
Maison >base de données >Redis >Construction de l'architecture haute disponibilité Redis jusqu'à l'analyse des principes
Construction de l'architecture haute disponibilité Redis jusqu'à l'analyse des principes

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBavant
- 2022-11-24 18:02:272580parcourir
Cet article vous apporte des connaissances pertinentes sur Redis, qui présente principalement le contenu pertinent, de la construction d'une architecture à haute disponibilité à l'analyse des principes. J'espère qu'il sera utile à tout le monde.

Apprentissage recommandé : Tutoriel vidéo Redis
En raison de la récente optimisation du système de l'entreprise, après avoir divisé la grande table en tables il y a quelque temps, nous travaillons maintenant à nouveau sur Redis. Concernant Redis, l'une des exigences est de migrer le service Redis d'Alibaba Cloud vers le propre serveur de l'entreprise (en raison de la nature de l'entreprise). Je viens de profiter de cette occasion pour revoir l'architecture de cluster haute disponibilité de Redis. Il existe trois modes de cluster Redis, à savoir le mode de réplication maître-esclave, le mode sentinelle et le mode cluster Cluster. Généralement, les clusters Sentinel et Cluster sont utilisés plus fréquemment. Comprenons brièvement ces trois modes.
Mécanisme de persistance
Avant de comprendre l'architecture du cluster, nous devons d'abord introduire le mécanisme de persistance de redis, car la persistance sera impliquée dans le cluster suivant. La persistance Redis consiste à stocker les données mises en cache dans la mémoire selon certaines règles pour empêcher la récupération des données ou la synchronisation des données des nœuds maître-esclave dans l'architecture du cluster lorsque le service Redis tombe en panne. Il existe deux méthodes de persistance Redis : RDB et AOF. Après la version 4.0, un nouveau mode de persistance hybride a été introduit.
RDB
RDB est le mécanisme de persistance activé par redis par défaut. Sa méthode de persistance consiste à générer un instantané et à le télécharger sur le disque selon les règles configurées par l'utilisateur "Au moins Y changements se sont produits dans X. secondes" fichier binaire dump.rdb. Par défaut, redis est configuré avec trois configurations : au moins une modification de clé de cache s'est produite dans les 900 secondes, au moins 10 modifications de clé de cache ont eu lieu dans les 300 secondes et au moins 10 000 modifications ont eu lieu dans les 60 secondes. "X秒内至少发生过Y次改动",生成快照并落盘到dump.rdb二进制文件中。默认情况下,redis配置了三种,分别为900秒内至少发生过1次缓存key的改动,300秒内至少发生过10次缓存key的改动以及60秒内至少发生过10000次改动。

除了redis自动快照持久化数据外,还有两个命令可以帮助我们手动进行内存数据快照,这两个命令分别为save和bgsave。

save:以同步的方式进行数据快照,当缓存数据量大,会阻塞其他命令的执行,效率不高。
bgsave:以异步的方式进行数据快照,有redis主线程fork出一个子进程来进行数据快照,不会阻塞其他命令的执行,效率较高。由于是采用异步快照的方式,那么就有可能发生在快照的过程中,有其他命令对数据进行了修改。为了避免这个问题reids采用了写时复制(Cpoy-On-Write)的方式,因为此时进行快照的进程是由主线程fork出来的,所以享有主线程的资源,当快照过程中发生数据改动时,那么该数据会被复制一份并生成副本数据,子进程会将改副本数据写入到dump.rdb文件中。
RDB快照是以二进制的方式进行存储的,所以在数据恢复时,速度会比较快,但是它存在数据丢失的风险。假如设置的快照规则为60秒内至少发生100次数据改动,那么在50秒时,redis服务由于某种原因突然宕机了,那在这50秒内的所有数据将会丢失。
AOF
AOF是Redis的另一种持久化方式,与RDB不同时是,AOF记录着每一条更改数据的命令并保存到磁盘下的appendonly.aof文件中,当redis服务重启时,会加载该文将并再次执行文件中保存的命令,从而达到数据恢复的效果。默认情况下,AOF是关闭的,可以通过修改conf配置文件来进行开启。
# appendonly no 关闭AOF持久化 appendonly yes # 开启AOF持久化 # The name of the append only file (default: "appendonly.aof") appendfilename "appendonly.aof" # 持久化文件名
AOF提供了三种方式,可以让命令保存到磁盘。默认情况下,AOF采用appendfsync everysec
sauf En plus de l'instantané automatique des données persistantes par Redis, il existe deux commandes qui peuvent nous aider à capturer manuellement les données de la mémoire. Ces deux commandes sont save et bgsave. 
save : effectuez des instantanés de données de manière synchrone. Lorsque la quantité de données mises en cache est importante, cela bloquera l'exécution d'autres commandes et sera inefficace.

- bgsave : effectuez des instantanés de données de manière asynchrone. Le thread principal Redis crée un sous-processus pour prendre des instantanés de données. Il ne bloquera pas l'exécution d'autres commandes. et est plus efficace. Puisqu'un instantané asynchrone est utilisé, il est possible que d'autres commandes modifient les données pendant le processus d'instantané. Afin d'éviter ce problème, Reids adopte la méthode de copie sur écriture (Cpoy-On-Write). Étant donné que le processus prenant l'instantané à ce moment-là est bifurqué par le thread principal, il bénéficie des ressources du thread principal. des changements de données se produisent pendant le processus d'instantané, puis les données seront copiées et les données de copie seront générées, et le processus enfant écrira les données de copie modifiées dans le fichier dump.rdb.

appendfsync always #每次有新的改写命令时,都会追加到磁盘的aof文件中。数据安全性最高,但效率最慢。 appendfsync everysec # 每一秒,都会将改写命令追加到磁盘中的aof文件中。如果发生宕机,也只会丢失1秒的数据。 appendfsync no #不会主动进行命令落盘,而是由操作系统决定什么时候写入到磁盘。数据安全性不高。 AOF propose trois façons d'enregistrer des commandes sur le disque. Par défaut, AOF utilise la méthode appendfsync Everysec pour la persistance des commandes. |
Après avoir activé AOF, vous devez redémarrer le service redis Lorsque la commande de réécriture correspondante est à nouveau exécutée, la commande d'opération sera enregistrée dans le fichier aof. | |
|---|---|---|
| Par rapport à RDB, bien qu'AOF ait une sécurité des données plus élevée, à mesure que le service continue de fonctionner, le fichier d'AOF deviendra de plus en plus volumineux, et la prochaine fois que les données seront restaurées, la vitesse sera plus rapide Le plus lent. Si RDB et AOF sont activés, redis donnera la priorité à AOF lors de la restauration des données. Après tout, AOF perdra moins de données. | ||
| RDB | AOF | |
| Efficacité de récupération | Élevée | Faible |
混合模式
由于RDB持久化方式容易造成数据丢失,AOF持久化方式数据恢复较慢,所以在redis4.0版本后,新出来混合持久化模式。混合持久化将RDB和AOF的优点进行了集成,并而且依赖于AOF,所以在使用混合持久化前,需要开启AOF。在开启混合持久化后,当发生AOF重写时,会将内存中的数据以RDB的数据格式保存到aof文件中,在下一次的重写之前,混合持久化会追加保存每条改写命令到aof文件中。当需要恢复数据时,会加载保存的rdb内容数据,然后再继续同步aof指令。
# AOF重写配置,当aof文件达到60MB并且比上次重写后的体量多100%时自动触发AOF重写 auto-aof-rewrite-percentage 100 auto-aof-rewrite-min-size 64mb aof-use-rdb-preamble yes # 开启混合持久化# aof-use-rdb-preamble no # 关闭混合持久化
AOF重写是指当aof文件越来越大时,redis会自动优化aof文件中无用的命令,从而减少文件体积。比如在处理文章阅读量时,每查看一次文章就会执行一次Incr命令,但是随着阅读量的不断增加,aof文件中的incr命令也会积累的越来越多。在AOF重写后,将会删除这些没用的Incr命令,将这些命令直接替换为set key value命令。除了redis自动重写AOF,如果需要,也可以通过bgrewriteaof命令手动触发。
主从复制
在生产环境中,一般不会直接配置单节点的redis服务,这样压力太大。为了缓解redis服务压力,可以搭建主从复制,做读写分离。redis主从复制,是有一个主节点Master和多个从节点Slave组成。主从节点间的数据同步只能是单向传输的,只能由Master节点传输到Slave节点。
环境配置
准备三台linux服务器,其中一台作为redis的主节点,两台作为reids的从节点。如果没有足够的机器可以在同一台机器上面将redis文件多复制两份并更改端口号,这样可以搭建一个伪集群。
| IP | 主/从节点 | 端口 | 版本 |
|---|---|---|---|
| 192.168.36.128 | 主 | 6379 | 5.0.14 |
| 192.168.36.130 | 从 | 6379 | 5.0.14 |
| 192.168.36.131 | 从 | 6379 | 5.0.14 |
- 配置从节点36.130,36.131机器中reids.conf
修改redis.conf文件中的replicaof,配置主节点的ip和端口号,并且开启从节点只读。


- 启动主节点36.128机器中reids服务
./src/redis-server redis.conf
 3. 依次启动从节点36.130,36.131机器中的redis服务
3. 依次启动从节点36.130,36.131机器中的redis服务
./src/redis-server redis.conf
启动成功后可以看到日志中显示已经与Master节点建立的连接。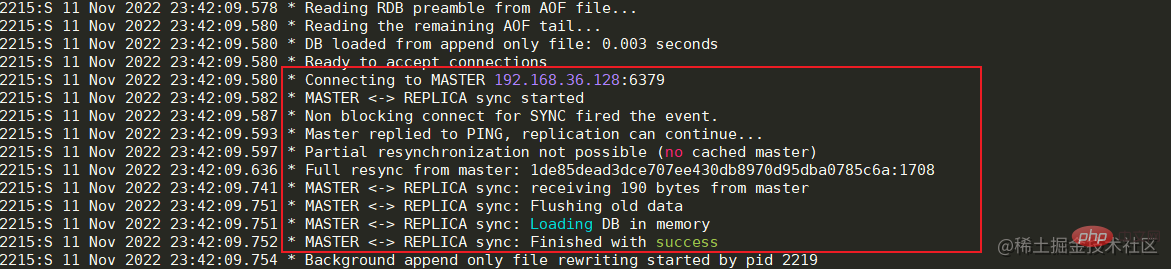 如果出现与Master节点的连接被拒,那么先检查Master节点的服务器是否开启防火墙,如果开启,可以开放6379端口或者关闭防火墙。如果防火墙被关闭但连接仍然被拒,那么可以修改Master节点服务中的redis.conf文件。将bing 127.0.0.1修改为本机对外的网卡ip或者直接注释掉即可,然后重启服务器即可。
如果出现与Master节点的连接被拒,那么先检查Master节点的服务器是否开启防火墙,如果开启,可以开放6379端口或者关闭防火墙。如果防火墙被关闭但连接仍然被拒,那么可以修改Master节点服务中的redis.conf文件。将bing 127.0.0.1修改为本机对外的网卡ip或者直接注释掉即可,然后重启服务器即可。

- 查看状态
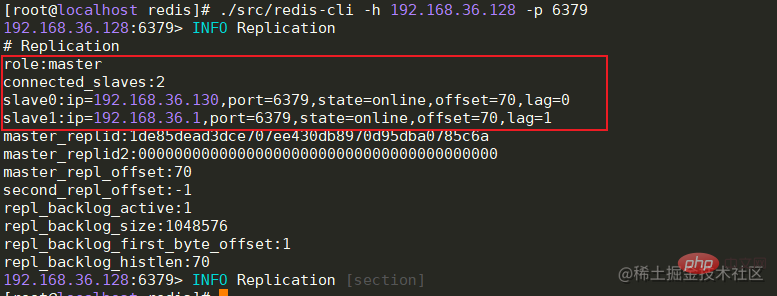
全部节点启动成功后,Master节点可以查看从节点的连接状态,offset偏移量等信息。
info replication # 主节点查看连接信息
数据同步流程
全量数据同步
主从节点之间的数据同步是通过建立socket长连接来进行传输的。当Slave节点启动时,会与Master节点建立长连接,并且发送psync同步数据命令。当Master节点收到psync命令时,会执行pgsave进行rdb内存数据快照(这里的rdb快照与conf文件中是否开启rdb无关),如果在快照过程中有新的改写命令,那么Master节点会将这些命令保存到repl buffer缓冲区中。当快照结束后,会将rdb传输给Slave节点。Slave节点在接收到rdb后,如果存在旧数据,那么会将这些旧数据清除并加载rdb。加载完成后会接受master缓存在repl buffer中的新命令。在这些步骤全部执行完成后,主从节点已经算连接成功了,后续Master节点的命令会不断的发送到Slave节点。如果在高并发的情况下,可能会存在数据延迟的情况。部分数据同步
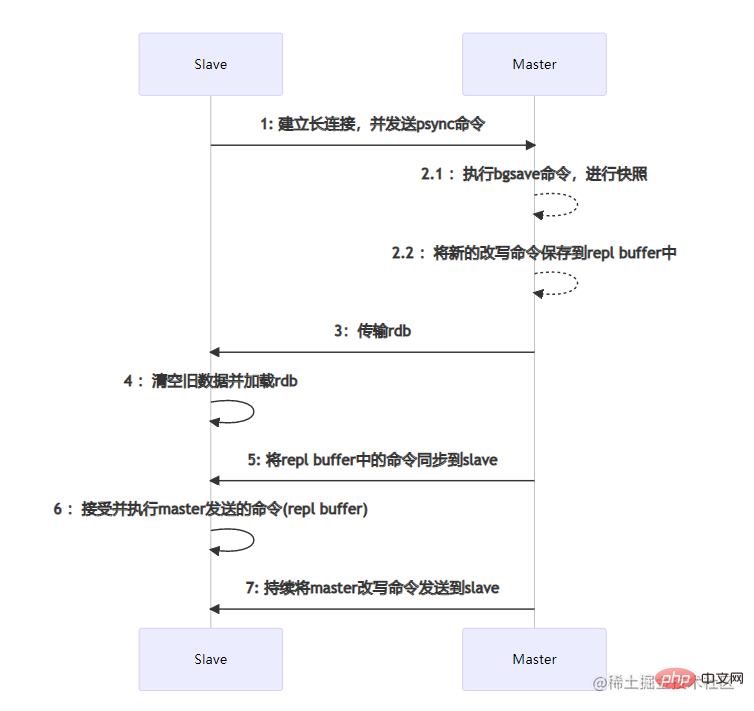 主从节点之间的数据同步是通过建立socket长连接来进行传输的。当Slave节点启动时,会与Master节点建立长连接,并且发送psync同步数据命令。当Master节点收到psync命令时,会执行pgsave进行rdb内存数据快照(这里的rdb快照与conf文件中是否开启rdb无关),如果在快照过程中有新的改写命令,那么Master节点会将这些命令保存到repl buffer缓冲区中。当快照结束后,会将rdb传输给Slave节点。Slave节点在接收到rdb后,如果存在旧数据,那么会将这些旧数据清除并加载rdb。加载完成后会接受master缓存在repl buffer中的新命令。在这些步骤全部执行完成后,主从节点已经算连接成功了,后续Master节点的命令会不断的发送到Slave节点。如果在高并发的情况下,可能会存在数据延迟的情况。
主从节点之间的数据同步是通过建立socket长连接来进行传输的。当Slave节点启动时,会与Master节点建立长连接,并且发送psync同步数据命令。当Master节点收到psync命令时,会执行pgsave进行rdb内存数据快照(这里的rdb快照与conf文件中是否开启rdb无关),如果在快照过程中有新的改写命令,那么Master节点会将这些命令保存到repl buffer缓冲区中。当快照结束后,会将rdb传输给Slave节点。Slave节点在接收到rdb后,如果存在旧数据,那么会将这些旧数据清除并加载rdb。加载完成后会接受master缓存在repl buffer中的新命令。在这些步骤全部执行完成后,主从节点已经算连接成功了,后续Master节点的命令会不断的发送到Slave节点。如果在高并发的情况下,可能会存在数据延迟的情况。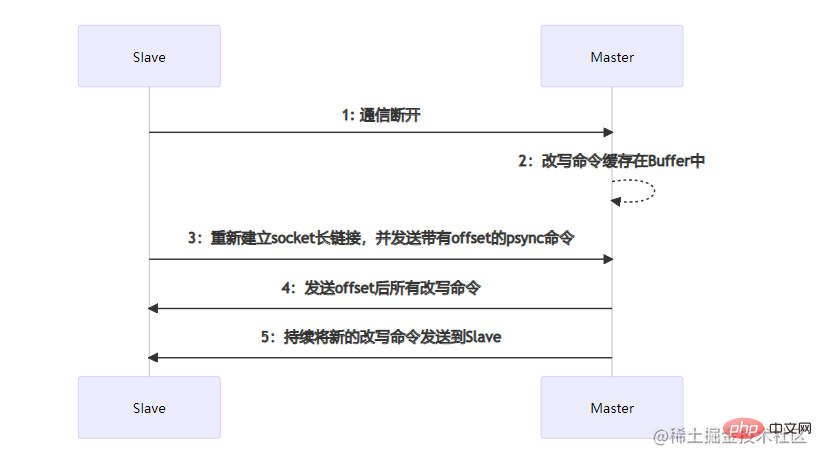
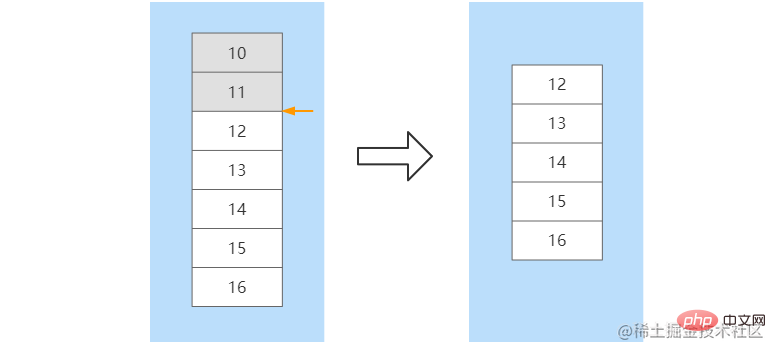
部分数据同步发生在Slave节点发生宕机,并且在短时间内进行了服务恢复。短时间内主从节点之间的数据差额不会太大,如果执行全量数据同步将会比较耗时。部分数据同步时,Slave会向Master节点建立socket长连接并发送带有一个offset偏移量的数据同步请求,这个offset可以理解数据同步的位置。Master节点在收到数据同步请求后,会根据offset结合buffer缓冲区内新的改写命令进行位置确定。如果确定了offset的位置,那么就会将这个位置往后的所有改写命令发送到Slave节点。如果没有确定offset的位置,那么会再次执行全量数据同步。比如,在Slave节点没有宕机之前命令已经同步到了offset=11这个位置,当该节点重启后,向Master节点发送该offset,Master根据offset在缓冲区中进行定位,在定位到11这个位置后,将该位置往后的所有命令发送给Slave。在数据同步完成后,后续Master节点的命令会不断的发送到该Slave节点
优缺点
-
优点
- 可以实现一主多从,读写分离,减轻Master节点读操作压力
- 是哨兵,集群架构的基础
-
缺点
- Il n'a pas de fonction de commutation automatique maître-esclave. Lorsque le nœud maître tombe en panne, vous devez changer manuellement le nœud maître
- Il est facile d'avoir une incohérence des données lorsque le nœud maître tombe en panne, s'il y a des données. qui n'est pas synchronisé, cela entraînera une perte de données
Mode Sentinelle
Le mode Sentinelle optimise davantage la réplication maître-esclave et sépare un processus sentinelle distinct pour surveiller l'état du serveur dans l'architecture maître-esclave une fois qu'un temps d'arrêt se produit, la sentinelle élira un nouveau nœud maître dans un court laps de temps et effectuera la commutation maître-esclave. De plus, sous un nœud multi-sentinelle, chaque sentinelle se surveillera mutuellement et vérifiera si le nœud sentinelle est en panne. Configuration de l'environnement 68.36.12 8
Maître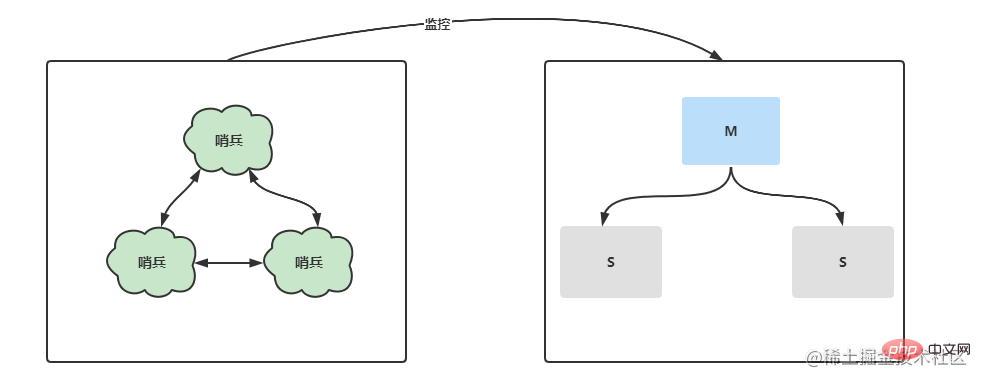
| 192.168.36.130 | de | 6379 | 26379 | |||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 192.168.36.131 | à partir de | 6379 | 26379 | 5.0.14 | ||||||||||||||||||
|
主从复制是哨兵模式的基础,所以在搭建哨兵前需要完成主从复制的配置。在搭建完主从后,哨兵的搭建就容易很多。
找到安装目录下的
在配置完成后,可以使用命令启动各机器的哨兵服务。启动成功后,可查看redis服务和哨兵服务的进行信息。
<dependency> <groupid>org.springframework.boot</groupid> <artifactid>spring-boot-starter-data-redis</artifactid> <version>2.2.2.RELEASE</version></dependency><dependency> <groupid>org.apache.commons</groupid> <artifactid>commons-pool2</artifactid> <version>2.4.2</version></dependency> server: port: 8081spring: redis: sentinel: master: mymaster # 主服务节点 nodes: 192.168.36.128:26379,192.168.36.130:26379,192.168.36.131:26379 #哨兵节点 timeout: 3000 #连接超时时间 @Slf4j
@RestController
public class RedisTest {
@Resource
private StringRedisTemplate stringRedisTemplate;
/*
* 每秒钟向redis中写入数据,中途kill掉主节点进程,模拟宕机
*/
@GetMapping("/redis/testSet")
public void test(@RequestParam(name = "key") String key,
@RequestParam(name = "value") String value) throws InterruptedException {
int idx=0;
for(;;){
try {
idx++;
stringRedisTemplate.opsForValue().set(key+idx, value);
log.info("=====存储成功:{},{}=====",key+idx,value);
}catch (Exception e){
log.error("====连接redis服务器失败:{}====",e.getMessage());
}
Thread.sleep(1000);
}
}
}
当启动服务后,通过节后向后端传递数据,可以看到输出的日志,表示redis哨兵集群已经可以正常运行了。那么这个时候kill掉36.128机器上的主节点,模拟服务宕机。通过日志可以知道,服务出现异常了,在过十几秒发现哨兵已经自动帮系统进行了主从切换,并且服务也可以正常访问了。 2022-11-14 22:20:23.134 INFO 8764 --- [nio-8081-exec-2] com.gz.redis.RedisTest : =====存储成功:test14,123===== 2022-11-14 22:20:24.142 INFO 8764 --- [nio-8081-exec-2] com.gz.redis.RedisTest : =====存储成功:test15,123===== 2022-11-14 22:20:24.844 INFO 8764 --- [xecutorLoop-1-1] i.l.core.protocol.ConnectionWatchdog : Reconnecting, last destination was /192.168.36.128:6379 2022-11-14 22:20:26.909 WARN 8764 --- [ioEventLoop-4-4] i.l.core.protocol.ConnectionWatchdog : Cannot reconnect to [192.168.36.128:6379]: Connection refused: no further information: /192.168.36.128:6379 2022-11-14 22:20:28.165 ERROR 8764 --- [nio-8081-exec-2] com.gz.redis.RedisTest : ====连接redis服务器失败:Redis command timed out; nested exception is io.lettuce.core.RedisCommandTimeoutException: Command timed out after 3 second(s)==== 2022-11-14 22:20:31.199 INFO 8764 --- [xecutorLoop-1-1] i.l.core.protocol.ConnectionWatchdog : Reconnecting, last destination was 192.168.36.128:6379 2022-11-14 22:20:52.189 ERROR 8764 --- [nio-8081-exec-2] com.gz.redis.RedisTest : ====连接redis服务器失败:Redis command timed out; nested exception is io.lettuce.core.RedisCommandTimeoutException: Command timed out after 3 second(s)==== 2022-11-14 22:20:53.819 WARN 8764 --- [ioEventLoop-4-2] i.l.core.protocol.ConnectionWatchdog : Cannot reconnect to [192.168.36.128:6379]: Connection refused: no further information: /192.168.36.128:6379 2022-11-14 22:20:56.194 ERROR 8764 --- [nio-8081-exec-2] com.gz.redis.RedisTest : ====连接redis服务器失败:Redis command timed out; nested exception is io.lettuce.core.RedisCommandTimeoutException: Command timed out after 3 second(s)==== 2022-11-14 22:20:57.999 INFO 8764 --- [xecutorLoop-1-2] i.l.core.protocol.ConnectionWatchdog : Reconnecting, last destination was 192.168.36.128:6379 2022-11-14 22:20:58.032 INFO 8764 --- [ioEventLoop-4-4] i.l.core.protocol.ReconnectionHandler : Reconnected to 192.168.36.131:6379 2022-11-14 22:20:58.040 INFO 8764 --- [nio-8081-exec-2] com.gz.redis.RedisTest : =====存储成功:test24,123===== 2022-11-14 22:20:59.051 INFO 8764 --- [nio-8081-exec-2] com.gz.redis.RedisTest : =====存储成功:test25,123===== 2022-11-14 22:21:00.057 INFO 8764 --- [nio-8081-exec-2] com.gz.redis.RedisTest : =====存储成功:test26,123===== 2022-11-14 22:21:01.065 INFO 8764 --- [nio-8081-exec-2] com.gz.redis.RedisTest : =====存储成功:test27,123===== 故障转移在多个哨兵的模式下,每个哨兵都会向redis节点发送心跳包来检测节点的运行状态。如果某个哨兵发现主节点连接超时了,没有收到心跳,那么系统并不会立刻进行故障转移,这种情况叫做 sentinel monitor master 192.168.36.128 6378 2 在故障转移前,需要选举出一个哨兵leader来进行Master节点的重新选举。哨兵的选举过程大致可以分为三步:
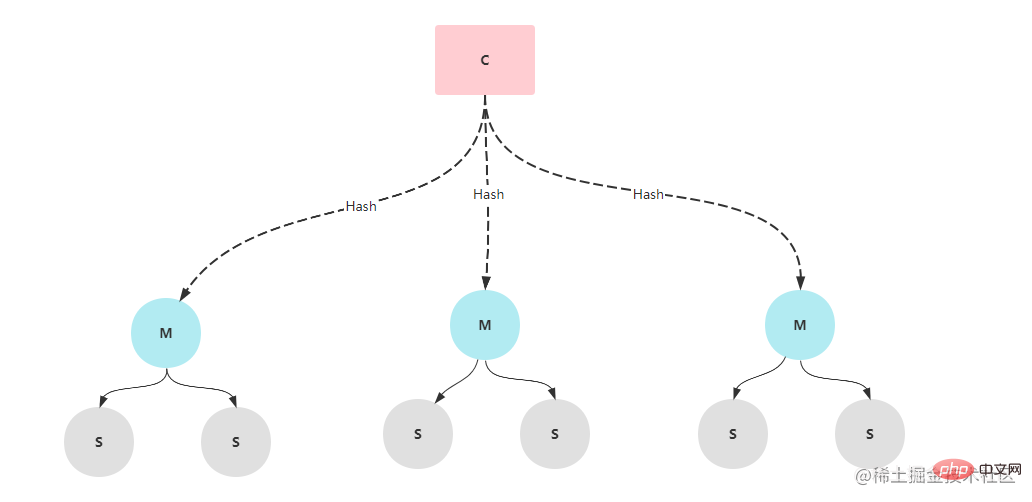
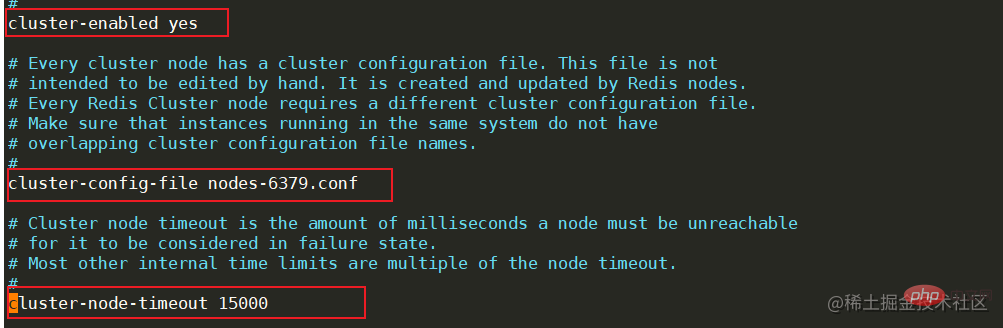
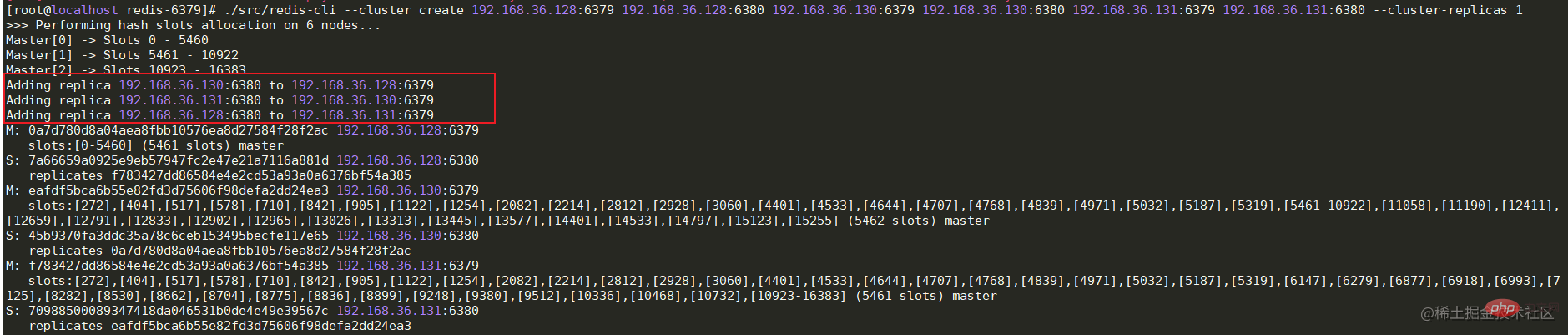
当选举出主哨兵后,那么这个主哨兵就会过滤掉宕机的redis节点,重新选举出Master节点。首先会根据redis节点的优先级进行选举(slave-priority),数值越大的从节点将会被选举为主节点。如果这个优先级相同,那么主哨兵节点就会选择数据最全的从节点作为新的主节点。如果还是选举失败,那么就会选举出进程id最小的从节点作为主节点。 脑裂在集群环境下会由于网络等原因出现脑裂的情况,所谓的脑裂就是由于主节点和从节点和哨兵处于不同的网络分区,由于网络波动等原因,使得哨兵没有能够即使接收到主节点的心跳,所以通过选举的方式选举了一个从节点为新的主节点,这样就存在了两个主节点,就像一个人有两个大脑一样,这样会导致客户端还在像老的主节点那里写入数据,新节点无法同步数据,当网络恢复后,哨兵会将老的主节点降为从节点,这时再从新主节点同步数据,这会导致大量数据丢失。如果需要避免脑裂的问题,可以配置下面两行信息。 min-replicas-to-write 3 # 最少从节点为3 min-replicas-max-lag 10 # 表示数据复制和同步的延迟不能超过10秒 优缺点优点:除了拥有主从复制的优点外,还可以进行故障转移,主从切换,系统更加可靠。 缺点:故障转移需要花费一定的时间,在高并发场景下容易出现数据丢失。不容易实现在线扩容。 Mode clusterEn mode sentinelle, bien que la commutation maître-esclave puisse être effectuée lorsque le nœud maître est en panne, le processus de commutation prend plus de dix secondes ou plus, ce qui entraînera la perte de certaines données. Si le degré de concurrence n'est pas élevé, vous pouvez utiliser ce mode cluster, mais en cas de concurrence élevée, ces dix secondes peuvent avoir de graves conséquences. Par conséquent, de nombreuses sociétés Internet utilisent l'architecture de cluster Cluster. Le cluster Cluster est composé de plusieurs nœuds Redis. Chaque nœud de service Redis possède un nœud maître et plusieurs nœuds esclaves. Lors du stockage des données, Redis effectuera une opération de hachage sur la clé des données et l'attribuera à différents emplacements en fonction des résultats de l'opération. . Peu. Dans des circonstances normales, l'architecture cluster Cluster nécessite 6 nœuds (trois maîtres et trois esclaves).
Configuration de l'environnementComme il n'y a que trois machines virtuelles, deux services Redis doivent être construits sur chaque serveur, avec les ports 6379 et 6380 respectivement. Cela peut créer 6 nœuds.
|


 搭建成功后,就来通过代码演示主节点宕机的情况下,哨兵是否会帮助系统自动进行主备切换。在springboot项目中引入对应的pom,并配置对应的redis哨兵信息。
搭建成功后,就来通过代码演示主节点宕机的情况下,哨兵是否会帮助系统自动进行主备切换。在springboot项目中引入对应的pom,并配置对应的redis哨兵信息。




Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Comment résoudre l'avalanche, la panne et la pénétration du cache Redis
- Que dois-je faire si PHP utilise Redis et que la mémoire est insuffisante ?
- Explication détaillée de la façon d'utiliser les verrous distribués Redis dans Laravel (avec des exemples de code)
- Structures de données couramment utilisées dans Redis (organisées et partagées)
- Comment utiliser Redis dans Node.js ? Il s'avère que c'est aussi simple que ça !