
Maison >Périphériques technologiques >IA >Les sources de données restent le principal goulot d'étranglement de l'intelligence artificielle
Les sources de données restent le principal goulot d'étranglement de l'intelligence artificielle

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBavant
- 2023-04-09 10:41:031207parcourir
Selon le rapport « State of Artificial Intelligence and Machine Learning » d'Appen publié cette semaine, les agences ont toujours du mal à obtenir des données fiables et propres pour soutenir leurs programmes d'intelligence artificielle et d'apprentissage automatique.

Selon l'enquête d'Appen auprès de 504 chefs d'entreprise et experts techniques, parmi les quatre étapes de l'intelligence artificielle, la source de données ; la préparation et le déploiement du modèle dirigé par l'homme ; le plus de ressources, prend le plus de temps et constitue le plus difficile.
Selon l'enquête d'Appen, les sources de données consomment en moyenne 34 % du budget d'intelligence artificielle d'une organisation, la préparation des données, les tests et le déploiement de modèles représentant chacun 24 % et l'évaluation des modèles 15 %. L'enquête a été menée par Harris Poll auprès de décideurs informatiques, de chefs d'entreprise et de gestionnaires, ainsi que de praticiens de la technologie des États-Unis, du Royaume-Uni, d'Irlande et d'Allemagne.
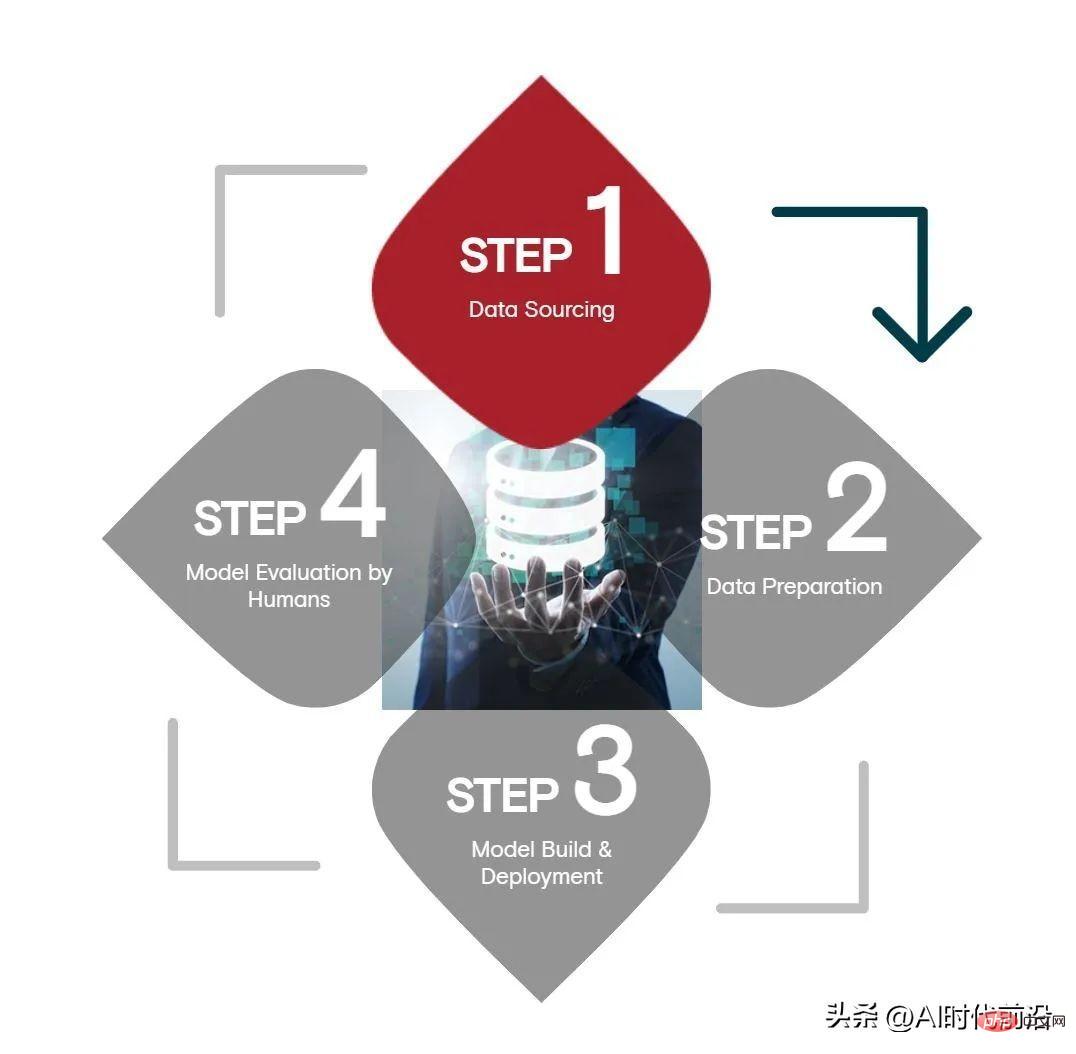
En termes de temps, les sources de données consomment environ 26 % du temps, le temps de préparation des données est de 24 %, le temps de test, de déploiement et d'évaluation du modèle est chacun de 23 %. Enfin, 42 % des techniciens estiment que l'approvisionnement en données est l'étape la plus difficile du cycle de vie de l'IA. Les autres étapes sont : l'évaluation du modèle (41 %), les tests et le déploiement du modèle (38 %) et la préparation des données (34 %). ) .
Malgré les défis, les organisations travaillent dur pour que cela fonctionne. Selon Appen, quatre cinquièmes (81 %) des personnes interrogées ont déclaré disposer de suffisamment de données pour soutenir leurs initiatives en matière d'IA. La clé du succès pourrait être la suivante : la grande majorité (88 %) des entreprises augmentent leurs données en faisant appel à des fournisseurs externes de données de formation en IA tels qu'Appen.
Cependant, l’exactitude des données reste sujette à caution. Appen a constaté que seulement 20 % des personnes interrogées ont signalé une exactitude des données supérieure à 80 %. Seulement 6 % (environ une personne sur 20) ont déclaré que leurs données étaient exactes à 90 % ou mieux.
Dans cet esprit, selon l'enquête d'Appen, près de la moitié (46 %) des personnes interrogées pensent que l'exactitude des données est importante. Seulement 2 % pensent que l’exactitude des données n’est pas un besoin majeur, tandis que 51 % estiment qu’il s’agit d’un besoin critique.
Le CTO d'Appen, Wilson Pang, a un point de vue différent sur l'importance de la qualité des données, avec 48 % de ses clients estimant que la qualité des données n'est pas importante.
« La précision des données est essentielle au succès des modèles d'IA et de ML, car des données riches en qualité génèrent de meilleurs résultats de modèle et un traitement et une prise de décision cohérents », indique le rapport. « Pour obtenir de bons résultats, les ensembles de données doivent être précis et complets. , et évolutif. »
L'essor de l'apprentissage profond et de l'IA centrée sur les données a fait passer la puissance du succès de l'IA d'une bonne science des données et d'une bonne modélisation de l'apprentissage automatique à une bonne gestion et des balises de données. Cela est particulièrement vrai dans les techniques d'apprentissage par transfert d'aujourd'hui. Les praticiens de l’intelligence artificielle abandonneront un grand modèle de langage ou de vision par ordinateur pré-entraîné et en recycleront une petite partie sur leurs propres données.
De meilleures données peuvent également aider à empêcher que des biais inutiles ne s’infiltrent dans les modèles d’IA, évitant ainsi les mauvais résultats que l’IA peut entraîner. Cela est particulièrement vrai pour les grands modèles de langage.
Le rapport indique : « Avec la montée en puissance des grands modèles linguistiques (LLM) formés sur des données de web scraping multilingues, les entreprises sont confrontées à un autre défi, car les corpus de formation sont remplis de langages toxiques, ainsi que de préjugés raciaux, de genre et religieux. les modèles présentent souvent un comportement indésirable »
Les biais dans les données du réseau soulèvent des problèmes épineux, bien qu'il existe certaines solutions de contournement (modification des programmes d'entraînement, filtrage des données d'entraînement et des résultats du modèle, et apprentissage par les tests), mais davantage de recherches). est nécessaire pour créer une référence « LLM centrée sur l’humain » et une bonne norme pour les méthodes d’évaluation des modèles.
Appen a déclaré que la gestion des données reste le plus grand obstacle auquel est confrontée l'intelligence artificielle. L'enquête révèle que 41 % des personnes interrogées estiment que la gestion des données constitue le plus gros goulot d'étranglement dans le cycle de l'intelligence artificielle. En quatrième position se trouve le manque de données, 30 % des personnes interrogées le citant comme le plus grand obstacle au succès de l'IA.
Mais il y a une bonne nouvelle : le temps que les entreprises consacrent à la gestion et à la préparation des données est en baisse. Appen a déclaré que le taux de cette année était légèrement supérieur à 47 %, contre 53 % dans le rapport de l'année dernière.
« La majorité des personnes interrogées ayant recours à des fournisseurs de données externes, on peut en déduire qu'en externalisant l'approvisionnement et la préparation des données, les data scientists gagnent le temps nécessaire pour gérer, nettoyer et étiqueter correctement leurs données », déclare la société d'étiquetage des données.
Cependant, à en juger par les taux d'erreur relativement élevés dans les données, les organisations ne devraient peut-être pas réduire leurs sources de données et leurs processus de préparation (qu'ils soient internes ou externes). Il existe de nombreux besoins concurrents lorsqu'il s'agit de créer et de maintenir des processus d'IA. La nécessité d'embaucher des professionnels des données qualifiés était un autre besoin majeur identifié par Appen. Cependant, jusqu'à ce que des progrès significatifs soient réalisés dans la gestion des données, les organisations devraient continuer à faire pression sur leurs équipes pour qu'elles continuent de souligner l'importance de la qualité des données.
L'enquête a également révélé que 93 % des organisations sont tout à fait ou plutôt d'accord sur le fait que l'éthique de l'IA devrait être le « fondement » des projets d'IA. Le PDG d'Appen, Mark Brayan, a déclaré que c'était un bon début, mais qu'il restait encore beaucoup de travail à faire. "Le problème est que beaucoup sont confrontés au défi d'essayer de créer une excellente IA avec des ensembles de données médiocres, ce qui crée d'énormes obstacles à la réalisation de leurs objectifs", a déclaré Brayan dans un communiqué de presse.
Selon Appen, selon le rapport collecté sur mesure. les données au sein des entreprises restent le principal ensemble de données utilisé pour l’intelligence artificielle, représentant 38 à 42 % des données. Les données synthétiques ont affiché des performances étonnamment solides, représentant 24 à 38 % des données d'une organisation, tandis que les données pré-étiquetées (généralement provenant de fournisseurs de services de données) représentaient 23 à 31 % des données.
En particulier, les données synthétiques ont le potentiel de réduire l'incidence des biais dans les projets d'IA sensibles, avec 97 % des participants à l'enquête d'Appen déclarant utiliser des données synthétiques pour « développer des ensembles de données de formation inclusifs ».
Autres conclusions intéressantes du rapport :
- 77 % des organisations recyclent leurs modèles mensuellement ou trimestriellement (Interprétation à l'avant-garde de l'ère de l'IA : l'intelligence artificielle n'est pas fixée une fois pour toutes, et est continuellement amélioré en fonction des besoins des applications et doit être constamment mis à jour.)
- 55 % des entreprises américaines déclarent être en avance sur leurs concurrents, alors que la proportion en Europe est de 44 % (Interprétation AI Times Frontier : les Européens sont légèrement inférieurs ; -clé que les Américains.)
- 42% des organisations ont déclaré que l'intelligence artificielle a été "largement" déployée, et dans le rapport sur l'état de l'intelligence artificielle 2021, cette proportion était de 51% (Interprétation de l'avant-garde de l'IA ; (ère : les applications d'intelligence artificielle sont de plus en plus répandues.)
- 7 % des établissements déclarent que leur budget pour l'IA dépasse 5 millions de dollars, contre 9 % l'année dernière. (Interprétation à la pointe de l'ère de l'IA : D'une part, cela peut être dû à la maturité progressive de l'intelligence artificielle qui réduit les coûts, mais montre aussi que l'intelligence artificielle n'est plus un « produit de luxe » et devient progressivement un "must-have" pour les entreprises.)
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Tendances technologiques à surveiller en 2023
- Comment l'intelligence artificielle apporte un nouveau travail quotidien aux équipes des centres de données
- L'intelligence artificielle ou l'automatisation peuvent-elles résoudre le problème de la faible efficacité énergétique des bâtiments ?
- Co-fondateur d'OpenAI interviewé par Huang Renxun : les capacités de raisonnement de GPT-4 n'ont pas encore atteint les attentes
- Bing de Microsoft surpasse Google en termes de trafic de recherche grâce à la technologie OpenAI