
Maison >base de données >SQL >Comprendre la fonction de fenêtrage en SQL dans un article
Comprendre la fonction de fenêtrage en SQL dans un article

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBavant
- 2022-09-02 16:55:484003parcourir
Cet article vous apporte des connaissances pertinentes sur SQL server. Il existe deux types de fonctions de fenêtrage, également appelées fonctions analytiques, l'une est la fonction de fenêtrage d'agrégation et l'autre est la fonction de fenêtrage de tri. vous les informations pertinentes sur la fonction de fenêtrage dans SQL. L'article la présente en détail à travers un exemple de code. Les amis qui en ont besoin peuvent s'y référer.

Etude recommandée : "Tutoriel SQL"
Définition de OVER
OVER est utilisé pour définir une fenêtre pour une ligne, qui opère sur un ensemble de valeurs Il n'est pas nécessaire d'utiliser la clause GROUP BY. pour regrouper les données. Possibilité de renvoyer à la fois les colonnes de la ligne de base et les colonnes agrégées dans la même ligne.
Syntaxe OVER
OVER ([colonne PARTITION BY] [colonne ORDER BY])
clause PARTITION BY pour le regroupement
clause ORDER BY pour le tri.
La fonction de fenêtre OVER() spécifie un ensemble de lignes et la fonction de fenêtrage calcule la valeur de chaque ligne dans l'ensemble de résultats de sortie de la fonction de fenêtre.
La fonction de fenêtrage peut regrouper les données sans utiliser GROUP BY, et peut également renvoyer les colonnes de la ligne de base et la colonne agrégée en même temps.
Utilisation de la fonction de fenêtrage OVER
OVER doit être utilisée avec la fonction d'agrégation ou la fonction de tri. La fonction d'agrégation fait généralement référence à des fonctions courantes telles que SUM(), MAX(), MIN, COUNT(), AVG(), etc. Les fonctions de tri font généralement référence à RANK(), ROW_NUMBER(), DENSE_RANK(), NTILE(), etc.
Exemples d'utilisation de OVER dans les fonctions d'agrégation
Nous utilisons les fonctions SUM et COUNT comme exemples pour vous le démontrer.
--建立测试表和测试数据
CREATE TABLE Employee
(
ID INT PRIMARY KEY,
Name VARCHAR(20),
GroupName VARCHAR(20),
Salary INT
)
INSERT INTO Employee
VALUES(1,'小明','开发部',8000),
(4,'小张','开发部',7600),
(5,'小白','开发部',7000),
(8,'小王','财务部',5000),
(9, null,'财务部',NULL),
(15,'小刘','财务部',6000),
(16,'小高','行政部',4500),
(18,'小王','行政部',4000),
(23,'小李','行政部',4500),
(29,'小吴','行政部',4700);La fonction de fenêtrage après SUM
SELECT *,
SUM(Salary) OVER(PARTITION BY Groupname) 每个组的总工资,
SUM(Salary) OVER(PARTITION BY groupname ORDER BY ID) 每个组的累计总工资,
SUM(Salary) OVER(ORDER BY ID) 累计工资,
SUM(Salary) OVER() 总工资
from Employee(astuce : vous pouvez faire glisser le code vers la gauche et la droite)
Les résultats sont les suivants :
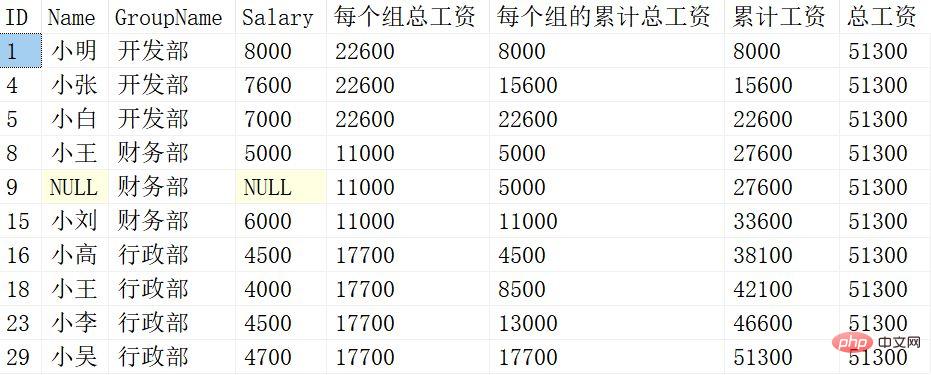
La signification de chaque fonction de fenêtrage est différente, expliquons-la en détail :
SUM (Salary) OVER (PARTITION BY Groupname)
Regroupez uniquement la colonne Groupname après PARTITION BY et résolvez la somme du salaire après le regroupement.
SUM(Salary) OVER (PARTITION BY Groupname ORDER BY ID)
Regroupez la colonne Groupname après PARTITION BY, puis triez par ID après ORDER BY, puis effectuez Salary au sein du groupe Traitement cumulatif.
SUM(Salary) OVER (ORDER BY ID)
Triez uniquement le contenu de l'ID après ORDER BY et accumulez le salaire trié.
SUM(Salary) OVER ()
La fonction de fenêtrage après résumé Salary
COUNT
SELECT *,
COUNT(*) OVER(PARTITION BY Groupname ) 每个组的个数,
COUNT(*) OVER(PARTITION BY Groupname ORDER BY ID) 每个组的累积个数,
COUNT(*) OVER(ORDER BY ID) 累积个数 ,
COUNT(*) OVER() 总个数
from EmployeeLe résultat renvoyé est le suivant :
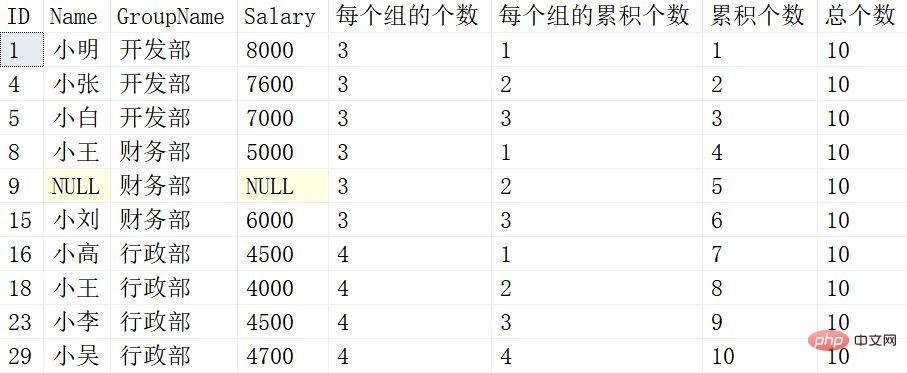
Chaque fenêtrage suivant Les fonctions ne seront plus interprétés un par un. Vous pouvez les comparer un par un avec la fonction de fenêtrage après SUM ci-dessus.
Exemples d'utilisation de OVER dans les fonctions de tri
Nous démontrons les quatre fonctions de tri une par une
--先建立测试表和测试数据 WITH t AS (SELECT 1 StuID,'一班' ClassName,70 Score UNION ALL SELECT 2,'一班',85 UNION ALL SELECT 3,'一班',85 UNION ALL SELECT 4,'二班',80 UNION ALL SELECT 5,'二班',74 UNION ALL SELECT 6,'二班',80 ) SELECT * INTO Scores FROM t; SELECT * FROM Scores
ROW_NUMBER()
Définition : La fonction de la fonction ROW_NUMBER() est de trier les données interrogées par SELECT Each Adding. un numéro de série associé à une donnée ne peut pas être utilisé pour classer les scores des étudiants. Il est généralement utilisé pour les requêtes de pagination, telles que l'interrogation des 10 meilleurs étudiants et l'interrogation de 10 à 100 étudiants. ROW_NUMBER() doit être utilisé avec ORDER BY, sinon une erreur sera signalée.
Trier les scores des élèves
SELECT *, ROW_NUMBER() OVER (PARTITION BY ClassName ORDER BY SCORE DESC) 班内排序, ROW_NUMBER() OVER (ORDER BY SCORE DESC) AS 总排序 FROM Scores;
Les résultats sont les suivants :
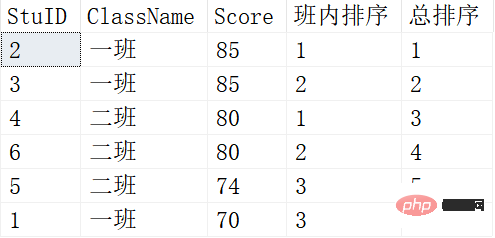
Les fonctions de PARTITION BY et ORDER BY ici sont les mêmes que les fonctions d'agrégation que nous avons vues ci-dessus, et elles sont utilisées pour le regroupement et le tri.
De plus, la fonction ROW_NUMBER() peut également prendre des données dans un ordre spécifié.
SELECT * FROM ( SELECT *, ROW_NUMBER() OVER (ORDER BY SCORE DESC) AS 总排序 FROM Scores ) t WHERE t.总排序=2;
Les résultats sont les suivants :

RANK()
Définition : La fonction RANK(), comme son nom l'indique, est une fonction de classement qui peut classer un certain champ. ROW_NUMBER() ? ROW_NUMBER() trie. Lorsqu'il y a des élèves avec les mêmes notes, ROW_NUMBER() les triera dans l'ordre. Leurs numéros de série sont différents, mais Rank() est différent. S’ils apparaissent identiques, leur classement est le même. Regardons l'exemple ci-dessous :
Exemple
SELECT ROW_NUMBER() OVER (ORDER BY SCORE DESC) AS [RANK],* FROM Scores; SELECT RANK() OVER (ORDER BY SCORE DESC) AS [RANK],* FROM Scores;
Résultat :
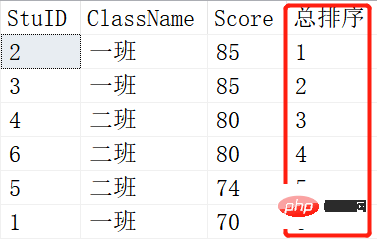
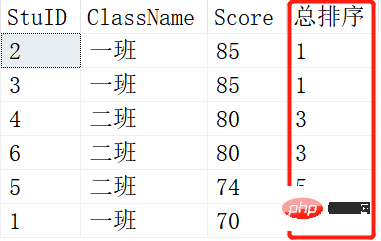
L'image du haut est le résultat de ROW_NUMBER(), et l'image du bas est le résultat de RANK(). Lorsque deux élèves ont les mêmes notes, il y a un changement. RANK() est 1-1-3-3-5-6, tandis que ROW_NUMBER() est toujours 1-2-3-4-5-6. C'est la différence entre RANK() et ROW_NUMBER().
DENSE_RANK()
定义:DENSE_RANK()函数也是排名函数,和RANK()功能相似,也是对字段进行排名,那它和RANK()到底有什么不同那?特别是对于有成绩相同的情况,DENSE_RANK()排名是连续的,RANK()是跳跃的排名,一般情况下用的排名函数就是RANK() 我们看例子:
示例
SELECT RANK() OVER (ORDER BY SCORE DESC) AS [RANK],* FROM Scores; SELECT DENSE_RANK() OVER (ORDER BY SCORE DESC) AS [RANK],* FROM Scores;
结果如下:
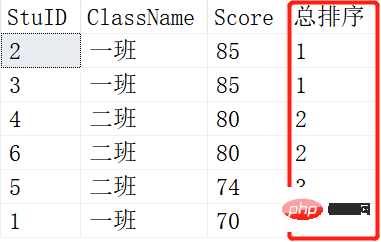
上面是RANK()的结果,下面是DENSE_RANK()的结果
NTILE()
定义:NTILE()函数是将有序分区中的行分发到指定数目的组中,各个组有编号,编号从1开始,就像我们说的'分区'一样 ,分为几个区,一个区会有多少个。
SELECT *,NTILE(1) OVER (ORDER BY SCORE DESC) AS 分区后排序 FROM Scores; SELECT *,NTILE(2) OVER (ORDER BY SCORE DESC) AS 分区后排序 FROM Scores; SELECT *,NTILE(3) OVER (ORDER BY SCORE DESC) AS 分区后排序 FROM Scores;
结果如下:
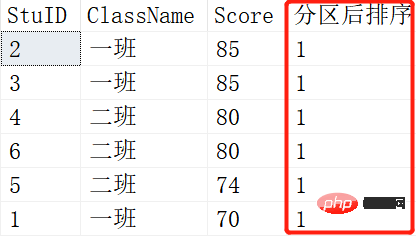
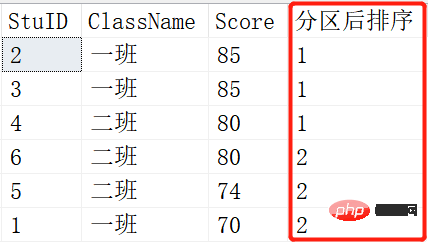
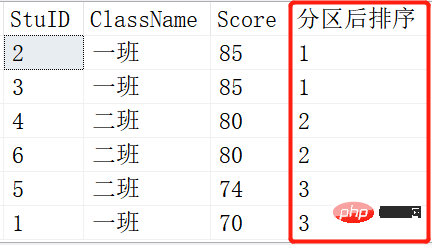
就是将查询出来的记录根据NTILE函数里的参数进行平分分区。
总结
OVER开窗函数是我们工作中经常要使用到的,特别是在做数据分析计算的时候,经常要对数据进行分组排序。上面我们额外介绍了聚合函数和排序函数的与OVER结合的使用方法,此外还有很多与OVER一起使用的函数,比如LEAD函数,LAG函数,STRING_AGG函数等等都会使用到开窗函数OVER,其使用方法也要务必掌握。
推荐学习:《SQL教程》
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- SQL Server utilise CROSS APPLY et OUTER APPLY pour implémenter les requêtes de connexion
- quelle est la différence entre les moteurs de stockage MySQL
- Exemples de méthodes permettant à SQL Server d'analyser/manipuler les données de champ au format Json
- Comment afficher le plan d'exécution dans MySQL
- Quelle est l'erreur 10061 de MySQL ?