
Maison >Java >javaDidacticiel >Comment comprendre la collection d'ensembles en Java
Comment comprendre la collection d'ensembles en Java

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBavant
- 2022-06-20 11:31:051967parcourir
Cet article vous apporte des connaissances pertinentes sur java, qui présente principalement des problèmes liés aux collections d'ensembles. Les caractéristiques des collections d'ensembles sont non ordonnées, non répétitives et sans index. J'espère que cela vous sera utile. pour vous. Tout le monde est utile.

Re apprentissage recommandé: "Java Video Tutorial"
set Collection Fonctionnalités:
- OrDorded: La séquence d'accès est incohérente
- no Duplication: la duplication peut être supprimée
- no Index: Là n'est pas une méthode indexée, vous ne pouvez donc pas utiliser le parcours de boucle for ordinaire, ni obtenir des éléments via des index
Définir les fonctionnalités de la classe d'implémentation de collection :
HashSet : Non ordonné, non répétitif, sans index
LinkedHashSet : Ordonné, sans duplication, sans index
TreeSet : Tri, sans duplication, sans index
La fonction de la collection Set est fondamentalement la même que l'API de Collection.
Collection de Hashset
Collection de HashSet:
Set<String> set = new HashSet<>();
set.add("石原里美");
set.add("石原里美");
set.add("工藤静香");
set.add("朱茵");
System.out.println(set);
set.remove("朱茵");
System.out.println(set);
Résultat de sortie:
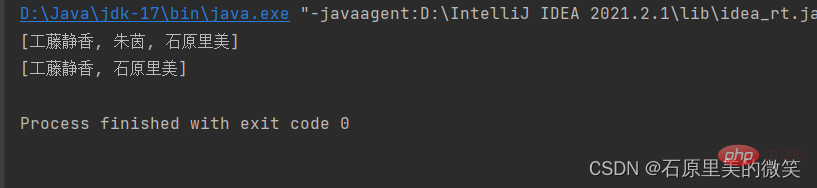
Grâce au code ci-dessus et aux résultats en cours d'exécution, nous pouvons clairement voir que la collection de HashSet est non ordonnée et non répétée;
En combinaison avec l'image ci-dessus, on peut voir que la collection HashSet ne peut pas obtenir de données via l'index de la méthode get(), et lors de la suppression des données dans la collection, les données ne peuvent être supprimées que par suppression directionnelle.
 LinkedHashSet set:
LinkedHashSet set:
Set<String> set = new LinkedHashSet<>();
set.add("石原里美");
set.add("石原里美");
set.add("工藤静香");
set.add("朱茵");
System.out.println(set);
set.remove("朱茵");
System.out.println(set);
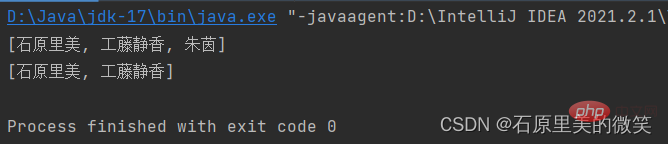
Résultat de sortie:
En comparant le code ci-dessus avec le résultat de sortie, vous pouvez voir la différence entre le désordre et l'ordre. les données entrantes sont perturbées, mais ce dernier stocke toujours les données dans l'ordre des données d'entrée, donc la sortie est dans un état ordonné. Collection TreeSet :
Collection TreeSet :
Set<Integer> set = new TreeSet<>(); set.add(13); set.add(23); set.add(23); set.add(11); System.out.println(set); set.remove(23); System.out.println(set);
Résultat de sortie :
Grâce au code ci-dessus et aux résultats de sortie, nous pouvons comprendre littéralement pourquoi TreeSet est caractérisé par le tri, et les données à stocker sont selon pour trier selon la méthode de tri par défaut de Java.Cependant, si vous stockez des objets personnalisés tels que des objets Personnes à ce moment-là, TreeSet ne peut pas être trié directement et une erreur se produira !
//People类:
public class People{
private String name;
private int age;
private String classroom;
public People(){
}
public People(String name, int age, String classroom) {
this.name = name;
this.age = age;
this.classroom = classroom;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
public String getClassroom() {
return classroom;
}
public void setClassroom(String classroom) {
this.classroom = classroom;
}
@Override
public String toString() {
return "People{" +
"name='" + name + '\'' +
", age=" + age +
", classroom='" + classroom + '\'' +
'}';
}
}
//main方法:
public static void main(String[] args) {
Set<People> p = new TreeSet<>();
p.add(new People("张三",19,"智能"));
p.add(new People("李四",18,"数据库"));
p.add(new People("王五",20,"渗透"));
System.out.println(p);
}Si nous voulons résoudre ce problème, nous devons personnaliser le type de stockage pour la collection TreeSet. Il existe deux façons de résoudre ce problème : La première
consiste à personnaliser la classe pour implémenter l'interface Comparable et remplacer la méthode compareTo. pour spécifier les règles ;L'autre est une collection avec son propre objet comparateur pour la définition des règles.
est une collection avec son propre objet comparateur pour la définition des règles.
- La classe personnalisée implémente l'interface Comparable et réécrit la méthode compareTo pour spécifier les règles de comparaison (le code supplémentaire non pertinent ne sera pas décrit ici, seule la partie importante du code est affichée)
//改变的第一个地方:实现Comparable类 public class People implements Comparable<People> { //改变的第二个地方:重写Comparable类中的compareTo方法 @Override public int compareTo(People o) { return this.age-o.age; } }Résultats de sortie ( selon la comparaison d'âge) :
Si le premier élément est considéré comme supérieur. que le deuxième élément, renvoyez simplement un entier positif
Si vous pensez que le premier élément est inférieur au deuxième élément, renvoyez simplement un entier négatif
Si vous pensez que le premier élément est égal au deuxième élément, renvoyez simplement 0. À ce stade fois, la collection Treeset ne conservera qu'un seul élément, on considère que les deux sont des doublons
🎜🎜🎜Méthode 2 : 🎜L'ensemble est livré avec son propre objet comparateur pour la définition des règles🎜Set<People> p = new TreeSet<>(new Comparator<People>() {
@Override
public int compare(People o1, People o2) {
return o1.getAge()-o2.getAge();
}
});🎜Modifications apportées à la création de l'ensemble. basé sur l'original, et ses critères de comparaison sont similaires à la méthode de définition précédente, relativement La méthode précédente est plus pratique et plus rapide. Ici, nous pouvons également revoir certaines des connaissances acquises précédemment sur les « expressions Lambda » et simplifier le bloc de code. 🎜Set<People> p = new TreeSet<>((o1, o2) -> o1.getAge()-o2.getAge());🎜Si vous n'avez pas étudié les expressions Lambda ou si votre connaissance des expressions Lambda n'est pas claire, vous pouvez lire comment comprendre les expressions lambda en Java - l'explication simplifiée de cet article peut vous être utile. 🎜
Apprentissage recommandé : "Tutoriel vidéo Java"
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!