
Maison >Périphériques technologiques >IA >Princeton Chen Danqi : Comment réduire la taille des « grands modèles »
Princeton Chen Danqi : Comment réduire la taille des « grands modèles »

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBavant
- 2023-04-08 16:01:031292parcourir
"Rendre les grands modèles plus petits"C'est la poursuite académique de nombreux chercheurs en modèles linguistiques. Compte tenu de l'environnement coûteux et des coûts de formation des grands modèles, Chen Danqi a prononcé un discours intitulé "Créer" lors de l'année académique de Qingyuan. Conférence de l'Intelligent Source Conference "Grands modèles plus petits" conférence invitée. Le rapport s'est concentré sur l'algorithme TRIME basé sur l'amélioration de la mémoire et l'algorithme CofiPruning basé sur l'élagage des joints à grains grossiers et fins et la distillation couche par couche. Le premier peut prendre en compte les avantages de la perplexité du modèle de langage et de la vitesse de récupération sans modifier la structure du modèle ; tandis que le second peut atteindre une vitesse de traitement plus rapide et avoir une structure de modèle plus petite tout en garantissant la précision des tâches en aval.

Chen Danqi Professeur adjoint du département d'informatique de l'Université de Princeton
Chen Danqi est diplômé de la classe Yao de l'Université Tsinghua en 2012 et a obtenu un doctorat en informatique de l'Université de Stanford en 2018. Il a étudié la linguistique et l'informatique au professeur de sciences Christopher Manning de l'Université de Stanford.
1 Contexte Introduction
Ces dernières années, le domaine du traitement du langage naturel est rapidement dominé par les grands modèles linguistiques. Depuis l'avènement de GPT 3, la taille des modèles de langage a augmenté de façon exponentielle. Les grandes entreprises technologiques continuent de publier des modèles linguistiques de plus en plus grands. Récemment, Meta AI a publié le modèle de langage OPT (un grand modèle de langage contenant 175 milliards de paramètres) et a ouvert le code source et les paramètres du modèle au public.

La raison pour laquelle les chercheurs admirent tant les grands modèles de langage est en raison de leurs excellentes capacités d'apprentissage et de leurs performances, mais les gens en savent encore très peu sur la nature de boîte noire des grands modèles de langage. Saisir une question dans le modèle de langage et raisonner étape par étape à travers le modèle de langage peut résoudre des problèmes de raisonnement très complexes, tels que la dérivation de réponses à des problèmes de calcul. Mais dans le même temps, les modèles linguistiques à grande échelle comportent également des risques, notamment leurs coûts environnementaux et économiques. Par exemple, la consommation d’énergie et les émissions de carbone des modèles linguistiques à grande échelle tels que GPT-3 sont stupéfiantes.  Face aux problèmes de formation coûteuse de grands modèles de langage et d'un grand nombre de paramètres, l'équipe de Chen Dan espère réduire la quantité de calcul des modèles de pré-formation grâce à la recherche universitaire et rendre les modèles de langage plus efficaces pour les applications de niveau inférieur. À cette fin, deux travaux de l'équipe sont mis en avant. L'un est une nouvelle méthode de formation pour les modèles de langage appelée TRIME, et l'autre est une méthode efficace d'élagage de modèles adaptée aux tâches en aval appelée CofiPruning.
Face aux problèmes de formation coûteuse de grands modèles de langage et d'un grand nombre de paramètres, l'équipe de Chen Dan espère réduire la quantité de calcul des modèles de pré-formation grâce à la recherche universitaire et rendre les modèles de langage plus efficaces pour les applications de niveau inférieur. À cette fin, deux travaux de l'équipe sont mis en avant. L'un est une nouvelle méthode de formation pour les modèles de langage appelée TRIME, et l'autre est une méthode efficace d'élagage de modèles adaptée aux tâches en aval appelée CofiPruning.
2 document, saisissez-le dans l'encodeur Transformer pour obtenir les vecteurs cachés, puis transportez ces vecteurs cachés vers la couche softmax. La sortie de cette couche est une matrice composée de vecteurs d'incorporation de mots, où V représente la taille de. le vocabulaire. Enfin, ceux-ci peuvent être utilisés. Le vecteur de sortie prédit le texte original et le compare avec la réponse standard du document donné pour calculer le gradient et mettre en œuvre la rétropropagation du gradient. Cependant, un tel paradigme de formation entraînera les problèmes suivants : (1) Un énorme encodeur Transformer entraînera des coûts de formation élevés (2) La longueur d'entrée du modèle de langage est fixe et la quantité de calcul du Transformer augmentera carrément avec ; le changement de la longueur de la séquence augmente, il est donc difficile pour Transformer de gérer des textes longs ; (3) Le paradigme de formation actuel consiste à projeter le texte dans un espace vectoriel de longueur fixe pour prédire les mots suivants ; un goulot d'étranglement du modèle de langage.

À cette fin, l'équipe de Chen Danqi a proposé un nouveau paradigme de formation - TRIME, qui utilise principalement la mémoire batch pour la formation, et sur cette base, elle a proposé trois modèles de langage partageant la même fonction d'objectif de formation, à savoir TrimeLM, TrimeLMlong et TrimeLMext. TrimeLM peut être considéré comme une alternative aux modèles de langage standard ; TrimeLMlong est conçu pour le texte à longue portée, similaire à Transformer-XL ; TrimeLMext combine un grand stockage de données, similaire à kNN-LM ; Sous le paradigme de formation mentionné ci-dessus, TRIME définit d'abord le texte d'entrée comme  , puis transmet l'entrée à l'encodeur Transformer
, puis transmet l'entrée à l'encodeur Transformer  pour obtenir le vecteur caché
pour obtenir le vecteur caché  , et après avoir passé la couche softmax
, et après avoir passé la couche softmax  , le la prédiction requise est obtenue. Le mot suivant
, le la prédiction requise est obtenue. Le mot suivant  , les paramètres entraînables dans l'ensemble du paradigme d'entraînement sont
, les paramètres entraînables dans l'ensemble du paradigme d'entraînement sont  et E. Les travaux de l'équipe de Chen Danqi se sont inspirés des deux travaux suivants : (1) L'algorithme de cache continu proposé par Grave et al. Cet algorithme entraîne un modèle de langage commun pendant le processus de formation
et E. Les travaux de l'équipe de Chen Danqi se sont inspirés des deux travaux suivants : (1) L'algorithme de cache continu proposé par Grave et al. Cet algorithme entraîne un modèle de langage commun pendant le processus de formation  pendant le processus d'inférence, étant donné le texte saisi
pendant le processus d'inférence, étant donné le texte saisi  , il énumère d'abord tous les mots qui sont apparus précédemment dans le texte donné et tous sont égaux à le mot suivant qui doit être prédit marque les positions, puis utilise la similarité entre les variables latentes et le paramètre de température pour calculer la distribution du cache. Dans la phase de test, l'interpolation linéaire de la distribution du modèle de langage et de la distribution du cache peut permettre d'obtenir de meilleurs résultats expérimentaux.
, il énumère d'abord tous les mots qui sont apparus précédemment dans le texte donné et tous sont égaux à le mot suivant qui doit être prédit marque les positions, puis utilise la similarité entre les variables latentes et le paramètre de température pour calculer la distribution du cache. Dans la phase de test, l'interpolation linéaire de la distribution du modèle de langage et de la distribution du cache peut permettre d'obtenir de meilleurs résultats expérimentaux.

(2) Le modèle de langage k-plus proche voisin (kNN-LM) proposé par Khandelwal et al en 2020. Cette méthode est similaire à l'algorithme de mise en cache continue. que kNN-LM est tout Une zone de stockage de données est construite sur la base des exemples de formation. Dans la phase de test, la recherche du voisin le plus proche sera effectuée sur les données de la zone de stockage de données pour sélectionner les meilleures données k. 
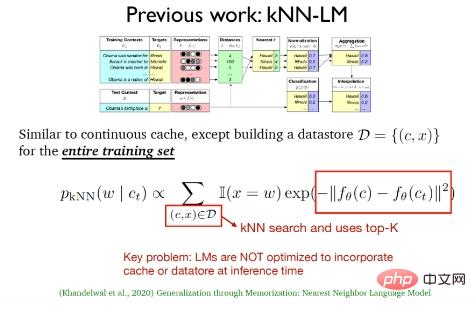
Les deux travaux ci-dessus n'ont en fait utilisé que la distribution de cache et la distribution du k-voisin le plus proche dans la phase de test, ils ont simplement continué le modèle de langage traditionnel. Dans la phase d'inférence, le modèle de langage l'a fait. pas optimiser le cache et les données.
De plus, il existe des travaux de modèles de langage pour des textes très longs dignes d'attention, comme le Transformer-XL proposé en 2019 qui combine le mécanisme de récurrence de l'attention et le modèle basé sur la mémoire proposé en 2020 Compressive Transformers of Memory compression , etc.
Sur la base de plusieurs travaux introduits précédemment, l'équipe de Chen Danqi a construit une méthode de formation de modèles de langage basée sur la mémoire par lots. L'idée principale est de construire une mémoire de travail pour le même lot de formation. Pour la tâche de prédire le mot suivant à partir d'un texte donné, l'idée de TRIME est très similaire à l'apprentissage contrastif. Elle considère non seulement la tâche de prédire la probabilité du mot suivant à l'aide de la matrice d'intégration de mots softmax, mais également. ajoute un nouveau module dans lequel il est pris en compte tous les autres textes qui apparaissent dans la mémoire d'entraînement et qui contiennent le même mot que le texte donné qui doit être prédit.

Par conséquent, la fonction objectif d'entraînement de l'ensemble du TRIME comprend deux parties :
(1) Tâche de prédiction basée sur la matrice d'intégration de mots de sortie.
(2) Partagez la similitude du même texte de mot à prédire dans la mémoire d'entraînement (mémoire d'entraînement), où la représentation vectorielle qui doit être mesurée est l'entrée via la couche de rétroaction finale et le produit scalaire mis à l'échelle est utilisé pour mesurer le vecteur similarité.
L'algorithme espère que le réseau final formé pourra obtenir le mot prédit final aussi précisément que possible, et en même temps, les textes partageant le même mot à prédire dans le même lot de formation sont aussi similaires que possible, donc que toutes les représentations de la mémoire texte sont transmises pendant le processus de formation. La rétropropagation permet l'apprentissage du réseau neuronal de bout en bout. L'idée de mise en œuvre de l'algorithme s'inspire largement de la récupération dense proposée en 2020. La récupération dense aligne les requêtes et les documents positivement liés dans la phase de formation et utilise les documents du même lot comme échantillons négatifs, et extrait les données des données volumineuses dans le phase d’inférence. Récupérer les documents pertinents de la zone de stockage.

La phase d'inférence de TRIME est presque la même que le processus d'entraînement. La seule différence est que différentes mémoires de test peuvent être utilisées, notamment la mémoire locale, la mémoire à long terme et la mémoire externe. La mémoire locale fait référence à tous les mots qui apparaissent dans le segment actuel et qui ont été vectorisés par le mécanisme d'attention ; la mémoire à long terme fait référence aux représentations textuelles qui ne peuvent pas être obtenues directement en raison des limitations de longueur de saisie mais qui proviennent du même document que le texte à traiter. La mémoire externe traitée fait référence à la grande zone de stockage de données qui stocke tous les échantillons d'entraînement ou corpus supplémentaires. 
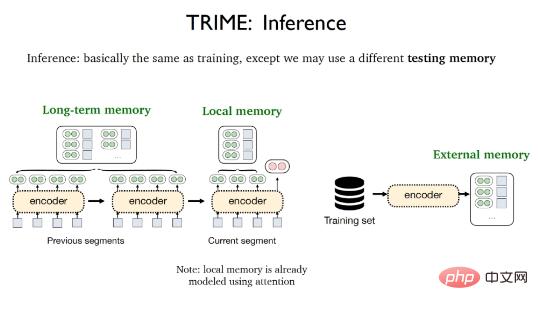
Afin de minimiser l'incohérence entre les phases d'entraînement et de test, certaines stratégies de traitement des données doivent être adoptées pour mieux construire la mémoire d'entraînement. La mémoire locale fait référence aux jetons précédents dans le même fragment de données et est extrêmement bon marché à utiliser. Le traitement par lots d'échantillonnage aléatoire peut être utilisé pour utiliser directement la mémoire locale dans la phase de formation et la phase de test en même temps. Il en résulte une version de base du modèle TrimeLM basée sur la mémoire locale.

La mémoire à long terme fait référence aux balises dans les fragments précédents du même document et doit s'appuyer sur des fragments précédents du même document. À cette fin, des segments consécutifs (segments consécutifs) dans le même document sont placés dans le même lot de formation, ce qui aboutit au modèle TrimeLMlong de mémoire collective à long terme.

La mémoire externe doit être combinée avec de grands magasins de données pour la récupération. À cette fin, BM25 peut être utilisé pour placer des fragments similaires dans les données d'entraînement dans le même lot d'entraînement, ce qui aboutit au modèle TrimeLMext combiné à une mémoire externe.

Pour résumer, le modèle de langage traditionnel n'utilise pas de mémoire dans la phase de formation et la phase de test ; la méthode de mise en cache continue utilise uniquement la mémoire locale ou la mémoire à long terme dans la phase de test ; mémoire dans la phase de test ; et Pour les trois modèles de langage de l'algorithme TRIME, l'amélioration de la mémoire est utilisée dans les étapes de formation et de test. TrimeLM utilise la mémoire locale à la fois dans les étapes de formation et de test. TrimeLMlong place des fragments consécutifs du même document dans le document. La même formation par lots combine la mémoire locale et la mémoire à long terme pendant la phase de test. TrimeLMext place les documents similaires dans le même lot pour la formation pendant la phase de formation et combine la mémoire locale, la mémoire à long terme et la mémoire externe pendant la phase de test.

En phase expérimentale, lors du test du paramètre de modèle 247M et de la longueur de tranche 3072 sur l'ensemble de données WikiText-103, les trois versions du modèle de langage basé sur l'algorithme TRIME peuvent obtenir une meilleure confusion que le traditionnel Effet de perplexité du transformateur, parmi lequel le modèle TrimeLMext basé sur la distance réelle peut obtenir les meilleurs résultats expérimentaux. Dans le même temps, TrimeLM et TrimeLMlong peuvent également maintenir une vitesse de récupération proche de celle du Transformer traditionnel, tout en présentant les avantages de perplexité et de vitesse de récupération.

Lorsque vous testez le paramètre de modèle 150M et la longueur de tranche 150 sur l'ensemble de données WikiText-103, vous pouvez voir que puisque TrimeLMlong place des segments consécutifs du même document dans le même lot de formation dans la phase de formation, ils sont combinés dans la phase de test. Il utilise la mémoire locale et la mémoire à long terme, donc même si la longueur de tranche n'est que de 150, les données réelles disponibles dans la phase de test peuvent atteindre 15 000 et les résultats expérimentaux sont bien meilleurs que les autres modèles de base.

Pour la construction de modèles de langage au niveau des caractères, le modèle de langage basé sur l'algorithme TRIME a également obtenu les meilleurs résultats expérimentaux sur l'ensemble de données enwik8. Dans le même temps, dans la tâche d'application de traduction automatique, TrimeMT_ext a également obtenu. obtenu de meilleurs résultats que les résultats expérimentaux de référence du modèle.

Pour résumer, le modèle de langage basé sur l'algorithme TRIME adopte trois méthodes de construction de mémoire, utilisant pleinement les données pertinentes dans le même lot pour obtenir une amélioration de la mémoire sans introduire beaucoup de calculs. Sans frais et sans modifier la structure globale du modèle, il permet d'obtenir de meilleurs résultats expérimentaux que les autres modèles de base.
Chen Danqi a également mis en évidence le modèle de langage basé sur la récupération. En fait, TrimeLMext peut être considéré comme une meilleure version du modèle de langage du k-voisin le plus proche, mais pendant le processus d'inférence, ces deux algorithmes sont plus rapides que les autres modèles de base. C'est presque 10 à 60 fois plus lent, ce qui est évidemment inacceptable. Chen Danqi a souligné l'une des orientations futures possibles du développement des modèles de langage basés sur la récupération : s'il est possible d'utiliser un encodeur de récupération plus petit et une zone de stockage de données plus grande pour réduire le coût de calcul de la recherche du voisin le plus proche.
Par rapport aux modèles de langage traditionnels, les modèles de langage basés sur la récupération présentent des avantages significatifs. Par exemple, les modèles de langage basés sur la récupération peuvent être mieux mis à jour et maintenus, tandis que les modèles de langage traditionnels ne peuvent pas être formés à l'aide des connaissances antérieures. Dans le même temps, le modèle linguistique basé sur la récupération peut également être mieux utilisé dans les domaines sensibles à la vie privée. Quant à la manière de mieux utiliser les modèles linguistiques basés sur la récupération, l'enseignant Chen Danqi estime que le réglage fin, l'incitation ou l'apprentissage en contexte peuvent être utilisés pour aider à la solution. 

Adresse papier : https://arxiv.org/abs/2204.00408
La technologie de compression de modèles est largement utilisée dans les grands modèles de langage, permettant aux modèles plus petits d'être adaptés plus rapidement aux applications en aval. Les méthodes traditionnelles de compression de modèles traditionnelles sont la distillation et l'élagage. Pour la distillation, il est souvent nécessaire de prédéfinir un modèle d'étudiant fixe. Ce modèle d'étudiant est généralement initialisé de manière aléatoire, puis les connaissances sont transférées du modèle d'enseignant au modèle d'étudiant pour réaliser la distillation des connaissances.
Par exemple, à partir de la version originale de BERT, après distillation générale, c'est-à-dire après une formation sur un grand nombre de corpus non labellisés, vous pouvez obtenir la version de base de TinyBERT4. Pour la version de base de TinyBERT4, vous pouvez. utilisez également la méthode de distillation axée sur les tâches. En obtenant le TinyBERT4 affiné, le modèle final peut être plus petit et plus rapide que le modèle BERT original au détriment d'une légère précision. Cependant, cette méthode basée sur la distillation présente également certains défauts. Par exemple, pour différentes tâches en aval, l'architecture du modèle est souvent fixe en même temps, elle doit être entraînée à partir de zéro à l'aide de données non étiquetées, ce qui est trop coûteux en calcul ;

Pour l'élagage, il est souvent nécessaire de partir d'un modèle enseignant puis de supprimer continuellement les parties non pertinentes du modèle d'origine. L'élagage non structuré proposé en 2019 peut obtenir des modèles plus petits mais présente une légère amélioration de la vitesse d'exécution, tandis que l'élagage structuré permet d'améliorer la vitesse dans les applications pratiques en supprimant des groupes de paramètres tels que les couches de rétroaction, comme en 2021. L'élagage en bloc proposé peut atteindre 2 à 3 fois amélioration de la vitesse.


En réponse aux limites des méthodes traditionnelles de distillation et d'élagage, l'équipe de Chen Danqi a proposé un algorithme appelé CofiPruning, Élagué à la fois les unités à grains grossiers et les unités à grains fins, et a conçu une couche par- La fonction objectif de distillation en couche transfère les connaissances du modèle non élagué au modèle élagué et peut finalement atteindre une augmentation de vitesse de plus de 10 fois tout en conservant une précision de plus de 90 %, par rapport à la méthode de distillation traditionnelle. Le coût de calcul est inférieur.
La proposition de CofiPruning est basée sur deux travaux de base importants :
(1) L'élagage de la couche entière peut améliorer la vitesse. Des travaux connexes soulignent qu'environ 50 % des couches du réseau neuronal peuvent être élaguées, mais. la taille à gros grains a un plus grand impact sur la précision.
(2) consiste à élaguer les unités plus petites telles que les têtes pour obtenir une meilleure flexibilité, mais cette méthode sera un problème d'optimisation plus difficile dans la mise en œuvre et n'aura pas un trop gros problème d'augmentation de vitesse.
Pour cette raison, l'équipe de Chen Danqi espère pouvoir tailler simultanément les unités à gros grains et les unités à grains fins, afin de bénéficier des avantages des deux granularités. De plus, afin de résoudre le problème du transfert de données du modèle d'origine vers le modèle élagué, CofiPruning adopte une méthode d'alignement couche par couche pour transférer les connaissances pendant le processus d'élagage. La fonction objectif finale inclut la perte de distillation et la parcimonie. décalage. Longue journée de perte.

En phase expérimentale, sur l'ensemble de données GLUE pour les tâches de classification de phrases et l'ensemble de données SQuAD1.1 pour les tâches de réponse aux questions, on peut constater que CofiPruning surpasse toutes les distillations et que la méthode de base élaguée est plus performante.

Pour TinyBERT, si la distillation universelle n'est pas utilisée, l'effet expérimental sera considérablement réduit, mais si la distillation universelle est utilisée, bien que l'effet expérimental puisse être amélioré, le temps de formation sera très coûteux ; L'algorithme CofiPruning peut non seulement obtenir presque le même effet que le modèle de base, mais également améliorer considérablement le temps d'exécution et le coût de calcul, et peut atteindre une vitesse de traitement plus rapide avec moins de coûts de calcul. Les expériences montrent que pour les unités à grains grossiers, les première et dernière couches de rétroaction seront conservées dans la plus grande mesure, tandis que les couches intermédiaires sont plus susceptibles d'être élaguées pour les unités à grains fins, les dimensions de la tête et du milieu du neurone supérieur ; réseau Plus susceptible d'être élagué.

En résumé, CofiPruning est un algorithme de compression de modèle très simple et efficace en élaguant conjointement les unités à gros grains et les unités à grains fins, combiné à la fonction objectif de distillation couche par couche, il peut. Connecter l’élagage de la structure et la distillation des connaissances tire parti des deux algorithmes, ce qui entraîne un traitement plus rapide et des structures de modèle plus petites. Concernant la tendance future de la compression des modèles, Chen Danqi s'est également concentré sur la question de savoir si les grands modèles de langage tels que GPT-3 pouvaient être élagués et si les tâches en amont pouvaient être élaguées. Ce sont des idées de recherche sur lesquelles on peut se concentrer à l'avenir.
3 Résumé et perspectives
Les modèles linguistiques à grande échelle ont désormais atteint une valeur d'application pratique très gratifiante. Cependant, en raison de coûts environnementaux et économiques coûteux, de problèmes de confidentialité et d'équité et de difficultés de mises à jour en temps réel, de grande ampleur. Modèles de langage à grande échelle Les modèles de langage laissent encore beaucoup à désirer. Chen Danqi estime que les futurs modèles de langage pourraient être utilisés comme bases de connaissances à grande échelle. Dans le même temps, l'échelle des modèles de langage devra être considérablement réduite à l'avenir. Des modèles de langage basés sur la récupération ou des modèles de langage clairsemés pourraient être utilisés pour. remplacer les travaux de récupération dense et de compression de modèles. Les chercheurs doivent également se concentrer là-dessus.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Tendances technologiques à surveiller en 2023
- Comment l'intelligence artificielle apporte un nouveau travail quotidien aux équipes des centres de données
- L'intelligence artificielle ou l'automatisation peuvent-elles résoudre le problème de la faible efficacité énergétique des bâtiments ?
- Co-fondateur d'OpenAI interviewé par Huang Renxun : les capacités de raisonnement de GPT-4 n'ont pas encore atteint les attentes
- Bing de Microsoft surpasse Google en termes de trafic de recherche grâce à la technologie OpenAI