
Maison >développement back-end >Tutoriel Python >Explication détaillée du protocole http, base essentielle des tests automatisés des interfaces Python
Explication détaillée du protocole http, base essentielle des tests automatisés des interfaces Python

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBavant
- 2022-05-31 11:39:582331parcourir
Cet article vous apporte des connaissances pertinentes sur python, qui introduit principalement les problèmes liés au protocole http dans la base nécessaire aux tests d'automatisation d'interface. Examinons-le ensemble, j'espère qu'il sera utile à tout le monde.

Apprentissage recommandé : Tutoriel vidéo Python
Protocole HTTP et caractéristiques
Si vous comparez le protocole HTTP en tant que personne, lorsque vous souhaitez comprendre cette personne en profondeur, vous comprendrez certainement d'abord la personnalité de l'autre personne les caractéristiques attendent. Alors quelles sont les caractéristiques du protocole HTTP ? En général, il présente les fonctionnalités suivantes :
- 1. La première fonctionnalité :
Le protocole HTTP prend en charge le mode client/serveurcar le protocole HTTP est membre duProtocole TCP et IP ; suites Un membre, comme les autres membres, est utilisé pour la communication entre le client et le serveur ; la façon dont fonctionne lemode client/serveurest que le client envoie une requête au serveur, et le serveur répond Un service qui demande et répond ; toutes lesrequêtes HTTPétablissent une communication à partir du client, et le serveur n'enverra pas de réponse avant de recevoir une demande du clientC'est l'une des caractéristiques de ; le protocole HTTP.HTTP协议支持 客户/服务端 模式;因为 HTTP 协议 是TCP、IP 协议簇的一员,与其他成员一样,用于客户端与服务器之间的通信;而客户/服务器模式的工作方式是由客户端向服务器发出请求,服务器端响应请求,并进行响应的服务;所有的HTTP请求都是从客户端开始建立通信,服务器端在没有接收到任何的客户端请求之前是不会发出响应的;这就是 HTTP协议 的特点之一。
- 2、第二个特点:
简单快速;客户端向服务器请求服务的时候,只需要传入请求的方法和路径;常用的请求方法有GET、HEAD、POST(除了这三种之外,还有其他不那么常用的方法,有兴趣的小伙伴可以在 HTTP协议状态及报文组成 一文进行拓展);由于 HTTP协议 简单,使得 HTTP服务器的程序规模小,因而通信速度很快。
- 3、第三个特点:
灵活;之所以灵活是因为 HTTP 允许传输任意类型的数据对象;传输的类型由Content-Type加以标记内容类型,支持多种内容格式的传输。(兼容性很强)
- 4、第四个特点:无连接;这里的无连接可不是没有连接的意思,而是限制每个连接只处理一个请求。服务器处理完客户端的请求并收到客户端的应答之后,就断开连接。采用如此的设计方式呢,能够节省传输时间。
- 拓展:可能有同学认为一个页面有很多个 HTTP 请求,来回这样连接、断开会效率很低。其实早期这么做的原因是因为产生于互联网,因此服务器需要处理同时面向全世界 数十万、上百万 的网页访问。但是每个客户端(或者说浏览器)与服务器之间交换数据的间歇性特别大,所以 HTTP 的传输是具备突发性与顺时性的,大部分通道实际上会很空闲,无端的占用资源比较浪费。因此呢, HTTP 的设计者有意使用这样的特点将协议设计为
请求的时候建立连接,请求完就释放连接。尽快的将资源释放出来服务给其他的客户端,无论怎样,对于同一个客户端来说,还是每一次只处理一个请求,所以我们也能看出来 HTTP 协议的另外一个优点,它很专一。(*^▽^*)
- 5、最后一个特点:无状态; 无状态的意思就是说
HTTP协议对于事务的处理没有记忆能力;缺少状态就意味着如果后续处理需要前面的信息,则必须要重传,这就很可能会导致每次连接传送的数据量增大。另一方面,在服务器不需要先前的信息时它的响应就比较快。
PS:所以 HTTP 的这些特性是既有优点也有缺点。
- 优点:优点在于解放服务器,每一次请求点到为止不会造成不必要的连接占用。
- 缺点:缺点在于每一次请求都会传输大量的重复内容信息。
- 所以保持 HTTP 连接的两种技术就应运而生了,那就是
cookie与session。
HTTP的请求与响应
现在我们知道 HTTP协议 是一种请求与响应的模式,那么就来一起认识一下 HTTP的请求和响应吧,先从 HTTP协议的请求说起。
HTTP的请求
请求 是发送给接口的数据对象,包括接口的地址(也就是常说的 URL

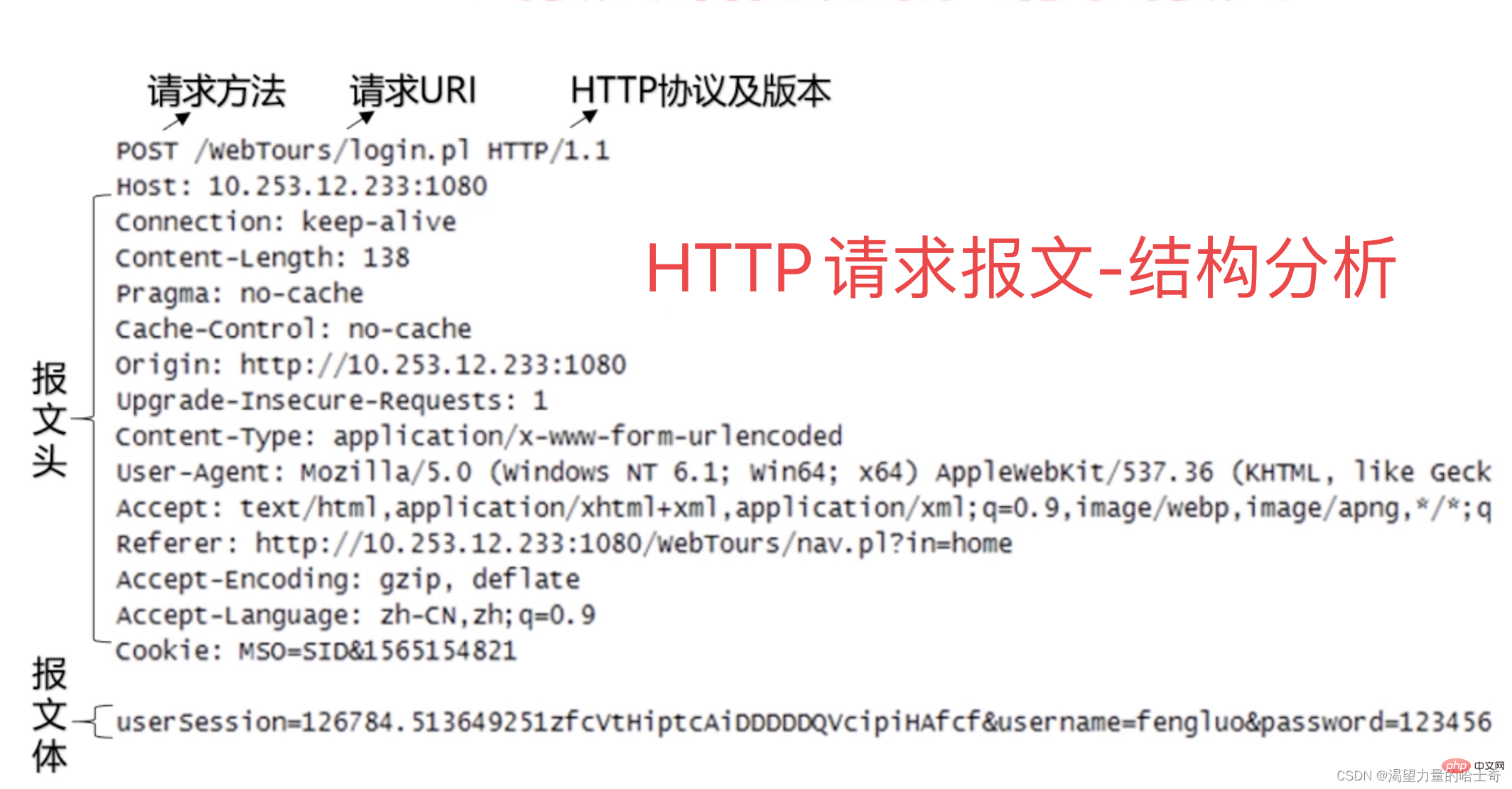
Simple et rapide ; lorsque le client demande un service au serveur, il lui suffit de transmettre la méthode et le chemin de requête couramment utilisés ; sont GET, HEAD, POST (En plus de ces trois, il existe d'autres méthodes moins couramment utilisées. Les amis intéressés peuvent développer l'article sur l'état du protocole HTTP et la composition des messages car le protocole HTTP est simple) ; ce qui rend la taille du programme du serveur HTTP petite, donc la vitesse de communication est très rapide. 🎜🎜🎜3. La troisième fonctionnalité : Flexible ; La raison pour laquelle il est flexible est que HTTP permet la transmission de tout type d'objet de données ; par Content-Type marque le type de contenu et prend en charge la transmission de plusieurs formats de contenu. (Forte compatibilité) 🎜🎜🎜4. La quatrième fonctionnalité : pas de connexion ; sans connexion ne signifie pas ici pas de connexion, mais limite chaque connexion à ne traiter qu'une seule requête. Une fois que le serveur a traité la demande du client et reçu la réponse du client, il se déconnecte. L’adoption d’une telle méthode de conception peut permettre de gagner du temps de transmission. 🎜🎜Expansion : certains étudiants peuvent penser qu'une page contient de nombreuses requêtes HTTP, et que se connecter et se déconnecter comme celui-ci sera très inefficace. En fait, au début, la raison en était que le système provenait d'Internet. Le serveur devait donc gérer simultanément des centaines de milliers, voire des millions de visites de pages Web provenant du monde entier. Cependant, l'échange de données entre chaque client (ou navigateur) et le serveur est très intermittent, de sorte que la transmission HTTP est rapide et en rafale. La plupart des canaux seront en fait inactifs et occupés sans raison, ce qui représente un gaspillage de ressources. Par conséquent, les concepteurs de HTTP ont intentionnellement utilisé cette fonctionnalité pour concevoir le protocole afin d'établir une connexion lorsque est demandé et de libérer la connexion une fois la demande terminée. Libérer des ressources pour servir d'autres clients le plus rapidement possible, quoi qu'il en soit, pour un même client, une seule requête est traitée à la fois, on peut donc également voir un autre avantage du protocole HTTP, C'est. très spécifique. (*^▽^*)🎜🎜🎜5. La dernière fonctionnalité : sans état signifie Protocole HTTP Il n'y a pas de mémoire pour traitement des transactions ; l'absence de statut signifie que si le traitement ultérieur nécessite des informations préalables, celles-ci doivent être retransmises, ce qui est susceptible d'augmenter la quantité de données transmises par connexion. En revanche, le serveur répond plus rapidement lorsqu'il n'a pas besoin d'informations préalables. 🎜🎜PS : Ces fonctionnalités de HTTP présentent donc à la fois des avantages et des inconvénients. 🎜🎜🎜Avantages : L'avantage est de libérer le serveur, et chaque point de requête n'entraînera pas d'occupation inutile de la connexion. 🎜Inconvénient : L'inconvénient est que chaque requête transmettra une grande quantité d'informations de contenu en double. 🎜C'est ainsi que deux technologies permettant de maintenir les connexions HTTP ont vu le jour, à savoir le cookie et la session. 🎜 Requête et réponse HTTP🎜🎜Maintenant, nous savons que le protocole HTTP est un mode de requête et de réponse, apprenons donc les requêtes et réponses HTTP. Commençons par HTTP. Commençons par le. demande d'accord. 🎜Requête HTTP
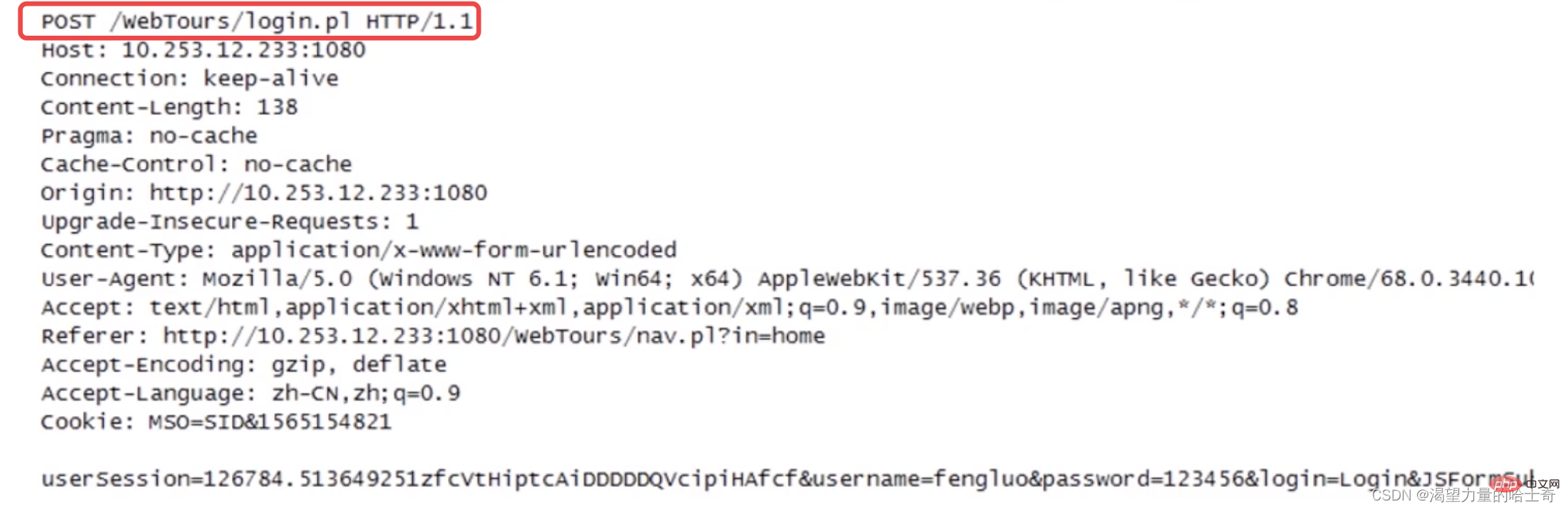
🎜Requête est un objet de données envoyé à l'interface, comprenant l'adresse de l'interface (également appelée URL), l'adresse demandée Méthodes (get, post...), paramètres, en-têtes de requêtes (Headers), Cookies, données, etc... Voir l'image ci-dessous : 🎜🎜🎜🎜🎜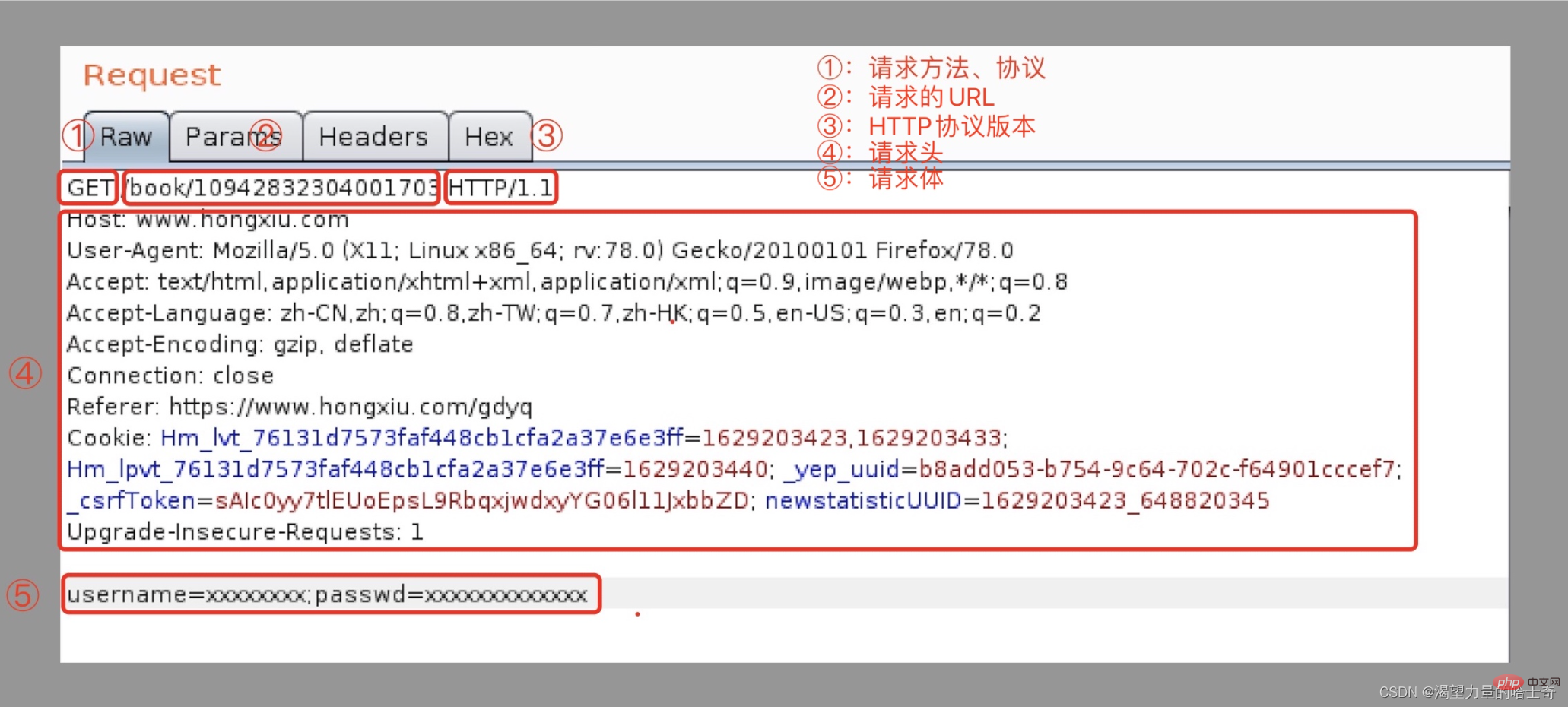
Le contenu du message dans l'image ci-dessus est le message typique de publication et de demande d'obtention du protocole HTTP (Ignorez le corps de la demande du message de demande d'obtention, c'est ce que j'ai inventé.) :忽略get请求报文的请求体,那是我瞎编的 。):
1、第一行就是请求行,包含有请求方法、请求URI、HTTP协议及版本(与第二行的 host属性 相结合形成了完整的 请求URL )
2、中间的部分就是报文头,包含有若干个属性;格式就是图中的
属性名:属性值这样的格式。服务端根据报文头来获取客户端的信息。3、最下面的部分就是报文体,报文体与报文头之间必须有一个空行。在类似图中这样一个
post 请求里面将页面表单里的组件值通过name=admin&passwd=123456这样类似的键值对的格式编码形成这样的格式化串,承载多个请求参数的数据。(不仅仅是报文体可以传输数据,请求的 URL 在get 请求方法的时候也是支持传递参数的。)
在这里可以看出主要的信息是通过请求的方法、url、与报文的主体来进行传递的。这也是 HTTP 的特征之一,简单快速,同时也会发现报文头里也包含有很多种信息,这些做一个了解即可。参考 HTTP协议状态及报文组成 文末的请求头报文。
HTTP的响应
熟悉了 HTTP 的请求,再来看一下响应。见下图:
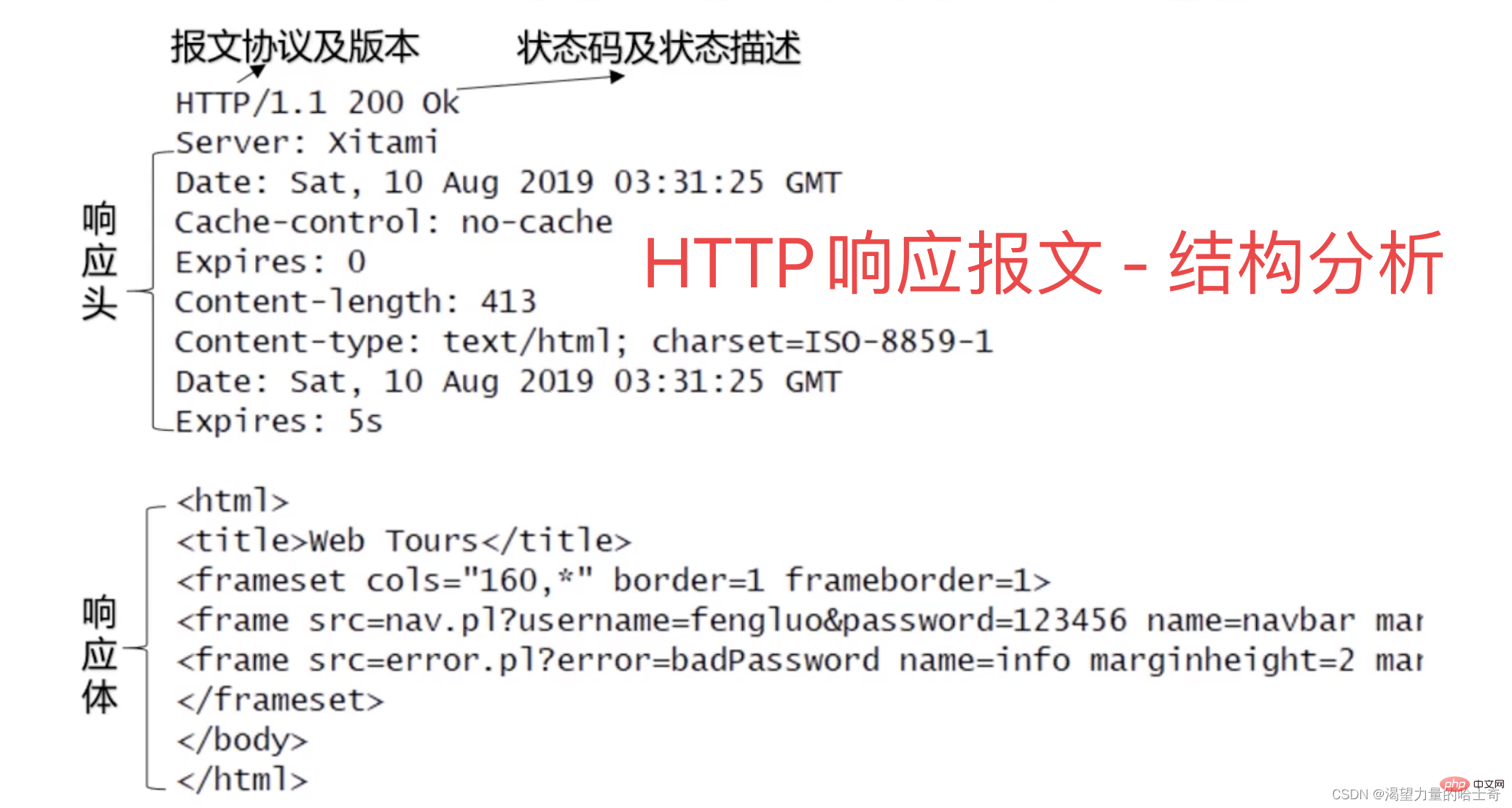
可以从响应报文的样式看出,与请求的报文比较相像,他也分为三个部分:请求行对应响应行、请求头对应响应头、请求体对应着响应体。
- 1、响应行分为两部分:报文协议版本及响应状态码。
- 2、响应头也分为服务器类型、相应数据类型响应时间等多个参数。
- 3、响应体就是我们真正想要的干货,就是请求的最终返回内容。主要针对这个内容进行解析,比如说请求的是一个页面,这个时候请求的返回就是一个比较大的
HTML。
HTTP请求方法剖析
更多内容参考 HTTP协议状态及报文组成 一文的 HTTP请求方法 。
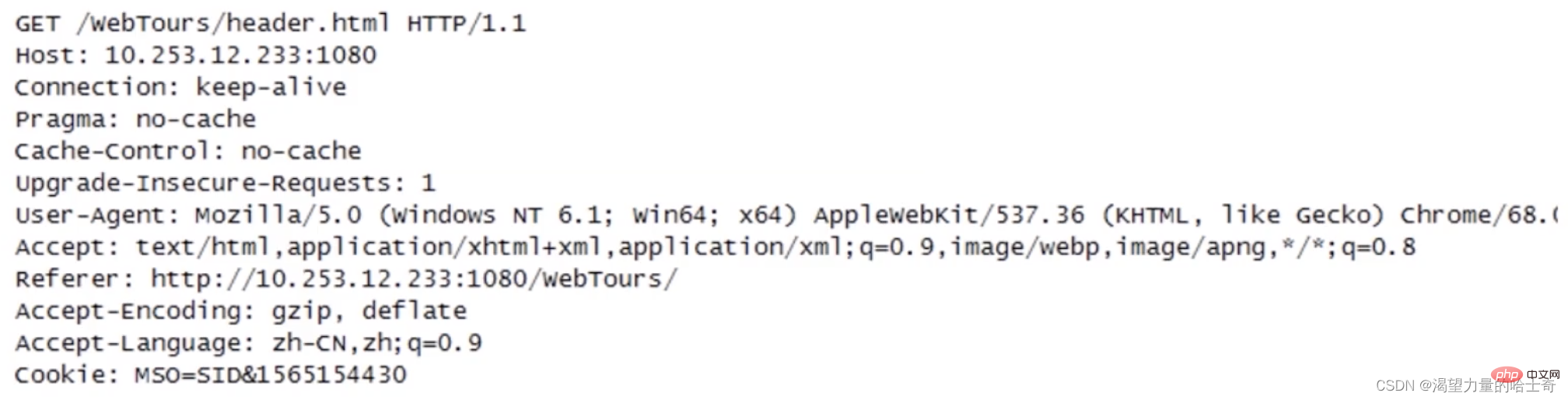
GET 方法
GET方法 用来请求访问已被 URI 识别的资源,指定的资源经服务器端解析后返回响应内容。(见下图)
PSOT 方法
POST方法 与 GET方法 功能类似,一般用来传输实体的主体;主要的目的不是为了获取响应主体的内容,是向 WEB服务器提供表单数据,尤其是大批量的数据 。
POST方法 其实是克服了 GET方法 的一些缺点,通过 POST 请求,数据就不是作为一个 URL 请求的一部分了,而是作为标准数据的格式来传递给 WEB服务器 这也就克服了 GET方法
🎜Vous pouvez voir les principaux points ici Les informations est transmis via la méthode de requête, l'URL et le corps du message. C'est aussi l'une des caractéristiques du HTTP. Il est simple et rapide. En même temps, vous constaterez également que l'en-tête du message contient également de nombreuses informations. Reportez-vous à l'état du protocole HTTP et à la composition du message pour le message d'en-tête de demande à la fin de l'article. 🎜
- 1. La première ligne est la ligne de requête, comprenant la méthode de requête, l'URI de la requête, le protocole HTTP et la version (combinés avec l'attribut host dans la deuxième ligne pour former un URL de demande complète)
2. La partie centrale est l'en-tête du message, qui contient plusieurs attributs ; le format est le
nom de l'attribut : valeur de l'attributdans la figure. Le serveur obtient des informations client sur la base de l'en-tête du message.- 3. La partie inférieure est le corps du message. Il doit y avoir une ligne vide entre le corps du message et l'en-tête du message. Dans une
demande de publicationcomme celle de la figure, les valeurs des composants du formulaire de page sont codées dans un format de paire clé-valeur similaire à celui dename=admin&passwd=123456pour former ce format. Chaîne, transportant les données de plusieurs paramètres de requête. (Non seulement le corps du message peut transmettre des données, mais l'URL demandée prend également en charge la transmission de paramètres lorsque laget request method.)
Réponse HTTP
🎜Maintenant que vous êtes familier avec les requêtes HTTP, examinons la réponse. Voir l'image ci-dessous : 🎜🎜🎜🎜🎜 peut être vu de la réponse Le style du message est similaire à celui du message de requête. Il est également divisé en trois parties : la ligne de requête correspond à la ligne de réponse, l'en-tête de la requête correspond à l'en-tête de la réponse et le corps de la requête correspond. au corps de réponse. 🎜🎜
- 1. La ligne de réponse est divisée en deux parties : la version du protocole de message et le code d'état de la réponse.
- 2. L'en-tête de réponse est également divisé en plusieurs paramètres tels que le type de serveur, le temps de réponse du type de données correspondant, etc.
- 3. Le corps de la réponse est ce que nous voulons vraiment, c'est-à-dire le contenu final de la requête. Ce contenu est principalement analysé. Par exemple, si une page est demandée, la réponse renvoyée par la requête sera un
HTMLrelativement volumineux.
Analyse de la méthode de requête HTTP
🎜Pour plus d'informations, veuillez vous référer à laMéthode de requête HTTP de l'article Statut du protocole HTTP et la composition des messages. 🎜Méthode GET
🎜Méthode GET est utilisée pour demander l'accès aux ressources qui ont été identifiées par URI. La ressource spécifiée est analysée par le serveur et. renvoie le contenu de la réponse. (Voir photo ci-dessous) 🎜🎜🎜🎜🎜Méthode PSOT
🎜Méthode POST a des fonctions similaires à la Méthode GET et est généralement utilisée pour transmettre le corps de l'entité, le but principal n'est pas d'obtenir le corps ; contenu du corps de la réponse, mais fournit les données du formulaire au serveur WEB, en particulier les gros lots de données. 🎜🎜La méthode POST pallie en fait certaines lacunes de la méthode GET. Grâce à la requête POST, les données ne font pas partie d'une requête URL. est transmis au serveur WEB en tant que format de données standard. Cela surmonte les inconvénients de la méthode GET selon laquelle les données ne peuvent pas être gardées confidentielles et la quantité de données est limitée. 🎜🎜🎜🎜🎜🎜🎜Ce qui suit est une introduction à certaines méthodes moins couramment utilisées. 🎜Méthode PUT
- Les données transférées du client vers le serveur remplacent le contenu du document spécifié.
- La plus grande différence entre la méthode PUT et la méthode POST est que PUT est idempotent, tandis que POST n'est pas idempotent. Par conséquent, nous utilisons le plus souvent la méthode
PUT pour transférer des ressources.PUT方法用作传输资源。开启 PUT方法 需要控制权限,否则会造成一定的安全隐患,比如向服务器传输带有恶意 payload 的攻击脚本。
HEAD 方法
HEAD方法几乎与GET方法相同,只不过HEAD方法只请求消息报文头,返回的响应中没有具体的内容,用于获取报头。
DELETE 方法
- 请求服务器删除指定的资源,也就是删除文件。(一般服务器会控制此方法的权限,否则会造成重大的安全漏洞。)
OPTIONS 方法
- 用来查询针对请求的 URI 指定的资源支持的方法,就是询问
请求的URL能够支持什么方法L'activation de la méthode PUT nécessite un contrôle des autorisations, sinon cela entraînera certains risques de sécurité, tels que la transmission de scripts d'attaque avec des charges utiles malveillantes au serveur.
Méthode HEAD
Méthode HEAD est presque la même que la méthode GET, sauf que la méthode HEAD ne demande que l'en-tête du message et renvoie la réponse Il n'y a pas de contenu spécifique dans , utilisé pour obtenir l'en-tête. Méthode DELETE
- demande au serveur de supprimer la ressource spécifiée, c'est-à-dire de supprimer le fichier. (En général, le serveur contrôlera les autorisations de cette méthode, sinon cela provoquera des failles de sécurité majeures.) La méthode
OPTIONS
- est utilisée pour interroger la méthode prise en charge par la ressource spécifiée par l'URI demandé, qui consiste à demander la requête
Quelles méthodes l'URL peut-elle prendre en charge ?.
Cette méthode est rarement utilisée dans le travail réel, elle est souvent utilisée par les attaquants et les ingénieurs en tests d'intrusion pour collecter des informations. La méthode
TRACE
- est utilisée pour faire écho aux requêtes reçues par le serveur, principalement à des fins de tests ou de diagnostics. (Pas couramment utilisé)
- est souvent utilisé dans les attaques intersites dans le domaine de la sécurité. La
- Méthode CONNECT
ouvre un canal de communication bidirectionnel avec la ressource demandée par le client, elle est donc plus souvent utilisée pour établir un tunnel. (C'est la méthode utilisée lors de l'utilisation d'un proxy)
| Explication détaillée du code d'état HTTP | Code d'état HTTP |
|---|---|
| 200 - La demande a réussi | |
| 404 - La ressource demandée (page Web, etc.) n'a pas été transférée. existe | 500 - Erreur interne du serveur |
| Classification du code d'état HTTP | |
| description | |
| 1** | Information, le serveur a reçu la demande et le demandeur doit continuer à effectuer l'opération |
Tableau des codes d'état HTTP
Code d'état |
Nom anglais | Description chinoise |
|---|---|---|
| 100 | Continuer | Continuer. Le client doit poursuivre sa demande |
| 101 | Switching Protocols | protocoles de commutation. Le serveur change de protocole en fonction de la demande du client. Vous ne pouvez passer qu'à un protocole plus avancé, par exemple passer à une nouvelle version du protocole HTTP |
| 200 | OK | La demande a réussi. Généralement utilisé pour les requêtes GET et POST |
| 201 | Created | a été créé. Demande et création réussie d'une nouvelle ressource |
| 202 | Accepté | Accepté. La demande a été acceptée, mais le traitement n'est pas terminé |
| 203 | Informations non autorisées | Informations non autorisées. La demande a abouti. Mais les méta-informations renvoyées ne sont pas sur le serveur d'origine, mais une copie |
| 204 | Pas de contenu | Pas de contenu. Le serveur a traité avec succès, mais aucun contenu n'a été renvoyé. Garantit que le navigateur continue d'afficher le document actuel sans mettre à jour la page Web |
| 205 | Réinitialiser le contenu | Réinitialiser le contenu. Le traitement du serveur réussit et le terminal utilisateur (par exemple le navigateur) doit réinitialiser la vue du document. Vous pouvez utiliser ce code retour pour effacer les champs du formulaire du navigateur |
| 206 | Contenu partiel | Contenu partiel. Le serveur a traité avec succès une partie de la requête GET |
| 300 | Choix multiples | Choix multiples. La ressource demandée peut inclure plusieurs emplacements, et par conséquent, une liste de caractéristiques et d'adresses de ressources peut être renvoyée pour que le terminal utilisateur (par exemple : navigateur) sélectionne |
| 301 | Déplacé de façon permanente | Déplacé de manière permanente. La ressource demandée a été définitivement déplacée vers le nouvel URI, les informations renvoyées incluront le nouvel URI et le navigateur sera automatiquement dirigé vers le nouvel URI. Toute nouvelle demande à venir doit utiliser le nouvel URI au lieu de |
| Found | Déplacement temporaire. Similaire au 301. Mais la ressource n'est déplacée que temporairement. Le client doit continuer à utiliser l'URI d'origine | |
| Voir Autre | pour afficher d'autres adresses. Similaire au 301. Utilisez les requêtes GET et POST pour afficher | |
| Non modifié | Non modifié. La ressource demandée n'a pas été modifiée. Lorsque le serveur renvoie ce code d'état, aucune ressource ne sera renvoyée. Les clients | mettent généralement en cache les ressources accédées en fournissant un en-tête indiquant que le client souhaite renvoyer uniquement les ressources modifiées après une date spécifiée |
| Utiliser le proxy | Utiliser le proxy | Utiliser le proxy. La ressource demandée doit être accessible via un proxy |
| 306 | Unused | Le code d'état HTTP obsolète |
| 307 | Redirection temporaire | Redirection temporaire. Similaire au 302. Redirection à l'aide de la requête GET |
| 401 | Non autorisé | La requête nécessite l'authentification de l'identité de l'utilisateur |
| 402 | Paiement requis | Réservé pour une utilisation future |
| 403 | Interdit | Le serveur comprend le demandant la demande du client, mais a refusé d'exécuter cette demande |
| 404 | Not Found |
Le serveur ne peut pas trouver la ressource (page Web) selon la demande du client. Avec ce code, les concepteurs de sites Web peuvent 🎜Définissez une page personnalisée pour "La ressource que vous avez demandée est introuvable" |
| 405 | Méthode non autorisée | La méthode dans la demande du client est interdite |
| 406 | Non acceptable | Le serveur ne peut pas être basé sur la demande du client Propriétés de contenu pour compléter la demande |
| 407 | Authentification proxy requise | La demande nécessite une authentification proxy, similaire à 401, mais le demandeur doit utiliser un proxy pour l'autorisation |
| 408 | Heure de la demande -out | server Le temps d'attente pour la requête envoyée par le client est trop long, timeout |
| 409 | Conflit | Le serveur peut renvoyer ce code lors de la réalisation de la requête PUT du client. Un conflit s'est produit lors du traitement du serveur. la demande |
| 410 | Gone | La ressource demandée par le client n'existe plus. 410 est différent de 404. Si la ressource a été définitivement supprimée, vous pouvez utiliser le code 410 Les concepteurs de sites Web peuvent spécifier le nouvel emplacement de la ressource via le code 301 Demander des informations sans Content-Length |
| 412 | . Échec de la condition | Erreur de condition préalable pour les informations de demande du client |
| 413 | Entité de demande trop grande | Le serveur ne peut pas la gérer car l'entité demandée est trop grande, la demande est donc refusée. Pour éviter les demandes continues du client, le serveur peut | fermer la connexion. Si le serveur ne peut pas le traiter temporairement, il contiendra un message de réponse Retry-After
| 414 | Request-URI Too Large |
L'URI demandé est trop long (l'URI est généralement une URL) et le le serveur ne peut pas le traiter |
| 415 | Type de média non pris en charge | Le serveur ne peut pas gérer le format multimédia attaché à la demande |
| 416 | Plage demandée non satisfaisante | Le client a demandé une plage non valide |
| 417 | Expectation Failed | Le serveur ne peut pas répondre aux attentes Les informations d'en-tête de la demande |
| Erreurs internes, la demande ne peut pas être complétée | 501 | |
| le serveur ne prend pas en charge le demande fonction et ne peut pas terminer la demande | 502 | |
| Le serveur agissant en tant que passerelle ou proxy a reçu une demande invalide du serveur distant | 503 | |
| En raison d'une surcharge ou du système maintenance, le serveur est temporairement incapable de traiter la demande du client. La durée du délai peut être incluse dans les informations d'en-tête Retry-After du serveur | 504 | |
| Le serveur agissant en tant que passerelle ou proxy n'a pas obtenu la demande du serveur distant dans time |
505 | |
| Le serveur ne prend pas en charge la version du protocole HTTP demandée et ne peut pas terminer le traitement | Apprentissage recommandé : | |
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Modularisation Python et installation de modules tiers (partage de synthèse)
- Résumé des points de connaissances multi-processus Python
- Introduction détaillée au module numpy de python
- Présentation de six fonctions intégrées Python très faciles à utiliser
- Explication graphique détaillée de la façon d'utiliser Python pour dessiner des graphiques de visualisation dynamique