
Maison >Périphériques technologiques >IA >La voie vers la mise en œuvre pratique de la technologie vocale intelligente Soul
La voie vers la mise en œuvre pratique de la technologie vocale intelligente Soul

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBavant
- 2023-04-09 09:21:031381parcourir
Auteur| Liu Zhongliang
Compilation| Lu Xinwang
Critique| Yun Zhao
Ces dernières années, la technologie du langage vocal intelligent a connu un essor, changeant progressivement la façon dont les gens travaillent et vivent, en particulier dans le domaine social. La technologie vocale intelligente met en avant des exigences plus élevées.
Il y a quelques jours, lors de la conférence mondiale sur la technologie de l'intelligence artificielle AISummit organisée par 51CTO, Liu Zhongliang, responsable de l'algorithme vocal de Soul, a prononcé un discours d'ouverture "La route vers la pratique de la technologie vocale intelligente de l'âme", basé sur certains des Les scénarios commerciaux de Soul et Soul partagés ont une certaine expérience pratique dans la technologie vocale intelligente.
Le contenu du discours est désormais organisé comme suit, en espérant inspirer tout le monde.
Scénario d'application vocale de Soul
Soul est un scénario social immersif recommandé sur la base de graphiques d'intérêt. Dans ce scénario, il y a beaucoup d'échanges vocaux, donc beaucoup de données ont été accumulées au cours de la période écoulée. À l'heure actuelle, une journée compte environ des millions d'heures. Si vous supprimez certains silences, bruits, etc. dans les appels vocaux et ne comptez que ces clips audio significatifs, il existe environ 670 millions de clips audio. Les entrées du service vocal de Soul sont principalement les suivantes :
Voice Party
Les groupes peuvent créer des salles où de nombreux utilisateurs peuvent avoir des discussions vocales.
Video Party
En fait, la plupart des utilisateurs de la plateforme Soul ne veulent pas montrer leur visage ou s'exposer, nous avons donc créé une image d'avatar 3D auto-développée ou un couvre-chef que les utilisateurs peuvent utiliser pour aider les utilisateurs à être plus express bien vous-même ou exprimez-vous sans pression.
Werewolf Game
est aussi une salle où de nombreuses personnes peuvent jouer au jeu ensemble.
Correspondance vocale
Un scénario plus unique est la correspondance vocale, ou c'est la même chose que d'appeler sur WeChat, c'est-à-dire que vous pouvez discuter en tête-à-tête.
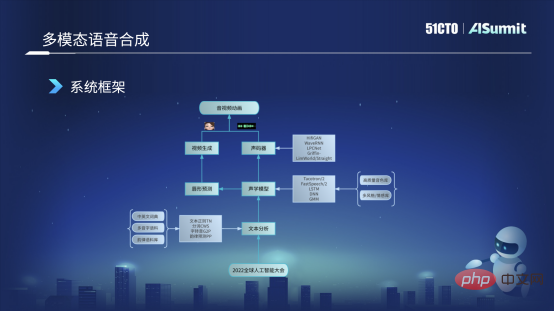
Sur la base de ces scénarios, nous avons construit des capacités vocales auto-développées, en nous concentrant principalement sur deux directions principales : la première est l'interaction naturelle homme-machine, et la seconde est la compréhension et la génération de contenu. Il y a quatre aspects principaux : le premier est la reconnaissance vocale et la synthèse vocale ; le second est l'analyse vocale et l'animation vocale. L'image ci-dessous montre les outils vocaux courants que nous utilisons, qui incluent principalement l'analyse vocale, tels que la qualité sonore, les effets sonores et. musique. Ensuite, il y a la reconnaissance vocale, comme la reconnaissance du chinois, la reconnaissance vocale chantée et la lecture mixte du chinois et de l'anglais. Le troisième est lié à la synthèse vocale, telle que la conversion de divertissement, la conversion vocale et la synthèse vocale chantée. Le quatrième est l'animation vocale, qui comprend principalement certaines formes de bouche pilotées par du texte, des formes de bouche pilotées par la voix et d'autres technologies d'animation vocale.
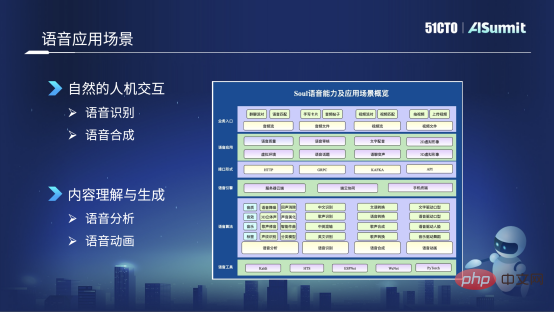
Sur la base de ces capacités d'algorithme vocal, nous disposons de nombreuses formes d'application vocale, telles que la détection de la qualité de la parole, y compris l'amélioration, la révision de la parole, le doublage de texte, les sujets vocaux, les sons de l'environnement virtuel, tels que ces effets sonores spatiaux 3D. , etc. . Ce qui suit est une introduction aux technologies utilisées dans les deux scénarios commerciaux de révision vocale et d'avatar.
Examen du contenu vocal
L'examen du contenu vocal consiste à étiqueter ou à identifier les clips audio dont le contenu est lié à la politique, à la pornographie, aux abus, à la publicité, etc., et grâce à la détection et à l'examen de ces étiquettes illégales, à assurer la sécurité du réseau. La technologie de base utilisée ici est la reconnaissance vocale de bout en bout, qui aide à convertir l'audio de l'utilisateur en texte, puis fournit une inspection de qualité secondaire aux réviseurs en aval.
Système de reconnaissance vocale de bout en bout
L'image ci-dessous est un cadre de reconnaissance vocale de bout en bout que nous utilisons actuellement. Premièrement, il capturera un fragment de l'audio de l'utilisateur pour l'extraction de fonctionnalités. fonctionnalités actuellement utilisées. Nous avons principalement utilisé les fonctionnalités d'Alfa-Bank et avons essayé d'utiliser des fonctionnalités pré-entraînées telles que Wav2Letter dans certains scénarios. Après avoir obtenu les fonctionnalités audio, une détection de point final sera effectuée, qui consiste à détecter si la personne parle et si le clip audio contient une voix humaine. Actuellement, on utilise essentiellement des VD énergétiques classiques et des modèles DNVD.
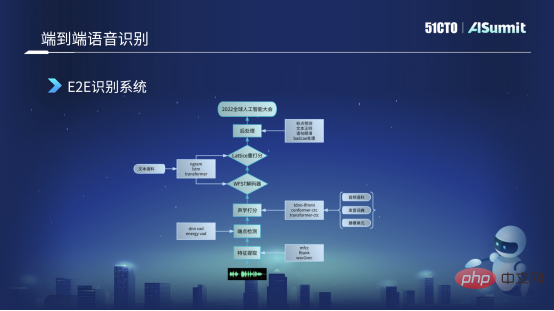
Après avoir obtenu ces fonctionnalités, nous les enverrons à un module de notation acoustique. Nous avons utilisé Transformer CDC au début pour ce modèle acoustique, et maintenant il a été itéré vers Conformer CDC. Après cette notation acoustique, nous enverrons une série de partitions de séquence au décodeur. Le décodeur se charge de décoder le texte, et il effectuera une seconde partition en fonction des résultats de la reconnaissance. Dans ce processus, les modèles que nous utilisons sont essentiellement certains, tels que le modèle EngelM traditionnel, et certains modèles d'apprentissage en profondeur Transformer actuellement plus courants pour la nouvelle notation. Enfin, nous effectuerons également un post-traitement, comme une détection de ponctuation, une régularisation de texte, un lissage de phrases, etc., et obtiendrons enfin un résultat de reconnaissance de texte significatif et précis, tel que "Conférence mondiale sur l'intelligence artificielle 2022".
Dans le système de reconnaissance vocale de bout en bout, en fait, le bout en bout dont nous parlons se situe principalement dans la partie notation acoustique. Nous utilisons la technologie de bout en bout. Les autres sont principalement traditionnelles. et les méthodes classiques d'apprentissage en profondeur.
Dans le processus de construction du système ci-dessus, nous avons en fait rencontré de nombreux problèmes. En voici trois principaux :
- Trop peu de données acoustiques supervisées C'est ce que tout le monde rencontre habituellement. Les principales raisons sont les suivantes : Tout d’abord, vous devez écouter l’audio avant de pouvoir l’annoter. Deuxièmement, son coût d’étiquetage est également très élevé. Par conséquent, le manque de cette partie des données est un problème commun à tout le monde.
- L'effet de reconnaissance du modèle est médiocre Il y a plusieurs raisons à cela. La première est que lors de la lecture d'un mélange de chinois et d'anglais ou dans plusieurs domaines, l'utilisation d'un modèle général pour l'identifier sera relativement médiocre.
- Le modèle est lent
Compte tenu de ces problèmes, nous les résolvons principalement des trois manières suivantes.
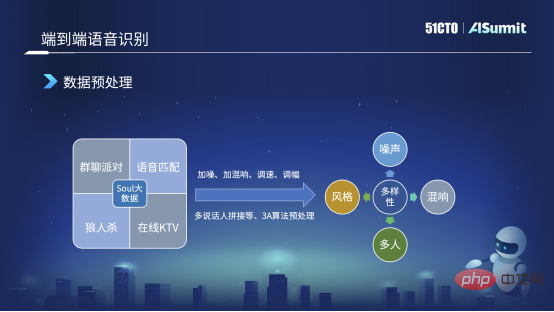
Prétraitement des données
Soul propose des scénarios nombreux et complexes. Par exemple, dans une discussion de groupe, il y aura des situations où plusieurs personnes se chevauchent ou où AB parle. Par exemple, dans KTV en ligne, il y aura des situations où les gens chantent et parlent en même temps. Mais lorsque nous étiquetons des données, parce que cela coûte relativement cher, nous sélectionnerons des données relativement propres dans ces scénarios pour l'étiquetage. Par exemple, nous pouvons étiqueter 10 000 heures de données propres. Cependant, la complexité des données propres est différente de celle des données des scénarios réels, nous effectuerons donc un prétraitement des données basé sur ces données propres. Par exemple, certaines méthodes classiques de prétraitement des données incluent l'ajout de bruit, l'ajout de réverbération, l'ajustement de la vitesse, l'ajustement de la vitesse plus ou moins rapide, l'ajustement de l'énergie, l'augmentation ou la diminution de l'énergie.
En plus de ces méthodes, nous effectuerons un prétraitement ciblé des données ou une augmentation des données pour certains problèmes qui surviennent dans nos scénarios commerciaux. Par exemple, je viens de mentionner qu'il est facile pour plusieurs haut-parleurs de se chevaucher dans une discussion de groupe, nous allons donc créer un audio d'épissage multi-haut-parleurs, ce qui signifie que nous allons faire une coupe des clips audio des trois haut-parleurs ABC et faire ensemble.
Parce que certains appels audio et vidéo effectueront un prétraitement d'algorithme 3D de base sur l'ensemble du front-end audio, comme l'annulation automatique de l'écho, la réduction intelligente du bruit, etc., nous nous adapterons donc également à l'utilisation en ligne. subissent également un prétraitement d'algorithmes 3D.
Après le prétraitement des données de cette manière, nous pouvons obtenir diverses données, telles que des données avec du bruit, une certaine réverbération, plusieurs personnes ou même plusieurs styles, qui seront augmentées. Par exemple, nous allons étendre 10 000 heures à environ 50 000 heures, voire 80 000 à 90 000 heures. Dans ce cas, la couverture et l'étendue des données seront très élevées.
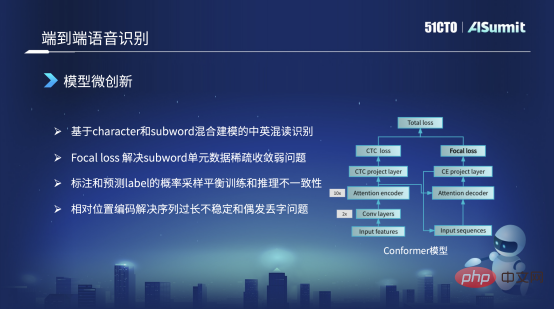
Modèle de micro-innovation
Le cadre principal du modèle que nous utilisons reste la structure Conformer. Sur le côté gauche de cette structure Conformer se trouve le framework classique Encoder CDC. Sur la droite se trouve un décodeur d'attention. Mais tout le monde a remarqué que dans la perte de droite, la structure originale du Conformer était une perte CE, et nous l'avons remplacée ici par une perte focale. La raison principale est que nous utilisons la perte focale pour résoudre le problème de la non-convergence des unités clairsemées et de la formation des données clairsemées, ou le problème d'une mauvaise formation, qui peut être résolu.
Par exemple, en lecture mixte chinois-anglais, nous avons très peu de mots anglais dans les données d'entraînement. Dans ce cas, cette unité ne peut pas être bien apprise. Grâce à la perte focale, nous pouvons augmenter son poids de perte, ce qui peut atténuer certains problèmes de quantité ou de mauvais entraînement, et résoudre certains cas graves.
Le deuxième point est que notre stratégie de formation sera différente. Par exemple, nous utiliserons également des méthodes de formation mixtes dans la stratégie de formation. Par exemple, au début de la formation, lorsque nous entraînerons la partie Décoder de l'entrée, nous continuerons. utilisez un entraînement de précision. Les données de la séquence d'étiquettes cible sont prises en entrée. Mais à mesure que le modèle d'entraînement converge, nous échantillonnerons ultérieurement une partie des étiquettes prédites selon une certaine probabilité en tant qu'entrée du décodeur pour effectuer quelques astuces. Que résout principalement cette astuce ? C'est le phénomène d'incohérence entre les caractéristiques d'entrée du modèle de formation et le modèle d'inférence en ligne. De cette manière, nous pouvons le résoudre en partie.
Mais il y a un autre problème. En fait, dans le modèle Conformer original ou dans le modèle fourni par Vnet ou ESPnet, la valeur par défaut est l'information de position absolue. Cependant, les informations de position absolue ne peuvent pas résoudre le problème d'identification lorsque la séquence est trop longue, nous allons donc changer les informations de position absolue en codage de position relative pour résoudre ce problème. De cette manière, les problèmes qui surviennent au cours du processus de reconnaissance, tels que la répétition de certains mots ou la perte occasionnelle de mots ou de mots, peuvent également être résolus.
Accélération d'inférence
Le premier est le modèle acoustique Nous allons changer le modèle autorégressif en cette méthode basée sur le décodage Encoder CDC+WFST, et résoudre d'abord une partie des résultats de reconnaissance, comme NBest, 10meilleur ou 20meilleur. Sur la base de 20best, nous l'enverrons à Decorde Rescore pour une deuxième notation. Cela peut éviter les dépendances temporelles et faciliter le calcul ou le raisonnement parallèle GPT.
En plus de la méthode d'accélération classique, nous utilisons également une méthode de quantification hybride, c'est-à-dire que dans le processus de raisonnement prospectif par apprentissage profond, nous utilisons 8 bits pour une partie du calcul, mais dans la partie centrale, comme la finance fonctions Nous utilisons toujours le 16 bits pour cette partie, principalement parce que nous allons trouver un équilibre approprié entre vitesse et précision.
Après ces optimisations, toute la vitesse d'inférence est relativement rapide. Mais au cours de notre processus de lancement, nous avons également découvert quelques petits problèmes, qui, je pense, peuvent être considérés comme une astuce.
Au niveau du modèle de langage, par exemple, notre scène contient beaucoup de textes de discussion, mais il y a aussi du chant. Nous avons besoin du même modèle pour résoudre à la fois la parole et le chant. En termes de modèles de langage, tels que le chat textuel, ils sont généralement fragmentés et courts, donc après nos expériences, nous avons constaté que le modèle à trois éléments est meilleur, mais que le modèle à cinq éléments n'a apporté aucune amélioration.
Mais par exemple, pour chanter, son texte est relativement long, et sa structure de phrase et sa grammaire sont relativement fixes, donc pendant l'expérience, cinq yuans valent mieux que trois yuans. Dans ce cas, nous utilisons une grammaire hybride pour modéliser conjointement le modèle linguistique du texte de discussion et du texte chanté. Nous utilisons le modèle de mélange « trois yuans + cinq yuans », mais ce mélange « trois yuans + cinq yuans » n'est pas une différence au sens traditionnel. Nous ne faisons pas de différence, mais utilisons la grammaire à trois yuans. de discuter. Prenez le chant à quatre yuans et la grammaire à cinq yuans et fusionnez-les directement. L'arpa ainsi obtenu est actuellement plus petit et plus rapide dans le processus de décodage. Plus important encore, il consomme moins de mémoire vidéo. Car lors du décodage sur le GPU, la taille de la mémoire vidéo est fixe. Par conséquent, nous devons contrôler dans une certaine mesure la taille du modèle linguistique afin d'améliorer autant que possible l'effet de reconnaissance via le modèle linguistique.
Après quelques optimisations et astuces du modèle acoustique et du modèle linguistique, notre vitesse d'inférence actuelle est également très rapide. Le taux en temps réel peut essentiellement atteindre le niveau de 0,1 ou 0,2.

La simulation virtuelle
aide principalement les utilisateurs à s'exprimer plus sans stress ou plus naturellement et librement en générant des sons, des formes de bouche, des expressions, des postures, etc. La technologie de base derrière cela est One est la synthèse vocale multimodale.
Synthèse vocale multimodale
La figure suivante est le cadre de base du système de synthèse vocale actuellement utilisé. Tout d'abord, nous obtiendrons le texte saisi par l'utilisateur, tel que "Conférence mondiale sur l'intelligence artificielle 2022", puis nous l'enverrons au module d'analyse de texte. Ce module analyse principalement le texte sous divers aspects, tels que la régularisation du texte et certains mots. segmentation, la chose la plus importante est l'auto-transfert, la conversion des mots en phonèmes, ainsi qu'une certaine prédiction de rimes et d'autres fonctions. Après cette analyse du texte, nous pouvons obtenir certaines caractéristiques linguistiques de la phrase de l'utilisateur, et ces caractéristiques seront envoyées au modèle acoustique. Pour le modèle acoustique, nous utilisons actuellement principalement certaines améliorations du modèle et formations basées sur le framework FastSpeech.
Le modèle acoustique obtient des caractéristiques acoustiques, telles que les caractéristiques Mel, ou des informations telles que la durée ou l'énergie, et son flux de fonctionnalités sera divisé en deux parties. Nous en enverrons une partie au vocodeur, qui sert principalement à générer des formes d’onde audio que nous pouvons écouter. L'autre direction d'écoulement est envoyée à la prédiction de la forme des lèvres. Nous pouvons prédire le coefficient BS correspondant à la forme des lèvres grâce au module de prédiction de la forme des lèvres. Après avoir obtenu la valeur de la fonctionnalité BS, nous l'enverrons au module de génération vidéo, qui est sous la responsabilité de l'équipe visuelle et peut générer un avatar virtuel, qui est une image virtuelle avec la forme et l'expression de la bouche. Au final, nous fusionnerons l'avatar virtuel et l'audio, et enfin générerons une animation audio et vidéo. Il s’agit du cadre de base et du processus de base de toute notre synthèse vocale multimodale.
Principaux problèmes du processus de synthèse vocale multimodale :
- La qualité des données de la bibliothèque de sons vocaux est relativement mauvaise.
- La qualité du son synthétique est médiocre.
- Le retard audio et vidéo est important, et la forme de la bouche et la voix ne correspondent pas
La méthode de traitement de Soul est similaire à celle de l'amélioration du système de reconnaissance vocale de bout en bout.
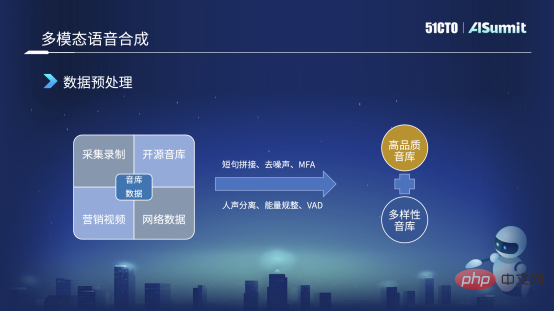
Prétraitement des données
Notre bibliothèque sonore provient de nombreuses sources. L'image de gauche est la première que nous allons collecter et enregistrer. Deuxièmement, bien sûr, nous sommes très reconnaissants envers la société de données open source, qui ouvrira certaines bibliothèques de sons, et nous les utiliserons également pour faire des expériences. Troisièmement, il y aura des vidéos de marketing public au niveau de l'entreprise sur notre plateforme. Lors de la réalisation des vidéos, nous avons invité des présentateurs de haute qualité à les réaliser, de sorte que la qualité sonore est également de très haute qualité. Quatrièmement, certaines données du réseau public, comme dans le processus de dialogue, certains timbres sont de qualité relativement élevée, nous allons donc également en explorer quelques-unes puis faire des pré-annotations, principalement pour faire des expériences internes et une pré-formation.
Compte tenu de la complexité de ces données, nous avons effectué certains prétraitements de données, comme l'épissage de phrases courtes, comme mentionné tout à l'heure, lors du processus de collecte, les phrases peuvent être longues ou courtes afin d'élargir le contenu. durée de la bibliothèque sonore, nous ferons une coupure pour les phrases courtes, et nous supprimerons un peu de silence pendant le processus. Si le silence est trop long, cela aura un certain impact.
Deuxièmement, c'est le débruitage. Par exemple, dans les données réseau ou les vidéos marketing que nous recevons, nous supprimerons le bruit grâce à certaines méthodes d'amélioration de la parole.
Troisièmement, en fait, la plupart des annotations actuelles sont des annotations phonétiques à caractères, mais les limites des phonèmes ne sont fondamentalement pas utilisées comme annotations maintenant, nous obtenons donc généralement les limites des phonèmes grâce à ces informations sur la méthode d'alignement forcé MFA. .
Ensuite, la séparation vocale suivante est assez particulière, car nous avons une musique de fond dans la vidéo marketing, nous allons donc faire une séparation vocale, supprimer la musique de fond et obtenir des données vocales sèches. Nous effectuons également une certaine régularisation de l'énergie et certains VAD concernent principalement les données de dialogue ou de réseau. J'utilise le VAD pour détecter des voix humaines efficaces, puis je les utilise pour effectuer des pré-annotations ou des pré-entraînements.
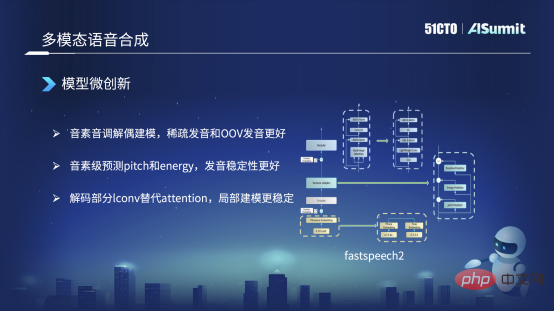
Modèle de micro-innovation
Dans le processus de création de FastSpeech, nous avons principalement apporté des modifications sur trois aspects. Le type à gauche de l'image de gauche est le modèle de base de FastSpeech. Le premier changement que nous avons apporté est que nous allons découpler les phonèmes et les tons pour la modélisation. Autrement dit, dans des circonstances normales, ce que notre frontal de texte convertit est un. séquence de phonèmes, comme Identique à l'image de gauche, une séquence monotone de phonèmes comme "bonjour". Mais nous allons le diviser en la partie droite, en deux parties, c'est-à-dire que la partie gauche est une séquence de phonèmes, avec uniquement des phonèmes et aucun ton. Celui de droite n’a que des tons et aucun phonème. Dans ce cas, nous les enverrons respectivement à un ProNet (son) et obtiendrons deux Embeddings. Les deux intégrations seront coupées ensemble pour remplacer la méthode d'intégration précédente. Dans ce cas, l'avantage est que cela peut résoudre le problème de la prononciation clairsemée, ou que certaines prononciations ne sont pas dans notre corpus de formation. Ce genre de problème peut fondamentalement être résolu.
La deuxième façon dont nous avons changé est que la méthode originale consiste d'abord à prédire une durée, qui est l'image de droite, puis en fonction de cette durée, nous élargissons l'ensemble sonore, puis prédisons l'énergie et la hauteur. Nous avons maintenant modifié l'ordre. Nous allons prédire la hauteur et l'énergie en fonction du niveau du phonème, puis après la prédiction, nous l'étendrons à une durée au niveau de l'image. L’avantage est que tout au long du processus de prononciation du phonème complet, sa prononciation est relativement stable, ce qui constitue un changement dans notre scénario.
La troisième est que nous avons apporté un changement alternatif dans la partie Décodeur, qui est la partie supérieure. Le décodeur d'origine utilisait la méthode Attention, mais nous sommes maintenant passés à la méthode Iconv ou Convolution. Cet avantage est dû au fait que, même si Self-Attention peut capturer des informations historiques et contextuelles très puissantes, sa capacité à modéliser progressivement est relativement faible. Ainsi, après être passé à Convolution, notre capacité à gérer ce type de modélisation locale sera meilleure. Par exemple, lors de la prononciation, le phénomène que nous venons de mentionner selon lequel la prononciation est relativement muette ou floue peut être fondamentalement résolu. Ce sont quelques-uns des changements majeurs que nous avons actuellement.
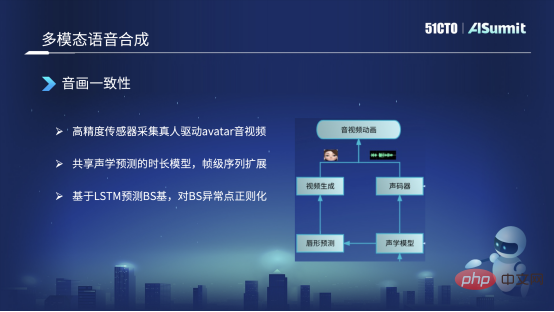
Modèle acoustique partagé
Le côté gauche est la forme de la bouche synthétisée et le côté droit est la voix synthétisée. Ils partagent des informations sur l'encodeur et la durée dans le modèle acoustique.
Nous avons réalisé principalement trois actions. La première est que nous collectons des données de haute précision. Par exemple, nous trouverons des personnes réelles qui porteront des capteurs de haute précision pour piloter l'image d'Avatar que nous avons prédite, obtenir de l'audio et de la vidéo haute résolution, et le faire. quelques annotations. De cette façon, vous obtiendrez des données synchronisées de texte, audio et vidéo.
La deuxième chose est, on peut également mentionner comment nous résolvons la cohérence de l'audio et de la vidéo ? Parce que nous synthétisons d'abord le son par synthèse de texte, après avoir obtenu le son, nous ferons une prédiction du son à la forme de la bouche. Dans ce processus, une asymétrie apparaîtra au niveau de l'image. À l'heure actuelle, nous utilisons cette méthode de partage de modèles acoustiques entre les formes de bouche synthétisées et les sons synthétisés, et nous le faisons après que la séquence au niveau de l'image ait été étendue. À l'heure actuelle, il peut être garanti qu'il est aligné au niveau de l'image, garantissant ainsi la cohérence de l'audio et de la vidéo.
Enfin, nous n'utilisons actuellement pas de méthode basée sur des séquences pour prédire la forme de la bouche ou la base du BS. Après le coefficient BS prédit, mais cela peut prédire certaines anomalies, nous effectuerons également un post-traitement, comme une régularisation. Par exemple, si la base BS est trop grande ou trop petite, la forme de la bouche s'ouvrira trop largement. ou même un changement trop petit. Nous définirons un champ d'application qui ne peut pas être trop grand et sera contrôlé dans une plage raisonnable. À l’heure actuelle, il est fondamentalement possible d’assurer la cohérence de l’audio et de la vidéo.
Future Outlook
Premièrement, la reconnaissance multimodale dans les situations très bruyantes, l'audio est combiné avec la forme de la bouche pour une reconnaissance multimodale afin d'améliorer la précision de la reconnaissance.
La seconde est la synthèse vocale multimodale et la conversion vocale en temps réel, qui peuvent conserver les caractéristiques d'émotion et de style de l'utilisateur, mais ne convertissent que le timbre de l'utilisateur en un autre timbre.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Tendances technologiques à surveiller en 2023
- Comment l'intelligence artificielle apporte un nouveau travail quotidien aux équipes des centres de données
- L'intelligence artificielle ou l'automatisation peuvent-elles résoudre le problème de la faible efficacité énergétique des bâtiments ?
- Co-fondateur d'OpenAI interviewé par Huang Renxun : les capacités de raisonnement de GPT-4 n'ont pas encore atteint les attentes
- Bing de Microsoft surpasse Google en termes de trafic de recherche grâce à la technologie OpenAI