
Maison >base de données >Redis >Comment résoudre l'avalanche, la panne et la pénétration du cache Redis
Comment résoudre l'avalanche, la panne et la pénétration du cache Redis

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBavant
- 2022-11-03 17:23:551821parcourir
Cet article vous apporte des connaissances pertinentes sur Redis, qui explique principalement comment résoudre les problèmes liés à l'avalanche, à la panne et à la pénétration du cache Redis. Cela signifie qu'un grand nombre de requêtes ne peuvent pas accéder au cache dans Redis. c'est-à-dire que les données sont introuvables dans Redis ; jetons-y un coup d'œil, j'espère que cela sera utile à tout le monde.

Apprentissage recommandé : Tutoriel vidéo Redis
1. Cache avalanche
1.
Avalanche de cache signifie qu'un grand nombre de requêtes ne peuvent pas atteindre les données mises en cache dans Redis, c'est-à-dire que les données sont introuvables dans Redis, puis Le système métier ne peut interroger que la base de données, ce qui entraîne l'envoi de toutes les requêtes à la base de données. Comme le montre l'image ci-dessous : 缓存雪崩是指大量的请求无法命中Redis中的缓存数据,也就是在Redis找不到数据了,那业务系统只能到数据库中查询,进而导致所有的请求都发送到了数据库。如下图所示:

数据库并不像Redis能处理大量请求,由缓存雪崩导致的请求激增必须会导致数据库所在宕机,这样势必会影响业务系统,所以如果发生缓存雪崩,对于业务系统肯定是致命的。
2. 为什么发会生缓存雪崩?
什么情况下出现缓存雪崩呢?总结起来有以下两个方面的原因:
大量
Redis缓存数据同时过期,导致所有的发送到Redis请求都无法命中数据,只能到数据库中进行查询。Redis服务器宕机,所有请求都无法经Redis来处理,只能转向数据库查询数据。
3. 如何避免缓存雪崩?
针对导致缓存雪崩的原因,有不同的解决方法:
针对大量缓存随机过期时间,解决方法就是在原始过期时间的基础上,再加一个随机过期时间,比如1到5分钟之间的随机过期时间,这样可以避免大量的缓存数据在同一时间过期。
而针对
Redis解决宕机的导致的缓存雪崩,可以提前搭建好Redis的主从服务器进行数据同步,并配置哨兵机制,这样在Redis服务器因为宕机而无法提供服务时,可以由哨兵将Redis从服务器设置为主服务器,继续提供服务。
二、缓存击穿
1. 什么是缓存击穿
缓存击穿与缓存雪崩的情况相似,雪崩是因为大量的数据过期,而缓存击穿则是指热点数据过期,所有针对热点数据的请求都需要到数据库中进行处理,如下图所示:

2. 怎么避免缓存击穿?
解决缓存击穿的三种方式:
- 不设置过期时间
如果我们能提前知道某个数据是热点数据,那么就可以不设置这些数据的过期,从而避免缓存击穿问题,比如一些秒杀活动的商品,在秒杀时会大量用户访问,这时候我们就可以将这些用于秒杀的商品数据提前写入缓存并且不设置过期时间。
- 互斥锁
提前知道某些数据会有大量访问,我们当然可以设置不过期,但更多时候,我们并不能提前预知,这种情况要怎么处理呢?
我们来分析一下缓存击穿的情况:
正常情况下,当某个Redis缓存数据过期时,如果有对该数据的请求,则重新到数据库中查询并再写入缓存,让后续的请求可以命中该缓存而无须再去数据库中查询。
而热点数据过期时,由于大量请求,当某个请求无法命中缓存时,会去查询数据库并重新把数据写入Redis,也就是在写入Redis之前,其他请求进来,也会去查询数据库。
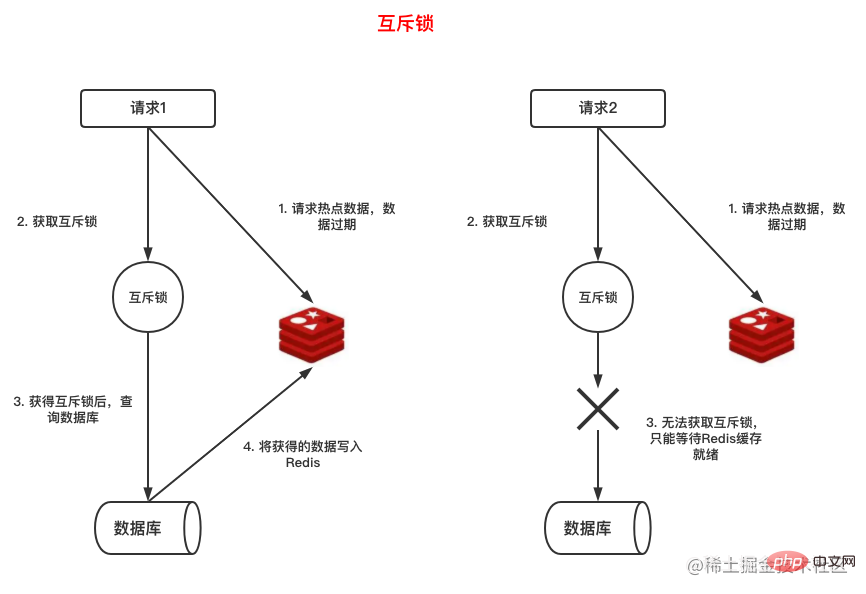
好了,我们知道热点数据过期后,很多请求会去查询数据库,那么我们可以给去查询数据库的业务逻辑加个互斥锁,只有获得锁的请求才能去查询数据库并把数据写回Redis
La base de données n'est pas comme
Redis qui peut gérer un grand nombre de requêtes. L'augmentation des requêtes provoquée par l'avalanche de cache entraînera certainement une panne de la base de données, ce qui affectera inévitablement le système métier. Par conséquent, si une avalanche de cache se produit, cela affectera certainement le système commercial et sera fatal.
2. Pourquoi une avalanche de cache se produit-elle ?  Dans quelles circonstances se produit une avalanche de cache ? Pour résumer, il y a deux raisons : 🎜
Dans quelles circonstances se produit une avalanche de cache ? Pour résumer, il y a deux raisons : 🎜
- 🎜Un grand nombre de données mises en cache
Redis ont expiré en même temps, provoquant l'envoi de toutes les requêtes à Redis pour ne pas atteindre les données, ne peut être interrogé que dans la base de données. 🎜
- 🎜Le serveur
Redis est en panne, toutes les requêtes ne peuvent pas être traitées par Redis et ne peuvent être tournées vers la base de données que pour interroger des données. 🎜
3. Comment éviter l'avalanche de cache ? 🎜🎜Il existe différentes solutions aux causes de l'avalanche de cache : 🎜
- 🎜Pour un grand nombre de délais d'expiration de cache aléatoires, la solution consiste à ajouter un délai d'expiration aléatoire au délai d'expiration d'origine, tel que 1 aléatoire délai d'expiration compris entre 5 minutes pour éviter qu'une grande quantité de données mises en cache n'expire en même temps. 🎜
- 🎜Pour résoudre l'avalanche de cache causée par le temps d'arrêt de
Redis, vous pouvez configurer le serveur maître-esclave de Redis à l'avance pour les données synchronisation et configurer le mécanisme Sentinel, de sorte que lorsque le serveur Redis n'est pas en mesure de fournir des services en raison d'un temps d'arrêt, Sentinel puisse définir le serveur esclave Redis sur le serveur maître et continuer à fournir des services. 🎜
2. Panne du cache 🎜1. Qu'est-ce que la panne du cache 🎜🎜 Panne du cache L'avalanche est similaire à l'avalanche de cache. L'avalanche est due à l'expiration d'une grande quantité de données, tandis que la panne du cache fait référence à l'expiration des données de point d'accès. Toutes les demandes de données de point d'accès doivent être traitées dans la base de données, comme indiqué dans le fichier. figure suivante : 🎜🎜🎜2. Comment éviter une panne de cache ? 🎜🎜Trois façons de résoudre une panne de cache : 🎜- Ne pas définir de délai d'expiration
🎜Si nous pouvons savoir à l'avance que certaines données sont des données chaudes, nous n'avons pas besoin de définir Ces données expirent, évitant ainsi le problème de panne du cache. Par exemple, certains produits des ventes flash seront accessibles par un grand nombre d'utilisateurs pendant la vente flash. À ce stade, nous pouvons écrire les données des produits pour les ventes flash dans le cache. avancez et ne fixez pas de délai d’expiration. 🎜- Verrou Mutex
🎜Sachant à l'avance que certaines données seront consultées en grande quantité, nous pouvons bien sûr le configurer pour qu'il n'expire pas, mais le plus souvent, nous ne pouvons pas prédire cette situation à l'avance Comment y faire face ? 🎜🎜Analysons la situation de panne du cache : 🎜🎜Dans des circonstances normales, lorsqu'une certaine donnée mise en cache Redis expire, s'il y a une demande pour les données, la base de données sera à nouveau interrogée, puis écrira dans le cache afin que les requêtes ultérieures puissent atteindre le cache sans interroger la base de données. 🎜🎜Lorsque les données du hotspot expirent, en raison d'un grand nombre de requêtes, lorsqu'une requête ne peut pas atteindre le cache, la base de données sera interrogée et les données seront à nouveau écrites dans Redis, c'est-à-dire lorsque écrire Redis Avant que d'autres requêtes n'arrivent, la base de données sera également interrogée. 🎜🎜D'accord, nous savons qu'après l'expiration des données du hotspot, de nombreuses requêtes interrogeront la base de données, nous pouvons donc ajouter un verrou mutex à la logique métier d'interrogation de la base de données. Seules les requêtes qui obtiennent le verrou peuvent interroger la base de données et écrire les données. backRedis, tandis que les autres requêtes qui n'ont pas obtenu le verrou ne peuvent qu'attendre que les données soient prêtes. 🎜🎜Les étapes ci-dessus sont présentées dans l'image ci-dessous : 🎜🎜🎜🎜- Définir le délai d'expiration logique
 Dans quelles circonstances se produit une avalanche de cache ? Pour résumer, il y a deux raisons : 🎜
Dans quelles circonstances se produit une avalanche de cache ? Pour résumer, il y a deux raisons : 🎜Redis ont expiré en même temps, provoquant l'envoi de toutes les requêtes à Redis pour ne pas atteindre les données, ne peut être interrogé que dans la base de données. 🎜Redis est en panne, toutes les requêtes ne peuvent pas être traitées par Redis et ne peuvent être tournées vers la base de données que pour interroger des données. 🎜- 🎜Pour un grand nombre de délais d'expiration de cache aléatoires, la solution consiste à ajouter un délai d'expiration aléatoire au délai d'expiration d'origine, tel que 1 aléatoire délai d'expiration compris entre 5 minutes pour éviter qu'une grande quantité de données mises en cache n'expire en même temps. 🎜
- 🎜Pour résoudre l'avalanche de cache causée par le temps d'arrêt de
Redis, vous pouvez configurer le serveur maître-esclave deRedisà l'avance pour les données synchronisation et configurer le mécanisme Sentinel, de sorte que lorsque le serveurRedisn'est pas en mesure de fournir des services en raison d'un temps d'arrêt, Sentinel puisse définir le serveur esclaveRedissur le serveur maître et continuer à fournir des services. 🎜
2. Panne du cache 🎜1. Qu'est-ce que la panne du cache 🎜🎜 Panne du cache L'avalanche est similaire à l'avalanche de cache. L'avalanche est due à l'expiration d'une grande quantité de données, tandis que la panne du cache fait référence à l'expiration des données de point d'accès. Toutes les demandes de données de point d'accès doivent être traitées dans la base de données, comme indiqué dans le fichier. figure suivante : 🎜🎜🎜2. Comment éviter une panne de cache ? 🎜🎜Trois façons de résoudre une panne de cache : 🎜- Ne pas définir de délai d'expiration
🎜Si nous pouvons savoir à l'avance que certaines données sont des données chaudes, nous n'avons pas besoin de définir Ces données expirent, évitant ainsi le problème de panne du cache. Par exemple, certains produits des ventes flash seront accessibles par un grand nombre d'utilisateurs pendant la vente flash. À ce stade, nous pouvons écrire les données des produits pour les ventes flash dans le cache. avancez et ne fixez pas de délai d’expiration. 🎜- Verrou Mutex
🎜Sachant à l'avance que certaines données seront consultées en grande quantité, nous pouvons bien sûr le configurer pour qu'il n'expire pas, mais le plus souvent, nous ne pouvons pas prédire cette situation à l'avance Comment y faire face ? 🎜🎜Analysons la situation de panne du cache : 🎜🎜Dans des circonstances normales, lorsqu'une certaine donnée mise en cache Redis expire, s'il y a une demande pour les données, la base de données sera à nouveau interrogée, puis écrira dans le cache afin que les requêtes ultérieures puissent atteindre le cache sans interroger la base de données. 🎜🎜Lorsque les données du hotspot expirent, en raison d'un grand nombre de requêtes, lorsqu'une requête ne peut pas atteindre le cache, la base de données sera interrogée et les données seront à nouveau écrites dans Redis, c'est-à-dire lorsque écrire Redis Avant que d'autres requêtes n'arrivent, la base de données sera également interrogée. 🎜🎜D'accord, nous savons qu'après l'expiration des données du hotspot, de nombreuses requêtes interrogeront la base de données, nous pouvons donc ajouter un verrou mutex à la logique métier d'interrogation de la base de données. Seules les requêtes qui obtiennent le verrou peuvent interroger la base de données et écrire les données. backRedis, tandis que les autres requêtes qui n'ont pas obtenu le verrou ne peuvent qu'attendre que les données soient prêtes. 🎜🎜Les étapes ci-dessus sont présentées dans l'image ci-dessous : 🎜🎜🎜🎜- Définir le délai d'expiration logique
🎜2. Comment éviter une panne de cache ? 🎜🎜Trois façons de résoudre une panne de cache : 🎜- Ne pas définir de délai d'expiration
🎜Si nous pouvons savoir à l'avance que certaines données sont des données chaudes, nous n'avons pas besoin de définir Ces données expirent, évitant ainsi le problème de panne du cache. Par exemple, certains produits des ventes flash seront accessibles par un grand nombre d'utilisateurs pendant la vente flash. À ce stade, nous pouvons écrire les données des produits pour les ventes flash dans le cache. avancez et ne fixez pas de délai d’expiration. 🎜- Verrou Mutex
🎜Sachant à l'avance que certaines données seront consultées en grande quantité, nous pouvons bien sûr le configurer pour qu'il n'expire pas, mais le plus souvent, nous ne pouvons pas prédire cette situation à l'avance Comment y faire face ? 🎜🎜Analysons la situation de panne du cache : 🎜🎜Dans des circonstances normales, lorsqu'une certaine donnée mise en cache Redis expire, s'il y a une demande pour les données, la base de données sera à nouveau interrogée, puis écrira dans le cache afin que les requêtes ultérieures puissent atteindre le cache sans interroger la base de données. 🎜🎜Lorsque les données du hotspot expirent, en raison d'un grand nombre de requêtes, lorsqu'une requête ne peut pas atteindre le cache, la base de données sera interrogée et les données seront à nouveau écrites dans Redis, c'est-à-dire lorsque écrire Redis Avant que d'autres requêtes n'arrivent, la base de données sera également interrogée. 🎜🎜D'accord, nous savons qu'après l'expiration des données du hotspot, de nombreuses requêtes interrogeront la base de données, nous pouvons donc ajouter un verrou mutex à la logique métier d'interrogation de la base de données. Seules les requêtes qui obtiennent le verrou peuvent interroger la base de données et écrire les données. backRedis, tandis que les autres requêtes qui n'ont pas obtenu le verrou ne peuvent qu'attendre que les données soient prêtes. 🎜🎜Les étapes ci-dessus sont présentées dans l'image ci-dessous : 🎜🎜🎜🎜- Définir le délai d'expiration logique
Bien que l'utilisation d'un verrou mutex puisse résoudre très simplement le problème de panne de cache, les demandes qui n'obtiennent pas le verrou sont mises en file d'attente et attendent, ce qui affecte les performances du système. Il existe une autre façon de résoudre. le problème de panne du cache. La méthode consiste à ajouter un délai d'expiration aux données métier. Par exemple, dans les données suivantes, nous avons ajouté le champ expire_at pour indiquer le délai d'expiration des données. expire_at字段用于表示数据过期时间。
{"name":"test","expire_at":"1599999999"}复制代码
这种方式的实现过程如下图所示:
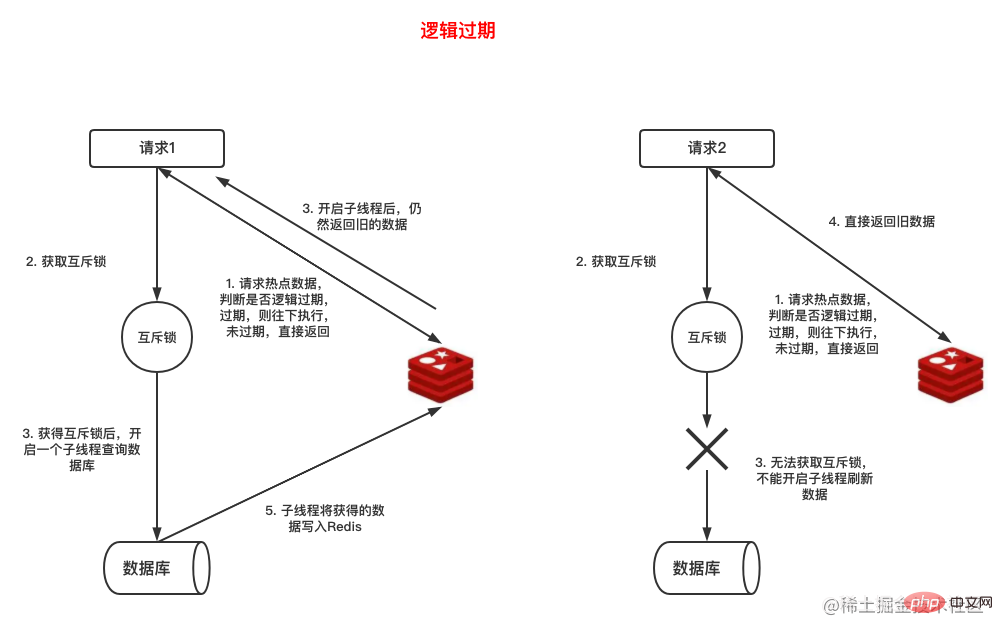
缓存中的热点数据中冗余一个逻辑过期时间,但数据在Redis不设置过期时间
当一个请求拿到Redis中的数据时,判断逻辑过期时间是否到期,如果没有到期,直接返回,如果到期则开启另一个线程获得锁后去查询数据库并将查询的最新数据写回Redis,而当前请求返回已经查询的数据。
三、缓存穿透
1. 什么是缓存穿透
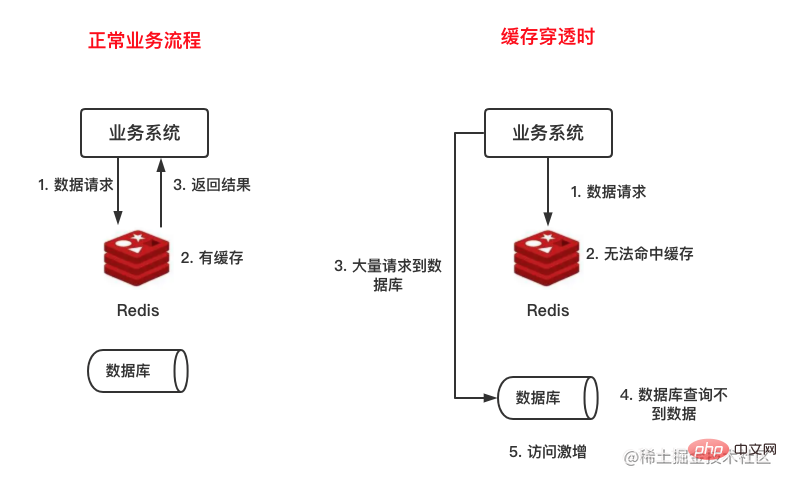
缓存穿透是指要查找的数据既不在缓存当中,也不在数据库中,因为不在缓存中,所以请求一定会到达数据库,Redis缓存形同虚设,如下图所示:
2. 为什么会发生缓存穿透
什么条件下会发生缓存穿透呢?主要有以下三种情况:
用户恶意攻击请求
误操作把
Redis和数据库里的数据删除了用户还未产生内容时,比如用户的文章列表,用户还未写文章,所以缓存和数据库都没有数据
3. 如何避免缓存穿透?
a. 缓存空值或缺省值
当在Redis缓存中查询不到数据时,再从数据库查询,如果同样没有数据,就直接缓存一个空间或缺省值,这样可以避免下次再去查询数据库;不过为了防止之后已经数据库已经相应数据库,再返回空值问题,应该为缓存设置过期时间,或者在产生数据时直接清除对应的缓存空值。
b. 布隆过滤器
虽然缓存空值可以解决缓存穿透问题,但仍然需要查询一次数据库才能确定是否有数据,如果有用户恶意攻击,高并发地使用系统不存在的数据id进行查询,所有的查询都要经过数据库,这样仍然会给数据库带来很大的压力。
所以,有没有不用查询数据库就能确定数据是否存在的办法呢?有的,用布隆过滤器。
布隆过滤器主要是两个部分:bit数组+N个哈希函数,其原理为:
使用N个哈希函数对所要标记的数据进行哈希值计算。
将计算到的哈希值对bit数组的长度取模,这样可以得到每个哈希值在bit数组的位置。
把bit数组中对应的位置标记为1。
下面是布隆过滤器原理示意图:

当要进行数据写入时,执行述述步骤,计算对应bit数组位置并标识为1,那么在执行查询时,就能查询该数据是否存在了。
另外,由于哈希碰撞问题导致的误差,所以不存在的数据经过布隆过滤器后,会被判定为存在,再去查数据库,不过哈希碰到的概率很小,用布隆过滤器已经能帮我们拦截大部分的穿透请求了。
Redis本身就支持布隆过滤器,所以我们可以直接使用Redis布隆过滤器,而不用自己去实现,非常方便。
四、小结
缓存的雪崩、击穿、穿透是在业务应用缓存时经常会碰到的缓存异常问题,其原因与解决方法如以下表示所示:
| 问题 | 原因 | 解决方法 |
|---|---|---|
| 缓存雪崩 | 大量数据过期或Redis服务器宕机 |
1. 随机过期时间 2. 主从+哨兵的集群 |
| 缓存击穿 | 热点数据过期 | 1. 不设置过期时间 2. 加互斥锁 3. 冗余逻辑过期时间 |
| 缓存穿透 | 请求数据库和Redisrrreee | Le processus de mise en œuvre de cette méthode est illustré dans la figure ci-dessous :
Lors d'une requête obtient Redis, déterminez si le délai d'expiration logique a expiré. S'il n'a pas expiré, revenez directement. S'il a expiré, démarrez un autre thread pour obtenir le verrou, interrogez la base de données et écrivez les dernières données interrogées. revient à <code>Redis et la requête actuelle renvoie les données qui ont été interrogées. 3. Pénétration du cache
1. Qu'est-ce que la pénétration du cache
La pénétration du cache signifie que les données à trouver ne sont ni dans le cache ni dans la base de données. Comme elles ne sont pas dans le cache, la requête atteindra définitivement la base de données. Le cache Redis est inutile, comme le montre la figure suivante. :
🎜2. Pourquoi la pénétration du cache se produit-elle
🎜Dans quelles conditions la pénétration du cache se produit-elle ? On distingue principalement les trois situations suivantes : 🎜🎜🎜🎜Demande d'attaque malveillante de la part de l'utilisateur🎜🎜🎜🎜Opération incorrecte pour supprimerRedis et les données de la base de données🎜🎜🎜🎜Lorsque l'utilisateur n'a pas encore généré contenu, tel que l'utilisateur La liste des articles, l'utilisateur n'a pas encore écrit d'article, il n'y a donc pas de données dans le cache et la base de données 🎜🎜🎜3 Comment éviter le cache. pénétration?
a. Mettre en cache la valeur vide ou la valeur par défaut
🎜Lorsque les données ne peuvent pas être interrogées dans le cacheRedis, récupérez-les from Pour les requêtes de base de données, s'il n'y a pas de données, mettez simplement en cache un espace ou une valeur par défaut directement, afin d'éviter d'interroger la base de données la prochaine fois, cependant, afin d'éviter le problème du retour de valeurs nulles lorsque la base de données a déjà correspondu ; à la base de données, le délai d'expiration doit être défini pour le cache ou effacer directement la valeur nulle du cache correspondante lors de la génération des données. 🎜b. Filtre Bloom
🎜Bien que la mise en cache des valeurs nulles puisse résoudre le problème de pénétration du cache, elle doit toujours interroger la base de données une fois pour déterminer s'il existe des données. S'il y a un utilisateur, les attaques malveillantes utilisent des identifiants de données qui n'existent pas dans le système pour interroger avec une concurrence élevée. Toutes les requêtes doivent passer par la base de données, ce qui exercera toujours une forte pression sur la base de données. 🎜🎜Alors, existe-t-il un moyen de déterminer si les données existent sans interroger la base de données ? Oui, utilisez leFiltre Bloom. 🎜🎜Le filtre Bloom se compose principalement de deux parties : tableau de bits + N fonctions de hachage. Son principe est : 🎜🎜🎜🎜Utiliser N fonctions de hachage pour calculer la valeur de hachage des données à marquer. 🎜🎜🎜🎜 Prenez la valeur de hachage calculée modulo la longueur du tableau de bits, afin que la position de chaque valeur de hachage dans le tableau de bits puisse être obtenue. 🎜🎜🎜🎜 Marquez la position correspondante dans le tableau de bits comme 1. 🎜🎜🎜🎜Ce qui suit est un diagramme schématique du principe du filtre Bloom : 🎜🎜🎜🎜Lorsque les données doivent être écrites, effectuez les étapes décrites ci-dessus, calculez la position du tableau de bits correspondant et marquez-la comme 1, puis lors de l'exécution de la requête, vous pouvez demander si les données existent . 🎜🎜De plus, en raison d'erreurs causées par des problèmes de collision de hachage, les données inexistantes seront jugées exister après avoir traversé le filtre Bloom, puis vérifié la base de données. Cependant, la probabilité de rencontre de hachage est très faible, utilisez donc Bloom. filter Le serveur peut déjà nous aider à intercepter la plupart des demandes de pénétration. 🎜🎜Redis lui-même prend en charge les filtres Bloom, nous pouvons donc utiliser directement les filtres Redis Bloom sans avoir à les implémenter nous-mêmes, ce qui est très pratique. 🎜IV. Résumé
🎜L'avalanche, la panne et la pénétration du cache sont des problèmes d'exception de cache qui sont souvent rencontrés lors de la mise en cache des applications métier. Leurs causes et solutions, comme indiqué ci-dessous. représentation : 🎜| Problème | Cause | Solution | 🎜
|---|---|---|
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Explication du principe de la stratégie de suppression de clé expirée de Redis
- Un article expliquant en détail comment utiliser Redis pour implémenter des verrous distribués
- Une brève discussion sur les raisons pour lesquelles Redis est lent et comment le résoudre
- Résumé de cinq façons d'implémenter des verrous distribués dans Redis
- Explication détaillée de la traversée des clés Redis et de la gestion de la base de données