
Maison >base de données >Redis >Résumé de 20 questions et réponses d'entretien Redis classiques (partager)
Résumé de 20 questions et réponses d'entretien Redis classiques (partager)

- 青灯夜游avant
- 2023-03-07 18:53:414811parcourir
Cet article a compilé pour vous 20 questions d'entretien Redis classiques. J'espère qu'il vous sera utile.

1. Qu'est-ce que Redis ? A quoi sert-il principalement ?
Redis, le nom anglais complet est Remote Dictionary Server (Remote Dictionary Service), est une base de données de valeurs-clés de type journal open source écrite en langage ANSI C, prend en charge le réseau, peut être basée sur la mémoire et peut être persisté et fournit une API multilingue.
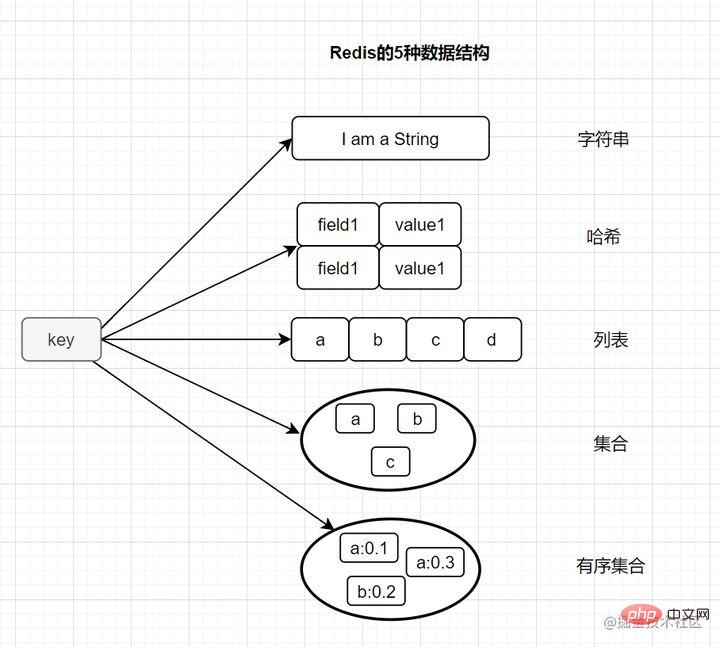
Différent de la base de données MySQL, les données Redis sont stockées en mémoire. Ses vitesses de lecture et d'écriture sont très rapides et peuvent gérer plus de 100 000 opérations de lecture et d'écriture par seconde. Par conséquent, Redis est largement utilisé dans la mise en cache. De plus, Redis est également souvent utilisé pour les verrous distribués. De plus, Redis prend en charge les transactions, la persistance, les scripts LUA, les événements pilotés par LRU et diverses solutions de cluster. 2. Parlons des types de structure de données de base de Redis
La plupart des amis savent que Redis a les cinq types de base suivants :
String (chaîne)- Hash (hash)
- List (list) )
- Set (set)
- zset (ensemble ordonné)
- Il dispose également de trois types de structures de données spéciaux
- Hyperloglog
- Bitmap
 Chaîne (string)
Chaîne (string)
- Exemple d'utilisation simple :
définir la valeur de la clé<.>, <code>get key, etc. - Scénarios d'application : session partagée, verrouillage distribué, compteur, limite de courant.
set key value、get key等 - 应用场景:共享session、分布式锁,计数器、限流。
- 内部编码有3种,
int(8字节长整型)/embstr(小于等于39字节字符串)/raw(大于39个字节字符串)
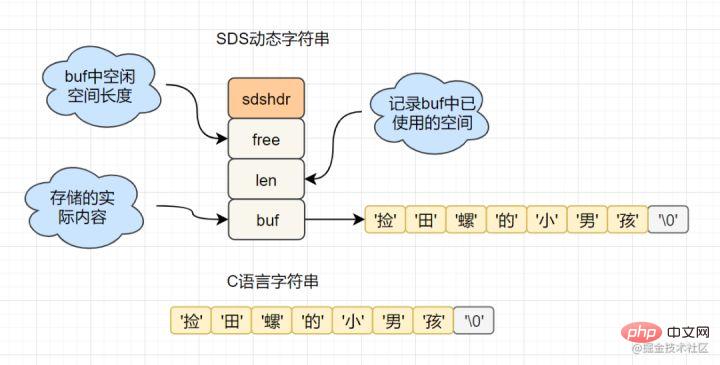
C语言的字符串是char[]实现的,而Redis使用SDS(simple dynamic string) 封装,sds源码如下:
struct sdshdr{
unsigned int len; // 标记buf的长度
unsigned int free; //标记buf中未使用的元素个数
char buf[]; // 存放元素的坑
}SDS 结构图如下:
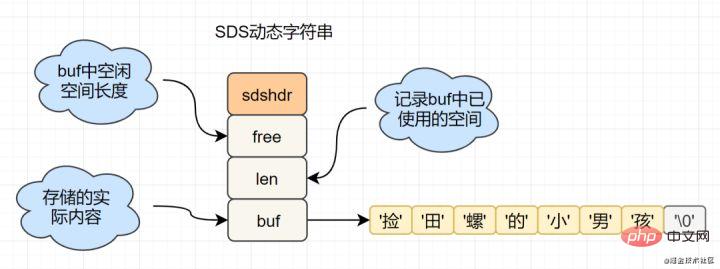
Redis为什么选择SDS结构,而C语言原生的char[]不香吗?
举例其中一点,SDS中,O(1)时间复杂度,就可以获取字符串长度;而C 字符串,需要遍历整个字符串,时间复杂度为O(n)
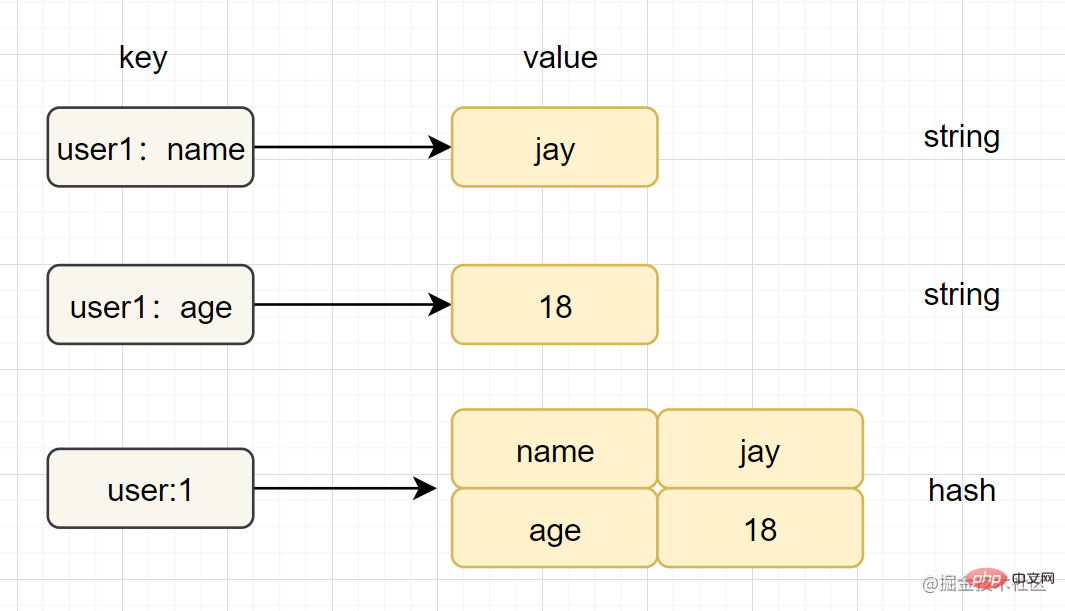
Hash(哈希)
- 简介:在Redis中,哈希类型是指v(值)本身又是一个键值对(k-v)结构
- 简单使用举例:
hset key field value、hget key field - 内部编码:
ziplist(压缩列表)、hashtable(哈希表) - 应用场景:缓存用户信息等。
- 注意点:如果开发使用hgetall,哈希元素比较多的话,可能导致Redis阻塞,可以使用hscan。而如果只是获取部分field,建议使用hmget。
字符串和哈希类型对比如下图:
List(列表)
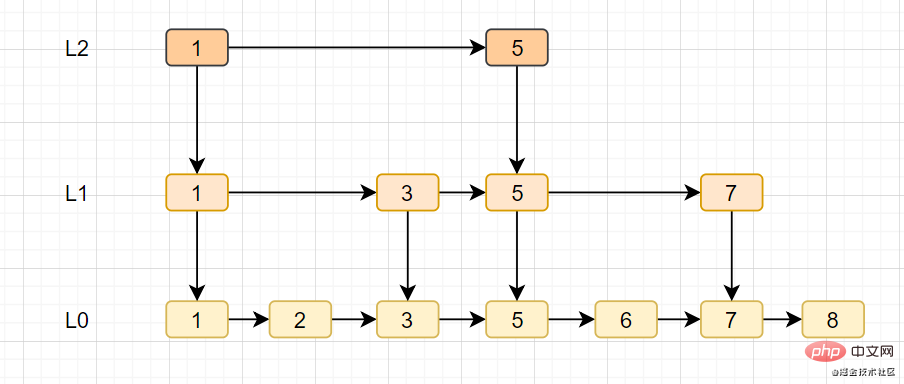
- 简介:列表(list)类型是用来存储多个有序的字符串,一个列表最多可以存储2^32-1个元素。
- 简单实用举例:
lpush key value [value ...]、lrange key start end - 内部编码:ziplist(压缩列表)、linkedlist(链表)
- 应用场景:消息队列,文章列表,
一图看懂list类型的插入与弹出:
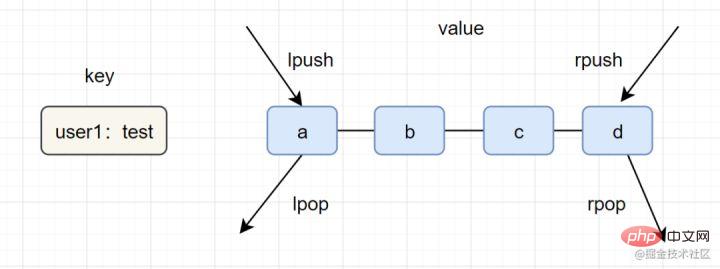
list应用场景参考以下:
- lpush+lpop=Stack(栈)
- lpush+rpop=Queue(队列)
- lpsh+ltrim=Capped Collection(有限集合)
- lpush+brpop=Message Queue(消息队列)
Set(集合)
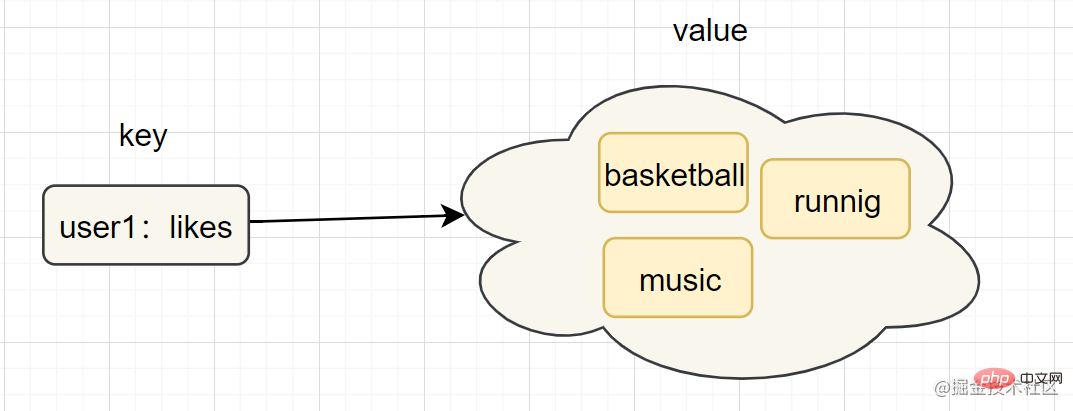
- 简介:集合(set)类型也是用来保存多个的字符串元素,但是不允许重复元素
- 简单使用举例:
sadd key element [element ...]、smembers key - 内部编码:
intset(整数集合)、hashtable(哈希表)Il existe 3 types d'encodage interne, -
C La chaîne du langage est implémentée par
char[], et Redis est encapsulé en utilisant SDS (simple chaîne dynamique) - Le code source sds est le suivant :
int (entier long de 8 octets)/embstr (inférieur ou égal à une chaîne de 39 octets)/raw (chaîne de plus de 39 octets)zadd user:ranking:2021-03-03 Jay 3Le diagramme de structure SDS est. comme suit :
🎜🎜Pourquoi Redis a-t-il choisi le 🎜 Structure SDS🎜, tandis que le natif du langage C n'est-il pas char[] délicieux ? 🎜🎜Par exemple, dans SDS, vous pouvez obtenir la longueur de la chaîne avec une complexité temporelle O(1) tandis que pour les chaînes C, vous devez parcourir la chaîne entière et la complexité temporelle est O(n)🎜 blockquote >🎜Hash (Hash)🎜🎜🎜Introduction : Dans Redis, le type de hachage fait référence à v (valeur) lui-même qui est une structure de paire clé-valeur (k-v)🎜🎜Exemple d'utilisation simple :hset key field value, <code>champ de clé hget🎜🎜Encodage interne :ziplist (liste compressée),hashtable (table de hachage)🎜🎜Scénarios d'application : mise en cache informations utilisateur, etc. 🎜🎜🎜Remarque🎜 : Si hgetall est utilisé dans le développement et qu'il existe de nombreux éléments de hachage, cela peut entraîner le blocage de Redis. Vous pouvez utiliser hscan. Si vous souhaitez uniquement obtenir certains champs, il est recommandé d'utiliser hmget. 🎜🎜🎜La comparaison entre les types de chaîne et de hachage est la suivante : 🎜🎜🎜🎜List (list)🎜🎜🎜Introduction : Le type list (list) est utilisé pour stocker plusieurs chaînes ordonnées. Une liste peut stocker jusqu'à 2 ^ 32-1 éléments. 🎜🎜Exemples simples et pratiques :
lpush key value [value ...],lrange key start end🎜🎜Encodage interne : ziplist (liste compressée), linkedlist (liste chaînée )🎜 🎜Scénarios d'application : file d'attente de messages, liste d'articles, 🎜🎜🎜Comprendre l'insertion et le pop-up du type de liste dans une seule image : 🎜🎜🎜🎜lpush+lpop=Stack (stack) 🎜🎜lpush+rpop=Queue ( file d'attente) 🎜🎜lpsh+ltrim =Capped Collection (collection limitée)🎜🎜lpush+brpop=Message Queue (file d'attente des messages)🎜🎜🎜Set (set)🎜🎜sadd key element [element ...],smembers key🎜🎜Encodage interne :intset (integer set), hashtable (Hash table)🎜🎜🎜Remarque🎜 : smembers, lrange et hgetall sont des commandes relativement lourdes. S'il y a trop d'éléments et qu'il y a une possibilité de bloquer Redis, vous pouvez utiliser sscan pour le compléter. . 🎜🎜Scénarios d'application : tags utilisateur, génération de loterie à nombres aléatoires, besoins sociaux. 🎜🎜🎜Ensemble commandé (zset)🎜
- Introduction : Une collection triée de chaînes et d'éléments ne peuvent pas être répétés
- Exemple de format simple :
membre de partition clé zadd [membre de partition...],membre clé zrankzadd key score member [score member ...],zrank key member- 底层内部编码:
Encodage interne sous-jacent :ziplist(压缩列表)、skiplist(跳跃表)ziplist (liste compressée),skiplist (liste ignorée)- Scénarios d'application : classements, besoins sociaux (tels que les likes des utilisateurs).
2.2 Trois types de données spéciaux de Redis
3.
- Géo : Introduit par Redis 3.2, le positionnement géographique est utilisé pour stocker des informations de localisation géographique et opérer sur les informations stockées.
- HyperLogLog : une structure de données utilisée pour les algorithmes statistiques de cardinalité, tels que UV pour les sites Web statistiques.
- Bitmaps : utilisez un bit pour mapper l'état d'un élément. Dans Redis, sa couche inférieure est basée sur le type de chaîne. Vous pouvez transformer les bitmaps en un tableau avec des bits comme unité
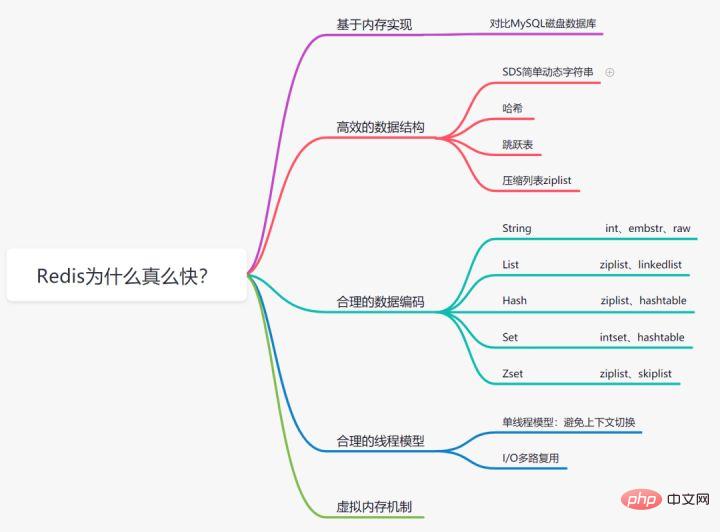
Pourquoi Redis est-il si rapide
3.1 Basé sur le stockage mémoire
Nous savons tous que la lecture et l'écriture en mémoire sont beaucoup plus rapides que le disque Redis est une base de données implémentée basée sur le stockage mémoire, par rapport à la base de données MySQL. où les données sont stockées sur le disque, économisant ainsi la consommation d'E/S du disque.3.2 Structure de données efficace
Nous savons que afin d'améliorer l'efficacité, l'index Mysql choisit la structure de données arborescente B+. En fait, une structure de données raisonnable peut rendre votre application/programme plus rapide. Jetons d'abord un coup d'œil à la structure des données et au diagramme d'encodage interne de Redis :Chaîne dynamique simple SDS
- Traitement de la longueur de chaîne : Redis obtient la longueur de la chaîne, la complexité temporelle est O(1) , et En langage C, il doit être parcouru depuis le début, et la complexité est O(n);
- Pré-allocation d'espace : plus la chaîne est modifiée fréquemment, plus l'allocation de mémoire sera fréquente, ce qui consomme des performances, et la modification SDS et l'expansion de l'espace nécessiteront une allocation supplémentaire d'espace inutilisé pour réduire la perte de performances.
- Libération d'espace paresseuse : lorsque SDS est raccourci, au lieu de recycler l'espace mémoire excédentaire, free enregistre l'espace excédentaire. S'il y a des modifications ultérieures, l'espace enregistré en free sera directement utilisé pour réduire l'allocation.
- Sécurité binaire : Redis peut stocker certaines données binaires, chaînes rencontrées en langage C'
- E/S : E/S réseau
- Multiple : plusieurs connexions réseau
- Multiplexage : réutilisation du même fil.
- Le multiplexage IO est en fait un modèle IO synchrone, qui implémente un thread capable de surveiller plusieurs descripteurs de fichiers ; une fois qu'un descripteur de fichier est prêt, il peut demander à l'application d'effectuer les opérations de lecture et d'écriture correspondantes sans descripteur de fichier. Lorsqu'il est prêt, le multiplexage IO est en fait un modèle IO synchrone, qui implémente un thread capable de surveiller plusieurs descripteurs de fichiers ; une fois qu'un descripteur de fichier est prêt, il peut demander à l'application d'effectuer les opérations de lecture et d'écriture correspondantes sans descripteur de fichier. l'application sera bloquée et le CPU sera remis.
Modèle monothread
- Redis est un modèle monothread, et le monothreading évite les changements inutiles de contexte CPU et la consommation de verrouillage de concurrence. Précisément parce qu'il s'agit d'un seul thread, si une certaine commande est exécutée trop longtemps (comme la commande hgetall), cela provoquera un blocage. Redis est une base de données pour des scénarios d'exécution rapide. , les commandes telles que smembers, lrange, hgetall, etc. doivent donc être utilisées avec prudence.
- Redis 6.0 introduit le multithreading pour accélérer, et son exécution de commandes et d'opérations de mémoire est toujours un seul thread.
3.5 Mécanisme de mémoire virtuelle
Redis construit directement le mécanisme VM par lui-même. Il n'appelle pas les fonctions système comme les systèmes ordinaires et perd un certain temps en déplacements et en requêtes.
Quel est le mécanisme de mémoire virtuelle de Redis ?
Le mécanisme de mémoire virtuelle échange temporairement les données rarement consultées (données froides) de la mémoire vers le disque, libérant ainsi un espace mémoire précieux pour d'autres données auxquelles il faut accéder (données chaudes). La fonction VM peut réaliser la séparation des données chaudes et froides, de sorte que les données chaudes soient toujours dans la mémoire et que les données froides soient enregistrées sur le disque. Cela peut éviter le problème de vitesse d'accès lente causée par une mémoire insuffisante.
4. Qu'est-ce que la panne de cache, la pénétration du cache, l'avalanche de cache ?
4.1 Problème de pénétration du cache
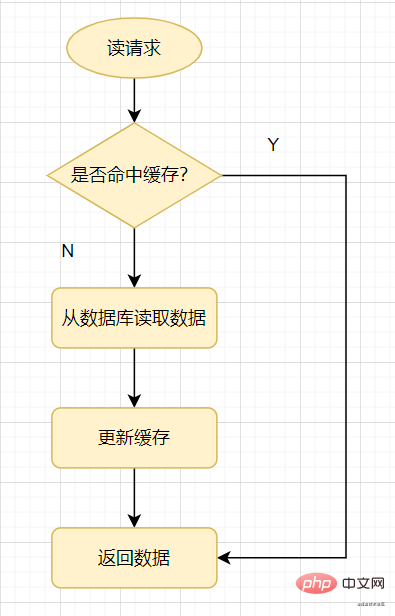
Examinons d'abord une manière courante d'utiliser le cache : lorsqu'une demande de lecture arrive, vérifiez d'abord le cache si le cache atteint une valeur, il reviendra directement si le cache ne le fait pas. appuyez, vérifiez la base de données, puis mettez à jour la valeur de la base de données dans le cache et revenez.
Lire le cache
Pénétration du cache : fait référence à l'interrogation d'une donnée qui n'existe certainement pas. Puisque le cache n'est pas atteint, il doit être interrogé à partir de la base de données. Si les données ne peuvent pas être trouvées, elles le seront. ne pas être écrit dans le cache, ce qui conduira à cela. Les données qui n'existent pas doivent être interrogées dans la base de données à chaque fois qu'une requête est faite, ce qui exerce une pression sur la base de données.
Pour faire simple, lors de l'accès à une requête de lecture, ni le cache ni la base de données n'ont une certaine valeur, ce qui entraînera la pénétration de chaque requête pour cette valeur dans la base de données.
La pénétration du cache est généralement causée par les situations suivantes :
- Conception commerciale déraisonnable, par exemple, la plupart des utilisateurs n'ont pas de garde activé, mais chaque demande que vous faites va au cache et interroge un certain identifiant utilisateur. voir s'il y a une protection.
- Erreurs commerciales/d'exploitation et de maintenance/développement, telles que la suppression accidentelle des données du cache et de la base de données.
- Attaque de demandes illégales par des pirates, par exemple, les pirates informatiques fabriquent délibérément un grand nombre de demandes illégales pour lire des données commerciales inexistantes.
Comment éviter la pénétration du cache ? Généralement, il existe trois méthodes.
- 1. S'il s'agit d'une demande illégale, nous vérifierons les paramètres à l'entrée de l'API et filtrerons les valeurs illégales.
- 2. Si la base de données de requêtes est vide, nous pouvons définir une valeur nulle ou une valeur par défaut pour le cache. Cependant, si une demande d'écriture arrive, le cache doit être mis à jour pour garantir la cohérence du cache. Dans le même temps, le délai d'expiration approprié est finalement défini pour le cache. (Couramment utilisé en entreprise, simple et efficace)
- 3. Utilisez le filtre Bloom pour déterminer rapidement si les données existent. Autrement dit, lorsqu'une requête de requête arrive, elle juge d'abord si la valeur existe via le filtre Bloom, puis continue de vérifier si elle existe.
Principe du filtre Bloom : Il se compose d'un tableau bitmap avec une valeur initiale de 0 et de N fonctions de hachage. Effectuez N algorithmes de hachage sur une clé pour obtenir N valeurs. Hachez ces N valeurs dans le tableau de bits et définissez-les sur 1. Puis lors de la vérification, si ces positions spécifiques sont toutes à 1, alors filtrage Bloom Le serveur détermine que la clé existe. .
4.2 Problème de snowrun du cache
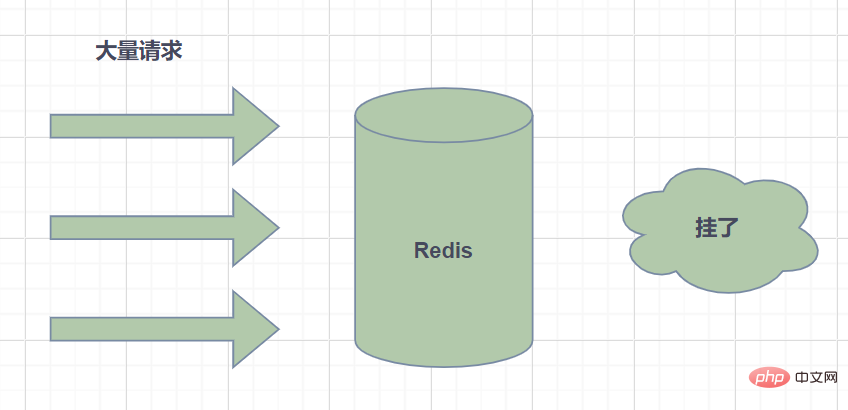
Cache snowrun : fait référence au délai d'expiration d'une grande quantité de données dans le cache, et les données de requête sont énormes, et les requêtes accèdent directement à la base de données, provoquant une pression excessive sur la base de données et même les temps d'arrêt.
- Les chutes de neige dans le cache sont généralement causées par l'expiration d'une grande quantité de données en même temps. Pour cette raison, elles peuvent être résolues en définissant le délai d'expiration de manière uniforme, c'est-à-dire en rendant le délai d'expiration relativement discret. Si vous utilisez une valeur fixe plus grande + une valeur aléatoire plus petite, 5 heures + 0 à 1800 secondes.
- Un échec de Redis peut également provoquer des chutes de neige dans le cache. Cela nécessite la construction d'un cluster haute disponibilité Redis.
4.3 Problème de panne de cache
Panne de cache : fait référence au moment où la clé du hotspot expire à un certain moment, et il y a un grand nombre de demandes simultanées pour cette clé à ce moment-là, ce qui entraîne un grand nombre de requêtes Hit db.
La panne du cache semble un peu similaire. En fait, la différence entre eux est que le crash du cache signifie que la base de données est soumise à une pression excessive, voire en panne, et qu'elle est simplement due à un grand nombre de requêtes simultanées au niveau de la base de données. On peut considérer que la panne est un sous-ensemble du cache snowrun. Certains articles estiment que la différence entre les deux réside dans le fait que la panne vise un certain cache de touches de raccourci, tandis que Xuebeng cible de nombreuses clés.
Il existe deux solutions :
- 1. Utilisez le schéma de verrouillage mutex. Lorsque le cache échoue, au lieu de charger immédiatement les données de la base de données, vous utilisez d'abord certaines commandes d'opération atomiques avec un retour réussi, telles que (setnx de Redis) pour fonctionner. En cas de succès, chargez les données de la base de données et configurez le cache. Sinon, essayez à nouveau de récupérer le cache.
- 2. "N'expire jamais" signifie qu'aucun délai d'expiration n'est défini, mais lorsque les données du point d'accès sont sur le point d'expirer, le thread asynchrone se met à jour et définit le délai d'expiration.
5. Quel est le problème de touche de raccourci et comment résoudre le problème de touche de raccourci
Qu'est-ce que la touche de raccourci ? Dans Redis, nous appelons les clés à fréquence d'accès élevée des clés de point d'accès.
Si une demande pour une certaine clé de hotspot est envoyée à l'hôte du serveur, en raison d'un volume de requêtes particulièrement important, cela peut entraîner des ressources hôte insuffisantes ou même des temps d'arrêt, affectant ainsi les services normaux.
Et comment la clé de hotspot est-elle générée ? Il y a deux raisons principales :
- Les données consommées par les utilisateurs sont bien supérieures aux données produites, comme les ventes flash, les actualités brûlantes et d'autres scénarios où il y a plus de lecture et moins d'écriture.
- Le partage des demandes est concentré, ce qui dépasse les performances d'un seul serveur Redi. Par exemple, si la clé de nom fixe et le hachage tombent sur le même serveur, la quantité d'accès instantané sera énorme, dépassant le goulot d'étranglement de la machine et provoquant des surchauffes. problèmes clés.
Alors, comment identifier les raccourcis clavier dans le développement quotidien ?
- Déterminez quelles touches de raccourci sont basées sur l'expérience ;
- Rapport de statistiques sur les clients
- Rapport à la couche d'agent de service
Comment résoudre le problème de touche de raccourci ?
- Extension du cluster Redis : ajoutez des copies de fragments pour équilibrer le trafic de lecture ;
- distribuez les touches de raccourci à différents serveurs ;
- utilisez le cache de deuxième niveau, c'est-à-dire le cache local JVM, pour réduire les demandes de lecture Redis.
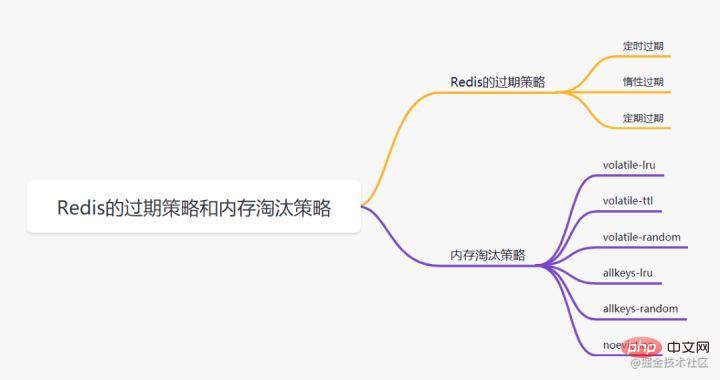
6. Stratégie d'expiration Redis et stratégie d'élimination de la mémoire
6.1 Stratégie d'expiration Redis
Nous sommes là
set key的时候,可以给它设置一个过期时间,比如expire key 60. Spécifiez que cette clé expirera après 60 secondes. Comment Redis la gérera-t-il après 60 secondes ? Introduisons d'abord plusieurs stratégies d'expiration :Expiration programmée
Chaque clé avec un délai d'expiration doit créer une minuterie, et la clé sera effacée immédiatement lorsque le délai d'expiration est atteint. Cette stratégie peut immédiatement effacer les données expirées et est très économe en mémoire ; cependant, elle occupera une grande quantité de ressources CPU pour traiter les données expirées, affectant ainsi le temps de réponse et le débit du cache.
Expiration paresseuse
Seulement lors de l'accès à une clé, il sera jugé si la clé a expiré, et elle sera effacée si elle expire. Cette stratégie peut économiser au maximum les ressources du processeur, mais elle est très peu respectueuse de la mémoire. Dans des cas extrêmes, un grand nombre de clés expirées ne seront plus accessibles, ne seront donc pas effacées et occuperont une grande quantité de mémoire.
Expiration périodique
À chaque fois, un certain nombre de clés dans le dictionnaire d'expiration d'un certain nombre de bases de données seront analysées et les clés expirées seront effacées. Cette stratégie est un compromis entre les deux premières. En ajustant l'intervalle de temps des analyses planifiées et la consommation de temps limitée de chaque analyse, l'équilibre optimal entre les ressources CPU et mémoire peut être atteint dans différentes circonstances.
Le dictionnaire expire enregistrera les données d'heure d'expiration de toutes les clés avec une heure d'expiration définie, où clé est un pointeur vers une clé dans l'espace clé et valeur est l'heure d'expiration représentée par l'horodatage UNIX de la clé avec une précision de la milliseconde. L'espace clé fait référence à toutes les clés enregistrées dans le cluster Redis.
Redis utilise à la fois l'expiration paresseuse et l'expiration périodiquedeux stratégies d'expiration.
- 假设Redis当前存放30万个key,并且都设置了过期时间,如果你每隔100ms就去检查这全部的key,CPU负载会特别高,最后可能会挂掉。
- 因此,redis采取的是定期过期,每隔100ms就随机抽取一定数量的key来检查和删除的。
- 但是呢,最后可能会有很多已经过期的key没被删除。这时候,redis采用惰性删除。在你获取某个key的时候,redis会检查一下,这个key如果设置了过期时间并且已经过期了,此时就会删除。
但是呀,如果定期删除漏掉了很多过期的key,然后也没走惰性删除。就会有很多过期key积在内存内存,直接会导致内存爆的。或者有些时候,业务量大起来了,redis的key被大量使用,内存直接不够了,运维小哥哥也忘记加大内存了。难道redis直接这样挂掉?不会的!Redis用8种内存淘汰策略保护自己~
6.2 Redis 内存淘汰策略
- volatile-lru:当内存不足以容纳新写入数据时,从设置了过期时间的key中使用LRU(最近最少使用)算法进行淘汰;
- allkeys-lru:当内存不足以容纳新写入数据时,从所有key中使用LRU(最近最少使用)算法进行淘汰。
- volatile-lfu:4.0版本新增,当内存不足以容纳新写入数据时,在过期的key中,使用LFU算法进行删除key。
- allkeys-lfu:4.0版本新增,当内存不足以容纳新写入数据时,从所有key中使用LFU算法进行淘汰;
- volatile-random:当内存不足以容纳新写入数据时,从设置了过期时间的key中,随机淘汰数据;。
- allkeys-random:当内存不足以容纳新写入数据时,从所有key中随机淘汰数据。
- volatile-ttl:当内存不足以容纳新写入数据时,在设置了过期时间的key中,根据过期时间进行淘汰,越早过期的优先被淘汰;
- noeviction:默认策略,当内存不足以容纳新写入数据时,新写入操作会报错。
7.说说Redis的常用应用场景
- 缓存
- 排行榜
- 计数器应用
- 共享Session
- 分布式锁
- 社交网络
- 消息队列
- 位操作
7.1 缓存
我们一提到redis,自然而然就想到缓存,国内外中大型的网站都离不开缓存。合理的利用缓存,比如缓存热点数据,不仅可以提升网站的访问速度,还可以降低数据库DB的压力。并且,Redis相比于memcached,还提供了丰富的数据结构,并且提供RDB和AOF等持久化机制,强的一批。
7.2 排行榜
当今互联网应用,有各种各样的排行榜,如电商网站的月度销量排行榜、社交APP的礼物排行榜、小程序的投票排行榜等等。Redis提供的
zset数据类型能够实现这些复杂的排行榜。比如,用户每天上传视频,获得点赞的排行榜可以这样设计:
- 1.用户Jay上传一个视频,获得6个赞,可以酱紫:
zadd user:ranking:2021-03-03 Jay 3
- 2.过了一段时间,再获得一个赞,可以这样:
zincrby user:ranking:2021-03-03 Jay 1
- 3.如果某个用户John作弊,需要删除该用户:
zrem user:ranking:2021-03-03 John
- 4.展示获取赞数最多的3个用户
zrevrangebyrank user:ranking:2021-03-03 0 27.3 计数器应用
各大网站、APP应用经常需要计数器的功能,如短视频的播放数、电商网站的浏览数。这些播放数、浏览数一般要求实时的,每一次播放和浏览都要做加1的操作,如果并发量很大对于传统关系型数据的性能是一种挑战。Redis天然支持计数功能而且计数的性能也非常好,可以说是计数器系统的重要选择。
7.4 共享Session
如果一个分布式Web服务将用户的Session信息保存在各自服务器,用户刷新一次可能就需要重新登录了,这样显然有问题。实际上,可以使用Redis将用户的Session进行集中管理,每次用户更新或者查询登录信息都直接从Redis中集中获取。
7.5 分布式锁
几乎每个互联网公司中都使用了分布式部署,分布式服务下,就会遇到对同一个资源的并发访问的技术难题,如秒杀、下单减库存等场景。
- L'utilisation du verrouillage local synchronisé ou réentrant ne fonctionnera certainement pas.
- Si le degré de concurrence n'est pas important, il n'y a aucun problème à utiliser le verrouillage pessimiste et le verrouillage optimiste de la base de données.
- Cependant, dans les situations de forte concurrence, l'utilisation de verrous de base de données pour contrôler l'accès simultané aux ressources affectera les performances de la base de données.
- En fait, setnx de Redis peut être utilisé pour implémenter des verrous distribués.
7.6 Réseau social
Les likes/dislikes, les fans, les amis/likes communs, le push, l'actualisation du menu déroulant, etc. sont des fonctions essentielles des sites de réseaux sociaux puisque le nombre de visites sur les sites de réseaux sociaux est généralement relativement. les données relationnelles volumineuses et traditionnelles ne peuvent pas être très appropriées pour sauvegarder ce type de données, et la structure de données fournie par Redis peut réaliser ces fonctions relativement facilement.
7.7 Message Queue
La file d'attente de messages est un middleware nécessaire pour les grands sites Web, tels que ActiveMQ, RabbitMQ, Kafka et d'autres middlewares de file d'attente de messages populaires. Elle est principalement utilisée pour le découplage commercial, l'écrêtage des pics de trafic et le traitement asynchrone des faibles valeurs réelles. -temps affaires. Redis fournit des fonctions de publication/abonnement et de file d'attente de blocage, qui peuvent implémenter un système de file d'attente de messages simple. De plus, cela n’est pas comparable à un middleware de messagerie professionnel.
Le fonctionnement 7,8 bits
est utilisé dans des scénarios avec des centaines de millions de données, tels que les enregistrements système pour des centaines de millions d'utilisateurs, les statistiques sur le nombre de connexions sans doublons, si un utilisateur est en ligne, etc. . Tencent compte 1 milliard d'utilisateurs. Comment vérifier si un utilisateur est en ligne en quelques millisecondes ? Ne dites jamais de créer une clé pour chaque utilisateur, puis de l'enregistrer une par une (vous pouvez calculer la mémoire requise, ce qui sera très effrayant, et il existe de nombreuses exigences similaires. Des opérations appropriées doivent être utilisées ici - utilisez le setbit, getbit, et les commandes bitcount. Le principe est : construire un tableau suffisamment long dans redis, chaque élément du tableau ne peut avoir que deux valeurs 0 et 1, puis l'indice d'indice de ce tableau est utilisé pour représenter l'ID utilisateur (doit être un nombre), alors évidemment, ce Un grand tableau de centaines de millions de long peut construire un système de mémoire via des indices et des valeurs d'éléments (0 et 1)
8 Quels sont les avantages et les inconvénients de Redis ? est basé sur la mémoire. Étant donné que la base de données non relationnelle K-V est basée sur la mémoire, si le serveur Redis raccroche, les données seront perdues. Afin d'éviter la perte de données, Redis fournit la persistance
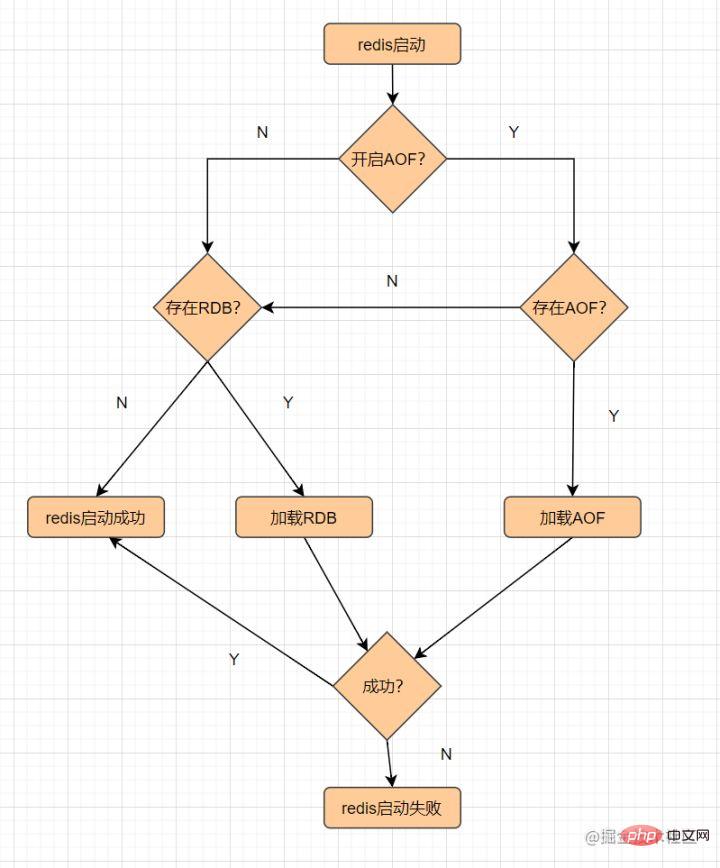
, ce qui signifie enregistrer les données sur le disque. . Il existe deux mécanismes de persistance :RDB et AOF Le processus de chargement des fichiers persistants est le suivant :
8.1 RDB
RDB, qui enregistre les données de la mémoire sur le disque sous la forme d'un fichier. instantané.
Qu'est-ce qu'un instantané ? Vous pouvez le comprendre de cette façon, prendre une photo des données au moment actuel, puis la sauvegarder
La persistance RDB fait référence à l'exécution d'un nombre spécifié d'opérations d'écriture dans un délai spécifié. intervalle de temps pour enregistrer les données dans la mémoire. L'instantané de l'ensemble de données est écrit sur le disque, ce qui est la méthode de persistance par défaut de Redis. Une fois l'opération terminée, un fichiersera généré dans le répertoire spécifié pour restaurer les données. Les principaux mécanismes de déclenchement de RDB sont les suivants :Avantages de RDB
dump.rdb文件,Redis 重启的时候,通过加载dump.rdb
Convient aux scénarios de récupération de données à grande échelle, tels que la sauvegarde, la réplication complète, etc.
Inconvénients de RDB
Il ne peut pas atteindre la persistance en temps réel/persistence de deuxième niveau Des versions nouvelles et anciennes existent. Des problèmes de compatibilité avec le format RDB
- AOF
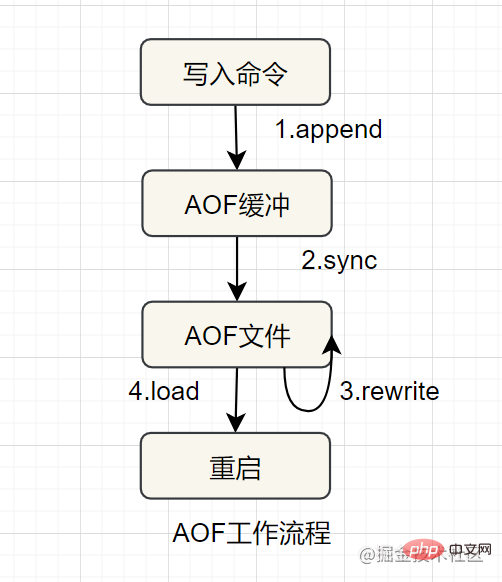
AOF (ajouter uniquement un fichier) Persistance, utilisation du formulaire de journal pour enregistrer chaque écriture. opération, ajouter au fichier et réexécuter la commande dans le fichier AOF lors du redémarrage Restaurer les données Cela résout principalement le problème en temps réel de la persistance des données. Le flux de travail d'AOF est le suivant :
Les avantages. d'AOF sont plus cohérents et intègres
Plus le fichier est volumineux, plus la récupération des données est lente
Mode maître-esclave, mode sentinelle et mode cluster
- 9. dans le projet. Il ne s'agira certainement pas d'un déploiement en un seul point du service Redis. Une fois le déploiement en un seul point arrêté, il n'est plus disponible. Afin d'obtenir une haute disponibilité, la pratique courante consiste à copier plusieurs copies de. la base de données et les déployer sur différents serveurs. Même si une machine est en panne, elle peut continuer à fournir des services. Il existe trois modes de déploiement pour Redis pour atteindre une haute disponibilité :
. 9.1 Mode maître-esclave
- En mode maître-esclave, Redis déploie plusieurs Chaque machine possède un nœud maître, qui est responsable des opérations de lecture et d'écriture, et un nœud esclave, qui est uniquement responsable des opérations de lecture. Les données du nœud esclave proviennent du nœud maître, et le principe de mise en œuvre est le
mécanisme de réplication maître-esclaveLa réplication maître-esclave comprend la réplication complète et la réplication incrémentielle. Généralement, lorsque l'esclave commence à se connecter au maître pour la première fois, ou lorsque l'on considère que c'est la première fois qu'il se connecte, la copie complète est utilisée. Le processus de copie complète est le suivant :
- 1. . L'esclave envoie une commande de synchronisation au maître.
- 2. Après avoir reçu la commande SYNC, le maître exécute la commande bgsave pour générer le fichier RDB complet.
- 3. Le maître utilise un tampon pour enregistrer toutes les commandes d'écriture lors de la génération d'instantanés RDB.
- 4. Une fois que le maître a exécuté bgsave, il envoie des fichiers d'instantanés RDB à tous les esclaves.
- 5. Après avoir reçu le fichier d'instantané RDB, l'esclave charge et analyse l'instantané reçu.
- 6. Le maître utilise un tampon pour enregistrer toutes les commandes écrites générées lors de la synchronisation RDB.
- 7. Une fois l'instantané maître envoyé, il commence à envoyer la commande d'écriture dans le tampon à l'esclave ;
- 8.salve accepte la demande de commande et exécute la commande d'écriture à partir du tampon maître
Après le redis2.8. version, il a été utilisé psync pour remplacer sync, car la commande sync consomme des ressources système et psync est plus efficace.
Une fois l'esclave entièrement synchronisé avec le maître, si les données sur le maître sont à nouveau mises à jour, la réplication incrémentielle sera déclenchée.
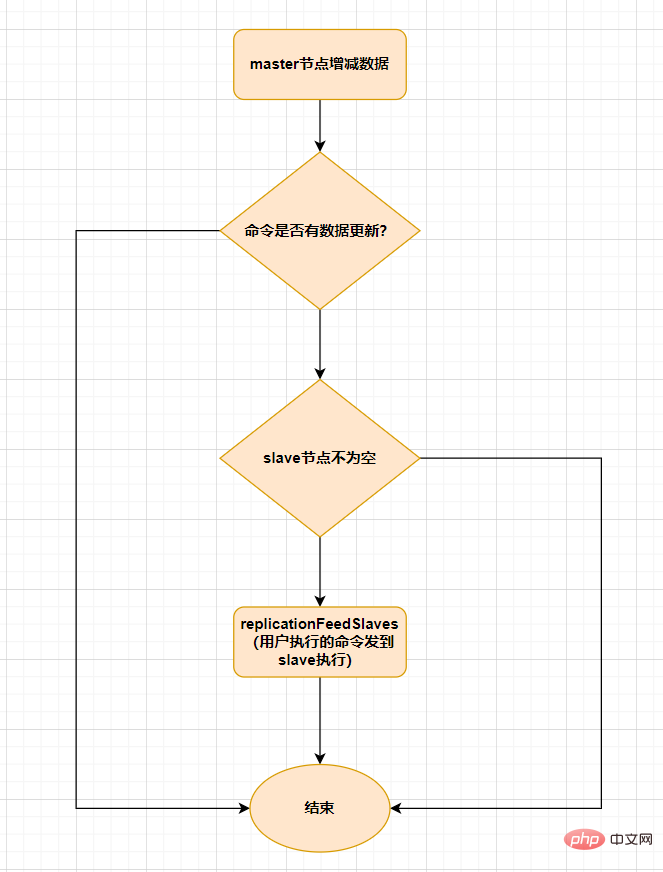
Lorsque les données augmentent ou diminuent sur le nœud maître,
replicationFeedSalves()函数,接下来在 Master节点上调用的每一个命令会使用replicationFeedSlaves()sera déclenché pour se synchroniser avec le nœud esclave. Avant d'exécuter cette fonction, le nœud maître déterminera si la commande exécutée par l'utilisateur a des mises à jour des données. S'il y a une mise à jour des données et que le nœud esclave n'est pas vide, cette fonction sera exécutée. La fonction de cette fonction est : Envoyer la commande exécutée par l'utilisateur à tous les nœuds esclaves, et laisser le nœud esclave l'exécuter. Le processus est le suivant :
9.2 Mode Sentinelle
En mode maître-esclave, une fois que le nœud maître ne peut pas fournir de services en raison d'une panne, il est nécessaire de promouvoir manuellement le nœud esclave en nœud maître, et en même temps, informez l'application de mettre à jour l'adresse du nœud maître. De toute évidence, cette méthode de gestion des pannes est inacceptable dans la plupart des scénarios commerciaux. Redis fournit officiellement l'architecture Redis Sentinel (Sentinel) à partir de la version 2.8 pour résoudre ce problème.
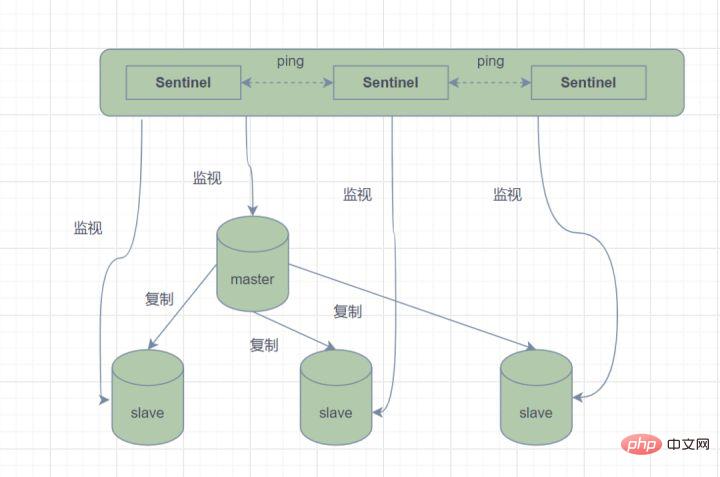
Mode Sentinel, un système Sentinel composé d'une ou plusieurs instances Sentinel, qui peut surveiller tous les nœuds maîtres et esclaves Redis, et lorsque le nœud maître surveillé entre dans l'état hors ligne, supprime automatiquement le maître hors ligne Un nœud esclave sous le serveur est mis à niveau vers un nouveau nœud maître. Cependant, si un processus sentinelle surveille un nœud Redis, des problèmes peuvent survenir (Problème à point unique). Par conséquent, plusieurs sentinelles peuvent être utilisées pour surveiller les nœuds Redis, et chaque sentinelle se surveillera également mutuellement.
Mode Sentinelle
En termes simples, le mode Sentinelle a trois fonctions :
- Envoyer des commandes et attendre que le serveur Redis (y compris le serveur maître et le serveur esclave) revienne pour surveiller son état de fonctionnement ;
- Surveillance Sentinel ; le maître Si un nœud tombe en panne, il passera automatiquement du nœud esclave au nœud maître, puis avertira les autres nœuds esclaves via le mode de publication et d'abonnement, modifiera le fichier de configuration et les laissera changer d'hôte
- Les sentinelles le feront ; se surveillent également mutuellement pour atteindre une haute disponibilité.
Quel est le processus de basculement ?
Supposons que le serveur principal soit en panne et que Sentinel 1 détecte ce résultat en premier. Le système n'effectuera pas immédiatement le processus de basculement. le serveur principal est indisponible, ce phénomène devient subjectif hors ligne. Lorsque les sentinelles suivantes détectent également que le serveur principal est indisponible et que le nombre atteint une certaine valeur, un vote aura lieu entre les sentinelles. Le résultat du vote sera initié par une sentinelle pour effectuer une opération de basculement. Une fois le changement réussi, chaque sentinelle utilisera le mode publication-abonnement pour basculer le serveur esclave qu'elle surveille vers l'hôte. Ce processus est appelé objectif hors ligne. De cette façon, tout est transparent pour le client.
Le mode de fonctionnement de Sentinel est le suivant :
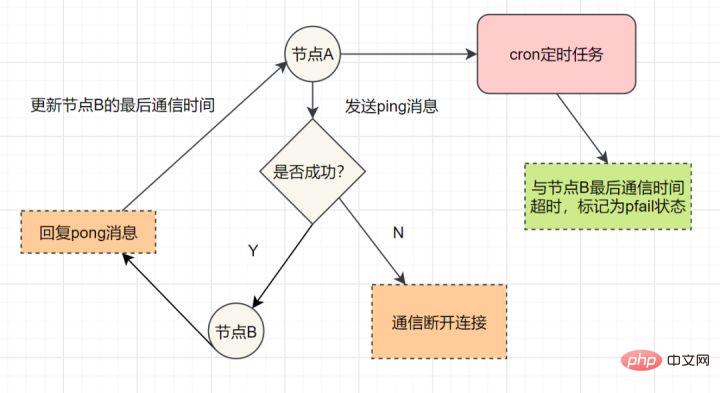
Chaque Sentinel envoie une commande PING au maître, à l'esclave et aux autres instances Sentinel qu'il connaît une fois par seconde.
Si le temps écoulé depuis la dernière réponse valide à la commande PING dépasse la valeur spécifiée par l'option down-after-milliseconds, l'instance sera marquée comme subjectivement hors ligne par Sentinel.
Si un Maître est marqué comme subjectif hors ligne, toutes les Sentinelles qui surveillent ce Maître doivent confirmer une fois par seconde que le Maître est effectivement entré dans l'état subjectif hors ligne.
Lorsqu'un nombre suffisant de Sentinelles (supérieur ou égal à la valeur spécifiée dans le fichier de configuration) confirment que le Maître est effectivement entré dans un état subjectif hors ligne dans la plage de temps spécifiée, le Maître sera marqué comme objectivement hors ligne.
Dans des circonstances normales, chaque Sentinelle enverra des commandes INFO à tous les maîtres et esclaves qu'elle connaît une fois toutes les 10 secondes.
Lorsque le maître est marqué comme objectivement hors ligne par Sentinel, la fréquence à laquelle Sentinel envoie des commandes INFO à tous les esclaves du maître hors ligne passera d'une fois toutes les 10 secondes à une fois toutes les secondes
S'il n'y en a pas assez Sentinelles doivent accepter Si le maître est hors ligne, le statut hors ligne objectif du maître sera supprimé ; si le maître renvoie à nouveau une réponse valide à la commande PING de Sentinel, le statut hors ligne subjectif du maître sera supprimé.
9.3 Mode cluster cluster
Le mode Sentinelle est basé sur le mode maître-esclave, qui réalise la séparation de la lecture et de l'écriture. Il peut également basculer automatiquement et la disponibilité du système est plus élevée. Cependant, les données stockées dans chaque nœud sont les mêmes, ce qui gaspille de la mémoire et n'est pas facile à développer en ligne. Par conséquent, le cluster Cluster a vu le jour. Il a été ajouté dans Redis 3.0 et a implémenté le stockage distribué de Redis. Segmentez les données, ce qui signifie stocker différents contenus sur chaque nœud Redis pour résoudre le problème de l'expansion en ligne. De plus, il offre également des capacités de réplication et de basculement.
Communication des nœuds du cluster
Un cluster Redis se compose de plusieurs nœuds Comment chaque nœud communique-t-il entre eux ? Grâce au Protocole Gossip !
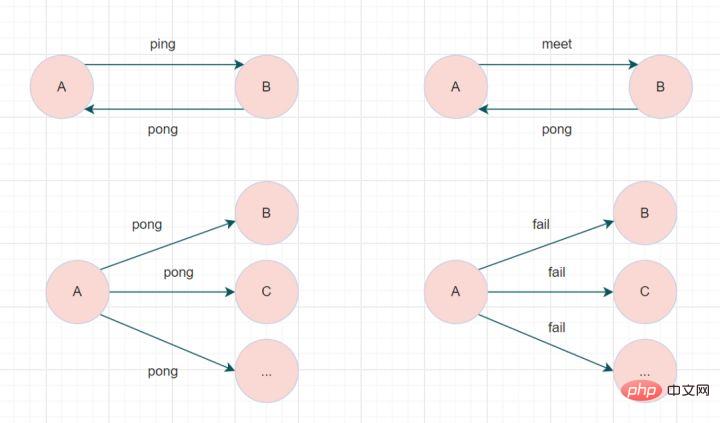
Le cluster Redis Cluster communique via le protocole Gossip. Les nœuds échangent en permanence des informations, notamment les pannes de nœud, l'adhésion de nouveaux nœuds, les informations de changement de nœud maître-esclave, les informations d'emplacement, etc. Les messages de potins couramment utilisés sont divisés en quatre types : ping, pong, rencontre et échec.
- message de rencontre : notifiez les nouveaux nœuds à rejoindre. L'expéditeur du message informe le destinataire de rejoindre le cluster actuel. Une fois la communication du message de rencontre terminée normalement, le nœud de réception rejoindra le cluster et effectuera des échanges périodiques de messages ping et pong.
- Message Ping : message le plus fréquemment échangé dans le cluster. Chaque nœud du cluster envoie des messages ping à plusieurs autres nœuds chaque seconde, qui sont utilisés pour détecter si les nœuds sont en ligne et échanger des informations d'état entre eux.
- message pong : lors de la réception d'un message ping ou d'une rencontre, il répondra à l'expéditeur sous forme de message de réponse pour confirmer la communication normale du message. Le message pong encapsule en interne ses propres données d'état. Un nœud peut également diffuser son propre message pong au cluster pour demander à l'ensemble du cluster de mettre à jour son statut.
- Message d'échec : lorsqu'un nœud détermine qu'un autre nœud du cluster est hors ligne, il diffusera un message d'échec au cluster. Après avoir reçu le message d'échec, les autres nœuds mettront à jour le nœud correspondant vers l'état hors ligne.
Spécialement, chaque nœud communique avec d'autres nœuds via le bus cluster. Lors de la communication, utilisez un numéro de port spécial, c'est-à-dire le numéro de port du service externe plus 10 000. Par exemple, si le numéro de port d'un nœud est 6379, alors le numéro de port qu'il utilise pour communiquer avec d'autres nœuds est 16379. La communication entre les nœuds utilise un protocole binaire spécial.
Algorithme Hash Slot
Puisqu'il s'agit d'un stockage distribué, l'algorithme distribué utilisé par le cluster Cluster est Consistent Hash ? Non, c'est l'algorithme Hash Slot.
Algorithme de slotL'ensemble de la base de données est divisé en 16384 slots (slots). Chaque paire clé-valeur entrant dans Redis est hachée en fonction de la clé et attribuée à l'un de ces 16384 slots. La carte de hachage utilisée est également relativement simple. Elle utilise l'algorithme CRC16 pour calculer une valeur de 16 bits, puis modulo 16384. Chaque clé de la base de données appartient à l'un de ces 16 384 emplacements, et chaque nœud du cluster peut gérer ces 16 384 emplacements.
Chaque nœud du cluster est responsable d'une partie des emplacements de hachage. Par exemple, le cluster actuel a les nœuds A, B et C, et le nombre d'emplacements de hachage sur chaque nœud = 16384/3, alors il y a :
- Le nœud A est responsable des emplacements de hachage 0 ~ 5460
- Le nœud B est responsable des emplacements de hachage 5461 ~ 10922
- Le nœud C est responsable des emplacements de hachage 10923 ~ 16383
Cluster Redis Cluster
Dans le cluster Redis Cluster, il faut s'assurer que 16384 emplacements correspondent. Tous les nœuds fonctionnent normalement. Si un nœud tombe en panne, l'emplacement dont il est responsable deviendra également invalide et l'ensemble du cluster ne fonctionnera pas.
Ainsi, afin d'assurer une haute disponibilité, le cluster Cluster introduit la réplication maître-esclave, et un nœud maître correspond à un ou plusieurs nœuds esclaves. Lorsque d'autres nœuds maîtres envoient une requête ping à un nœud maître A, si plus de la moitié des nœuds maîtres communiquent avec A expirent, alors le nœud maître A est considéré comme étant en panne. Si le nœud maître tombe en panne, le nœud esclave sera activé.
Sur chaque nœud de Redis, il y a deux choses, l'une est l'emplacement, sa plage de valeurs est de 0 à 16383. L'autre est le cluster, qui peut être compris comme un plug-in de gestion de cluster. Lorsque la clé à laquelle nous accédons arrive, Redis obtiendra une valeur de 16 bits basée sur l'algorithme CRC16, puis prendra le résultat modulo 16384. Chaque clé dans Jiangzi correspond à un emplacement de hachage numéroté entre 0 et 16383. Utilisez cette valeur pour trouver le nœud correspondant à l'emplacement correspondant, puis passez automatiquement au nœud correspondant pour les opérations d'accès.
虽然数据是分开存储在不同节点上的,但是对客户端来说,整个集群Cluster,被看做一个整体。客户端端连接任意一个node,看起来跟操作单实例的Redis一样。当客户端操作的key没有被分配到正确的node节点时,Redis会返回转向指令,最后指向正确的node,这就有点像浏览器页面的302 重定向跳转。
故障转移
Redis集群实现了高可用,当集群内节点出现故障时,通过故障转移,以保证集群正常对外提供服务。
redis集群通过ping/pong消息,实现故障发现。这个环境包括主观下线和客观下线。
主观下线: 某个节点认为另一个节点不可用,即下线状态,这个状态并不是最终的故障判定,只能代表一个节点的意见,可能存在误判情况。
主观下线
客观下线: 指标记一个节点真正的下线,集群内多个节点都认为该节点不可用,从而达成共识的结果。如果是持有槽的主节点故障,需要为该节点进行故障转移。
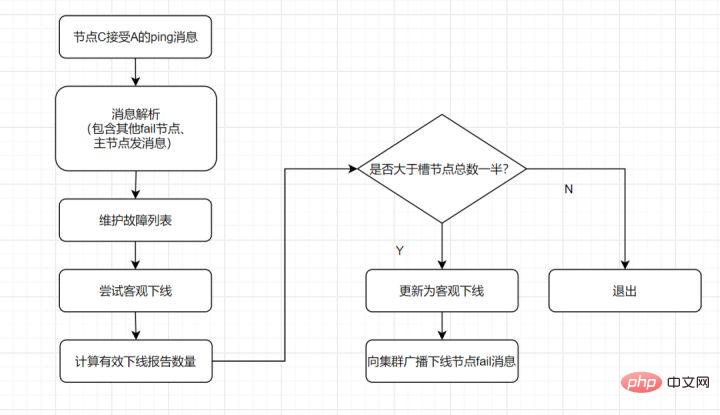
- 假如节点A标记节点B为主观下线,一段时间后,节点A通过消息把节点B的状态发到其它节点,当节点C接受到消息并解析出消息体时,如果发现节点B的pfail状态时,会触发客观下线流程;
- 当下线为主节点时,此时Redis Cluster集群为统计持有槽的主节点投票,看投票数是否达到一半,当下线报告统计数大于一半时,被标记为客观下线状态。
流程如下:
客观下线
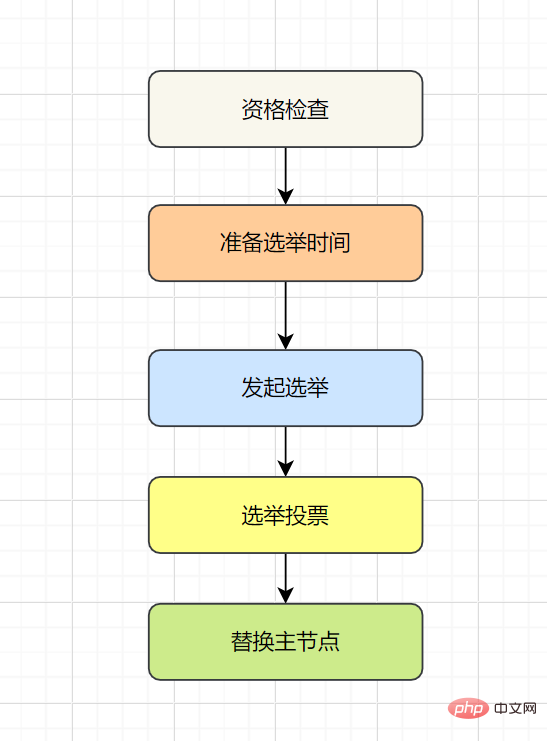
故障恢复:故障发现后,如果下线节点的是主节点,则需要在它的从节点中选一个替换它,以保证集群的高可用。流程如下:
- 资格检查:检查从节点是否具备替换故障主节点的条件。
- 准备选举时间:资格检查通过后,更新触发故障选举时间。
- 发起选举:到了故障选举时间,进行选举。
- 选举投票:只有持有槽的主节点才有票,从节点收集到足够的选票(大于一半),触发替换主节点操作
10. 使用过Redis分布式锁嘛?有哪些注意点呢?
分布式锁,是控制分布式系统不同进程共同访问共享资源的一种锁的实现。秒杀下单、抢红包等等业务场景,都需要用到分布式锁,我们项目中经常使用Redis作为分布式锁。
选了Redis分布式锁的几种实现方法,大家来讨论下,看有没有啥问题哈。
- 命令setnx + expire分开写
- setnx + value值是过期时间
- set的扩展命令(set ex px nx)
- set ex px nx + 校验唯一随机值,再删除
10.1 命令setnx + expire分开写
if(jedis.setnx(key,lock_value) == 1){ //加锁 expire(key,100); //设置过期时间 try { do something //业务请求 }catch(){ } finally { jedis.del(key); //释放锁 } }如果执行完
setnx加锁,正要执行expire设置过期时间时,进程crash掉或者要重启维护了,那这个锁就“长生不老”了,别的线程永远获取不到锁啦,所以分布式锁不能这么实现。10.2 setnx + value值是过期时间
long expires = System.currentTimeMillis() + expireTime; //系统时间+设置的过期时间 String expiresStr = String.valueOf(expires); // 如果当前锁不存在,返回加锁成功 if (jedis.setnx(key, expiresStr) == 1) { return true; } // 如果锁已经存在,获取锁的过期时间 String currentValueStr = jedis.get(key); // 如果获取到的过期时间,小于系统当前时间,表示已经过期 if (currentValueStr != null && Long.parseLong(currentValueStr) < System.currentTimeMillis()) { // 锁已过期,获取上一个锁的过期时间,并设置现在锁的过期时间(不了解redis的getSet命令的小伙伴,可以去官网看下哈) String oldValueStr = jedis.getSet(key_resource_id, expiresStr); if (oldValueStr != null && oldValueStr.equals(currentValueStr)) { // 考虑多线程并发的情况,只有一个线程的设置值和当前值相同,它才可以加锁 return true; } } //其他情况,均返回加锁失败 return false; }笔者看过有开发小伙伴是这么实现分布式锁的,但是这种方案也有这些缺点:
- 过期时间是客户端自己生成的,分布式环境下,每个客户端的时间必须同步。
- 没有保存持有者的唯一标识,可能被别的客户端释放/解锁。
- 锁过期的时候,并发多个客户端同时请求过来,都执行了
jedis.getSet(),最终只能有一个客户端加锁成功,但是该客户端锁的过期时间,可能被别的客户端覆盖。10.3:set的扩展命令(set ex px nx)(注意可能存在的问题)
if(jedis.set(key, lock_value, "NX", "EX", 100s) == 1){ //加锁 try { do something //业务处理 }catch(){ } finally { jedis.del(key); //释放锁 } }这个方案可能存在这样的问题:
- 锁过期释放了,业务还没执行完。
- 锁被别的线程误删。
10.4 set ex px nx + 校验唯一随机值,再删除
if(jedis.set(key, uni_request_id, "NX", "EX", 100s) == 1){ //加锁 try { do something //业务处理 }catch(){ } finally { //判断是不是当前线程加的锁,是才释放 if (uni_request_id.equals(jedis.get(key))) { jedis.del(key); //释放锁 } } }在这里,判断当前线程加的锁和释放锁是不是一个原子操作。如果调用jedis.del()释放锁的时候,可能这把锁已经不属于当前客户端,会解除他人加的锁。
一般也是用lua脚本代替。lua脚本如下:
if redis.call('get',KEYS[1]) == ARGV[1] then return redis.call('del',KEYS[1]) else return 0 end;这种方式比较不错了,一般情况下,已经可以使用这种实现方式。但是存在锁过期释放了,业务还没执行完的问题(实际上,估算个业务处理的时间,一般没啥问题了)。
11. 使用过Redisson嘛?说说它的原理
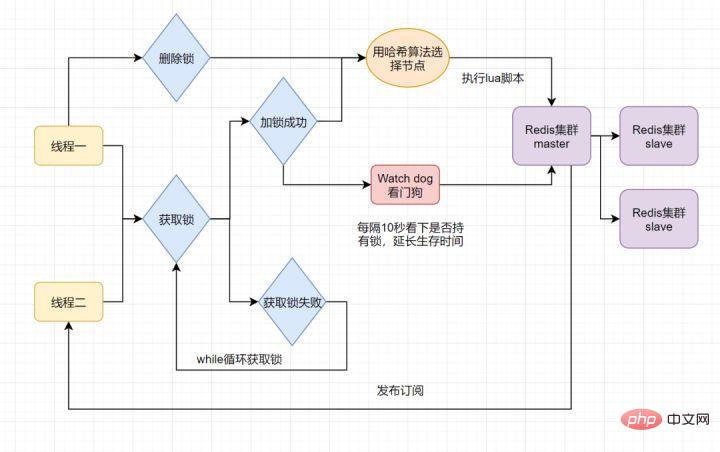
分布式锁可能存在锁过期释放,业务没执行完的问题。有些小伙伴认为,稍微把锁过期时间设置长一些就可以啦。其实我们设想一下,是否可以给获得锁的线程,开启一个定时守护线程,每隔一段时间检查锁是否还存在,存在则对锁的过期时间延长,防止锁过期提前释放。
当前开源框架Redisson就解决了这个分布式锁问题。我们一起来看下Redisson底层原理是怎样的吧:
只要线程一加锁成功,就会启动一个
watch dog看门狗,它是一个后台线程,会每隔10秒检查一下,如果线程1还持有锁,那么就会不断的延长锁key的生存时间。因此,Redisson就是使用Redisson解决了锁过期释放,业务没执行完问题。12. 什么是Redlock算法
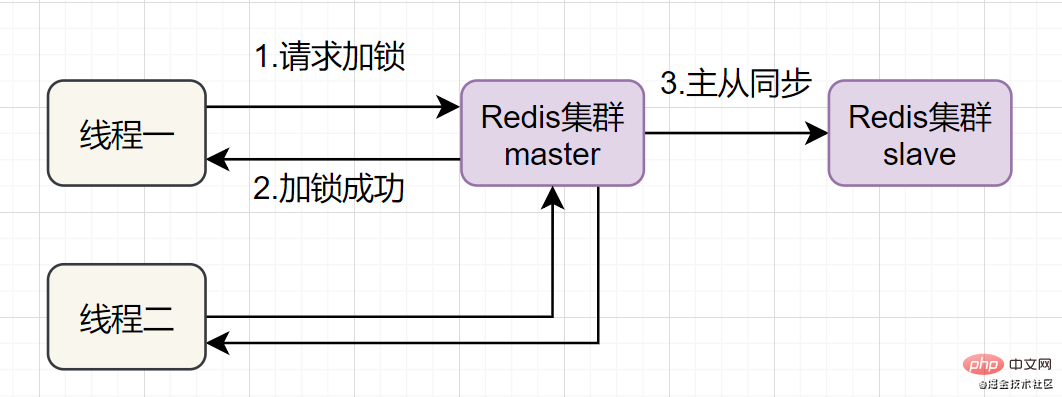
Redis一般都是集群部署的,假设数据在主从同步过程,主节点挂了,Redis分布式锁可能会有哪些问题呢?一起来看些这个流程图:
如果线程一在Redis的master节点上拿到了锁,但是加锁的key还没同步到slave节点。恰好这时,master节点发生故障,一个slave节点就会升级为master节点。线程二就可以获取同个key的锁啦,但线程一也已经拿到锁了,锁的安全性就没了。
为了解决这个问题,Redis作者 antirez提出一种高级的分布式锁算法:Redlock。Redlock核心思想是这样的:
搞多个Redis master部署,以保证它们不会同时宕掉。并且这些master节点是完全相互独立的,相互之间不存在数据同步。同时,需要确保在这多个master实例上,是与在Redis单实例,使用相同方法来获取和释放锁。
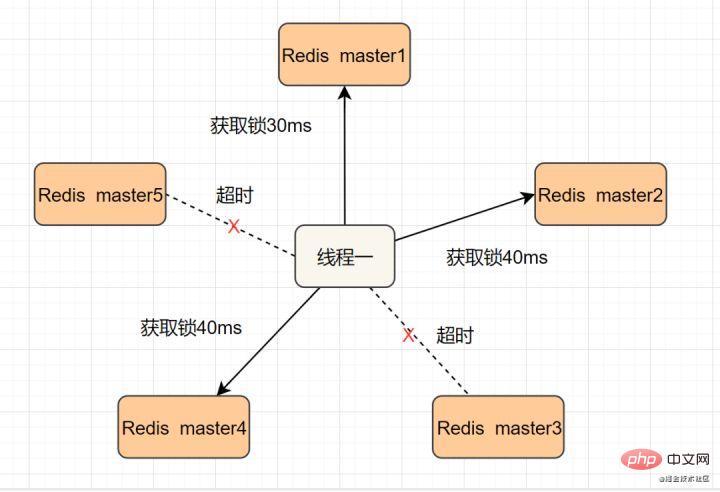
我们假设当前有5个Redis master节点,在5台服务器上面运行这些Redis实例。
RedLock的实现步骤:如下
- 1.获取当前时间,以毫秒为单位。
- 2.按顺序向5个master节点请求加锁。客户端设置网络连接和响应超时时间,并且超时时间要小于锁的失效时间。(假设锁自动失效时间为10秒,则超时时间一般在5-50毫秒之间,我们就假设超时时间是50ms吧)。如果超时,跳过该master节点,尽快去尝试下一个master节点。
- 3.客户端使用当前时间减去开始获取锁时间(即步骤1记录的时间),得到获取锁使用的时间。当且仅当超过一半(N/2+1,这里是5/2+1=3个节点)的Redis master节点都获得锁,并且使用的时间小于锁失效时间时,锁才算获取成功。(如上图,10s> 30ms+40ms+50ms+4m0s+50ms)
- 如果取到了锁,key的真正有效时间就变啦,需要减去获取锁所使用的时间。
- 如果获取锁失败(没有在至少N/2+1个master实例取到锁,有或者获取锁时间已经超过了有效时间),客户端要在所有的master节点上解锁(即便有些master节点根本就没有加锁成功,也需要解锁,以防止有些漏网之鱼)。
简化下步骤就是:
- 按顺序向5个master节点请求加锁
- 根据设置的超时时间来判断,是不是要跳过该master节点。
- 如果大于等于三个节点加锁成功,并且使用的时间小于锁的有效期,即可认定加锁成功啦。
- 如果获取锁失败,解锁!
13. Redis的跳跃表
跳跃表
- La table de saut est l'une des implémentations sous-jacentes de l'ensemble ordonné zset.
- La table de saut prend en charge la recherche de nœuds de complexité moyenne O(logN), dans le pire des cas, et peut également traiter les nœuds par lots via opérations séquentielles.
- L'implémentation de la liste à sauter se compose de deux structures : zskiplist et zskiplistNode, où zskiplist est utilisé pour enregistrer les informations de la table à sauter (telles que le nœud d'en-tête, le nœud de queue, la longueur) et zskiplistNode est utilisé pour représenter les nœuds de la liste à sauter.
- La liste de sauts est basée sur la liste chaînée, ajoutant des index à plusieurs niveaux pour améliorer l'efficacité de la recherche.
14. Comment MySQL et Redis assurent-ils la cohérence des doubles écritures
- Double suppression retardée du cache
- Mécanisme de nouvelle tentative de suppression du cache
- Lire le biglog et supprimer le cache de manière asynchrone
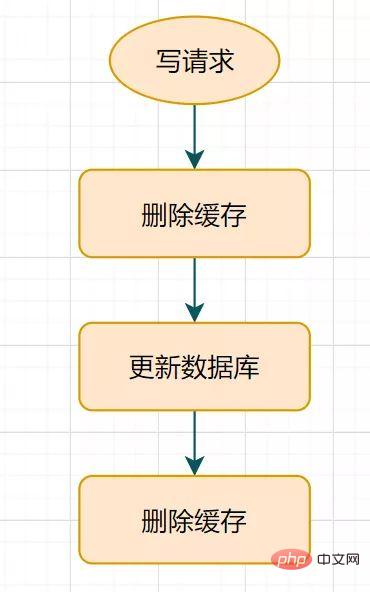
14.1 Double suppression retardée ?
Qu'est-ce que la double suppression différée ? L'organigramme est le suivant :
Processus de double suppression retardé
- Supprimez d'abord le cache
- puis mettez à jour la base de données
- Veillez pendant un moment (par exemple 1 seconde) et supprimez à nouveau le cache.
Combien de temps faut-il habituellement pour dormir pendant un certain temps ? Sont-ils tous 1 seconde ?
Ce temps de veille = le temps nécessaire pour lire les données de la logique métier + quelques centaines de millisecondes. Afin de garantir la fin de la demande de lecture, la demande d'écriture peut supprimer les données sales mises en cache qui peuvent être apportées par la demande de lecture.
Cette solution n'est pas mauvaise. Ce n'est que pendant la période de sommeil (par exemple, seulement 1 seconde) qu'il peut y avoir des données sales, et les entreprises générales l'accepteront. Mais que se passe-t-il si la suppression du cache échoue une deuxième fois ? Les données du cache et de la base de données peuvent toujours être incohérentes, n'est-ce pas ? Que diriez-vous de définir un délai d’expiration naturel pour la clé et de la laisser expirer automatiquement ? L'entreprise doit-elle accepter des incohérences de données pendant la période d'expiration ? Ou existe-t-il une autre meilleure solution ?
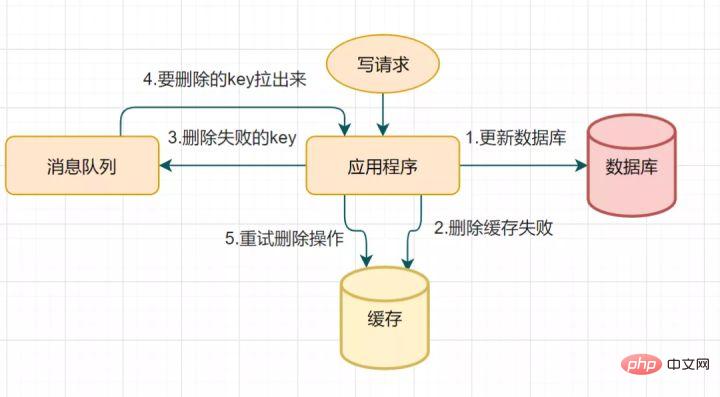
14.2 Mécanisme de nouvelle tentative de suppression du cache
En raison d'une double suppression retardée, la deuxième étape de suppression du cache peut échouer, entraînant une incohérence des données. Vous pouvez utiliser cette solution pour optimiser : si la suppression échoue, supprimez-la simplement quelques fois de plus pour vous assurer que la suppression du cache est réussie. Vous pouvez ainsi introduire un mécanisme de nouvelle tentative de suppression du cache
processus de nouvelle tentative de suppression du cache
- demande d'écriture pour mettre à jour la base de données
- Le cache n'a pas pu être supprimé pour une raison quelconque
- Mettez la clé qui n'a pas pu être supprimée dans la file d'attente des messages
- Consommez les messages de la file d'attente des messages et obtenez la clé à supprimer
- Réessayez le opération de suppression du cache
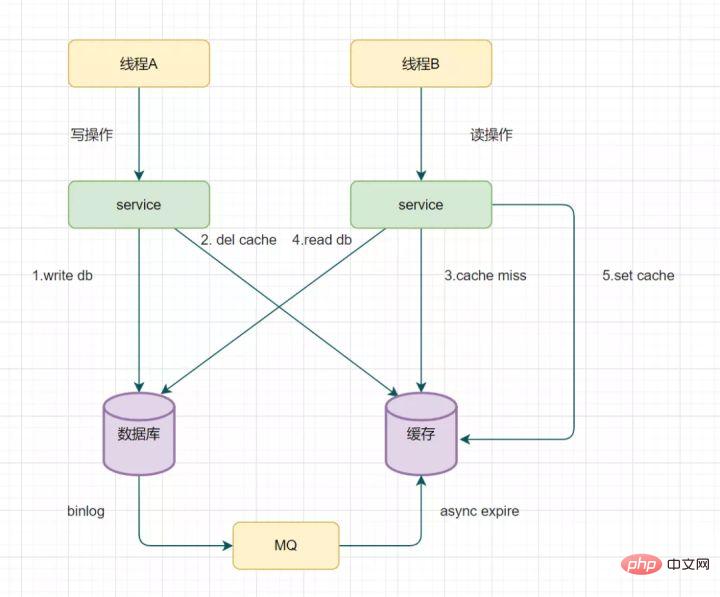
14.3 Lire le biglog et supprimer le cache de manière asynchrone
Vous pouvez réessayer de supprimer le mécanisme de cache, mais cela entraînera de nombreuses intrusions dans le code métier. En fait, il peut également être optimisé de cette manière : éliminer les clés de manière asynchrone via le binlog de la base de données.
Prenons MySQL comme exemple
- Vous pouvez utiliser le canal d'Alibaba pour collecter et envoyer les journaux binlog à la file d'attente MQ
- Ensuite, confirmez et traitez ce message de mise à jour via le mécanisme ACK, supprimez le cache et assurez le cache des données cohérence
15. Pourquoi le multithreading a-t-il changé après Redis 6.0 ?
- Avant Redis 6.0, lorsque Redis traitait les requêtes des clients, y compris la lecture des sockets, l'analyse, l'exécution, l'écriture des sockets, etc., elles étaient toutes traitées par un thread principal séquentiel et série. C'est ce qu'on appelle le « thread unique ».
- Pourquoi le multithreading n'était-il pas utilisé avant Redis6.0 ? Lors de l'utilisation de Redis, il n'y a presque aucune situation dans laquelle le processeur devient un goulot d'étranglement. Redis est principalement limité par la mémoire et le réseau. Par exemple, sur un système Linux normal, Redis peut gérer 1 million de requêtes par seconde en utilisant le pipeline, donc si l'application utilise principalement des commandes O(N) ou O(log(N)), elle ne consommera guère beaucoup de CPU.
L'utilisation du multi-threading par Redis ne signifie pas qu'il abandonne complètement le monothreading. Redis utilise toujours un modèle monothread pour traiter les demandes des clients. Il utilise uniquement le multithreading pour gérer la lecture et l'écriture des données et l'analyse des protocoles. il utilise toujours un seul thread pour exécuter les commandes.
Le but de ceci est que le goulot d'étranglement des performances de Redis réside dans les E/S du réseau plutôt que dans le processeur. L'utilisation du multithreading peut améliorer l'efficacité de la lecture et de l'écriture des E/S, améliorant ainsi les performances globales de Redis.
16. Parlons du mécanisme de transaction Redis
Redis implémente le mécanisme de transaction via un ensemble de commandes telles que MULTI, EXEC, WATCH. Les transactions prennent en charge l'exécution de plusieurs commandes à la fois, et toutes les commandes d'une transaction seront sérialisées. Pendant le processus d'exécution de la transaction, les commandes dans la file d'attente seront sérialisées et exécutées dans l'ordre, et les demandes de commandes soumises par d'autres clients ne seront pas insérées dans la séquence de commandes d'exécution de la transaction.
En bref, une transaction Redis est l'exécution séquentielle, unique et exclusive d'une série de commandes dans une file d'attente.
Le processus d'exécution de la transaction Redis est le suivant :Démarrer la transaction (MULTI)
17.- Mise en file d'attente des commandes
- Exécuter la transaction (EXEC), annuler la transaction (DISCARD)
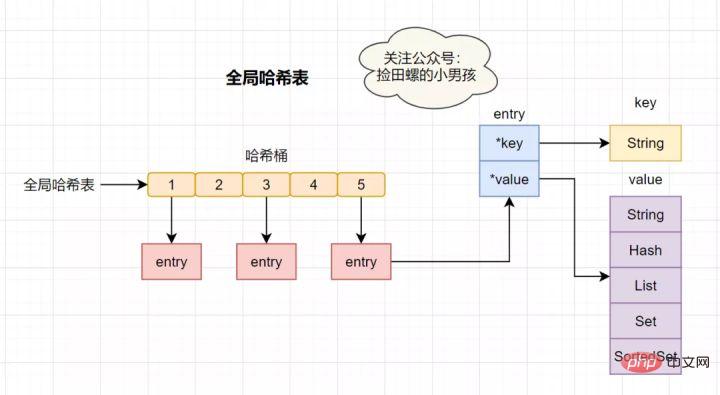
Redis en tant que base de données en mémoire K-V qui utilise un hachage global pour enregistrer toutes les paires clé-valeur. Cette table de hachage est composée de plusieurs compartiments de hachage. L'élément d'entrée dans le compartiment de hachage stocke les pointeurs
key etvalue, où *key pointe vers la clé réelle et *value pointe vers la valeur réelle.
La vitesse de recherche dans la table de hachage est très rapide, quelque peu similaire à HashMap en Java, ce qui nous permet de trouver rapidement des paires clé-valeur dans une complexité temporelle O(1). Tout d'abord, calculez la valeur de hachage via la clé, recherchez l'emplacement du compartiment de hachage correspondant, puis localisez l'entrée et recherchez les données correspondantes dans l'entrée.
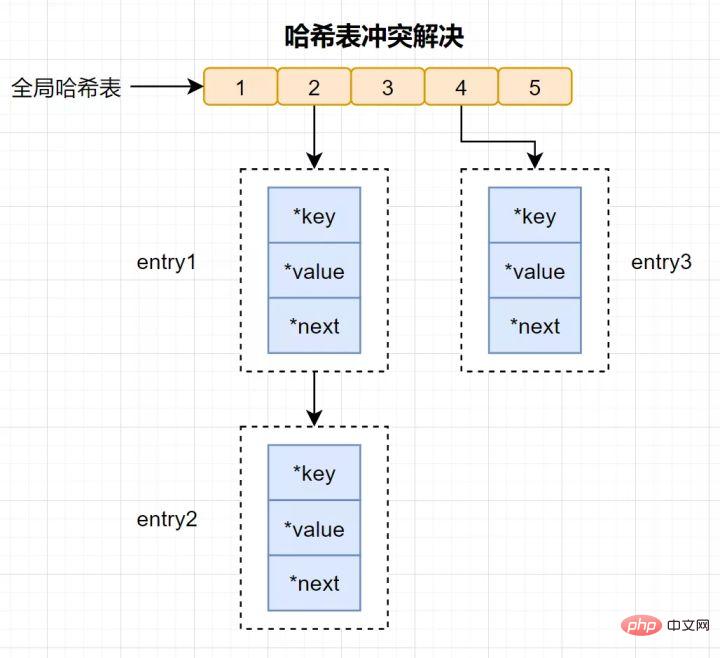
Qu'est-ce qu'une collision de hachage ?
Conflit de hachage : la même valeur de hachage est calculée via différentes clés, ce qui donne le même compartiment de hachage.
Afin de résoudre les conflits de hachage, Redis utilise le hachage de chaîne. Le hachage en chaîne signifie que plusieurs éléments du même compartiment de hachage sont stockés dans une liste chaînée et qu'ils sont connectés tour à tour à l'aide de pointeurs.
Certains lecteurs peuvent encore avoir des questions : les éléments de la chaîne de conflits de hachage ne peuvent être recherchés qu'un par un via des pointeurs puis exploités. Lorsqu'une grande quantité de données est insérée dans la table de hachage, plus il y aura de conflits, plus la liste chaînée des conflits sera longue et l'efficacité des requêtes sera réduite.
Afin de maintenir l'efficacité, Redis effectuera une opération de rehachage sur la hash table, ce qui signifie ajouter des compartiments de hachage et réduire les conflits. Afin de rendre le rehachage plus efficace, Redis utilise également deux tables de hachage globales par défaut, une pour l'utilisation actuelle, appelée table de hachage principale, et une pour l'expansion, appelée table de hachage de sauvegarde. 18. Lors de la génération RDB, Redis peut-il gérer les requêtes d'écriture en même temps ?
Oui, Redis fournit deux instructions pour générer du RDB, à savoir save et bgsave.
S'il s'agit d'une instruction de sauvegarde, elle bloquera car elle est exécutée par le thread principal.
- S'il s'agit d'une instruction bgsave, elle force un processus enfant pour écrire le fichier RDB. La persistance de l'instantané est entièrement gérée par le processus enfant et le processus parent peut continuer à traiter les demandes des clients.
- 19. Quel protocole est utilisé au bas de Redis ?
RESP, le nom anglais complet est Redis Serialization Protocol, qui est un ensemble de protocoles de sérialisation spécialement conçus pour redis. Ce protocole est en fait apparu dans la version 1.2 de redis. mais ce n'est qu'avec Redis2.0 qu'il est finalement devenu la norme pour le protocole de communication Redis.
RESP présente principalement les avantages d'une mise en œuvre simple, d'une vitesse d'analyse rapide et d'une bonne lisibilité
.20. Filtre Bloom
Pour résoudre le problème depénétration du cache
, nous pouvons utiliser leFiltre Bloom. Qu'est-ce qu'un filtre bloom ? Un filtre Bloom est une structure de données qui prend très peu de place. Il se compose d'un long vecteur binaire et d'un ensemble de fonctions de mappage de hachage. Il est utilisé pour récupérer si un élément est dans un ensemble, l'efficacité spatiale et le temps de requête. Ils sont bien meilleurs que les algorithmes ordinaires. Les inconvénients sont un certain taux de mauvaise reconnaissance et des difficultés de suppression.
Quel est le principe du filtre Bloom ?
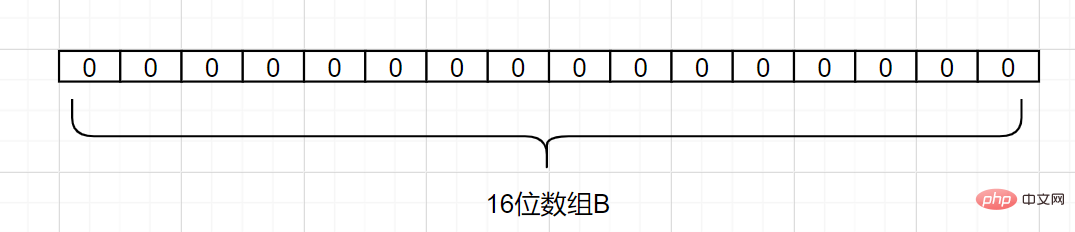
Supposons que nous ayons un ensemble A et qu'il y ait n éléments dans A. À l'aide des fonctions de hachagek , chaque élément de A est mappé à différentes positions dans un tableau B d'une longueur d'un bit, et les nombres binaires à ces positions sont tous définis sur 1. Si l'élément à vérifier est mappé par ces k fonctions de hachage et qu'il s'avère que les nombres binaires à ses k positions sont tous 1, cet élément appartient probablement à l'ensemble A. Au contraire, ne doit pas appartenir à l'ensemble A. . Regardons un exemple simple. Supposons que l'ensemble A comporte 3 éléments, à savoir {d1, d2, d3
}. Il existe 1 fonction de hachage, qui estHash1. Mappez maintenant chaque élément de A à un tableau B de longueur 16 bits.
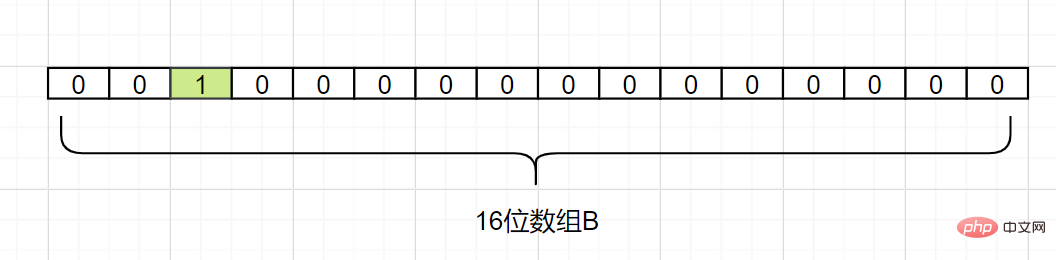
Nous mappons maintenant d1. En supposant que Hash1(d1) = 2, nous changeons la grille avec l'indice 2 dans le tableau B en 1, comme suit :
Nous mappons maintenant
Également mappé, en supposant que Hash1. (d2) = 5, nous changeons la grille d'indice 5 dans le tableau B en 1, comme suit :
Ensuite, nous mappons également
, en supposant que Hash1(d3 ) est également égal à 2, il marque également le grille avec l'indice 2 à 1 :
Par conséquent, nous voulons confirmer si un élément dn est dans l'ensemble A, il nous suffit de calculer l'indice d'index obtenu par Hash1 (dn), à condition que s'il est 0, cela signifie que cet élément
. Et si l'indice d'index est 1 ? Alors l’élémentpeut être un élément de A. Parce que vous voyez, les valeurs d'indice obtenues par d1 et d3 peuvent toutes deux être 1, ou elles peuvent être mappées par d'autres nombres. Le filtre Bloom a cet inconvénient : il y aura des faux positifs causés par une collision de hachage, là. est une erreur de jugement. Comment réduire cette erreur
?
- Créez davantage de mappages de fonctions de hachage pour réduire la probabilité de collision de hachage
- Dans le même temps, augmenter la longueur en bits du tableau B peut augmenter la plage de données générées par la fonction de hachage et également réduire la probabilité de collision de hachage
Nous ajoutons une autre fonction Hash2Hash map, en supposant que Hash2(d1)=6, Hash2(d3)=8, elles ne seront pas en conflit, comme suit :
Même s'il y a une erreur, nous pouvons trouver que , Le filtre Bloom ne stocke pas les données complètes, il utilise simplement une série de fonctions de carte de hachage pour calculer la position, puis remplit le vecteur binaire. Si le nombre est grand, le filtre Bloom peut économiser beaucoup d'espace de stockage grâce à un très faible taux d'erreur, ce qui est assez rentable. Actuellement, les filtres Bloom disposent déjà de bibliothèques open source qui les implémentent en conséquence, telles que la
la bibliothèque de classes Guava de Googleet la bibliothèque de classes Algebird de Twitter, qui sont facilement disponibles, ou vous pouvez implémenter votre propre conception basée sur les Bitmaps fournis avec Redis. . Pour plus de connaissances sur la programmation, veuillez visiter :
Vidéos de programmation
 🎜🎜List (list)🎜🎜🎜Introduction : Le type list (list) est utilisé pour stocker plusieurs chaînes ordonnées. Une liste peut stocker jusqu'à 2 ^ 32-1 éléments. 🎜🎜Exemples simples et pratiques :
🎜🎜List (list)🎜🎜🎜Introduction : Le type list (list) est utilisé pour stocker plusieurs chaînes ordonnées. Une liste peut stocker jusqu'à 2 ^ 32-1 éléments. 🎜🎜Exemples simples et pratiques : 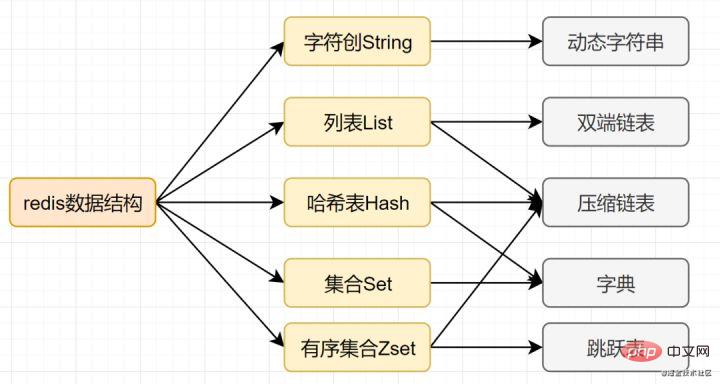

 Inconvénients d'AOF
Inconvénients d'AOF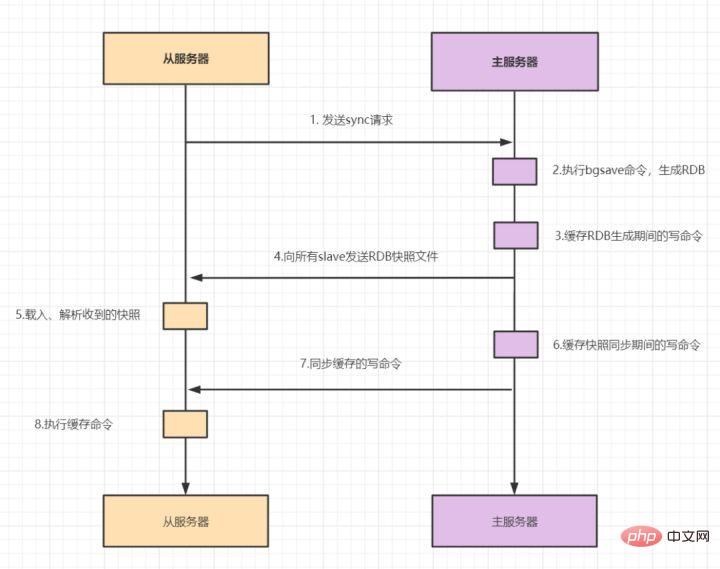

 d2
d2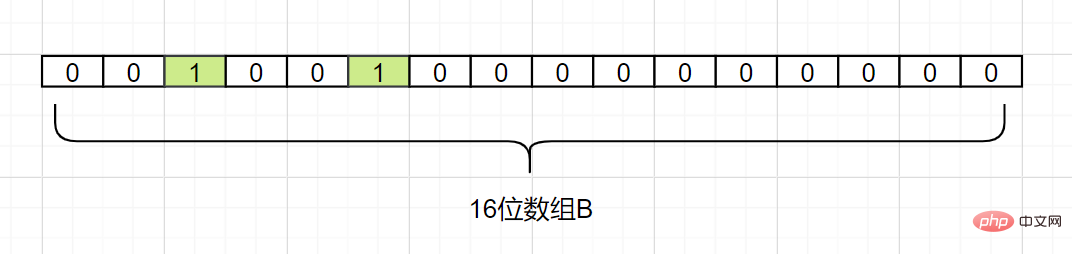 d3
d3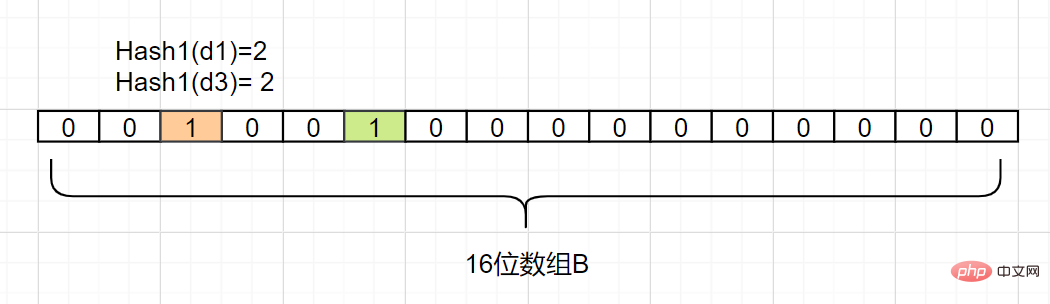 n'est pas dans l'ensemble A
n'est pas dans l'ensemble A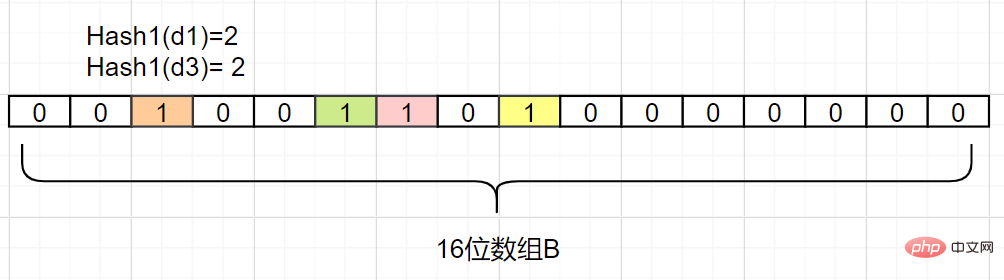
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Comment utiliser Redis dans Node.js ? Il s'avère que c'est aussi simple que ça !
- Une brève analyse de la stratégie de persistance Redis
- Comprendre l'avalanche de cache Redis, la panne du cache et la pénétration du cache dans un seul article
- Résumer l'utilisation de zrangeByScore dans PHPredis
- Construction de l'architecture haute disponibilité Redis jusqu'à l'analyse des principes