
Trois années de partage d'expérience en entretien : quatre étapes et trois facteurs déterminants des entretiens front-end

- 青灯夜游avant
- 2022-12-16 15:32:333985parcourir
La situation de l'emploi cette année est tout simplement sombre. Basé sur la "mentalité de la chance" selon laquelle l'année prochaine sera pire que cette année, j'ai choisi de démissionner sans hésitation. Après un mois et demi de travail acharné, j'ai reçu une assez bonne offre. , le salaire et la plateforme ont été grandement améliorés, mais il y a encore un grand écart entre elle et mes attentes psychologiques. La plus grande conclusion est donc la suivante : ne parlez pas nu ! Ne dites rien nu ! Ne dites rien nu ! Parce que la pression exercée sur les gens lors de l'entretien et les dommages psychologiques causés par l'écart entre la réalité et les idéaux sont incommensurables, c'est un bon choix pour survivre dans un tel environnement.
Recommandations associées : Résumé des grandes questions d'entretien frontal 2023 (Collection)
Ce qui suit est un résumé des quatre étapes suivantes et des trois facteurs déterminants qui seront vécus lors des entretiens frontaux dans des circonstances normales :
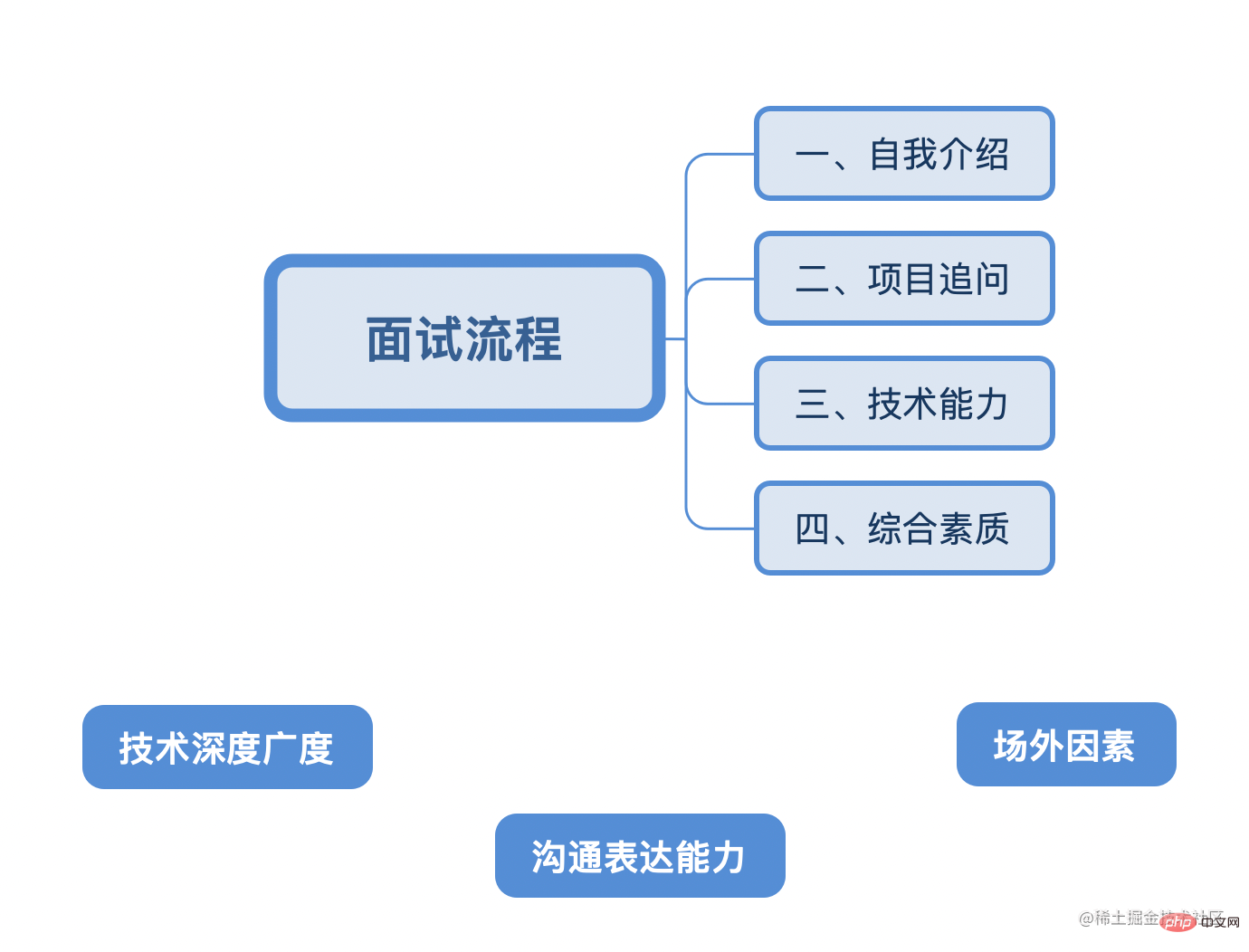 En tant que personnel frontal, la profondeur et l'étendue de la technologie sont classées en premier. Trois ans sont une ligne de démarcation à ce moment-là.
En tant que personnel frontal, la profondeur et l'étendue de la technologie sont classées en premier. Trois ans sont une ligne de démarcation à ce moment-là.
Deuxièmement, de bonnes compétences en communication et en expression, des vêtements, des performances et d'autres facteurs hors site peuvent augmenter la reconnaissance de vous par l'intervieweur.
Certaines personnes sont très compétentes, mais l'intervieweur se sent mal à l'aise pendant l'entretien. Il pense que vous êtes arrogant/négligé/phare/impossible de vous exprimer clairement, alors il vous rejettera simplement. C'est la plus grande perte qui l'emporte sur le gain.
Ce qui suit est un résumé de toute ma préparation à l'entretien et des questions qui m'ont été posées, car pendant le processus d'entretien, la communication avec l'intervieweur n'est pas dans une large mesure une simple approbation. Il est préférable de transmettre les connaissances par la vôtre. résumez-le et exprimez-le de manière concise, puis complétez-le sur place en fonction des questions de l'intervieweur. [Apprentissage recommandé : front-end web, enseignement de la programmation]
1. Auto-présentation
L'intervieweur vous demande de vous présenter et ne limite pas la portée de l'auto-présentation. pour apprendre de votre auto-présentation Je vous connais, donc l'introduction doit être courte et fluide Face à différents intervieweurs, le contenu de l'auto-présentation peut être exactement le même, il est donc important de préparer vos mots à l'avance et d'en être sûr. faire attention : ne trébuche pas, sois confiant ! La fluidité d’expression et la capacité de communication sont également l’un des points d’évaluation des candidats par l’intervieweur. J'ai également été intervieweur. Les candidats confiants et généreux sont souvent plus susceptibles d'être favorisés.
1. Introduction personnelle (situation de base), le CV principal est disponible, cet aspect doit être court
2 Ce pour quoi vous excellez, y compris technique et non technique. Les personnes techniques peuvent comprendre votre transition, mais les personnes non techniques peuvent vous comprendre en tant que personne
3 Choisissez les projets les plus importants que vous avez réalisés, ne présentez pas tous les projets comme les approbations
4. intérêts ou opinions, ou même vos propres projets de carrière. Cela devrait donner à l'intervieweur le sentiment : aimer « lancer » ou « réfléchir »
Exemple :
Bonjour l'intervieweur, je m'appelle xxx, je suis diplômé de l'université xx en xx et je suis engagé dans le développement front-end depuis l'obtention de mon diplôme. . Travail.
La pile technologique dans laquelle je suis bon est le bucket de la famille vue. J'ai un certain degré de recherche sur l'utilisation et le code source de vue2 et vue3 ; je connais les outils d'empaquetage webpack et vite ; de projets moyens et grands à partir de zéro et de capacité.
Dans mon entreprise précédente, j'étais principalement la personne en charge de la gamme de produits xx, et mes principales responsabilités l'étaient. . . . . .
En plus des travaux liés au développement, il possède également une certaine expérience en gestion technique : comme servir de réviseur des exigences, de juge de révision des interactions UI/UE, responsable de la planification du développement, de la collaboration des membres, de la révision du code des membres, de l'organisation de réunions régulières, etc.
Habituellement, j'enregistre des articles d'étude ou des notes d'étude sur le blog que j'ai créé, j'écris également des articles techniques originaux et les publie sur Nuggets, et j'ai remporté le XX Award.
En général, essayez de limiter l'auto-présentation entre 3 et 5 minutes. La première priorité est d'être concis et précis, puis de mettre en valeur vos capacités et vos points forts.
Pour les intervieweurs techniques ordinaires, l'auto-présentation n'est qu'une déclaration d'ouverture habituelle avant l'entretien. Généralement, les informations de base indiquées sur le CV ont déjà satisfait à leur compréhension de base de vous. Mais pour les intervieweurs de niveau superviseur ou les RH, ils apprécieront votre personnalité, vos habitudes comportementales, votre résistance au stress et d'autres capacités globales. Par conséquent, vous devez être aussi positif que possible pendant le processus d'entretien, avoir de larges passe-temps, comme l'apprentissage continu, comme le travail d'équipe, et être capable de faire des heures supplémentaires sans condition, etc. Bien sûr, je ne veux pas vous laisser tricher, mais dans cet environnement, ces « capacités secondaires » sont aussi des armes magiques qui peuvent améliorer votre compétitivité dans une certaine mesure.
2. Project mining
Dans la situation actuelle du marché, lorsque vous recevez un avis d'entretien, il y a de fortes chances que ce soit parce que votre expérience de projet est plus adaptée au poste pour lequel vous recrutez. Par conséquent, vous devez accorder une attention particulière à la préparation du projet, par exemple :
Approfondir les techniques utilisées dans le projet
Contrôle de la conception globaleidées du projet
Gestion du projetprocessus d'exploitation
La capacité de collaboration en équipe.
Quels sont les points d'optimisation du projet
Je n'entrerai pas dans les détails ici car ils varient d'une personne à l'autre, il suffit de les découvrir en fonction de votre propre situation.
3. Personnel
Parlons d'abord de l'individu. Lorsque vous passerez l'entretien technique et atteindrez le niveau de superviseur et des RH, peu importe à quel point votre technologie actuelle est géniale, ils examineront en outre votre potentiel personnel, votre capacité d'apprentissage, personnalité et Concernant les soft skills comme l'intégration en équipe, voici quelques questions faciles à poser :
Pourquoi as-tu changé de métier ?
Partez directement du développement personnel pour montrer votre ambition :
J'ai toujours voulu aller sur une plateforme plus grande, qui non seulement a une meilleure ambiance technique, mais qui apprend aussi plus
- Je veux m'élargir Dans en termes de connaissances, j'ai toujours créé des produits x-end xx auparavant. La pile technologique est relativement simple, je devrais donc apprendre de xx.
- Je suis tombé dans une zone de confort dans mon emploi précédent et je ne pouvais faire que ces choses. Je souhaite changer de plateforme pour élargir mon champ d'application technique, entrer en contact et apprendre de nouveaux systèmes techniques, qui seront plus bénéfiques. à mon développement personnel ultérieur
Parlez-nous de vous et des front-ends ordinaires Quels sont vos points forts ?
1. Je suis doué pour la planification et la synthèse. Je procéderai à une analyse complète des projets que je gère. L'un est le démontage des activités, en utilisant des cartes mentales pour démonter les activités de chaque module. Solution, distinguer chaque module de code selon sa fonction. Revenez au développement. Je pense que c'est quelque chose que de nombreux front-ends qui font uniquement du développement commercial aveugle ne peuvent pas faire
2 J'aime me spécialiser dans la technologie, je continue généralement à apprendre le code source de vue, et je publie également mes propres articles techniques, comme le. celui que j'ai écrit ligne par ligne auparavant. Lisez intensivement le code source de teleport , il a fallu une trentaine d'heures pour l'écrire, et interpréter la fonction et le rôle de chaque ligne de code source (mais pourquoi la lecture et les likes sont-ils si faibles) .
Quelles sont vos lacunes ?
Je suis plus sérieux et introverti, donc je vais aussi essayer de me rendre plus extraverti.
La première consiste à organiser diverses réunions de révision. En tant que représentant frontal, je dois préparer divers documents et prononcer des discours.
Je fais donc plus de partage technique au sein de l'équipe et anime des réunions régulières chaque semaine, ce qui me donne aussi le courage de m'exprimer et de discuter.
Êtes-vous attentif aux nouvelles technologies récemment ?
Outil de gestion des dépendances de packages pnpm (pas d'installation répétée de dépendances, structure node_modules non plate, ajout de packages dépendants via des liens symboliques)
outil de packaging vite (environnement de développement extrêmement rapide)
flutter (Google Cadre de développement d'applications mobiles (App) lancé et open source, axé sur le multiplateforme, la haute fidélité et les hautes performances)
rust (j'ai entendu dire que c'est la future base de js)
turbopack, le successeur de webpack , a déclaré qu'il est 10 fois plus rapide que Vite, et que le webpack est 700 fois plus rapide. Ensuite, You Yuxi a personnellement vérifié qu'il n'est pas 10 fois plus rapide que Vite. Continuer à étudier ?
- Mon plan personnel est le suivant : Dans 3 à 5 ans, tout en améliorant ma profondeur technique, j'élargirai également mes connaissances, c'est-à-dire que la profondeur et la largeur seront améliorées, principalement en largeur seulement lorsque vous serez pleinement. comprenez le grand front-end, pouvez-vous faire de meilleurs choix
Échelle de l'équipe, spécifications de l'équipe et processus de développement
Cela varie d'une personne à l'autre, alors préparez-vous simplement en conséquence, car les modèles R&D des équipes de différentes tailles sont très différents.Les objectifs de la révision du code
1. La chose la plus importante est la maintenabilité du code (nom des variables, commentaires, principe d'unité des fonctions, etc.)
2. peut être reproduit par application, évolutivité)3. Nouvelles fonctionnalités d'ES (chaîne facultative es6+, ES2020, ES2021, at)4. Spécifications d'utilisation des fonctions (par exemple, lors de l'utilisation de la carte comme forEach)
5. utiliser des algorithmes pour écrire du code plus élégant et plus performantComment diriger une équipe
J'occupais un rôle de direction technique dans ma dernière entreprise. 0,Implémenter les spécifications de développement
, j'ai publié sur le wiki interne de l'entreprise, de la dénomination, des meilleures pratiques à l'utilisation de diverses bibliothèques d'outils. Au début de l'arrivée de nouvelles personnes, je donnerai la priorité au suivi de la qualité de leur code1 Répartition du travail en équipe
: Chaque personne est responsable seule du développement d'un produit, puis je désignerai généralement. quelques personnes pour développer des modules publics2. Assurance qualité du code : Nous réviserons leur code chaque semaine, nous organiserons également une révision croisée du code et mettrons les articles de sortie des résultats modifiés dans le wiki
3 Organiser des réunions régulières : Organiser des réunions régulières. des réunions chaque semaine pour synchroniser leurs avancées et risques respectifs, répartir les tâches de travail en fonction de leur propre progression
4 Partage technologique : Nous organiserons également des partages technologiques occasionnels. Au début, c'était juste moi qui partageais, comme le micro système frontal, le code source d'ice stark
5, Public Demand Pool : comme la mise à niveau de webpack5/vite la mise à niveau de vue2.7 ; introduction du sucre de syntaxe de configuration ; utilisation de pnpm ; Optimisation des performances de la carte topologique
6, Projet d'optimisation : Après la sortie de la première version du produit, j'ai également lancé un projet spécial d'optimisation des performances, les performances de chargement du premier écran, l'optimisation du volume d'emballage. ; que chacun soit responsable des éléments d'optimisation correspondants
Que pensez-vous des heures supplémentaires ?
Je pense qu'il y a généralement deux situations lorsqu'on fait des heures supplémentaires :
Premièrement, le calendrier du projet est serré, donc bien sûr, l'avancement du projet passe en premier, après tout, tout le monde en dépend pour gagner sa vie
Deuxièmement, c'est un question de ses propres capacités, peu familier avec l'entreprise, ou introduisant une toute nouvelle pile technologique, je pense que je dois non seulement faire des heures supplémentaires pour suivre le rythme, mais aussi utiliser mon temps libre pour étudier et combler mes lacunes
Quels sont vos passe-temps ?
J'aime généralement lire, c'est-à-dire que je lis des livres sur la psychologie, la gestion du temps et certaines compétences orales en lecture sur WeChat
Ensuite, j'écris des articles, car je trouve qu'il est facile d'oublier de simplement prendre des notes. J'enregistre uniquement le contenu des autres et j'écris mes propres articles originaux. Ce faisant, je peux convertir une très grande partie de mes connaissances en mes propres contenus. Par conséquent, en plus de mes propres articles sur les mines d'or, j'ai souvent aussi des opinions sur le sujet. sortie du projet. L'article est exporté vers le wiki
D'autres passe-temps sont jouer au basket et chanter avec des amis
4. Technologie
Assurez-vous de prêter attention aux entretiens techniques : Soyez concis et précis, soyez détaillé de manière appropriée, et si vous ne comprenez pas, dites simplement que vous ne comprenez pas. Étant donné que le processus d'entretien est un processus de communication en face à face avec l'intervieweur, aucun intervieweur n'aimerait qu'un candidat bavarde longtemps sans parler des points clés. En même temps, pendant le processus de parole, l'auditeur sera passif. ignorez les parties qui ne l'intéressent pas, il est donc nécessaire de mettre en évidence les caractéristiques essentielles d'une certaine technologie et de développer de manière appropriée autour de ce noyau.
Les grandes entreprises sélectionneront essentiellement les candidats à l'aide de questions algorithmiques. Il n'y a pas de raccourcis vers les algorithmes. Vous ne pouvez répondre aux questions que étape par étape, puis répondre à nouveau aux questions. Ceux qui sont faibles dans cet aspect doivent planifier à l'avance et étudier.
Le processus d'entretien technique posera principalement des questions sur les technologies liées au domaine front-end. Généralement, l'intervieweur se basera sur votre établissement, et le plus souvent, l'intervieweur se basera sur les questions d'entretien qu'il a préparées auparavant, ou. la technologie que l'équipe du projet connaît. Cliquez pour poser des questions, car elles sont toutes inconnues, donc tous les aspects sont assez exigeants.
Si vous souhaitez entrer dans une entreprise de taille moyenne à grande avec de bonnes perspectives de développement, vous ne pouvez pas vous tromper en mémorisant simplement l'expérience des autres. Bien que chaque résumé ici soit très bref, c'est ma compréhension de chacun. les points sont quelques-uns des points de connaissances de base extraits après une étude approfondie, vous n'avez donc pas peur de la « pensée divergente » de l'intervieweur.
Le processus d'entretien implique généralement la prise en compte des huit grands types de connaissances suivants :
JS/CSS/TypeScript/Framework (Vue, React)/Navigateur et réseau/Optimisation des performances/Ingénierie front-end/Architecture/Autres
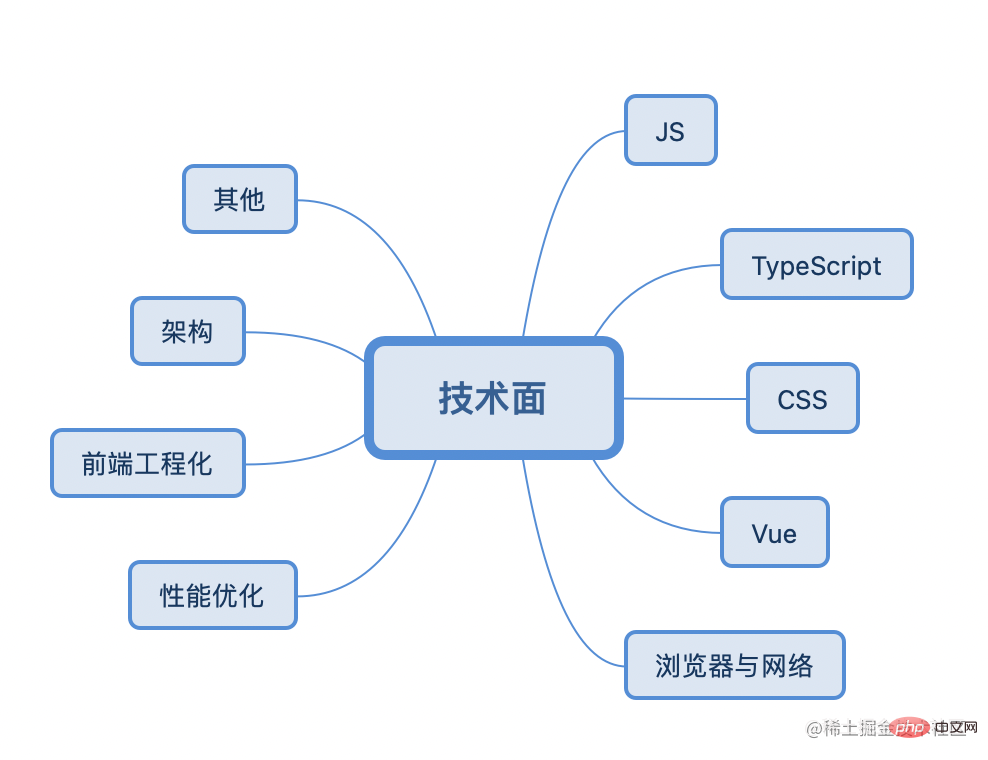
Par conséquent, la préparation technique avant l'entretien ne se fait en aucun cas du jour au lendemain. Elle nécessite également une accumulation quotidienne. Par exemple, vous pouvez consacrer dix à vingt minutes par jour à l'étude approfondie d'un des petits points de connaissance. peu importe le nombre d'années d'entretiens, il suffira de parler avec éloquence.
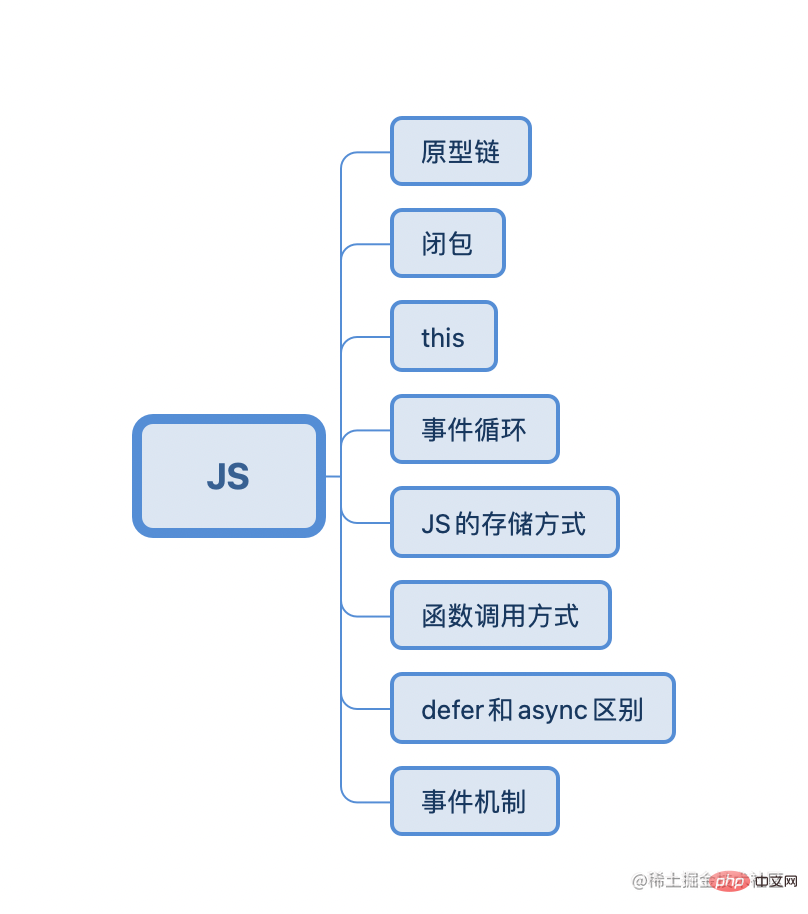
Chapitre JS
Le livre d'enveloppe rouge du Stud d'apprentissage JS et le Blog approfondi de la série JS de M. Yu YuC'est fondamentalement ok
Les questions courantes d'entretien JS incluent généralement celles-ci
Qu'est-ce qu'un prototype/ Chaîne prototype ?
L'essence d'un prototype est un objet.
Lorsque nous créons un constructeur, cette fonction aura un attribut prototype par défaut, et la valeur de cet attribut pointe vers l'objet prototype de cette fonction.
Cet objet prototype est utilisé pour fournir des attributs partagés pour les objets d'instance créés via le constructeur, c'est-à-dire que est utilisé pour implémenter l'héritage basé sur un prototype et le partage d'attributs
Ainsi, les objets d'instance que nous créons via le constructeur le seront be from L'objet prototype de cette fonction hérite des propriétés ci-dessus
Lors de la lecture des attributs de l'instance, si elle est introuvable, elle recherchera les attributs dans le prototype associé à l'objet. S'elle ne peut pas être trouvée, elle recherchera le prototype du prototype jusqu'à ce qu'elle atteigne le niveau supérieur. (le niveau supérieur est Prototype of Object.prototype, la valeur est nulle). Object.prototype的原型,值为null)。
所以通过原型一层层相互关联的链状结构就称为原型链。
什么是闭包?
定义:闭包是指引用了其他函数作用域中变量的函数,通常是在嵌套函数中实现的。
从技术角度上所有 js 函数都是闭包。
从实践角度来看,满足以下俩个条件的函数算闭包
即使创建它的上下文被销毁了,它依然存在。(比如从父函数中返回)
在代码中引用了自由变量(在函数中使用的既不是函数参数也不是函数局部变量的变量称作自由变量)
使用场景:
-
创建私有变量
vue 中的data,需要是一个闭包,保证每个data中数据唯一,避免多次引用该组件造成的data共享
-
延长变量的生命周期
一般函数的词法环境在函数返回后就被销毁,但是闭包会保存对创建时所在词法环境的引用,即便创建时所在的执行上下文被销毁,但创建时所在词法环境依然存在,以达到延长变量的生命周期的目的
应用
- 柯里化函数
- 例如计数器、延迟调用、回调函数等
this 的指向
在绝大多数情况下,函数的调用方式决定了 this 的值(运行时绑定)
1、全局的this非严格模式指向window对象,严格模式指向 undefined
2、对象的属性方法中的this 指向对象本身
3、apply、call、bind 可以变更 this 指向为第一个传参
4、箭头函数中的this指向它的父级作用域,它自身不存在 this
浏览器的事件循环?
js 代码执行过程中,会创建对应的执行上下文并压入执行上下文栈中。
如果遇到异步任务就会将任务挂起,交给其他线程去处理异步任务,当异步任务处理完后,会将回调结果加入事件队列中。
当执行栈中所有任务执行完毕后,就是主线程处于闲置状态时,才会从事件队列中取出排在首位的事件回调结果,并把这个回调加入执行栈中然后执行其中的代码,如此反复,这个过程就被称为事件循环。
事件队列分为了宏任务队列和微任务队列,在当前执行栈为空时,主线程回先查看微任务队列是否有事件存在,存在则依次执行微任务队列中的事件回调,直至微任务队列为空;不存在再去宏任务队列中处理。
常见的宏任务有setTimeout()、setInterval()、setImmediate()、I/O、用户交互操作,UI渲染
常见的微任务有promise.then()、promise.catch()、new MutationObserver、process.nextTick()
La structure de chaîne qui est interconnectée couche par couche à travers des prototypes est appelée une chaîne de prototypes.
Qu'est-ce qu'une fermeture ?
-
Définition : La fermeture fait référence à une fonction
qui fait référence à des variables dans le cadre d'autres fonctions, généralement implémentées dans des fonctions imbriquées.
- Techniquement, toutes les fonctions js sont des fermetures. D'un point de vue pratique, une fonction qui remplit les deux conditions suivantes est considérée comme une fermeture
Même si le contexte qui l'a créée est détruit, elle existe toujours. (Par exemple, retour de la fonction parent)
Les variables libres sont référencées dans le code (les variables utilisées dans la fonction qui ne sont ni des paramètres de fonction ni des variables locales de fonction sont appelées variables libres)
Définition : La fermeture fait référence à une fonction
qui fait référence à des variables dans le cadre d'autres fonctions, généralement implémentées dans des fonctions imbriquées.Scénarios d'utilisation :
Créer des variables privées
les données dans vue doivent être une fermeture pour garantir que les données de chaque donnée sont uniques et éviter le partage de données causé par de multiples références au composant
Prolonger le cycle de vie des variables
🎜Généralement, l'environnement lexical d'une fonction est détruit après le retour de la fonction, mais la fermeture conservera une référence à l'environnement lexical où elle a été créée. Même si le contexte d'exécution où elle a été créée est détruit, l'environnement lexical où elle a été créée. a été créé existe toujours pour réaliser l'extension. Le but du cycle de vie des variables🎜🎜🎜🎜🎜application🎜🎜- 🎜fonctions de currying🎜🎜telles que les compteurs, les appels retardés, les fonctions de rappel, etc.🎜🎜
-
捕获阶段:事件最开始由不太具体的节点最早接受事件, 而最具体的节点(触发节点)最后接受事件。为了让事件到达最终目标之前拦截事件。
比如点击一个div,则 click 事件会按这种顺序触发: document =>
=>=><div>,即由 document 捕获后沿着 DOM 树依次向下传播,<strong>并在各节点上触发捕获事件</strong>,直到到达实际目标元素。<li> <p><strong>目标阶段</strong></p> <p>当事件到达目标节点的,事件就进入了目标阶段。<strong>事件在目标节点上被触发</strong>(执行事件对应的函数),然后会逆向回流,直到传播至最外层的文档节点。</p> </li> <li> <p><strong>冒泡阶段</strong></p> <p>事件在目标元素上触发后,会继续随着 DOM 树一层层往上冒泡,直到到达最外层的根节点。</p> </li> <p>所有事件都要经历捕获阶段和目标阶段,但有些事件会跳过冒泡阶段,比如元素获得焦点 focus 和失去焦点 blur 不会冒泡</p> <p><strong>扩展一</strong></p> <p>e.target 和 e.currentTarget 区别?</p> <ul> <li> <code>e.target指向触发事件监听的对象。 -
e.currentTarget指向添加监听事件的对象。
🎜this Pointant vers 🎜🎜🎜Dans la plupart des cas, la méthode d'appel de la fonction détermine la valeur de this (liaison d'exécution) 🎜🎜1 Le global this non-. Le mode strict pointe vers l'objet fenêtre, et le mode strict pointe vers l'objet fenêtre non défini🎜🎜2 Ceci dans la méthode d'attribut de l'objet pointe vers l'objet lui-même🎜🎜3. Appliquer, appeler et lier peut modifier cela pour pointer vers l'objet fenêtre. premier paramètre passé🎜🎜4. Ceci dans la fonction flèche pointe vers sa portée parent, qui elle-même n'existe pas this🎜🎜La boucle d'événements du navigateur ? 🎜🎜🎜Lors de l'exécution du code js, le contexte d'exécution correspondant sera créé et poussé dans la pile de contexte d'exécution. 🎜🎜Si une tâche asynchrone est rencontrée, la tâche sera suspendue et transmise à d'autres threads pour traiter la tâche asynchrone. Lorsque la tâche asynchrone est traitée, le résultat du rappel sera ajouté à la file d'attente des événements. 🎜🎜Lorsque toutes les tâches de la pile d'exécution ont été exécutées, c'est-à-dire lorsque le thread principal est inactif, le résultat du rappel d'événement classé en premier sera retiré de la file d'attente des événements, et ce rappel sera ajouté à la pile d'exécution, puis le code qu'il contient sera exécuté, donc à plusieurs reprises, ce processus est appelé une boucle d'événements. 🎜🎜La file d'attente des événements est divisée en 🎜file d'attente des tâches macro🎜 et file d'attente des micro-tâches. Lorsque la pile d'exécution actuelle est vide, le thread principal vérifie d'abord s'il y a un événement dans la file d'attente des micro-tâches. les rappels d'événements dans la file d'attente des microtâches seront exécutés en séquence jusqu'à ce que la file d'attente des microtâches soit vide ; si elle n'existe pas, elle sera traitée dans la file d'attente des macrotâches. 🎜🎜🎜Les tâches de macro courantes incluent 🎜setTimeout(), setInterval(), setImmediate(), E/S, opérations d'interaction utilisateur, interface utilisateur rendu🎜🎜🎜Les microtâches courantes incluent🎜promise.then(), promise.catch(), new MutationObserver, process.nextTick ()🎜🎜🎜La différence essentielle entre les macro-tâches et les micro-tâches🎜🎜🎜🎜🎜Les macro-tâches ont des tâches asynchrones claires qui doivent être exécutées et des rappels, et nécessitent la prise en charge d'autres threads asynchrones🎜🎜🎜🎜Micro-tâches ne sont pas clairs. Les tâches asynchrones doivent être exécutées, seuls les rappels sont requis et aucune autre prise en charge de threads asynchrones n'est requise. 🎜🎜🎜🎜🎜Comment les données sont stockées dans la pile et le tas en JavaScript🎜🎜🎜1 Les types de données de base sont de taille fixe et faciles à utiliser, ils sont donc stockés dans la pile🎜🎜2. Les types de données sont incertains, ils sont donc stockés dans la pile et laissez-les déterminer leur taille lors de la demande de mémoire🎜🎜3. Un stockage séparé de cette manière peut minimiser l'utilisation de la mémoire. L'efficacité de la pile est supérieure à celle du tas🎜🎜4. Les variables dans la mémoire de la pile seront récupérées immédiatement après la fin de l'environnement d'exécution, tandis que toutes les références aux variables dans la mémoire du tas doivent être terminées avant de le faire. être recyclé🎜🎜🎜Parlons du garbage collection v8🎜🎜 🎜1. Effectuez le garbage collection en différentes générations en fonction de la durée de survie de l'objet, puis utilisez différents algorithmes de recyclage pour différentes générations 🎜🎜2. utilise l'algorithme de récupération de l'espace pour le temps : l'espace entier est divisé en deux blocs. Les variables n'existent que dans l'un d'eux. Lors du recyclage, les variables survivantes sont copiées dans un autre espace, et les variables non survivantes sont recyclées. est répété encore et encore🎜🎜3. L'ancienne génération utilise l'effacement des marques et le tri des marques : parcourez tous les objets et la marque est accessible (en direct), puis ceux qui ne sont pas en direct sont recyclés comme déchets. Après le recyclage, pour éviter la discontinuité de la mémoire, les objets vivants doivent être déplacés vers une extrémité de la mémoire par marquage et tri, puis nettoyer la mémoire limite une fois le mouvement terminé🎜Méthodes d'appel de fonction
setTimeout(), setInterval(), setImmediate(), E/S, opérations d'interaction utilisateur, interface utilisateur rendu🎜🎜🎜Les microtâches courantes incluent🎜promise.then(), promise.catch(), new MutationObserver, process.nextTick ()🎜🎜🎜La différence essentielle entre les macro-tâches et les micro-tâches🎜🎜🎜🎜🎜Les macro-tâches ont des tâches asynchrones claires qui doivent être exécutées et des rappels, et nécessitent la prise en charge d'autres threads asynchrones🎜🎜🎜🎜Micro-tâches ne sont pas clairs. Les tâches asynchrones doivent être exécutées, seuls les rappels sont requis et aucune autre prise en charge de threads asynchrones n'est requise. 🎜🎜🎜🎜🎜Comment les données sont stockées dans la pile et le tas en JavaScript🎜🎜🎜1 Les types de données de base sont de taille fixe et faciles à utiliser, ils sont donc stockés dans la pile🎜🎜2. Les types de données sont incertains, ils sont donc stockés dans la pile et laissez-les déterminer leur taille lors de la demande de mémoire🎜🎜3. Un stockage séparé de cette manière peut minimiser l'utilisation de la mémoire. L'efficacité de la pile est supérieure à celle du tas🎜🎜4. Les variables dans la mémoire de la pile seront récupérées immédiatement après la fin de l'environnement d'exécution, tandis que toutes les références aux variables dans la mémoire du tas doivent être terminées avant de le faire. être recyclé🎜🎜🎜Parlons du garbage collection v8🎜🎜 🎜1. Effectuez le garbage collection en différentes générations en fonction de la durée de survie de l'objet, puis utilisez différents algorithmes de recyclage pour différentes générations 🎜🎜2. utilise l'algorithme de récupération de l'espace pour le temps : l'espace entier est divisé en deux blocs. Les variables n'existent que dans l'un d'eux. Lors du recyclage, les variables survivantes sont copiées dans un autre espace, et les variables non survivantes sont recyclées. est répété encore et encore🎜🎜3. L'ancienne génération utilise l'effacement des marques et le tri des marques : parcourez tous les objets et la marque est accessible (en direct), puis ceux qui ne sont pas en direct sont recyclés comme déchets. Après le recyclage, pour éviter la discontinuité de la mémoire, les objets vivants doivent être déplacés vers une extrémité de la mémoire par marquage et tri, puis nettoyer la mémoire limite une fois le mouvement terminé🎜Méthodes d'appel de fonction
1. La fonction ordinaire utilise directement () pour appeler et transmettre des paramètres, tels que : fonction test(x, y) { return x + y}, test(3, 4)function直接使用()调用并传参,如:function test(x, y) { return x + y},test(3, 4)
2、作为对象的一个属性方法调用,如:const obj = { test: function (val) { return val } }, obj.test(2)
3、使用call或apply调用,更改函数 this 指向,也就是更改函数的执行上下文
4、new可以间接调用构造函数生成对象实例
defer和async的区别
一般情况下,当执行到 script 标签时会进行下载 + 执行两步操作,这两步会阻塞 HTML 的解析;
async 和 defer 能将script的下载阶段变成异步执行(和 html解析同步进行);
async下载完成后会立即执行js,此时会阻塞HTML解析;
defer会等全部HTML解析完成且在DOMContentLoaded 事件之前执行。
浏览器事件机制
DOM 事件流三阶段:
例如:
<ul>
<li><span>hello 1</span></li>
</ul>
let ul = document.querySelectorAll('ul')[0]
let aLi = document.querySelectorAll('li')
ul.addEventListener('click',function(e){
let oLi1 = e.target
let oLi2 = e.currentTarget
console.log(oLi1) // 被点击的li
console.log(oLi2) // ul
console.og(oLi1===oLi2) // false
})给 ul 绑定了事件,点击其中 li 的时候,target 就是被点击的 li, currentTarget 就是被绑定事件的 ul
事件冒泡阶段(上述例子),e.currenttarget和e.target是不相等的,但是在事件的目标阶段,e.currenttarget和e.target是相等的
作用:
e.target可以用来实现事件委托,该原理是通过事件冒泡(或者事件捕获)给父元素添加事件监听,e.target指向引发触发事件的元素
扩展二
addEventListener 参数
语法:
addEventListener(type, listener); addEventListener(type, listener, options || useCapture);
type: 监听事件的类型,如:'click'/'scroll'/'focus'
listener: 必须是一个实现了
EventListener接口的对象,或者是一个函数。当监听的事件类型被触发时,会执行-
options:指定 listerner 有关的可选参数对象
- capture: 布尔值,表示 listener 是否在事件捕获阶段传播到 EventTarget 时触发
- once:布尔值,表示 listener 添加之后最多调用一次,为 true 则 listener 在执行一次后会移除
- passive: 布尔值,表示 listener 永远不会调用
preventDefault() - signal:可选,
AbortSignal,当它的abort()2 Appelé comme méthode d'attribut de l'objet, tel que :
const obj = { test: function. (val) { return val } },obj.test(2)3 Utilisez -
4
newpeut indirectement appeler le constructeur pour générer une instance d'objet🎜La différence entre defer et async🎜🎜🎜 Dans des circonstances normales, lorsque la balise de script est exécutée, elle téléchargera + exécutera des opérations en deux étapes. Ces deux étapes bloqueront l'analyse du HTML ; 🎜🎜async et defer peuvent transformer la 🎜phase de téléchargement🎜 du script en exécution asynchrone (synchronisée avec l'analyse HTML) ; 🎜🎜async exécutera js immédiatement après la fin du téléchargement, ce qui bloquera l'analyse HTML 🎜🎜defer attendra que toute l'analyse HTML soit terminée ; terminé et exécuté avant l’événement DOMContentLoaded. 🎜
🎜Mécanisme d'événements du navigateur🎜🎜🎜Flux d'événements DOM en trois étapes : 🎜
- 🎜🎜🎜Étape de capture🎜 : Événements commencez par les nœuds les moins spécifiques recevant l'événement en premier, et le nœud le plus spécifique (le nœud déclencheur) recevant l'événement en dernier. Intercepter les événements avant qu’ils n’atteignent leur destination finale. 🎜🎜Par exemple, si vous cliquez sur un div, l'événement click sera déclenché dans cet ordre : document =>
- React prône la programmation fonctionnelle, les données immuables et le flux de données unidirectionnel, qui ne peuvent être transmis que via
setState. ouonchangepour implémenter les mises à jour de la vuesetState或者onchange来实现视图更新 - Vue 基于数据可变,设计了响应式数据,通过监听数据的变化自动更新视图
- React 推荐使用 jsx + inline style的形式,就是 all in js
- Vue 是单文件组件(SFC)形式,在一个组件内分模块(tmplate/script/style),当然vue也支持jsx形式,可以在开发vue的ui组件库时使用
- Vue2采用双端比较,Vue3采用快速比较
-
react主要使用diff队列保存需要更新哪些DOM,得到patch树,再统一操作批量更新DOM。,需要使用shouldComponentUpdate()来手动优化react的渲染。 - props / $emit
- ref / $refs
- root
- attrs / listeners
- eventBus / vuex / pinia / localStorage / sessionStorage / Cookie / window
- provide / inject
- 同步头部节点
- 同步尾部节点
- 新增新的节点
- 删除多余节点
- 处理未知子序列(贪心 + 二分处理最长递增子序列)
处于同一个 BFC 的元素外边距会产生重叠(此时需要将它们放在不同 BFC 中);
清除浮动(float),使用 BFC 包裹浮动的元素即可
阻止元素被浮动元素覆盖,应用于两列式布局,左边宽度固定,右边内容自适应宽度(左边float,右边 overflow)
href是Hypertext Reference的简写,表示超文本引用,指向网络资源所在位置。href 用于在当前文档和引用资源之间确立联系
src是source的简写,目的是要把文件下载到html页面中去。src 用于替换当前内容
-
浏览器解析方式
当浏览器遇到href会并行下载资源并且不会停止对当前文档的处理。(同时也是为什么建议使用 link 方式加载 CSS,而不是使用 @import 方式)
当浏览器解析到src ,会暂停其他资源的下载和处理,直到将该资源加载或执行完毕。(这也是script标签为什么放在底部而不是头部的原因)
-
flex
<div class="wrapper flex-center"> <p>horizontal and vertical</p> </div> .wrapper { width: 900px; height: 300px; border: 1px solid #ccc; } .flex-center { // 注意是父元素 display: flex; justify-content: center; // 主轴(竖线)上的对齐方式 align-items: center; // 交叉轴(横轴)上的对齐方式 } -
flex + margin
<div class="wrapper"> <p>horizontal and vertical</p> </div> .wrapper { width: 900px; height: 300px; border: 1px solid #ccc; display: flex; } .wrapper > p { margin: auto; } -
Transform + absolute
<div class="wrapper"> <img src="/static/imghwm/default1.png" data-src="test.png" class="lazy" alt="Trois années de partage d'expérience en entretien : quatre étapes et trois facteurs déterminants des entretiens front-end" > </div> .wrapper { width: 300px; height: 300px; border: 1px solid #ccc; position: relative; } .wrapper > img { position: absolute; left: 50%; top: 50%; tansform: translate(-50%, -50%) }注:使用该方法只适用于行内元素(a、img、label、br、select等)(宽度随元素的内容变化而变化),用于块级元素(独占一行)会有问题,left/top 的50%是基于图片最左侧的边来移动的,tanslate会将多移动的图片自身的半个长宽移动回去,就实现了水平垂直居中的效果
-
display: table-cell
<div class="wrapper"> <p>absghjdgalsjdbhaksldjba</p> </div> .wrapper { width: 900px; height: 300px; border: 1px solid #ccc; display: table-cell; vertical-align: middle; text-align: center; } -
存储型 xss
黑客利用站点漏洞将恶意 js 代码提交到站点服务器,用户访问页面就会导致恶意脚本获取用户的cookie等信息。
-
反射性 xss
用户将一段恶意代码请求提交给 web 服务器,web 服务器接收到请求后将恶意代码反射到浏览器端
-
基于 DOM 的 xss 攻击
通过网络劫持在页面传输过程中更改 HTML 内容
-
自动发起 get 请求
比如黑客网站有个图片:
<img src="/static/imghwm/default1.png" data-src="https://time.geekbang.org/sendcoin?user=hacker&number=100" class="lazy" alt="Trois années de partage d'expérience en entretien : quatre étapes et trois facteurs déterminants des entretiens front-end" >
黑客将转账的请求接口隐藏在 img 标签内,欺骗浏览器这是一张图片资源。当该页面被加载时,浏览器会自动发起 img 的资源请求,如果服务器没有对该请求做判断的话,那么服务器就会认为该请求是一个转账请求,于是用户账户上的 100 极客币就被转移到黑客的账户上去了。
-
自动发起 post 请求
黑客在页面中构建一个隐藏的表单,当用户点开链接后,表单自动提交
-
引诱用户点击链接
比如页面上放了一张美女图片,下面放了图片下载地址,而这个下载地址实际上是黑客用来转账的接口,一旦用户点击了这个链接,那么他的极客币就被转到黑客账户上了
- Scénario d'application : (la requête GET est une requête idempotent) Généralement, la requête Get est utilisée pour faire des requêtes à le serveur Scénarios dans lesquels les ressources n'auront pas d'impact, comme la demande de ressources pour une page Web. (Et Post n'est pas une requête idempotent) Elle est généralement utilisée dans des scénarios qui ont un impact sur les ressources du serveur, comme des opérations telles que l'enregistrement des utilisateurs. (Idempotence signifie que l'effet de l'exécution d'une méthode de requête plusieurs fois et de son exécution une seule fois est exactement le même)
- Faut-il mettre en cache : Parce que les scénarios d'application des deux sont différents, les navigateurs mettent généralement en cache les requêtes Get, mais rarement Publier des requêtes Demander la mise en cache.
- Les paramètres sont transmis de différentes manières : Get transmet les paramètres via la chaîne de requête et Post transmet les paramètres via le corps de la requête.
- Sécurité : La requête Get peut mettre les paramètres demandés dans l'URL et l'envoyer au serveur. Cette approche est moins sûre que la requête Post car l'URL demandée sera conservée dans l'historique.
- Longueur de la requête : En raison des restrictions de longueur du navigateur sur l'URL, cela affectera la longueur de la requête d'obtention lors de l'envoi des données. Cette restriction est stipulée par le navigateur et non par la RFC.
- Type de paramètre : Le paramètre get autorise uniquement les caractères ASCII, et le transfert de paramètres post prend en charge plus de types de données (tels que des fichiers, des images).
-
Du point de vue de la mise en cache
- Lisez certaines données volumineuses qui ne changent pas fréquemment via localstorage/sessionStorage/indexdDB
- Utilisez le cache http (cache fort et négociation) Cache), stocker le contenu en mémoire ou sur le disque dur, réduisant ainsi les requêtes au serveur
Il est plus couramment utilisé dans le réseau pour utiliser le CDN pour les ressources statiques
-
En termes de packaging
- Sur- chargement des routes à la demande
- Emballage optimisé La taille de la ressource finale
- Activer les ressources de compression gzip
- Charger des bibliothèques tierces à la demande
-
Niveau de code
- Réduire les requêtes inutiles et supprimer le code inutile
- Éviter les longues -temps de traitement js bloquant les threads principaux (cela prend du temps et n'est pas pertinent pour le DOM peut être envoyé aux travailleurs Web pour traitement ou divisé en petites tâches) Amélioration de la vitesse du premier écran
- Chargement paresseux des routes, le premier écran ne demandera que les ressources liées à la première routeUtilisez cdn pour accélérer le troisième -bibliothèques de fête, nous sommes un produit de toB, vous en aurez besoin. Il est déployé sur l'intranet, il n'est donc généralement pas utilisé. ToC est principalement utilisé
- rendu côté serveur ssr, et le serveur renvoie directement le code HTML épissé. page
- vue Méthodes courantes d'optimisation des performances
- Défilement virtuelComposant fonctionnel
- v-show/ keep-alive Réutilisation dom
- deffer composant de rendu retardé (requestIdleCallback) "Time Slicing" tri et stockage, affichage des données
- Indicateurs de performance des pages Web :
- FP (first-paint) Le temps entre le chargement de la page et le moment où le premier pixel est dessiné à l'écran
- FCP (first-contentful-paint ), le temps entre le chargement de la page et la fin du rendu à l'écran d'une partie du contenu de la page
LCP (largest-contentful-paint), le temps entre le chargement de la page et l'achèvement du rendu du plus grand élément de texte ou d'image à l'écran 首屏渲染时间计算:通过
MutationObserver监听document对象的属性变化样式集中改变,好的方式是使用动态 class
-
读写操作分离,避免读后写,写后又读
// bad 强制刷新 触发四次重排+重绘 div.style.left = div.offsetLeft + 1 + 'px'; div.style.top = div.offsetTop + 1 + 'px'; div.style.right = div.offsetRight + 1 + 'px'; div.style.bottom = div.offsetBottom + 1 + 'px'; // good 缓存布局信息 相当于读写分离 触发一次重排+重绘 var curLeft = div.offsetLeft; var curTop = div.offsetTop; var curRight = div.offsetRight; var curBottom = div.offsetBottom; div.style.left = curLeft + 1 + 'px'; div.style.top = curTop + 1 + 'px'; div.style.right = curRight + 1 + 'px'; div.style.bottom = curBottom + 1 + 'px';
原来的操作会导致四次重排,读写分离之后实际上只触发了一次重排,这都得益于浏览器的渲染队列机制:
当我们修改了元素的几何属性,导致浏览器触发重排或重绘时。它会把该操作放进渲染队列,等到队列中的操作到了一定的数量或者到了一定的时间间隔时,浏览器就会批量执行这些操作。
使用
display: none后元素不会存在渲染树中,这时对它进行各种操作,然后更改 display 显示即可(示例:向2000个div中插入一个div)通过 documentFragment 创建 dom 片段,在它上面批量操作 dom ,操作完后再添加到文档中,这样只有一次重排(示例:一次性插入2000个div)
复制节点在副本上操作然后替换它
使用 BFC 脱离文档流,重排开销小
-
优化请求数
- 雪碧图,将所有图标合并成一个独立的图片文件,再通过
background-url和backgroun-position来显示图标 - 懒加载,尽量只加载用户正则浏览器或者即将浏览的图片。最简单使用监听页面滚动判断图片是否进入视野;使用 intersection Observer API;使用已知工具库;使用css的
background-url来懒加载 - base64,小图标或骨架图可以使用内联 base64因为 base64相比普通图片体积大。注意首屏不需要懒加载,设置合理的占位图避免抖动。
- 雪碧图,将所有图标合并成一个独立的图片文件,再通过
-
减小图片大小
- 使用合适的格式比如WebP、svg、video替代 GIF 、渐进式 JPEG
- 削减图片质量
- 使用合适的大小和分辨率
- 删除冗余的图片信息
- Svg 压缩
缓存
非响应式变量可以定义在
created钩子中使用 this.xxx 赋值访问局部变量比全局变量块,因为不需要切换作用域
尽可能使用
const声明变量,注意数组和对象使用 v8 引擎时,运行期间,V8 会将创建的对象与隐藏类关联起来,以追踪它们的属性特征。能够共享相同隐藏类的对象性能会更好,v8 会针对这种情况去优化。所以为了贴合”共享隐藏类“,我们要避免”先创建再补充“式的动态属性复制以及动态删除属性(使用delete关键字)。即尽量在构造函数/对象中一次性声明所有属性。属性删除时可以设置为 null,这样可以保持隐藏类不变和继续共享。
-
避免内存泄露的方式
- 尽可能少创建全局变量
- 手动清除定时器
- 少用闭包
- 清除 DOM 引用
- 弱引用
避免强制同步,在修改 DOM 之前查询相关值
避免布局抖动(一次 JS 执行过程中多次执行强制布局和抖动操作),尽量不要在修改 DOM 结构时再去查询一些相关值
合理利用 css 合成动画,如果能用 css 处理就交给 css。因为合成动画会由合成线程执行,不会占用主线程
避免频繁的垃圾回收,优化存储结构,避免小颗粒对象的产生
-
hash : chaque fois que le projet est construit, un hachage sera généré, qui est lié à l'ensemble du projet. S'il y a des changements quelque part dans le projet, il changera.
le hachage sera calculé en fonction du contenu de chaque projet, il est facile de provoquer des changements de hachage inutiles, ce qui n'est pas propice à la gestion des versions. D’une manière générale, il y a peu de possibilités d’utiliser directement les hachages.
-
hash de contenu : lié au contenu d'un seul fichier. Si le contenu du fichier spécifié change, le hachage changera. Le contenu reste inchangé et la valeur de hachage reste inchangée
Pour les fichiers CSS, MiniCssExtractPlugin est généralement utilisé pour l'extraire dans un fichier CSS séparé.
Vous pouvez utiliser contenthash pour marquer ce moment afin de vous assurer que le hachage peut être mis à jour lorsque le contenu du fichier CSS change.
-
chunk hash : lié au chunk généré par le packaging webpack. Chaque entrée aura un hachage différent.
De manière générale, pour les fichiers de sortie, nous utilisons chunkhash.
Parce qu'une fois le webpack empaqueté, chaque fichier d'entrée et ses dépendances finiront par générer un fichier js distinct.
L'utilisation de chunkhash à ce stade peut garantir l'exactitude de la mise à jour de l'ensemble du contenu packagé.
-
Environnement de développement
Vite utilise le navigateur pour analyser les importations, compiler et renvoyer à la demande côté serveur, en sautant complètement la notion de packaging, et le le serveur suivra Facile à utiliser (équivalent à convertir les fichiers que nous développons au format ESM et à les envoyer directement au navigateur)
Lorsque le navigateur analyse l'importation de HelloWorld depuis './components/HelloWorld.vue', il enverra une requête au nom de domaine actuel pour obtenir Pour les ressources correspondantes (ESM prend en charge l'analyse des chemins relatifs), le navigateur télécharge directement les fichiers correspondants et les analyse dans les enregistrements du module (ouvrez le panneau réseau et vous pouvez voir que les données de réponse sont toutes de type ESM js ). Ensuite, instanciez et allouez de la mémoire au module, et établissez la relation de mappage entre le module et la mémoire en fonction des instructions d'importation et d'exportation. Enfin, exécutez le code.
vite démarrera un serveur koa pour intercepter la demande d'ESM du navigateur, trouvera le fichier correspondant dans le répertoire via le chemin de la demande, le traitera au format ESM et le renverra au client.
Le chargement à chaud de Vite établit une connexion websocket entre le client et le serveur. Une fois le code modifié, le serveur envoie un message pour informer le client de demander le code du module modifié. Pour terminer la mise à jour à chaud, cela signifie redemander celui-ci. Le fichier de vue est modifié. Ce fichier garantit que la vitesse de mise à jour à chaud n'est pas affectée par la taille du projet.
L'environnement de développement utilisera esbuild pour pré-construire le cache pour les dépendances. Le premier démarrage sera plus lent et les démarrages suivants liront directement le cache
-
L'environnement de production
utilise le rollup pour créer le code et fournit. instructions pour optimiser le processus de construction. L'inconvénient est que l'environnement de développement et l'environnement de production peuvent être incohérents ;
- 5. Le projet ESM active la balise useExport ; et utilise le tremblement d'arborescence
- 7. exclure/inclure spécifie la plage correspondante ; l'alias spécifie l'alias du chemin ; le stockage persistant du chargeur de cache
- ES6模块是引用,重新赋值会编译报错,不能修改其变量的指针指向,但可以改变内部属性的值;
- ES6模块中的值属于动态只读引用。
- 对于只读来说,即不允许修改引入变量的值,import的变量是只读的,不论是基本数据类型还是复杂数据类型。当模块遇到import命令时,就会生成一个只读引用。等到脚本真正执行时,再根据这个只读引用,到被加载的那个模块里面去取值。
- 对于动态来说,原始值发生变化,import 加载的值也会发生变化。不论是基本数据类型还是复杂数据类型。
- 循环加载时,ES6模块是动态引用。只要两个模块之间存在某个引用,代码就能够执行。
- CommonJS模块是拷贝(浅拷贝),可以重新赋值,可以修改指针指向;
- 对于基本数据类型,属于复制。即会被模块缓存。同时,在另一个模块可以对该模块输出的变量重新赋值。
- 对于复杂数据类型,属于浅拷贝。由于两个模块引用的对象指向同一个内存空间,因此对该模块的值做修改时会影响另一个模块。 当使用require命令加载某个模块时,就会运行整个模块的代码。
- 当使用require命令加载同一个模块时,不会再执行该模块,而是取到缓存之中的值。也就是说,CommonJS模块无论加载多少次,都只会在第一次加载时运行一次,以后再加载,就返回第一次运行的结果,除非手动清除系统缓存。
- 当循环加载时,脚本代码在require的时候,就会全部执行。一旦出现某个模块被"循环加载",就只输出已经执行的部分,还未执行的部分不会输出。
- Le module ES6 est une référence, la réaffectation provoquera une erreur de compilation, ne peut pas Modifiez le pointeur de sa variable, mais vous pouvez changer la valeur de la propriété interne ;
- Les valeurs du module ES6 sont des références dynamiques en lecture seule.
- En lecture seule, c'est-à-dire que la valeur de la variable importée ne peut pas être modifiée. La variable importée est en lecture seule, qu'il s'agisse d'un type de données de base ou d'un type de données complexe. Lorsqu'un module rencontre une commande d'importation, une référence en lecture seule est générée. Lorsque le script est réellement exécuté, la valeur sera récupérée du module chargé en fonction de cette référence en lecture seule.
- Pour les dynamiques, lorsque la valeur d'origine change, la valeur chargée par import changera également. Qu'il s'agisse d'un type de données de base ou d'un type de données complexe.
- Lors d'un chargement en boucle, les modules ES6 sont référencés dynamiquement. Tant qu'une référence existe entre les deux modules, le code pourra s'exécuter.
- Le module CommonJS est une copie (copie superficielle), qui peut être réaffectée et le pointeur pointé vers ;
- Pour les types de données de base ; , il appartient à la copie. Autrement dit, il sera mis en cache par le module. Parallèlement, les variables sorties par ce module peuvent être réaffectées dans un autre module.
- Pour les types de données complexes, il s'agit d'une copie superficielle. Puisque les objets référencés par les deux modules pointent vers le même espace mémoire, les modifications de la valeur du module affecteront l'autre module. Lorsqu'un module est chargé à l'aide de la commande require, l'intégralité du code du module sera exécuté.
- Lorsque la commande require est utilisée pour charger le même module, le module ne sera pas exécuté à nouveau, mais la valeur dans le cache sera obtenue. En d'autres termes, quel que soit le nombre de chargements du module CommonJS, il ne s'exécutera qu'une seule fois lors de son premier chargement. S'il est chargé ultérieurement, le résultat de la première exécution sera renvoyé, sauf si le cache système est chargé. effacé manuellement.
- Lors d'un chargement en boucle, tous les codes de script seront exécutés lorsque nécessaire. Une fois qu'un module est "chargé en boucle", seule la partie exécutée sera sortie, et la partie non exécutée ne sera pas sortie.
- 转义 esnext、typescript 到目标环境支持 js (高级语言到到低级语言叫编译,高级语言到高级语言叫转译)
- 代码转换(taro)
- 代码分析(模块分析、tree-shaking、linter 等)
parse 阶段:首先使用
@babel/parser将源码转换成 ASTtransform 阶段:接着使用
@babel/traverse遍历 AST,并调用 visitor 函数修改 AST,修改过程中通过@babel/types来创建、判断 AST 节点;使用@babel/template来批量创建 ASTgenerate 阶段:使用
@babel/generate将 AST 打印为目标代码字符串,期间遇到代码错误位置时会用到@babel/code-frame
=> > =>, c'est-à-dire qu'il est capturé par le document puis propagé vers le bas le long de l'arborescence DOM, 🎜 et déclenche des événements de capture sur chaque nœud 🎜 jusqu'à ce qu'il atteigne l'élément cible réel. . 🎜🎜🎜🎜🎜Phase cible🎜🎜🎜Lorsque l'événement atteint le nœud cible, l'événement entre dans la phase cible. 🎜L'événement est déclenché sur le nœud cible🎜 (exécutant la fonction correspondant à l'événement), puis revient en sens inverse jusqu'à ce qu'il se propage vers le nœud de document le plus externe. 🎜🎜🎜🎜🎜Phase de bouillonnement🎜🎜🎜Une fois l'événement déclenché sur l'élément cible, il continuera à bouillonner couche par couche le long de l'arborescence DOM jusqu'à ce qu'il atteigne le nœud racine le plus externe. 🎜🎜🎜🎜Tous les événements doivent passer par la phase de capture et la phase de cible, mais certains événements sauteront la phase de bouillonnement, comme l'élément qui gagne et perd la concentration, le flou ne bouillonnera pas 🎜🎜🎜Extended 🎜🎜🎜e. différence entre target et e.currentTarget ? 🎜- 🎜
e.targetpointe vers l'objet qui déclenche l'écoute des événements. 🎜🎜e.currentTargetpointe vers l'objet ajouté pour écouter l'événement. 🎜🎜🎜Par exemple : 🎜// 比如 <input v-model="sth" /> // 等价于 <input :value="sth" @input="sth = $event.target.value" />
🎜 a lié un événement à ul. Lorsque vous cliquez sur le li, la cible est le li cliqué, et currentTarget est l'étape de bouillonnement de l'événement ul🎜🎜 de l'événement lié (l'exemple ci-dessus), e.currenttarget ete.targetne sont pas égaux, mais dans la phase cible de l'événement,e.currenttargetete.target>Est égal 🎜🎜Fonction : 🎜🎜e.targetpeut être utilisé pour atteindre Délégation d'événement, le principe est d'utiliser le bouillonnement d'événement (ou capture d'événement) pour ajouter un événement à l'écoute de l'élément parent, e.target pointe vers l'élément qui a déclenché l'événement déclencheur 🎜🎜🎜Extension 2🎜🎜🎜addEventListener paramètres🎜🎜Syntaxe : 🎜// 父组件 <my-button v-model="number"></my-button> // 子组件 <script> export default { props: { value: Number, // 属性名必须是 value }, methods: { add() { this.$emit('input', this.value + 1) // 事件名必须是 input }, } } </script>- 🎜🎜type : Le type de événement d'écoute, tel que : 'click'/' scroll'/'focus'🎜🎜🎜🎜listener : doit être une implémentation
EventListenerobjet de l'interface, ou C'est un docs/Web/JavaScript/Guide/Functions" ref="nofollow noopener noreferrer">Fonctions. Lorsque le type d'événement surveillé est déclenché, il sera exécuté 🎜🎜🎜🎜options : Spécifiez l'objet paramètre facultatif lié à l'écouteur 🎜- 🎜capture : valeur booléenne, indiquant si l'écouteur est déclenché lorsqu'il est propagé à l'EventTarget pendant le phase de capture d'événement 🎜🎜once : valeur booléenne, indiquant que l'écouteur sera appelé au plus une fois après avoir été ajouté. Si vrai, l'écouteur sera supprimé après avoir été exécuté une fois 🎜🎜passive : valeur booléenne, indiquant que l'écouteur ne le sera jamais. call
preventDefault()🎜🎜signal : Facultatif,AbortSignal, lorsque sa méthodeabort()est appelée, l'écouteur sera supprimé🎜🎜🎜 🎜🎜useCapture : valeur booléenne, la valeur par défaut est false, l'écouteur est exécuté à la fin de la phase de bouillonnement de l'événement, et true signifie qu'il est exécuté au début de la phase de capture. La fonction est de modifier le timing de l'événement pour faciliter l'interception/non-interception. 🎜Article Vue
L'auteur est principalement engagé dans le développement lié à Vue et a également réalisé des projets liés à React. Bien sûr, React n'est qu'au niveau de la capacité à réaliser des projets, c'est donc le genre. de chose qui peut être mentionnée dans un CV. Le framework n'est pas cher. Plus c'est mieux, mieux c'est. Apprendre la série de codes sources Vue me rend très confiant dans Vue. Il en va de même pour le processus d'apprentissage. Si vous parvenez à maîtriser les principes d'un framework, l'apprentissage d'autres frameworks n'est qu'une question de temps.

La différence entre vue et réagir
1 Variabilité des données
2、写法
3、diff 算法
扩展:了解 react hooks吗
组件类的写法很重,层级一多很难维护。
函数组件是纯函数,不能包含状态,也不支持生命周期方法,因此无法取代类。
React Hooks 的设计目的,就是加强版函数组件,完全不使用"类",就能写出一个全功能的组件
React Hooks 的意思是,组件尽量写成纯函数,如果需要外部功能和副作用,就用钩子把外部代码"钩"进来。
vue组件通信方式
vue 渲染列表为什么要加key?
Vue 在处理更新同类型 vnode 的一组子节点(比如v-for渲染的列表节点)的过程中,为了减少 DOM 频繁创建和销毁的性能开销:
对没有 key 的子节点数组更新是通过就地更新的策略。它会通过对比新旧子节点数组的长度,先以比较短的那部分长度为基准,将新子节点的那一部分直接 patch 上去。然后再判断,如果是新子节点数组的长度更长,就直接将新子节点数组剩余部分挂载;如果是新子节点数组更短,就把旧子节点多出来的那部分给卸载掉)。所以如果子节点是组件或者有状态的 DOM 元素,原有的状态会保留,就会出现渲染不正确的问题。
有 key 的子节点更新是调用的
patchKeyedChildrenVue conçoit des données réactives en fonction de la variabilité des données et met automatiquement à jour la vue en surveillant les modifications des données2. Méthode d'écriture
🎜🎜React recommande d'utiliser le style jsx + inline. Le formulaire est entièrement en js🎜🎜Vue est un formulaire de composant de fichier unique (SFC), divisé en modules (tmplate/script/style) au sein d'un composant. Bien sûr, vue prend également en charge le formulaire jsx, qui peut être utilisé lors du développement de l'interface utilisateur de vue. bibliothèque de composants🎜 🎜🎜3. Algorithme Diff🎜🎜🎜Vue2 utilise une comparaison double, Vue3 utilise une comparaison rapide🎜🎜reactutilise principalement la file d'attente diff pour enregistrer les DOM qui doivent être mis à jour, obtenir le patch arborescence, puis effectuez des opérations unifiées pour mettre à jour les DOM par lots. , vous devez utilisershouldComponentUpdate()pour optimiser manuellement le rendu de réaction. 🎜🎜🎜🎜Extension : Connaissez-vous les hooks de réaction ? 🎜🎜🎜L'écriture des classes de composants est très lourde, et elle est difficile à maintenir s'il y a trop de niveaux. 🎜🎜Les composants de fonction sont des fonctions pures, ne peuvent pas contenir d'état et ne prennent pas en charge les méthodes de cycle de vie, ils ne peuvent donc pas remplacer les classes. 🎜🎜🎜Le but de la conception de React Hooks est d'améliorer le composant fonctionnel. Vous pouvez écrire un composant complet sans utiliser de "classes" du tout 🎜🎜🎜🎜React Hooks signifie que le composant doit être écrit comme une fonction pure. autant que possible. Si un composant externe est nécessaire, pour les fonctions et les effets secondaires, utilisez des hooks pour "accrocher" du code externe. 🎜🎜🎜méthode de communication des composants vue🎜🎜🎜🎜props / $emit🎜🎜ref / $refs🎜🎜root🎜🎜attrs / auditeurs🎜🎜eventBus / vuex / pinia / localStorage / sessionStorage / Cookie / window🎜🎜provide / inject🎜🎜
Pourquoi 🎜vue ajoute-t-il une clé à la liste de rendu ? 🎜🎜🎜Vue est en train de mettre à jour un groupe de nœuds enfants du même type de vnode (comme le nœud de liste rendu par v-for), afin de réduire la création et la destruction fréquentes de la surcharge de performances du DOM : 🎜🎜La mise à jour du tableau de nœuds enfants sans clé s'effectue via la stratégie 🎜mise à jour sur place🎜. Il comparera les longueurs des anciens et des nouveaux tableaux de nœuds enfants, utilisera d'abord la longueur la plus courte comme base et corrigera directement la partie du nouveau nœud enfant. Ensuite, jugez, si la longueur du nouveau tableau de nœuds enfants est plus longue, montez directement la partie restante du nouveau tableau de nœuds enfants ; si le nouveau tableau de nœuds enfants est plus court, désinstallez la partie supplémentaire de l'ancien nœud enfant) . 🎜Donc, si le nœud enfant est un composant ou un élément DOM avec état, l'état d'origine sera conservé et un rendu incorrect se produira🎜. 🎜🎜La mise à jour des nœuds enfants avec la clé s'appelle
patchKeyedChildren. Cette fonction est l'endroit familier pour implémenter l'algorithme de comparaison de base. Le processus général consiste à synchroniser le nœud principal, le nœud final et le processus. ajout et suppression de nœuds, et enfin utiliser la méthode de résolution de la sous-séquence croissante la plus longue pour traiter la sous-séquence inconnue. Il s'agit de maximiser la réutilisation des nœuds existants, de réduire la surcharge de performances des opérations DOM et d'éviter le problème des erreurs d'état des nœuds enfants causées par les mises à jour sur place. 🎜🎜Pour résumer, si vous utilisez v-for pour parcourir des constantes ou si les nœuds enfants sont des nœuds sans "état" comme du texte brut, vous pouvez utiliser la méthode d'écriture sans ajouter de clé. Cependant, dans le processus de développement réel, il est recommandé d'ajouter la clé de manière uniforme, ce qui permet de réaliser un plus large éventail de scénarios et d'éviter d'éventuelles erreurs de mise à jour de statut. Nous pouvons généralement utiliser ESlint pour configurer la clé en tant qu'élément requis de v-for. 🎜想详细了解这个知识点的可以去看看我之前写的文章:v-for 到底为啥要加上 key?
vue3 相对 vue2的响应式优化
vue2使用的是
Object.defineProperty去监听对象属性值的变化,但是它不能监听对象属性的新增和删除,所以需要使用$set、$delete这种语法糖去实现,这其实是一种设计上的不足。所以 vue3 采用了
proxy去实现响应式监听对象属性的增删查改。其实从api的原生性能上
proxy是比Object.defineProperty要差的。而 vue 做的响应式性能优化主要是在将嵌套层级比较深的对象变成响应式的这一过程。
vue2的做法是在组件初始化的时候就递归执行
Object.defineProperty把子对象变成响应式的;而vue3是在访问到子对象属性的时候,才会去将它转换为响应式。这种延时定义子对象响应式会对性能有一定的提升
Vue 核心diff流程
前提:当同类型的 vnode 的子节点都是一组节点(数组类型)的时候,
步骤:会走核心 diff 流程
Vue3是快速选择算法
Vue2是双端比较算法
在新旧字节点的头尾节点,也就是四个节点之间进行对比,找到可复用的节点,不断向中间靠拢的过程
diff目的:diff 算法的目的就是为了尽可能地复用节点,减少 DOM 频繁创建和删除带来的性能开销
vue双向绑定原理
基于 MVVM 模型,viewModel(业务逻辑层)提供了数据变化后更新视图和视图变化后更新数据这样一个功能,就是传统意义上的双向绑定。
Vue2.x 实现双向绑定核心是通过三个模块:Observer监听器、Watcher订阅者和Compile编译器。
首先监听器会监听所有的响应式对象属性,编译器会将模板进行编译,找到里面动态绑定的响应式数据并初始化视图;watchr 会去收集这些依赖;当响应式数据发生变更时Observer就会通知 Watcher;watcher接收到监听器的信号就会执行更新函数去更新视图;
vue3的变更是数据劫持部分使用了porxy 替代 Object.defineProperty,收集的依赖使用组件的副作用渲染函数替代watcher
v-model 原理
vue2 v-model 原理剖析
V-model 是用来监听用户事件然后更新数据的语法糖。
其本质还是单向数据流,内部是通过绑定元素的 value 值向下传递数据,然后通过绑定 input 事件,向上接收并处理更新数据。
单向数据流:父组件传递给子组件的值子组件不能修改,只能通过emit事件让父组件自个改。
// 比如 <input v-model="sth" /> // 等价于 <input :value="sth" @input="sth = $event.target.value" />
给组件添加
v-model属性时,默认会把value作为组件的属性,把input作为给组件绑定事件时的事件名:// 父组件 <my-button v-model="number"></my-button> // 子组件 <script> export default { props: { value: Number, // 属性名必须是 value }, methods: { add() { this.$emit('input', this.value + 1) // 事件名必须是 input }, } } </script>如果想给绑定的 value 属性和 input 事件换个名称呢?可以这样:
在 Vue 2.2 及以上版本,你可以在定义组件时通过 model 选项的方式来定制 prop/event:
<script> export default { model: { prop: 'num', // 自定义属性名 event: 'addNum' // 自定义事件名 } }vue3 v-model 原理
实现和 vue2 基本一致
<Son v-model="modalValue"/>
等同于
<Son v-model="modalValue"/>
自定义 model 参数
<Son v-model:visible="visible"/> setup(props, ctx){ ctx.emit("update:visible", false) }vue 响应式原理
不管vue2 还是 vue3,响应式的核心就是观察者模式 + 劫持数据的变化,在访问的时候做依赖收集和在修改数据的时候执行收集的依赖并更新数据。具体点就是:
vue2 的话采用的是
Object.definePorperty劫持对象的 get 和 set 方法,每个组件实例都会在渲染时初始化一个 watcher 实例,它会将组件渲染过程中所接触的响应式变量记为依赖,并且保存了组件的更新方法 update。当依赖的 setter 触发时,会通知 watcher 触发组件的 update 方法,从而更新视图。Vue3 使用的是 ES6 的 proxy,proxy 不仅能够追踪属性的获取和修改,还可以追踪对象的增删,这在 vue2中需要 delete 才能实现。然后就是收集的依赖是用组件的副作用渲染函数替代 watcher 实例。
性能方面,从原生 api 角度,proxy 这个方法的性能是不如 Object.property,但是 vue3 强就强在一个是上面提到的可以追踪对象的增删,第二个是对嵌套对象的处理上是访问到具体属性才会把那个对象属性给转换成响应式,而 vue2 是在初始化的时候就递归调用将整个对象和他的属性都变成响应式,这部分就差了。
扩展一
vue2 通过数组下标更改数组视图为什么不会更新?
尤大:性能不好
注意:vue3 是没问题的
why 性能不好?
我们看一下响应式处理:
export class Observer { this.value = value this.dep = new Dep() this.vmCount = 0 def(value, '__ob__', this) if (Array.isArray(value)) { // 这里对数组进行单独处理 if (hasProto) { protoAugment(value, arrayMethods) } else { copyAugment(value, arrayMethods, arrayKeys) } this.observeArray(value) } else { // 对对象遍历所有键值 this.walk(value) } } walk (obj: Object) { const keys = Object.keys(obj) for (let i = 0; i < keys.length; i++) { defineReactive(obj, keys[i]) } } observeArray (items: Array<any>) { for (let i = 0, l = items.length; i < l; i++) { observe(items[i]) } } }对于对象是通过
Object.keys()遍历全部的键值,对数组只是observe监听已有的元素,所以通过下标更改不会触发响应式更新。理由是数组的键相较对象多很多,当数组数据大的时候性能会很拉胯。所以不开放
computed 和 watch
Computed 的大体实现和普通的响应式数据是一致的,不过加了延时计算和缓存的功能:
在访问computed对象的时候,会触发 getter ,初始化的时候将 computed 属性创建的 watcher (vue3是副作用渲染函数)添加到与之相关的响应式数据的依赖收集器中(dep),然后根据里面一个叫 dirty 的属性判断是否要收集依赖,不需要的话直接返回上一次的计算结果,需要的话就执行更新重新渲染视图。
watchEffect?
watchEffect会自动收集回调函数中响应式变量的依赖。并在首次自动执行
推荐在大部分时候用
watch显式的指定依赖以避免不必要的重复触发,也避免在后续代码修改或重构时不小心引入新的依赖。watchEffect适用于一些逻辑相对简单,依赖源和逻辑强相关的场景(或者懒惰的场景 )$nextTick 原理?
vue有个机制,更新 DOM 是异步执行的,当数据变化会产生一个异步更行队列,要等异步队列结束后才会统一进行更新视图,所以改了数据之后立即去拿 dom 还没有更新就会拿不到最新数据。所以提供了一个 nextTick 函数,它的回调函数会在DOM 更新后立即执行。
nextTick 本质上是个异步任务,由于事件循环机制,异步任务的回调总是在同步任务执行完成后才得到执行。所以源码实现就是根据环境创建异步函数比如 Promise.then(浏览器不支持promise就会用MutationObserver,浏览器不支持MutationObserver就会用setTimeout),然后调用异步函数执行回调队列。
所以项目中不使用$nextTick的话也可以直接使用Promise.then或者SetTimeout实现相同的效果
Vue 异常处理
1、全局错误处理:
Vue.config.errorHandlerVue.config.errorHandler = function(err, vm, info) {};如果在组件渲染时出现运行错误,错误将会被传递至全局
Vue.config.errorHandler配置函数 (如果已设置)。比如前端监控领域的 sentry,就是利用这个钩子函数进行的 vue 相关异常捕捉处理
2、全局警告处理:
Vue.config.warnHandlerVue.config.warnHandler = function(msg, vm, trace) {};注意:仅在开发环境生效
像在模板中引用一个没有定义的变量,它就会有warning
3、单个vue 实例错误处理:
renderErrorconst app = new Vue({ el: "#app", renderError(h, err) { return h("pre", { style: { color: "red" } }, err.stack); } });和组件相关,只适用于开发环境,这个用处不是很大,不如直接看控制台
4、子孙组件错误处理:
errorCapturedVue.component("cat", { template: `<div><slot></slot></div>`, props: { name: { type: string } }, errorCaptured(err, vm, info) { console.log(`cat EC: ${err.toString()}\ninfo: ${info}`); return false; } });注:只能在组件内部使用,用于捕获子孙组件的错误,一般可以用于组件开发过程中的错误处理
5、终极错误捕捉:
window.onerrorwindow.onerror = function(message, source, line, column, error) {};它是一个全局的异常处理函数,可以抓取所有的 JavaScript 异常
Vuex 流程 & 原理
Vuex 利用 vue 的mixin 机制,在beforeCreate 钩子前混入了 vuexinit 方法,这个方法实现了将 store 注入 vue 实例当中,并注册了 store 的引用属性 store.xxx`去引入vuex中定义的内容。
然后 state 是利用 vue 的 data,通过
new Vue({data: {$$state: state}}将 state 转换成响应式对象,然后使用 computed 函数实时计算 getterVue.use函数里面具体做了哪些事
概念
可以通过全局方法
Vue.use()注册插件,并能阻止多次注册相同插件,它需要在new Vue之前使用。该方法第一个参数必须是
Object或Function类型的参数。如果是Object那么该Object需要定义一个install方法;如果是Function那么这个函数就被当做install方法。Vue.use()执行就是执行install方法,其他传参会作为install方法的参数执行。所以**
Vue.use()本质就是执行需要注入插件的install方法**。源码实现
export function initUse (Vue: GlobalAPI) { Vue.use = function (plugin: Function | Object) { const installedPlugins = (this._installedPlugins || (this._installedPlugins = [])) // 避免重复注册 if (installedPlugins.indexOf(plugin) > -1) { return this } // 获取传入的第一个参数 const args = toArray(arguments, 1) args.unshift(this) if (typeof plugin.install === 'function') { // 如果传入对象中的install属性是个函数则直接执行 plugin.install.apply(plugin, args) } else if (typeof plugin === 'function') { // 如果传入的是函数,则直接(作为install方法)执行 plugin.apply(null, args) } // 将已经注册的插件推入全局installedPlugins中 installedPlugins.push(plugin) return this } }使用方式
installedPlugins import Vue from 'vue' import Element from 'element-ui' Vue.use(Element)
怎么编写一个vue插件
要暴露一个
install方法,第一个参数是Vue构造器,第二个参数是一个可选的配置项对象Myplugin.install = function(Vue, options = {}) { // 1、添加全局方法或属性 Vue.myGlobalMethod = function() {} // 2、添加全局服务 Vue.directive('my-directive', { bind(el, binding, vnode, pldVnode) {} }) // 3、注入组件选项 Vue.mixin({ created: function() {} }) // 4、添加实例方法 Vue.prototype.$myMethod = function(methodOptions) {} }CSS篇
Css直接面试问答的题目相对来说比较少,更多的是需要你能够当场手敲代码实现功能,一般来说备一些常见的布局,熟练掌握flex基本就没有什么问题了。
什么是 BFC
Block Formatting context,块级格式上下文
BFC 是一个独立的渲染区域,相当于一个容器,在这个容器中的样式布局不会受到外界的影响。
比如浮动元素、绝对定位、overflow 除 visble 以外的值、display 为 inline/tabel-cells/flex 都能构建 BFC。
常常用于解决
伪类和伪元素及使用场景
伪类
伪类即:当元素处于特定状态时才会运用的特殊类
开头为冒号的选择器,用于选择处于特定状态的元素。比如
:first-child选择第一个子元素;:hover悬浮在元素上会显示;:focus用键盘选定元素时激活;:link+:visted点击过的链接的样式;:not用于匹配不符合参数选择器的元素;:fist-child匹配元素的第一个子元素;:disabled匹配禁用的表单元素伪元素
伪元素用于创建一些不在文档树中的元素,并为其添加样式。比如说,我们可以通过
::before来在一个元素前增加一些文本,并为这些文本添加样式。虽然用户可以看到这些文本,但是这些文本实际上不在文档树中。示例:::before在被选元素前插入内容。需要使用 content 属性来指定要插入的内容。被插入的内容实际上不在文档树中h1:before { content: "Hello "; }::first-line匹配元素中第一行的文本src 和 href 区别
不定宽高元素的水平垂直居中
浏览器和网络篇
浏览器和网络是八股中最典型的案例了,无论你是几年经验,只要是前端,总会有问到你的浏览器和网络协议。
最好的学习文章是李兵老师的《浏览器工作原理与实践》
跨页面通信的方法?
这里分了同源页面和不同源页面的通信。
不同源页面可以通过 iframe 作为一个桥梁,因为 iframe 可以指定 origin 来忽略同源限制,所以可以在每个页面都嵌入同一个 iframe 然后监听 iframe 中传递的 message 就可以了。
同源页面的通信大致分为了三类:广播模式、共享存储模式和口口相传模式
第一种广播模式,就是可以通过 BroadCast Channel、Service Worker 或者 localStorage 作为广播,然后去监听广播事件中消息的变化,达到页面通信的效果。
第二种是共享存储模式,我们可以通过Shared Worker 或者 IndexedDB,创建全局共享的数据存储。然后再通过轮询去定时获取这些被存储的数据是否有变更,达到一个的通信效果。像常见cookie 也可以作为实现共享存储达到页面通信的一种方式
最后一种是口口相传模式,这个主要是在使用 window.open 的时候,会返回被打开页面的 window 的引用,而在被打开的页面可以通过 window.opener 获取打开它的页面的 window 点引用,这样,多个页面之间的 window 是能够相互获取到的,传递消息的话通过 postMessage 去传递再做一个事件监听就可以了
详细说说 HTTP 缓存
在浏览器第一次发起请求服务的过程中,会根据响应报文中的缓存标识决定是否缓存结果,是否将缓存标识和请求结果存入到浏览器缓存中。
HTTP 缓存分为强制缓存和协商缓存两类。
强制缓存就是请求的时候浏览器向缓存查找这次请求的结果,这里分了三种情况,没查找到直接发起请求(和第一次请求一致);查找到了并且缓存结果还没有失效就直接使用缓存结果;查找到但是缓存结果失效了就会使用协商缓存。
强制缓存有 Expires 和 Cache-control 两个缓存标识,Expires 是http/1.0 的字段,是用来指定过期的具体的一个时间(如 Fri, 02 Sep 2022 08:03:35 GMT),当服务器时间和浏览器时间不一致的话,就会出现问题。所以在 http1.1 添加了 cache-control 这个字段,它的值规定了缓存的范围(public/private/no-cache/no-store),也可以规定缓存在xxx时间内失效(max-age=xxx)是个相对值,就能避免了 expires带来的问题。
La négociation du cache est le processus qui consiste à forcer le résultat mis en cache à devenir invalide. Le navigateur transporte l'identifiant du cache pour lancer une requête au serveur, et le serveur décide s'il doit utiliser le cache via l'identifiant du cache.
Les champs qui contrôlent le cache de négociation sont last-modified / if-modified-since et Etag / if-none-match, ce dernier a une priorité plus élevée.
Le processus général consiste à transmettre la valeur de dernière modification ou Etag au serveur via le message de requête et à la comparer avec la valeur correspondante sur le serveur si le résultat est cohérent avec le if-modified-depuis ou if-none-. faites correspondre le message de réponse, puis négociez Le cache est valide, utilisez le résultat mis en cache et renvoyez 304 sinon il n'est pas valide, demandez à nouveau le résultat et renvoyez 200
L'ensemble du processus de saisie de l'URL à l'affichage de la page
Une fois que l'utilisateur a saisi un élément de contenu, le navigateur déterminera d'abord si le contenu est une recherche. Le contenu est toujours une URL. S'il s'agit d'un contenu de recherche, il sera combiné avec le moteur de recherche par défaut pour générer l'URL. Par exemple, le navigateur Google est goole.com/search?xxxx. S'il s'agit d'une URL, le protocole sera combiné, tel que http/https. Lorsque la page n'écoute pas l'heure précédant le téléchargement ou accepte de poursuivre le processus d'exécution, la barre d'icônes du navigateur entre en état de chargement.
Ensuite, le processus du navigateur enverra la demande d'URL au processus réseau via la communication inter-processus IPC. Le processus réseau recherchera d'abord la ressource dans le cache, s'il y en a une, il interceptera la demande et en renverra 200 directement. Sinon, il entrera dans le processus de demande de réseau.
Le processus de requête réseau consiste dans le fait que le processus réseau demande au serveur DNS de renvoyer l'IP et le numéro de port correspondant au nom de domaine (si ceux-ci ont déjà été mis en cache, le résultat mis en cache sera renvoyé directement s'il n'y a pas de numéro de port). , http par défaut est 80, https par défaut est 443, s'il s'agit de https Il est également nécessaire d'établir une connexion sécurisée TLS pour créer un canal de données crypté.
Ensuite, la poignée de main TCP à trois voies établit une connexion entre le navigateur et le serveur, puis effectue la transmission des données. Après avoir terminé la transmission des données, agitez la main quatre fois pour vous déconnecter
connection: keep-alive, vous pouvez toujours maintenir le contact. connexion.Le processus réseau analysera les paquets de données obtenus via TCP. Tout d'abord, le type de données est déterminé en fonction du type de contenu de l'en-tête de réponse, s'il s'agit d'un flux d'octets ou d'un type de fichier, il sera transmis au téléchargement. gestionnaire de téléchargement Naviguez à ce moment-là Le processus est terminé. S'il est de type texte/html, le processus du navigateur sera averti pour obtenir le document pour le rendu.
Le processus du navigateur reçoit la notification de rendu et jugera s'il s'agit du même site en fonction de la page actuelle et de la nouvelle page saisie. Si tel est le cas, le processus de rendu créé par la page Web précédente sera réutilisé. un processus sera créé.
Le processus du navigateur envoie le message « Soumettre le document » au processus de rendu. Lorsque le processus de rendu reçoit le message, il établira un canal de transmission de données avec le processus réseau. Une fois la transmission des données terminée, il renvoie le message « Confirmer la soumission ». "message au processus du navigateur.
Une fois que le navigateur a reçu le message « Confirmer la soumission » du processus de rendu, il mettra à jour l'état de la page du navigateur : état de sécurité, URL de la barre d'adresse, messages d'historique avant et arrière, et mettra à jour la page Web à ce moment-là. est une page blanche (écran blanc).
Processus de rendu de page (mémoire clé)
Enfin, le processus de rendu effectue l'analyse des pages et le chargement des sous-ressources du document. Le processus de rendu convertit le HTML en une arborescence DOM et convertit le CSS en styleSeets (CSSOM). Copiez ensuite l'arborescence DOM et filtrez les éléments non affichés pour créer un arbre de rendu de base. Calculez ensuite le style de chaque nœud DOM et calculez les informations de disposition de position de chaque nœud pour créer une arborescence de disposition.
Lorsqu'il existe un contexte de superposition ou lorsqu'un recadrage est requis, les calques seront créés indépendamment. Il s'agit d'une superposition, qui formera finalement une arborescence en couches. Le processus de rendu générera une liste de dessins pour chaque couche et la soumettra au fil de composition. . Le fil de composition Le calque est divisé en tuiles (pour éviter de dessiner tout le contenu du calque à la fois, et la partie de la fenêtre peut être rendue en fonction de la priorité des tuiles), et les tuiles sont converties en bitmaps dans le pool de threads de rastérisation. .
Une fois la conversion terminée, le fil de synthèse envoie la commande de bloc de dessin DrawQuard au processus du navigateur. Le navigateur génère une page basée sur le message DrawQuard et l'affiche sur le navigateur.
Shorthand :
Le processus de rendu du navigateur analyse le HTML dans une arborescence dom et le CSS dans une arborescence cssom. Ensuite, il copiera d'abord une arborescence DOM pour filtrer les éléments qui ne sont pas affichés (tels que display : aucun), et puis combinez-les avec cssom combine et calcule les informations de mise en page de chaque nœud DOM pour créer une arborescence de mise en page.
Une fois l'arborescence de mise en page générée, elle sera superposée en fonction du contexte d'empilement du calque ou d'une partie recadrée pour former un arbre en couches.
Le processus de rendu génère ensuite une liste de dessins pour chaque calque et la soumet au fil de composition. Afin d'éviter un rendu unique, le fil de composition effectue le rendu en blocs. Il divise le calque en tuiles et convertit les tuiles via la rastérisation. pool de threads.
Une fois la conversion terminée, le fil de synthèse envoie la commande pour dessiner la tuile au navigateur pour l'afficher
La différence entre TCP et UDP
UDP est le User Datagram Protocol (User Dataprogram Protocol) Une fois qu'IP a transmis le paquet de données à l'ordinateur désigné via les informations d'adresse IP, UDP peut distribuer le paquet de données au bon ordinateur. via le programme de numéro de port. UDP peut vérifier si les données sont correctes, mais il ne dispose d'aucun mécanisme de retransmission et rejettera uniquement les paquets de données incorrects. En même temps, UDP ne peut pas confirmer s'il a atteint la destination après l'envoi. UDP ne peut pas garantir la fiabilité des données, mais la vitesse de transmission est très rapide. Il est généralement utilisé dans des domaines tels que les vidéos en ligne et les jeux interactifs qui ne garantissent pas strictement l'intégrité des données.
TCP est un protocole de contrôle de transmission (Transmission Control Protocol) introduit pour résoudre le problème selon lequel les données UDP sont faciles à perdre et ne peuvent pas assembler correctement les paquets de données. Il s'agit d'un protocole de communication de couche de transport fiable, orienté connexion et basé sur le flux d'octets. . TCP fournit un mécanisme de retransmission pour gérer la perte de paquets ; et TCP introduit un mécanisme de tri des paquets qui peut combiner des paquets de données dans le désordre en fichiers complets.
En plus du port de destination et du numéro de port local, l'en-tête TCP fournit également un numéro de séquence pour le tri, afin que l'extrémité réceptrice puisse réorganiser les paquets de données via le numéro de séquence.
La différence entre TCP et UDP
Le cycle de vie d'une connexion TCP passera par trois étapes : l'étape de liaison, la transmission de données et l'étape de déconnexion.
Phase de connexion
est utilisée pour établir le lien entre le client et le serveur. La prise de contact à trois est utilisée pour confirmer les capacités d'envoi et de réception de paquets de données entre le client et le serveur.
1. Le client envoie d'abord un message SYN pour confirmer que le serveur peut envoyer des données, et entre dans l'état SYN_SENT pour attendre la confirmation du serveur
2. Lorsque le serveur reçoit le message SYN, il enverra un ACK. message de confirmation au client. , en même temps, le serveur enverra également un message SYN au client pour confirmer si le client peut envoyer des données. À ce moment, le serveur entre dans l'état SYN_RCVD
3. le message ACK + SYN, il enverra un message au serveur Enverra le paquet de données et entrera dans l'état ESTABLISHED (établira une connexion); lorsque le serveur recevra le paquet ACK envoyé par le client, il entrera également dans l'état ESTABLISHED et terminera la poignée de main à trois
Phase de transfert de données
Dans cette phase, l'extrémité destinataire doit traiter chaque paquet Effectuer une opération de confirmation
Ainsi, lorsque l'expéditeur envoie un paquet de données et ne reçoit pas de message de confirmation de la part du récepteur dans le délai spécifié, cela sera considéré comme une perte de paquet, déclenchant ainsi le mécanisme de renvoi.
Un gros fichier est présent. Pendant le processus de transmission, il sera divisé en plusieurs petits paquets de données une fois que les paquets de données arrivent au destinataire. côté réception, ils seront triés en fonction du numéro de séquence dans l’en-tête TCP pour garantir l’intégrité des données.
Phase de déconnexion
Agitez quatre fois pour vous assurer que la connexion établie par les deux parties peut être déconnectée
1 Le client initie un paquet FIN au serveur et entre dans l'état FIN_WAIT_1
2. Paquet, envoyez un paquet de confirmation ACK avec son propre numéro de séquence, et le serveur entre dans l'état CLOSE_WAIT. À l'heure actuelle, le client n'a aucune donnée à envoyer au serveur, mais si le serveur a des données à envoyer au client, celui-ci doit quand même les recevoir. Après avoir reçu l'ACK, le client entre dans l'état FIN_WAIT_2
3 Une fois les données du serveur envoyées, il envoie un paquet FIN au client. À ce moment, le serveur entre dans l'état LAST_ACK
4. et envoie un paquet de confirmation ACK. A ce moment, le client entre dans l'état TIME_WAIT et attend 2 MSL avant d'entrer dans l'état CLOSED, le serveur entre dans l'état CLOSED après avoir reçu l'ACK du client ;
Pendant quatre vagues, étant donné que TCP est une communication full-duplex, après que la partie de fermeture active envoie le paquet FIN, l'extrémité réceptrice peut toujours envoyer des données et le canal de données du serveur vers le client ne peut pas être fermé immédiatement, donc le serveur -side ne peut pas être Le paquet
FINest envoyé avec le paquetACKau client. LeACKne peut être confirmé qu'en premier, puis le paquet. Le serveur n'enverra pastant qu'il n'est pas nécessaire d'envoyer le paquet FIN, donc quatre vagues doivent être quatre interactions de paquets de donnéesFIN包与对客户端的ACK包合并发送,只能先确认ACK,然后服务器待无需发送数据时再发送FIN包,所以四次挥手时必须是四次数据包的交互Content-length 了解吗?
Content-length 是 http 消息长度,用十进制数字表示的字节的数目。
如果 content-length > 实际长度,服务端/客户端读取到消息队尾时会继续等待下一个字节,会出现无响应超时的情况
如果 content-length
当不确定content-length的值应该使用Transfer-Encoding: chunked,能够将需要返回的数据分成多个数据块,直到返回长度为 0 的终止块
跨域常用方案
什么是跨域?
协议 + 域名 + 端口号均相同时则为同域,任意一个不同则为跨域
解决方案
1、 传统的jsonp:利用
<script></script>Content-length Do vous comprenez? 🎜🎜🎜Content-length est la longueur du message http, le nombre d'octets exprimé sous forme de nombre décimal. 🎜🎜Si la longueur du contenu > longueur réelle, le serveur/client continuera d'attendre l'octet suivant lors de la lecture de la fin de la file d'attente des messages, et un délai d'attente sans réponse se produira 🎜🎜Si la longueur du contenu 🎜Solutions inter-domaines courantes🎜🎜🎜🎜Qu'est-ce que le cross-domain ? 🎜🎜🎜Si le protocole + le nom de domaine + le numéro de port sont les mêmes, c'est le même domaine. Si l'un d'eux est différent, c'est multi-domaine 🎜🎜🎜Solution🎜🎜🎜1. Les balises <script> n'ont pas de restrictions inter-domaines et ne prennent en charge que l'interface get. Plus personne ne devrait l'utiliser🎜.<p>2、 一般使用 cors(跨域资源共享)来解决跨域问题,浏览器在请求头中发送origin字段指明请求发起的地址,服务端返回Access-control-allow-orign,如果一致的话就可以进行跨域访问<p>3、 Iframe 解决主域名相同,子域名不同的跨域请求<p>4、 浏览器关闭跨域限制的功能<p>5、 http-proxy-middleware 代理<p><strong>预检<p>补充:http会在跨域的时候发起一次<strong>预检请求,“需预检的请求”要求必须首先使用OPTIONS方法发起一个预检请求到服务器,以获知服务器是否允许该实际请求。“预检请求”的使用,可以避免跨域请求对服务器的用户数据产生未预期的影响。<p>withCredentials为 true不会产生预请求;content-type为application/json会产生预请求;设置了用户自定义请求头会产生预检请求;delete方法会产生预检请求;<h4 data-id="heading-52"><strong>XSS 和 CSRF</script>
xss基本概念
Xss (Cross site scripting)跨站脚本攻击,为了和 css 区别开来所以叫 xss
Xss 指黑客向 html 或 dom 中注入恶意脚本,从而在用户浏览页面的时候利用注入脚本对用户实施攻击的手段
恶意脚本可以做到:窃取 cookie 信息、监听用户行为(比如表单的输入)、修改DOM(比如伪造登录界面骗用户输入账号密码)、在页面生成浮窗广告等
恶意脚本注入方式:
前两种属于服务端漏洞,最后一种属于前端漏洞
防止xss攻击的策略
1、服务器对输入脚本进行过滤或者转码,比如将
code:<script>alert('你被xss攻击了')</script>转换成code:3f1c4e4b6b16bbbd69b2ee476dc4f83aalert('你被xss攻击了')2cacc6d41bbb37262a98f745aa00fbf02、充分利用内容安全策略 CSP(content-security-policy),可以通过 http 头信息的 content-security-policy 字段控制可以加载和执行的外部资源;或者通过html的meta 标签
<meta http-equiv="Content-Security-Policy" content="script-src 'self'; object-src 'none'; style-src cdn.example.org third-party.org; child-src https:">3、cookie设置为 http-only, cookie 就无法通过
document.cookie来读取csrf基本概念
Csrf(cross site request forgery)跨站请求伪造,指黑客引导用户访问黑客的网站。
CSRF 是指黑客引诱用户打开黑客的网站,在黑客的网站中,利用用户的登录状态发起的跨站请求。简单来讲,CSRF 攻击就是黑客利用了用户的登录状态,并通过第三方的站点来做一些坏事。
Csrf 攻击场景
防止csrf方法
1、设置 cookie 时带上SameSite: strict/Lax选项
2、验证请求的来源站点,通过 origin 和 refere 判断来源站点信息
3、csrf token,浏览器发起请求服务器生成csrf token,发起请求前会验证 csrf token是否合法。第三方网站肯定是拿不到这个token。我们的 csrf token 是前后端约定好后写死的。
websocket
websocket是一种支持双向通信的协议,就是服务器可以主动向客户端发消息,客户端也可以主动向服务器发消息。
Il établit une connexion basée sur le protocole HTTP. Il a une bonne compatibilité avec le protocole http, il peut donc passer le serveur proxy HTTP, il n'y a pas de restriction de même origine.
WebSocket est un protocole événementiel, ce qui signifie qu'il peut être utilisé pour une véritable communication en temps réel. Contrairement à HTTP (où les mises à jour doivent être constamment demandées), avec les websockets, les mises à jour sont envoyées dès qu'elles sont disponibles
Les WebSockets ne seront pas automatiquement récupérés lorsque la connexion est terminée. Il s'agit d'un mécanisme qui doit être implémenté par vous-même lors du développement d'applications. , et il existe de nombreuses raisons pour lesquelles les bibliothèques open source côté client.
Les serveurs de développement comme webpack et vite utilisent websocket pour implémenter les mises à jour à chaud
Différence entre Post et Get
Optimisation des performances
L'optimisation des performances est un point auquel les moyennes et grandes entreprises accordent une grande attention. Parce qu'il est étroitement lié aux KPI des personnes front-end, il deviendra naturellement une question fréquente en entretien.
Quelles sont les méthodes d'optimisation des performances
Les indicateurs ci-dessus peuvent être obtenus via
- PerformanceObserver
如何减少回流、重绘,充分利用 GPU 加速渲染?
首先应该避免直接使用 DOM API 操作 DOM,像 vue react 虚拟 DOM 让对 DOM 的多次操作合并成了一次。
Css 中的
transform、opacity、filter、will-change能触发硬件加速大图片优化的方案
代码优化
感兴趣的可以看看我之前的一篇性能优化技巧整理的文章极意 · 代码性能优化之道
Ingénierie front-end
L'ingénierie front-end est le point de compétence le plus essentiel dans la croissance de l'ER front-end Toutes les fonctions qui peuvent améliorer l'efficacité du développement front-end peuvent être considérées comme faisant partie du front-end. fin de l'ingénierie. Ceux qui débutent peuvent commencer par construire un échafaudage à partir de zéroUn long article de 10 000 mots explique en détail l'ensemble du processus de création d'un framework vue3 + vite2+ ts4 au niveau de l'entreprise à partir de zéro
Pour les entretiens, la chose la plus importante à examiner est la maîtrise des outils de packaging.
Processus d'exécution et cycle de vie de webpack
webpack est un ensemble qui fournit des fonctions d'empaquetage de ressources statiques pour les applications JS modernes.
Le processus principal comporte trois étapes : l'étape d'initialisation, l'étape de construction et l'étape de génération
1. Lors de l'étape d'initialisation, les paramètres d'initialisation seront lus à partir du fichier de configuration, de l'objet de configuration et des paramètres Shell et combinés avec la configuration par défaut pour former les paramètres finaux. En plus de créer l'objet compilateur du compilateur et d'initialiser son environnement d'exécution
2. Dans la phase de construction, le compilateur exécutera sa méthode run() pour démarrer le processus de compilation. Il confirmera d'abord le fichier d'entrée, et commencez à rechercher et à saisir des fichiers à partir du fichier d'entrée. Créez des objets dépendants pour tous les fichiers qui leur sont directement ou brièvement associés, puis créez des objets de module basés sur les objets dépendants. À ce stade, le chargeur sera utilisé pour convertir le module en. contenu js standard, puis l'interpréteur js sera appelé pour convertir le contenu en un objet AST, puis à partir de l'AST Recherchez les modules dont dépend le module et récurez cette étape jusqu'à ce que tous les fichiers de dépendances d'entrée aient été traités par cette étape . Enfin, la compilation des modules est terminée et le contenu traduit de chaque module et le graphe de dépendances entre eux sont obtenus. Ce graphe de dépendances est la relation de mappage de tous les modules utilisés dans le projet.
3. Dans la phase de génération, combinez les modules compilés en morceaux, puis convertissez chaque morceau en un fichier séparé et affichez-le dans la liste de fichiers. Après avoir déterminé le contenu de sortie, déterminez le chemin de sortie et le nom du fichier en fonction de la configuration. , puis ajoutez le fichier. Le contenu est écrit dans le système de fichiers
le plugin et le chargeur de webpack
loader
webpack ne peut comprendre que les fichiers JS et JSON. Le chargeur est essentiellement un convertisseur qui peut convertir d'autres types de fichiers. en éléments reconnus par webpack.
Loader convertira le module créé par l'objet dépendant en contenu js standard pendant la phase de construction du webpack. Par exemple, vue-loader convertit les fichiers vue en modules js et les polices d'image sont converties en URL de données via url-loader. Ce sont des éléments que webpack peut reconnaître.
Vous pouvez configurer différents chargeurs dans module.rules pour analyser différents fichiers
plugin
Le plug-in est essentiellement une classe avec une fonction d'application
class myPlugin { apply(compiler) {} }Cette fonction d'application a un compilateur de paramètres, qui est le compilateur généré lors. Lors de la phase d'initialisation de l'objet webpack, vous pouvez appeler des hooks dans l'objet compilateur pour enregistrer les rappels de divers hooks. Ces hooks s'exécutent tout au long du cycle de vie de la compilation. Par conséquent, les développeurs peuvent y insérer du code spécifique via des rappels de hook pour réaliser des fonctions spécifiques.Par exemple, le plugin stylelint peut spécifier le type de fichier et la plage de fichiers que stylelint doit vérifier ; HtmlWebpackPlugin est utilisé pour générer des fichiers modèles packagés ; MiniCssExtactPlugin extraira tous les CSS en morceaux indépendants, et stylelintplugin peut fournir une fonction de vérification de style pendant la phase de développement. .
Stratégie de hachage de Webpack
MiniCssExtractPlugin Pour les navigateurs, d'une part, ils s'attendent à obtenir les dernières ressources à chaque fois qu'ils demandent des ressources de page, d'autre part, ils s'attendent à pouvoir réutiliser les objets mis en cache lorsque les ressources sont disponibles ; pas changé. À ce stade, en utilisant la méthode nom de fichier + valeur de hachage du fichier, vous pouvez distinguer si la ressource a été mise à jour en utilisant simplement le nom du fichier. Webpack dispose d'une méthode de calcul de hachage intégrée pour les fichiers générés, vous pouvez ajouter un champ de hachage au fichier de sortie.
Webpack a trois hachages intégrés
Extension : hachage du chargeur de fichiers Certains étudiants peuvent se poser les questions suivantes.
On constate souvent que lors du traitement de certaines images et du packaging du chargeur de fichiers de polices, [name]_[hash:8].[ext] est utilisé
Mais si d'autres fichiers de projet sont modifiés, tels que index.js, le Le hachage de l'image générée n'a pas changé.
Il convient de noter ici que le champ de hachage du chargeur de fichiers, l'espace réservé défini par le chargeur lui-même, n'est pas cohérent avec le champ de hachage intégré du webpack.
Le hachage ici consiste à utiliser des algorithmes de hachage tels que md4 pour hacher le contenu du fichier.
Ainsi, tant que le contenu du fichier reste inchangé, le hachage restera cohérent.
Principe de Vite
Vite est principalement composé de deux parties
Comparaison entre webpack et vite
Le principe de mise à jour à chaud de Webpack est simplement qu'une fois qu'une certaine dépendance se produit (comme
a.js)改变,就将这个依赖所处的module的更新,并将新的module发送给浏览器重新执行。每次热更新都会重新生成bundle. Imaginez s'il y avait il y a de plus en plus de dépendances, même si Si vous ne modifiez qu'un seul fichier, théoriquement la vitesse de mise à jour à chaud deviendra de plus en plus lenteVite utilise le navigateur pour analyser les importations, les compiler et les renvoyer côté serveur selon les besoins, en ignorant complètement les Concept de packaging, le serveur peut être utilisé à tout moment, à chaud. La mise à jour consiste à établir une connexion websocket entre le client et le serveur. Une fois le code modifié, le serveur envoie un message pour informer le client de demander le code du module modifié. terminez la mise à jour à chaud, quel que soit le fichier modifié, il sera demandé à nouveau. Cela garantit que la vitesse de mise à jour à chaud n'est pas affectée par la taille du projet
Le plus grand point fort de Vite actuellement est l'expérience de développement. et la mise à jour à chaud est rapide, ce qui optimise évidemment l'expérience du développeur. Étant donné que la couche inférieure de l'environnement de production est le rollup, le rollup est plus adapté aux petits projets. La base de code n'est pas aussi bonne que le webpack en termes d'extension et de fonctionnalités. peut utiliser Vite comme serveur de développement et utiliser webpack pour l'empaquetage de production
Quelles optimisations de webpack avez-vous effectuées ? 0. Mettez à niveau la version du webpack, 3 litres 4, le test réel consiste à augmenter la vitesse d'empaquetage de plusieurs dizaines de secondes .
1. splitChunksPlugin sépare le module partagé et génère des morceaux séparés, comme certaines bibliothèques dépendantes tierces, il peut être divisé séparément pour éviter que des morceaux individuels ne soient trop volumineux2. La bibliothèque équivaut à être séparée du code métier. Ce n'est que lorsque la version de la bibliothèque dépendante elle-même change qu'elle sera reconditionnée, ce qui améliorera la vitesse de packaging
3. peut utiliser oneOf pour les chargeurs
. Tant que le chargeur correspondant correspond, le chargeur ne continuera pas à être exécuté. Utilisez happyPack pour convertir l'exécution synchrone du chargeur en exécution parallèle (style-loader, css-. loader, less-loader sont combinés pour l'exécution)- 4. exclure/inclure spécifie la plage correspondante ; alias spécifie l'alias du chemin
8. terserPlugin peut fournir une compression de code, supprimer des commentaires et supprimer des espaces ;
processus d'exécution d'exécution npm
0. L'élément de configuration du script peut être défini dans le fichier package.json, qui peut définir la clé et la valeur du script en cours d'exécution
1. Lors de l'installation de npm, npm lira la configuration et exécutez-le Lien logiciel de script vers le répertoire
node_modules/.bin,node_modules/.bin目录下,同时将./bin加入当环境变量$PATH中,所以如果在全局直接运行该命令会去全局目录里找,可能会找不到该命令就会报错。比如 npm run start,他是执行的webpack-dev-server带上参数2、还有一种情况,就是单纯的执行脚本命令,比如 npm run build,实际运行的是 node build.js,即使用 node 执行 build.js 这个文件
ESM和CJS 的区别
ES6
CommonJS
设计模式篇
代理模式
代理模式:为对象提供一个代用品或占位符,以便控制对它的访问
例如实现图片懒加载的功能,先通过一张
, donc si l'exécution de cette commande directement globalement la recherchera dans le répertoire global. Si la commande est introuvable, une erreur sera signalée. Par exemple, npm run start exécute webpack-dev-server avec des paramètresloading图占位,然后通过异步的方式加载图片,等图片加载好了再把完成的图片加载到imgajoutez également./binà la variable d'environnement$PATH2 Il existe également une situation où la simple exécution d'une commande de script, telle que npm run build, exécute en fait node build.js, c'est-à-dire en utilisant node Execute the. build.js fileLa différence entre ESM et CJS
ES6CommonJS
Modèles de conception
Mode Agent
Mode Agent : Fournir un substitut ou un espace réservé pour l'objet pour en contrôler l'accès
Par exemple, pour implémenter la fonction de chargement paresseux des images, transmettez d'abord un espace réservé pour l'imageloading, puis chargez l'image de manière asynchrone, attendez que l'image est chargée, puis chargez l'image complétée dans la baliseimgMode Décorateur
La définition du mode décorateur : sans changer l'objet lui-même, lorsque le programme est en cours d'exécution. Pendant ce temps période, les méthodes sont ajoutées dynamiquement à l'objetIl est généralement utilisé pour conserver la méthode d'origine inchangée, puis monter d'autres méthodes sur la méthode d'origine pour répondre aux besoins existants. 🎜🎜Les décorateurs comme TypeScript sont un modèle de décorateur typique, et le mixin dans vue🎜🎜🎜le modèle singleton🎜🎜🎜 garantit qu'une classe n'a qu'une seule instance et fournit un point d'accès global pour y accéder. La méthode d'implémentation consiste à déterminer d'abord si l'instance existe. Si elle existe, elle sera renvoyée directement. Si elle n'existe pas, elle sera créée et renvoyée. Cela garantit qu'une classe n'a qu'un seul objet instance🎜🎜Par exemple, La sous-application d'Ice Stark ne garantit qu'un rendu à la fois. Sous-application🎜🎜🎜Mode observateur et mode publication-abonnement🎜🎜🎜1 Bien qu'il y ait des abonnés et des éditeurs dans les deux modes (des observateurs spécifiques peuvent être considérés comme des abonnés et des cibles spécifiques peuvent être considérées comme des éditeurs), mais les observateurs Le mode est programmé par des cibles spécifiques, tandis que le mode publication/abonnement est uniformément ajusté par le centre de planification. Il existe donc une dépendance entre l'abonné et l'éditeur du mode observateur. le mode publication/abonnement ne le fait pas. 🎜🎜2. Les deux modèles peuvent être utilisés pour un couplage lâche, une gestion améliorée du code et une réutilisation potentielle. 🎜🎜3. En mode observateur, l'observateur connaît le sujet et le sujet tient des registres de l'observateur. Cependant, dans le modèle de publication-abonnement, l'éditeur et l'abonné ignorent l'existence de l'autre. Ils communiquent uniquement via des courtiers de messages🎜🎜4. Le mode observateur est la plupart du temps synchrone. Par exemple, lorsqu'un événement est déclenché, le Sujet appellera la méthode observateur. Le modèle de publication-abonnement est principalement asynchrone (utilisant des files d'attente de messages) 🎜Autres
Expressions régulières
Quel type de données est une expression régulière ?
est un objet,
let re = /ab+c/est équivalent àlet re = new RegExp('ab+c')let re = /ab+c/等价于let re = new RegExp('ab+c')正则贪婪模式和非贪婪模式?
量词
*:0或多次;?:0或1次;+:1到多次;{m}:出现m次;{m,}:出现至少m次;{m, n}:出现m到n次贪婪模式
正则中,表示次数的量词默认是贪婪的,会尽可能匹配最大长度,比如
a*会从第一个匹配到a的时候向后匹配尽可能多的a,直到没有a为止。非贪婪模式
在量词后面加
?就能变成非贪婪模式,非贪婪即找出长度最小且满足条件的贪婪& 非贪婪特点
贪婪模式和非贪婪模式,都需要发生回溯才能完成相应的功能
独占模式
独占模式和贪婪模式很像,独占模式会尽可能多地去匹配,如果匹配失败就结束,不会进行回溯,这样的话就比较节省时间。
写法:量词后面使用
+优缺点:独占模式性能好,可以减少匹配的时间和 cpu 资源;但是某些情况下匹配不到,比如:
正则 文本 结果 贪婪模式 a{1,3}ab aaab 匹配 非贪婪模式 a{1,3}?ab aaab 匹配 独占模式 a{1,3}+ab aaab 不匹配 a{1,3}+ab 去匹配 aaab 字符串,a{1,3}+ 会把前面三个 a 都用掉,并且不会回溯
常见正则匹配
🎜🎜Mode gourmand🎜🎜🎜Dans les expressions régulières, le quantificateur indiquant le nombre de fois est gourmand par défaut et correspondra autant que possible à la longueur maximale. Par exemple,操作符 说明 实例 . 表示任何单个字符 [ ] 字符集,对单个字符给出范围 [abc]表示 a、b、c,[a-z]表示 a-z 的单个字符[^ ] 非字符集,对单个字符给出排除范围 [^abc]表示非a或b或c的单个字符_ 前一个字符零次或无限次扩展 abc_表示 ab、abc、abcc、abccc 等` ` 左右表达式的任意一个 `abc def`表示 abc、def $ 匹配字符串结尾 abc$表示 abc 且在一个字符串结尾( ) 分组标记内部只能使用 (abc)表示 abc,`(abcdef)`表示 abc、def D 非数字 d 数字,等价于0-9 S 可见字符 s 空白字符(空格、换行、制表符等等) W 非单词字符 w 单词字符,等价于[a-z0-9A-Z_] 匹配字符串开头 ^abc表示 abc 且在一个字符串的开头{m,n} 扩展前一个字符 m 到 n 次 ab{1,2}c表示 abc、abbc{m} 扩展前一个字符 m 次 ab{2}c表示 abbc{m,} 匹配前一个字符至少m 次 ? 前一个字符 0 次或 1 次扩展 abc?mode gourmand régulier et mode non gourmand ?
Quantifier*: 0 ou plusieurs fois ;?: 0 ou 1 fois ;{m}: apparaît m fois ;{m,}: apparaît au moins m fois ;{m, n}: apparaît m à n ; timesa*correspondra à l'envers. du premier match à a. Autant de a que possible jusqu'à ce qu'il ne reste plus de a. 🎜🎜🎜Mode non gourmand🎜🎜🎜Ajouter?après le quantificateur pour devenir mode non gourmand signifie trouver la longueur minimale et remplir les conditions 🎜🎜🎜Gourmand et non gourmand. caractéristiques🎜🎜 🎜Le mode gourmand et le mode non gourmand ont tous deux besoin d'un 🎜retour en arrière🎜 pour compléter la fonction correspondante🎜🎜🎜Mode exclusif🎜🎜🎜Le mode exclusif est très similaire au mode gourmand Le mode exclusif correspondra au plus grand nombre possible, et il le fera. se termine si le match échoue, aucun retour en arrière n'est effectué, ce qui fait gagner du temps. 🎜🎜Écriture : utilisez+après le quantificateur🎜🎜Avantages et inconvénients : le mode exclusif a de bonnes performances et peut réduire le temps de correspondance et les ressources CPU, mais dans certains cas, la correspondance ne peut pas être obtenue, comme : 🎜🎜 Régulier Texte Résultat 🎜🎜Mode gourmand🎜🎜a{1,3}ab🎜🎜aaab🎜🎜match🎜🎜 🎜mode non gourmand🎜🎜a{1,3}?ab🎜🎜aaab🎜🎜 match🎜🎜 🎜Mode exclusif🎜🎜a{1,3}+ab🎜🎜aaab🎜🎜ne correspond pas🎜🎜🎜🎜🎜a{1,3}+ab pour correspondre à la chaîne aaab, a{1,3 }+ remplacera le précédent. Les trois a sont utilisés et il n'y aura pas de retour en arrière🎜🎜🎜Correspondance régulière commune🎜🎜 Opérateur Description Instance 🎜 🎜 🎜🎜.🎜🎜 représente n'importe quel personnage 🎜 🎜🎜🎜🎜🎜🎜 🎜🎜🎜🎜 🎜[ ]🎜🎜Jeu de caractères, donnant une plage pour un seul caractère🎜🎜 [abc]représente a, b, c, [a-z] représente un seul caractère de a-z🎜🎜 🎜🎜🎜🎜🎜🎜🎜[^ ]🎜🎜Jeu de non-caractères, donnant une plage d'exclusion pour un seul caractère🎜🎜 [^abc]Représente un seul caractère qui n'est ni a, ni b, ni c🎜 🎜🎜🎜🎜🎜🎜🎜🎜_🎜🎜Le caractère précédent est développé zéro ou à l'infini 🎜🎜 abc_signifie ab, abc, abc, abccc, etc. $🎜🎜correspond à la fin de la chaîne🎜🎜abc$ code> signifie abc et à la fin d'une chaîne 🎜🎜🎜🎜🎜🎜🎜🎜<tr>🎜( )🎜🎜 ne peut être utilisé qu'à l'intérieur la balise de regroupement 🎜🎜<code>(abc)signifie abc,`(abc 🎜🎜def)` signifie abc, def🎜🎜🎜🎜🎜🎜D🎜🎜non-number🎜🎜🎜🎜🎜 🎜🎜🎜🎜🎜🎜 🎜d🎜🎜numéro, équivalent à 0- 9🎜 🎜🎜🎜🎜🎜🎜🎜🎜🎜🎜 🎜S🎜🎜caractères visibles🎜🎜 🎜🎜🎜🎜🎜🎜🎜🎜 🎜 🎜s🎜🎜caractères vides (espaces, nouvelles lignes, tabulations, etc.) 🎜🎜🎜🎜🎜🎜🎜🎜🎜🎜🎜 🎜W🎜🎜Caractères non-mots 🎜🎜🎜🎜🎜 🎜🎜🎜 🎜🎜🎜 w 🎜🎜Caractères de mots, etc. Au prix de [a-z0-9A-Z_]🎜🎜🎜🎜🎜🎜🎜🎜🎜🎜🎜 🎜correspond au début de la chaîne🎜🎜 ^abcsignifie abc et se trouve au début d'une chaîne 🎜🎜🎜🎜🎜🎜🎜🎜🎜{m,n}🎜🎜Développez le caractère précédent m pour n fois🎜🎜 ab{1,2}csignifie abc, abbc🎜🎜🎜 🎜🎜🎜🎜🎜🎜{m}🎜🎜Développe le caractère précédent m fois 🎜🎜 ab{2}csignifie abbc🎜🎜🎜🎜🎜🎜🎜🎜🎜{m ,}🎜🎜correspond au caractère précédent au moins m fois 🎜🎜🎜🎜🎜🎜🎜🎜🎜🎜🎜 🎜? 🎜🎜Le caractère précédent est développé 0 fois ou 1 fois🎜🎜 abc?signifie ab, abc🎜🎜🎜🎜🎜🎜🎜🎜🎜🎜单元测试
概念:前端自动化测试领域的, 用来验证独立的代码片段能否正常工作
1、可以直接用 Node 中自带的 assert 模块做断言:如果当前程序的某种状态符合 assert 的期望此程序才能正常执行,否则直接退出应用。
function multiple(a, b) { let result = 0; for (let i = 0; i < b; ++i) result += a; return result; } const assert = require('assert'); assert.equal(multiple(1, 2), 3));2、常见单测工具:Jest,使用示例
const sum = require('./sum'); describe('sum function test', () => { it('sum(1, 2) === 3', () => { expect(sum(1, 2)).toBe(3); }); // 这里 test 和 it 没有明显区别,it 是指: it should xxx, test 是指 test xxx test('sum(1, 2) === 3', () => { expect(sum(1, 2)).toBe(3); }); })babel原理和用途
babel 用途
bebel 如何转换的?
对源码字符串 parse 生成 AST,然后对 AST 进行增删改,然后输出目标代码字符串
转换过程
好的,以上就是我对三年前端经验通过面试题做的一个总结了,祝大家早日找到心仪的工作~
- React prône la programmation fonctionnelle, les données immuables et le flux de données unidirectionnel, qui ne peuvent être transmis que via
call ou apply pour appeler. et changez la fonction vers laquelle cela pointe, c'est-à-dire changer le contexte d'exécution de la fonction
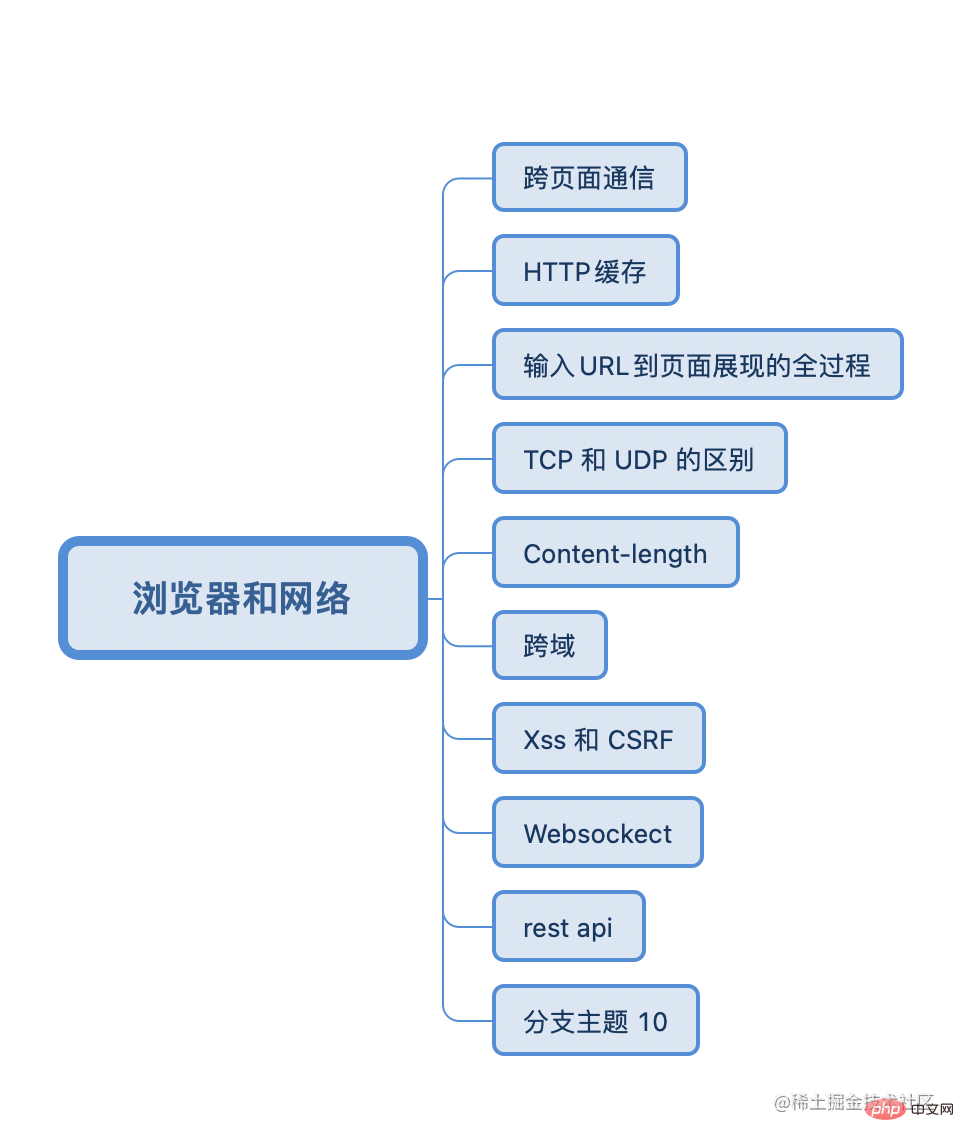
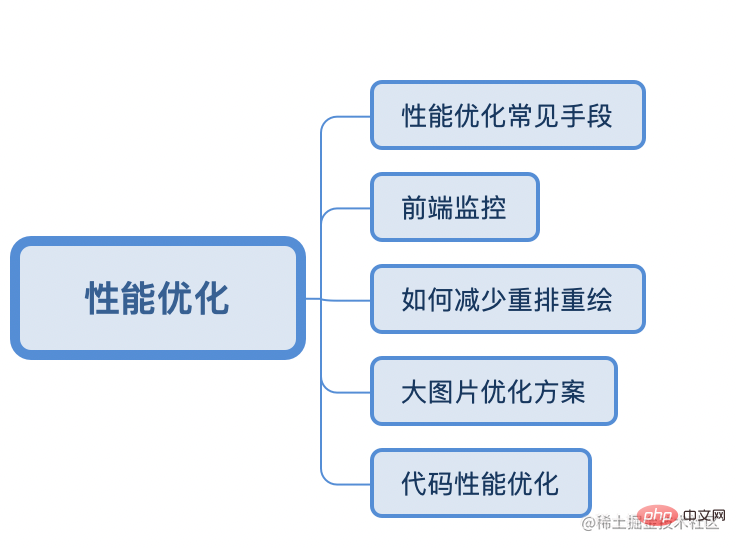
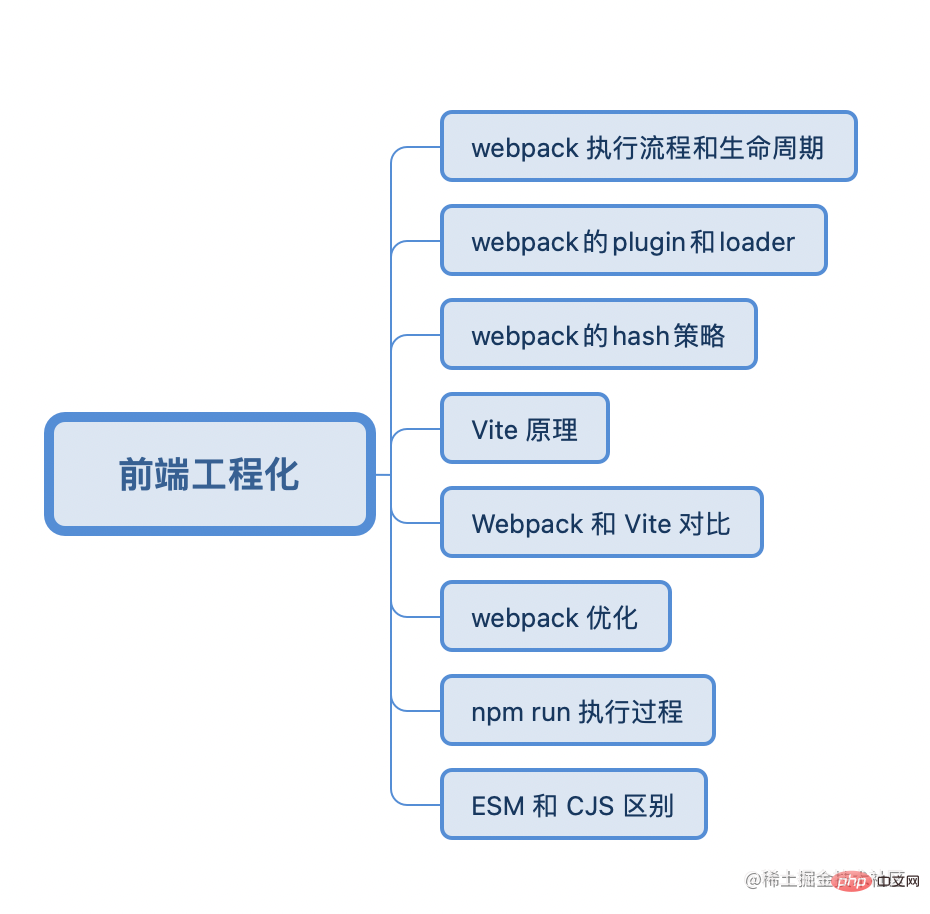
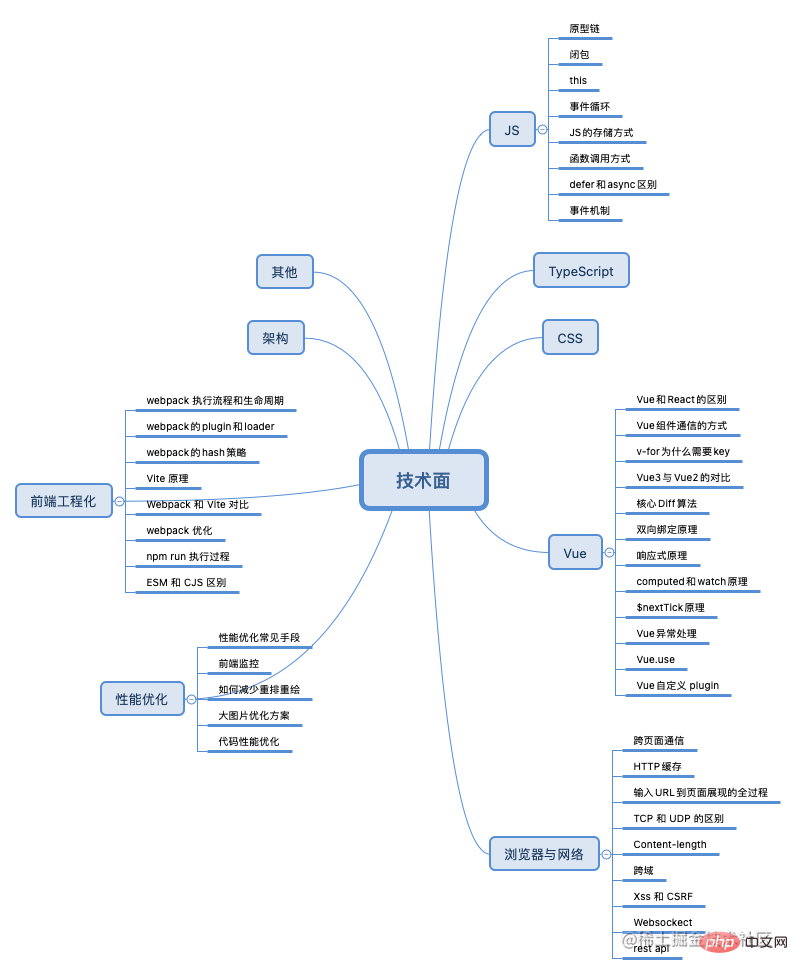
Articles Liés
Voir plus- Résumez quelques questions courantes d'entretien d'embauche (avec réponses) pour vous aider à consolider vos connaissances !
- Partage des questions d'entretien à haute fréquence Vue en 2023 (avec analyse des réponses)
- Découvrez ces 3 questions d'entretien incontournables pour tester votre maîtrise de Vue !
- [Les essentiels du Front-end] 16 outils pratiques/partage de sites web
- [Compilation et résumé] 20 questions d'entretien Vue à haute fréquence
- [Compétences avancées] Neuf questions d'entretien frontales pour vous aider à consolider vos connaissances !
- [Compilation et partage] 75 points de test haute fréquence en CSS pour les entretiens front-end