
Maison >interface Web >js tutoriel >Parlons de l'implémentation asynchrone et de la conduite d'événements dans Node
Parlons de l'implémentation asynchrone et de la conduite d'événements dans Node

- 青灯夜游avant
- 2022-11-08 20:14:441373parcourir
Cet article vous guidera à travers l'implémentation asynchrone et la conduite d'événements dans Node J'espère qu'il sera utile à tout le monde !

Caractéristiques de Node
Certaines tâches dans les ordinateurs peuvent généralement être divisées en deux catégories, l'une est appelée à forte intensité d'E/S et l'autre est appelée à forte intensité de calcul pour les tâches à forte intensité de calcul, vous ne pouvez que continuer ; extraire Cela affecte les performances du processeur, mais pour les tâches gourmandes en IO, idéalement, cela n'est pas nécessaire. Il vous suffit de notifier le périphérique IO pour le traitement, puis d'obtenir les données après un certain temps. [Recommandations de didacticiel associées : Tutoriel vidéo Nodejs, Vidéo de programmation]
Pour certains scénarios, certaines tâches non liées doivent être effectuées. Les méthodes courantes actuelles sont les suivantes :
- Achèvement parallèle multithread. : Le coût du multithreading est la surcharge plus importante liée à la création de threads et à l'exécution du changement de contexte de thread. De plus, dans les entreprises complexes, la programmation multithread est souvent confrontée à des problèmes tels que les verrous et la synchronisation des états.
- Exécution séquentielle monothread : facile à exprimer, mais l'inconvénient de l'exécution en série est la performance. Toute tâche légèrement plus lente entraînera du code ultérieur. to be Group
node a donné sa solution avant les deux : utiliser un seul thread pour éviter les blocages multi-thread, la synchronisation d'état et d'autres problèmes ; utiliser des E/S asynchrones pour empêcher un seul thread de se bloquer, afin de mieux utiliser le CPUnode在两者之前给出了它的方案:利用单线程,远离多线程死锁、状态同步等问题;利用异步IO,让单线程远离阻塞,以更好地使用CPU
Node是如何实现异步的
刚才讲了
node在多任务处理的方案,但是node内部想要实现却并不容易,下面介绍操作系统的几个概念,方面后续大家更好理解,后面再讲一讲异步的实现以及node的事件循环机制:
阻塞IO与非阻塞IO
- 阻塞IO:应用层面发起IO调用之后,就一直等待数据,等操作系统内核层面完成所有操作后,调用才结束;
操作系统中一切皆文件,输入输出设备同样被抽象为了文件,内核在执行IO操作时,通过文件描述符进行管理
- 非阻塞IO:差别为调用后立即返回一个文件描述符,并不等待,这时候CPU的时间片就可以用来处理其他事务,之后可以通过这个文件描述符进行结果的获取;
非阻塞IO存在的一些问题:虽然其让CPU的利用率提高了,但是由于立即返回的是一个文件描述符,我们并不知道IO操作什么时候完成,为了确认状态变更,我们只能作轮询操作
不同的轮询方法
-
read:最原始、性能最低的一种,通过重复检查IO状态来完成完整数据的获取 -
select:通过对文件描述符上的事件状态来进行判断,相对来说消耗更少;缺点就是它采用了一个1024长度的数组来存储状态,所以它最多可以同时检查1024个文件描述符 -
poll:由于select的限制,poll改进为链表的存储方式,其他的基本都一致;但是当文件描述符较多的时候,它的性能还是非常低下的 -
eopll:该方案是linux下效率最高的IO事件通知机制,在进入轮询的时候如果没有检查IO事件,将会进行休眠,直到事件发生将它唤醒 -
kqueue:与epoll类似,不过仅在FreeBSD系统下存在
尽管epoll利用了事件来降低对CPU的耗用,但休眠期间CPU几乎是闲置的;我们期待的异步IO应该是应用程序发起非阻塞调用,无须通过遍历或事件唤醒等方式轮询,可以直接处理下一个任务,只需IO完成后通过信号或者回调将数据传递给应用程序即可。
linux下还有中AIO方式就是通过信号或回调来传递数据的,不过只有Linux有,并且有限制无法利用系统缓存
node中对于异步IO的实现
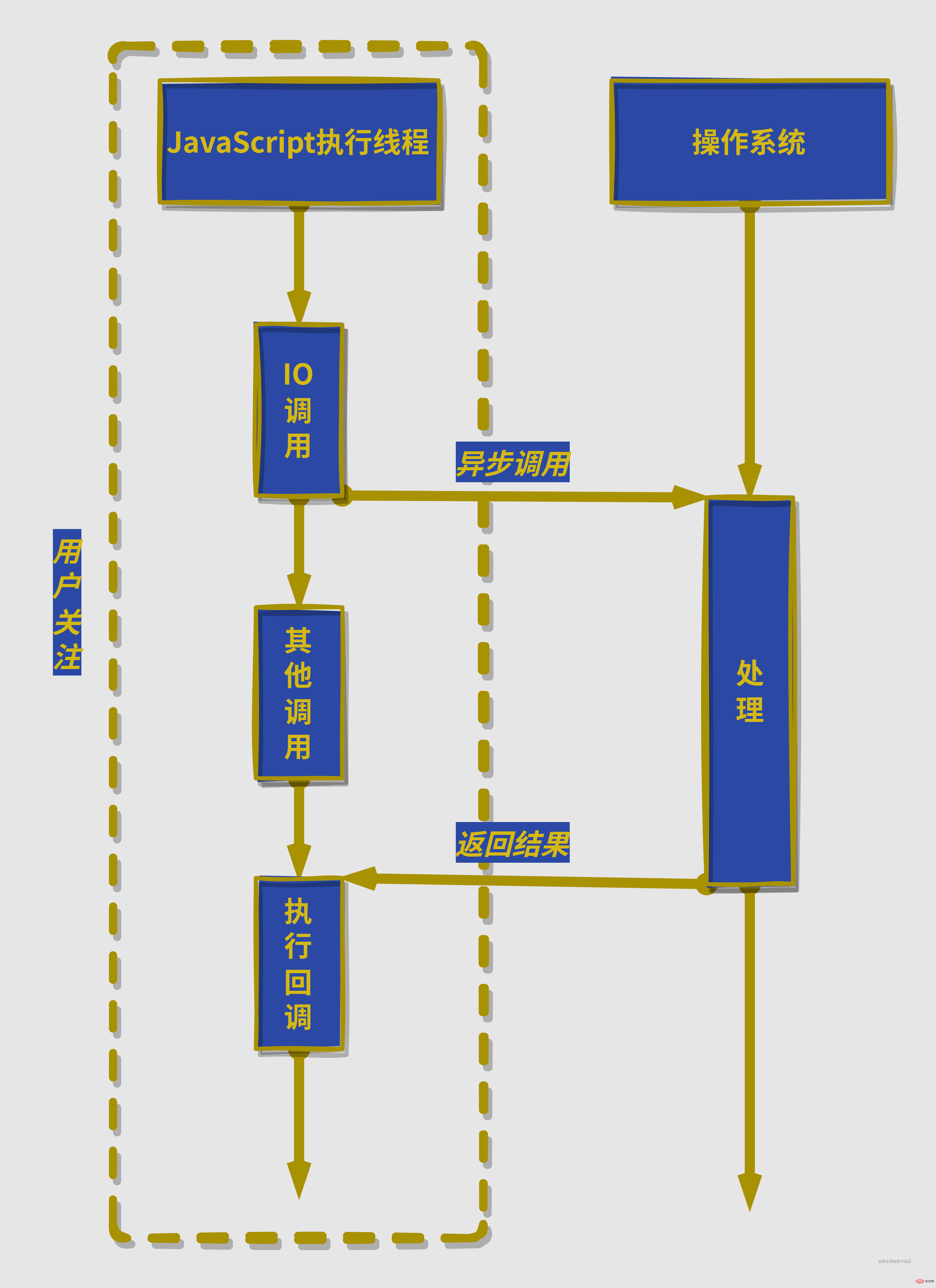
先说结论,node对异步IO的实现是通过多线程实现的。可能会混淆的地方就是node内部虽然是多线程的,但是我们程序员开发的JavaScript
🎜 🎜Comment Node implémente l'asynchronisme🎜🎜🎜🎜Je viens de parler de la solution multitâche de node, mais node Ce n'est pas facile à mettre en œuvre en interne. Voici quelques concepts du système d'exploitation afin que vous puissiez mieux les comprendre à l'avenir, nous parlerons de l'implémentation de l'implémentation asynchrone et du mécanisme de boucle d'événements de node : 🎜🎜. 🎜E/S bloquantes et IO non bloquantes🎜
🎜🎜E/S bloquantes : une fois que la couche d'application a lancé un appel IO, elle attend les données jusqu'à ce que la couche du noyau du système d'exploitation soit terminée. toutes les opérations avant la fin de l'appel ; 🎜🎜🎜 🎜Tout dans le système d'exploitation est un fichier, et les périphériques d'entrée et de sortie sont également résumés dans des fichiers. Lorsque le noyau effectue des opérations d'E/S, il est géré via des 🎜descripteurs de fichiers🎜🎜🎜🎜🎜. IO non bloquant : La différence est qu'un descripteur de fichier est renvoyé immédiatement après l'appel, sans attendre, à ce moment la tranche de temps CPU peut être utilisée pour traiter d'autres transactions, et ensuite les résultats peuvent être obtenus via ce descripteur de fichier ; 🎜🎜Quelques problèmes avec les IO non bloquantes : Bien que cela améliore l'utilisation du CPU, mais comme un descripteur de fichier est renvoyé immédiatement, nous ne savons pas quand l'opération IO est terminée. Afin de confirmer le changement d'état, nous pouvons. effectuer uniquement une opération d'interrogation 🎜🎜 Différente La méthode d'interrogation 🎜
🎜🎜read : la plus primitive et la moins performante, termine l'acquisition de données complètes en 🎜vérifiant à plusieurs reprises l'état de l'IO🎜🎜🎜select code> : le jugement est effectué en jugeant l'état de l'événement 🎜 sur le 🎜descripteur de fichier, ce qui est relativement moins cher, l'inconvénient est qu'il utilise un ; Tableau de 1024 longueurs pour stocker l'état, afin qu'il puisse vérifier jusqu'à 1024 descripteurs de fichiers en même temps 🎜🎜<code>poll : en raison des limitations de select, poll</code.> est amélioré en une méthode de stockage de liste chaînée, et les autres sont fondamentalement les mêmes ; mais lorsque le descripteur de fichier est plus grand que la plupart du temps, ses performances sont toujours très faibles🎜🎜eopll code> : Cette solution est le mécanisme de notification d'événement IO le plus efficace sous <code>linux. S'il n'y a pas de vérification de l'événement IO, il se mettra en veille jusqu'à ce que l'événement se produise pour le réveiller🎜🎜kqueue<.> : similaire à <code>epoll, mais n'existe que sous le système FreeBSD🎜🎜🎜Bien que epoll utilise des événements pour réduire la consommation du processeur, mais le processeur est presque inactif pendant la veille ; Les E/S asynchrones que nous prévoyons devraient être un appel non bloquant lancé par l'application, sans qu'il soit nécessaire d'interroger via une traversée ou un réveil d'événement, vous pouvez gérer directement la tâche suivante, il suffit de transmettre les données à l'application via un signal ou un rappel. une fois l’IO terminé. 🎜🎜🎜Il existe également une méthode AIO sous Linux qui transmet des données via des signaux ou des rappels, mais elle n'est disponible que sous Linux, et il existe des restrictions qui ne peuvent pas utiliser le cache système🎜🎜🎜Nœud pour l'implémentation des IO asynchrones 🎜
🎜Permettez-moi d'abord de parler de la conclusion. node implémente les IO asynchrones via le multi-threading. Ce qui peut prêter à confusion, c'est que même si node est multi-thread en interne, le code JavaScript développé par nos programmeurs ne s'exécute que sur un seul thread. 🎜node utilise certains threads pour effectuer des IO bloquantes ou des IO non bloquantes ainsi qu'une technologie d'interrogation pour terminer l'acquisition de données, permettant à un thread d'effectuer le traitement de calcul et de transférer les données obtenues à partir des IO via la communication entre les threads. réalise facilement la simulation des IO asynchrones. node通过部分线程进行阻塞IO或者非阻塞IO加上轮询技术来完成数据获取,让一个线程进行计算处理,通过线程之间的通信将IO得到的数据进行传递,这就轻松实现了异步IO的模拟。

除了异步IO,计算机中的其他资源也适用,因为linux中一切皆文件,磁盘、硬件、套接字等几乎所有计算机资源都被抽象为了文件,接下来介绍对计算机资源的调用都以IO为例子。
事件循环
在进程启动时,node便会创建一个类似与while(true)的循环,每执行一次循环体的过程我们成为Tick;
下方为node中事件循环流程图:
很简单的一张图,简单解释一下:就是每次都从IO观察者里面获取执行完成的事件(是个请求对象,简单理解就是包含了请求中产生的一些数据),然后没有回调函数的话就继续取出下一个事件(请求对象),有回调就执行回调函数
异步IO细节
注:不同平台有不同的细节实现,这张图隐藏了相关平台兼容细节,比如windows下使用IOCP中的PostQueuedCompletionStatus()提交执行状态,通过GetQueuedCompletionStatus获取执行完成的请求,并且IOCP内部实现了线程池的细节,而linux等平台通过eopll实现这个过程,并在libuv下自实现了线程池
setTimtout与setInterval
除了IO等计算机资源需要异步调用之外,node本身还存在一些与异步IO无关的一些其他异步API:
setTimeoutsetIntervalsetImmediateprocess.nextTick
该小节先讲解前面两个api
它们的实现原理与异步IO比较类似,只是不需要IO线程池的参与:
-
setTimtout与setInterval创建的定时器会被插入到定时器观察者内部的一个红黑树中
- 每次
tick
- En plus de l'asynchrone IO, cela s'applique également aux autres ressources de l'ordinateur, car sous Linux, tout est un fichier et presque toutes les ressources informatiques telles que les disques, le matériel et les sockets sont résumées dans des fichiers. L'introduction suivante aux appels aux ressources informatiques utilise IO comme un fichier. exemple.
Boucle d'événement
Lorsque le processus démarre, node créera un événement similaire à while (true) boucle, chaque fois que le corps de la boucle est exécuté, nous devenons Tick ; Ce qui suit est l'organigramme de la boucle d'événements dans node :
eopll code> : Cette solution est le mécanisme de notification d'événement IO le plus efficace sous <code>linux. S'il n'y a pas de vérification de l'événement IO, il se mettra en veille jusqu'à ce que l'événement se produise pour le réveiller🎜🎜kqueue<.> : similaire à <code>epoll, mais n'existe que sous le système FreeBSD🎜🎜🎜Bien que epoll utilise des événements pour réduire la consommation du processeur, mais le processeur est presque inactif pendant la veille ; Les E/S asynchrones que nous prévoyons devraient être un appel non bloquant lancé par l'application, sans qu'il soit nécessaire d'interroger via une traversée ou un réveil d'événement, vous pouvez gérer directement la tâche suivante, il suffit de transmettre les données à l'application via un signal ou un rappel. une fois l’IO terminé. 🎜🎜🎜Il existe également une méthode AIO sous Linux qui transmet des données via des signaux ou des rappels, mais elle n'est disponible que sous Linux, et il existe des restrictions qui ne peuvent pas utiliser le cache système🎜🎜🎜Nœud pour l'implémentation des IO asynchrones 🎜
🎜Permettez-moi d'abord de parler de la conclusion.node implémente les IO asynchrones via le multi-threading. Ce qui peut prêter à confusion, c'est que même si node est multi-thread en interne, le code JavaScript développé par nos programmeurs ne s'exécute que sur un seul thread. 🎜node utilise certains threads pour effectuer des IO bloquantes ou des IO non bloquantes ainsi qu'une technologie d'interrogation pour terminer l'acquisition de données, permettant à un thread d'effectuer le traitement de calcul et de transférer les données obtenues à partir des IO via la communication entre les threads. réalise facilement la simulation des IO asynchrones. node通过部分线程进行阻塞IO或者非阻塞IO加上轮询技术来完成数据获取,让一个线程进行计算处理,通过线程之间的通信将IO得到的数据进行传递,这就轻松实现了异步IO的模拟。
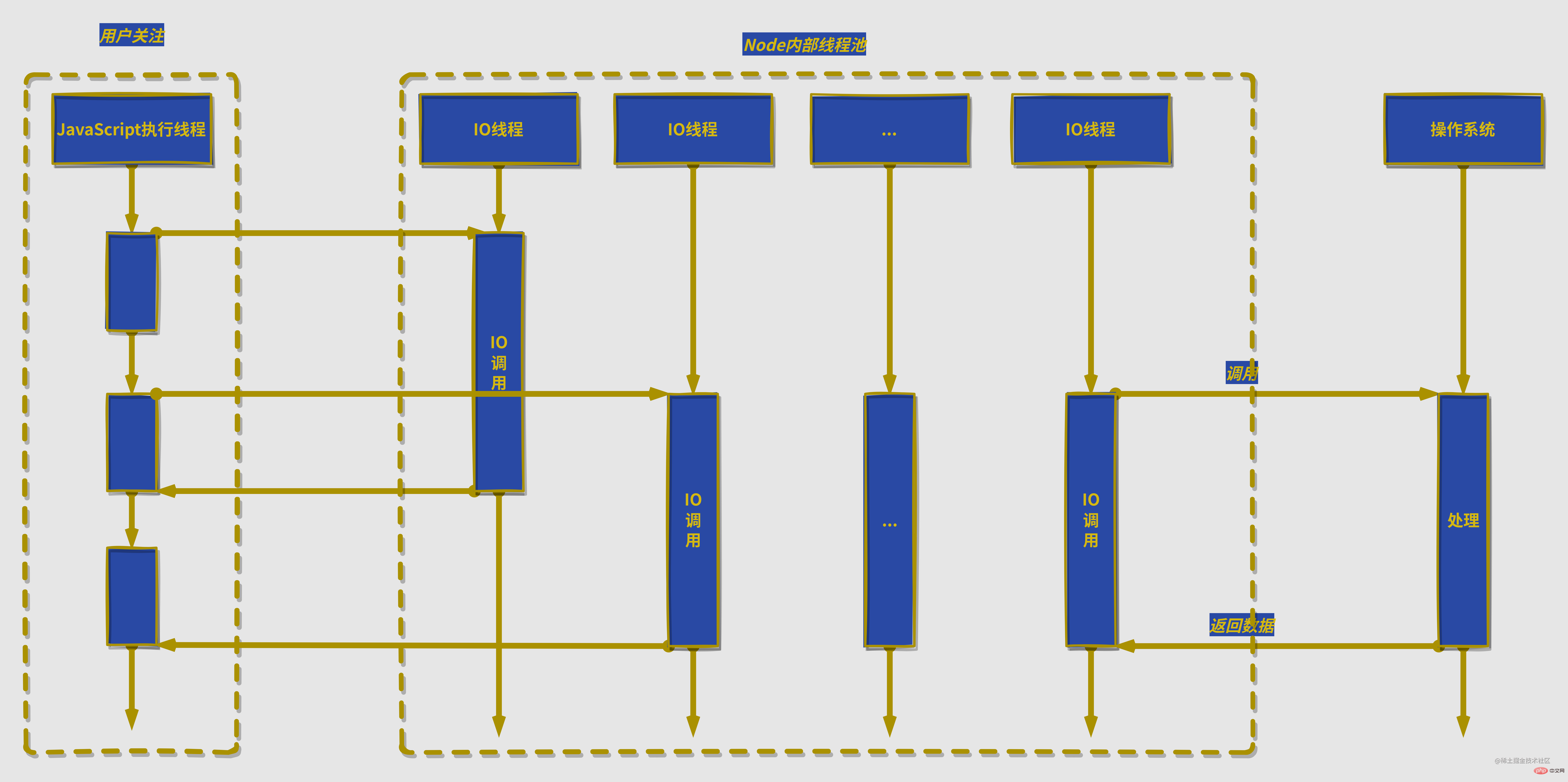
除了异步IO,计算机中的其他资源也适用,因为linux中一切皆文件,磁盘、硬件、套接字等几乎所有计算机资源都被抽象为了文件,接下来介绍对计算机资源的调用都以IO为例子。
事件循环
在进程启动时,node便会创建一个类似与while(true)的循环,每执行一次循环体的过程我们成为Tick;
下方为node中事件循环流程图:
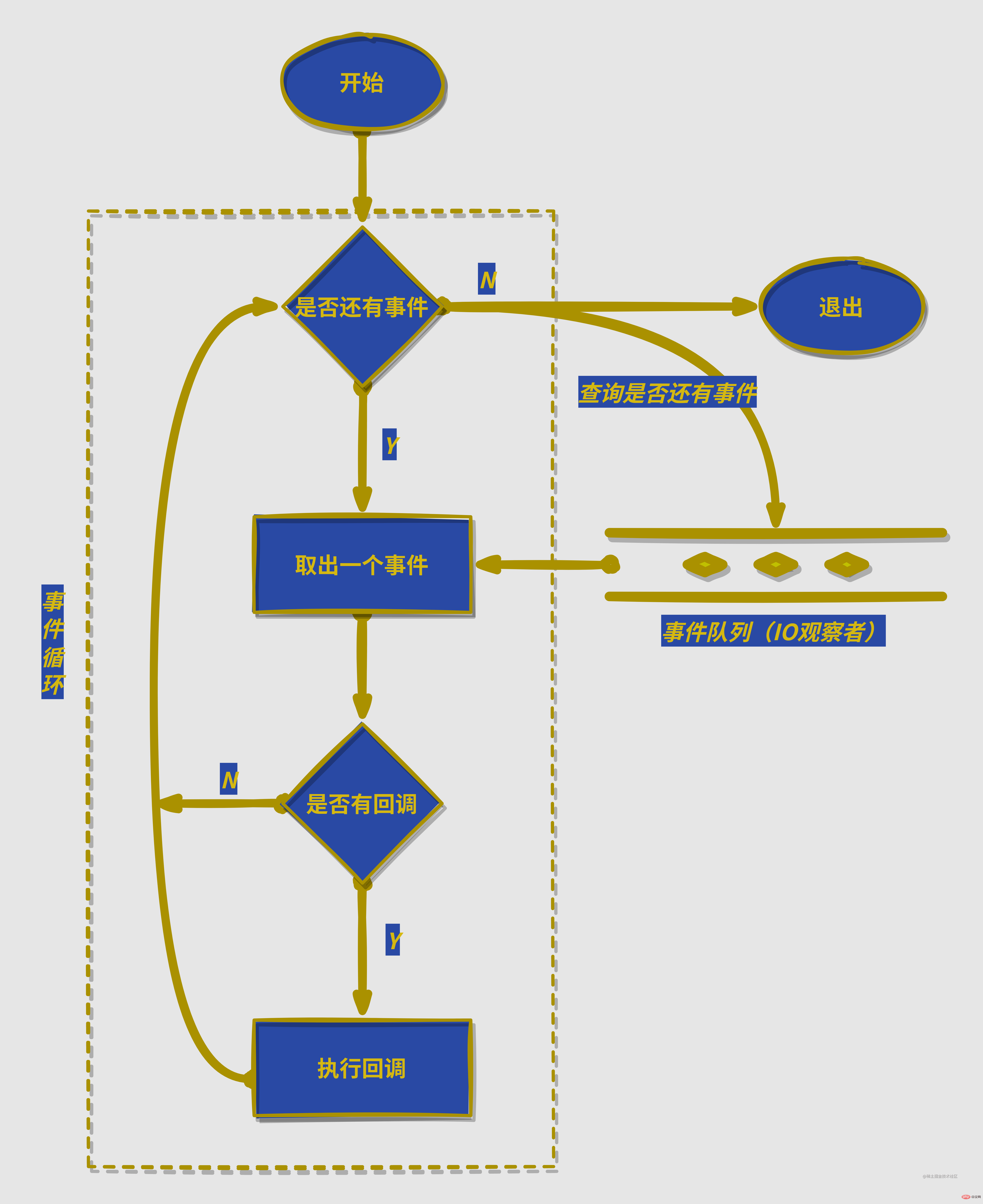
很简单的一张图,简单解释一下:就是每次都从IO观察者里面获取执行完成的事件(是个请求对象,简单理解就是包含了请求中产生的一些数据),然后没有回调函数的话就继续取出下一个事件(请求对象),有回调就执行回调函数
异步IO细节
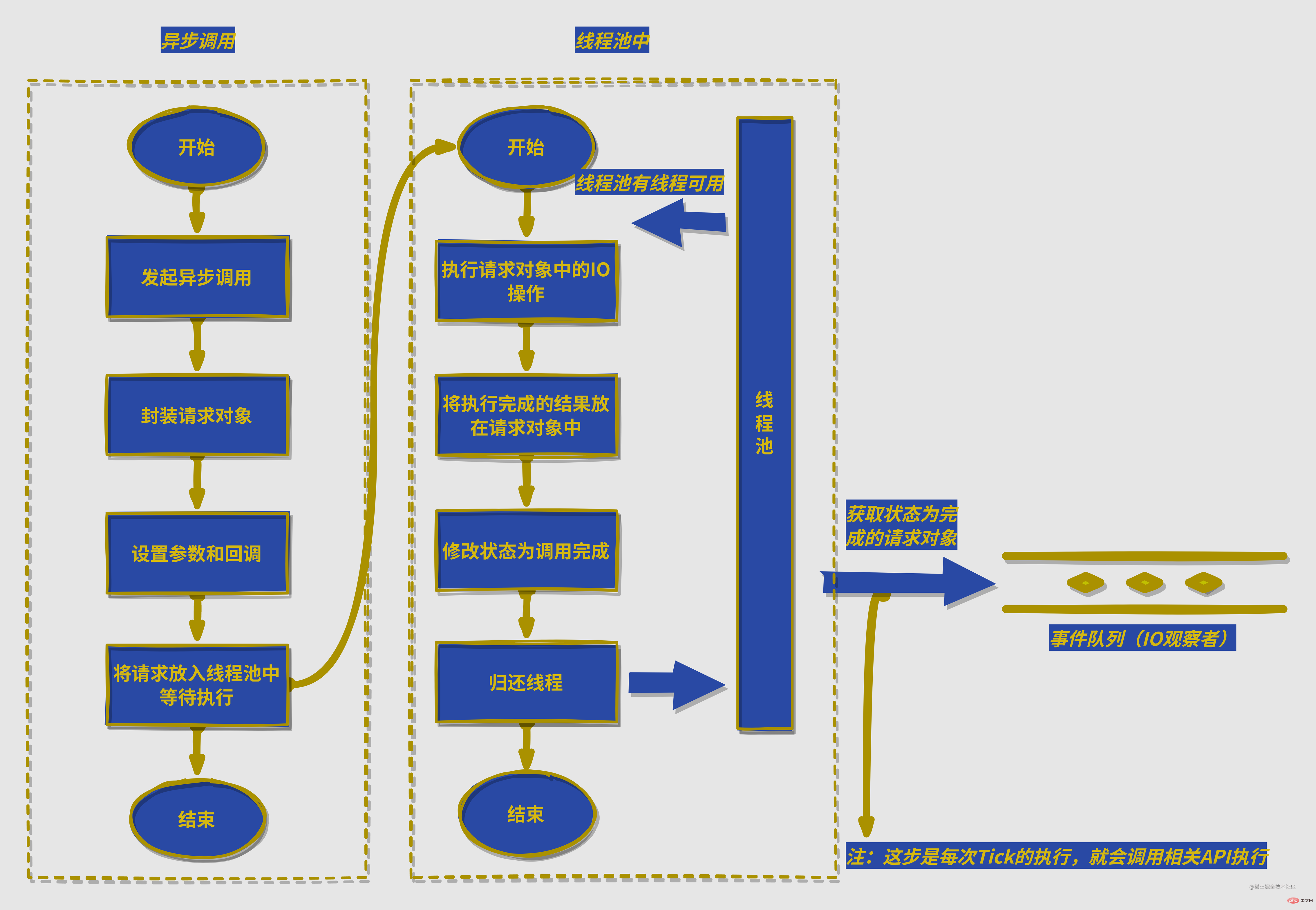
注:不同平台有不同的细节实现,这张图隐藏了相关平台兼容细节,比如windows下使用IOCP中的
PostQueuedCompletionStatus()提交执行状态,通过GetQueuedCompletionStatus获取执行完成的请求,并且IOCP内部实现了线程池的细节,而linux等平台通过eopll实现这个过程,并在libuv下自实现了线程池
setTimtout与setInterval
除了IO等计算机资源需要异步调用之外,node本身还存在一些与异步IO无关的一些其他异步API:
setTimeoutsetIntervalsetImmediateprocess.nextTick
该小节先讲解前面两个api
它们的实现原理与异步IO比较类似,只是不需要IO线程池的参与:
-
setTimtout与setInterval创建的定时器会被插入到定时器观察者内部的一个红黑树中 - 每次
tick - En plus de l'asynchrone IO, cela s'applique également aux autres ressources de l'ordinateur, car sous Linux, tout est un fichier et presque toutes les ressources informatiques telles que les disques, le matériel et les sockets sont résumées dans des fichiers. L'introduction suivante aux appels aux ressources informatiques utilise IO comme un fichier. exemple.
Boucle d'événement
Lorsque le processus démarre,nodecréera un événement similaire àwhile (true)boucle, chaque fois que le corps de la boucle est exécuté, nous devenonsTick;Ce qui suit est l'organigramme de la boucle d'événements dans
node:
node lui-même présente également des problèmes sans rapport avec les IO asynchrones. CertainesAutres API asynchrones : - 定时器精度不够
- 定时器使用红黑树来创建定时器对象和迭代操作,浪费性能
- 即
process.nextTick更加轻量 -
process.nextTick的回调执行优先级高于setImmediate -
process.nextTick的回调函数保存在一个数组中,每轮事件循环下全部执行,setImmediate的结果则是保存在链表中,每轮循环按序执行第一个回调 - 同步式
- 每进程-->每请求
- 每线程-->每请求
- Le minuteur n'est pas assez précis
- Le minuteur utilise un arbre rouge-noir pour créer des objets de minuteur et des opérations itératives, ce qui gaspille les performances
- c'est-à-dire
process.nextTickPlus léger - La priorité d'exécution du rappel de
process.nextTickest supérieure à celle desetImmediate - process.nextTick est enregistrée dans un tableau et est exécutée à chaque tour de la boucle d'événement. Le résultat de
setImmediateest enregistré dans un lien. list, et chaque tour de la boucle exécute le premier dans l'ordre. Un rappel - Synchrone
- Par processus-->Par requête
- Par thread-->Par requête
setTimeoutsetImmediate process.nextTicksetTimtout et setInterval être inséré dans un arbre rouge-noir à l'intérieur de l'observateur du minuteurlog🎜 🎜🎜🎜🎜🎜🎜🎜🎜 🎜2🎜🎜🎜🎜🎜🎜🎜🎜🎜🎜🎜🎜🎜🎜 🎜n🎜🎜)🎜🎜🎜 🎜🎜🎜🎜🎜Avez-vous déjà réfléchi à ce problème ? Pourquoi le timer n'est-il pas nécessaire ? devrait être capable de l'expliquer. Voici une brève explication des raisons pour approfondir votre mémoire : 🎜Le pool de threads IO dans node est un moyen d'appeler IO et d'attendre le retour des données (voir l'implémentation spécifique). Il permet à un seul thread de JavaScript d'appeler). IO de manière asynchrone, et il n'est pas nécessaire d'attendre que l'exécution de l'IO soit terminée (car le pool de threads IO le fait), et les données finales peuvent être obtenues (via le mode observateur : l'observateur IO obtient l'événement de fin d'exécution du pool de threads et le mécanisme de boucle d'événements exécute les rappels suivants (fonction)node中的IO线程池是用来调用IO并等待数据返回(看具体实现)的一种方式,它使JavaScript单线程得以异步调用IO,并且不需要等待IO执行完成(因为是IO线程池做了),并且能获取到最终的数据(通过观察者模式:IO观察者从线程池获取执行完成的事件,事件循环机制执行后续的回调函数)
上述这段话可能有点简略,如果你还不明白,可以看下之前的那几种图~
process.nextTick与setImmediate
这两个函数都是代表立即异步执行一个函数,那为什么不用setTimeout(() => { ... }, 0)来完成呢?
轻量具体来说:我们在每次调用process.nextTick的时候,只会将回调函数放入队列中,在下一轮Tick时取出执行。定时器中采用红黑树的方式时,nextTick为
那process.nextTick与setImmediate又有什么区别呢?毕竟它们都是将回调函数立即异步执行
注意:之所以process.nextTick的回调执行优先级高于setImmediate,因为事件循环对观察者的检查是有顺序的,process.nextTick属于idle观察者,setImmediate属于check观察者。iedl观察者 > IO 观察者 > check观察者
高性能服务器
对于网络套接字的处理,
node也应用到了异步IO,网络套接字上侦听到的请求都会形成事件交给IO观察者,事件循环会不停地处理这些网络IO事件,如果我们在JavaScrpt层面上有传入对应的回调函数,这些回调函数就会在事件循环中执行(处理这些网络请求)
常见的服务器模型:
而node采用的是事件驱动的方式处理这些请求,无需对每个请求创建额外的对应线程,可以省略掉创建线程和销毁线程的开销,同时操作系统的调度任务因为线程较少(只有node
🎜process .nextTick et setImmediate
🎜Les deux fonctions représentent l'exécution asynchrone immédiate d'une fonction, alors pourquoi pas utiliser setTimeout(() => { ... }, 0) pour le terminer ? 🎜process.nextTick, nous mettrons uniquement la fonction de rappel dans la file d'attente, comme suit : et s'exécute après un tour de Tick. Lors de l'utilisation de la méthode de l'arbre rouge-noir dans le timerO(l og2 span >n), nextTick pourO(1) 🎜🎜Quelle est la différence entre process.nextTick et setImmediate ? Après tout, ils exécutent tous immédiatement la fonction de rappel de manière asynchrone🎜process.nextTick est supérieure à cela. de setImmediate est dû au fait que la boucle d'événements vérifie l'observateur. C'est dans l'ordre, process.nextTick appartient à l'observateur idle et setImmediate appartient à l'observateur check. iedl observer> IO observer> check observer🎜🎜Serveur haute performance
🎜Pour le traitement du réseau sockets,🎜Modèles de serveurs courants : 🎜nodeest également appliqué aux IO asynchrones. Les requêtes écoutées sur le socket réseau formeront des événements et seront transmises aux observateurs IO. La boucle d'événements traitera en continu ces événements réseau. dans les fonctions de rappel correspondantes au niveauJavaSccrpt, ces fonctions de rappel seront exécutées dans la boucle d'événements (traitant ces requêtes réseau) 🎜
node). Le changement de contexte est bon marché. 🎜Problème classique--Problème d'avalancheSolution :
Description du problème : Lorsque le serveur est démarré pour la première fois, il n'y a aucune donnée dans le cache. Si le nombre de visites est énorme, le même SQL le fera. être envoyé à la base de données pour des requêtes répétées, affectant les performances. SQL会被发送到数据库中反复查询,影响性能。
解决方案:
const proxy = new events.EventEmitter();
let status = "ready"; // 状态锁,避免反复查询
const select = function(callback) {
proxy.once("selected", callback); // 绑定一个只执行一次名为selected的事件
if(status === "ready") {
status = "pending";
// sql
db.select("SQL", (res) => {
proxy.emit("selected", res); // 触发事件,返回查询数据
status = "ready";
})
}
}使用once
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Vous apprendre étape par étape comment déployer le projet node koa express dans la pagode
- Une brève analyse de la façon dont Node effectue une connexion tierce sur Weibo
- Un article expliquant la modularité dans es6 en détail
- Qu'est-ce que le RPC ? Parlons de la façon d'implémenter la communication RPC dans le nœud
- Comment utiliser Redis dans Node.js ? Il s'avère que c'est aussi simple que ça !