
Maison >base de données >tutoriel mysql >Comment afficher le plan d'exécution dans MySQL
Comment afficher le plan d'exécution dans MySQL

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBavant
- 2022-08-30 13:47:426771parcourir

Apprentissage recommandé : Tutoriel vidéo mysql
Utilisez le mot-clé expliquer pour simuler l'optimiseur exécutant des instructions de requête SQL, afin de savoir comment MySQL traite vos instructions SQL et analyser vos instructions de requête ou vos structures de table.
Expliquez les informations contenues dans le plan d'exécution
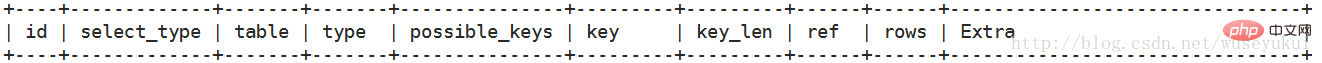
Les champs les plus importants sont : id, type, clé, lignes, Extra
Explication détaillée de chaque champ
id
Sélectionnez le numéro de séquence de la requête, comprenant un ensemble de nombres, Indique l'ordre dans lequel les clauses de sélection ou les tables d'opérations sont exécutées dans la requête
Trois situations :
1 : L'ordre d'exécution est de haut en bas

. 2. Différents identifiants : S'il s'agit d'une sous-requête, le numéro de série de l'identifiant augmentera. Plus la valeur de l'identifiant est grande, plus la priorité est élevée et plus elle sera exécutée tôt

3. le même mais différent (les deux situations existent en même temps) : Si l'identifiant est le même, il peut être considéré comme un groupe Exécuter séquentiellement de haut en bas dans tous les groupes, plus la valeur de l'identifiant est grande, plus elle est élevée ; priorité, plus elle est exécutée tôt

- 1 : Requête de sélection simple, la requête le fait. ne contient pas de sous-requêtes ni d'unions 2. PRIMAIRE
- : La requête contient des sous-parties complexes et la requête la plus externe est marquée Pour primaire 3, SOUS-REQUÊTE
- : Une sous-requête est incluse dans la liste de sélection ou où 4. , DERIVED
- : La sous-requête contenue dans la liste from est marquée comme dérivée (dérivée), et mysql ou exécute récursivement ces sous-requêtes Query et met les résultats dans la table de temps zéro 5 : Si la deuxième sélection apparaît après. l'union, elle sera marquée comme union ; si l'union est incluse dans la sous-requête de la clause from, la sélection externe sera marquée comme dérivée
- 6, UNION RESULT : Sélectionnez
type
system > const > eq_ref > ref > fulltext > ref_or_null > index_merge > unique_subquery > index_subquery > range > index > ALL
De manière générale, une bonne requête SQL doit au moins atteindre le niveau de plage, et accédez de préférence à la ref
1. system
: La table n'a qu'une seule ligne d'enregistrements (égale à la table système). Habituellement, elle n'apparaîtra pas et peut être ignorée. 2. const
: Cela signifie qu'il est trouvé via l'index une fois que const est utilisé pour comparer la clé primaire ou l'index unique. Comme vous n'avez besoin de faire correspondre qu'une seule ligne de données, c'est très rapide. Si la clé primaire est placée dans la liste Where, MySQL peut convertir la requête en const
 3 : analyse d'index unique Pour chaque clé d'index, un seul enregistrement de la table lui correspond. Couramment observé dans les analyses de clé primaire ou d’index unique.
3 : analyse d'index unique Pour chaque clé d'index, un seul enregistrement de la table lui correspond. Couramment observé dans les analyses de clé primaire ou d’index unique.
Remarque : TOUTES les analyses complètes de la table avec le moins d'enregistrements, telles que la table t1

: analyse d'index non unique, renvoie toutes les lignes correspondant à une seule valeur. Essentiellement, il s'agit également d'un accès à l'index, qui renvoie toutes les lignes correspondant à une seule valeur. Cependant, il peut trouver plusieurs lignes répondant aux critères, il doit donc s'agir d'un mélange de recherche et d'analyse
.
5. range : récupérez uniquement les lignes dans une plage donnée, en utilisant un index pour sélectionner les lignes. La colonne clé indique quel index est utilisé. Généralement, les requêtes telles que between, , in, etc. apparaissent dans l'instruction Where. Cette analyse de plage sur les colonnes d'index est meilleure qu'une analyse d'index complète. Il suffit de commencer à un certain point et de se terminer à un autre point, sans analyser l'intégralité de l'index

6 : Analyse complète de l'index. La différence entre index et ALL est que le type d'index ne traverse que l'index. arbre. Il s'agit généralement de TOUS les blocs, car les fichiers d'index sont généralement plus petits que les fichiers de données. (Bien que Index et ALL lisent tous deux la table entière, l'index est lu à partir de l'index, tandis que ALL est lu à partir du disque dur)

7 : Analyse complète de la table, parcourez la table entière pour trouver la correspondance. S'il y a un index sur le champ impliqué dans la requête sur la ligne
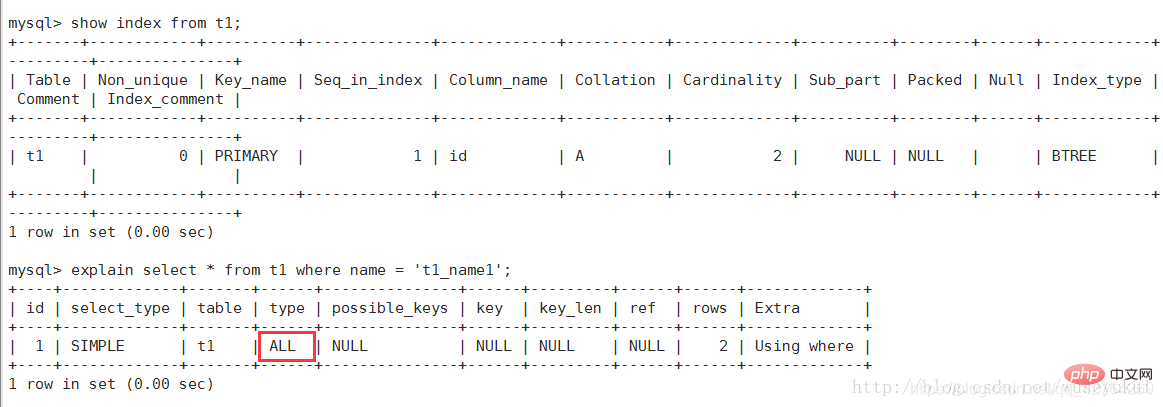 possible_keys
possible_keys
, l'index sera répertorié, mais il ne sera peut-être pas réellement utilisé par la requête
key
L'index réellement utilisé, s'il est NULL, il n'est pas utilisé comme index.
Si un index de couverture est utilisé dans la requête, l'index n'apparaîtra que dans la liste des clés
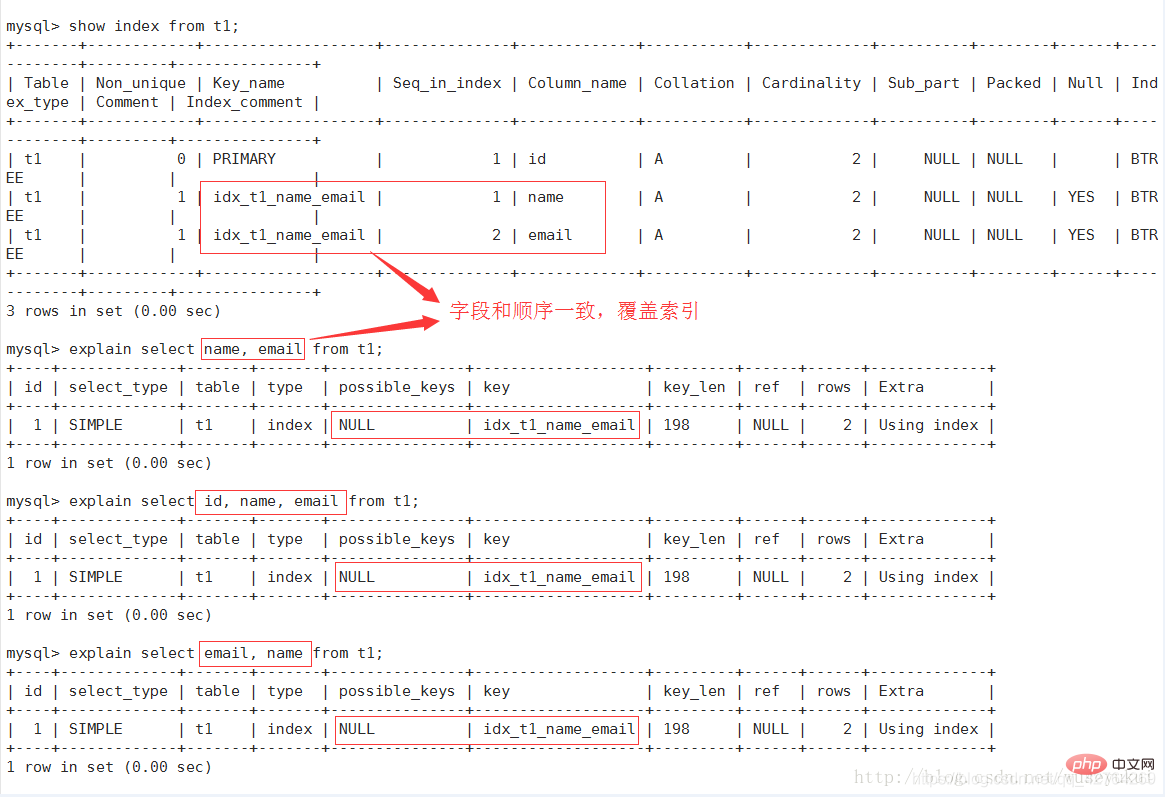
 key_len
key_len
représente le nombre d'octets utilisés dans l'index et la longueur de l'index utilisée dans la requête (longueur maximale possible), et non la longueur réelle utilisée. En théorie, plus la longueur est courte, mieux c'est. key_len est calculé en fonction de la définition de la table. Il n'est pas récupéré de la table. La colonne
ref
display index est utilisée si possible, c'est une constante.
lignes
En fonction des statistiques de table et de la sélection d'index, estimez approximativement le nombre de lignes qui doivent être lues pour trouver les enregistrements requis
Extra
ne convient pas à l'affichage dans d'autres champs, mais constitue une information supplémentaire très importante
1. Utilisation du tri de fichiers :
mysql utilise un index externe pour trier les données, au lieu de trier et de lire selon l'index du tableau. En d'autres termes, MySQL ne peut pas utiliser l'index pour effectuer l'opération de tri en tant que "tri de fichiers" les exigences. MySQL doit à nouveau implémenter le "tri de fichiers" à l'intérieur
2. Utilisation de tables temporaires :
3. Utilisation de l'index :
signifie que l'opération de sélection correspondante utilise un 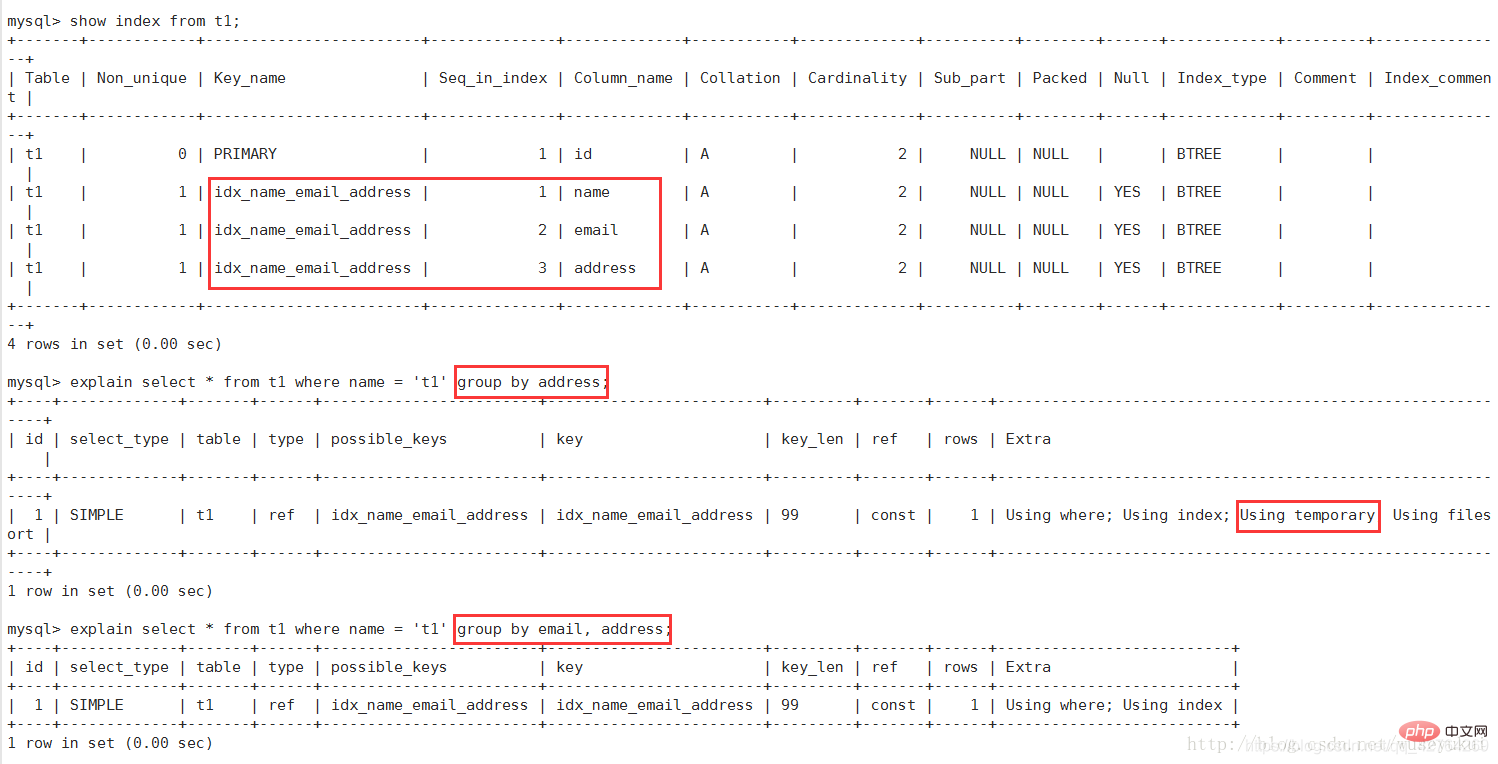 index de couverture
index de couverture
Si vous utilisez où apparaît en même temps, cela signifie que l'index est utilisé pour effectuer une recherche de valeurs de clé d'index (voir l'image ci-dessus)
Si Utiliser où apparaît en même temps, cela indique que l'index est utilisé pour lire des données au lieu d'effectuer des opérations de rechercheCovering Index
(Covering Index) : Également appelé couverture d'index. Ce sont les champs de la liste de sélection qui peuvent être obtenus uniquement à partir de l'index. Il n'est pas nécessaire de relire le fichier de données en fonction de l'index. En d'autres termes, la colonne de requête doit être couverte par l'index construit.
Remarque : 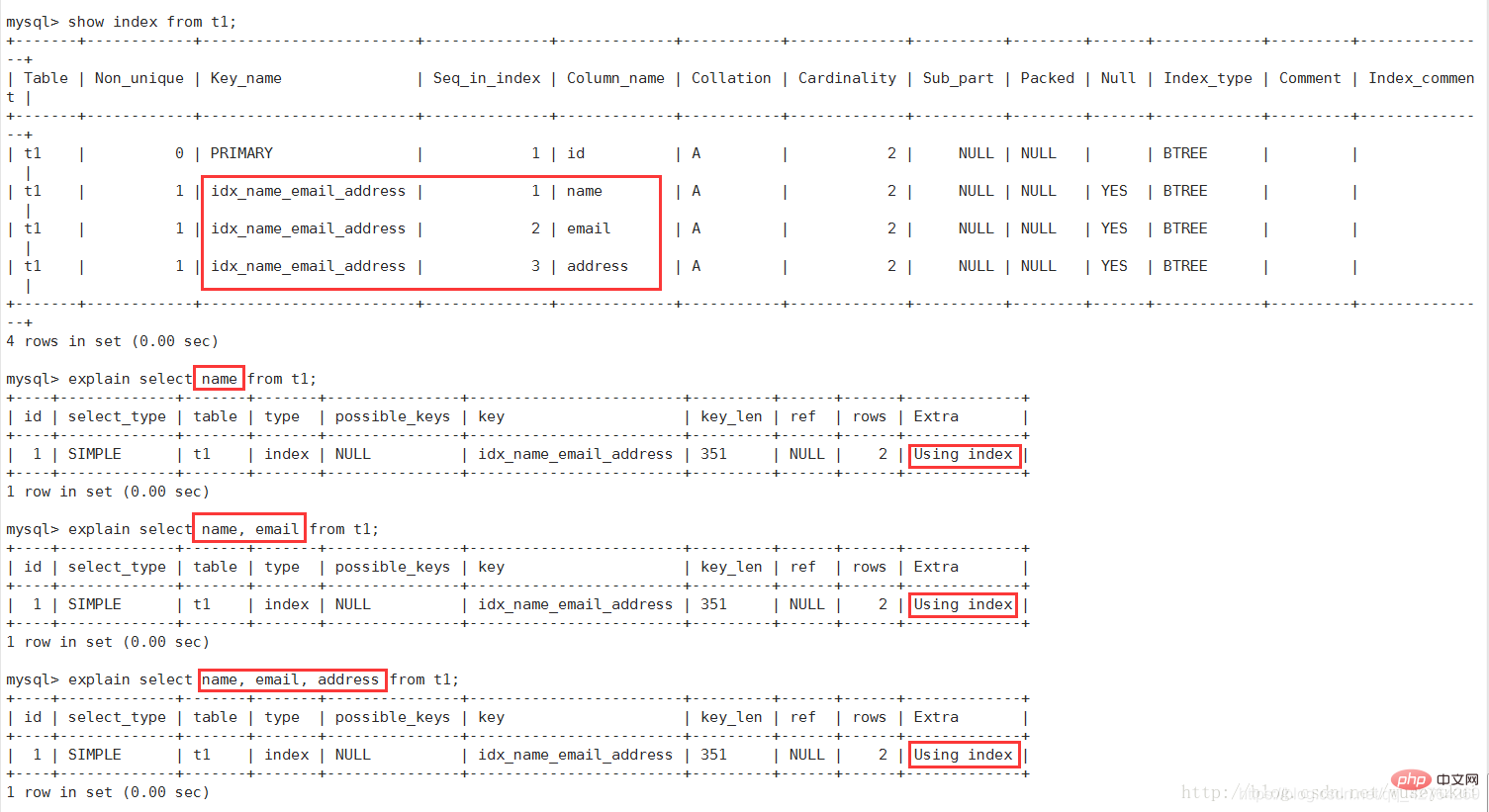
a. Si vous devez utiliser un index de couverture, supprimez uniquement les colonnes requises des champs de la liste de sélection. N'utilisez pas select *b. sera trop volumineux, ce qui réduira la taille du fichier
4. Utilisation du cache de liens utilisé
- 6. WHERE :
- valeur de la clause Where Elle est toujours fausse et ne peut pas être utilisée pour obtenir des ancêtres
7 Sélectionnez les tables optimisées :
En l'absence de clause group by, optimisez MIN/. Opérations MAX basées sur l'index ou optimisation de COUNT pour l'opération du moteur de stockage MyISAM (*), vous n'avez pas besoin d'attendre la phase d'exécution pour effectuer les calculs, l'optimisation peut être complétée lors de la phase de génération du plan d'exécution de la requête
8 . distinct :
Optimisez l'opération distincte, arrêtez de chercher la même chose après avoir trouvé le premier ancêtre correspondant. Ça vaut le coup
Cas complet

Séquence d'exécution
1 (id = 4), [select id, name from t2] : select_type est union, indiquant que la sélection avec id=4 est la deuxième sélection dans l'union.
2 (id = 3), [select id, name from t1 which address = '11'] : Comme il s'agit d'une sous-requête incluse dans l'instruction from, elle est marquée comme DERIVED (dérivée), où adresse = '11' passé L'index composite idx_name_email_address peut être récupéré, donc le type est index.
3 (id = 2), [select id from t3] : Comme il s'agit d'une sous-requête incluse dans select, elle est marquée comme SUBQUERY.
4 (id = 1), [select d1.name, … d2 from … d1] : select_type est PRIMARY, indiquant que la requête est la requête la plus externe, et la colonne du tableau est marquée comme "derived3", indiquant que la requête les résultats proviennent d'une table dérivée (sélectionnez le résultat pour id = 3).
5 (id = NULL), [ ... union ... ] : Représente l'étape de lecture des lignes de la table temporaire de l'union "Union 1, 4" dans la colonne du tableau signifie utiliser les résultats de sélection de id=1. et id=4.
Apprentissage recommandé : Tutoriel vidéo mysql
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Instructions SQL courantes pour l'optimisation des bases de données dans MySQL (partage de résumé)
- Disposition spéciale des journaux MySQL : refaire le journal et annuler le journal
- Résoudre le problème d'erreur de fuseau horaire Mysql dans un article
- Quelle est la différence entre la syntaxe de MySQL et celle du serveur SQL ?
- Résumé et disposition de MySQL basé sur la construction maître-esclave GTID