
Maison >interface Web >js tutoriel >Comment utiliser Node pour la compression d'images
Comment utiliser Node pour la compression d'images

- 青灯夜游avant
- 2023-03-20 18:22:482358parcourir
Comment utiliser Node pour la compression d'images ? L'article suivant utilise les images PNG comme exemple pour présenter comment compresser des images. J'espère qu'il vous sera utile !

Récemment, je souhaite fournir des services de traitement d'image, dont l'un consiste à implémenter la fonction de compression d'image. Dans le passé, lors du développement du front-end, je pouvais simplement utiliser l'API prête à l'emploi de Canvas pour le traiter. Le back-end pouvait également avoir une API prête à l'emploi, mais je ne sais pas. En y réfléchissant bien, je n'ai jamais compris le principe de la compression d'image en détail, j'ai donc juste profité de cette occasion pour faire quelques recherches et études, j'ai donc écrit cet article pour l'enregistrer. Comme toujours, s'il y a quelque chose qui ne va pas, DDDD (emmenez votre frère avec vous).
Nous téléchargeons d’abord l’image sur le backend et voyons quels paramètres le backend reçoit. J'utilise Node.js (Nest) comme backend ici et j'utilise des images PNG comme exemple.
L'interface et les paramètres sont imprimés comme suit :
@Post('/compression')<br/>@UseInterceptors(FileInterceptor('file'))<br/>async imageCompression(@UploadedFile() file: Express.Multer.File) {<br/> <br/> return {<br/> file<br/> }<br/>}<br/>
Pour effectuer la compression, nous devons obtenir les données de l'image. Comme vous pouvez le voir, la seule chose qui peut masquer les données d'image est cette chaîne de tampons. Alors, que décrit cette chaîne de tampons ? Vous devez d’abord comprendre ce qu’est PNG. [Tutoriels associés recommandés : Tutoriel vidéo Nodejs, Enseignement de la programmation]
PNG
Voici l'adresse WIKI de PNG.
Après avoir lu, j'ai appris que PNG est composé d'un en-tête de fichier de 8 octets et de plusieurs morceaux. Le diagramme schématique est le suivant :
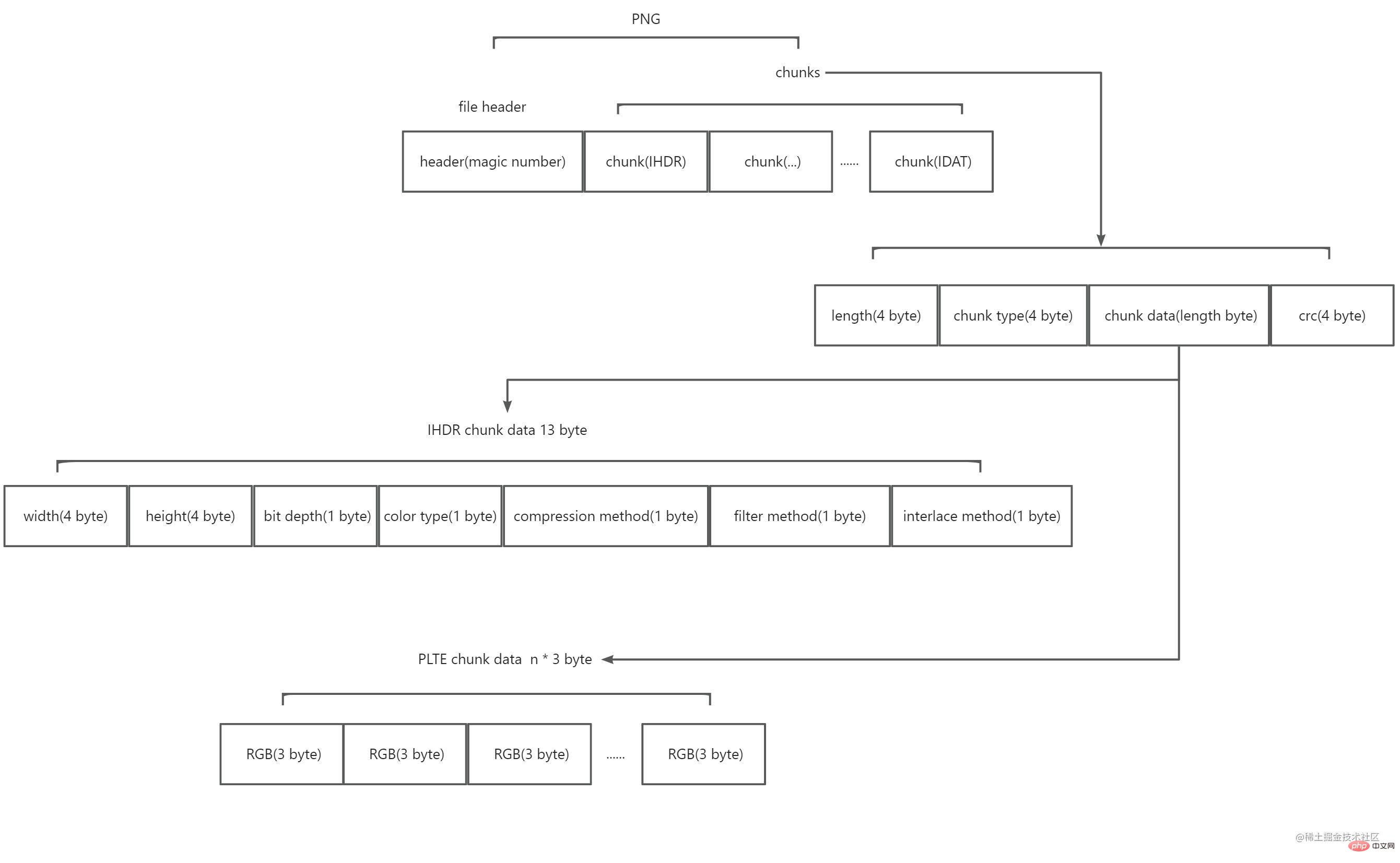
Parmi eux :
L'en-tête du fichier est composé d'un nombre dit magique. La valeur est 89 50 4e 47 0d 0a 1a 0a (hexadécimal). Il marque cette chaîne de données au format PNG.
Les blocs sont divisés en deux types, l'un est appelé morceaux critiques (morceaux critiques) et l'autre est appelé morceaux auxiliaires (morceaux auxiliaires). Le bloc clé est indispensable. Sans le bloc clé, le décodeur ne pourra pas identifier et afficher correctement l'image. Le bloc auxiliaire est facultatif et certains logiciels peuvent transporter le bloc auxiliaire après le traitement de l'image. Chaque bloc est composé de quatre parties : 4 octets décrivent la longueur du contenu de ce bloc, 4 octets décrivent le type de ce bloc et n octets décrit le contenu du bloc (n est la taille de la valeur de 4 octets précédente, c'est-à-dire que la longueur maximale d'un bloc est de 28*4), et la vérification CRC sur 4 octets vérifie les données du bloc et marque la fin d'un bloc. Parmi eux, la valeur de 4 octets du type de bloc est de 4 codes acsii. La première lettre en majuscule signifie qu'il s'agit d'un bloc clé , et en minuscule signifie qu'il s'agit d'un bloc auxiliaire ; la casse signifie qu'il est public , et en minuscule signifie qu'il est public ; la troisième lettre doit être en majuscule , utilisée pour l'expansion ultérieure de PNG ; la quatrième lettre indique si le bloc peut être copié en toute sécurité lorsqu'il l'est. non reconnu, les majuscules signifient qu'il peut être copié en toute sécurité uniquement lorsque le bloc clé n'a pas été modifié, et les minuscules signifient que la copie est sûre. PNG fournit officiellement de nombreux types de blocs définis. Ici, il vous suffit de connaître les types de blocs clés, à savoir IHDR, PLTE, IDAT et IEND.
IHDR
Exigence PNGLe premier bloc doit être IHDR. Le contenu du bloc d'IHDR est fixé à 13 octets et contient les informations suivantes de l'image :
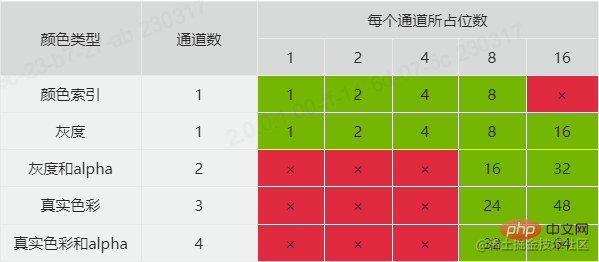
largeur (4 octets) et hauteur (4 octets)profondeur de bits (1 octet, les valeurs sont 1, 2, 4, 8 ou 16) et type de couleur type de couleur (1 octet, la valeur est 0, 2, 3, 4 ou 6) méthode de compression méthode de compression (1 octet, la valeur est 0) et méthode de filtrage méthode de filtrage (1 octet, la valeur est 0) 0)Méthode d'entrelacement (1 octet, la valeur est 0 ou 1)La largeur et la hauteur sont faciles à comprendre, les autres ne semblent pas familières, je les expliquerai ensuite. Avant d'expliquer la profondeur de bits, examinons d'abord le type de couleur. Le type de couleur a 5 valeurs :- 0 signifie niveaux de gris. Si vous le considérez comme RVB, vous pouvez le comprendre. Les valeurs des trois canaux de couleur sont égales, il n'est donc pas nécessaire d'avoir plus de deux canaux pour les représenter.
- 2 représente la couleur réelle (rgb) qui possède trois canaux, à savoir R (rouge), G (vert), B (bleu).
3 représente l'index de couleur (indexé). Il n'a également qu'un seul canal, représentant la valeur d'index de la couleur. Ce type est souvent équipé d'un ensemble de listes de couleurs, et la couleur spécifique est obtenue en fonction de la valeur d'index et de la requête de liste de couleurs.
4 représente les niveaux de gris et l'alpha. Il possède deux canaux En plus du canal en niveaux de gris, il existe un canal alpha supplémentaire pour contrôler la transparence.
6 signifie vraie couleur et alpha qui a quatre canaux.
La raison pour laquelle nous parlons de canal est qu'il est ici lié à la profondeur de bits. La valeur de profondeur de bits définit le nombre de bits occupés par chaque canal. En combinant la profondeur de bits et le type de couleur, vous pouvez connaître le type de format de couleur de l'image et la taille de la mémoire occupée par chaque pixel. Les combinaisons officiellement prises en charge par PNG sont les suivantes :
Le filtrage et la compression sont dus au fait que PNG ne stocke pas les données originales de l'image, mais les données traitées, c'est pourquoi les images PNG occupent moins de mémoire. PNG utilise deux étapes pour compresser et convertir les données d’image.
La première étape est le filtrage. Le but du filtrage est de permettre aux données d'image originales d'atteindre un taux de compression plus élevé après avoir respecté les règles. Par exemple, s'il y a une image dégradée, de gauche à droite, les couleurs sont [#000000, #000001, #000002, ..., #ffffff], alors nous pouvons nous mettre d'accord sur une règle selon laquelle les pixels de droite sont toujours la même chose que Comparez-le avec le pixel de gauche précédent, puis les données traitées deviennent [1, 1, 1, ..., 1], cela permettra-t-il une meilleure compression ? PNG ne dispose actuellement que d'une seule méthode de filtrage, basée sur les pixels adjacents comme valeurs prédites et soustrayant les valeurs prédites du pixel actuel. Il existe cinq types de filtrage. (Actuellement, je ne sais pas où ce type de valeur est stocké. Il se peut que ce soit dans IDAT. Si vous le trouvez, supprimez le dans cette parenthèse. Il a été déterminé que ce type de valeur est stocké dans les données IDAT ) Comme suit Comme indiqué dans le tableau :
| Type d'octet | Nom du filtre | Valeur prédite |
|---|---|---|
| 0 | Aucun | Aucun traitement |
| 1 | Sub | Neighborring Pixels sur la gauche |
| 2 | up | adjacent pixels au-dessus de |
| 3 | Average | math.floor ((pixels adjacents à gauche + pixels adjacents ci-dessus) / 2) |
| 4 | Paeth | Prenez la valeur la plus proche |
第二步,压缩。PNG也只有一种压缩算法,使用的是DEFLATE算法。这里不细说,具体看下面的章节。
交错方式,有两种值。0表示不处理,1表示使用Adam7 算法进行处理。我没有去详细了解该算法,简单来说,当值为0时,图片需要所有数据都加载完毕时,图片才会显示。而值为1时,Adam7会把图片划分多个区域,每个区域逐级加载,显示效果会有所优化,但通常会降低压缩效率。加载过程可以看下面这张gif图。

PLTE
PLTE的块内容为一组颜色列表,当颜色类型为颜色索引时需要配置。值得注意的是,颜色列表中的颜色一定是每个通道8bit,每个像素24bit的真实色彩列表。列表的长度,可以比位深约定的少,但不能多。比如位深是2,那么22,最多4种颜色,列表长度可以为3,但不能为5。
IDAT
IDAT的块内容是图片原始数据经过PNG压缩转换后的数据,它可能有多个重复的块,但必须是连续的,并且只有当上一个块填充满时,才会有下一个块。
IEND
IEND的块内容为0 byte,它表示图片的结束。
阅读到这里,我们把上面的接口改造一下,解析这串buffer。
@Post('/compression')<br/>@UseInterceptors(FileInterceptor('file'))<br/>async imageCompression(@UploadedFile() file: Express.Multer.File) {<br/> const buffer = file.buffer;<br/><br/> const result = {<br/> header: buffer.subarray(0, 8).toString('hex'),<br/> chunks: [],<br/> size: file.size,<br/> };<br/><br/> let pointer = 8;<br/> while (pointer < buffer.length) {<br/> let chunk = {};<br/> const length = parseInt(buffer.subarray(pointer, pointer + 4).toString('hex'), 16);<br/> const chunkType = buffer.subarray(pointer + 4, pointer + 8).toString('ascii');<br/> const crc = buffer.subarray(pointer + length, pointer + length + 4).toString('hex');<br/> chunk = {<br/> ...chunk,<br/> length,<br/> chunkType,<br/> crc,<br/> };<br/><br/> switch (chunkType) {<br/> case 'IHDR':<br/> const width = parseInt(buffer.subarray(pointer + 8, pointer + 12).toString('hex'), 16);<br/> const height = parseInt(buffer.subarray(pointer + 12, pointer + 16).toString('hex'), 16);<br/> const bitDepth = parseInt(<br/> buffer.subarray(pointer + 16, pointer + 17).toString('hex'),<br/> 16,<br/> );<br/> const colorType = parseInt(<br/> buffer.subarray(pointer + 17, pointer + 18).toString('hex'),<br/> 16,<br/> );<br/> const compressionMethod = parseInt(<br/> buffer.subarray(pointer + 18, pointer + 19).toString('hex'),<br/> 16,<br/> );<br/> const filterMethod = parseInt(<br/> buffer.subarray(pointer + 19, pointer + 20).toString('hex'),<br/> 16,<br/> );<br/> const interlaceMethod = parseInt(<br/> buffer.subarray(pointer + 20, pointer + 21).toString('hex'),<br/> 16,<br/> );<br/><br/> chunk = {<br/> ...chunk,<br/> width,<br/> height,<br/> bitDepth,<br/> colorType,<br/> compressionMethod,<br/> filterMethod,<br/> interlaceMethod,<br/> };<br/> break;<br/> case 'PLTE':<br/> const colorList = [];<br/> const colorListStr = buffer.subarray(pointer + 8, pointer + 8 + length).toString('hex');<br/> for (let i = 0; i < colorListStr.length; i += 6) {<br/> colorList.push(colorListStr.slice(i, i + 6));<br/> }<br/> chunk = {<br/> ...chunk,<br/> colorList,<br/> };<br/> break;<br/> default:<br/> break;<br/> }<br/> result.chunks.push(chunk);<br/> pointer = pointer + 4 + 4 + length + 4;<br/> }<br/><br/> return result;<br/>}<br/>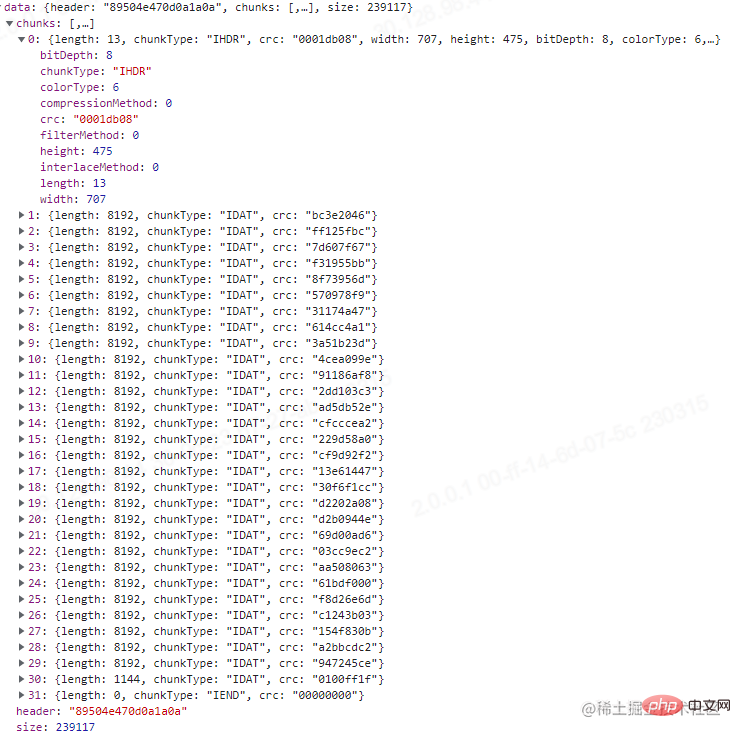
这里我测试用的图没有PLTE,刚好我去TinyPNG压缩我那张测试图之后进行上传,发现有PLTE块,可以看一下,结果如下图。
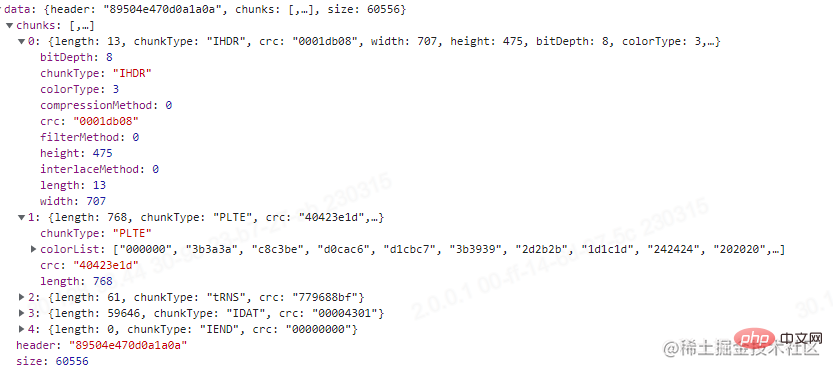
通过比对这两张图,压缩图片的方式我们也能窥探一二。
PNG的压缩
前面说过,PNG使用的是一种叫DEFLATE的无损压缩算法,它是Huffman Coding跟LZ77的结合。除了PNG,我们经常使用的压缩文件,.zip,.gzip也是使用的这种算法(7zip算法有更高的压缩比,也可以了解下)。要了解DEFLATE,我们首先要了解Huffman Coding和LZ77。
Huffman Coding
哈夫曼编码忘记在大学的哪门课接触过了,它是一种根据字符出现频率,用最少的字符替换出现频率最高的字符,最终降低平均字符长度的算法。
举个例子,有字符串"ABCBCABABADA",如果按照正常空间存储,所占内存大小为12 * 8bit = 96bit,现对它进行哈夫曼编码。
1.统计每个字符出现的频率,得到A 5次 B 4次 C 2次 D 1次
2.对字符按照频率从小到大排序,将得到一个队列D1,C2,B4,A5
3.按顺序构造哈夫曼树,先构造一个空节点,最小频率的字符分给该节点的左侧,倒数第二频率的字符分给右侧,然后将频率相加的值赋值给该节点。接着用赋值后节点的值和倒数第三频率的字符进行比较,较小的值总是分配在左侧,较大的值总是分配在右侧,依次类推,直到队列结束,最后把最大频率和前面的所有值相加赋值给根节点,得到一棵完整的哈夫曼树。
4.对每条路径进行赋值,左侧路径赋值为0,右侧路径赋值为1。从根节点到叶子节点,进行遍历,遍历的结果就是该字符编码后的二进制表示,得到:A(0)B(11)C(101)D(100)。
完整的哈夫曼树如下(忽略箭头,没找到连线- -!):
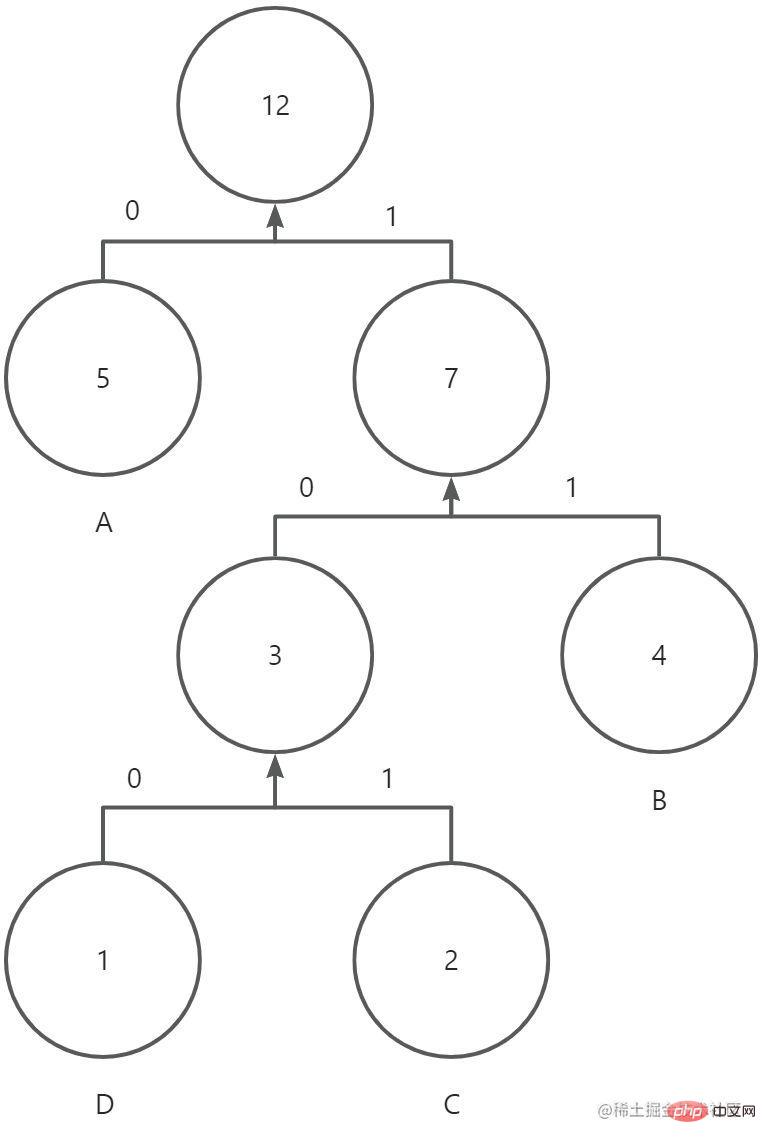
压缩后的字符串,所占内存大小为5 * 1bit + 4 * 2bit + 2 * 3bit + 1 * 3bit = 22bit。当然在实际传输过程中,还需要把编码表的信息(原始字符和出现频率)带上。因此最终占比大小为 4 * 8bit + 4 * 3bit(频率最大值为5,3bit可以表示)+ 22bit = 66bit(理想状态),小于原有的96bit。
LZ77
LZ77算法还是第一次知道,查了一下是一种基于字典和滑动窗的无所压缩算法。(题外话:因为Lempel和Ziv在1977年提出的算法,所以叫LZ77,哈哈哈?)
我们还是以上面这个字符串"ABCBCABABADA"为例,现假设有一个4 byte的动态窗口和一个2byte的预读缓冲区,然后对它进行LZ77算法压缩,过程顺序从上往下,示意图如下:

总结下来,就是预读缓冲区在动态窗口中找到最长相同项,然后用长度较短的标记来替代这个相同项,从而实现压缩。从上图也可以看出,压缩比跟动态窗口的大小,预读缓冲区的大小和被压缩数据的重复度有关。
DEFLATE
DEFLATE【RFC 1951】是先使用LZ77编码,对编码后的结果在进行哈夫曼编码。我们这里不去讨论具体的实现方法,直接使用其推荐库Zlib,刚好Node.js内置了对Zlib的支持。接下来我们继续改造上面那个接口,如下:
import * as zlib from 'zlib';<br/><br/>@Post('/compression')<br/>@UseInterceptors(FileInterceptor('file'))<br/>async imageCompression(@UploadedFile() file: Express.Multer.File) {<br/> const buffer = file.buffer;<br/><br/> const result = {<br/> header: buffer.subarray(0, 8).toString('hex'),<br/> chunks: [],<br/> size: file.size,<br/> };<br/><br/> // 因为可能有多个IDAT的块 需要个数组缓存最后拼接起来<br/> const fileChunkDatas = [];<br/> let pointer = 8;<br/> while (pointer < buffer.length) {<br/> let chunk = {};<br/> const length = parseInt(buffer.subarray(pointer, pointer + 4).toString('hex'), 16);<br/> const chunkType = buffer.subarray(pointer + 4, pointer + 8).toString('ascii');<br/> const crc = buffer.subarray(pointer + length, pointer + length + 4).toString('hex');<br/> chunk = {<br/> ...chunk,<br/> length,<br/> chunkType,<br/> crc,<br/> };<br/><br/> switch (chunkType) {<br/> case 'IHDR':<br/> const width = parseInt(buffer.subarray(pointer + 8, pointer + 12).toString('hex'), 16);<br/> const height = parseInt(buffer.subarray(pointer + 12, pointer + 16).toString('hex'), 16);<br/> const bitDepth = parseInt(<br/> buffer.subarray(pointer + 16, pointer + 17).toString('hex'),<br/> 16,<br/> );<br/> const colorType = parseInt(<br/> buffer.subarray(pointer + 17, pointer + 18).toString('hex'),<br/> 16,<br/> );<br/> const compressionMethod = parseInt(<br/> buffer.subarray(pointer + 18, pointer + 19).toString('hex'),<br/> 16,<br/> );<br/> const filterMethod = parseInt(<br/> buffer.subarray(pointer + 19, pointer + 20).toString('hex'),<br/> 16,<br/> );<br/> const interlaceMethod = parseInt(<br/> buffer.subarray(pointer + 20, pointer + 21).toString('hex'),<br/> 16,<br/> );<br/><br/> chunk = {<br/> ...chunk,<br/> width,<br/> height,<br/> bitDepth,<br/> colorType,<br/> compressionMethod,<br/> filterMethod,<br/> interlaceMethod,<br/> };<br/> break;<br/> case 'PLTE':<br/> const colorList = [];<br/> const colorListStr = buffer.subarray(pointer + 8, pointer + 8 + length).toString('hex');<br/> for (let i = 0; i < colorListStr.length; i += 6) {<br/> colorList.push(colorListStr.slice(i, i + 6));<br/> }<br/> chunk = {<br/> ...chunk,<br/> colorList,<br/> };<br/> break;<br/> case 'IDAT':<br/> fileChunkDatas.push(buffer.subarray(pointer + 8, pointer + 8 + length));<br/> break;<br/> default:<br/> break;<br/> }<br/> result.chunks.push(chunk);<br/> pointer = pointer + 4 + 4 + length + 4;<br/> }<br/><br/> const originFileData = zlib.unzipSync(Buffer.concat(fileChunkDatas));<br/><br/> // 这里原图片数据太长了 我就只打印了长度<br/> return {<br/> ...result,<br/> originFileData: originFileData.length,<br/> };<br/>}<br/>
最终打印的结果,我们需要注意红框的那几个部分。可以看到上图,位深和颜色类型决定了每个像素由4 byte组成,然后由于过滤方式的存在,会在每行的第一个字节进行标记。因此该图的原始数据所占大小为:707 * 475 * 4 byte + 475 * 1 byte = 1343775 byte。正好是我们打印的结果。
我们也可以试试之前TinyPNG压缩后的图,如下:
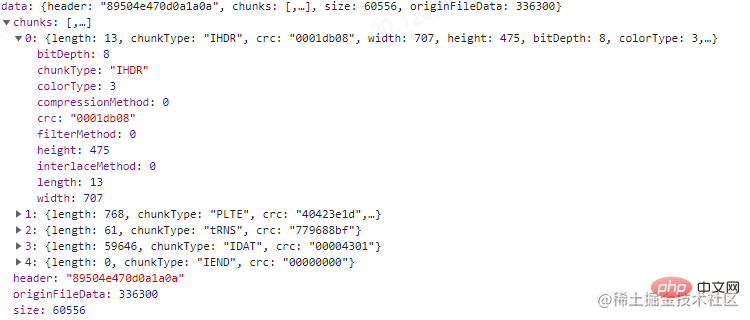
可以看到位深为8,索引颜色类型的图每像素占1 byte。计算得到:707 * 475 * 1 byte + 475 * 1 byte = 336300 byte。结果也正确。
总结
现在再看如何进行图片压缩,你可能很容易得到下面几个结论:
1.减少不必要的辅助块信息,因为辅助块对PNG图片而言并不是必须的。
2.减少IDAT的块数,因为每多一个IDAT的块,就多余了12 byte。
3.降低每个像素所占的内存大小,比如当前是4通道8位深的图片,可以统计整个图片色域,得到色阶表,设置索引颜色类型,降低通道从而降低每个像素的内存大小。
4.等等....
至于JPEG,WEBP等等格式图片,有机会再看。溜了溜了~(还是使用现成的库处理压缩吧)。
好久没写文章,写完才发现语雀不能免费共享,发在这里吧。
更多node相关知识,请访问:nodejs 教程!
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Comment configurer l'environnement Node dans IDEA ? Brève analyse des méthodes
- Qu'est-ce qu'EventLoop ? Comment tester les performances d'un nœud ou d'une page
- Qu'est-ce que le cache ? Comment l'implémenter à l'aide d'un nœud ?
- Comment mettre à niveau la version du nœud ? Partage de tutoriel détaillé
- Une brève analyse de la façon dont le module http de Node gère les téléchargements de fichiers
- Compréhension approfondie du mécanisme de boucle d'événements Node (EventLoop)