
- Faible latence : comment répondre aux exigences de QPS élevé et de faible latence pendant la diffusion
- Les changements de données provoquent la dégradation du modèle : le monde réel est en constante évolution, comment gérer les effets du modèle ; atténuation ;
- Voyage dans le temps : le traitement des données des caractéristiques des séries chronologiques est sujet à des problèmes ;
- Biais d'entraînement/de service : les données utilisées pour l'entraînement et la prédiction sont incohérentes ;
La liste ci-dessus présente quelques défis liés aux données dans l'apprentissage automatique. De plus, dans la vie réelle, les données en temps réel posent de plus grands défis.
Alors, pour une entreprise, comment mettre en œuvre l’IA à grande échelle ? En prenant l'exemple d'une grande entreprise, elle peut avoir plus de 1 000 scénarios d'application et plus de 1 500 modèles exécutés en ligne en même temps. Comment prendre en charge autant de modèles ? Comment pouvons-nous techniquement parvenir à une mise en œuvre « plus grande, plus rapide, meilleure et moins coûteuse » de l’IA ?
Beaucoup : De multiples scénarios doivent être mis en œuvre autour des processus métiers clés, qui peuvent être de l'ordre de 1 000 voire des dizaines de milliers pour les grandes entreprises.
Rapide : le temps de mise en œuvre de chaque scène doit être court et la vitesse d'itération doit être rapide. Par exemple, dans les scénarios recommandés, il est souvent nécessaire de réaliser un entraînement complet une fois par jour et un entraînement progressif toutes les 15 minutes, voire toutes les 5 minutes.
Bon : L'effet d'atterrissage de chaque scène doit répondre aux attentes, au moins mieux qu'avant sa mise en œuvre.
Économie : Le coût de mise en œuvre de chaque scénario est relativement économique, conforme aux attentes.
Pour réellement réaliser « plus, plus vite, mieux et moins cher », nous avons besoin de MLOps.

Dans le domaine du développement logiciel traditionnel, lorsque nous rencontrons des problèmes similaires tels qu'un déploiement lent et une qualité instable, nous utilisons DevOps pour les résoudre. DevOps a considérablement amélioré l’efficacité du développement et du lancement de logiciels et favorisé l’itération et le développement rapides de logiciels modernes. Face à des problèmes avec les systèmes d'IA, nous pouvons tirer les leçons de l'expérience mature dans le domaine DevOps pour développer des MLOps. Ainsi, comme le montre la figure, « Développement de l'apprentissage automatique + Développement de logiciels modernes » devient MLOps.
Qu'est-ce que le MLOps exactement ?
Il n'existe actuellement aucune définition standard dans l'industrie de ce qu'est le MLOps.
- Définition de wikipedia : MLOps est un ensemble de pratiques qui visent à déployer et
maintenir des modèles d'apprentissage automatique en production de manière fiable et efficace. - Définition de Google Cloud : MLOps est une culture et une pratique d'ingénierie d'apprentissage automatique qui vise à unifier le développement et le fonctionnement du système d'apprentissage automatique.
- Définition de Microsoft Azure : MLOps peut aider les scientifiques des données et les ingénieurs d'application à rendre les modèles d'apprentissage automatique plus efficaces en production.
Les déclarations ci-dessus sont assez alambiquées. Ma compréhension personnelle de cela est relativement simple : MLOps est l'intégration continue, le déploiement continu, la formation continue et la surveillance continue de "Code+Modèle+Données".
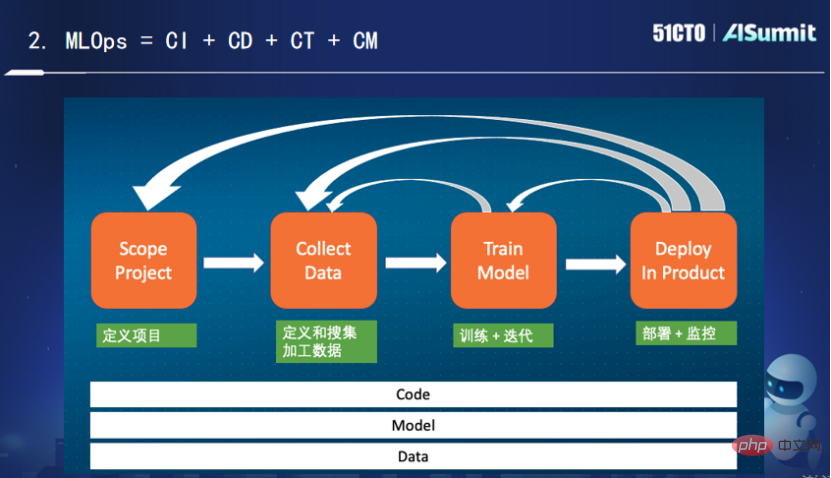
L'image ci-dessus montre une scène de vie typique de l'apprentissage automatique. Après avoir défini la phase du projet, nous commençons à définir et à collecter les données de traitement. Nous devons observer quelles données sont utiles pour résoudre le problème actuel ? Comment traiter, comment réaliser l'ingénierie des fonctionnalités, comment convertir et stocker.
Après avoir collecté les données, nous commençons à entraîner et à itérer le modèle. Nous devons continuellement ajuster l'algorithme, puis continuer à nous entraîner, et enfin obtenir un résultat qui répond aux attentes. Si vous n'êtes pas satisfait du résultat, vous devez revenir à la couche supérieure. À ce stade, vous devez obtenir plus de données, effectuer plus de conversions sur les données, puis vous entraîner à nouveau, en répétant le cycle jusqu'à ce que vous obteniez un résultat plus satisfaisant. algorithme de modèle, puis recommencez le déploiement en ligne.
Pendant le processus de déploiement et de suivi, si l'effet du modèle est incohérent, il est nécessaire d'observer les problèmes survenus lors de la formation et du déploiement. Après avoir été déployé pendant un certain temps, vous pourriez être confronté au problème de la dégradation du modèle et vous devrez vous recycler. Parfois, il y a même un problème avec les données trouvées lors du processus de déploiement, et à ce moment il est nécessaire de revenir à la couche de traitement des données. De plus, l'effet de déploiement est loin de répondre aux attentes du projet et il faudra peut-être revenir au point de départ initial.
Vous pouvez voir que l'ensemble du processus est un processus cyclique et itératif. Pour la pratique de l'ingénierie, nous avons besoin d'une intégration continue, d'un déploiement continu, d'une formation continue et d'une surveillance continue. Parmi eux, la formation continue et la surveillance continue sont propres aux MLOps. Le rôle de la formation continue est que même si le modèle de code ne change pas, il doit quand même être continuellement formé aux modifications de ses données. Le rôle de la surveillance continue est de surveiller en permanence s'il existe des problèmes de correspondance entre les données et le modèle. La surveillance fait ici référence non seulement à la surveillance du système en ligne, mais également à la surveillance de certains indicateurs liés au système et à l'apprentissage automatique, tels que le taux de rappel, le taux de précision, etc. Pour résumer, je pense que MLOps est en fait l'intégration continue, le déploiement continu, la formation continue et la surveillance continue du code, des modèles et des données.
Bien sûr, MLOps ne se limite pas aux processus et aux pipelines, il inclut également un contenu plus important et plus important. Par exemple :
(1) Plateforme de stockage : stockage et lecture des fonctionnalités et des modèles
(2) Plateforme informatique : streaming et traitement par lots pour le traitement des fonctionnalités
(3) File d'attente de messages : utilisée pour recevoir des données en temps réel
(4) Outil de planification : planification de diverses ressources (informatique/stockage)
(5) Feature Store : inscrivez-vous, découvrez et partagez diverses fonctionnalités
( 6 ) Model Store : Caractéristiques du modèle
(7) Evaluation Store : Suivi/AB tests du modèle
Feature Store, Model store et Evaluation store sont tous des applications et plateformes émergentes dans le domaine de l'apprentissage automatique, car parfois elles sont en ligne en même temps. L'exécution de plusieurs modèles et la réalisation d'itérations rapides nécessitent une bonne infrastructure pour conserver ces informations afin de rendre l'itération plus efficace. Ces nouvelles applications et nouvelles plates-formes ont émergé au fur et à mesure que les temps l'exigent.
Projet unique de MLOps - Feature Store
Ce qui suit est une brève introduction à Feature Store, qui est la plate-forme de fonctionnalités. En tant que plateforme unique dans le domaine du machine learning, Feature Store possède de nombreuses fonctionnalités.
Tout d'abord, il est nécessaire de répondre à la fois aux exigences de formation des modèles et de prédiction. Les moteurs de stockage de données de fonctionnalités ont des exigences d’application complètement différentes selon les scénarios. La formation des modèles nécessite une bonne évolutivité et un grand espace de stockage ; la prédiction en temps réel doit répondre aux exigences de hautes performances et de faible latence.
Deuxièmement, le problème d'incohérence entre le traitement des fonctionnalités lors des étapes de formation et de prédiction doit être résolu. Lors de la formation du modèle, les scientifiques en IA utilisent généralement des scripts Python, puis utilisent Spark ou SparkSQL pour terminer le traitement des fonctionnalités. Ce type de formation n'est pas sensible aux retards et est moins efficace lorsqu'il s'agit d'affaires en ligne. Par conséquent, les ingénieurs utiliseront un langage plus performant pour traduire le processus de traitement des fonctionnalités. Cependant, le processus de traduction est extrêmement fastidieux et les ingénieurs doivent vérifier à plusieurs reprises auprès des scientifiques si la logique est conforme aux attentes. Tant qu'il y a une légère incohérence avec les attentes, cela entraînera un problème d'incohérence entre la ligne et la ligne.
Troisièmement, le problème de la réutilisation dans le traitement des fonctionnalités doit être résolu pour éviter le gaspillage et partager efficacement. Dans les applications d'IA d'une entreprise, cette situation se produit souvent : la même fonctionnalité est utilisée par différents services métier, la source de données provient du même fichier journal et la logique d'extraction effectuée au milieu est également similaire, mais parce qu'elle se trouve dans des services différents. Ou utilisé dans différents scénarios, il ne peut pas être réutilisé, ce qui équivaut à l'exécution N fois de la même logique, et les fichiers journaux sont volumineux, ce qui représente un énorme gaspillage de ressources de stockage et de ressources informatiques.
En résumé, Feature Store est principalement utilisé pour résoudre le stockage et les services de fonctionnalités hautes performances, la cohérence des données de fonctionnalités, la réutilisation des fonctionnalités et d'autres problèmes liés à la formation de modèles et à la prédiction de modèles. Les scientifiques des données peuvent utiliser Feature Store pour le déploiement et le partage.
Les produits de plateforme de fonctionnalités grand public actuellement sur le marché peuvent être grossièrement divisés en trois catégories.
- Chaque entreprise d'IA mène des auto-recherches. Tant que l'entreprise nécessite une formation en temps réel, ces entreprises développeront essentiellement une plate-forme de fonctionnalités similaire pour résoudre les trois problèmes ci-dessus. Mais cette plateforme de fonctionnalités est profondément liée au business.
- Produits SAAS ou partie de la plateforme d'apprentissage automatique fournie par les fournisseurs de cloud. Par exemple, SageMaker fourni par AWS, Vertex fourni par Google et la plateforme d'apprentissage automatique Azure fournie par Microsoft. Ils disposeront d'une plate-forme de fonctionnalités intégrée à la plate-forme d'apprentissage automatique pour permettre aux utilisateurs de gérer diverses fonctionnalités complexes.
- Quelques produits open source et commerciaux. Pour donner quelques exemples, Feast, un produit Feature Store open source ; Tecton fournit un produit de plate-forme de fonctionnalités commerciales open source complet ; OpenMLDB, un produit Feature Store open source.
Modèle de maturité MLOps
Le modèle de maturité est utilisé pour mesurer les objectifs de capacité d'un système et d'un ensemble de règles. Dans le domaine DevOps, le modèle de maturité est souvent utilisé pour évaluer les capacités DevOps d'une entreprise. Il existe également un modèle de maturité correspondant dans le domaine du MLOps, mais il n'a pas encore été standardisé. Voici une brève introduction au modèle de maturité d'Azure concernant MLOps.
Selon le degré d'automatisation de l'ensemble du processus d'apprentissage automatique, le modèle mature de MLOps est divisé en (0, 1, 2, 3, 4) niveaux, dont 0 signifie aucune automatisation. (1,2,3) est une automatisation partielle, 4 est hautement automatisé

Le niveau de maturité est 0, c'est-à-dire qu'il n'y a pas de MLOps. Cette étape signifie que la préparation des données est manuelle, la formation du modèle est également manuelle et le déploiement de la formation du modèle est également manuel. Tout le travail est effectué manuellement, ce qui convient à certaines directions métiers qui mènent des projets pilotes innovants sur l’IA.
Le niveau de maturité est 1, c'est-à-dire qu'il y a DevOps mais pas de MLOps. Sa préparation des données se fait automatiquement, mais la formation du modèle se fait manuellement. Une fois que les scientifiques ont obtenu les données, ils effectuent divers ajustements et formations avant de les terminer. Le déploiement du modèle se fait également manuellement.
Le niveau de maturité est 2, ce qui correspond à une formation automatisée. La formation du modèle est terminée automatiquement. En bref, une fois les données mises à jour, un pipeline similaire est immédiatement démarré pour la formation automatisée. Cependant, l'évaluation et le lancement des résultats de la formation sont toujours effectués manuellement.
Le niveau de maturité est 3, ce qui correspond à un déploiement automatisé. Une fois la formation automatique du modèle terminée, l'évaluation et le lancement du modèle s'effectuent automatiquement sans intervention manuelle.
Le niveau de maturité est de 4, ce qui signifie reconversion et déploiement automatique. Il surveille en permanence le modèle en ligne. Lorsqu'il s'avère que la capacité du modèle en ligne du modèle DK s'est dégradée, il déclenche automatiquement une formation répétée. L'ensemble du processus est entièrement automatisé, ce qui peut être qualifié de système le plus abouti.
Pour du contenu plus passionnant, veuillez consulter le site officiel de la conférence : Cliquez pour voir
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Tendances technologiques à surveiller en 2023
- Comment l'intelligence artificielle apporte un nouveau travail quotidien aux équipes des centres de données
- L'intelligence artificielle ou l'automatisation peuvent-elles résoudre le problème de la faible efficacité énergétique des bâtiments ?
- Co-fondateur d'OpenAI interviewé par Huang Renxun : les capacités de raisonnement de GPT-4 n'ont pas encore atteint les attentes
- Bing de Microsoft surpasse Google en termes de trafic de recherche grâce à la technologie OpenAI