
Maison >Périphériques technologiques >IA >Un moyen simple de traiter de grands ensembles de données d'apprentissage automatique en Python
Un moyen simple de traiter de grands ensembles de données d'apprentissage automatique en Python

- 王林avant
- 2023-04-09 19:51:011814parcourir
Public cible pour cet article :
- Les personnes qui souhaitent effectuer des opérations Pandas/NumPy sur de grands ensembles de données.
- Les personnes souhaitant utiliser Python pour effectuer des tâches d'apprentissage automatique sur le Big Data.

Cet article utilisera des fichiers au format .csv pour démontrer diverses opérations de python, ainsi que d'autres formats tels que des tableaux, des fichiers texte, etc.
Pourquoi ne pouvons-nous pas utiliser des pandas pour de grands ensembles de données d'apprentissage automatique ?
Nous savons que Pandas utilise la mémoire de l'ordinateur (RAM) pour charger votre ensemble de données d'apprentissage automatique, mais si votre ordinateur dispose de 8 Go de mémoire (RAM), pourquoi les pandas ne peuvent-ils toujours pas charger un ensemble de données de 2 Go ? La raison en est que le chargement d'un fichier de 2 Go à l'aide de Pandas nécessite non seulement 2 Go de RAM, mais plus de mémoire, car la mémoire totale requise dépend de la taille de l'ensemble de données et des opérations que vous effectuerez sur cet ensemble de données.
Voici une comparaison rapide des ensembles de données de différentes tailles chargés dans la mémoire de l'ordinateur :
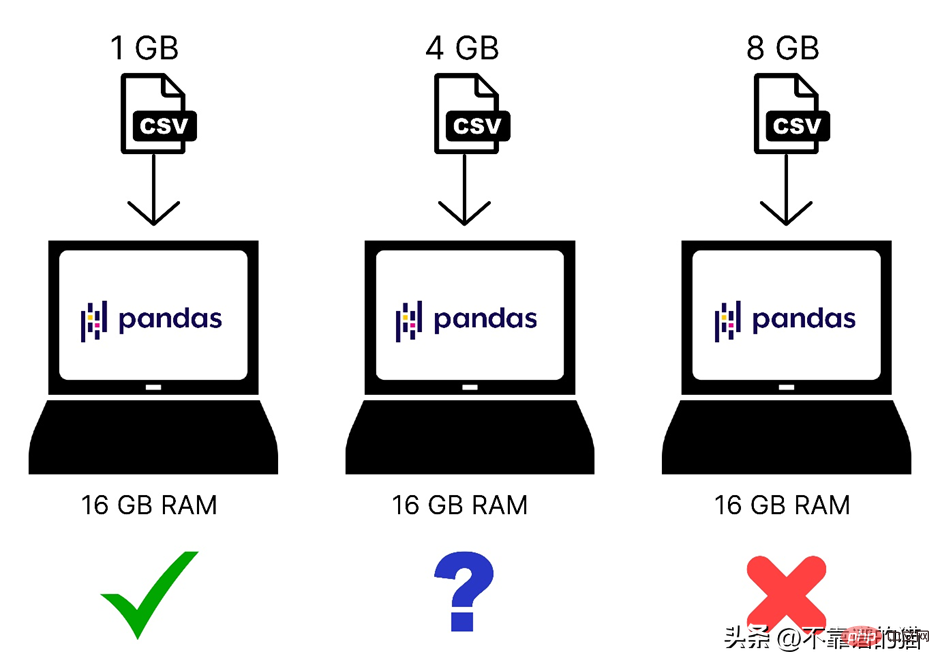
De plus, Pandas n'utilise qu'un seul cœur du système d'exploitation, ce qui ralentit le traitement. En d’autres termes, nous pouvons dire que pandas ne prend pas en charge le parallélisme (divisant un problème en tâches plus petites).
Supposons que l'ordinateur dispose de 4 cœurs. La figure suivante montre le nombre de cœurs utilisés par les pandas lors du chargement d'un fichier CSV :
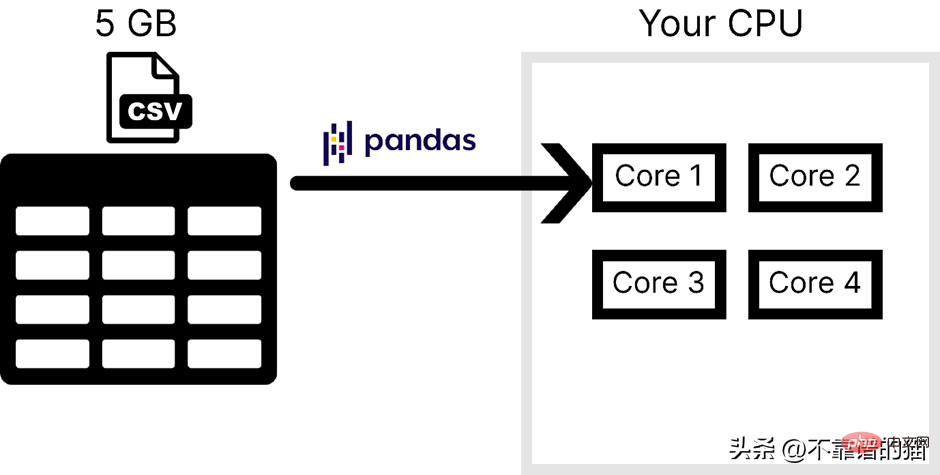
Les principales raisons pour lesquelles les pandas ne sont généralement pas utilisés pour traiter de grands ensembles de données d'apprentissage automatique sont les suivantes : suit : l’un est l’utilisation de la mémoire de l’ordinateur et le second est le manque de parallélisme. Dans NumPy et Scikit-learn, le même problème se pose pour les grands ensembles de données.
Pour résoudre ces deux problèmes, vous pouvez utiliser une bibliothèque python appelée Dask, qui nous permet d'effectuer diverses opérations telles que pandas, NumPy et ML sur de grands ensembles de données.
Comment fonctionne Dask ?
Dask charge votre ensemble de données dans des partitions, tandis que pandas charge généralement l'intégralité de l'ensemble de données d'apprentissage automatique sous forme de trame de données. Dans Dask, chaque partition d'un ensemble de données est considérée comme une trame de données pandas.
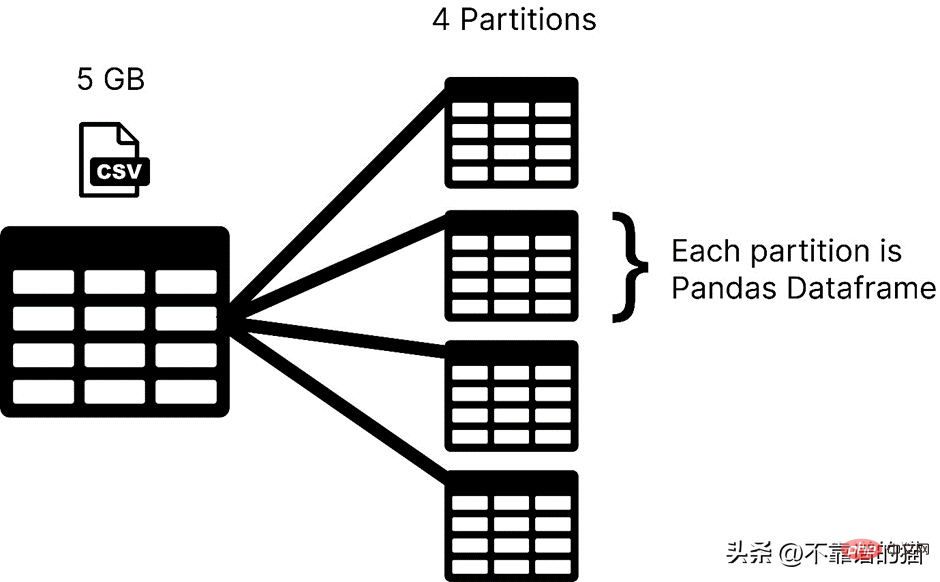
Dask charge une partition à la fois, vous n'avez donc pas à vous soucier des erreurs d'allocation de mémoire.
Voici une comparaison de l'utilisation de dask pour charger des ensembles de données d'apprentissage automatique de différentes tailles dans la mémoire de l'ordinateur :
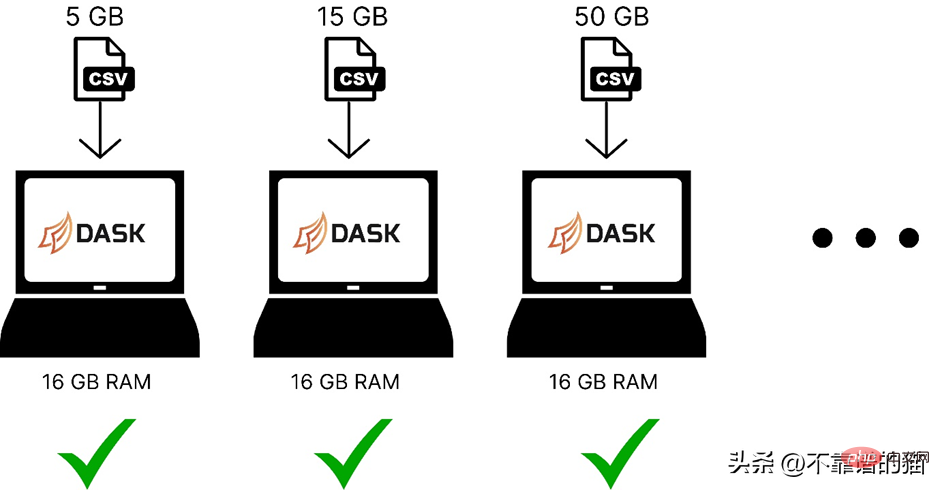
Dask résout le problème du parallélisme car il divise les données en plusieurs partitions, en utilisant un noyau distinct, qui effectue les calculs. sur l'ensemble de données plus rapidement.
En supposant que l'ordinateur ait 4 cœurs, voici comment dask charge un fichier csv de 5 Go :
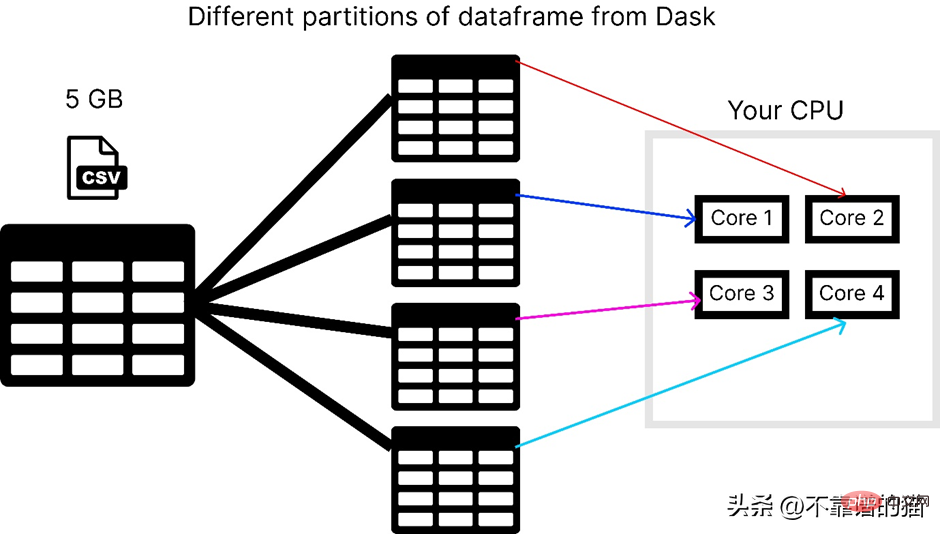
Pour utiliser la bibliothèque dask, vous pouvez l'installer à l'aide de la commande suivante :
<span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">pip</span> <span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">install</span> <span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">dask</span>
Dask possède plusieurs modules comme dask. array, dask.dataframe et dask.distributed ne fonctionneront que si vous avez installé respectivement les bibliothèques correspondantes (telles que NumPy, pandas et Tornado).
Comment utiliser dask pour traiter des fichiers CSV volumineux ?
dask.dataframe est utilisé pour gérer de gros fichiers csv, j'ai d'abord essayé d'importer un ensemble de données de 8 Go à l'aide de pandas.
<span style="color: rgb(215, 58, 73); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">import</span> <span style="color: rgb(0, 92, 197); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">pandas</span> <span style="color: rgb(215, 58, 73); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">as</span> <span style="color: rgb(0, 92, 197); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">pd</span><br><span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">df</span> <span style="color: rgb(215, 58, 73); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">=</span> <span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">pd</span>.<span style="color: rgb(0, 92, 197); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">read_csv</span>(<span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">“data</span>.<span style="color: rgb(0, 92, 197); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">csv”</span>)
Il a généré une erreur d'allocation de mémoire dans mon ordinateur portable de 16 Go de RAM.
Maintenant, essayez d'importer les mêmes données de 8 Go en utilisant dask.dataframe
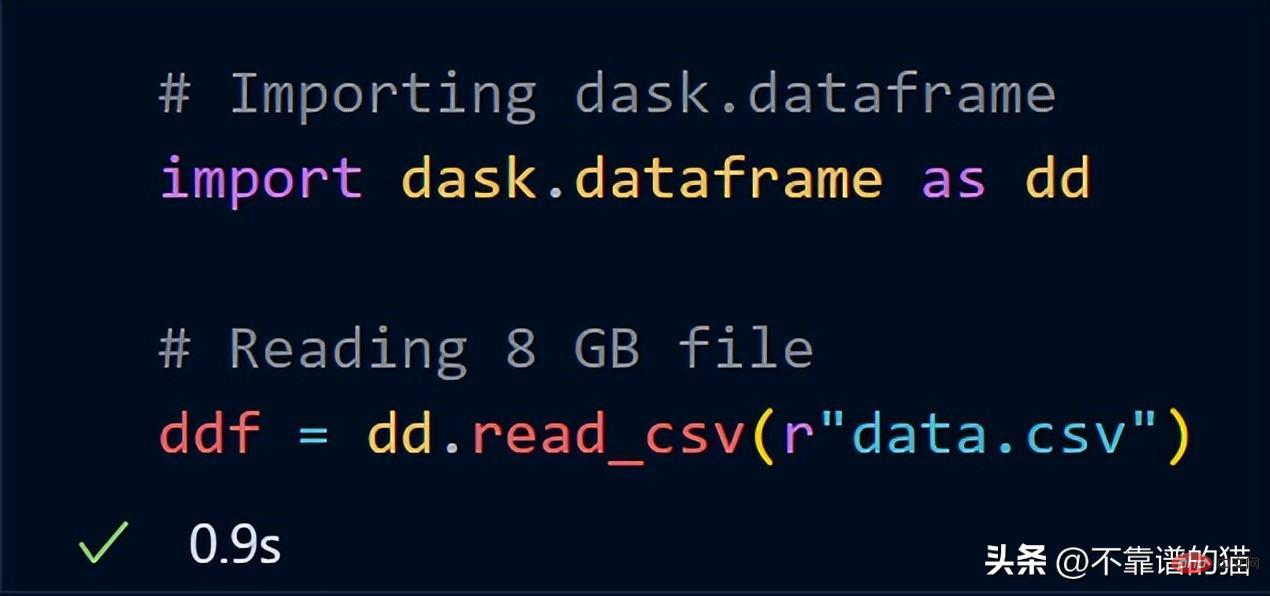
dask n'a pris qu'une seconde pour charger l'intégralité du fichier de 8 Go dans la variable ddf.
Voyons le résultat de la variable ddf.
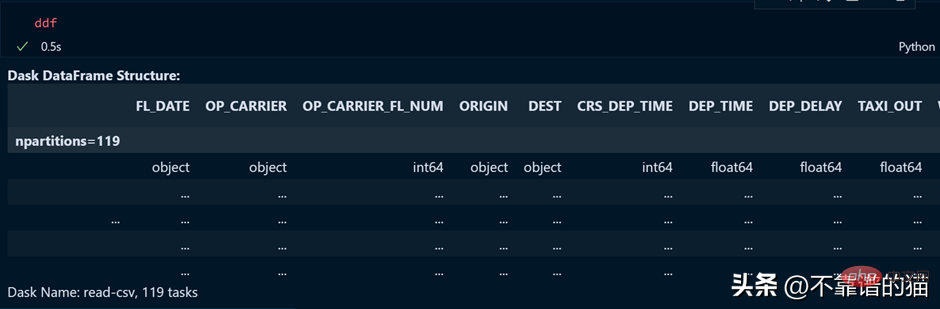
Comme vous pouvez le constater, le temps d'exécution est de 0,5 seconde, et il est montré ici qu'il a été divisé en 119 partitions.
Vous pouvez également vérifier le nombre de partitions de votre dataframe en utilisant :
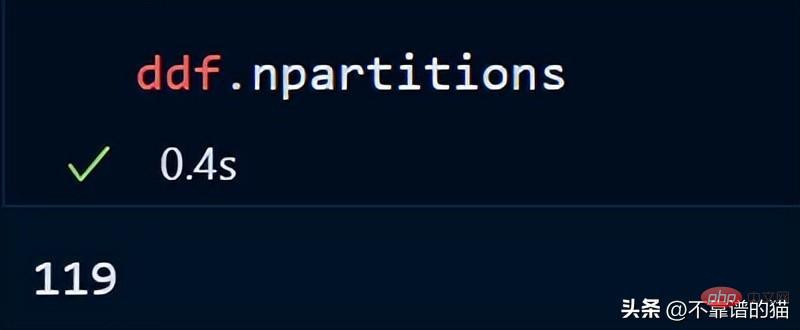
Par défaut, dask a chargé mon fichier CSV de 8 Go dans 119 partitions (chaque taille de partition est de 64 Mo), ceci est basé sur ce qui est disponible. effectué en fonction de la mémoire physique et du nombre de cœurs de l'ordinateur.
Peut également spécifier mon propre nombre de partitions en utilisant le paramètre Blocksize lors du chargement du fichier CSV.
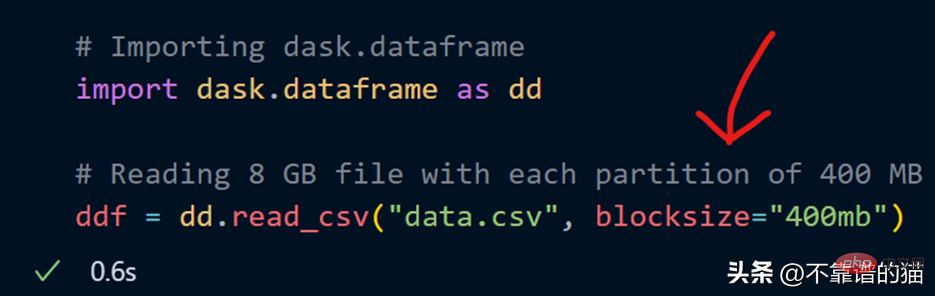
Maintenant, un paramètre de taille de bloc avec une valeur de chaîne de 400 Mo est spécifié, ce qui donne à chaque partition une taille de 400 Mo. Voyons combien de partitions il y a
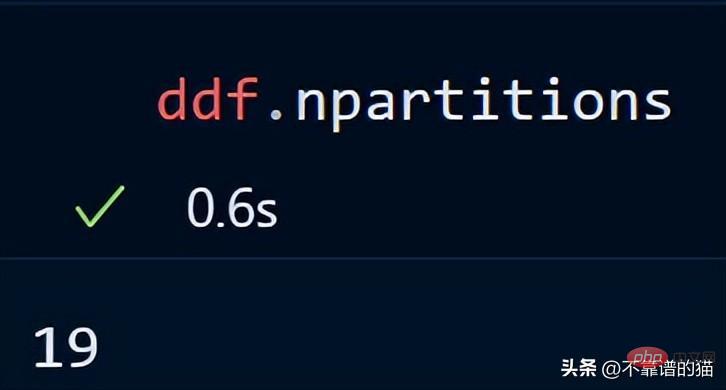
Point clé : lors de l'utilisation de Dask DataFrames, une bonne règle une solution empirique consiste à conserver les partitions sous 100 Mo.
Une partition spécifique du dataframe peut être appelée en utilisant :
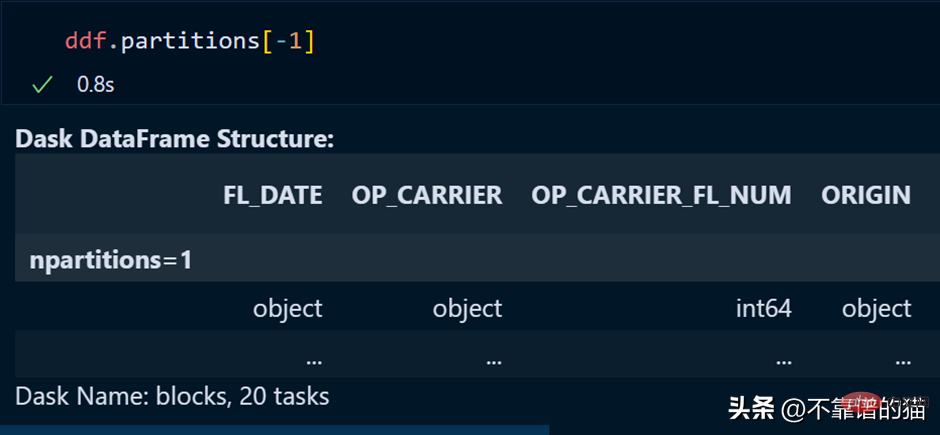
La dernière partition peut également être appelée en utilisant un index négatif, tout comme nous l'avons fait lors de l'appel du dernier élément de la liste.
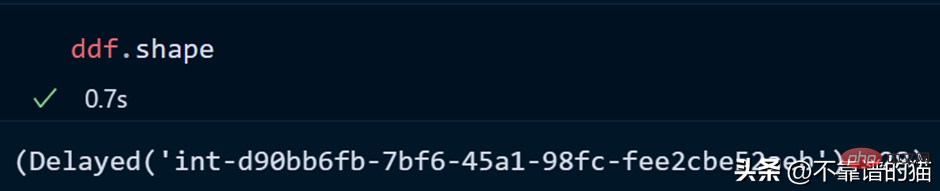
Voyons la forme de l'ensemble de données :
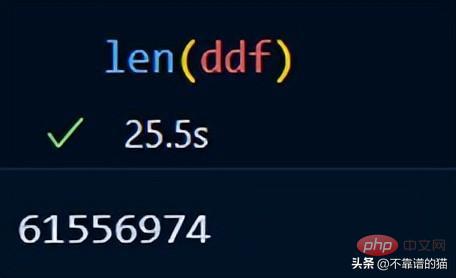
Vous pouvez utiliser len() pour vérifier le nombre de lignes dans l'ensemble de données :
Dask inclut déjà un exemple d'ensemble de données. J'utiliserai des données de séries chronologiques pour vous montrer comment dask effectue des opérations mathématiques sur un ensemble de données.
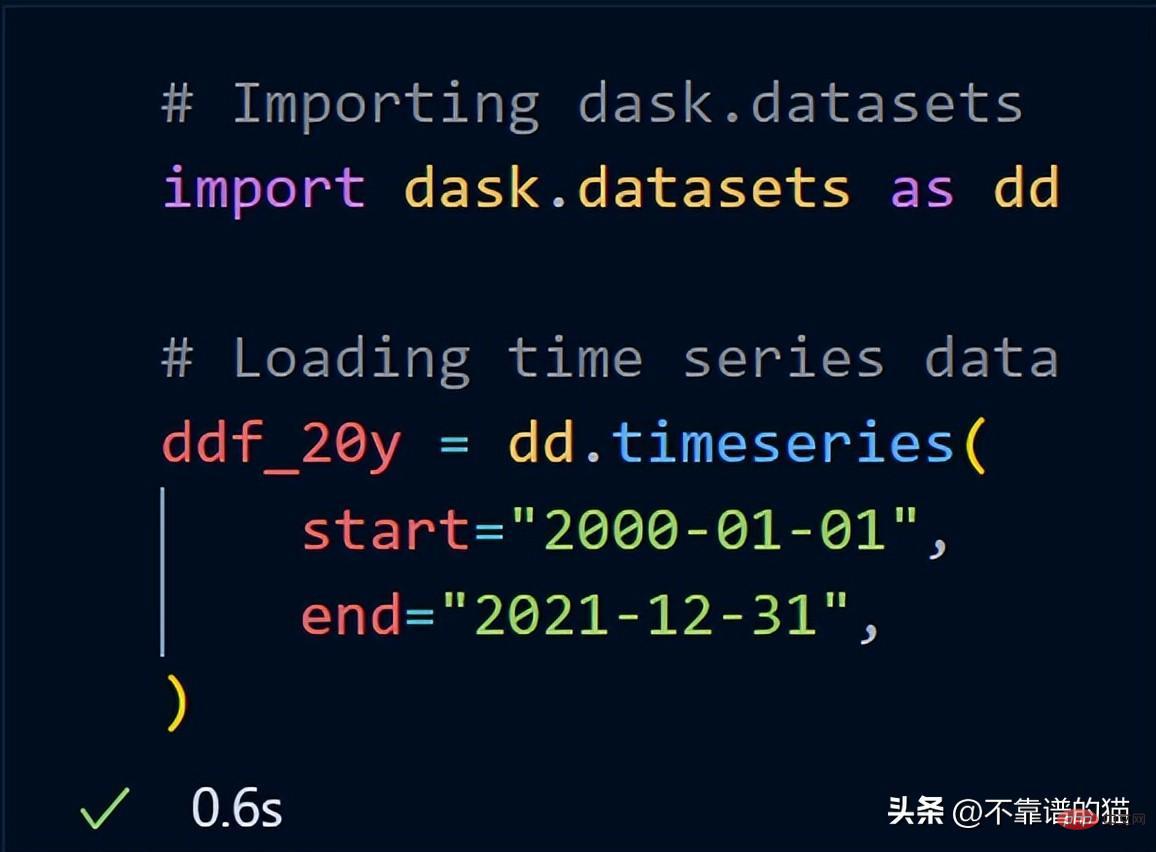
Après avoir importé dask.datasets, ddf_20y a chargé les données de séries chronologiques du 1er janvier 2000 au 31 décembre 2021.
Regardons le nombre de partitions pour nos données de séries chronologiques.
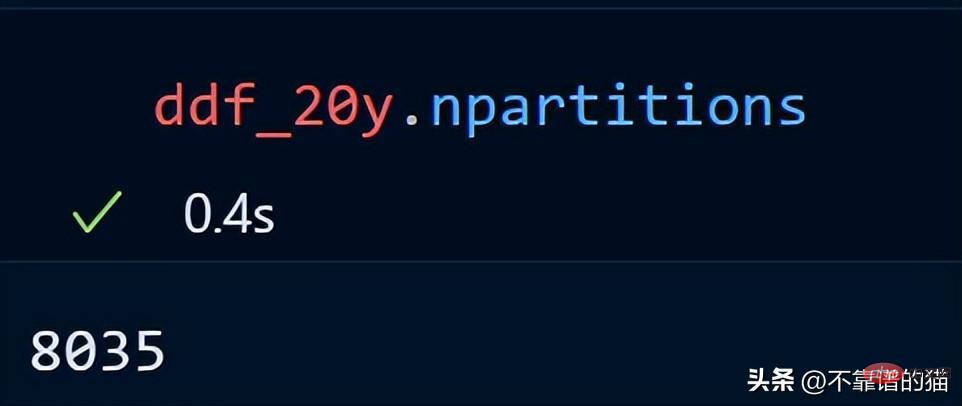
Les données de séries chronologiques sur 20 ans sont réparties dans 8035 partitions.
Chez les pandas, nous utilisons head pour imprimer les premières lignes de l'ensemble de données, et il en va de même pour dask.
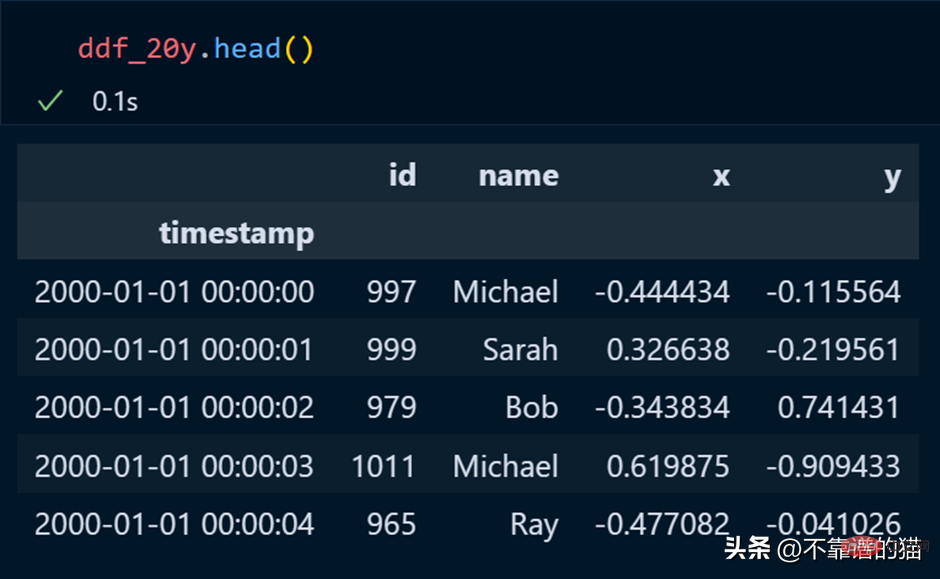
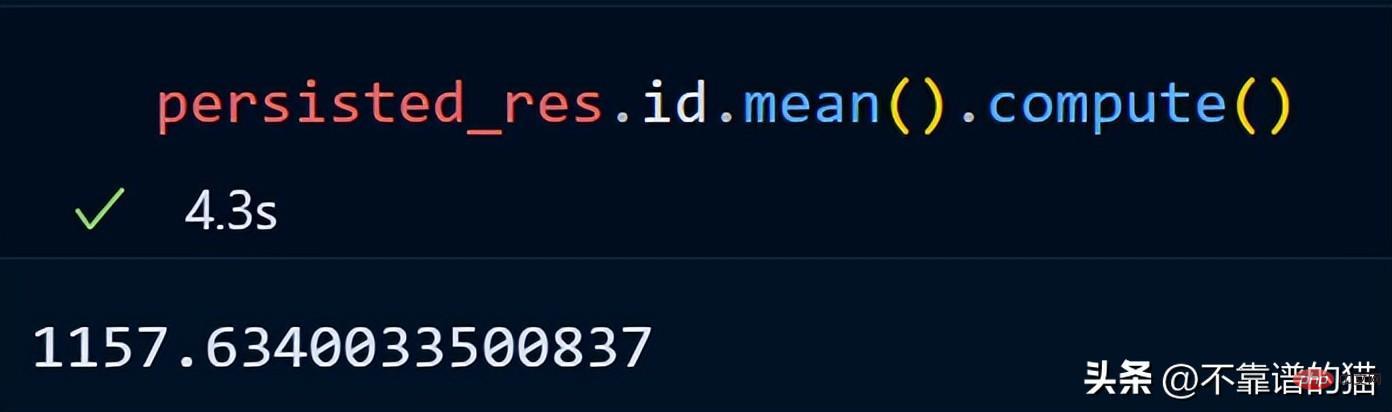
Calculons la moyenne de la colonne id.
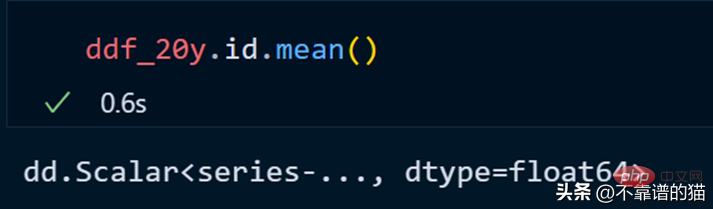
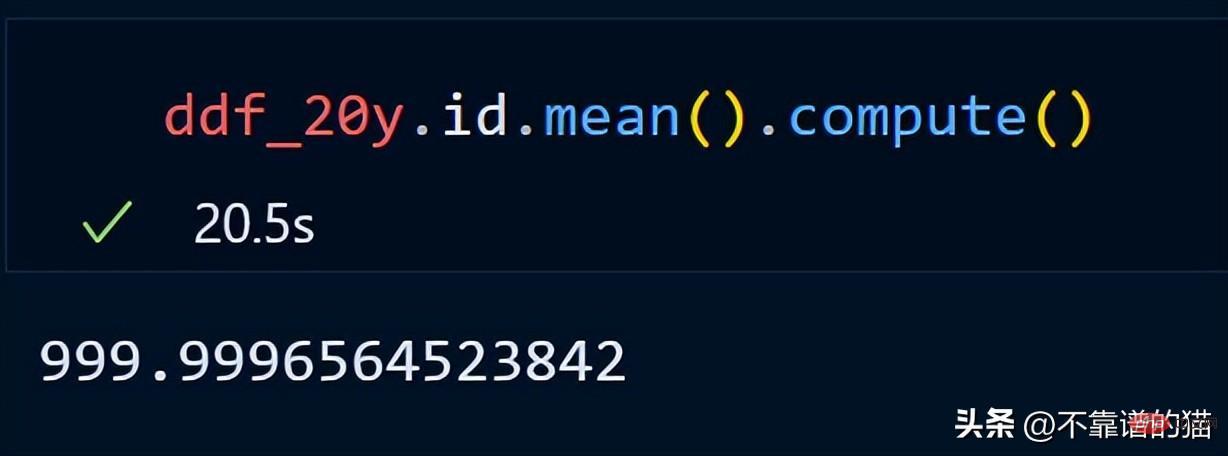
dask n'imprime pas le nombre total de lignes du dataframe car il utilise des calculs paresseux (la sortie n'est affichée que lorsque cela est nécessaire). Pour afficher la sortie, nous pouvons utiliser la méthode de calcul.
Supposons que je veuille normaliser chaque colonne de l'ensemble de données (convertir la valeur entre 0 et 1), le code Python est le suivant :
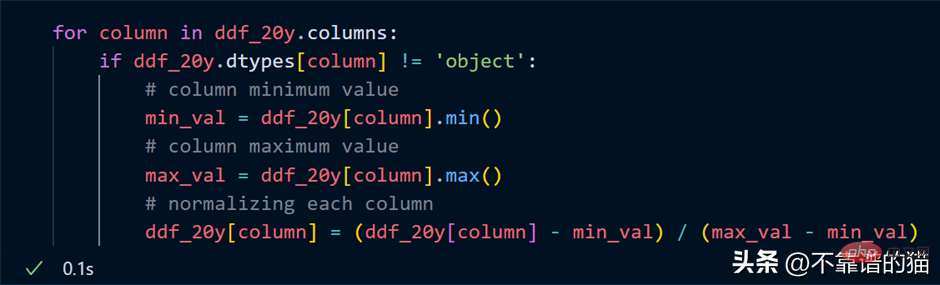
Parcourez les colonnes et trouvez la somme minimale de chacune valeur maximale de la colonne et normalisez ces colonnes à l’aide d’une formule mathématique simple.
Point clé : dans notre exemple de normalisation, ne pensez pas qu'un calcul numérique réel se produit, il s'agit simplement d'une évaluation paresseuse (le résultat ne vous est jamais montré tant qu'il n'est pas nécessaire).
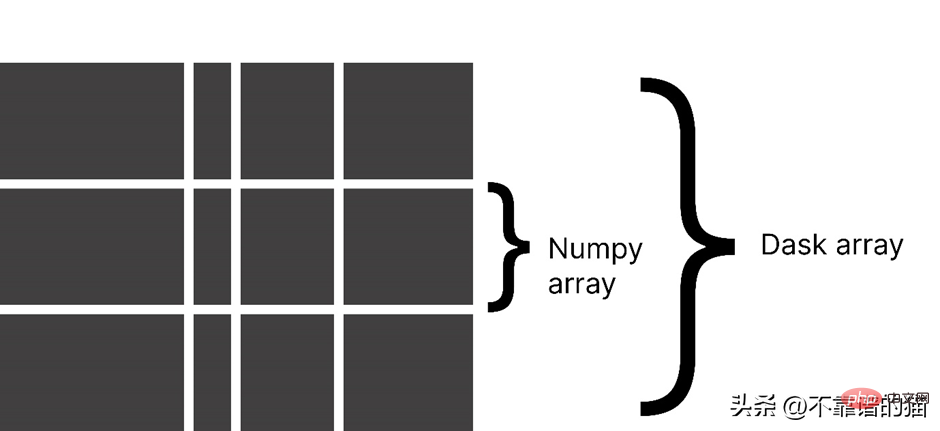
Pourquoi utiliser le tableau Dask ?
Dask divise un tableau en petits morceaux, chaque morceau étant un tableau NumPy.
dask.arrays est utilisé pour gérer de grands tableaux, le code Python suivant utilise dask pour créer un tableau de 10 000 x 10 000 et le stocke dans la variable x.
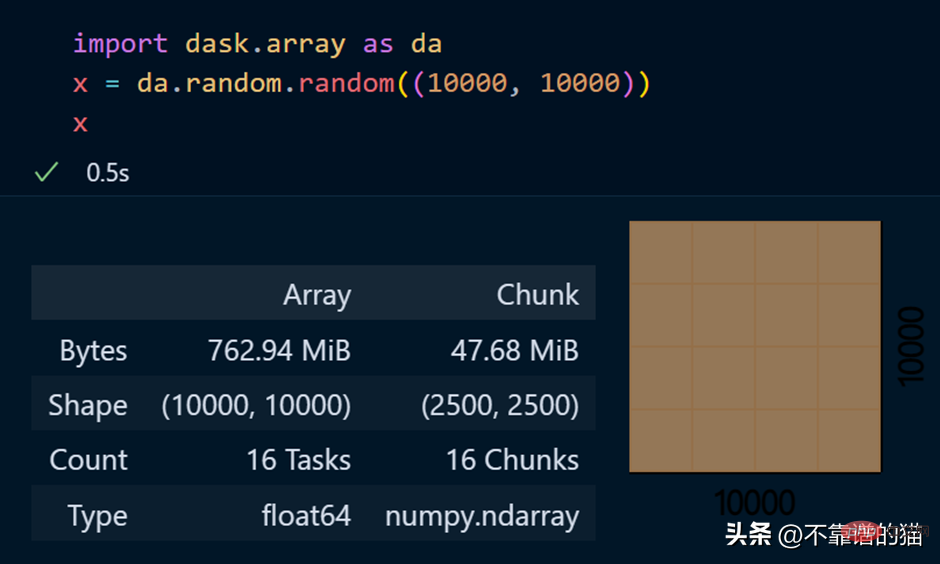
L'appel de la variable x produit diverses informations sur le tableau.
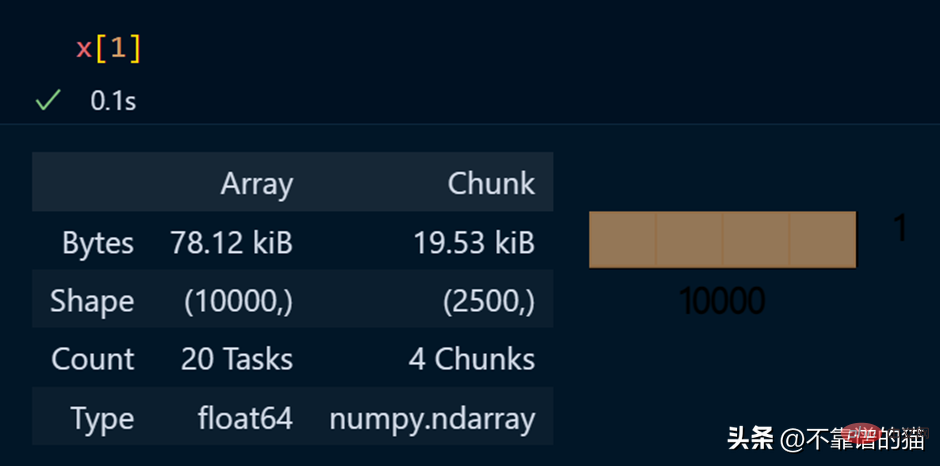
Afficher des éléments spécifiques d'un tableau
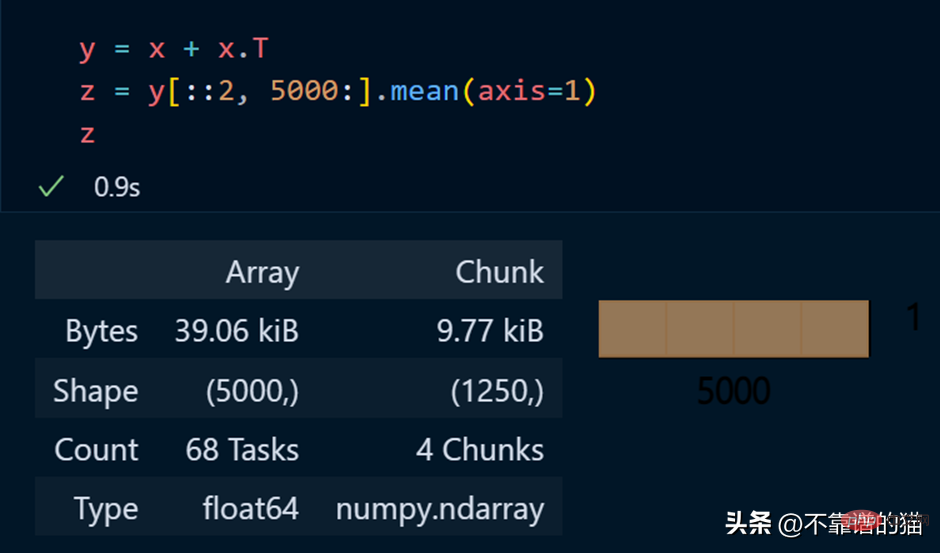
Exemple Python d'exécution d'opérations mathématiques sur un tableau dask :
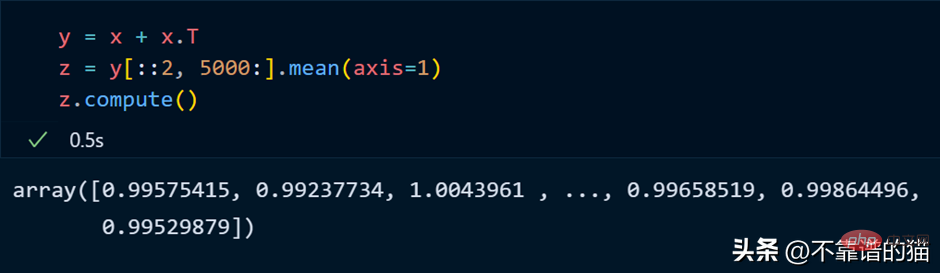
正如您所看到的,由于延迟执行,它不会向您显示输出。我们可以使用compute来显示输出:
dask 数组支持大多数 NumPy 接口,如下所示:
- 数学运算:+, *, exp, log, ...
- sum(), mean(), std(), sum(axis=0), ...
- 张量/点积/矩阵乘法:tensordot
- 重新排序/转置:transpose
- 切片:x[:100, 500:100:-2]
- 使用列表或 NumPy 数组进行索引:x[:, [10, 1, 5]]
- 线性代数:svd、qr、solve、solve_triangular、lstsq
但是,Dask Array 并没有实现完整 NumPy 接口。
你可以从他们的官方文档中了解更多关于 dask.arrays 的信息。
什么是Dask Persist?
假设您想对机器学习数据集执行一些耗时的操作,您可以将数据集持久化到内存中,从而使数学运算运行得更快。
从 dask.datasets 导入了时间序列数据
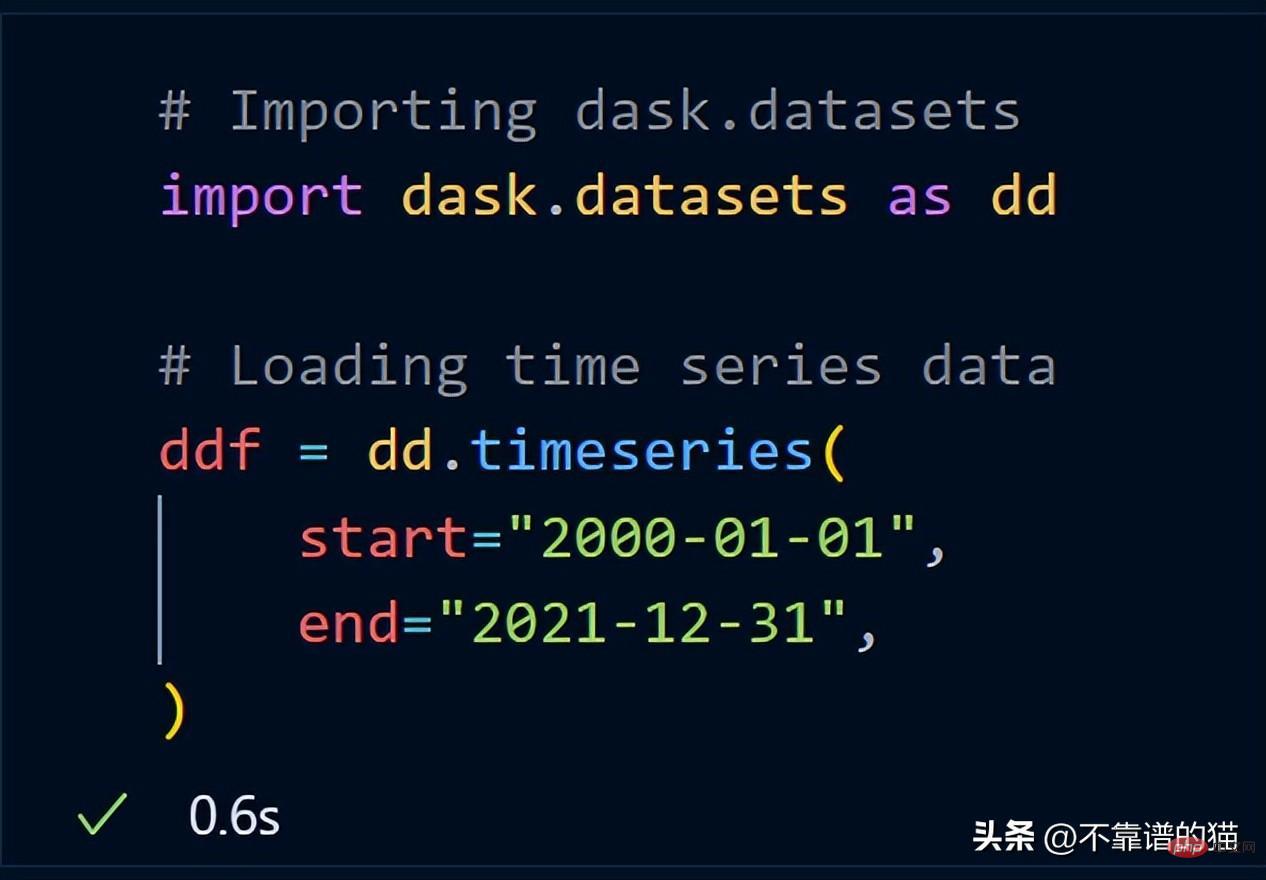
让我们取数据集的一个子集并计算该子集的总行数。
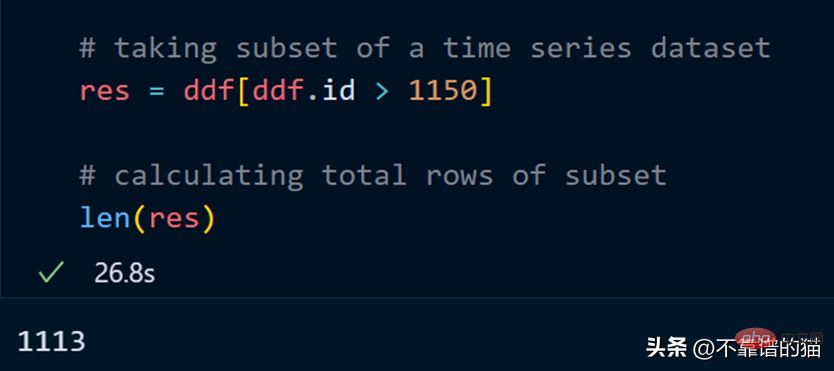
计算总行数需要 27 秒。
我们现在使用 persist 方法:
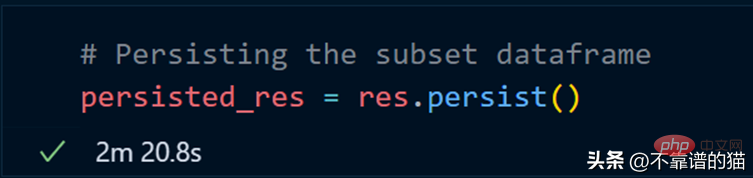
持久化我们的子集总共花了 2 分钟,现在让我们计算总行数。
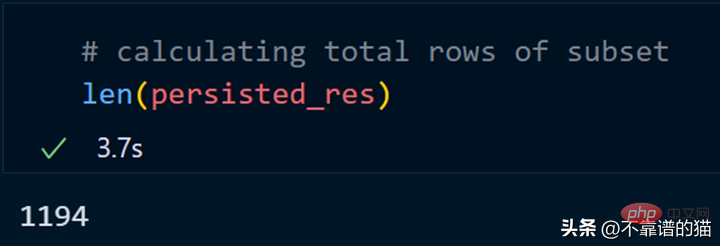
同样,我们可以对持久化数据集执行其他操作以减少计算时间。
persist应用场景:
- 数据量大
- 获取数据的一个子集
- 对子集应用不同的操作
为什么选择 Dask ML?
Dask ML有助于在大型数据集上使用流行的Python机器学习库(如Scikit learn等)来应用ML(机器学习)算法。
什么时候应该使用 dask ML?
- 数据不大(或适合 RAM),但训练的机器学习模型需要大量超参数,并且调优或集成技术需要大量时间。
- 数据量很大。
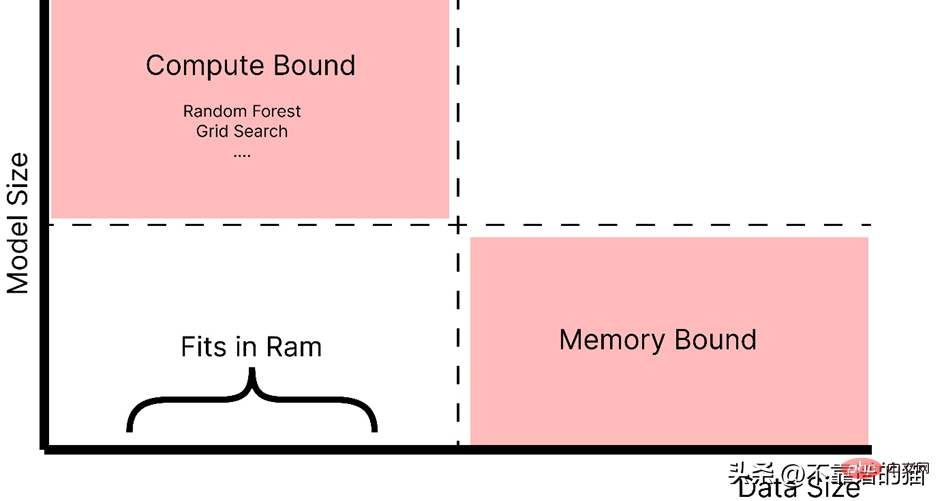
正如你所看到的,随着模型大小的增加,例如,制作一个具有大量超参数的复杂模型,它会引起计算边界的问题,而如果数据大小增加,它会引起内存分配错误。因此,在这两种情况下(红色阴影区域)我们都使用 Dask 来解决这些问题。
如官方文档中所述,dask ml 库用例:
- 对于内存问题,只需使用 scikit-learn(或其他ML 库)。
- 对于大型模型,使用 dask_ml.joblib 和scikit-learn estimators。
- 对于大型数据集,使用 dask_ml estimators。
让我们看一下 Dask.distributed 的架构:
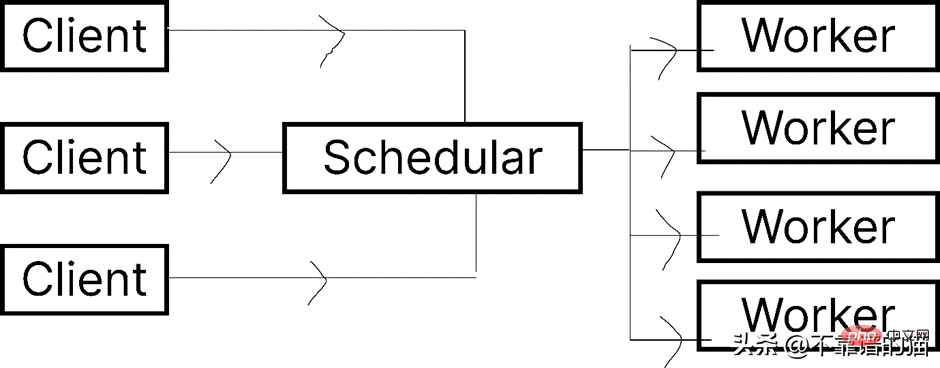
Dask 让您能够在计算机集群上运行任务。在 dask.distributed 中,只要您分配任务,它就会立即开始执行。
简单地说,client就是提交任务的你,执行任务的是Worker,调度器则执行两者之间通信。
python -m <span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">pip</span> <span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">install</span> <span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">dask</span> distributed –upgrade
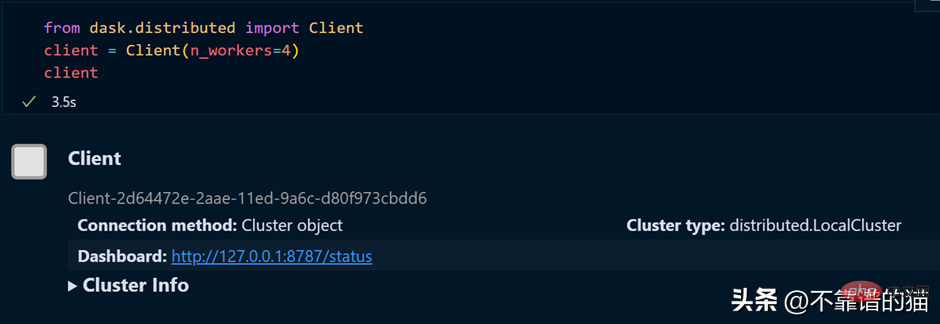
如果您使用的是单台机器,那么就可以通过以下方式创建一个具有4个worker的dask集群
如果需要dashboard,可以安装bokeh,安装bokeh的命令如下:
<span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">pip</span> <span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">install</span> <span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">bokeh</span>
就像我们从 dask.distributed 创建客户端一样,我们也可以从 dask.distributed 创建调度程序。
要使用 dask ML 库,您必须使用以下命令安装它:
<span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">pip</span> <span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">install</span> <span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">dask</span>-ml
我们将使用 Scikit-learn 库来演示 dask-ml 。
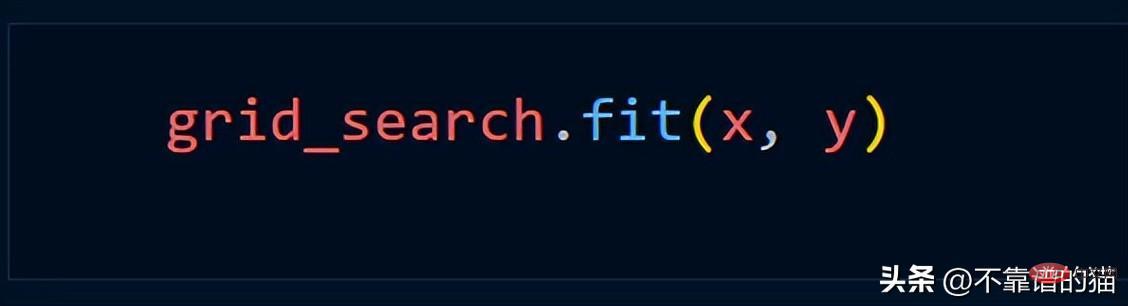
En supposant que nous utilisons la méthode Grid_Search, nous utilisons généralement le code Python suivant
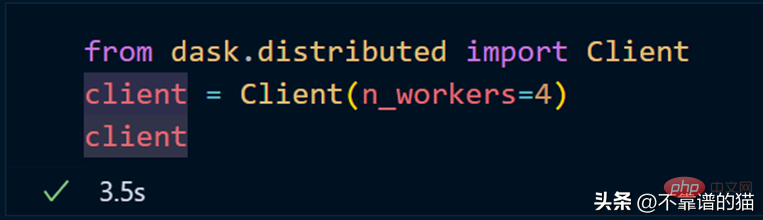
Créez un cluster à l'aide de dask.distributed :
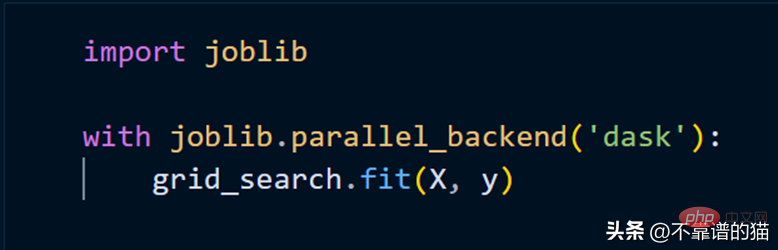
Pour adapter le modèle scikit-learn à l'aide de clusters, il nous suffit d'utiliser joblib.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Tendances technologiques à surveiller en 2023
- Comment l'intelligence artificielle apporte un nouveau travail quotidien aux équipes des centres de données
- L'intelligence artificielle ou l'automatisation peuvent-elles résoudre le problème de la faible efficacité énergétique des bâtiments ?
- Co-fondateur d'OpenAI interviewé par Huang Renxun : les capacités de raisonnement de GPT-4 n'ont pas encore atteint les attentes
- Bing de Microsoft surpasse Google en termes de trafic de recherche grâce à la technologie OpenAI