
Maison >interface Web >js tutoriel >[Résumé de l'expérience] Comment résoudre les fuites de mémoire dans Node ? Partager des idées
[Résumé de l'expérience] Comment résoudre les fuites de mémoire dans Node ? Partager des idées

- 青灯夜游avant
- 2023-01-28 19:25:373207parcourir
Comment résoudre les fuites de mémoire dans Node ? L'article suivant résumera l'expérience de dépannage des fuites de mémoire Node pour tout le monde. J'espère qu'il sera utile à tout le monde !
![[Résumé de l'expérience] Comment résoudre les fuites de mémoire dans Node ? Partager des idées](https://img.php.cn/upload/article/000/000/024/63d505e3d0d7d931.jpg)
Dans le scénario de développement côté serveur Nodejs, la fuite de mémoire est certainement le problème le plus gênant ;
Mais tant que le projet continue d'être développé et itéré, le problème de fuite de mémoire est absolument inévitable, il arrive tôt ou tard. Par conséquent, maîtriser systématiquement les méthodes efficaces de dépannage des fuites de mémoire est la capacité la plus fondamentale et essentielle d'un ingénieur Nodejs. Nodejs 服务端开发的场景中,内存泄漏 绝对是最令人头疼的问题;
但是只要项目一直在开发迭代,那么出现 内存泄漏 的问题绝对不可避免,只是出现的时间早晚而已。所以系统性掌握有效的 内存泄漏 排查方法是一名Nodejs 工程师最基础、最核心的能力。
内存泄漏处理的难点就是如何能在无数的功能、函数中找到具体是哪一个功能中的哪一个函数的第多少行到多少行引起了内存泄漏。
很遗憾目前市面上没有能够轻松定位内存泄漏的工具,所以很多初次遇到这种问题的工程师会感到茫然,一下子不知道该如何处理。
这里我以22年的一次排查 内存泄漏 的案例分享一下我的处理思路。
问题描述
2022 Q4 某天,研发用户群中反馈我们的研发平台不能访问,后台中出现了大量的异常任务未完成。
第一反应就是可能出现了内存泄漏还好服务接入了监控(prometheus + grafana),在grafana 监控面板中发现在 10.00 后内存一直在涨没有下来过出现了明显的数据泄漏。【相关教程推荐:nodejs视频教程】
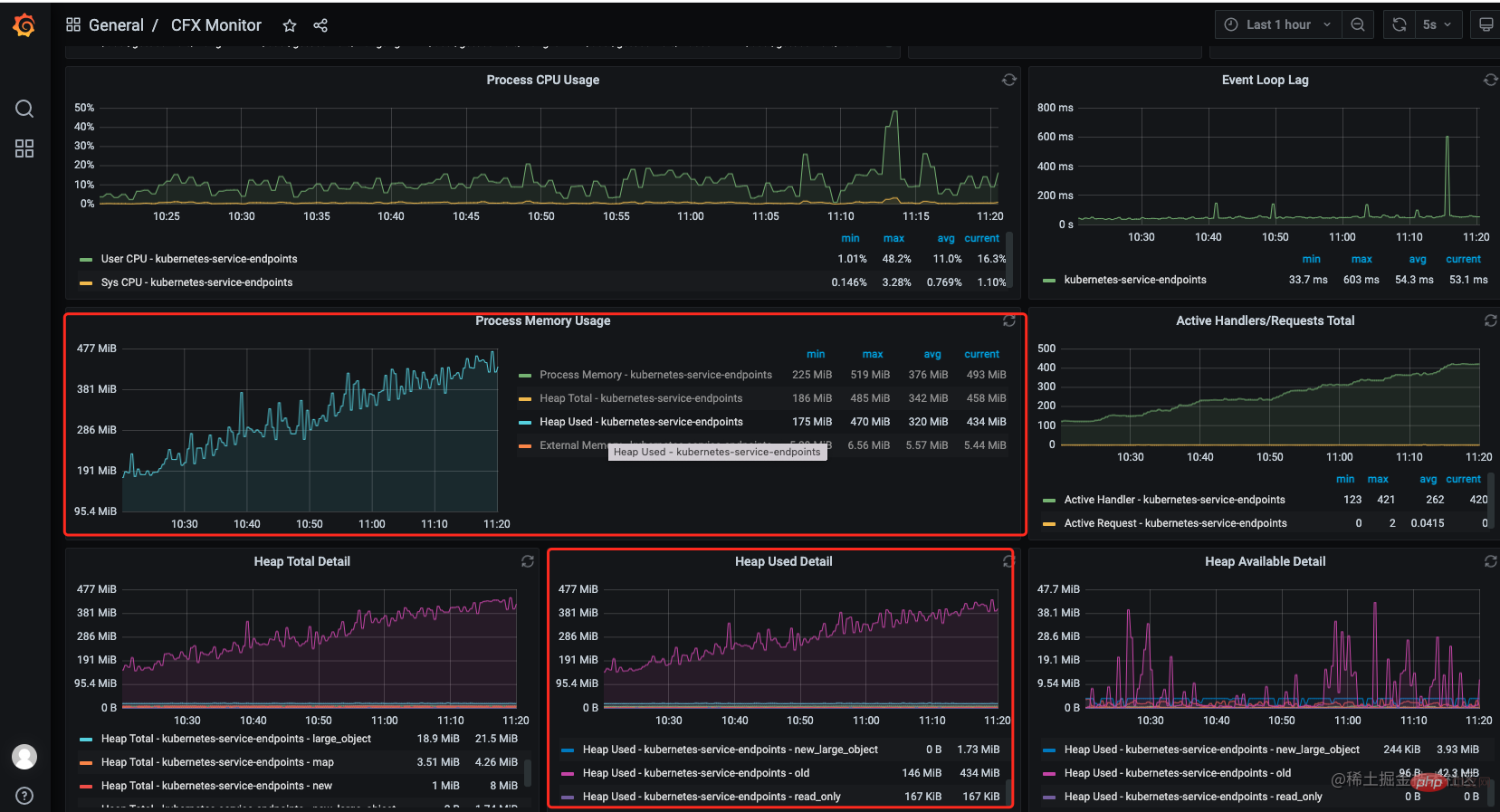
说明:
process memory:rss(Resident Set Size),进程的常驻内存大小。heapTotal: V8 堆的总大小。heapUsed: V8 堆已使用的大小。external: V8 堆外的内存使用量。在
Nodejs中可以调用全局方法process.memoryUsage()获取这些数据其中heapTotal和heapUsed是 V8 堆的使用情况,V8 堆是Node.js中 JavaScript 对象存储的地方。而external则表示非 V8 堆中分配的内存,例如 C++ 对象。rss则是进程所有内存的使用量。一般看监控数据的时候重点关注heapUsed的指标就行了
内存泄漏类型
内存泄漏主要分为:
- 全局性泄漏
- 局部性泄漏
其实不管是全局性内存泄漏还是局部性的内存泄漏,要做的都是尽可能缩小排除范围。
全局性内存泄漏
全局性内容泄漏出现一般高发于:中间件与组件中,这种类型的内存泄漏排查起来也是最简单的。
很遗憾我在 2022 Q4 中遇到的内存泄漏不属于这个类型,所以还得按照局部性泄漏的思路进行分析。
二分法排查
这种类型我就不讲其它科学的分析方法了,这种情况下我认为使用二分法排查是最快的。
流程流程:
先注释一半的代码(减少一半
中间件、组件、或其它公用逻辑的使用)随便选择一个接口或新写一个测试接口进行压测
如果出现内存泄漏,那么泄漏点就在当前使用的代码之中,若没有泄漏则泄漏点出现在
然后一直循环往复上述流程大约 20 ~ 60 min 一定可以定位到内存泄漏的详细位置
2020 年的时候我在做基于
NuxtSSR 应用时,上线前压测发现应用内存泄漏,判断定为全局性的泄漏之后,采用二分法排查大约花了 30min 就成功定位了问题。
当时泄漏的原因是我们在服务端使用axios导致的泄漏,后来统一axios相关的全换成node-fetch后就解决了,从此换上了axios PDST后来绝对不会在Node服务中使用axios了
局部性内存泄漏排查
大多数内存泄漏的情况都是局部性的泄漏,泄漏点可能存在与某个中间件、某个接口、某个异步任务中,由于这样的特性它的排查难度也较大。这种情况都会做 heapdump
fuite de mémoire en 22 ans. 🎜Description du problème
🎜2022 Q4 Un jour, le groupe d'utilisateurs R&D a signalé que notre plateforme R&D ne pouvait pas être consulté, un grand nombre de tâches anormales n’ont pas été terminées en arrière-plan.
La première réaction est qu'il peut y avoir une fuite de mémoire. Heureusement, le service est connecté au monitoring (prometheus + grafana). panneau de surveillance, j'ai découvert qu'après 10h00, la mémoire ne cessait d'augmenter et ne diminuait jamais, et il y avait une fuite de données évidente. [Tutoriels associés recommandés : tutoriel vidéo nodejs]🎜🎜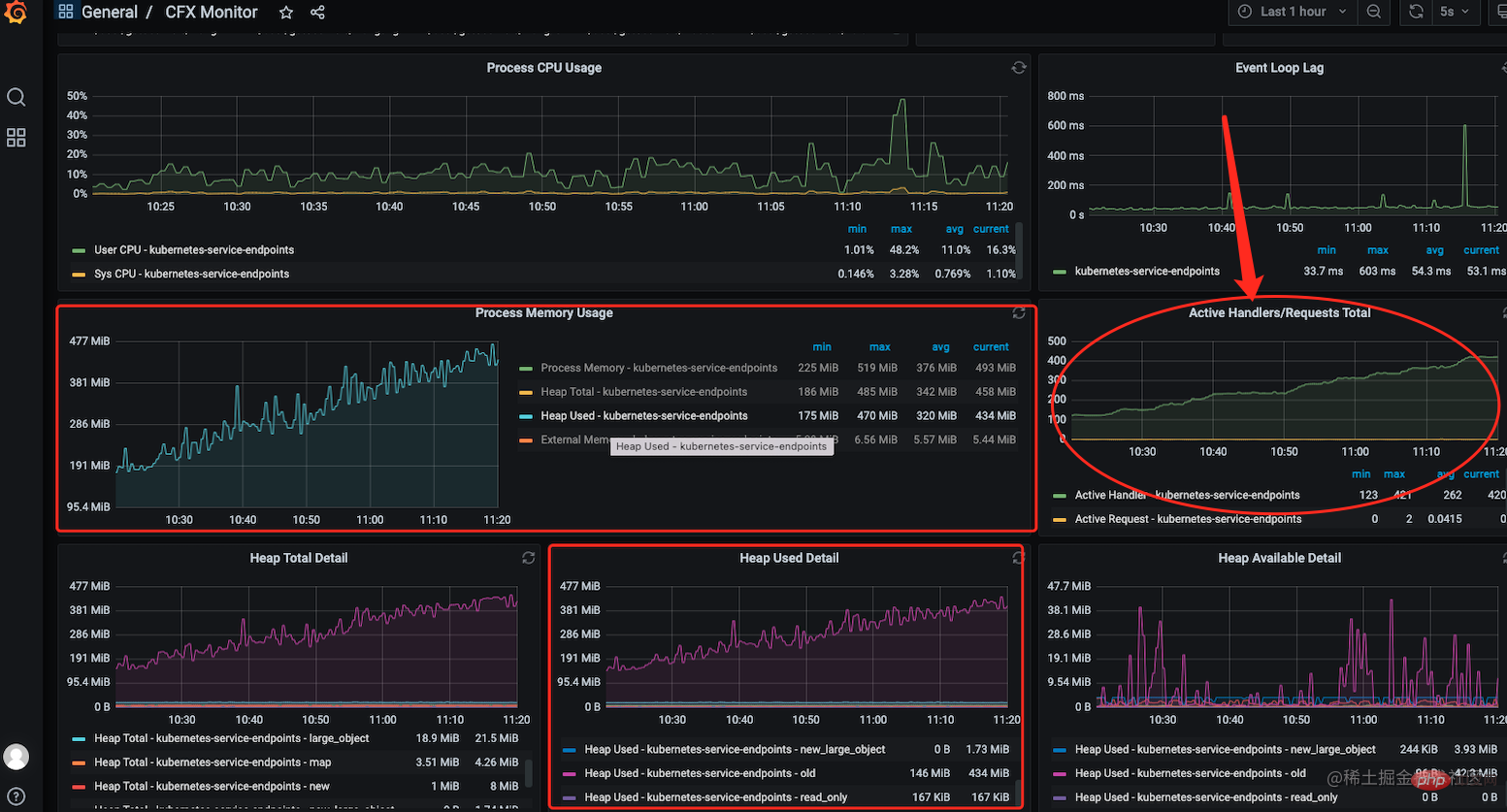 🎜
🎜🎜Description : 🎜🎜Dans
mémoire du processus:rss(Resident Set Size), la taille de la mémoire résidente du processus.heapTotal: La taille totale du tas V8.heapUsed: La taille du tas V8 utilisé.externe: utilisation de la mémoire en dehors du tas V8.Nodejsvous pouvez appeler la méthode globaleprocess.memoryUsage()pour obtenir ces données, parmi lesquellesheapTotaletheapUsedest l'utilisation du tas V8, où les objets JavaScript dansNode.jssont stockés. Etexternalreprésente la mémoire allouée dans un tas non V8, tel que les objets C++.rssest l'utilisation totale de la mémoire du processus. Généralement, lorsque vous examinez les données de surveillance, concentrez-vous simplement sur l'indicateurheapUsed🎜
Type de fuite de mémoire h2 >🎜Les fuites de mémoire sont principalement divisées en :🎜
- Fuites globales
- Fuites locales
🎜En fait, s'il s'agit d'une fuite de mémoire globale ou une fuite locale Pour les fuites de mémoire, tout ce que vous avez à faire est de réduire autant que possible la portée de l'exclusion. 🎜
Fuite de mémoire globale
🎜Les fuites de contenu globales se produisent généralement dans : middlewareAvec composant, ce type de fuite de mémoire est également le plus simple à dépanner. 🎜🎜Malheureusement, la fuite de mémoire que j'ai rencontrée au T4 2022 n'appartient pas à ce type, je dois donc l'analyser selon l'idée de fuites locales. 🎜Dépannage de dichotomie
🎜Je ne parlerai pas d'autres méthodes d'analyse scientifique pour ce type. Dans ce cas, je pense utiliser le dépannage de dichotomie française. est le plus rapide. 🎜🎜Flux de processus : 🎜
- 🎜Premier commentaire de la moitié du code (réduire la moitié du
middleware, composant, ou l'utilisation d'une autre logique publique)🎜
- 🎜Choisissez une interface ou écrivez une nouvelle interface de test pour les tests de résistance🎜
- 🎜Si la mémoire apparaît Fuite, alors le point de fuite est dans le code actuellement utilisé. S'il n'y a pas de fuite, le point de fuite apparaît dans 🎜
- 🎜 Continuez ensuite à répéter le processus ci-dessus pendant environ 20 à 60 minutes. localisez définitivement les détails de la fuite de mémoire Localisation 🎜
🎜En 2020, alors que je travaillais sur une application SSR basée sur Nuxt, un test de résistance avant de partir. online a détecté une fuite de mémoire d'application, qui a été déterminée comme étant une fuite globale. Après cela, il a fallu environ 30 minutes pour localiser le problème à l'aide de la méthode de dichotomie.
La raison de la fuite à cette époque était que nous utilisions axios côté serveur. Plus tard, nous avons unifié axios et l'avons remplacé par node. -fetch Cela a été résolu après cela, et je suis passé à axios PDST à partir de ce moment-là. Je n'utiliserai jamais axios dans le Node service plus🎜
Dépannage des fuites de mémoire locale
🎜La plupart des fuites de mémoire sont des fuites locales, et le point de fuite peut exister avec un certain middleware, composant, ou l'utilisation d'une autre logique publique)🎜Nuxt, un test de résistance avant de partir. online a détecté une fuite de mémoire d'application, qui a été déterminée comme étant une fuite globale. Après cela, il a fallu environ 30 minutes pour localiser le problème à l'aide de la méthode de dichotomie. La raison de la fuite à cette époque était que nous utilisions
axios côté serveur. Plus tard, nous avons unifié axios et l'avons remplacé par node. -fetch Cela a été résolu après cela, et je suis passé à axios PDST à partir de ce moment-là. Je n'utiliserai jamais axios dans le Node service plus🎜
Middleware, une certaine interface et une certaine tâche asynchrone sont plus difficiles à dépanner en raison de ces caractéristiques. Dans ce cas, un heapdump sera effectué pour analyse. 🎜Ici, je parle principalement de mes idées dans ce cas. Je mettrai la description détaillée de heapdump dans le paragraphe suivant, heapdump的详细说明我放在下个段落,
Heap Dump:堆转储, 后面部分都使用heapdump表示,做heapdump的工具和教程也非常多比如:chrome、vscode、heapdump 这个开源库。我用的 heapdump 库做的网上教程非常多这里不展开了。
局部性内存泄漏排查需要一定的内存泄漏排查经验,每次遇到都把它当成对自己的一次磨砺,这样的经验积累多了以后排查内存泄漏问题会越来越快。
1. 确定内存泄漏出现的时间范围
这一点非常重要,明确了这一点可以大幅度缩小排查范围。
经常会出现这种情况,这个迭代做了A、B、C 三个功能,压测时或上线后出现了内存泄漏。那么就可以直接锁定,内存泄漏发生小这三个新的功能之中。这种情况下就不需要非常麻烦的去生产做 heapdump 我们在本地通过一些工具就可以很轻松的分析定位出内存泄漏点。
由于我们 20年Q4 的一些特殊情况,当我们发现存在内存泄漏的时候已经很难确定内存泄漏初次出现在什么时间点了,只能大概锁定在 1 月的时间内。这一个月中我们又经历了一个大版本迭代,如果一一排查这些功能与接口成本必然非常高。
所以还需要结合更多的数据进行进一步分析
2. 采集 heapdump 数据
- 生产启动时
node添加--expose-gc,这个参数会向全局注入gc()方法,方便手动触发 GC 获取更准确的堆快照数据 - 这里我加入了两个接口并带上了自己的专属权限,
- 手动触发 GC
- 打印堆快照
-
heapdump- 项目启动后第一次打印快照数据
- 内存上涨 100M 后:先触发 GC,再第二次打印堆快照数据
- 内存接近临界时再次触发 GC 然后打印堆快照
采集堆快照数据时需要特别注意的一些点!
- 在
heapdump时 Node 服务会中断,根据当时服务器内存大小这个时间会在 2 ~ 30min 左右。在生产环境做heapdump需要和运维一起制定合理的策略。我在这里是使用了主、备两个pod, 当主pod停掉之后,业务请求会通过负载均衡到备用pod由此保障生产业务的正常进行。(这个过程必定是一个与运维密切配合的过程,毕竟heapdump玩抽还需要通过他们拿到服务器中堆快照文件)- 上述接近临界点打印快照只是一个模糊的描述,如果你试过就知道等非常接近临界点再打印内存快照就打印不出来了。所以接近这个度需要自己把握。
- 做至少 3 次
heapdump(实际上为了拿到最详细的数据我是做了 5 次)
3. 结合监控面板的数据进行分析
需要你的应用服务接入监控,我这里应用是使用prometheus + grafana 做的监控, 主要监控服务的以下指标
-
QPS(每秒请求访问量) ,请求状态,及其访问路径 -
ART(平均接口响应时间) 及其访问数据 -
NodeJs版本 -
Actice Handlers(句柄) -
Event Loop Lag(事件滞后) - 服务进程重启次数
- CPU 使用率
- 内存使用:
rss、heapTotal、heapUsed、external、heapAvailableDetail
只有
heapdump数据是不够的,heapdump数据非常晦涩,就算在可视化工具的加持下也难以准确定位问题。这个时候我是结合了grafana的一些数据一起看。
我的分析处理结果
由于当时的对快照数据丢失了,我这里模拟一下当时的场景。
1、通过 grafana 监控面看看到内存一直在涨一直下不来,但同时我也注意到,服务中的句柄
Heap Dump: Heap dump, les parties suivantes sont toutes L'utilisation deheapdumpsignifie qu'il existe de nombreux outils et didacticiels pour effectuer duheapdump, tels que : chrome, vscode et la bibliothèque open source heapdump. Il existe de nombreux didacticiels en ligne pour la bibliothèque heapdump que j'utilise, que je n'aborderai pas ici.plus vite.
1. Déterminez la plage horaire dans laquelle la fuite de mémoire se produit
Cela peut être très important. améliorer Réduire la portée de l’enquête.
Cette situation se produit souvent. Cette itération comporte trois fonctions A, B et C, et une fuite de mémoire se produit lors du stress test ou après la mise en ligne. Vous pourrez alors directement verrouiller et de petites fuites de mémoire se produiront parmi ces trois nouvelles fonctions. Dans ce cas, il n'est pas nécessaire d'aller en production pour faire duheapdump. Nous pouvons facilement analyser et localiser le point de fuite mémoire localement grâce à certains outils. 🎜🎜En raison de circonstances particulières au cours de notreT4 2020, lorsque nous avons découvert une fuite de mémoire, il a été difficile de déterminer quand la fuite de mémoire est apparue pour la première fois. Nous n'avons pu la verrouiller qu'approximativement en janvier. Ce mois-ci, nous avons effectué une autre itération majeure de version. Si nous vérifions ces fonctions et interfaces une par une, le coût sera très élevé. Par conséquent, davantage de données doivent être combinées pour une analyse plus approfondie🎜2. Collecter les données de tas
🎜Collection Certains points nécessitent une attention particulière lors du regroupement de données instantanées ! 🎜
- Lorsque la production démarrenode Ajoutez
--expose-gcCe paramètre injectera la méthodegc()globalement pour faciliter le déclenchement manuel du GC afin d'obtenir unInstantané du tasDonnées- Ici, j'ai ajouté deux interfaces et apporté mes propres autorisations exclusives,
- Déclencher manuellement le GC
- Imprimer l'instantané du tas
heapdumpli>
- Imprimer les données d'instantané pour la première fois après le démarrage du projet
- Après que la mémoire augmente de 100 Mo : Déclenchez d'abord le GC, puis imprimez les données de l'instantané du tas pour la deuxième fois
- Déclenchez à nouveau le GC lorsque la mémoire est proche du niveau critique, puis imprimez l'instantané du tas
- Le service Node sera interrompu pendant le
heapdump. Ce temps sera d'environ 2 à 30 minutes selon la taille de la mémoire du serveur à ce moment-là. . Lorsque vous effectuez unheapdumpdans un environnement de production, vous devez travailler avec l'exploitation et la maintenance pour développer une stratégie raisonnable. Ici, j'utilise deuxpod, le principal et le sauvegarde. Lorsque lepodprincipal est arrêté, la charge des requêtes métier sera équilibrée sur lepodde sauvegarde. Cela garantit le déroulement normal des opérations de production. (Ce processus doit être étroitement coordonné avec l'exploitation et la maintenance. Après tout,heapdumpdoit obtenir le fichierinstantané de tassur le serveur via eux)- L'impression mentionnée ci-dessus d'instantanés proches du point critique n'est qu'une vague description. Si vous l'avez essayée, vous saurez qu'elle ne s'imprimera pas si vous attendez qu'elle soit très proche du point critique puis imprimez la mémoire. instantané. Il faut donc se contrôler pour se rapprocher de ce diplôme.
- Faites au moins 3 fois un
heapdump(en fait, je l'ai fait 5 fois pour obtenir les données les plus détaillées)3. Combinez les données du panneau de surveillance pour analyse
🎜Vous avez besoin de votre service d'application pour accéder à la surveillance. Mon application ici utiliseprometheus<. surveillance> + <code>grafana, surveillant principalement les indicateurs suivants du service 🎜
QPS(demandes de visites par seconde), statut de la demande et chemin d'accèsART(temps de réponse moyen de l'interface) et ses données d'accèsNodeJsversionGestionnaires Actice(handle)Event Loop Lag(event lag)- Nombre de redémarrages du processus de service
- Utilisation du processeur
- Utilisation de la mémoire :
rss,heapTotal,heapUsed,external,heapAvailableDetail🎜Seules les donnéesheapdumpne suffisent pas, les donnéesheapdumpsont très obscures, même dans les outils de visualisation. Il est également difficile de localiser avec précision le problème avec la bénédiction de . À ce moment-là, je l'ai examiné avec quelques données degrafana. 🎜Mes résultats d'analyse et de traitement
🎜Étant donné que les données de l'instantané ont été perdues à ce moment-là, je vais simuler la scène ici . 🎜🎜1. Grâce à l'interface de surveillancegrafana, j'ai vu que la mémoire a augmenté et n'a pas diminué. Mais en même temps, j'ai aussi remarqué que le nombre dehandles. code> dans le service a également grimpé en flèche et n'a pas diminué. 🎜🎜🎜🎜2. C'est à ce moment-là que j'ai examiné les nouvelles fonctionnalités du mois où la fuite s'est produite. Je soupçonne que la fuite de mémoire peut être causée par l'utilisation du composant de file d'attente de messages
bull. J'ai d'abord analysé le code de l'application concerné, mais je n'ai pas pu voir qu'il y avait un problème qui aurait provoqué une fuite de mémoire. Combiné avec le problème de fuite de handle dans 1, il semble que vous deviez libérer manuellement certaines ressources après avoir utilisébull. Pour le moment, je ne suis pas sûr de la raison spécifique.bull消息队列组件造成的内存泄漏。先去分析了相关应用代码,但并看不出那里写的有问题导致了内存泄漏, 结合 1 中句柄泄漏的问题感觉是在使用bull后需要手动的去释放某些资源,在这个时候还不太确定具体原因。3、然后对 5 次的
heapdunmp数据进行了分析,数据导入chrome对 5 次堆快照进行对比后,发现每次创建队列后 TCP、Socket、EventEmitter 的事件都没有被释放到。到这里基本可以确定是由于对bull的使用不规范导致的。在bull通常不会频繁创建队列,队列占用的系统资源并不会被自动释放,若有需要,需手动释放。
4、在调整完代码后重新进行了压测,问题解决。
Tips: Nodejs 中的
句柄是一种指针,指向底层系统资源(如文件、网络连接等)。句柄允许 Node.js 程序访问和操作这些资源,而无需直接与底层系统交互。句柄可以是整数或对象,具体取决于 Node.js 库或模块使用的句柄类型。常见句柄:
fs.open()返回的文件句柄net.createServer()返回的网络服务器句柄dgram.createSocket()返回的 UDP socket 句柄child_process.spawn()返回的子进程句柄crypto.createHash()返回的哈希句柄zlib.createGzip()返回的压缩句柄heapdump 分析总结
通常很多人第一次拿到
堆快照数据是懵的,我也是。在看了网上无数的分析技巧结合自身实战后总结了一些比较好用的技巧,一些基础的使用教程这里就不讲了。这里主要讲数据导入chrome后如何看图;Summary 视图
TCPSocketEventEmitterglobalComparison 视图
如果通过
Summary视图, 不能定位到问题这时我们一般会使用Comparison视图。通过这个视图我们能对比两个堆快照中对象个数、与对象占有内存的变化; 通过这些信息我们可以判断在一段时间(某些操作)之后,堆中的对象与内存变化的数值,通过这些数值我们可以找出一些异常的对象。通过这些对象的名称属性或作用可以缩小我们内存泄漏的排查范围。在
3. Ensuite, les 5 fois des donnéesComparison视图中选择两个堆快照,并在它们之间进行比较。您可以查看哪些对象在两个堆快照之间新增,哪些对象在两个堆快照之间减少,以及哪些对象的大小发生了变化。Comparisonheapdunmpont été analysées et les données ont été importées danschrome. Après avoir comparé les 5 fois des instantanés de tas, il a été constaté qu'après. à chaque création de file d'attente, les événements TCP, Socket, EventEmitter ne sont pas libérés. À ce stade, il est fondamentalement certain que cela est dû à une utilisation irrégulière debull. Les files d'attente ne sont généralement pas créées fréquemment dansbull, et les ressources système occupées par la file d'attente ne sont pas automatiquement libérées. Si nécessaire, elles doivent être libérées manuellement.
4. Après avoir ajusté le code, le test de résistance a été effectué à nouveau et le problème a été résolu. Conseils : Le
handledans Nodejs est un pointeur qui pointe vers les ressources système sous-jacentes (telles que les fichiers, les connexions réseau, etc.). Les handles permettent aux programmes Node.js d'accéder et de manipuler ces ressources sans interagir directement avec le système sous-jacent. Le handle peut être un entier ou un objet, selon le type de handle utilisé par la bibliothèque ou le module Node.js.Handlecommun :
fs.open()Handle de fichier renvoyénet.createServer() code > Le handle du serveur réseau renvoyédgram.createSocket()Le handle du socket UDP renvoyéchild_process.spawn()Le Descripteur de processus enfant renvoyécrypto.createHash()Le descripteur de hachage renvoyézlib.createGzip()Descripteur de compression renvoyé
![[Résumé de lexpérience] Comment résoudre les fuites de mémoire dans Node ? Partager des idées](https://img.php.cn/upload/article/000/000/024/3ac32851609e14d3da1d33f80496eee4-2.png)
![[Résumé de lexpérience] Comment résoudre les fuites de mémoire dans Node ? Partager des idées](https://img.php.cn/upload/article/000/000/024/5ec58d2950a8a038af2e3794ac452eac-3.png) 看这个视图的时候一般会先对 Retained Size 进行排查,然后观察其中对象的大小与数量,有经验的工程师,可以快速判断出某些对象数量异常。在这个视图中除了关心自己定义的一些对象之外,
一些容易发生内存泄漏的对象也需要注意如:
看这个视图的时候一般会先对 Retained Size 进行排查,然后观察其中对象的大小与数量,有经验的工程师,可以快速判断出某些对象数量异常。在这个视图中除了关心自己定义的一些对象之外,
一些容易发生内存泄漏的对象也需要注意如:![[Résumé de lexpérience] Comment résoudre les fuites de mémoire dans Node ? Partager des idées](https://img.php.cn/upload/article/000/000/024/2b53f8bd03c08e00f15929d1f42ae4da-4.png)
résumé de l'analyse du tas
Habituellement, de nombreuses personnes obtiennent l'instantané du tasLes données sont confuses, et moi aussi. Après avoir lu d'innombrables techniques d'analyse sur Internet et les avoir combinées avec ma propre pratique réelle, j'ai résumé quelques techniques plus utiles. Certains didacticiels d'utilisation de base ne seront pas abordés ici. Ici, nous parlons principalement de la façon d'afficher les images après avoir importé des données dans <code>chrome ![[Résumé de lexpérience] Comment résoudre les fuites de mémoire dans Node ? Partager des idées](https://img.php.cn/upload/article/000/000/024/fb8d54159c4bbba0c28af97d6b1eb853-5.png)
Lorsque nous regardons cette vue, nous vérifions généralement en premier la taille conservée. , puis observez-le en fonction de la taille et du nombre d'objets, des ingénieurs expérimentés peuvent rapidement déterminer que le nombre de certains objets est anormal. Dans cette optique, en plus de se soucier de certains objets définis par vous-même,
Certains objets sujets aux fuites de mémoire nécessitent également une attention particulière, tels que :
TCPSocket- EventEmitter
global
Vue comparative
![[Résumé de lexpérience] Comment résoudre les fuites de mémoire dans Node ? Partager des idées](https://img.php.cn/upload/article/000/000/024/8075e15765360c3c802b42b410e6b54b-6.png) Si passé la vue
Si passé la vue Résumé, si le problème ne peut pas être localisé, nous utilisons généralement la vue Comparaison. Grâce à cette vue, nous pouvons comparer le nombre d'objets dans les deux instantanés de tas et les changements dans la mémoire occupée par les objets ;
Grâce à ces informations, nous pouvons juger les valeurs des objets dans le tas et les changements de mémoire après un certain temps (certaines opérations). Grâce à ces valeurs, nous pouvons trouver des objets anormaux. Les attributs de nom ou les fonctions de ces objets peuvent restreindre la portée de notre dépannage en cas de fuite de mémoire.
Comparaison et comparez-les. Vous pouvez voir quels objets ont été ajoutés entre deux instantanés de tas, quels objets ont été réduits entre deux instantanés de tas et quels objets ont changé de taille. La vue Comparaison vous permet également d'afficher les relations entre les objets, ainsi que les détails des objets tels que le type, la taille et le nombre de références. Grâce à ces informations, vous pouvez comprendre quels objets sont à l'origine de la fuite de mémoire. 🎜🎜🎜🎜🎜🎜Vue Confinement🎜🎜🎜 montre toutes les relations de référence accessibles entre les objets. Chaque objet est représenté par un point et relié à son objet parent par une ligne. De cette façon, vous pouvez voir les relations hiérarchiques entre les objets et comprendre quels objets provoquent des fuites de mémoire. 🎜🎜🎜🎜🎜🎜Vue statistiques🎜🎜🎜Cette image est très simple et je n'entrerai pas dans les détails🎜🎜🎜🎜Scénario de fuite de mémoire
- Variables globales : les variables globales ne seront pas recyclées
- Cache : l'utilisation d'une bibliothèque tierce gourmande en mémoire telle que
lru-cacheentraînera une panne de mémoire si trop est stocké. Ce n'est pas suffisant. Il est recommandé d'utiliserredisau lieu delru-cachedans le service Nodejslru-cache存的太多就会导致内存不够用,在 Nodejs 服务中建议使用redis替代lru-cache - 句柄泄漏:调用完系统资源没有释放
- 事件监听
- 闭包
- 循环引用
总结
服务需要接入监控,方便第一时间确定问题类型
判断内存泄漏是全局性的还是局部性的
全局性内存泄漏使用二分法快速排查定位
-
局部内存泄漏
- 确定内存泄漏出现时间点,快速定位问题功能
- 采堆快照数据,至少 3 次
- 结合监控数据、堆快照数据、与出现泄漏事时间点内的新功能对内存泄漏点进行定位
遇到内存泄漏的问题不要畏惧,多积累内存泄漏问题的排查经验处理经验多了找起来就非常快了。每次解决之后做复盘总结回头再多看看
Gérer la fuite : les ressources système ne sont pas libérées après l'appel.堆快照
Surveillance des événementsClosure
- Loop Quote
🎜Ne rencontrez pas de problèmes de fuite de mémoire N'ayez pas peur Accumulez plus d'expérience dans le dépannage des problèmes de fuite de mémoire, plus vous aurez d'expérience dans la résolution des problèmes de fuite de mémoire, plus cela sera facile. être de les trouver. Après chaque solution, faites un résumé de révision et revenez sur Heap Snapshot. Les données vous aideront à accumuler une expérience pertinente plus rapidement🎜🎜🎜🎜Autres🎜🎜🎜🎜Outils de test de stress : wrk🎜🎜🎜Plus de nœuds. Pour des connaissances connexes, veuillez visiter : 🎜tutoriel nodejs🎜 ! 🎜Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Nœud apprenant à minimiser l'allocation du tas et à éviter les fuites de mémoire
- Un article expliquant en détail les modules Express et de routage dans Node
- Cet article vous amènera à comprendre le système de modules dans node
- Un article expliquant en détail l'authentification de l'identité d'Express dans Node
- Un article analysant brièvement comment utiliser la file d'attente de messages dans le nœud
- Un article pour parler du chargement automatique du routage back-end des nœuds