
Maison >base de données >tutoriel mysql >Parlons de la façon d'optimiser l'instruction order By dans SQL
Parlons de la façon d'optimiser l'instruction order By dans SQL

- 青灯夜游avant
- 2022-09-27 13:45:272514parcourir
Comment optimiser l'instruction orderBy en SQL ? L'article suivant vous présentera la méthode d'optimisation de l'instruction orderBy dans SQL. Elle a une bonne valeur de référence et j'espère qu'elle vous sera utile.

Lorsque vous utilisez une base de données pour une requête de données, vous rencontrerez inévitablement le besoin de trier l'ensemble des résultats de la requête en fonction de certains champs. En SQL, l'instruction orderby est généralement utilisée pour y parvenir. Placez les champs à trier après le mot-clé. S'il y a plusieurs champs, séparez-les par ",".
select * from table t order by t.column1,t.column2;
Le SQL ci-dessus signifie interroger les données du tableau, puis les trier par colonne 1. Si la colonne 1 est la même, elle sera triée par la colonne 2. La méthode de tri par défaut est l'ordre décroissant. Bien entendu, la méthode de tri peut également être précisée. Ajoutez DESC et ASE après le champ trié pour indiquer respectivement l'ordre décroissant et ascendant.
L'utilisation de ce orderby permet de mettre en œuvre facilement des opérations de tri quotidiennes. Je l'ai beaucoup utilisé et je me demande si vous avez déjà rencontré ce scénario : parfois après avoir utilisé orderby, l'efficacité d'exécution de SQL est très lente, et parfois elle est plus rapide. Comme je suis obsédé par le caillé toute la journée, je ne le fais pas. Je n'ai pas le temps de l'étudier. Quoi qu'il en soit, je trouve que c'est incroyable. Pendant que je suis libre ce week-end, étudions comment orderby est implémenté dans MySQL.
Pour faciliter la description, nous créons d'abord un tableau de données t1, comme suit :
CREATE TABLE `t1` ( `id` int(11) NOT NULL not null auto_increment, `a` int(11) DEFAULT NULL, `b` int(11) DEFAULT NULL, `c` int(11) DEFAULT NULL, PRIMARY KEY (`id`) , KEY `a` (`a`) USING BTREE ) ENGINE=InnoDB;
Et insérons les données :
insert into t1 (a,b,c) values (1,1,3); insert into t1 (a,b,c) values (1,4,5); insert into t1 (a,b,c) values (1,3,3); insert into t1 (a,b,c) values (1,3,4); insert into t1 (a,b,c) values (1,2,5); insert into t1 (a,b,c) values (1,3,6);
Afin de rendre l'index efficace, insérez 10 000 lignes 7, 7, 7, données non pertinentes, et lorsque la quantité de données est petite, la table entière sera analysée directement
insert into t1 (a,b,c) values (7,7,7);
Nous devons maintenant trouver tous les enregistrements avec a=1, puis les trier en fonction du champ b.
La requête SQL est
select a,b,c from t1 where a = 1 order by b limit 2;
Afin d'empêcher l'analyse complète de la table pendant le processus de requête, nous avons ajouté un index sur le champ a.
Nous vérifions d'abord le plan d'exécution de SQL via l'instruction
explain select a,b,c from t1 where a = 1 order by b lmit 2;
, comme indiqué ci-dessous :

En plus, nous pouvons voir que Using filesort apparaît, ce qui signifie que l'opération de tri est effectuée lors de l'exécution de SQL. L'opération de tri est effectuée dans sort_buffer, qui est un tampon mémoire alloué par MySQL à chaque thread. Ce tampon est spécialement utilisé pour effectuer le tri. La taille par défaut est de 1 Mo, et sa taille est contrôlée par la variable sort_buffer_size.
Lorsque mysql implémente orderby, il implémente deux méthodes d'implémentation différentes en fonction des différents contenus de champ placés dans sort_buffer : le tri de champ complet et le tri de rowid.
Tri complet des champs
Tout d'abord, examinons le processus d'exécution SQL dans son ensemble à travers une image :
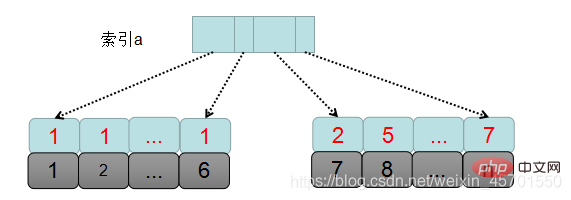
mysql détermine d'abord l'ensemble de données qui doit être trié en fonction des conditions de requête, qui est l'ensemble de données avec a=1 dans le tableau, c'est-à-dire que ces enregistrements ont des identifiants de clé primaire de 1 à 6.
L'ensemble du processus d'exécution SQL est le suivant :
1. Créez et initialisez sort_buffer, et déterminez les champs qui doivent être placés dans le tampon, c'est-à-dire les trois champs a, b et c.
2. Recherchez le premier identifiant de clé primaire qui satisfait a=1 à partir de l'arborescence d'index a, c'est-à-dire id=1.
3. Revenez à la table de l'index id, supprimez toute la ligne de données, puis retirez les valeurs de a, b, c de toute la ligne de données et placez-les dans sort_buffer.
4. Recherchez l'identifiant de clé primaire suivant de a=1 dans l'ordre à partir de l'index a.
5. Répétez les étapes 3 et 4 jusqu'à ce que le dernier enregistrement avec a=1 soit obtenu, c'est-à-dire l'identifiant de clé primaire=5.
6. À ce stade, les champs a, b et c de tous les enregistrements qui répondent à la condition a=1 sont tous lus et placés dans le sort_buffer. Ensuite, ces données sont triées en fonction de la valeur de b. la méthode est un tri rapide. C'est le tri rapide que l'on rencontre souvent dans les entretiens, et la complexité temporelle du tri rapide est log2n.
7. Retirez ensuite les 2 premières lignes de données de l'ensemble de résultats triés.
Ce qui précède est le processus d'exécution de orderby dans msql. Étant donné que les données placées dans sort_buffer correspondent à tous les champs qui doivent être générés, ce tri est appelé tri complet.
Je me demande si vous avez des questions après avoir vu cela ? Que dois-je faire si la quantité de données à trier est importante et que le sort_buffer ne peut pas y tenir ?
En effet, s'il y a beaucoup de lignes de données avec a=1 et que de nombreux champs doivent être stockés dans sort_buffer, il peut y avoir plus de trois champs a, b et c. Certaines entreprises peuvent avoir besoin de sortir. plus de champs. Ensuite, le sort_buffer avec une taille par défaut de seulement 1 Mo risque de ne pas être en mesure de l'accueillir.
Lorsque sort_buffer ne peut pas le prendre en charge, mysql créera un lot de fichiers disque temporaires pour faciliter le tri. Par défaut, 12 fichiers temporaires seront créés, et les données à trier seront divisées en 12 parties. Chaque partie sera triée séparément pour former 12 fichiers ordonnés de données internes, puis ces 12 fichiers ordonnés seront fusionnés en un fichier ordonné. . Fichiers volumineux, et enfin terminer le tri des données.
Le tri basé sur les fichiers est beaucoup moins efficace que le tri basé sur la mémoire Afin d'améliorer l'efficacité du tri, le tri basé sur les fichiers doit être évité autant que possible. Si vous souhaitez éviter le tri basé sur les fichiers, vous devez le faire. permettre à sort_buffer de s'adapter aux éléments qui doivent être triés. Volume de données.
Mysql a donc été optimisé pour les situations où sort_buffer ne peut pas le prendre en charge. Il s'agit de réduire le nombre de champs stockés dans sort_buffer lors du tri.
La méthode d'optimisation spécifique est le tri rowId suivant
RowId 排序
在全字段排序实现中,排序的过程中,要把需要输出的字段全部放到sort_buffer中,当输出的字段比较多的时候,可以放到sort_buffer中的数据行就会变少。也就增大了sort_buffer无法容纳数据的风险,直至出现基于文件的排序。
rowId排序对全字段排序的优化手段,主要是减少了放到sort_buffer中字段个数。
在rowId排序中,只会将需要排序的字段和主键Id放到sort_buffer中。
select a,b,c from t1 where a = 1 order by b limit 2;
在rowId的排序中的执行流程如下:
1.初始化并创建sort_buffer,并确认要放入的的字段,id和b。
2.从索引树a中找到第一个满足a=1的主键id,也就是id=1。
3.回表主键索引id,取出整行数据,从整行数据中取出id和b,存入sort_buffer中。
4.从索引a中取出下一条满足a=1的 记录的主键id。
5.重复步骤3和4,直到最后一个满足a=1的主键id,也就是a=6。
6.对sort_buffer中的数据,按照字段b排序。
7.从sort_buffer中的有序数据集中,取出前2个,因为此时取出的数据只有id和b,要想获取a和c字段,需要根据id字段,回表到主键索引中取出整行数据,从整行数据中获取需要的数据。
根据rowId排序的执行步骤,可以发现:相比全字段排序,rowId排序的实现方式,减少了存放到sort_buffer中的数据量,降低了基于文件的外部排序的可能性。
那rowid排序有不足的地方吗?肯定有的,要不然全字段排序就没有存在的意义了。rowid排序不足之处在于,在最后的步骤7中,增加了回表的次数,不过这个回表的次数,取决于limit后的值,如果返回的结果集比较小的话,回表的次数还是比较小的。
mysql是如何在全字段排序和rowId排序的呢?其实是根据存放的sort_buffer中每行字段的长度决定的,如果mysql认为每次放到sort_buffer中的数据量很大的话,那么就用rowId排序实现,否则使用全字段排序。那么多大算大呢?这个大小的阈值有一个变量的值来决定,这个变量就是 max_length_for_sort_data。如果每次放到sort_buffer中的数据大小大于该字段值的话,就使用rowId排序,否则使用全字段排序。
orderby的优化
上面讲述了orderby的两种排序的方式,以及一些优化策略,优化的目的主要就是避免基于磁盘文件的外部排序。因为基于磁盘文件的排序效率要远低于基于sort_buffer的内存排序。
但是当数据量比较大的时候,即使sort_buffer比较大,所有数据全部放在内存中排序,sql的整体执行效率也不高,因为排序这个操作,本身就是比较消耗性能的。
试想,如果基于索引a获取到所有a=1的数据,按照字段b,天然就是有序的,那么就不用执行排序操作,直接取出来的数据,就是符合结果的数据集,那么sql的执行效率就会大幅度增长。
其实要实现整个sql执行过程中,避免排序操作也不难,只需要创建一个a和b的联合索引即可。
alter table t1 add index a_b (a,b);
添加a和b的联合索引后,sql执行流程就变成了:
1.从索引树(a,b)中找到第一个满足a=1的主键id,也就是id=1。
2.回表到主键索引树,取出整行数据,并从中取出a,b,c,直接作为结果集的一部分返回。
3.从索引树(a,b)上取出下一个满足a=1的主键id。
4.重复步骤2和3,直到找到第二个满足a=1的主键id,并回表获取字段a,b,c。
此时我们可以通过查看sql的执行计划,来判断sql的执行过程中是否执行了排序操作。
explain select a,b from t1 where a = 1 order by b lmit 2;

通过查看执行计划,我们发现extra中已经没有了using filesort了,也就是没有执行排序操作了。
其实还可以通过覆盖索引,对该sql进一步优化,通过在索引中覆盖字段c,来避免回表的操作。
alter table t1 add index a_b_c (a,b,c);
添加索引a_b_c后,sql的执行过程如下:
1.从索引树(a,b,c)中找到第一个满足a=1的索引,从中取出a,b,c。直接作为结果集的一部分直接返回。
2.从索引(a,b,c)中取出下一个,满足a=1的记录作为结果集的一部分。
3.重复执行步骤2,直到查到第二个a=1或者不满足a=1的记录。
此时通过查看执行sql的的还行计划可以发现 extra中只有 Using index。
explain select a,b from t1 where a = 1 order by b lmit 2;

Résumé
Grâce à de multiples optimisations de ce SQL, l'efficacité d'exécution finale de SQL est fondamentalement la même que l'efficacité des requêtes du SQL ordinaire sans tri. La raison pour laquelle l’opération de tri trié par ordre peut être évitée est de tirer parti des caractéristiques naturellement ordonnées de l’index.
Mais nous savons tous que les index peuvent accélérer l'efficacité des requêtes, mais les coûts de maintenance des index sont relativement élevés. L'ajout et la modification de données dans la table de données impliqueront des modifications d'index, donc plus il y a d'index, mieux c'est. Parfois, cela ne vaut pas la peine d'en ajouter. trop d'index simplement à cause de requêtes et de tris inhabituels.
【Recommandation associée : tutoriel vidéo mysql】
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Explication détaillée de l'utilisation des blocages MySQL et des méthodes de détection et d'évitement
- SQL Server restaure le processus d'opération de sauvegarde complète et de sauvegarde différentielle
- Résumé de l'utilisation de la séquence Sequence dans MySQL
- Un article pour parler du mécanisme d'implémentation interne du verrouillage Mysql
- Interférer avec l'utilisation de la jointure par hachage par l'optimiseur MySQL