
Maison >Périphériques technologiques >IA >Sans accumuler de paramètres ni dépendre du temps, Meta accélère le processus de formation ViT et augmente le débit de 4 fois.
Sans accumuler de paramètres ni dépendre du temps, Meta accélère le processus de formation ViT et augmente le débit de 4 fois.

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBavant
- 2023-04-09 09:21:071041parcourir
À ce stade, le modèle de transformateur visuel (ViT) a été largement utilisé dans diverses tâches de vision par ordinateur telles que la classification d'images, la détection et la segmentation de cibles, et peut obtenir des résultats SOTA en matière de représentation et de reconnaissance visuelles. Étant donné que les performances des modèles de vision par ordinateur sont souvent positivement corrélées au nombre de paramètres et au temps de formation, la communauté IA a expérimenté des modèles ViT à plus grande échelle.
Mais il convient de noter qu'à mesure que les modèles commencent à dépasser l'échelle des téraflops, le domaine a rencontré des goulots d'étranglement majeurs. La formation d'un seul modèle peut prendre des mois et nécessiter des milliers de GPU, ce qui augmente les besoins en accélérateurs et aboutit à des modèles ViT à grande échelle qui excluent de nombreux praticiens.
Afin d'élargir le champ d'utilisation du modèle ViT, les chercheurs de Meta AI ont développé des méthodes de formation plus efficaces. Il est très important d’optimiser la formation pour une utilisation optimale de l’accélérateur. Cependant, ce processus prend du temps et nécessite une expertise considérable. Pour mettre en place une expérience ordonnée, les chercheurs doivent choisir parmi d’innombrables optimisations possibles : chacune des millions d’opérations effectuées au cours d’une session de formation peut être entravée par des inefficacités.
Meta AI a découvert que améliorait l'efficacité du calcul et du stockage en appliquant une série d'optimisations à l'implémentation de ViT dans sa base de code de classification d'images PyCls. Pour les modèles ViT formés à l'aide de PyCI, la méthode de Meta AI peut améliorer la vitesse de formation et le débit par accélérateur (TFLOPS).
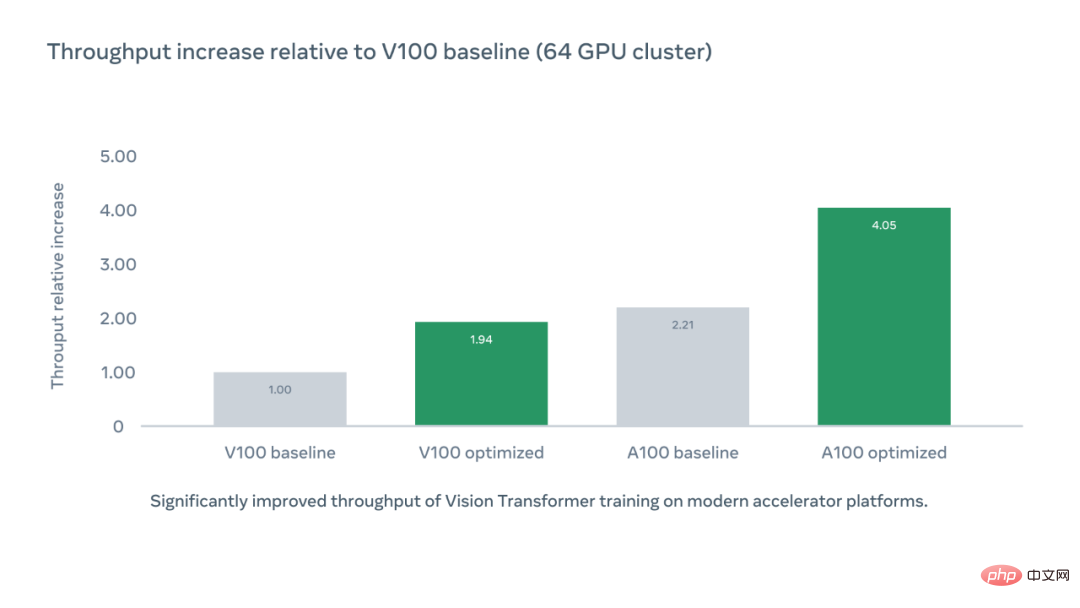
Le graphique ci-dessous montre l'augmentation relative du débit de l'accélérateur par puce par rapport à la ligne de base du V100 en utilisant la base de code optimisée PyCI, et le débit de l'accélérateur optimisé pour l'A100 est 4,05 fois supérieur à celui de la ligne de base du V100.
Comment ça marche
Meta AI a d'abord analysé la base de code PyCI pour identifier les sources potentielles de faible efficacité de formation, se concentrant finalement sur le choix des formats de nombres. Par défaut, la plupart des applications utilisent un format à virgule flottante simple précision 32 bits pour représenter les valeurs du réseau neuronal. La conversion vers un format demi-précision 16 bits (FP16) peut réduire l'empreinte mémoire et le temps d'exécution d'un modèle, mais réduit souvent également la précision.
Les chercheurs ont adopté une solution de compromis, à savoir la précision mixte. Grâce à lui, le système effectue des calculs dans un format simple précision pour accélérer l'entraînement et réduire l'utilisation de la mémoire, tout en stockant les résultats en simple précision pour maintenir la précision. Plutôt que de convertir manuellement des parties du réseau en demi-précision, ils ont expérimenté différents modes de formation automatisée à précision mixte, qui basculent automatiquement entre les formats numériques. La précision mixte automatique des modes plus avancés repose principalement sur des opérations de demi-précision et des poids de modèle. Les paramètres équilibrés utilisés par les chercheurs peuvent accélérer considérablement l'entraînement sans sacrifier la précision.
Pour rendre le processus plus efficace, les chercheurs ont pleinement profité de l'algorithme de formation Fully Sharder Data Parallel (FSDP) de la bibliothèque FairScale, qui fragmente les paramètres, les gradients et les états de l'optimiseur sur le GPU. Grâce à l'algorithme FSDP, les chercheurs peuvent créer des modèles à plus grande échelle en utilisant moins de GPU. De plus, nous avons utilisé l'optimiseur MTA, un classificateur ViT regroupé et une disposition de tenseur d'entrée par lots par seconde pour ignorer les opérations de transposition redondantes.
L'axe X de la figure ci-dessous montre les optimisations possibles, et l'axe Y montre l'augmentation relative du débit de l'accélérateur par rapport au benchmark de données distribuées parallèles (DDP) lors de l'entraînement avec ViT-H/16.
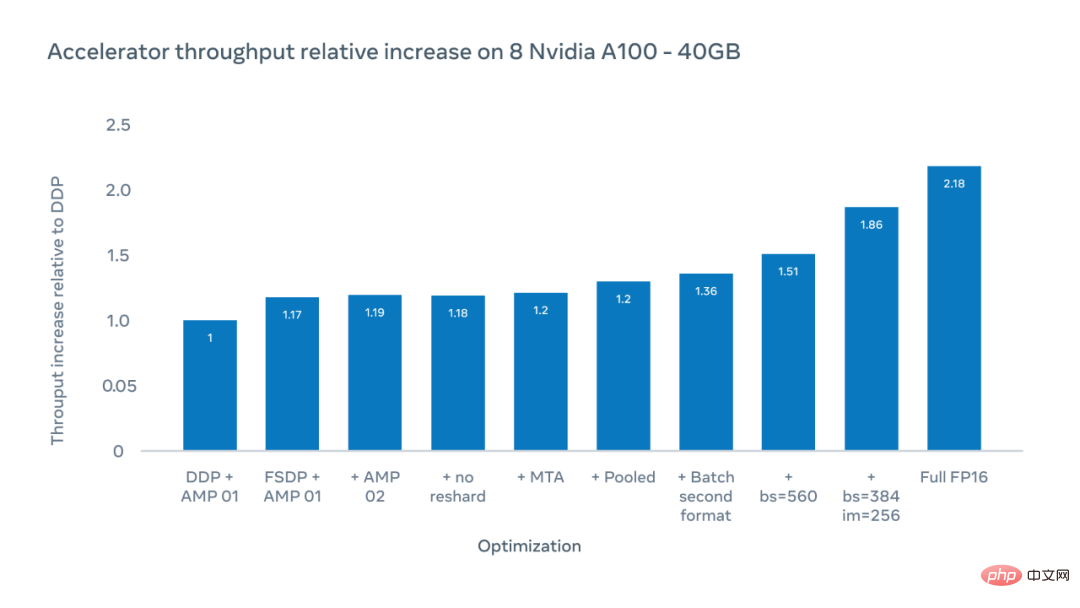
Les chercheurs ont obtenu une multiplication par 1,51 du débit de l'accélérateur, mesuré comme le nombre d'opérations en virgule flottante effectuées par seconde sur chaque puce accélératrice, pour une taille totale de patch de 560. En augmentant la taille de l'image de 224 pixels à 256 pixels, ils ont pu augmenter le débit à 1,86x. Cependant, changer la taille de l’image signifie changer les hyperparamètres, ce qui aura un impact sur la précision du modèle. Lors de l'entraînement en mode FP16 complet, le débit relatif augmente jusqu'à 2,18x. Bien que la précision ait parfois été réduite, dans les expériences, la précision a été réduite de moins de 10 %.
L'axe Y de la figure ci-dessous est l'époque, la durée de la dernière formation sur l'ensemble de données ImageNet-1K. Nous nous concentrons ici sur les temps de formation réels pour les configurations existantes, qui utilisent généralement une taille d'image de 224 pixels.
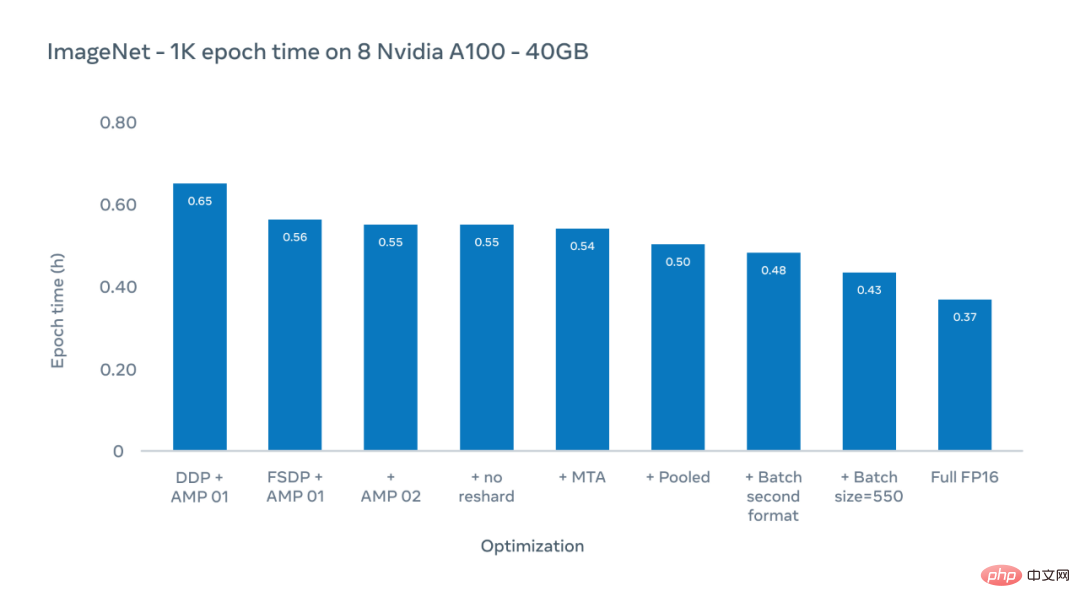
Les chercheurs de Meta AI ont utilisé un schéma d'optimisation pour réduire le temps d'époque (la durée d'une session de formation sur l'ensemble de données ImageNet-1K) de 0,65 heure à 0,43 heure.
L'axe X de la figure ci-dessous représente le nombre de puces d'accélérateur GPU A100 dans une configuration spécifique, et l'axe Y représente le débit absolu en TFLOPS par puce.
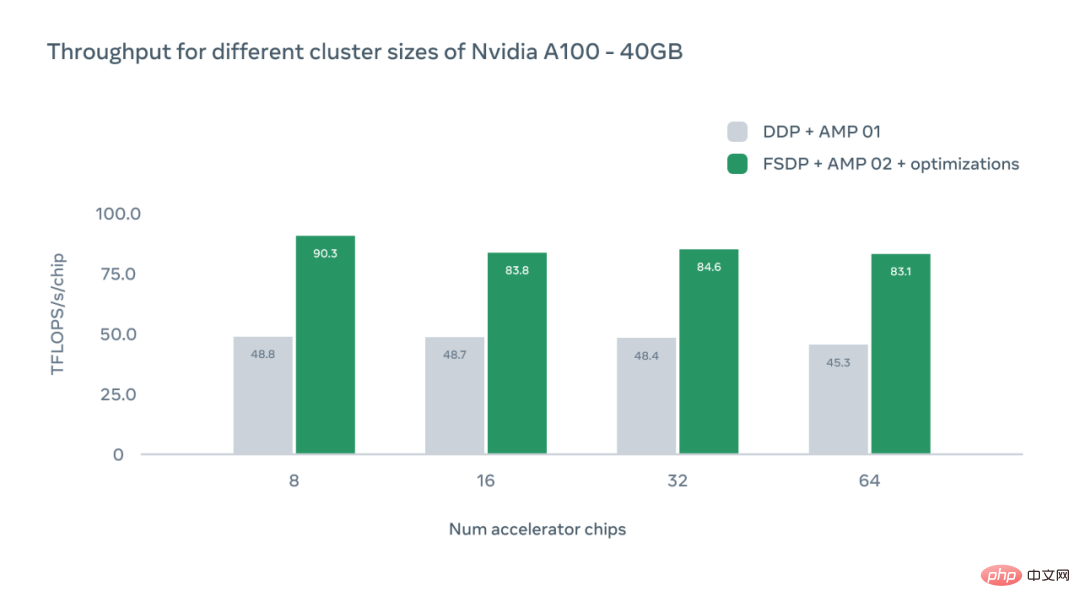
L'étude aborde également l'impact des différentes configurations GPU. Dans chaque cas, le système a atteint un débit supérieur au niveau de base de données distribuées parallèles (DDP). À mesure que le nombre de puces augmente, nous pouvons observer une légère diminution du débit en raison de la surcharge de communication entre les appareils. Cependant, même avec 64 GPU, le système Meta est 1,83 fois plus rapide que le benchmark DDP.
Importance des nouvelles recherches
Doubler le débit réalisable dans la formation ViT peut effectivement doubler la taille du cluster de formation, et l'amélioration de l'utilisation des accélérateurs réduit directement les émissions de carbone des modèles d'IA. Étant donné que le développement récent de grands modèles a entraîné la tendance à des modèles plus grands et à des temps de formation plus longs, cette optimisation devrait aider le domaine de la recherche à pousser davantage la technologie de pointe, à raccourcir les délais d'exécution et à augmenter la productivité.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Tendances technologiques à surveiller en 2023
- Comment l'intelligence artificielle apporte un nouveau travail quotidien aux équipes des centres de données
- L'intelligence artificielle ou l'automatisation peuvent-elles résoudre le problème de la faible efficacité énergétique des bâtiments ?
- Co-fondateur d'OpenAI interviewé par Huang Renxun : les capacités de raisonnement de GPT-4 n'ont pas encore atteint les attentes
- Bing de Microsoft surpasse Google en termes de trafic de recherche grâce à la technologie OpenAI