
Maison >Java >javaDidacticiel >Points de connaissances en programmation simultanée pour l'apprentissage des threads Java
Points de connaissances en programmation simultanée pour l'apprentissage des threads Java

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBavant
- 2022-06-22 12:14:281625parcourir
Cet article vous apporte des connaissances pertinentes sur java, qui organise principalement les problèmes liés à la programmation simultanée, y compris le modèle de mémoire Java, l'explication détaillée de volatile et le principe d'implémentation de synchronisé, etc. ça aide tout le monde.

Étude recommandée : "Tutoriel vidéo Java"
1 Les bases de JMM - principes informatiques
Le modèle de mémoire Java est le modèle de mémoire Java, ou JMM en abrégé. JMM définit le fonctionnement de la machine virtuelle Java (JVM) dans la mémoire de l'ordinateur (RAM). JVM est l'intégralité du modèle virtuel de l'ordinateur, JMM est donc affilié à JVM. La version Java1.5 l'a refactorisé et le Java actuel utilise toujours la version Java1.5. Les problèmes rencontrés par Jmm sont similaires à ceux rencontrés dans les ordinateurs modernes.
Problèmes de concurrence sur les ordinateurs physiques. Les problèmes de concurrence rencontrés par les machines physiques présentent de nombreuses similitudes avec les situations dans les machines virtuelles. Le schéma de gestion de la concurrence des machines physiques a également une importance de référence considérable pour la mise en œuvre de machines virtuelles. D D'après le "Rapport de Jeff Dean dans le GOOGLE Plot de Google", nous pouvons voir que
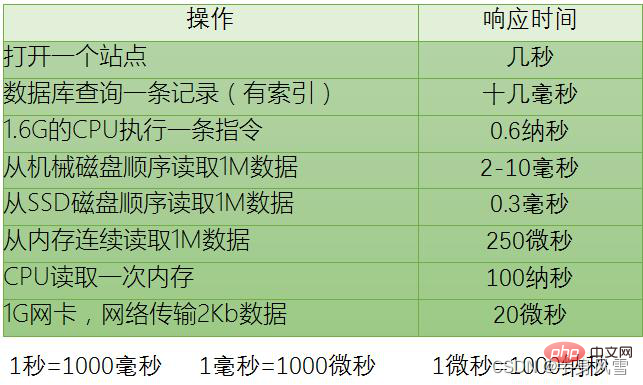
Les cas suivants sont uniquement à titre d'illustration et ne représentent pas la situation réelle.Si 1 M de données int sont lues dans la mémoire et accumulées par le CPU, combien de temps cela prendra-t-il ?
Faites un calcul simple. Pour 1 M de données, le type int en Java est de 32 bits et 4 octets. Il y a un total de 1024*1024/4 = 262144 entiers. Le temps de calcul du CPU est : 262144
0,6 = 157286 nanosecondes. Nous savons qu'il faut 250 000 nanosecondes pour lire 1 million de données de la mémoire. Bien qu'il y ait un écart entre les deux (bien sûr, cet écart n'est pas petit, 100 000 nanosecondes suffisent au processeur pour exécuter près de 200 000 instructions), mais c'est le cas. toujours du même ordre de grandeur. Cependant, sans aucun mécanisme de mise en cache, cela signifie que chaque nombre doit être lu de la mémoire. Dans ce cas, il faut 100 nanosecondes au processeur pour lire la mémoire une fois, et 262 144 entiers sont lus de la mémoire vers le processeur plus le nombre entier. temps de calcul. Cela prend 262144100+250000 = 26 464 400 nanosecondes, ce qui est une différence d'ordre de grandeur.
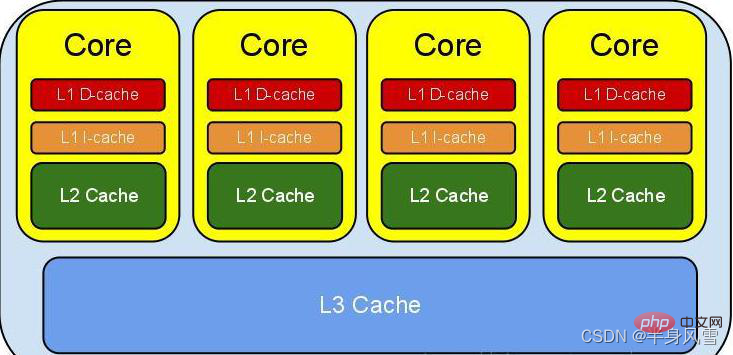
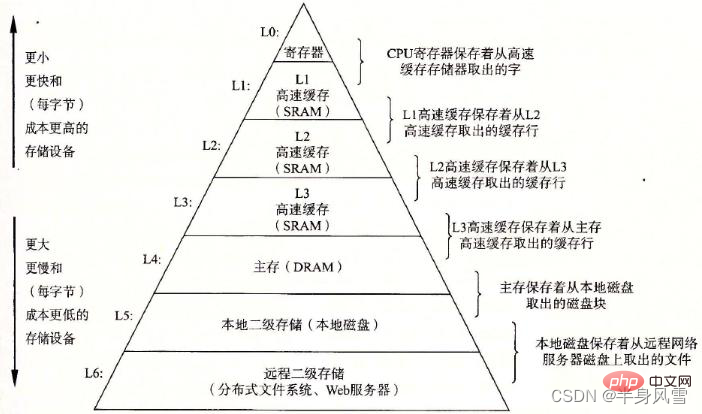
2. Java Memory Model (JMM)
D'un point de vue abstrait, JMM définit la relation abstraite entre les threads et la mémoire principale : les variables partagées entre les threads sont stockées dans la mémoire principale (Main Memory), et chaque thread a un privé. la mémoire locale (Local Memory), qui stocke une copie de la variable partagée que le thread peut lire/écrire. La mémoire locale est un concept abstrait de JMM et n'existe pas vraiment. Il couvre les caches, les tampons d'écriture, les registres et d'autres optimisations du matériel et du compilateur.
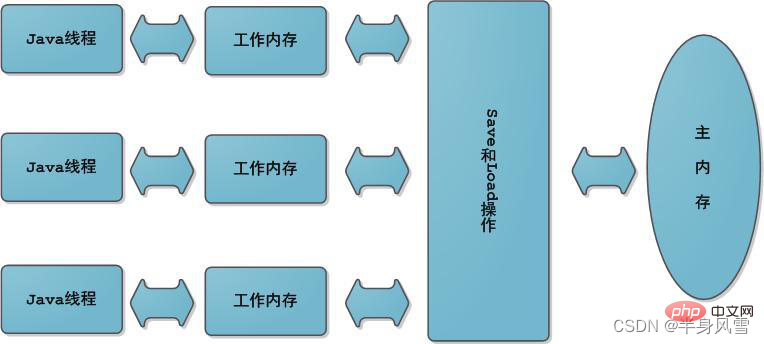
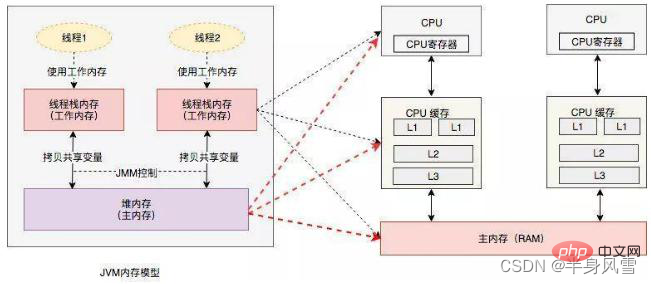
2.1 Visibilité
La visibilité signifie que lorsque plusieurs threads accèdent à la même variable, si un thread modifie la valeur de la variable, les autres threads peuvent immédiatement voir la valeur modifiée.
Puisque toutes les opérations sur les variables par les threads doivent être effectuées dans la mémoire de travail et ne peuvent pas directement lire et écrire des variables dans la mémoire principale, alors pour les variables partagées V, elles sont d'abord dans leur propre mémoire de travail puis synchronisées avec la mémoire principale. Cependant, il ne sera pas vidé dans la mémoire principale à temps, mais il y aura un certain décalage horaire. Évidemment, à ce stade, l'opération du thread A sur la variable V n'est plus visible pour le thread B.
Pour résoudre le problème de visibilité des objets partagés, on peut utiliser le mot-clé volatile ou le verrou.
2.2. Atomicité
Atomicité : Autrement dit, une ou plusieurs opérations sont soit toutes exécutées et le processus d'exécution ne sera interrompu par aucun facteur, soit elles ne sont pas exécutées du tout.
Nous savons tous que les ressources CPU sont allouées en unités de threads et sont appelées en temps partagé. Le système d'exploitation permet à un processus de s'exécuter pendant une courte période de temps, par exemple 50 millisecondes. Après 50 millisecondes, le système d'exploitation. resélectionnera l'exécution d'un processus (nous l'appelons "changement de tâche"), ces 50 millisecondes sont appelées la "tranche de temps". La plupart des tâches sont commutées une fois la période écoulée terminée.
Alors pourquoi le changement de thread provoque-t-il des bugs ? Étant donné que le système d'exploitation effectue un changement de tâche, cela peut se produire après l'exécution d'une instruction CPU ! Notez qu'il s'agit d'une instruction CPU, d'une instruction CPU, d'une instruction CPU, et non d'une instruction dans un langage de haut niveau. Par exemple, count++ n'est qu'une phrase en Java, mais dans les langages de haut niveau, une instruction nécessite souvent plusieurs instructions CPU pour être exécutée. En fait, count++ contient au moins trois instructions CPU ! 那么线程切换为什么会带来 bug 呢?因为操作系统做任务切换,可以发生在任何一条 CPU 指令执行完!注意,是 CPU 指令,CPU 指令,CPU 指令,而不是高级语言里的一条语句。比如 count++,在 java 里就是一句话,但高级语言里一条语句往往需要多条 CPU 指令完成。其实 count++至少包含了三个 CPU 指令!
三、volatile 详解
3.1、volatile 特性
可以把对 volatile 变量的单个读/写,看成是使用同一个锁对这些单个读/写
Vous pouvez considérer une seule3.1. Fonctionnalités volatiles
lecture/écriture d'une variable volatile comme utilisant le même verrou pour lire/écrire ces codes simples> L'opération est synchronisé
public class Volati {
// 使用volatile 声明一个64位的long型变量
volatile long i = 0L;// 单个volatile 变量的读
public long getI() {
return i;
}// 单个volatile 变量的写
public void setI(long i) {
this.i = i;
}// 复合(多个)volatile 变量的 读/写
public void iCount(){
i ++;
}}
- peut être vu comme le code suivant :
-
public class VolaLikeSyn { // 使用 long 型变量 long i = 0L; public synchronized long getI() { return i; }// 对单个的普通变量的读用同一个锁同步 public synchronized void setI(long i) { this.i = i; }// 普通方法调用 public void iCount(){ long temp = getI(); // 调用已同步的读方法 temp = temp + 1L; // 普通写操作 setI(temp); // 调用已同步的写方法 }}La variable volatile elle-même a donc les caractéristiques suivantes : - Visibilité : La lecture d'une variable volatile peut toujours être vue L'écriture finale (par n'importe quel thread ) à cette variable volatile.
: La lecture/écriture d'une variable volatile unique est atomique, mais les opérations composées comme volatile++ ne sont pas atomiques.
- Bien que volatile puisse garantir que les variables sont vidées dans la mémoire principale à temps après l'exécution, pour count++, une situation non atomique et multi-instructions, en raison du changement de thread, le thread A vient de charger count=0 dans la mémoire de travail , et le thread B vient de charger count=0 dans la mémoire de travail. Cela fera que les résultats d'exécution des threads A et B seront tous deux 1, et les deux seront écrits dans la mémoire principale. la mémoire est toujours 1, pas 2
- 3.2. Le principe d'implémentation de la clé volatile
- volatile Les variables modifiées par mot auront un préfixe "lock:".
Préfixe de verrouillage, Lock n'est pas une barrière de mémoire, mais il peut remplir des fonctions similaires à une barrière de mémoire. Lock verrouille le bus et le cache du CPU, ce qui peut être compris comme un verrou au niveau des instructions du CPU.
Dans le même temps, cette instruction écrira les données de la ligne de cache actuelle du processeur directement dans la mémoire système, et cette réécriture dans l'opération de mémoire invalidera les données mises en cache à cette adresse dans d'autres processeurs.
- Si le numéro d'entrée du moniteur est 0, alors le thread entre dans le moniteur, puis définit le numéro d'entrée sur 1, et le thread devient propriétaire du moniteur.
- Si le fil occupe déjà le moniteur et vient juste de rentrer, le nombre d'entrées dans le moniteur est augmenté de 1.
- Si d'autres threads ont déjà occupé le moniteur, le thread entrera dans l'état de blocage jusqu'à ce que le numéro d'entrée du moniteur soit 0, puis tentera à nouveau d'obtenir la propriété du moniteur. Pour la méthode de synchronisation, à en juger par les résultats de décompilation de la méthode de synchronisation, la synchronisation de la méthode n'est pas implémentée via les instructions Monitorenter et MonitorExit. Par rapport à la méthode ordinaire, le pool de constantes a un identifiant ACC_SYNCHRONIZED supplémentaire.
La JVM implémente la synchronisation des méthodes basée sur cet identifiant : lorsque la méthode est appelée, l'instruction appelante vérifiera si l'indicateur d'accès ACC_SYNCHRONIZED de la méthode est défini. S'il est défini, le thread d'exécution obtiendra d'abord le moniteur, puis s'exécutera. une fois l'acquisition réussie. Corps de la méthode, le moniteur est libéré une fois la méthode exécutée. Pendant l’exécution de la méthode, aucun autre thread ne peut à nouveau obtenir le même objet moniteur.
Le verrou utilisé par synchronisé est stocké dans l'en-tête de l'objet Java. L'en-tête de l'objet Java se compose de deux parties : le mot de marque et le pointeur de classe :
- Le mot de marque stocke l'état de synchronisation, l'identification, le code de hachage, l'état du GC, etc.
- klass pointer stocke le pointeur de type de l'objet, qui pointe vers ses métadonnées de classe. De plus, pour les tableaux, il existe également des données enregistrant la longueur du tableau.

Les informations de verrouillage existent dans le mot de marque de l'objet. Les données par défaut dans MarkWord sont destinées à stocker le HashCode et d'autres informations de l'objet.

Mais cela changera à mesure que le fonctionnement de l'objet change. Différents statuts de verrouillage correspondent à différentes méthodes de stockage des enregistrements
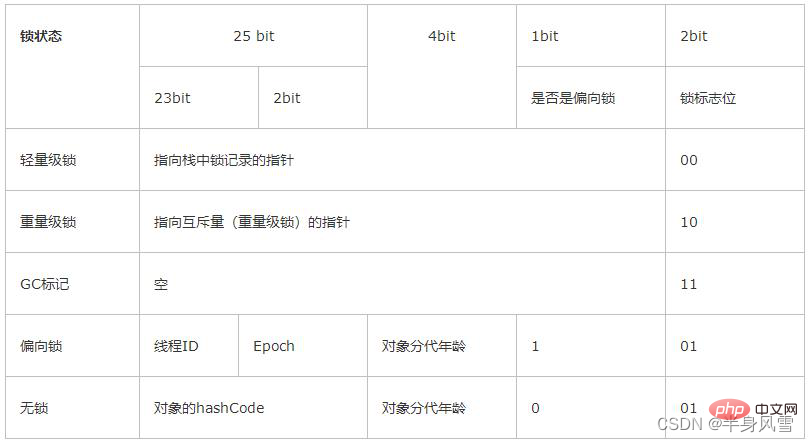
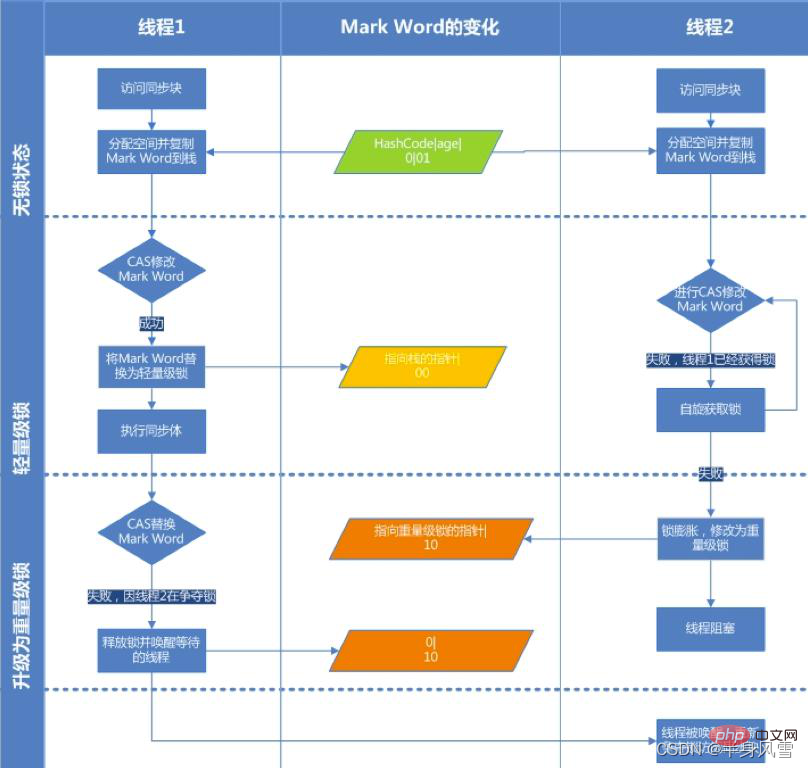
4.1. En comparant l'image ci-dessus, nous avons constaté qu'il y en a un total de. verrous Il existe quatre états,
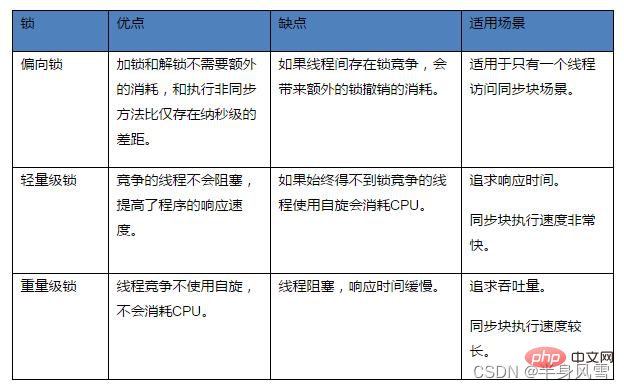
état sans verrouillage, état de verrouillage biaisé, état de verrouillage léger et état de verrouillage lourd, qui augmenteront progressivement avec la situation de concurrence. Les verrous peuvent être améliorés mais pas dégradés afin d'améliorer l'efficacité de l'acquisition et du déverrouillage des verrous. 4.2. Verrou biaisé
Présentation de l'arrière-plan : Dans la plupart des cas, non seulement les verrous n'ont pas de concurrence multi-thread, mais sont toujours acquis plusieurs fois par le même thread afin de rendre l'acquisition des verrous moins coûteuse. , des verrous biaisés sont introduits. Réduisez les opérations CAS inutiles.顾Le verrou biaisé, comme son nom l'indique, sera biaisé lors de la première visite du thread. Si le verrou synchrone n'est accessible que par un thread pendant l'opération, il n'y a pas de litige multithread, alors le thread n'a pas besoin de se déclencher. synchronisation, réduire la réduction, réduire Certaines opérations CAS de verrouillage/déverrouillage (telles que certaines opérations CAS de files d'attente), dans ce cas, un verrou de biais sera ajouté au thread. Si d'autres threads préemptent le verrou pendant le fonctionnement, le thread détenant le verrou biaisé sera suspendu et la JVM éliminera le verrou biaisé et restaurera le verrou à un verrou léger standard. Il améliore encore les performances d'exécution du programme en éliminant les primitives de synchronisation lorsqu'il n'y a pas de concurrence pour les ressources.
Regardez l'image ci-dessous pour comprendre le processus d'acquisition du verrouillage de biais :
Étape 1. Visitez Mark Word pour voir si l'indicateur de verrouillage de biais est défini sur 1 et si l'indicateur de verrouillage est 01, confirmez que il est dans un état biaisé. 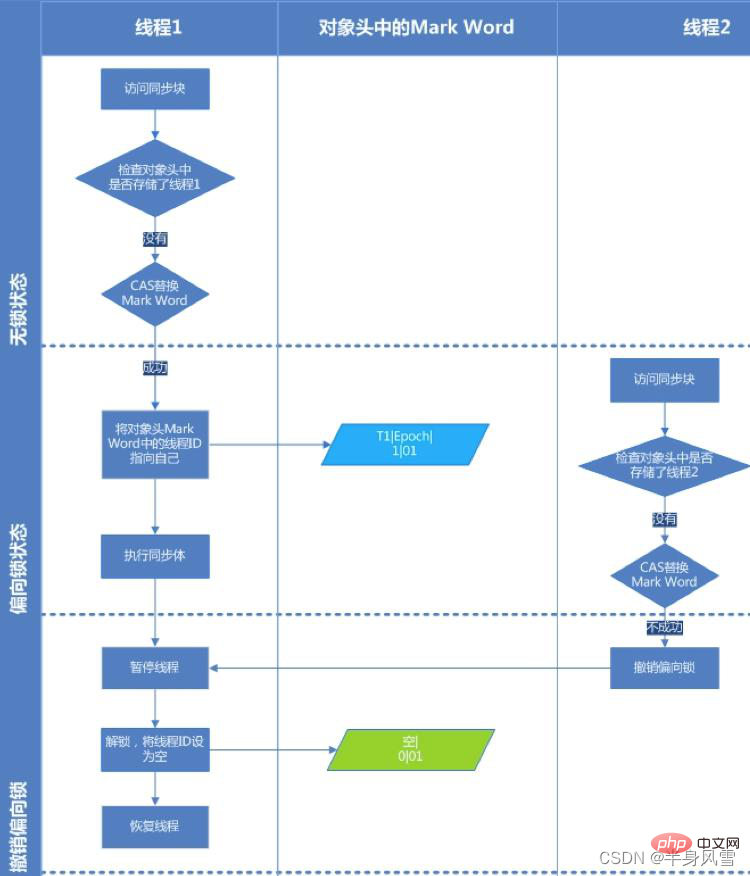 Étape 2. S'il est dans l'état biaisable, testez si l'ID du thread pointe vers le thread actuel. Si tel est le cas, passez à l'étape 5, sinon passez à l'étape 3.
Étape 2. S'il est dans l'état biaisable, testez si l'ID du thread pointe vers le thread actuel. Si tel est le cas, passez à l'étape 5, sinon passez à l'étape 3.
Étape 4. Si CAS ne parvient pas à acquérir le verrou de biais, cela signifie qu'il y a de la concurrence. Lorsqu'il atteint le point de sécurité global (safepoint), le thread qui obtient le verrou de biais est suspendu, le verrou de biais est mis à niveau vers un verrou léger, puis le thread bloqué au point de sécurité continue d'exécuter le code de synchronisation. (La révocation du verrouillage de biais entraînera l'arrêt du mot)
Étape 5. Exécutez le code de synchronisation.
Déverrouillage du biais :
L'annulation du blocage du biais est mentionnée dans la quatrième étape ci-dessus. Ce n'est que lorsque d'autres fils tentent de rivaliser pour le blocage de biais que le fil qui maintient le blocage de biais libère le blocage de biais et que le fil ne libère pas activement le blocage de biais. Pour annuler le verrou biaisé, vous devez attendre le point de sécurité global (aucun bytecode n'est en cours d'exécution à ce stade). Il mettra d'abord en pause le thread qui possède le verrou biaisé, déterminera si l'objet de verrouillage est dans un état verrouillé. , puis restaurez le verrouillage biaisé à l'état précédent après avoir annulé le verrouillage biaisé. L'état du verrouillage (le bit d'indicateur est "01") ou du verrouillage léger (le bit d'indicateur est "00").
Scénarios applicables aux verrous biaisés :
Il n'y a toujours qu'un seul thread exécutant le bloc de synchronisation. Avant de terminer l'exécution et de libérer le verrou, il n'y a pas d'autre thread pour exécuter le bloc de synchronisation. Il est utilisé lorsqu'il n'y en a pas. concurrence pour le verrou. Une fois qu'il y a La concurrence est mise à niveau vers un verrou léger, le verrou biaisé doit être révoqué, ce qui entraînera l'arrêt du fonctionnement du mot ; locks, le verrouillage biaisé effectuera de nombreuses opérations supplémentaires, en particulier lors de l'annulation du verrouillage de biais, cela entraînera l'entrée dans le point de sécurité, ce qui entraînera stw et entraînera une dégradation des performances. .
jvm Activer/désactiver le verrouillage des biais4.3, verrouillage léger Mis à niveau à partir du verrou de biais, le verrou de biais s'exécute lorsqu'un thread entre dans le bloc de synchronisation. Lorsque le deuxième thread rejoint la contention de verrouillage, le verrou de biais sera mis à niveau vers un verrou léger.Activer le verrouillage des biais : -XX:+UseBiasedLocking -XX:BiasedLockingStartupDelay=0 Désactiver le verrouillage des biais : -XX:-UseBiasedLocking
Verrouillage léger Le processus de verrouillage :
- Lorsque le code entre dans le bloc de synchronisation, si l'état de verrouillage de l'objet de synchronisation est déverrouillé et que le biais n'est pas autorisé (l'indicateur de verrouillage est "01", s'il s'agit d'un verrou biaisé est "0"), la machine virtuelle va d'abord créez un espace appelé Lock Record dans le cadre de pile du thread actuel, qui est utilisé pour stocker une copie du Mark Word actuel de l'objet de verrouillage, qui est officiellement appelé Displaced Mark Word.
- Copiez le mot Mark dans l'en-tête de l'objet dans l'enregistrement de verrouillage.
- Une fois la copie réussie, la machine virtuelle utilisera l'opération CAS pour essayer de mettre à jour le mot de marque de l'objet vers un pointeur vers l'enregistrement de verrouillage et pointera le pointeur du propriétaire dans l'enregistrement de verrouillage vers le mot de marque de l'objet. Si la mise à jour réussit, passez à l'étape 4, sinon passez à l'étape 5.
- Si cette opération de mise à jour réussit, alors ce thread possède le verrou de l'objet, et l'indicateur de verrouillage de l'objet Mark Word est défini sur "00", ce qui signifie que cet objet est dans un état de verrouillage léger
- Si cela opération de mise à jour En cas d'échec, la machine virtuelle vérifiera d'abord si le mot de marque de l'objet pointe vers le cadre de pile du thread actuel. Si tel est le cas, cela signifie que le thread actuel possède déjà le verrou de cet objet, et alors il peut. entrez directement dans le bloc de synchronisation pour continuer l'exécution. Sinon, cela signifie que plusieurs threads sont en compétition pour le verrou, puis il tournera et attendra le verrou, et l'objet verrou n'a pas été obtenu après un certain nombre de fois. Le pointeur de thread lourd pointe vers le thread concurrent, et le thread concurrent se bloquera également, en attendant que le thread léger libère le verrou et le réveille. La valeur d'état de l'indicateur de verrouillage passe à "10". Ce qui est stocké dans le Mark Word est le pointeur vers le verrou lourd (mutex), et les threads suivants en attente du verrou entreront également dans l'état de blocage.
Mais la rotation du thread consomme le processeur. Pour le dire franchement, cela signifie que le processeur ne peut pas toujours occuper le processeur pour tourner et effectuer un travail inutile, vous devez donc définir un temps d'attente maximum pour la rotation.
Si le temps d'exécution du thread détenant le verrou dépasse le temps d'attente maximum de rotation et que le verrou n'est pas libéré, les autres threads en compétition pour le verrou ne pourront toujours pas obtenir le verrou dans le temps d'attente maximum. le thread concurrent s'arrêtera de lui-même. Le spin entre dans l'état de blocage.
Mais si la concurrence pour le verrou est féroce, ou si le fil qui maintient le verrou doit occuper le verrou pendant une longue période pour exécuter le bloc de synchronisation, il n'est pas approprié d'utiliser le verrou tournant à ce moment-là, car le verrou tournant est toujours occupe le processeur pour un travail inutile avant d'acquérir le verrou. Ce n'est pas un si gros problème. Le coût de la rotation des threads est supérieur au coût du blocage et de la suspension des opérations. Les autres threads qui ont besoin de cup ne peuvent pas obtenir le processeur, ce qui entraîne un gaspillage. de CPU.
4.3.3. Seuil de temps de spin lock
Le but du spin lock est d'occuper les ressources CPU sans les libérer, et d'attendre que le verrou soit acquis pour le traiter immédiatement. Mais comment choisir le temps d’exécution du spin ? Si le temps d'exécution du spin est trop long, un grand nombre de threads seront dans l'état de spin et occuperont les ressources du processeur, ce qui affectera les performances de l'ensemble du système. Le nombre de tours est donc important.次 Choix du nombre de tours par JVM, JDK1.5 par défaut à 10 fois, introduction des verrous de rotation adaptatifs dans la version 1.6, le verrouillage de rotation adaptatif signifie que le temps de rotation n'est pas fixe, mais à partir de l'heure précédente, l'heure précédente était dans l'heure précédente dans l'heure précédente.Il est déterminé par le temps de rotation du même verrou et le statut du propriétaire du verrou. On considère essentiellement que le moment du changement de contexte d'un thread est le meilleur moment.
Dans JDK1.6, -XX:+UseSpinning active le verrou rotatif ; après JDK1.7, ce paramètre est supprimé et contrôlé par jvm
; 
Tutoriel vidéo Java"
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Javascript a-t-il des structures de données ?
- Un article sur les opérations détaillées sur JavaScript DOM
- En savoir plus sur le mécanisme multithread Java
- Explication détaillée du mappage faible de JavaScript et des connaissances faibles en matière de collection
- Comment comprendre la collection d'ensembles en Java