
Maison >interface Web >js tutoriel >Un article sur les flux lisibles dans Node
Un article sur les flux lisibles dans Node

- 青灯夜游avant
- 2023-02-02 20:12:531997parcourir
Cet article vous guidera à travers l'interprétation du code source du flux Node.js, une compréhension plus approfondie du flux lisible Node et un aperçu de ses principes de base, de son utilisation et de son mécanisme de fonctionnement. J'espère qu'il vous sera utile !

1. Concepts de base
1.1. Evolution historique des streams
Les streams ne sont pas un concept propre à Nodejs. Ils ont été introduits il y a des décennies dans le système d'exploitation Unix et les programmes peuvent interagir les uns avec les autres sur les flux via l'opérateur de canal (|).
L'opérateur pipe (|) peut être utilisé sous MacOS et Linux basés sur les systèmes Unix. Il peut convertir la sortie du processus sur le côté gauche de l'opérateur en entrée sur le côté droit.
Dans Node, si nous utilisons le readFile traditionnel pour lire un fichier, le fichier sera lu dans la mémoire du début à la fin. Lorsque tout le contenu aura été lu, le contenu du fichier chargé dans la mémoire sera unifié. traiter avec.
Il y aura deux inconvénients à faire cela :
Mémoire : cela prend beaucoup de mémoire
Temps : vous devez attendre que la totalité de la charge utile des données soit chargée avant de commencer à traiter les données
Afin de résoudre les problèmes ci-dessus, Node.js imite et implémente le concept de flux. Dans les flux Node.js, il existe quatre types de flux. Ce sont tous des instances d'EventEmitter dans Node.js :
- .
Readable Stream (Readable Stream)
Writable Stream
Readable Full-Duplex Stream (Duplex Stream)
Transform Stream
Afin d'apprendre cette partie du contenu en profondeur, étape par étape Comprendre le concept de flux dans Node.js, et comme la partie code source est relativement complexe, j'ai décidé de commencer à apprendre cette partie à partir du flux lisible.
1.2. Qu'est-ce qu'un flux ?
Un flux est une structure de données abstraite et une collection de données qui y sont stockées ne peuvent être que les types suivants (uniquement dans le cas de objectMode ===). false ):
- string
- Buffer
Nous pouvons considérer le flux comme une collection de ces données, tout comme les liquides. Nous sauvegardons d'abord ces liquides dans un conteneur (le tampon interne BufferList du flux), et attendons. jusqu'à ce que le correspondant Lorsque l'événement est déclenché, nous versons le liquide à l'intérieur dans le tuyau et informons les autres d'utiliser leurs propres conteneurs de l'autre côté du tuyau pour récupérer le liquide à l'intérieur pour le traitement.

1.3. Qu'est-ce que le flux lisible ?
Le flux lisible est un type de flux. Il a deux modes et trois états
Deux modes de lecture :
Mode flux : les données seront lues. du système sous-jacent et transmis au gestionnaire d'événements enregistré le plus rapidement possible via EventEmitter
Mode Pause : dans ce mode, les données ne seront pas lues et doivent être affichées. Appelez la méthode Stream.read() pour lire les données de le flux
Trois états :
readableFlowing === null : L'appel de Stream.pipe() et Stream.resume fera passer son statut à true, commencera à générer des données et se déclenchera activement. events
readableFlowing === false : À ce moment, le flux de données sera suspendu, mais la génération de données ne sera pas suspendue, donc un retard de données se produira
readableFlowing = == TRUE : Normal et données consommées
2. Principe de base
2.1. Définition de l'état interne (ReadableState)
ReadableState
_readableState: ReadableState {
objectMode: false, // 操作除了string、Buffer、null之外的其他类型的数据需要把这个模式打开
highWaterMark: 16384, // 水位限制,1024 \* 16,默认16kb,超过这个限制则会停止调用\_read()读数据到buffer中
buffer: BufferList { head: null, tail: null, length: 0 }, // Buffer链表,用于保存数据
length: 0, // 整个可读流数据的大小,如果是objectMode则与buffer.length相等
pipes: [], // 保存监听了该可读流的所有管道队列
flowing: null, // 可独流的状态 null、false、true
ended: false, // 所有数据消费完毕
endEmitted: false, // 结束事件收否已发送
reading: false, // 是否正在读取数据
constructed: true, // 流在构造好之前或者失败之前,不能被销毁
sync: true, // 是否同步触发'readable'/'data'事件,或是等到下一个tick
needReadable: false, // 是否需要发送readable事件
emittedReadable: false, // readable事件发送完毕
readableListening: false, // 是否有readable监听事件
resumeScheduled: false, // 是否调用过resume方法
errorEmitted: false, // 错误事件已发送
emitClose: true, // 流销毁时,是否发送close事件
autoDestroy: true, // 自动销毁,在'end'事件触发后被调用
destroyed: false, // 流是否已经被销毁
errored: null, // 标识流是否报错
closed: false, // 流是否已经关闭
closeEmitted: false, // close事件是否已发送
defaultEncoding: 'utf8', // 默认字符编码格式
awaitDrainWriters: null, // 指向监听了'drain'事件的writer引用,类型为null、Writable、Set<Writable>
multiAwaitDrain: false, // 是否有多个writer等待drain事件
readingMore: false, // 是否可以读取更多数据
dataEmitted: false, // 数据已发送
decoder: null, // 解码器
encoding: null, // 编码器
[Symbol(kPaused)]: null
},2.2.
BufferList est un conteneur utilisé pour que les flux stockent des données internes. Il est conçu sous la forme d'une liste chaînée et possède trois attributs : tête, queue et longueur.
Je représente chaque nœud de la BufferList en tant que BufferNode, et le type de données à l'intérieur dépend du mode objet.
Cette structure de données obtient les données d'en-tête plus rapidement que Array.prototype.shift().
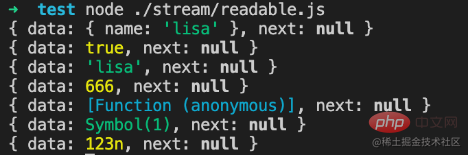
2.2.1. Type de stockage des données
Si objectMode === true :
alors les données peuvent être de n'importe quel type, et quelles que soient les données poussées, elles seront stockées
objectMode =true
const Stream = require('stream');
const readableStream = new Stream.Readable({
objectMode: true,
read() {},
});
readableStream.push({ name: 'lisa'});
console.log(readableStream._readableState.buffer.tail);
readableStream.push(true);
console.log(readableStream._readableState.buffer.tail);
readableStream.push('lisa');
console.log(readableStream._readableState.buffer.tail);
readableStream.push(666);
console.log(readableStream._readableState.buffer.tail);
readableStream.push(() => {});
console.log(readableStream._readableState.buffer.tail);
readableStream.push(Symbol(1));
console.log(readableStream._readableState.buffer.tail);
readableStream.push(BigInt(123));
console.log(readableStream._readableState.buffer.tail);Run result:
If objectMode === false:
alors les données ne peuvent être qu'une chaîne ou Buffer ou Uint8Array
objectMode=false
const Stream = require('stream');
const readableStream = new Stream.Readable({
objectMode: false,
read() {},
});
readableStream.push({ name: 'lisa'});Run result:

2.2.2. 数据存储结构
我们在控制台通过node命令行创建一个可读流,来观察buffer中数据的变化:

当然在push数据之前我们需要实现他的_read方法,或者在构造函数的参数中实现read方法:
const Stream = require('stream');
const readableStream = new Stream.Readable();
RS._read = function(size) {}或者
const Stream = require('stream');
const readableStream = new Stream.Readable({
read(size) {}
});经过readableStream.push('abc')操作之后,当前的buffer为:
可以看到目前的数据存储了,头尾存储的数据都是字符串'abc'的ascii码,类型为Buffer类型,length表示当前保存的数据的条数而非数据内容的大小。
2.2.3. 相关API
打印一下BufferList的所有方法可以得到:

除了join是将BufferList序列化为字符串之外,其他都是对数据的存取操作。
这里就不一一讲解所有的方法了,重点讲一下其中的consume 、_getString和_getBuffer。
2.2.3.1. consume
源码地址:BufferList.consume https://github.com/nodejs/node/blob/d5e94fa7121c9d424588f0e1a388f8c72c784622/lib/internal/streams/buffer_list.js#L80
comsume
// Consumes a specified amount of bytes or characters from the buffered data.
consume(n, hasStrings) {
const data = this.head.data;
if (n < data.length) {
// `slice` is the same for buffers and strings.
const slice = data.slice(0, n);
this.head.data = data.slice(n);
return slice;
}
if (n === data.length) {
// First chunk is a perfect match.
return this.shift();
}
// Result spans more than one buffer.
return hasStrings ? this.\_getString(n) : this.\_getBuffer(n);
}代码一共有三个判断条件:
如果所消耗的数据的字节长度小于链表头节点存储数据的长度,则将头节点的数据取前n字节,并把当前头节点的数据设置为切片之后的数据
如果所消耗的数据恰好等于链表头节点所存储的数据的长度,则直接返回当前头节点的数据

如果所消耗的数据的长度大于链表头节点的长度,那么会根据传入的第二个参数进行最后一次判断,判断当前的BufferList底层存储的是string还是Buffer
2.2.3.2. _getBuffer
源码地址:BufferList._getBuffer https://github.com/nodejs/node/blob/d5e94fa7121c9d424588f0e1a388f8c72c784622/lib/internal/streams/buffer_list.js#L137
comsume
// Consumes a specified amount of bytes from the buffered data.
_getBuffer(n) {
const ret = Buffer.allocUnsafe(n);
const retLen = n;
let p = this.head;
let c = 0;
do {
const buf = p.data;
if (n > buf.length) {
TypedArrayPrototypeSet(ret, buf, retLen - n);
n -= buf.length;
} else {
if (n === buf.length) {
TypedArrayPrototypeSet(ret, buf, retLen - n);
++c;
if (p.next)
this.head = p.next;
else
this.head = this.tail = null;
} else {
TypedArrayPrototypeSet(ret,
new Uint8Array(buf.buffer, buf.byteOffset, n),
retLen - n);
this.head = p;
p.data = buf.slice(n);
}
break;
}
++c;
} while ((p = p.next) !== null);
this.length -= c;
return ret;
}总的来说就是循环对链表中的节点进行操作,新建一个Buffer数组用于存储返回的数据。
首先从链表的头节点开始取数据,不断的复制到新建的Buffer中,直到某一个节点的数据大于等于要取的长度减去已经取得的长度。
或者说读到链表的最后一个节点后,都还没有达到要取的长度,那么就返回这个新建的Buffer。
2.2.3.3. _getString
源码地址:BufferList._getString https://github.com/nodejs/node/blob/d5e94fa7121c9d424588f0e1a388f8c72c784622/lib/internal/streams/buffer_list.js#L106
comsume
// Consumes a specified amount of characters from the buffered data.
_getString(n) {
let ret = '';
let p = this.head;
let c = 0;
do {
const str = p.data;
if (n > str.length) {
ret += str;
n -= str.length;
} else {
if (n === str.length) {
ret += str;
++c;
if (p.next)
this.head = p.next;
else
this.head = this.tail = null;
} else {
ret += StringPrototypeSlice(str, 0, n);
this.head = p;
p.data = StringPrototypeSlice(str, n);
}
break;
}
++c;
} while ((p = p.next) !== null);
this.length -= c;
return ret;
}对于操作字符串来说和操作Buffer是一样的,也是循环从链表的头部开始读数据,只是进行数据的拷贝存储方面有些差异,还有就是_getString操作返回的数据类型是string类型。
2.3. 为什么可读流是EventEmitter的实例?
对于这个问题而言,首先要了解什么是发布订阅模式,发布订阅模式在大多数API中都有重要的应用,无论是Promise还是Redux,基于发布订阅模式实现的高级API随处可见。
它的优点在于能将事件的相关回调函数存储到队列中,然后在将来的某个时刻通知到对方去处理数据,从而做到关注点分离,生产者只管生产数据和通知消费者,而消费者则只管处理对应的事件及其对应的数据,而Node.js流模式刚好符合这一特点。
那么Node.js流是怎样实现基于EventEmitter创建实例的呢?
这部分源码在这儿:stream/legacy https://github.com/nodejs/node/blob/d5e94fa7121c9d424588f0e1a388f8c72c784622/lib/internal/streams/legacy.js#L10
legacy
function Stream(opts) {
EE.call(this, opts);
}
ObjectSetPrototypeOf(Stream.prototype, EE.prototype);
ObjectSetPrototypeOf(Stream, EE);然后在可读流的源码中有这么几行代码:
这部分源码在这儿:readable https://github.com/nodejs/node/blob/d5e94fa7121c9d424588f0e1a388f8c72c784622/lib/internal/streams/readable.js#L77
legacy
ObjectSetPrototypeOf(Readable.prototype, Stream.prototype); ObjectSetPrototypeOf(Readable, Stream);
首先将Stream的原型对象继承自EventEmitter,这样Stream的所有实例都可以访问到EventEmitter上的方法。
同时通过ObjectSetPrototypeOf(Stream, EE)将EventEmitter上的静态方法也继承过来,并在Stream的构造函数中,借用构造函数EE来实现所有EventEmitter中的属性的继承,然后在可读流里,用同样的的方法实现对Stream类的原型继承和静态属性继承,从而得到:
Readable.prototype.__proto__ === Stream.prototype;
Stream.prototype.__proto__ === EE.prototype
因此:
Readable.prototype.__proto__.__proto__ === EE.prototype
所以捋着可读流的原型链可以找到EventEmitter的原型,实现对EventEmitter的继承
2.4. 相关API的实现
这里会按照源码文档中API的出现顺序来展示,且仅解读其中的核心API实现。
注:此处仅解读Node.js可读流源码中所声明的函数,不包含外部引入的函数定义,同时为了减少篇幅,不会将所有代码都拷贝下来。
Readable.prototype
Stream {
destroy: [Function: destroy],
_undestroy: [Function: undestroy],
_destroy: [Function (anonymous)],
push: [Function (anonymous)],
unshift: [Function (anonymous)],
isPaused: [Function (anonymous)],
setEncoding: [Function (anonymous)],
read: [Function (anonymous)],
_read: [Function (anonymous)],
pipe: [Function (anonymous)],
unpipe: [Function (anonymous)],
on: [Function (anonymous)],
addListener: [Function (anonymous)],
removeListener: [Function (anonymous)],
off: [Function (anonymous)],
removeAllListeners: [Function (anonymous)],
resume: [Function (anonymous)],
pause: [Function (anonymous)],
wrap: [Function (anonymous)],
iterator: [Function (anonymous)],
[Symbol(nodejs.rejection)]: [Function (anonymous)],
[Symbol(Symbol.asyncIterator)]: [Function (anonymous)]
}2.4.1. push
readable.push
Readable.prototype.push = function(chunk, encoding) {
return readableAddChunk(this, chunk, encoding, false);
};push方法的主要作用就是将数据块通过触发'data'事件传递给下游管道,或者将数据存储到自身的缓冲区中。
以下代码为相关伪代码,仅展示主流程:
readable.push
function readableAddChunk(stream, chunk, encoding, addToFront) {
const state = stream.\_readableState;
if (chunk === null) { // push null 流结束信号,之后不能再写入数据
state.reading = false;
onEofChunk(stream, state);
} else if (!state.objectMode) { // 如果不是对象模式
if (typeof chunk === 'string') {
chunk = Buffer.from(chunk);
} else if (chunk instanceof Buffer) { //如果是Buffer
// 处理一下编码
} else if (Stream.\_isUint8Array(chunk)) {
chunk = Stream.\_uint8ArrayToBuffer(chunk);
} else if (chunk != null) {
err = new ERR\_INVALID\_ARG\_TYPE('chunk', ['string', 'Buffer', 'Uint8Array'], chunk);
}
}
if (state.objectMode || (chunk && chunk.length > 0)) { // 是对象模式或者chunk是Buffer
// 这里省略几种数据的插入方式的判断
addChunk(stream, state, chunk, true);
}
}
function addChunk(stream, state, chunk, addToFront) {
if (state.flowing && state.length === 0 && !state.sync &&
stream.listenerCount('data') > 0) { // 如果处于流动模式,有监听data的订阅者
stream.emit('data', chunk);
} else { // 否则保存数据到缓冲区中
state.length += state.objectMode ? 1 : chunk.length;
if (addToFront) {
state.buffer.unshift(chunk);
} else {
state.buffer.push(chunk);
}
}
maybeReadMore(stream, state); // 尝试多读一点数据
}push操作主要分为对objectMode的判断,不同的类型对传入的数据会做不同的操作:
- objectMode === false: 将数据(chunk)转换成Buffer
- objectMode === true: 将数据原封不动的传递给下游
其中addChunk的第一个判断主要是处理Readable处于流动模式、有data监听器、并且缓冲区数据为空时的情况。
这时主要将数据passthrough透传给订阅了data事件的其他程序,否则就将数据保存到缓冲区里面。
2.4.2. read
除去对边界条件的判断、流状态的判断,这个方法主要有两个操作
调用用户实现的_read方法,对执行结果进行处理
从缓冲区buffer中读取数据,并触发'data'事件
readable.read
// 如果read的长度大于hwm,则会重新计算hwm
if (n > state.highWaterMark) {
state.highWaterMark = computeNewHighWaterMark(n);
}
// 调用用户实现的\_read方法
try {
const result = this.\_read(state.highWaterMark);
if (result != null) {
const then = result.then;
if (typeof then === 'function') {
then.call(
result,
nop,
function(err) {
errorOrDestroy(this, err);
});
}
}
} catch (err) {
errorOrDestroy(this, err);
}如果说用户实现的_read方法返回的是一个promise,则调用这个promise的then方法,将成功和失败的回调传入,便于处理异常情况。
read方法从缓冲区里读区数据的核心代码如下:
readable.read
function fromList(n, state) {
// nothing buffered.
if (state.length === 0)
return null;
let ret;
if (state.objectMode)
ret = state.buffer.shift();
else if (!n || n >= state.length) { // 处理n为空或者大于缓冲区的长度的情况
// Read it all, truncate the list.
if (state.decoder) // 有解码器,则将结果序列化为字符串
ret = state.buffer.join('');
else if (state.buffer.length === 1) // 只有一个数据,返回头节点数据
ret = state.buffer.first();
else // 将所有数据存储到一个Buffer中
ret = state.buffer.concat(state.length);
state.buffer.clear(); // 清空缓冲区
} else {
// 处理读取长度小于缓冲区的情况
ret = state.buffer.consume(n, state.decoder);
}
return ret;
}2.4.3. _read
用户初始化Readable stream时必须实现的方法,可以在这个方法里调用push方法,从而持续的触发read方法,当我们push null时可以停止流的写入操作。
示例代码:
readable._read
const Stream = require('stream');
const readableStream = new Stream.Readable({
read(hwm) {
this.push(String.fromCharCode(this.currentCharCode++));
if (this.currentCharCode > 122) {
this.push(null);
}
},
});
readableStream.currentCharCode = 97;
readableStream.pipe(process.stdout);
// abcdefghijklmnopqrstuvwxyz%2.4.4. pipe(重要)
将一个或多个writable流绑定到当前的Readable流上,并且将Readable流切换到流动模式。
这个方法里面有很多的事件监听句柄,这里不会一一介绍:
readable.pipe
Readable.prototype.pipe = function(dest, pipeOpts) {
const src = this;
const state = this.\_readableState;
state.pipes.push(dest); // 收集Writable流
src.on('data', ondata);
function ondata(chunk) {
const ret = dest.write(chunk);
if (ret === false) {
pause();
}
}
// Tell the dest that it's being piped to.
dest.emit('pipe', src);
// 启动流,如果流处于暂停模式
if (dest.writableNeedDrain === true) {
if (state.flowing) {
pause();
}
} else if (!state.flowing) {
src.resume();
}
return dest;
}pipe操作和Linux的管道操作符'|'非常相似,将左侧输出变为右侧输入,这个方法会将可写流收集起来进行维护,并且当可读流触发'data'事件。
有数据流出时,就会触发可写流的写入事件,从而做到数据传递,实现像管道一样的操作。并且会自动将处于暂停模式的可读流变为流动模式。
2.4.5. resume
使流从'暂停'模式切换到'流动'模式,如果设置了'readable'事件监听,那么这个方法其实是没有效果的
readable.resume
Readable.prototype.resume = function() {
const state = this._readableState;
if (!state.flowing) {
state.flowing = !state.readableListening; // 是否处于流动模式取决于是否设置了'readable'监听句柄
resume(this, state);
}
};
function resume(stream, state) {
if (!state.resumeScheduled) { // 开关,使resume_方法仅在同一个Tick中调用一次
state.resumeScheduled = true;
process.nextTick(resume_, stream, state);
}
}
function resume_(stream, state) {
if (!state.reading) {
stream.read(0);
}
state.resumeScheduled = false;
stream.emit('resume');
flow(stream);
}
function flow(stream) { // 当流处于流模式该方法会不断的从buffer中读取数据,直到缓冲区为空
const state = stream._readableState;
while (state.flowing && stream.read() !== null);
// 因为这里会调用read方法,设置了'readable'事件监听器的stream,也有可能会调用read方法,
//从而导致数据不连贯(不影响data,仅影响在'readable'事件回调中调用read方法读取数据)
}2.4.6. pause
将流从流动模式转变为暂停模式,停止触发'data'事件,将所有的数据保存到缓冲区
readable.pause
Readable.prototype.pause = function() {
if (this._readableState.flowing !== false) {
debug('pause');
this._readableState.flowing = false;
this.emit('pause');
}
return this;
};2.5. 使用方法与工作机制
使用方法在BufferList部分已经讲过了,创建一个Readable实例,并实现其_read()方法,或者在构造函数的第一个对象参数中实现read方法。
2.5.1. 工作机制

Seul le processus général est dessiné ici, ainsi que les conditions de déclenchement de la conversion de mode du flux Readable.
Parmi eux :
- needReadable(true) : mode pause et données du tampon
- push : si il est en mode flux, aucune donnée dans le tampon ne déclenchera l'événement 'data' ; sinon, enregistrez les données dans le tampon et déclenchez l'événement 'readable' en fonction du besoinReadable status
- read : Lors de la lecture de données avec length=0 , les données dans le tampon ont atteint hwm ou ont débordé. L'événement « lisible » doit être déclenché ; lire les données du tampon et déclencher l'événement « données »
- resume : s'il y a un écouteur « lisible », cette méthode ne le fera pas. fonctionne ; sinon, le flux passera du mode pause au mode flux et le tampon sera effacé. Les données dans des conditions de déclenchement lisibles : l'événement « lisible » est lié et il y a des données dans le tampon. il y a des données dans le tampon, et needReadable === true. Lors de la lecture de données avec une longueur = 0, le tampon dans les données a atteint hwm ou a débordé
Afin de résoudre la mémoire. problème et problème de temps, Node.js a implémenté son propre flux, afin que les données puissent être lues dans la mémoire par petits morceaux.
- Les flux ne sont pas un concept unique à Node.js. Ils ont été introduits dans le fonctionnement d'Unix. système il y a des décennies.
- Il existe quatre types de flux : le flux lisible, le flux inscriptible, le flux lisible et inscriptible, le flux de conversion, ils héritent tous des méthodes d'instance et des méthodes statiques d'EventEmiiter, et sont tous des instances de EE
- Le conteneur sous-jacent. du flux est basé sur BufferList, qui est une implémentation de liste chaînée personnalisée, chaque tête et chaque queue étant un "pointeur" qui pointe vers la référence de nœud suivante
- Le flux lisible a deux modes et trois états. En mode flux, le flux lisible a deux modes et trois états. les données seront envoyées au consommateur via EventEmitter
- Sur la base du flux, nous pouvons mettre en œuvre un traitement en chaîne des données et assembler différentes fonctions de traitement de flux pour mettre en œuvre diverses opérations sur le flux et le convertir en données souhaitées
- Pour plus de nœuds -connaissances connexes, veuillez visiter :
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Nœud apprenant à minimiser l'allocation du tas et à éviter les fuites de mémoire
- Cet article vous donnera une compréhension approfondie de Node.js (explication détaillée avec images et texte)
- Cet article vous amènera à comprendre le système de modules dans node
- Un article expliquant en détail l'authentification de l'identité d'Express dans Node
- Un article analysant brièvement comment utiliser la file d'attente de messages dans le nœud
- Un article pour parler du chargement automatique du routage back-end des nœuds