
Maison >base de données >SQL >Explication détaillée des fonctions de la fenêtre SQL dans un article
Explication détaillée des fonctions de la fenêtre SQL dans un article

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBavant
- 2022-06-22 15:33:272995parcourir
Cet article vous apporte des connaissances pertinentes sur SQL, qui organise principalement les problèmes liés aux fonctions de fenêtre. Les fonctions de fenêtre SQL fournissent des analyses complexes et des rapports statistiques pour le traitement analytique en ligne (OLAP) et les fonctions de business intelligence (BI), telles que le cumul de produits. statistiques de ventes, classements de catégories, analyse année sur année/mois sur mois, etc. Examinons-les ensemble, j'espère que cela sera utile à tout le monde.

Apprentissage recommandé : "Tutoriel SQL"
Qu'est-ce qu'une fonction de fenêtre ?
Les fonctions de fenêtre SQL fournissent des fonctions complexes d'analyse et de rapport de statistiques pour le traitement analytique en ligne (OLAP) et la business intelligence (BI), telles que produit Statistiques de ventes cumulées, classement des catégories, analyse année sur année/mois sur mois, etc. Ces fonctionnalités sont souvent difficiles à mettre en œuvre avec des fonctions d'agrégation et des opérations de regroupement.
La fonction Window (Window Function) peut analyser un ensemble de données et renvoyer des résultats comme une fonction d'agrégation. La différence entre les deux est que la fonction window n'agrège pas un ensemble de données en un seul résultat, mais analyse plutôt un ensemble de données. data pour chaque ligne de données. Renvoie un résultat. La différence entre les fonctions d'agrégation et les fonctions de fenêtre est illustrée dans la figure ci-dessous.

Prenez la fonction SUM comme exemple pour démontrer la différence entre les deux fonctions. SUM() dans l'instruction suivante est une fonction d'agrégation :
SELECT SUM(salary) AS "所有员工月薪总和" FROM employee
La fonction SUM ci-dessus peut être utilisée comme fonction d'agrégation, ce qui signifie que toutes les données des employés sont résumées dans un résultat. Ainsi, la requête renvoie le salaire mensuel total de tous les employés :
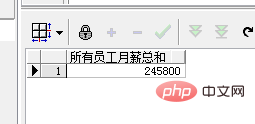
SUM() dans l'instruction suivante est une fonction fenêtre :
SELECT emp_name AS "员工姓名", SUM(salary) OVER () AS "所有员工月薪总和" FROM employee;
Parmi eux, le mot-clé OVER indique que SUM() est une fonction fenêtre. Les parenthèses vides indiquent que toutes les données sont résumées en un seul groupe. Les résultats renvoyés par cette requête sont les suivants :
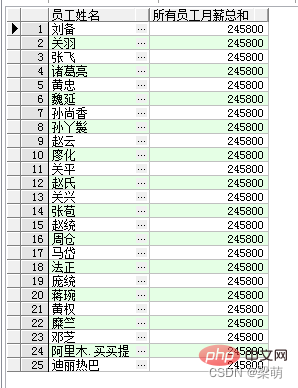
Les résultats de la requête ci-dessus renvoient tous les noms d'employés, et les mêmes résultats récapitulatifs sont renvoyés pour chaque employé via la fonction d'agrégation SUM().
Comme vous pouvez le voir dans l'exemple ci-dessus, la syntaxe de la fonction window est différente de la fonction d'agrégation dans la mesure où elle contient une clause OVER. La clause OVER est utilisée pour spécifier une fenêtre pour l'analyse des données. La définition complète de la fonction window est la suivante :

où window_function est le nom de la fonction window, expression est un objet d'analyse facultatif (nom du champ ou expression), et la clause OVER contient trois options : partition (PARTITION BY), tri (ORDER BY) et taille de la fenêtre (frame_clause).
Conseils : les fonctions d'agrégation résument plusieurs lignes de données dans le même groupe en un seul résultat, tandis que les fonctions de fenêtre conservent toutes les données d'origine. Dans certaines bases de données, les fonctions de fenêtre sont également appelées fonctions de traitement analytique en ligne (OLAP) ou fonctions analytiques.
Composants de la fonction fenêtre
1. Créer des partitions de données
L'option PARTITION BY dans la clause OVER de la fonction fenêtre est utilisée pour définir des partitions et son rôle est similaire à la clause GROUP BY dans l'instruction de requête. Si nous spécifions l'option de partition, la fonction window analysera chaque partition séparément.
Par exemple, l'état suivant comptabilise le salaire mensuel total des employés selon différents départements :
SELECT emp_name AS "员工姓名", salary "月薪", dept_id AS "部门编号", SUM(salary) OVER ( PARTITION BY dept_id ) AS "部门合计" FROM employee;
Parmi eux, l'option PARTITION PAR indique un partitionnement par département. Les résultats renvoyés par la requête sont les suivants :
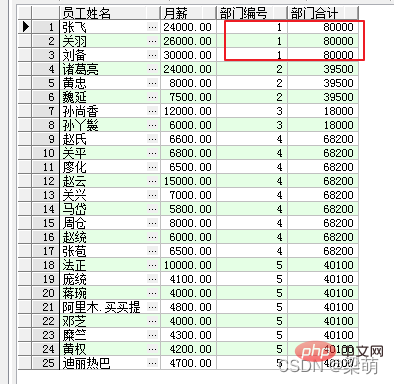
Les trois premières lignes de données dans les résultats de la requête appartiennent au même département, donc leurs champs totaux de département correspondants sont égaux à 80 000 (30 000+26 000+24 000). Les employés des autres départements sont comptés de la même manière.
Conseils : Après avoir spécifié l'option PARTITION BY dans la clause OVER de la fonction fenêtre, nous pouvons obtenir des résultats statistiques de groupe sans utiliser la clause GROUP BY.
Si l'option PARTITION BY n'est pas précisée, cela signifie que toutes les données seront analysées dans leur ensemble.
2. Tri dans la partition
L'option ORDER BY dans la clause OVER de la fonction window est utilisée pour spécifier la méthode de tri des données dans la partition, et sa fonction est similaire à la clause ORDER BY dans l'instruction de requête. .
Les options de tri sont généralement utilisées pour le classement catégoriel des données. Par exemple, l'instruction suivante est utilisée pour analyser le classement salarial mensuel des employés au sein du département :
SELECT emp_name AS "员工姓名", salary "月薪", dept_id AS "部门编号", RANK() OVER ( PARTITION BY dept_id ORDER BY salary DESC ) AS "部门内排名" FROM employee;
Parmi eux, la fonction RANK est utilisée pour calculer le classement des données, l'option PARTITION BY indique le partitionnement par département, et l'option L’option ORDER BY indique le salaire mensuel au sein du département du plus élevé au plus faible. Les résultats renvoyés par la requête sont les suivants :
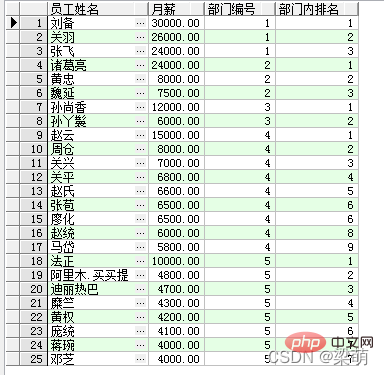
查询结果中的前3行数据属于同一个部门:“刘备”的月薪最高,在部门内排名第1;“关羽”排名第2;“张飞”排名第3。其他部门的员工采用同样的方式进行排名。
提示:窗口函数OVER子句中的ORDER BY选项和查询语句中的ORDER BY子句的使用方法相同。因此,也可以使用NULLS FIRST或者NULLS LAST选项指定空值的排序位置。
3.指定窗口大小
窗口函数OVER子句中的frame_clause选项用于指定一个移动的分析窗口,窗口总是位于分区的范围之内,是分区的一个子集。在指定了分析窗口之后,窗口函数不再基于分区进行分析,而是基于窗口内的数据进行分析。
窗口选项可以用于实现各种复杂的分析功能,例如计算累计到当前日期为止的销售额总和,每个月及其前后各N个月的平均销售额等。
指定窗口大小的具体选项如下:

其中,ROWS表示以数据行为单位计算窗口的偏移量,RANGE表示以数值(例如10天、5km等)为单位计算窗口的偏移量。
frame_start选项用于定义窗口的起始位置,可以指定以下内容之一:
●UNBOUNDED PRECEDING——表示窗口从分区的第一行开始。
●N PRECEDING——表示窗口从当前行之前的第N行开始。
●CURRENT ROW——表示窗口从当前行开始。
frame_end选项用于定义窗口的结束位置,可以指定以下内容之一:
●CURRENT ROW——表示窗口到当前行结束。
●M FOLLOWING——表示窗口到当前行之后的第M行结束。
●UNBOUNDED FOLLOWING——表示窗口到分区的最后一行结束。
下图说明了这些窗口大小选项的含义
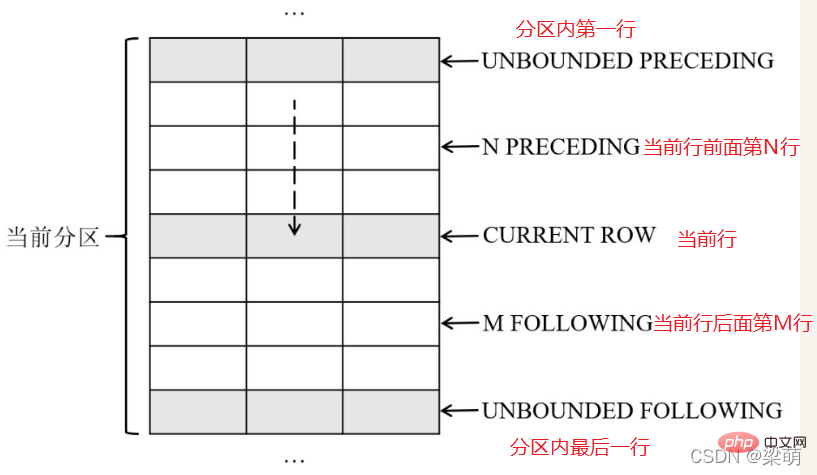
下面语句表示分析窗口从当前分区的第一行开始,直到当前行结束,即对应到图中前面5行记录。
ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW
窗口函数分类
1.聚合窗口函数
许多常见的聚合函数也可以作为窗口函数使用,包括AVG()、SUM()、COUNT()、MAX()以及MIN()等函数。
SQL窗口函数-聚合窗口函数
2.排名窗口函数
排名窗口函数用于对数据进行分组排名,包括ROW_NUMBER()、RANK()、DENSE_RANK()、PERCENT_RANK()、CUME_DIST()以及NTILE()等函数。
SQL窗口函数-排名窗口函数
3.取值窗口函数
取值窗口函数用于返回指定位置上的数据行,包括FIRST_VALUE()、LAST_VALUE()、LAG()、LEAD()、NTH_VALUE()等函数。
SQL窗口函数-取值窗口函数
示例表和脚本
--员工信息表 CREATE TABLE employee ( emp_id NUMBER , emp_name VARCHAR2(50) NOT NULL , sex VARCHAR2(10) NOT NULL , dept_id INTEGER NOT NULL , manager INTEGER , hire_date DATE NOT NULL , job_id INTEGER NOT NULL , salary NUMERIC(8,2) NOT NULL , bonus NUMERIC(8,2) , email VARCHAR2(100) NOT NULL , comments VARCHAR2(500) , create_by VARCHAR2(50) NOT NULL , create_ts TIMESTAMP NOT NULL , update_by VARCHAR2(50) , update_ts TIMESTAMP ) ; COMMENT ON TABLE employee IS '员工信息表'; COMMENT ON COLUMN employee.emp_id IS '员工编号,自增主键'; COMMENT ON COLUMN employee.emp_name IS '员工姓名'; COMMENT ON COLUMN employee.sex IS '性别'; COMMENT ON COLUMN employee.dept_id IS '部门编号'; COMMENT ON COLUMN employee.manager IS '上级经理'; COMMENT ON COLUMN employee.hire_date IS '入职日期'; COMMENT ON COLUMN employee.job_id IS '职位编号'; COMMENT ON COLUMN employee.salary IS '月薪'; COMMENT ON COLUMN employee.bonus IS '年终奖金'; COMMENT ON COLUMN employee.email IS '电子邮箱'; COMMENT ON COLUMN employee.comments IS '备注信息'; COMMENT ON COLUMN employee.create_by IS '创建者'; COMMENT ON COLUMN employee.create_ts IS '创建时间'; COMMENT ON COLUMN employee.update_by IS '修改者'; COMMENT ON COLUMN employee.update_ts IS '修改时间'; INSERT INTO employee(EMP_ID,emp_name, sex, dept_id, manager, hire_date, job_id, salary, bonus, email, comments, create_by, create_ts, update_by, update_ts) VALUES (1,'刘备', '男', 1, NULL, DATE '2000-01-01', 1, 30000, 10000, 'liubei@shuguo.com', NULL, 'Admin', TIMESTAMP '2000-01-01 10:00:00', NULL, NULL); INSERT INTO employee(EMP_ID,emp_name, sex, dept_id, manager, hire_date, job_id, salary, bonus, email, comments, create_by, create_ts, update_by, update_ts) VALUES (2,'关羽', '男', 1, 1, DATE '2000-01-01', 2, 26000, 10000, 'guanyu@shuguo.com', NULL, 'Admin', TIMESTAMP '2000-01-01 10:00:00', NULL, NULL); INSERT INTO employee(EMP_ID,emp_name, sex, dept_id, manager, hire_date, job_id, salary, bonus, email, comments, create_by, create_ts, update_by, update_ts) VALUES (3,'张飞', '男', 1, 1, DATE '2000-01-01', 2, 24000, 10000, 'zhangfei@shuguo.com', NULL, 'Admin', TIMESTAMP '2000-01-01 10:00:00', NULL, NULL); INSERT INTO employee(EMP_ID,emp_name, sex, dept_id, manager, hire_date, job_id, salary, bonus, email, comments, create_by, create_ts, update_by, update_ts) VALUES (4,'诸葛亮', '男', 2, 1, DATE '2006-03-15', 3, 24000, 8000, 'zhugeliang@shuguo.com', NULL, 'Admin', TIMESTAMP '2006-03-15 10:00:00', NULL, NULL); INSERT INTO employee(EMP_ID,emp_name, sex, dept_id, manager, hire_date, job_id, salary, bonus, email, comments, create_by, create_ts, update_by, update_ts) VALUES (5,'黄忠', '男', 2, 4, DATE '2008-10-25', 4, 8000, NULL, 'huangzhong@shuguo.com', NULL, 'Admin', TIMESTAMP '2008-10-25 10:00:00', NULL, NULL); INSERT INTO employee(EMP_ID,emp_name, sex, dept_id, manager, hire_date, job_id, salary, bonus, email, comments, create_by, create_ts, update_by, update_ts) VALUES (6,'魏延', '男', 2, 4, DATE '2007-04-01', 4, 7500, NULL, 'weiyan@shuguo.com', NULL, 'Admin', TIMESTAMP '2007-04-01 10:00:00', NULL, NULL); INSERT INTO employee(EMP_ID,emp_name, sex, dept_id, manager, hire_date, job_id, salary, bonus, email, comments, create_by, create_ts, update_by, update_ts) VALUES (7,'孙尚香', '女', 3, 1, DATE '2002-08-08', 5, 12000, 5000, 'sunshangxiang@shuguo.com', NULL, 'Admin', TIMESTAMP '2002-08-08 10:00:00', NULL, NULL); INSERT INTO employee(EMP_ID,emp_name, sex, dept_id, manager, hire_date, job_id, salary, bonus, email, comments, create_by, create_ts, update_by, update_ts) VALUES (8,'孙丫鬟', '女', 3, 7, DATE '2002-08-08', 6, 6000, NULL, 'sunyahuan@shuguo.com', NULL, 'Admin', TIMESTAMP '2002-08-08 10:00:00', NULL, NULL); INSERT INTO employee(EMP_ID,emp_name, sex, dept_id, manager, hire_date, job_id, salary, bonus, email, comments, create_by, create_ts, update_by, update_ts) VALUES (9,'赵云', '男', 4, 1, DATE '2005-12-19', 7, 15000, 6000, 'zhaoyun@shuguo.com', NULL, 'Admin', TIMESTAMP '2005-12-19 10:00:00', 'Admin', TIMESTAMP '2006-12-31 10:00:00'); INSERT INTO employee(EMP_ID,emp_name, sex, dept_id, manager, hire_date, job_id, salary, bonus, email, comments, create_by, create_ts, update_by, update_ts) VALUES (10,'廖化', '男', 4, 9, DATE '2009-02-17', 8, 6500, NULL, 'liaohua@shuguo.com', NULL, 'Admin', TIMESTAMP '2009-02-17 10:00:00', NULL, NULL); INSERT INTO employee(EMP_ID,emp_name, sex, dept_id, manager, hire_date, job_id, salary, bonus, email, comments, create_by, create_ts, update_by, update_ts) VALUES (11,'关平', '男', 4, 9, DATE '2011-07-24', 8, 6800, NULL, 'guanping@shuguo.com', NULL, 'Admin', TIMESTAMP '2011-07-24 10:00:00', NULL, NULL); INSERT INTO employee(EMP_ID,emp_name, sex, dept_id, manager, hire_date, job_id, salary, bonus, email, comments, create_by, create_ts, update_by, update_ts) VALUES (12,'赵氏', '女', 4, 9, DATE '2011-11-10', 8, 6600, NULL, 'zhaoshi@shuguo.com', NULL, 'Admin', TIMESTAMP '2011-11-10 10:00:00', NULL, NULL); INSERT INTO employee(EMP_ID,emp_name, sex, dept_id, manager, hire_date, job_id, salary, bonus, email, comments, create_by, create_ts, update_by, update_ts) VALUES (13,'关兴', '男', 4, 9, DATE '2011-07-30', 8, 7000, NULL, 'guanxing@shuguo.com', NULL, 'Admin', TIMESTAMP '2011-07-30 10:00:00', NULL, NULL); INSERT INTO employee(EMP_ID,emp_name, sex, dept_id, manager, hire_date, job_id, salary, bonus, email, comments, create_by, create_ts, update_by, update_ts) VALUES (14,'张苞', '男', 4, 9, DATE '2012-05-31', 8, 6500, NULL, 'zhangbao@shuguo.com', NULL, 'Admin', TIMESTAMP '2012-05-31 10:00:00', NULL, NULL); INSERT INTO employee(EMP_ID,emp_name, sex, dept_id, manager, hire_date, job_id, salary, bonus, email, comments, create_by, create_ts, update_by, update_ts) VALUES (15,'赵统', '男', 4, 9, DATE '2012-05-03', 8, 6000, NULL, 'zhaotong@shuguo.com', NULL, 'Admin', TIMESTAMP '2012-05-03 10:00:00', NULL, NULL); INSERT INTO employee(EMP_ID,emp_name, sex, dept_id, manager, hire_date, job_id, salary, bonus, email, comments, create_by, create_ts, update_by, update_ts) VALUES (16,'周仓', '男', 4, 9, DATE '2010-02-20', 8, 8000, NULL, 'zhoucang@shuguo.com', NULL, 'Admin', TIMESTAMP '2010-02-20 10:00:00', NULL, NULL); INSERT INTO employee(EMP_ID,emp_name, sex, dept_id, manager, hire_date, job_id, salary, bonus, email, comments, create_by, create_ts, update_by, update_ts) VALUES (17,'马岱', '男', 4, 9, DATE '2014-09-16', 8, 5800, NULL, 'madai@shuguo.com', NULL, 'Admin', TIMESTAMP '2014-09-16 10:00:00', NULL, NULL); INSERT INTO employee(EMP_ID,emp_name, sex, dept_id, manager, hire_date, job_id, salary, bonus, email, comments, create_by, create_ts, update_by, update_ts) VALUES (18,'法正', '男', 5, 2, DATE '2017-04-09', 9, 10000, 5000, 'fazheng@shuguo.com', NULL, 'Admin', TIMESTAMP '2017-04-09 10:00:00', NULL, NULL); INSERT INTO employee(EMP_ID,emp_name, sex, dept_id, manager, hire_date, job_id, salary, bonus, email, comments, create_by, create_ts, update_by, update_ts) VALUES (19,'庞统', '男', 5, 18, DATE '2017-06-06', 10, 4100, 2000, 'pangtong@shuguo.com', NULL, 'Admin', TIMESTAMP '2017-06-06 10:00:00', NULL, NULL); INSERT INTO employee(EMP_ID,emp_name, sex, dept_id, manager, hire_date, job_id, salary, bonus, email, comments, create_by, create_ts, update_by, update_ts) VALUES (20,'蒋琬', '男', 5, 18, DATE '2018-01-28', 10, 4000, 1500, 'jiangwan@shuguo.com', NULL, 'Admin', TIMESTAMP '2018-01-28 10:00:00', NULL, NULL); INSERT INTO employee(EMP_ID,emp_name, sex, dept_id, manager, hire_date, job_id, salary, bonus, email, comments, create_by, create_ts, update_by, update_ts) VALUES (21,'黄权', '男', 5, 18, DATE '2018-03-14', 10, 4200, NULL, 'huangquan@shuguo.com', NULL, 'Admin', TIMESTAMP '2018-03-14 10:00:00', NULL, NULL); INSERT INTO employee(EMP_ID,emp_name, sex, dept_id, manager, hire_date, job_id, salary, bonus, email, comments, create_by, create_ts, update_by, update_ts) VALUES (22,'糜竺', '男', 5, 18, DATE '2018-03-27', 10, 4300, NULL, 'mizhu@shuguo.com', NULL, 'Admin', TIMESTAMP '2018-03-27 10:00:00', NULL, NULL); INSERT INTO employee(EMP_ID,emp_name, sex, dept_id, manager, hire_date, job_id, salary, bonus, email, comments, create_by, create_ts, update_by, update_ts) VALUES (23,'邓芝', '男', 5, 18, DATE '2018-11-11', 10, 4000, NULL, 'dengzhi@shuguo.com', NULL, 'Admin', TIMESTAMP '2018-11-11 10:00:00', NULL, NULL); INSERT INTO employee(EMP_ID,emp_name, sex, dept_id, manager, hire_date, job_id, salary, bonus, email, comments, create_by, create_ts, update_by, update_ts) VALUES (24,'简雍', '男', 5, 18, DATE '2019-05-11', 10, 4800, NULL, 'jianyong@shuguo.com', NULL, 'Admin', TIMESTAMP '2019-05-11 10:00:00', NULL, NULL); INSERT INTO employee(EMP_ID,emp_name, sex, dept_id, manager, hire_date, job_id, salary, bonus, email, comments, create_by, create_ts, update_by, update_ts) VALUES (25,'孙乾', '男', 5, 18, DATE '2018-10-09', 10, 4700, NULL, 'sunqian@shuguo.com', NULL, 'Admin', TIMESTAMP '2018-10-09 10:00:00', NULL, NULL);
推荐学习:《SQL教程》
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!