
Maison >base de données >Redis >La différence entre la stratégie d'élimination de la mémoire de Redis et la stratégie de suppression expirée
La différence entre la stratégie d'élimination de la mémoire de Redis et la stratégie de suppression expirée

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBavant
- 2022-08-01 15:12:343132parcourir

Apprentissage recommandé : Tutoriel vidéo Redis
Avant-propos
Redis peut définir le délai d'expiration des clés, il doit donc y avoir un mécanisme correspondant pour supprimer les paires clé-valeur expirées, et à quoi sert ce travail, c'est l'expiration Stratégie de suppression de valeur clé.
La « stratégie d'élimination de la mémoire » et la « stratégie de suppression d'expiration » de Redis sont facilement confondues par de nombreux amis. Bien que ces deux mécanismes effectuent tous deux des opérations de suppression, les conditions de déclenchement et les stratégies utilisées sont différentes.
Aujourd'hui, je vais vous expliquer la "stratégie d'élimination de la mémoire" et la "stratégie de suppression expirée".
Stratégie de suppression expirée
Redis peut définir le délai d'expiration des clés, il doit donc y avoir un mécanisme correspondant pour supprimer les paires clé-valeur expirées, et qu'est-ce que cela fait, c'est la stratégie de suppression clé-valeur expirée .
Comment définir le délai d'expiration ?
Parlons d’abord de la commande permettant de définir le délai d’expiration de la clé. Il existe 4 commandes pour définir le délai d'expiration de la clé :
- expire 42538adbdb6240b2b083a000a615d5bd 751fecf49c9d13ca89ee2cbb9b75d4f6 : définir la clé pour qu'elle expire après n secondes. Par exemple, expirer la clé 100 signifie définir la clé pour qu'elle expire après 100 secondes ; pexpire 8a66db7248cea4b091ced72fb7100c95 751fecf49c9d13ca89ee2cbb9b75d4f6 : définissez la clé pour qu'elle expire après n millisecondes. Par exemple, pexpire key2 100000 signifie que la clé2 expire après 100 000 millisecondes (100 secondes).
- expireat
key> 751fecf49c9d13ca89ee2cbb9b75d4f6 : définissez la clé pour qu'elle expire après un certain horodatage (précis à la milliseconde), par exemple, pexpireat key4 1655654400000 signifie que la clé4 expire après l'horodatage 1655654400000 (précis à la milliseconde) - Bien sûr, lors de la définition de la chaîne, vous pouvez également définir le délai d'expiration de la clé en même temps. Il existe 3 commandes :
set 42538adbdb6240b2b083a000a615d5bd 8487820b627113dd990f63dd2ef215f3 ex 751fecf49c9d13ca89ee2cbb9b75d4f6 , spécifiez le délai d'expiration (précis en secondes) en même temps ;
- set 42538adbdb6240b2b083a000a615d5bd 8487820b627113dd990f63dd2ef215f3 px 751fecf49c9d13ca89ee2cbb9b75d4f6 : lors de la définition de la paire clé-valeur, spécifiez également le délai d'expiration (précis en millisecondes) ;
- setex 42538adbdb6240b2b083a000a615d5bd 751fecf49c9d13ca89ee2cbb9b75d4f6 8487820b627113dd990f63dd2ef215f3 : Définir Lors de la saisie d'une paire clé-valeur, spécifiez également le délai d'expiration (précis en secondes).
- Si vous souhaitez vérifier le temps de survie restant d'une clé, vous pouvez utiliser la commande TTL 42538adbdb6240b2b083a000a615d5bd
# 设置键值对的时候,同时指定过期时间位 60 秒 > setex key1 60 value1 OK # 查看 key1 过期时间还剩多少 > ttl key1 (integer) 56 > ttl key1 (integer) 52Si vous regrettez soudainement et annulez le délai d'expiration de la clé, vous pouvez utiliser la commande PERSIST 42538adbdb6240b2b083a000a615d5bd
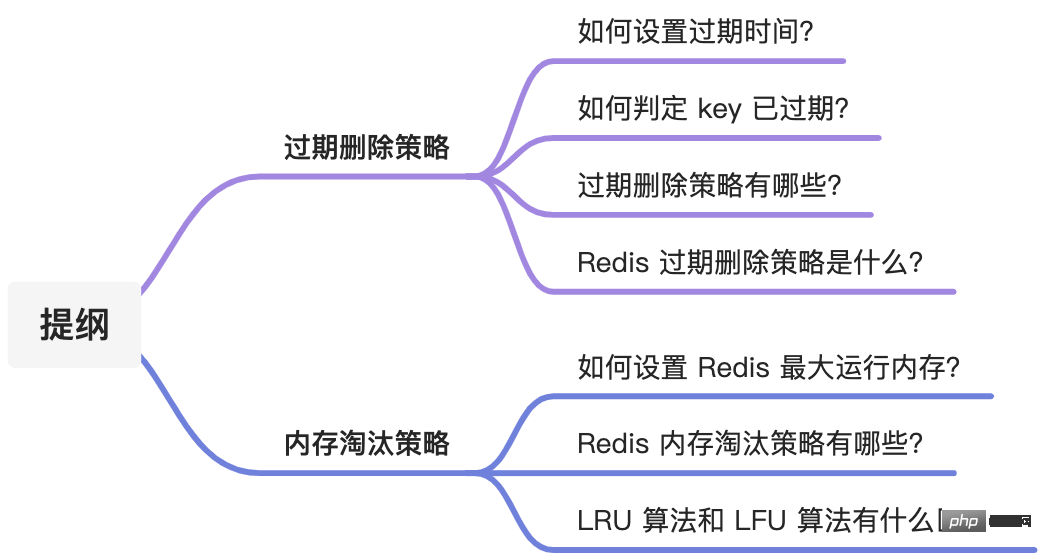
# 取消 key1 的过期时间 > persist key1 (integer) 1 # 使用完 persist 命令之后, # 查下 key1 的存活时间结果是 -1,表明 key1 永不过期 > ttl key1 (integer) -1Comment déterminer si la clé a expiré ? Chaque fois que nous définissons un délai d'expiration pour une clé, Redis stockera la clé avec le délai d'expiration dans un dictionnaire d'expiration (expires dict). En d'autres termes, le "dictionnaire d'expiration" enregistre le délai d'expiration de toutes les clés de la base de données. .
Le dictionnaire expiré est stocké dans la structure redisDb, comme suit :
typedef struct redisDb {
dict *dict; /* 数据库键空间,存放着所有的键值对 */
dict *expires; /* 键的过期时间 */
....
} redisDb;La structure des données du dictionnaire expiré est la suivante :
La clé du dictionnaire expiré est un pointeur, pointant vers un certain objet clé ;
- La valeur du dictionnaire expiré est Un entier de type long long. Cet entier stocke l'heure d'expiration de la clé
- La structure des données du dictionnaire d'expiration est présentée dans la figure ci-dessous :
Le dictionnaire est en fait une table de hachage, et le plus grand avantage de la table de hachage est qu'elle nous permet d'effectuer une recherche rapide avec une complexité temporelle O(1). Lorsque nous interrogeons une clé, Redis vérifie d'abord si la clé existe dans le dictionnaire d'expiration : 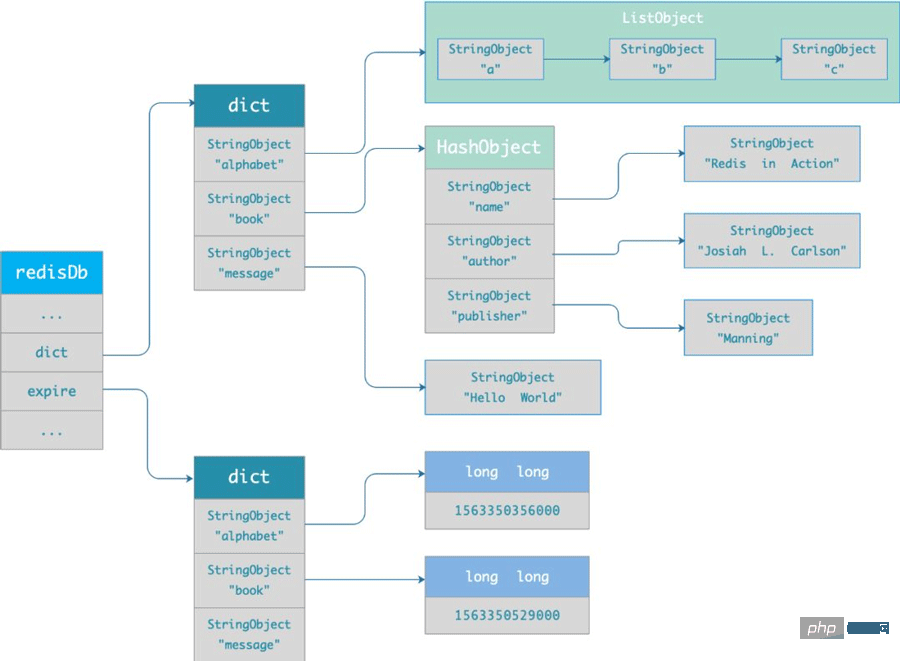
Sinon, la valeur de la clé sera lue normalement
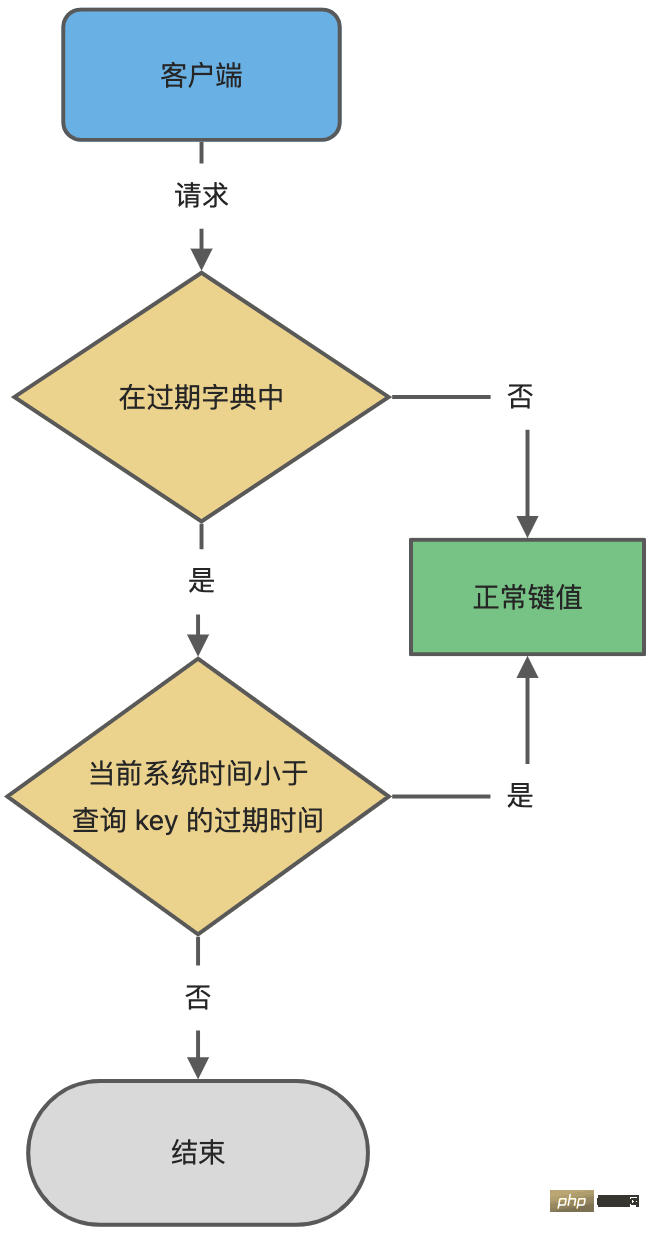
- Si elle existe, l'heure d'expiration de la clé sera obtenue, puis par rapport au système actuel L'heure est comparée. Si elle est supérieure à l'heure du système, elle n'a pas expiré. Sinon, il est déterminé que la clé a expiré.
- Le processus de détermination des clés expirées est illustré dans la figure ci-dessous :
Quelles sont les stratégies de suppression expirées ?
Avant de parler de la stratégie de suppression d'expiration Redis, permettez-moi d'abord de vous présenter les trois stratégies courantes de suppression d'expiration :
- 定时删除;
- 惰性删除;
- 定期删除;
接下来,分别分析它们的优缺点。
定时删除策略是怎么样的?
定时删除策略的做法是,在设置 key 的过期时间时,同时创建一个定时事件,当时间到达时,由事件处理器自动执行 key 的删除操作。
定时删除策略的优点:可以保证过期 key 会被尽快删除,也就是内存可以被尽快地释放。因此,定时删除对内存是最友好的。
定时删除策略的缺点:在过期 key 比较多的情况下,删除过期 key 可能会占用相当一部分 CPU 时间,在内存不紧张但 CPU 时间紧张的情况下,将 CPU 时间用于删除和当前任务无关的过期键上,无疑会对服务器的响应时间和吞吐量造成影响。所以,定时删除策略对 CPU 不友好。
惰性删除策略是怎么样的?惰性删除策略的做法是,不主动删除过期键,每次从数据库访问 key 时,都检测 key 是否过期,如果过期则删除该 key。
惰性删除策略的优点:因为每次访问时,才会检查 key 是否过期,所以此策略只会使用很少的系统资源,因此,惰性删除策略对 CPU 时间最友好。
惰性删除策略的缺点:如果一个 key 已经过期,而这个 key 又仍然保留在数据库中,那么只要这个过期 key 一直没有被访问,它所占用的内存就不会释放,造成了一定的内存空间浪费。所以,惰性删除策略对内存不友好。
定期删除策略是怎么样的?定期删除策略的做法是,每隔一段时间「随机」从数据库中取出一定数量的 key 进行检查,并删除其中的过期key。
定期删除策略的优点:通过限制删除操作执行的时长和频率,来减少删除操作对 CPU 的影响,同时也能删除一部分过期的数据减少了过期键对空间的无效占用。
定期删除策略的缺点:
- 内存清理方面没有定时删除效果好,同时没有惰性删除使用的系统资源少。
- 难以确定删除操作执行的时长和频率。如果执行的太频繁,定期删除策略变得和定时删除策略一样,对CPU不友好;如果执行的太少,那又和惰性删除一样了,过期 key 占用的内存不会及时得到释放。
Redis 过期删除策略是什么?
前面介绍了三种过期删除策略,每一种都有优缺点,仅使用某一个策略都不能满足实际需求。
所以, Redis 选择「惰性删除+定期删除」这两种策略配和使用,以求在合理使用 CPU 时间和避免内存浪费之间取得平衡。
Redis 是怎么实现惰性删除的?
Redis 的惰性删除策略由 db.c 文件中的 expireIfNeeded 函数实现,代码如下:
int expireIfNeeded(redisDb *db, robj *key) {
// 判断 key 是否过期
if (!keyIsExpired(db,key)) return 0;
....
/* 删除过期键 */
....
// 如果 server.lazyfree_lazy_expire 为 1 表示异步删除,反之同步删除;
return server.lazyfree_lazy_expire ? dbAsyncDelete(db,key) :
dbSyncDelete(db,key);
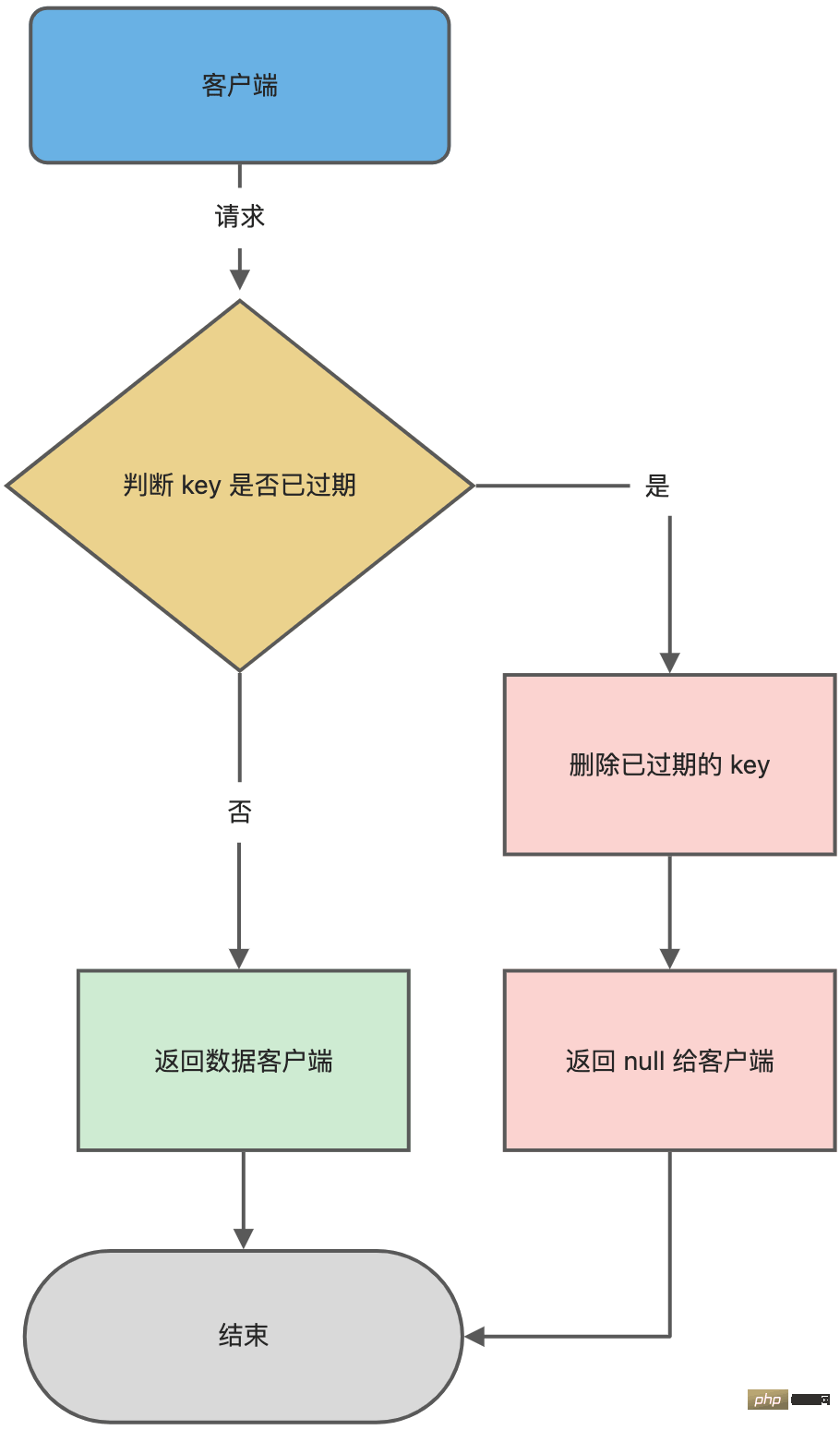
}Redis 在访问或者修改 key 之前,都会调用 expireIfNeeded 函数对其进行检查,检查 key 是否过期:
- 如果过期,则删除该 key,至于选择异步删除,还是选择同步删除,根据lazyfree_lazy_expire 参数配置决定(Redis 4.0版本开始提供参数),然后返回 null 给客服端;
- 如果没有过期,不做任何处理,然后返回正常的键值对给客户端;
惰性删除的流程图如下:
Redis 是怎么实现定期删除的?
再回忆一下,定期删除策略的做法:每隔一段时间「随机」从数据库中取出一定数量的 key 进行检查,并删除其中的过期key。
1.这个间隔检查的时间是多长呢?
在 Redis 中,默认每秒进行 10 次过期检查一次数据库,此配置可通过 Redis 的配置文件 redis.conf 进行配置,配置键为 hz 它的默认值是 hz 10。
特别强调下,每次检查数据库并不是遍历过期字典中的所有 key,而是从数据库中随机抽取一定数量的 key 进行过期检查。
2.随机抽查的数量是多少呢?
我查了下源码,定期删除的实现在 expire.c 文件下的 activeExpireCycle 函数中,其中随机抽查的数量由 ACTIVE_EXPIRE_CYCLE_LOOKUPS_PER_LOOP 定义的,它是写死在代码中的,数值是 20。
也就是说,数据库每轮抽查时,会随机选择 20 个 key 判断是否过期。
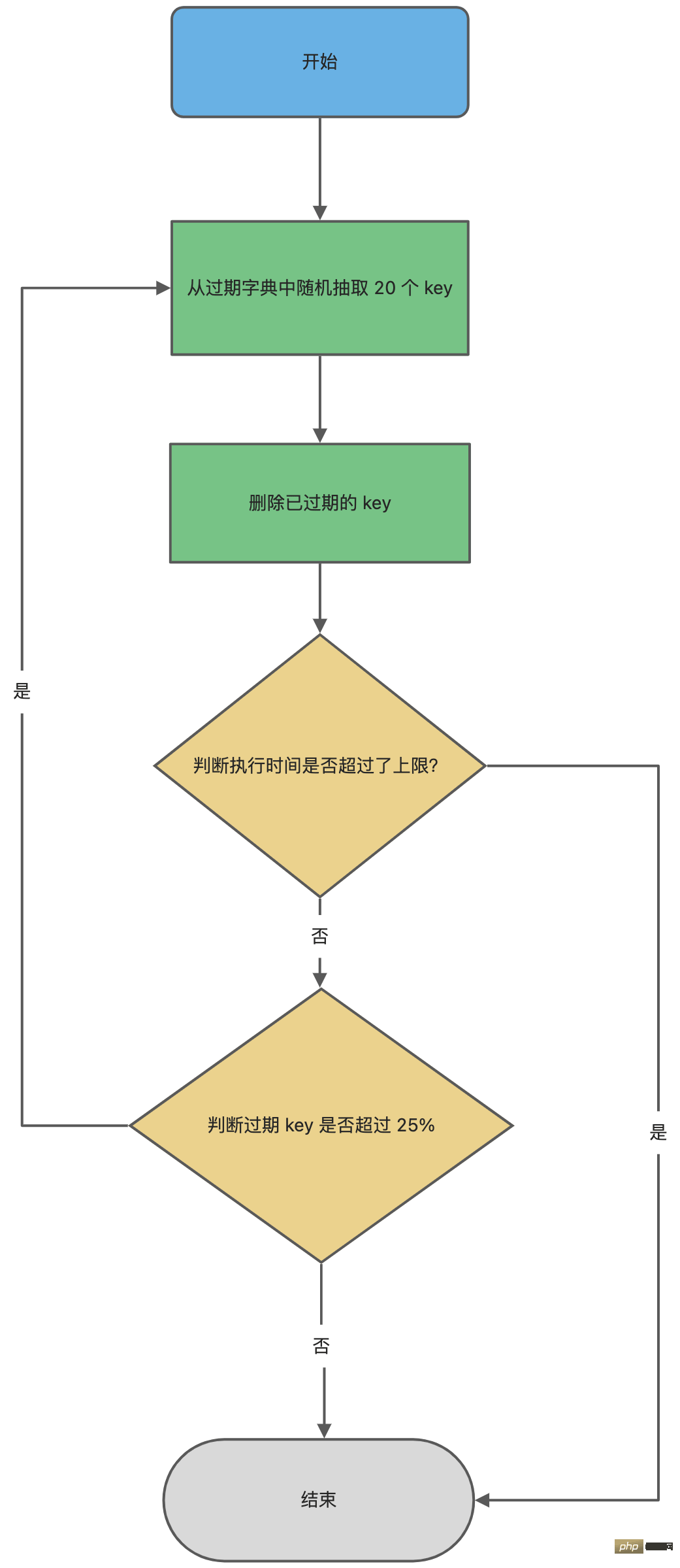
接下来,详细说说 Redis 的定时删除的流程:
- 从过期字典中随机抽取 20 个 key;
- 检查这 20 个 key 是否过期,并删除已过期的 key;
- 如果本轮检查的已过期 key 的数量,超过 5 个(20/4),也就是「已过期 key 的数量」占比「随机抽取 key 的数量」大于 25%,则继续重复步骤 1;如果已过期的 key 比例小于 25%,则停止继续删除过期 key,然后等待下一轮再检查。
可以看到,定时删除是一个循环的流程。
那 Redis 为了保证定时删除不会出现循环过度,导致线程卡死现象,为此增加了定时删除循环流程的时间上限,默认不会超过 25ms。
针对定时删除的流程,我写了个伪代码:
do {
//已过期的数量
expired = 0;
//随机抽取的数量
num = 20;
while (num--) {
//1. 从过期字典中随机抽取 1 个 key
//2. 判断该 key 是否过期,如果已过期则进行删除,同时对 expired++
}
// 超过时间限制则退出
if (timelimit_exit) return;
/* 如果本轮检查的已过期 key 的数量,超过 25%,则继续随机抽查,否则退出本轮检查 */
} while (expired > 20/4);定时删除的流程如下:
内存淘汰策略
前面说的过期删除策略,是删除已过期的 key,而当 Redis 的运行内存已经超过 Redis 设置的最大内存之后,则会使用内存淘汰策略删除符合条件的 key,以此来保障 Redis 高效的运行。
如何设置 Redis 最大运行内存?
在配置文件 redis.conf 中,可以通过参数 maxmemory 4d5e782727adce28d9e975bcb1fbc12c 来设定最大运行内存,只有在 Redis 的运行内存达到了我们设置的最大运行内存,才会触发内存淘汰策略。
不同位数的操作系统,maxmemory 的默认值是不同的:
- 在 64 位操作系统中,maxmemory 的默认值是 0,表示没有内存大小限制,那么不管用户存放多少数据到 Redis 中,Redis 也不会对可用内存进行检查,直到 Redis 实例因内存不足而崩溃也无作为。
- 在 32 位操作系统中,maxmemory 的默认值是 3G,因为 32 位的机器最大只支持 4GB 的内存,而系统本身就需要一定的内存资源来支持运行,所以 32 位操作系统限制最大 3 GB 的可用内存是非常合理的,这样可以避免因为内存不足而导致 Redis 实例崩溃。
Redis 内存淘汰策略有哪些?
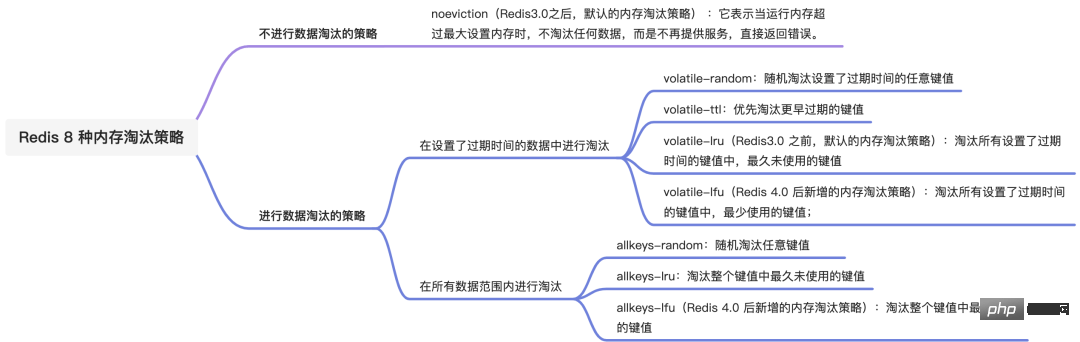
Redis 内存淘汰策略共有八种,这八种策略大体分为「不进行数据淘汰」和「进行数据淘汰」两类策略。
1.不进行数据淘汰的策略
noeviction(Redis3.0之后,默认的内存淘汰策略) :它表示当运行内存超过最大设置内存时,不淘汰任何数据,而是不再提供服务,直接返回错误。
2.进行数据淘汰的策略
针对「进行数据淘汰」这一类策略,又可以细分为「在设置了过期时间的数据中进行淘汰」和「在所有数据范围内进行淘汰」这两类策略。
在设置了过期时间的数据中进行淘汰:
- volatile-random:随机淘汰设置了过期时间的任意键值;
- volatile-ttl:优先淘汰更早过期的键值。
- volatile-lru(Redis3.0 之前,默认的内存淘汰策略):淘汰所有设置了过期时间的键值中,最久未使用的键值;
- volatile-lfu(Redis 4.0 后新增的内存淘汰策略):淘汰所有设置了过期时间的键值中,最少使用的键值;
在所有数据范围内进行淘汰:
- allkeys-random:随机淘汰任意键值;
- allkeys-lru:淘汰整个键值中最久未使用的键值;
- allkeys-lfu(Redis 4.0 后新增的内存淘汰策略):淘汰整个键值中最少使用的键值。
如何查看当前 Redis 使用的内存淘汰策略?
可以使用 config get maxmemory-policy 命令,来查看当前 Redis 的内存淘汰策略,命令如下:
127.0.0.1:6379> config get maxmemory-policy 1) "maxmemory-policy" 2) "noeviction"
可以看出,当前 Redis 使用的是 noeviction 类型的内存淘汰策略,它是 Redis 3.0 之后默认使用的内存淘汰策略,表示当运行内存超过最大设置内存时,不淘汰任何数据,但新增操作会报错。
如何修改 Redis 内存淘汰策略?
设置内存淘汰策略有两种方法:
- 方式一:通过“config set maxmemory-policy c108bdf0b9c068e379c81772fce52805”命令设置。它的优点是设置之后立即生效,不需要重启 Redis 服务,缺点是重启 Redis 之后,设置就会失效。
- 方式二:通过修改 Redis 配置文件修改,设置“maxmemory-policy c108bdf0b9c068e379c81772fce52805”,它的优点是重启 Redis 服务后配置不会丢失,缺点是必须重启 Redis 服务,设置才能生效。
LRU 算法和 LFU 算法有什么区别?
LFU 内存淘汰算法是 Redis 4.0 之后新增内存淘汰策略,那为什么要新增这个算法?那肯定是为了解决 LRU 算法的问题。
接下来,就看看这两个算法有什么区别?Redis 又是如何实现这两个算法的?
什么是 LRU 算法?
LRU 全称是 Least Recently Used 翻译为最近最少使用,会选择淘汰最近最少使用的数据。
传统 LRU 算法的实现是基于「链表」结构,链表中的元素按照操作顺序从前往后排列,最新操作的键会被移动到表头,当需要内存淘汰时,只需要删除链表尾部的元素即可,因为链表尾部的元素就代表最久未被使用的元素。
Redis 并没有使用这样的方式实现 LRU 算法,因为传统的 LRU 算法存在两个问题:
- 需要用链表管理所有的缓存数据,这会带来额外的空间开销;
- 当有数据被访问时,需要在链表上把该数据移动到头端,如果有大量数据被访问,就会带来很多链表移动操作,会很耗时,进而会降低 Redis 缓存性能。
Redis 是如何实现 LRU 算法的?
Redis 实现的是一种近似 LRU 算法,目的是为了更好的节约内存,它的实现方式是在 Redis 的对象结构体中添加一个额外的字段,用于记录此数据的最后一次访问时间。
当 Redis 进行内存淘汰时,会使用随机采样的方式来淘汰数据,它是随机取 5 个值(此值可配置),然后淘汰最久没有使用的那个。
Redis 实现的 LRU 算法的优点:
- 不用为所有的数据维护一个大链表,节省了空间占用;
- 不用在每次数据访问时都移动链表项,提升了缓存的性能;
但是 LRU 算法有一个问题,无法解决缓存污染问题,比如应用一次读取了大量的数据,而这些数据只会被读取这一次,那么这些数据会留存在 Redis 缓存中很长一段时间,造成缓存污染。
因此,在 Redis 4.0 之后引入了 LFU 算法来解决这个问题。
什么是 LFU 算法?
LFU 全称是 Least Frequently Used 翻译为最近最不常用的,LFU 算法是根据数据访问次数来淘汰数据的,它的核心思想是“如果数据过去被访问多次,那么将来被访问的频率也更高”。
所以, LFU 算法会记录每个数据的访问次数。当一个数据被再次访问时,就会增加该数据的访问次数。这样就解决了偶尔被访问一次之后,数据留存在缓存中很长一段时间的问题,相比于 LRU 算法也更合理一些。
Redis 是如何实现 LFU 算法的?
LFU 算法相比于 LRU 算法的实现,多记录了「数据的访问频次」的信息。Redis 对象的结构如下:
typedef struct redisObject {
...
// 24 bits,用于记录对象的访问信息
unsigned lru:24;
...
} robj;Redis 对象头中的 lru 字段,在 LRU 算法下和 LFU 算法下使用方式并不相同。
在 LRU 算法中,Redis 对象头的 24 bits 的 lru 字段是用来记录 key 的访问时间戳,因此在 LRU 模式下,Redis可以根据对象头中的 lru 字段记录的值,来比较最后一次 key 的访问时间长,从而淘汰最久未被使用的 key。
在 LFU 算法中,Redis对象头的 24 bits 的 lru 字段被分成两段来存储,高 16bit 存储 ldt(Last Decrement Time),低 8bit 存储 logc(Logistic Counter)。
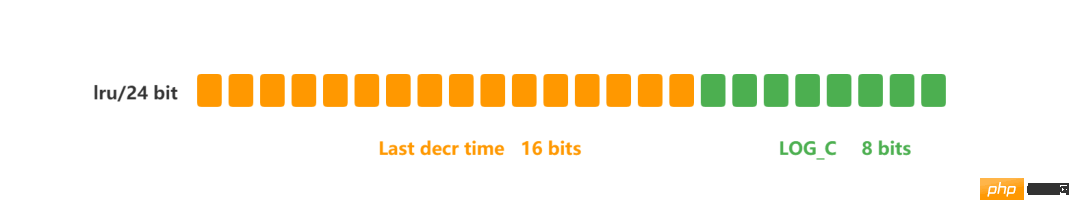
- ldt 是用来记录 key 的访问时间戳;
- logc 是用来记录 key 的访问频次,它的值越小表示使用频率越低,越容易淘汰,每个新加入的 key 的logc 初始值为 5。
注意,logc 并不是单纯的访问次数,而是访问频次(访问频率),因为 logc 会随时间推移而衰减的。
À chaque accès à la clé, une opération de décroissance sera d'abord effectuée sur logc. La valeur de décroissance est liée à la différence entre les temps d'accès précédent et suivant si la différence de temps entre le dernier temps d'accès et ce temps d'accès est importante, alors la valeur d'atténuation sera plus grande, l'algorithme LFU mis en œuvre de cette manière élimine les données en fonction de la fréquence d'accès, et pas seulement du nombre d'accès. La fréquence d'accès doit prendre en compte la durée de l'accès à la clé. Plus l'accès précédent à la clé est long par rapport à l'heure actuelle, la fréquence d'accès de cette clé diminuera en conséquence et la probabilité d'être éliminée sera plus grande.
Après avoir terminé l'opération d'atténuation sur logc, démarrez l'opération d'augmentation sur logc. L'opération d'augmentation n'est pas simplement + 1 directement, mais augmente en fonction de la probabilité. Plus le logc est grand pour une clé, plus il sera difficile de l'augmenter. logc.
Ainsi, lorsque Redis accède à la clé, logc change comme ceci :
- Atténuez d'abord logc en fonction de la durée écoulée entre le dernier accès et l'heure actuelle
- Ensuite, augmentez la valeur de logc selon une certaine probabilité ;
redis.conf fournit deux éléments de configuration pour ajuster l'algorithme LFU afin de contrôler la croissance et la décroissance de logc :
- lfu-decay-time est utilisé pour ajuster la vitesse de décroissance de logc, qui est une valeur en minutes. la valeur par défaut est 1. Plus la valeur de lfu-decay-time est grande, plus la décroissance est lente ;
- lfu-log-factor est utilisé pour ajuster le taux de croissance de logc. Plus la valeur de lfu-log-factor est grande. ralentir la croissance de logc.
Résumé
La stratégie de suppression expirée utilisée par Redis est "suppression paresseuse + suppression régulière", et les objets supprimés sont des clés expirées.

La stratégie d'élimination de la mémoire consiste à résoudre le problème de mémoire excessive. Lorsque la mémoire en cours d'exécution de Redis dépasse la mémoire en cours d'exécution maximale, la stratégie d'élimination de la mémoire sera déclenchée. Après Redis 4.0, un total de 8 stratégies d'élimination de la mémoire sont disponibles. été mis en œuvre. J'y pense aussi 8 stratégies sont classées comme suit :
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Cet article vous apprend à implémenter la file d'attente de messages Redis à l'aide de ThinkPHP à l'aide de think-queue.
- Redis de la construction de l'environnement à une utilisation compétente (partage de résumé)
- La collection ordonnée Redis utilise l'induction de points de connaissance
- Apprentissage Redis : utilisation de base de Jedis
- Explication graphique détaillée du cluster Redis et de son extension