
Maison >Périphériques technologiques >IA >Exploration de la technologie multimodale dans les principaux scénarios de rappel de recherche de Taobao
Exploration de la technologie multimodale dans les principaux scénarios de rappel de recherche de Taobao

- PHPzavant
- 2023-04-08 23:31:061568parcourir
Le rappel de recherche, en tant que base du système de recherche, détermine la limite supérieure d'amélioration de l'effet. Comment continuer à apporter une valeur incrémentielle différenciée aux résultats des rappels massifs existants est le principal défi auquel nous sommes confrontés. La combinaison de la pré-formation multimodale et du rappel nous ouvre de nouveaux horizons et apporte une amélioration significative des effets en ligne.
Avant-propos
La pré-formation multimodale est au centre de la recherche universitaire et industrielle. Par la pré-formation sur des données à grande échelle, la correspondance sémantique entre différentes modalités peut être obtenue, qui peut être utilisée de diverses manières. des tâches en aval. Par exemple, la réponse visuelle aux questions, le raisonnement visuel et la récupération d’images et de textes peuvent améliorer l’effet. Au sein du groupe, il y a aussi quelques recherches et applications de pré-formation multimodale. Dans le scénario de recherche principal de Taobao, il existe une demande naturelle de récupération intermodale entre la requête saisie par l'utilisateur et les produits à rappeler. Cependant, dans le passé, davantage de titres et de fonctionnalités statistiques étaient utilisés pour les produits, et les fonctionnalités plus intuitives telles que les images ont été ignorées. Mais pour certaines requêtes comportant des éléments visuels (comme une robe blanche, une robe à fleurs), je pense que tout le monde sera attiré en premier par l'image sur la page de résultats de recherche.
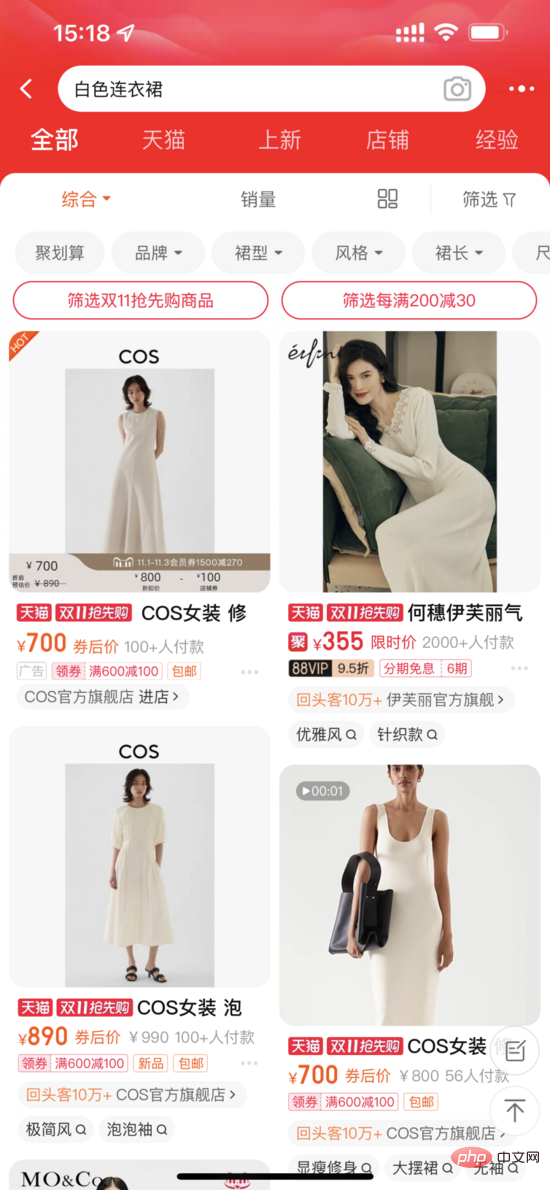

Scène de recherche principale Taobao
D'une part, l'image occupe une position plus importante, d'autre part, l'image peut contenir des informations qui ne sont pas incluses dans le titre, comme des éléments visuels blancs et cassés comme des fleurs. Pour ces derniers, deux situations doivent être distinguées : l'une est qu'il y a des informations dans le titre, mais elles ne peuvent pas être entièrement affichées en raison de restrictions d'affichage. Cette situation n'affecte pas le rappel du produit dans le lien système ; qu'il n'y a pas d'information dans le titre mais l'image Il y en a, c'est-à-dire que l'image peut apporter un incrément par rapport au texte. C’est sur ce dernier point que nous devons nous concentrer.
▐ Problèmes techniques et solutions
Lors de l'application de la technologie multimodale dans le scénario principal de recherche et de rappel, deux problèmes principaux doivent être résolus :
- Multi-modal pré-formation graphique et texte Le modèle intègre généralement deux modes : image et texte En raison de l'existence de Query, la recherche principale doit considérer des modes texte supplémentaires basés sur les modes graphiques et texte originaux des images et des titres des produits. Dans le même temps, il existe un écart sémantique entre la requête et les titres de produits. La requête est relativement courte et large, tandis que les titres de produits sont souvent longs et remplis de mots-clés car les vendeurs font du référencement.
- Habituellement, la relation entre les tâches de pré-formation et les tâches en aval est que la pré-formation utilise des données non étiquetées à grande échelle et qu'en aval utilise une petite quantité de données étiquetées. Cependant, pour la recherche et le rappel principaux, l'ampleur de la tâche de rappel de vecteurs en aval est énorme, avec des milliards de données. Cependant, limité par les ressources GPU limitées, le pré-entraînement ne peut utiliser qu'une quantité relativement faible de données. Dans ce cas, la pré-formation peut également apporter des avantages aux tâches en aval.
Notre solution est la suivante :
- Pré-formation texte-image : transmettez la requête et l'article de produit via l'encodeur respectivement et saisissez-les dans l'encodeur multimodal en tant que tours jumelles. Si nous regardons les tours Requête et Objet, elles n'interagissent qu'à un stade ultérieur, similaire au modèle à deux flux. Cependant, en regardant spécifiquement la tour Objet, les deux modes d'image et de titre interagissent à un stade précoce. est un modèle à flux unique. Par conséquent, la structure de notre modèle est différente des structures courantes à flux unique ou à double flux. Le point de départ de cette conception est d'extraire plus efficacement les vecteurs de requête et les vecteurs d'éléments, de fournir des entrées pour le modèle de rappel vectoriel à deux tours en aval et d'introduire la méthode de modélisation du produit interne à deux tours dans la phase de pré-formation. Afin de modéliser la connexion sémantique et l'écart entre la requête et le titre, nous partageons les tours jumelles de l'encodeur de requête et d'élément, puis apprenons le modèle de langage séparément.
- Lien entre les tâches de pré-entraînement et de rappel : Sur la base de la méthode de construction de l'échantillon et de la perte de la tâche de rappel vectoriel en aval, les tâches et les méthodes de modélisation de la phase de pré-entraînement sont conçues. À la différence des tâches courantes de correspondance d'images et de texte, nous utilisons les tâches de correspondance Query-Item et Query-Image, et utilisons l'élément avec le plus de clics sous Requête comme échantillon positif, et utilisons d'autres échantillons du lot comme échantillons négatifs. les tours jumelles des tâches de requête et d'article modélisées à la manière d'un produit interne. Le point de départ de cette conception est de rapprocher la pré-formation de la tâche de rappel de vecteurs et de fournir autant que possible une contribution efficace aux tâches en aval avec des ressources limitées. De plus, pour la tâche de rappel vectoriel, si le vecteur d'entrée de pré-entraînement est fixe pendant le processus de formation, il ne peut pas être ajusté efficacement pour les données à grande échelle. Pour cette raison, nous avons également modélisé le vecteur d'entrée de pré-entraînement dans le vecteur. tâche de rappel. Mise à jour des vecteurs d'entraînement. Modèle pré-entraîné Il existe trois manières principales d'extraire des fonctionnalités à partir d'images : en utilisant un modèle formé dans le domaine CV pour extraire les fonctionnalités RoI, les fonctionnalités Grid et les fonctionnalités Patch de l'image. Du point de vue de la structure du modèle, il existe deux types principaux selon les différentes méthodes de fusion des caractéristiques de l'image et des caractéristiques du texte : le modèle à flux unique ou le modèle à double flux. Dans le modèle à flux unique, les caractéristiques de l'image et les caractéristiques du texte sont assemblées et entrées dans l'encodeur à un stade précoce, tandis que dans le modèle à double flux, les caractéristiques de l'image et les caractéristiques du texte sont respectivement entrées dans deux encodeurs indépendants, puis entrée dans l’encodeur multimodal pour le traitement.
▐
Exploration initialeLa façon dont nous extrayons les caractéristiques de l'image est la suivante : divisez l'image en une séquence de correctifs et utilisez ResNet pour extraire les caractéristiques de l'image de chaque correctif. En termes de structure de modèle, nous avons essayé une structure à flux unique, c'est-à-dire en associant la requête, le titre et l'image ensemble et en les saisissant dans l'encodeur. Après plusieurs séries d'expériences, nous avons constaté que sous cette structure, il est difficile d'extraire des vecteurs de requête purs et des vecteurs d'éléments comme entrées pour la tâche de rappel de vecteurs à deux tours en aval. Si vous masquez les modes inutiles lors de l'extraction d'un certain vecteur, la prédiction ne sera pas cohérente avec l'entraînement. Ce problème est similaire à l'extraction directe du modèle à deux tours à partir d'un modèle interactif. D'après notre expérience, ce modèle n'est pas aussi efficace que le modèle à deux tours entraîné. Sur cette base, nous proposons une nouvelle structure de modèle. ▐
Structure du modèle
La partie inférieure du modèle est composée de tours jumelles et la partie supérieure est fusionnée avec les tours jumelles. tours via un encodeur multimodal. Différentes de la structure à double flux, les tours jumelles ne sont pas composées d'une seule modalité. La tour Item contient des modalités doubles de titre et d'image qui sont assemblées et entrées dans l'encodeur. modèle à flux unique. Afin de modéliser la relation sémantique et l'écart entre la requête et le titre, nous partageons les tours jumelles de l'encodeur de requête et d'élément, puis apprenons le modèle de langage séparément. Pour la pré-formation, la conception de tâches appropriées est également essentielle. Nous avons essayé les tâches de correspondance image-texte couramment utilisées de Titre et d'Image. Bien qu'elles puissent atteindre un degré de correspondance relativement élevé, elles apportent peu de gain à la tâche de rappel de vecteur en aval. En effet, lors de l'utilisation de Query pour rappeler l'élément, le titre de. L'élément et la correspondance de l'image ne sont pas le facteur clé. Par conséquent, lorsque nous concevons des tâches, nous accordons davantage d’attention à la relation entre la requête et l’élément. Actuellement, un total de 5 tâches de pré-formation sont utilisées.
▐ Tâche de pré-formation
- Modélisation du langage masqué (MLM) : dans le jeton de texte, masquez au hasard 15 % et utilisez le texte et les images restants pour prédire le jeton de texte masqué. Pour la requête et le titre, il existe des tâches MLM respectives. MLM minimise la perte d'entropie croisée :
 où représente le jeton de texte restant
où représente le jeton de texte restant
- Modélisation de patch masqué (MPM) : dans le jeton de patch de l'image, masquez aléatoirement 25 % et utilisez l'image et le texte restants. Prédisez le jeton d’image masquée. MPM minimise la perte de divergence KL : où représente les jetons d'image restants
-
Classification des éléments de requête (QIC) : L'élément avec le plus de clics sous une requête est utilisé comme échantillon positif, et d'autres échantillons dans le lot sont utilisés comme échantillon négatif. QIC réduit la dimensionnalité du jeton Query Tower et Item Tower [CLS] à 256 dimensions via une couche linéaire, puis effectue un calcul de similarité pour obtenir la probabilité prédite, minimisant ainsi la perte d'entropie croisée : Parmi eux, peut être calculé Prenez diverses méthodes :
 où représente le jeton de texte restant
où représente le jeton de texte restant
 où représente les jetons d'image restants
où représente les jetons d'image restants
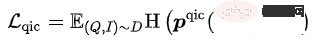 Parmi eux,
Parmi eux,  peut être calculé Prenez diverses méthodes :
peut être calculé Prenez diverses méthodes :
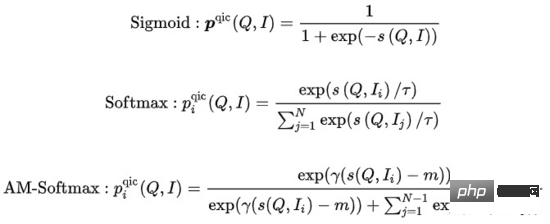
où représente le calcul de similarité, représente l'hyperparamètre de température, et m représentent respectivement le facteur d'échelle et le facteur de relaxation
- Correspondance des éléments de requête (QIM) : l'élément avec le plus de clics dans le cadre d'une requête est utilisé comme échantillon positif, et les autres éléments du lot qui ressemblent le plus à la requête actuelle sont utilisés comme échantillons négatifs. QIM utilise le jeton [CLS] de l'encodeur multimodal pour calculer la probabilité de prédiction et minimiser la perte d'entropie croisée :
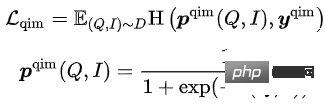
- Query Image Matching (QIM2) : dans les échantillons QIM, le masque supprime le titre et renforce la correspondance de requête avec l'image. QIM2 minimise la perte d'entropie croisée :
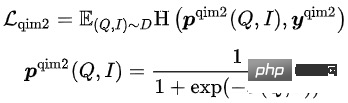
L'objectif de formation du modèle est de minimiser la perte globale :
Parmi ces 5 tâches de pré-formation, la tâche MLM et la tâche MPM sont situées au dessus de la tour Item, la modélisation Titre Ou la possibilité d'utiliser des informations intermodales pour se restaurer une fois qu'une partie du jeton de l'image est masquée. Il existe une tâche MLM indépendante au-dessus de la tour de requête. En partageant l'encodeur de la tour de requête et la tour d'éléments, la relation sémantique et l'écart entre la requête et le titre sont modélisés. La tâche QIC utilise le produit interne de deux tours pour aligner dans une certaine mesure les tâches de pré-entraînement et de rappel vectoriel en aval, et utilise AM-Softmax pour réduire la distance entre la représentation de la requête et la représentation des éléments les plus cliqués sous la requête. , et repoussez la distance entre la requête et les éléments les plus cliqués. La distance des autres éléments. La tâche QIM est située au-dessus de l'encodeur multimodal et utilise des informations multimodales pour modéliser la correspondance de la requête et de l'élément. En raison de la quantité de calcul, le rapport d'échantillons positifs et négatifs de la tâche NSP habituelle est de 1:1. Afin d'élargir davantage la distance entre les échantillons positifs et négatifs, un échantillon négatif difficile est construit sur la base des résultats du calcul de similarité des résultats. Tâche QIC. La tâche QIM2 se situe dans la même position que la tâche QIM, modélisant explicitement les informations incrémentielles apportées par les images par rapport au texte. "Modèle de rappel vectoriel" Pour des raisons de performances, la structure des tours jumelles User et Item est souvent utilisée pour calculer le produit interne des vecteurs. Une question centrale du modèle de rappel vectoriel est la suivante : comment construire des échantillons positifs et négatifs et l'échelle d'échantillonnage des échantillons négatifs. Notre solution consiste à utiliser le clic de l'utilisateur sur un élément d'une page comme échantillon positif, à échantillonner des dizaines de milliers d'échantillons négatifs en fonction de la distribution des clics dans l'ensemble du pool de produits et à utiliser Sampled Softmax Loss pour déduire de l'échantillon d'échantillonnage que le L'article fait partie du pool de produits complet.
où
représente le calcul de similarité, représente l'hyperparamètre de température
▐ Exploration initiale
En suivant le paradigme commun FineTune, nous avons essayé d'entrer des vecteurs pré-entraînés directement dans Twin Towers MLP, combinant un échantillonnage négatif à grande échelle et Sampled Softmax pour entraîner le rappel de vecteurs multimodaux. Modèle. Cependant, contrairement aux tâches habituelles en aval à petite échelle, la taille de l’échantillon d’entraînement de la tâche de rappel vectoriel est énorme, de l’ordre de plusieurs milliards. Nous avons observé que la quantité de paramètres de MLP ne peut pas prendre en charge la formation du modèle et qu'il atteindra bientôt son propre état de convergence, mais l'effet n'est pas bon. Dans le même temps, les vecteurs pré-entraînés sont utilisés comme entrées plutôt que comme paramètres dans le modèle de rappel de vecteurs et ne peuvent pas être mis à jour au fur et à mesure de la progression de l'entraînement. En conséquence, la pré-formation sur des données à relativement petite échelle entre en conflit avec les tâches en aval sur des données à grande échelle.
Il existe plusieurs solutions. Une méthode consiste à intégrer le modèle de pré-entraînement dans le modèle de rappel vectoriel. Cependant, le nombre de paramètres du modèle de pré-entraînement est trop grand et couplé à la taille de l'échantillon du modèle de rappel vectoriel. , il ne peut pas être utilisé dans des conditions de ressources limitées. Ensuite, organisez une formation régulière à un moment raisonnable. Une autre méthode consiste à construire une matrice de paramètres dans le modèle de rappel de vecteurs, à charger les vecteurs pré-entraînés dans la matrice et à mettre à jour les paramètres de la matrice au fur et à mesure de la progression de l'entraînement. Après investigation, cette méthode est relativement coûteuse en termes de mise en œuvre technique. Sur cette base, nous proposons une structure de modèle qui modélise de manière simple et réalisable les mises à jour de vecteurs pré-entraînement.
▐ Structure du modèle
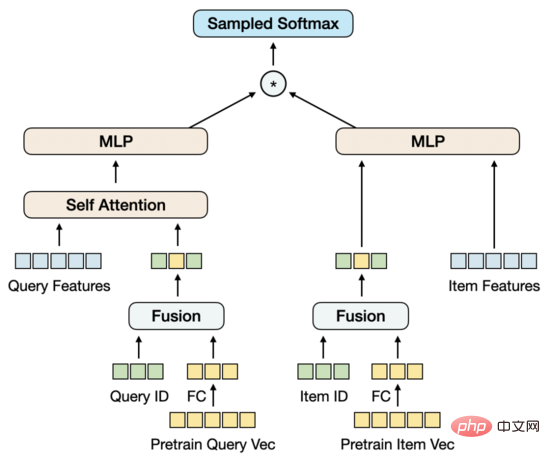
Nous réduisons d'abord la dimension du vecteur de pré-entraînement via FC La raison pour laquelle la dimension est réduite ici plutôt que dans la pré-entraînement est parce que le courant. le vecteur de haute dimension est destiné à l'échantillonnage d'échantillon négatif est toujours dans la plage de performances acceptable. Dans ce cas, la réduction de la dimensionnalité dans la tâche de rappel de vecteur est plus cohérente avec l'objectif de formation. Dans le même temps, nous introduisons la matrice d'intégration ID de la requête et de l'élément. La dimension d'intégration est cohérente avec la dimension du vecteur de pré-entraînement réduit, puis l'ID et le vecteur de pré-entraînement sont fusionnés. Le point de départ de cette conception est d'introduire une quantité de paramètres suffisante pour prendre en charge les données d'entraînement à grande échelle, tout en permettant au vecteur de pré-entraînement d'être mis à jour de manière adaptative au fur et à mesure de la progression de l'entraînement.
Dans le cas de la fusion uniquement des vecteurs ID et de pré-entraînement, l'effet du modèle dépasse non seulement l'effet du MLP à deux tours qui utilise uniquement des vecteurs de pré-entraînement, mais dépasse également le modèle de base MGDSPR, qui contient plus de fonctionnalités. En allant plus loin, l'introduction de davantage de fonctionnalités sur cette base peut continuer à améliorer l'effet.
Analyse expérimentale
▐ Indicateurs d'évaluation
Pour l'effet du modèle pré-entraîné, les indicateurs des tâches en aval sont généralement utilisés pour évaluer, et les indicateurs d'évaluation individuels sont rarement utilisés . Cependant, de cette manière, le coût d'itération du modèle pré-entraîné sera relativement élevé, car chaque itération d'une version du modèle nécessite d'entraîner la tâche de rappel vectoriel correspondante, puis d'évaluer les indicateurs de la tâche de rappel vectoriel, et le l'ensemble du processus sera très long. Existe-t-il des mesures efficaces pour évaluer uniquement les modèles pré-entraînés ? Nous avons d'abord essayé Rank@K dans certains articles. Cet indicateur est principalement utilisé pour évaluer la tâche de correspondance image-texte : utilisez d'abord le modèle pré-entraîné pour noter l'ensemble de candidats artificiellement construit, puis calculez les résultats Top K triés en fonction du score. La proportion d’échantillons positifs correspondants. Nous avons directement appliqué Rank@K à la tâche de correspondance des éléments de requête et avons constaté que les résultats n'étaient pas conformes aux attentes. Un meilleur modèle de pré-formation avec Rank@K peut obtenir de moins bons résultats dans le modèle de rappel vectoriel en aval et ne peut pas guider le pré-entraînement. formation. Itérations de formation du modèle. Sur cette base, nous unifions l'évaluation du modèle de pré-formation et l'évaluation du modèle de rappel vectoriel, et utilisons les mêmes indicateurs et processus d'évaluation, qui peuvent guider relativement efficacement l'itération du modèle de pré-formation.
Recall@K : L'ensemble de données d'évaluation est composé des données du jour suivant de l'ensemble d'entraînement. Tout d'abord, les résultats de clics et de transactions de différents utilisateurs sous la même requête sont agrégés dans  , puis. les résultats Top K prédits par le modèle sont calculés Hits Proportion :
, puis. les résultats Top K prédits par le modèle sont calculés Hits Proportion :
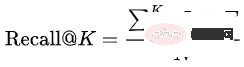
Dans le processus de prédiction des résultats Top K par le modèle, il est nécessaire d'extraire les vecteurs Query et Item à partir du modèle de pré-entraînement/rappel vectoriel et utilisez la récupération du voisin le plus proche pour obtenir une requête sur les K éléments les plus importants. Ce processus simule le rappel vectoriel dans le moteur en ligne pour maintenir la cohérence entre hors ligne et en ligne. Pour le modèle pré-entraîné, la différence entre cet indicateur et Rank@K est que les vecteurs de requête et d'élément sont extraits du modèle pour la récupération du produit interne vectoriel, au lieu d'utiliser directement le modèle de fusion modale pour noter en plus une requête ; non seulement Pour rappeler les éléments correspondants, il est également nécessaire de rappeler les clics et les éléments de transaction des différents utilisateurs sous cette requête.
Pour le modèle de rappel vectoriel, une fois que Recall@K a augmenté jusqu'à un certain niveau, vous devez également faire attention à la corrélation entre la requête et l'élément. Un modèle peu pertinent, même s’il peut améliorer l’efficacité de la recherche, sera également confronté à une détérioration de l’expérience utilisateur et à une augmentation des plaintes et de l’opinion publique causée par une augmentation des Bad Cases. Nous utilisons un modèle hors ligne cohérent avec le modèle de corrélation en ligne pour évaluer la corrélation entre la requête et l'élément et entre les catégories de requête et d'élément.
▐ Expérience de pré-formation
Nous avons sélectionné un pool de produits de 100 millions de niveaux dans certaines catégories pour construire un ensemble de données de pré-formation.
Notre modèle de base est un FashionBert optimisé, qui ajoute des tâches QIM et QIM2 lors de l'extraction des vecteurs de requête et d'élément, nous utilisons uniquement le Mean Pooling pour les jetons non-Padding. Les expériences suivantes explorent les gains apportés par la modélisation avec deux tours par rapport à une seule tour, et donnent le rôle des pièces clés grâce à des expériences d'ablation.

De ces expériences, nous pouvons tirer les conclusions suivantes :
- Expérience 8 vs Expérience 3 : Le modèle optimisé à deux tours est nettement supérieur à la ligne de base à une tour dans Recall@1000.
- Expérience 3 vs Expérience 1/2 : Pour le modèle à tour unique, la manière d'extraire les vecteurs de requête et d'élément est importante. Nous avons essayé d'utiliser le jeton [CLS] pour la requête et l'élément, et avons obtenu de mauvais résultats. L'expérience 1 utilise respectivement les jetons correspondants pour la requête et l'élément pour effectuer le Mean Pooling, et l'effet est meilleur, mais la suppression supplémentaire du jeton de remplissage, puis l'exécution du Mean Pooling apporteront une plus grande amélioration. L'expérience 2 a vérifié que la modélisation explicite de la correspondance requête-image pour mettre en évidence les informations sur l'image apporterait des améliorations.
- Expérience 6 vs Expérience 4/5 : L'expérience 4 a déplacé la tâche MLM/MPM de la tour Item vers l'encodeur multimodal, et l'effet sera pire, car placer ces deux tâches dans la tour Item peut améliorer l'apprentissage de Représentation des éléments ; De plus, la récupération multimodale basée sur le titre et l'image dans la tour des éléments aura une correspondance plus forte. L'expérience 5 a vérifié que l'ajout de la norme L2 aux vecteurs de requête et d'élément pendant la formation et la prédiction apportera des améliorations.
- Expérience 6/7/8 : La modification de la perte de la tâche QIC apportera une amélioration Par rapport à Sigmoid, Softmax est plus proche de la tâche de rappel de vecteur en aval, et AM-Softmax augmente encore la distance entre les échantillons positifs et les échantillons négatifs. .
▐ Expérience de rappel vectoriel
Nous avons sélectionné 1 milliard de pages cliquées pour construire un ensemble de données de rappel vectoriel. Chaque page contient 3 éléments de clic comme échantillons positifs, et 10 000 échantillons négatifs sont échantillonnés dans le pool de produits en fonction de la répartition des clics. Sur cette base, aucune amélioration significative de l'effet n'a été observée en augmentant davantage la quantité de données de formation ou en échantillonnage négatif.
Notre modèle de base est le modèle MGDSPR de la recherche principale. Les expériences suivantes explorent les gains apportés en combinant un pré-entraînement multimodal avec un rappel vectoriel par rapport à la ligne de base, et donnent le rôle des éléments clés grâce à des expériences d'ablation.
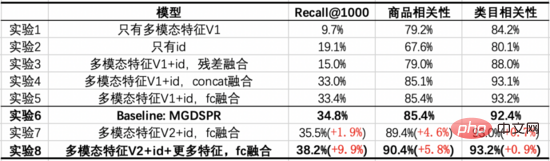
De ces expériences, nous pouvons tirer les conclusions suivantes :
- Expérience 7/8 vs Expérience 6 : Après la fusion des fonctionnalités multimodales et de l'identification via FC, elle a dépassé la ligne de base dans trois indicateurs, tout en augmentant Recall@1000, cela améliore également encore plus la pertinence du produit. Sur cette base, l'ajout des mêmes fonctionnalités que Baseline peut encore améliorer trois indicateurs et améliorer encore plus Recall@1000.
- Expérience 1 vs Expérience 2 : par rapport à l'ID uniquement, seules les fonctionnalités multimodales ont un Recall@1000 inférieur, mais une corrélation plus élevée, et la corrélation est proche de celle disponible en ligne. Cela montre que le modèle de rappel multimodal présente actuellement moins de mauvais cas dans les résultats du rappel, mais que l'efficacité des clics et des transactions n'est pas suffisamment prise en compte.
- Expérience 3/4/5 vs Expérience 1/2 : après avoir fusionné les fonctionnalités multimodales avec l'ID, cela peut améliorer les trois indicateurs. Parmi eux, l'ID est transmis via FC puis combiné avec les fonctionnalités multimodales dimensionnellement réduites. Additionnés, l'effet est meilleur. Cependant, par rapport à Baseline, il existe encore une lacune dans Recall@1000.
- Expérience 7 vs Expérience 5 : après avoir superposé l'optimisation du modèle pré-entraîné, le Recall@1000 et la corrélation de produits sont améliorés, et la corrélation de catégorie est fondamentalement la même.
Nous avons filtré les éléments que le système en ligne a pu rappeler parmi les 1000 meilleurs résultats du modèle de rappel vectoriel et avons constaté que la corrélation des résultats incrémentiels restants est fondamentalement inchangée. Sous un grand nombre de requêtes, nous constatons que ces résultats incrémentiels capturent des informations sur l'image au-delà du titre du produit et jouent un certain rôle dans l'écart sémantique entre la requête et le titre. requête : beau costume
requête : chemise cintrée à la taille pour femme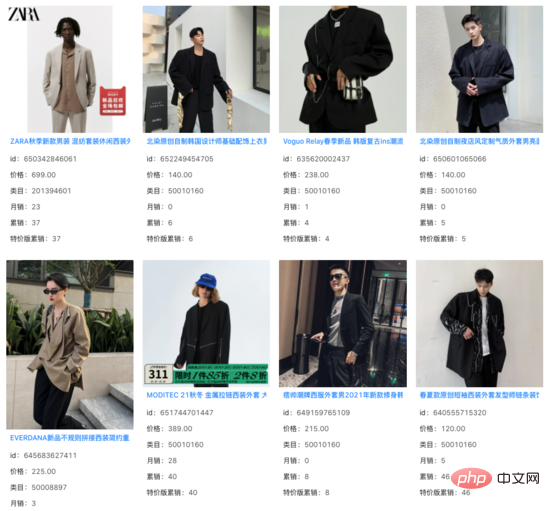
Résumé et Outlook
Visant aux exigences d'application du scénario de recherche principal, nous avons proposé un modèle de pré-formation texte-image, qui adopte la structure de l'encodeur multimodal d'entrée à double tour de requête et d'élément, dans lequel le La tour d'éléments contient plusieurs images et textes. Modèle modal à flux unique. Les tâches de correspondance Query-Item et Query-Image, ainsi que la tâche de multi-classification Query-Item modélisée par le produit interne des tours jumelles Query et Item, rapprochent la pré-formation de la tâche de rappel vectoriel en aval. Dans le même temps, la mise à jour des vecteurs pré-entraînés est modélisée en rappel de vecteurs. Dans le cas de ressources limitées, la pré-formation utilisant une quantité relativement petite de données peut encore améliorer les performances des tâches en aval qui utilisent des données massives.
Dans d'autres scénarios de recherche principale, tels que la compréhension, la pertinence et le tri des produits, il est également nécessaire d'appliquer la technologie multimodale. Nous avons également participé à l'exploration de ces scénarios et pensons que la technologie multimodale apportera des avantages à de plus en plus de scénarios à l'avenir.
Présentation de l'équipe
Équipe principale de rappel de recherche Taobao : L'équipe est responsable du rappel et du tri approximatif des liens dans le lien de recherche principal. La direction technique principale actuelle est le rappel vectoriel personnalisé multi-objectif basé sur des échantillons plein espace, et prédiction à grande échelle basée sur un rappel multimodal entraîné, une réécriture sémantique de requête similaire basée sur un apprentissage contrastif et des modèles de classement grossiers, etc.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Tendances technologiques à surveiller en 2023
- Comment l'intelligence artificielle apporte un nouveau travail quotidien aux équipes des centres de données
- L'intelligence artificielle ou l'automatisation peuvent-elles résoudre le problème de la faible efficacité énergétique des bâtiments ?
- Co-fondateur d'OpenAI interviewé par Huang Renxun : les capacités de raisonnement de GPT-4 n'ont pas encore atteint les attentes
- Bing de Microsoft surpasse Google en termes de trafic de recherche grâce à la technologie OpenAI