
Maison >développement back-end >Tutoriel Python >Explication super détaillée du robot d'exploration Python
Explication super détaillée du robot d'exploration Python

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBavant
- 2022-07-14 16:58:504255parcourir
Cet article vous apporte des connaissances pertinentes sur Python, qui organise principalement les problèmes liés aux robots d'exploration Web (également appelés web spiders, web robots) simulent les navigateurs pour envoyer des requêtes réseau et recevoir des réponses aux requêtes, un programme qui capture automatiquement Internet. informations selon certaines règles. Jetons-y un coup d'œil, j'espère que cela sera utile à tout le monde.

【Recommandation associée : Tutoriel vidéo Python3】
Crawler
Le robot d'exploration Web (également connu sous le nom d'araignée Web, robot de réseau) simule le navigateur pour envoyer des requêtes réseau et recevoir des réponses aux requêtes, un programme qui s'exécute automatiquement. explore les informations Internet.
En principe, tant que le navigateur (client) peut faire n'importe quoi, le robot d'exploration peut le faire.
Pourquoi devrions-nous utiliser des robots d'exploration
L'ère du Big Data sur Internet nous offre la commodité de la vie et l'apparence explosive des données massives sur le réseau.
Dans le passé, nous utilisions les livres, les journaux, la télévision, la radio ou l'information. La quantité d'informations était limitée et devait être filtrée dans une certaine mesure. L'information était relativement efficace, mais l'inconvénient était qu'elle était trop restreinte. La transmission asymétrique de l’information limite notre vision et nous empêche d’apprendre davantage d’informations et de connaissances.
À l'ère du big data sur Internet, nous avons soudainement accès gratuitement à l'information. Nous avons obtenu une quantité massive d'informations, mais la plupart sont des informations indésirables invalides.
Par exemple, Sina Weibo génère des centaines de millions de mises à jour de statut par jour, tandis que dans le moteur de recherche Baidu, vous pouvez rechercher un seul message - 100 000 000 de messages sur la perte de poids.
Dans une telle quantité de fragments d'informations, comment obtenons-nous des informations qui nous sont utiles ?
La réponse est le dépistage !
Collectez du contenu pertinent grâce à une certaine technologie, et ce n'est qu'après analyse et sélection que nous pouvons obtenir les informations dont nous avons réellement besoin.
Ce travail de collecte, d'analyse et d'intégration d'informations peut être appliqué dans un très large éventail de domaines, qu'il s'agisse des services de vie, des voyages, des investissements financiers, de la demande du marché des produits de diverses industries manufacturières, etc... Vous pouvez utiliser cette technologie pour obtenir des informations plus précises et plus efficaces à exploiter.
Bien que la technologie des robots d'exploration Web ait un nom étrange, qui fait que la première réaction de Neng est celle d'une créature douce et se tortillante, il s'agit en fait d'un outil puissant qui peut avancer dans le monde virtuel.
Préparation des robots
Nous parlons généralement des robots Python. En fait, il peut y avoir un malentendu ici. Les robots ne sont pas propres à Python. Il existe de nombreux langages qui peuvent être utilisés pour le crawl, tels que : PHP, JAVA, C#, C++, Python. Choisissez Python La raison pour laquelle vous faites des robots est que Python est relativement simple et possède des fonctions relativement complètes.
Nous devons d'abord télécharger Python, j'ai téléchargé la dernière version officielle 3.8.3
Deuxièmement, nous avons besoin d'un environnement pour exécuter Python, j'utilise pychram

Vous pouvez également le télécharger depuis la version officielle,
Nous avons également besoin de quelques bibliothèques Pour prendre en charge le fonctionnement du robot (certaines bibliothèques peuvent venir avec Python)
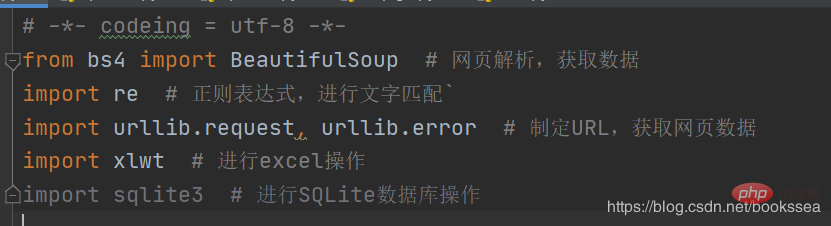
Ce sont presque les bibliothèques que j'ai déjà écrites à l'arrière

(pendant le processus d'exécution du robot, pas nécessairement Vous uniquement. J'ai besoin des bibliothèques ci-dessus. Cela dépend de la façon dont vous écrivez le robot. Quoi qu'il en soit, si vous avez besoin d'une bibliothèque, nous pouvons l'installer directement dans les paramètres)
Explication du projet de robot
Ce que je fais, c'est explorer le code du robot de. les 250 meilleurs films classés par Douban
Ce que nous voulons explorer, c'est ce site Web : https://movie.douban.com/top250
J'ai fini d'explorer ici. Laissez-moi vous montrer le rendu. J'ai enregistré le contenu exploré en xls.
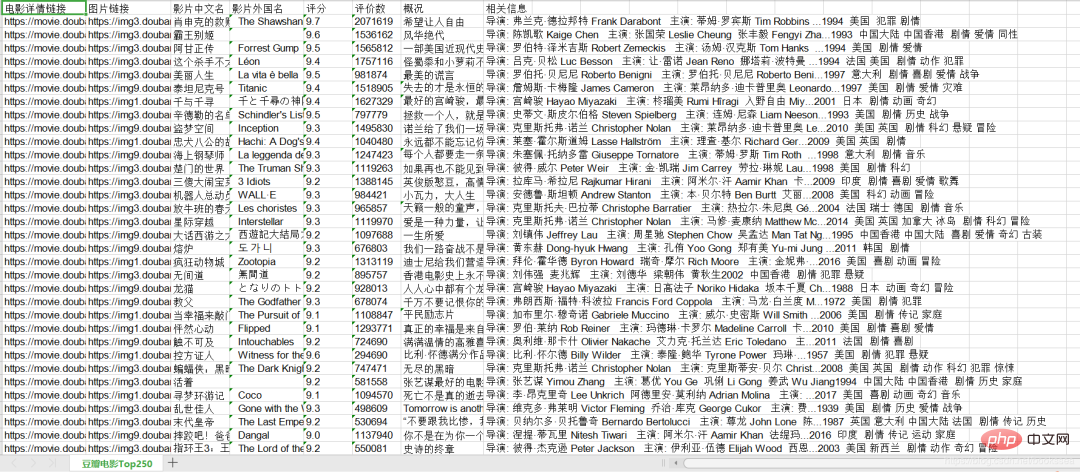
Le contenu que nous avons exploré est le suivant : Lien des détails du film, lien de l'image, nom chinois du film, nom étranger du film, note, nombre de critiques, aperçu et informations connexes.
Analyse du code
Publiez d'abord le code, puis je l'analyserai étape par étape en fonction du code
# -*- codeing = utf-8 -*-
from bs4 import BeautifulSoup # 网页解析,获取数据
import re # 正则表达式,进行文字匹配`
import urllib.request, urllib.error # 制定URL,获取网页数据
import xlwt # 进行excel操作
#import sqlite3 # 进行SQLite数据库操作
findLink = re.compile(r'<a href="(.*?)">') # 创建正则表达式对象,标售规则 影片详情链接的规则
findImgSrc = re.compile(r'<img.*src="(.*?)"', re.S)
findTitle = re.compile(r'<span class="title">(.*)</span>')
findRating = re.compile(r'<span class="rating_num" property="v:average">(.*)</span>')
findJudge = re.compile(r'<span>(\d*)人评价</span>')
findInq = re.compile(r'<span class="inq">(.*)</span>')
findBd = re.compile(r'<p class="">(.*?)</p>', re.S)
def main():
baseurl = "https://movie.douban.com/top250?start=" #要爬取的网页链接
# 1.爬取网页
datalist = getData(baseurl)
savepath = "豆瓣电影Top250.xls" #当前目录新建XLS,存储进去
# dbpath = "movie.db" #当前目录新建数据库,存储进去
# 3.保存数据
saveData(datalist,savepath) #2种存储方式可以只选择一种
# saveData2DB(datalist,dbpath)
# 爬取网页
def getData(baseurl):
datalist = [] #用来存储爬取的网页信息
for i in range(0, 10): # 调用获取页面信息的函数,10次
url = baseurl + str(i * 25)
html = askURL(url) # 保存获取到的网页源码
# 2.逐一解析数据
soup = BeautifulSoup(html, "html.parser")
for item in soup.find_all('p', class_="item"): # 查找符合要求的字符串
data = [] # 保存一部电影所有信息
item = str(item)
link = re.findall(findLink, item)[0] # 通过正则表达式查找
data.append(link)
imgSrc = re.findall(findImgSrc, item)[0]
data.append(imgSrc)
titles = re.findall(findTitle, item)
if (len(titles) == 2):
ctitle = titles[0]
data.append(ctitle)
otitle = titles[1].replace("/", "") #消除转义字符
data.append(otitle)
else:
data.append(titles[0])
data.append(' ')
rating = re.findall(findRating, item)[0]
data.append(rating)
judgeNum = re.findall(findJudge, item)[0]
data.append(judgeNum)
inq = re.findall(findInq, item)
if len(inq) != 0:
inq = inq[0].replace("。", "")
data.append(inq)
else:
data.append(" ")
bd = re.findall(findBd, item)[0]
bd = re.sub('<br(\s+)?/>(\s+)?', "", bd)
bd = re.sub('/', "", bd)
data.append(bd.strip())
datalist.append(data)
return datalist
# 得到指定一个URL的网页内容
def askURL(url):
head = { # 模拟浏览器头部信息,向豆瓣服务器发送消息
"User-Agent": "Mozilla / 5.0(Windows NT 10.0; Win64; x64) AppleWebKit / 537.36(KHTML, like Gecko) Chrome / 80.0.3987.122 Safari / 537.36"
}
# 用户代理,表示告诉豆瓣服务器,我们是什么类型的机器、浏览器(本质上是告诉浏览器,我们可以接收什么水平的文件内容)
request = urllib.request.Request(url, headers=head)
html = ""
try:
response = urllib.request.urlopen(request)
html = response.read().decode("utf-8")
except urllib.error.URLError as e:
if hasattr(e, "code"):
print(e.code)
if hasattr(e, "reason"):
print(e.reason)
return html
# 保存数据到表格
def saveData(datalist,savepath):
print("save.......")
book = xlwt.Workbook(encoding="utf-8",style_compression=0) #创建workbook对象
sheet = book.add_sheet('豆瓣电影Top250', cell_overwrite_ok=True) #创建工作表
col = ("电影详情链接","图片链接","影片中文名","影片外国名","评分","评价数","概况","相关信息")
for i in range(0,8):
sheet.write(0,i,col[i]) #列名
for i in range(0,250):
# print("第%d条" %(i+1)) #输出语句,用来测试
data = datalist[i]
for j in range(0,8):
sheet.write(i+1,j,data[j]) #数据
book.save(savepath) #保存
# def saveData2DB(datalist,dbpath):
# init_db(dbpath)
# conn = sqlite3.connect(dbpath)
# cur = conn.cursor()
# for data in datalist:
# for index in range(len(data)):
# if index == 4 or index == 5:
# continue
# data[index] = '"'+data[index]+'"'
# sql = '''
# insert into movie250(
# info_link,pic_link,cname,ename,score,rated,instroduction,info)
# values (%s)'''%",".join(data)
# # print(sql) #输出查询语句,用来测试
# cur.execute(sql)
# conn.commit()
# cur.close
# conn.close()
# def init_db(dbpath):
# sql = '''
# create table movie250(
# id integer primary key autoincrement,
# info_link text,
# pic_link text,
# cname varchar,
# ename varchar ,
# score numeric,
# rated numeric,
# instroduction text,
# info text
# )
#
#
# ''' #创建数据表
# conn = sqlite3.connect(dbpath)
# cursor = conn.cursor()
# cursor.execute(sql)
# conn.commit()
# conn.close()
# 保存数据到数据库
if __name__ == "__main__": # 当程序执行时
# 调用函数
main()
# init_db("movietest.db")
print("爬取完毕!")
Maintenant, je vais l'expliquer et l'analyser de bas en bas en fonction du code -- coding = utf -8 --, démarrage Il s'agit de définir l'encodage sur utf-8 et de l'écrire au début pour éviter les caractères tronqués.
Ensuite, l'importation suivante consiste à importer quelques bibliothèques et à faire des préparatifs (je n'ai pas utilisé la bibliothèque sqlite3, donc je l'ai commentée).
Certains des mots suivants commençant par find sont des expressions régulières, qui nous permettent de filtrer les informations.
(Les expressions régulières utilisent la bibliothèque re et les expressions régulières ne sont pas obligatoires. Ce n'est pas nécessaire.)
Le processus général est divisé en trois étapes :
1 Explorez la page Web
2. Analysez les données une par une
3. . Enregistrez la page Web
先分析流程1,爬取网页,baseurl 就是我们要爬虫的网页网址,往下走,调用了 getData(baseurl) ,
我们来看 getData方法
for i in range(0, 10): # 调用获取页面信息的函数,10次 url = baseurl + str(i * 25)
这段大家可能看不懂,其实是这样的:
因为电影评分Top250,每个页面只显示25个,所以我们需要访问页面10次,25*10=250。
baseurl = "https://movie.douban.com/top250?start="
我们只要在baseurl后面加上数字就会跳到相应页面,比如i=1时
https://movie.douban.com/top250?start=25
我放上超链接,大家可以点击看看会跳到哪个页面,毕竟实践出真知。
然后又调用了askURL来请求网页,这个方法是请求网页的主体方法,
怕大家翻页麻烦,我再把代码复制一遍,让大家有个直观感受
def askURL(url):
head = { # 模拟浏览器头部信息,向豆瓣服务器发送消息
"User-Agent": "Mozilla / 5.0(Windows NT 10.0; Win64; x64) AppleWebKit / 537.36(KHTML, like Gecko) Chrome / 80.0.3987.122 Safari / 537.36"
}
# 用户代理,表示告诉豆瓣服务器,我们是什么类型的机器、浏览器(本质上是告诉浏览器,我们可以接收什么水平的文件内容)
request = urllib.request.Request(url, headers=head)
html = ""
try:
response = urllib.request.urlopen(request)
html = response.read().decode("utf-8")
except urllib.error.URLError as e:
if hasattr(e, "code"):
print(e.code)
if hasattr(e, "reason"):
print(e.reason)
return html
这个askURL就是用来向网页发送请求用的,那么这里就有老铁问了,为什么这里要写个head呢?
这是因为我们要是不写的话,访问某些网站的时候会被认出来爬虫,显示错误,错误代码
418
这是一个梗大家可以百度下,
418 I’m a teapot
The HTTP 418 I’m a teapot client error response code indicates that
the server refuses to brew coffee because it is a teapot. This error
is a reference to Hyper Text Coffee Pot Control Protocol which was an
April Fools’ joke in 1998.
我是一个茶壶
所以我们需要 “装” ,装成我们就是一个浏览器,这样就不会被认出来,
伪装一个身份。
来,我们继续往下走,
html = response.read().decode("utf-8")
这段就是我们读取网页的内容,设置编码为utf-8,目的就是为了防止乱码。
访问成功后,来到了第二个流程:
2.逐一解析数据
解析数据这里我们用到了 BeautifulSoup(靓汤) 这个库,这个库是几乎是做爬虫必备的库,无论你是什么写法。
下面就开始查找符合我们要求的数据,用BeautifulSoup的方法以及 re 库的
正则表达式去匹配,
findLink = re.compile(r'<a href="(.*?)">') # 创建正则表达式对象,标售规则 影片详情链接的规则 findImgSrc = re.compile(r'<img.*src="(.*?)"', re.S) findTitle = re.compile(r'<span class="title">(.*)</span>') findRating = re.compile(r'<span class="rating_num" property="v:average">(.*)</span>') findJudge = re.compile(r'<span>(\d*)人评价</span>') findInq = re.compile(r'<span class="inq">(.*)</span>') findBd = re.compile(r'<p class="">(.*?)</p>', re.S)
匹配到符合我们要求的数据,然后存进 dataList , 所以 dataList 里就存放着我们需要的数据了。
最后一个流程:
3.保存数据
# 3.保存数据 saveData(datalist,savepath) #2种存储方式可以只选择一种 # saveData2DB(datalist,dbpath)
保存数据可以选择保存到 xls 表, 需要(xlwt库支持)
也可以选择保存数据到 sqlite数据库, 需要(sqlite3库支持)
这里我选择保存到 xls 表 ,这也是为什么我注释了一大堆代码,注释的部分就是保存到 sqlite 数据库的代码,二者选一就行
保存到 xls 的主体方法是 saveData (下面的saveData2DB方法是保存到sqlite数据库):
def saveData(datalist,savepath):
print("save.......")
book = xlwt.Workbook(encoding="utf-8",style_compression=0) #创建workbook对象
sheet = book.add_sheet('豆瓣电影Top250', cell_overwrite_ok=True) #创建工作表
col = ("电影详情链接","图片链接","影片中文名","影片外国名","评分","评价数","概况","相关信息")
for i in range(0,8):
sheet.write(0,i,col[i]) #列名
for i in range(0,250):
# print("第%d条" %(i+1)) #输出语句,用来测试
data = datalist[i]
for j in range(0,8):
sheet.write(i+1,j,data[j]) #数据
book.save(savepath) #保存
创建工作表,创列(会在当前目录下创建),
sheet = book.add_sheet('豆瓣电影Top250', cell_overwrite_ok=True) #创建工作表
col = ("电影详情链接","图片链接","影片中文名","影片外国名","评分","评价数","概况","相关信息")
然后把 dataList里的数据一条条存进去就行。
最后运作成功后,会在左侧生成这么一个文件

打开之后看看是不是我们想要的结果
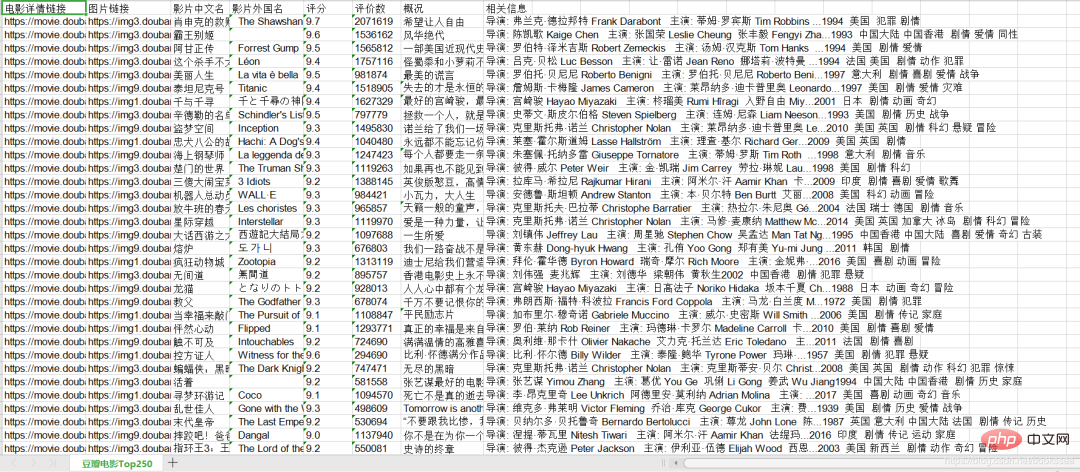
成了,成了!如果我们需要以数据库方式存储,可以先生成 xls 文件,再把 xls 文件导入数据库中,就可以啦!
【相关推荐:Python3视频教程 】
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Comprendre l'utilisation de Tkinter en python en un seul article
- Parlons de la façon de lire le contenu des fichiers mat (données matlab) à l'aide de python
- Que signifient python et jquery ?
- Maîtriser complètement l'interface graphique du fonctionnement automatique de Python PyAutoGUI
- Compilation de points de connaissance des normes de codage Python