
Maison >base de données >tutoriel mysql >Maîtriser complètement Mysql expliquer
Maîtriser complètement Mysql expliquer

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBavant
- 2022-04-01 13:21:212258parcourir
Cet article vous apporte des connaissances pertinentes sur mysql, qui présente principalement les problèmes liés à expliquer. Expliquez dans Mysql peut être appelé l'outil d'analyse d'optimisation des performances de Mysql Nous pouvons l'utiliser pour analyser les instructions SQL correspondantes implémentées. aide tout le monde.

Apprentissage recommandé : Tutoriel vidéo mysql
L'optimisation des performances de la base de données est l'une des compétences de base que tout programmeur back-end doit posséder, et expliquer dans Mysql peut être appelé l'artefact d'analyse d'optimisation des performances de Mysql. Utilisation Il analyse comment le plan d'exécution correspondant de l'instruction SQL est exécuté au bas de Mysql. Il est d'une grande importance pour nous d'évaluer l'efficacité d'exécution de SQL et de déterminer la direction d'optimisation des performances de Mysql. Cependant, de nombreux étudiants ne savent toujours pas comment effectuer une analyse approfondie de l'exécution du SQL existant basée sur l'explication. Par conséquent, cet article développe la localisation des problèmes de performances des bases de données via l'analyse explicative.
Expliquez les bases
Pour chaque SQL, lorsqu'il est envoyé au serveur Mysql par le client, il sera analysé par le composant optimiseur Mysql, qui comprend principalement des traitements spéciaux et des modifications dans l'ordre d'exécution pour garantir une efficacité d'exécution optimale, et enfin générer le plan d'exécution correspondant. Le soi-disant plan d'exécution fait en fait référence à la manière d'obtenir les données au niveau du moteur de stockage, qu'il s'agisse d'obtenir des données via un index ou une analyse complète de la table, s'il est nécessaire de renvoyer la table après avoir obtenu les données, etc. Une compréhension simple. est le processus d'obtention de données dans Mysql .
Ensuite, examinons de plus près ce qu'est cette explication et pourquoi elle peut nous guider dans l'optimisation des performances. Lorsque nous exécutons l'instruction suivante :
explain SELECT * FROM user_info where NAME='mufeng'
Après avoir exécuté l'instruction expliquer, nous obtiendrons les résultats d'exécution suivants. Ces 12 champs similaires à la table de la base de données sont en fait une description détaillée du plan d'exécution exécuté par Mysql. Examinons de plus près la signification de ces 12 champs. Ce n'est qu'en comprenant leur signification que nous pourrons comprendre comment Mysql effectue les requêtes de données.

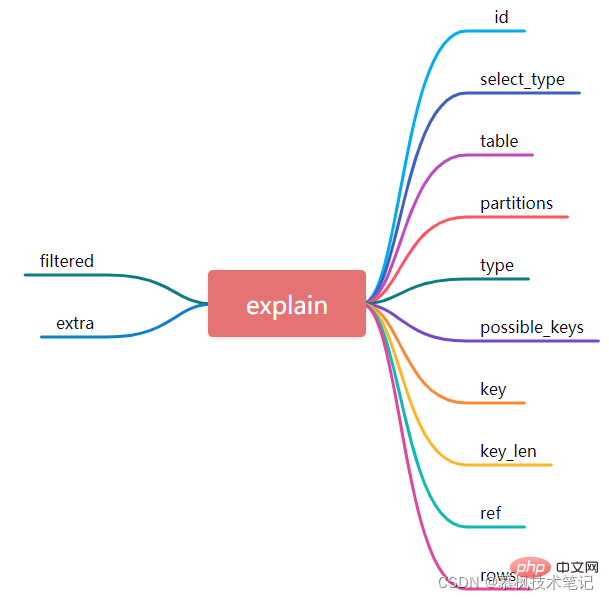
1. id
En fait, chaque requête de sélection correspondra à un identifiant, qui représente l'ordre d'exécution SQL. Plus la valeur de l'identifiant est grande, plus la priorité de l'instruction SQL correspondante est élevée. exécution. Certaines instructions SQL de requêtes complexes contiennent souvent des sous-requêtes, puis le numéro de série de l'identifiant sera incrémenté. S'il existe une requête imbriquée, nous pouvons constater que la requête la plus interne correspond au plus grand identifiant, elle sera donc exécutée en premier.

Comme le montre la figure ci-dessus, dans l'instruction de requête SQL, l'identifiant du premier plan d'exécution est 1, l'identifiant du deuxième plan d'exécution est 2, la table correspondant au plan d'exécution avec l'identifiant 1 est order , et l'identifiant est 2. La table correspondant au plan d'exécution est user_info. En combinaison avec l'instruction SQL, nous savons que l'identifiant de sélection de sous-requête de user_info est exécuté en premier, puis la requête de données sur l'ordre de la table est exécutée.
2. select_type
select_type représente le type de requête correspondant au plan d'exécution. Les types de requêtes courants incluent principalement les requêtes ordinaires, les requêtes conjointes et les sous-requêtes. SIMPLE (l'instruction de requête est une requête simple et ne contient pas de sous-requêtes), PRIMARY (lorsque l'instruction de requête contient des sous-requêtes, elle correspond au type de requête le plus externe), UNION (le type de requête correspondant à l'instruction select qui apparaît après l'union marquera ce type), SUBQUERY (la sous-requête sera marquée comme ce type), DEPENDENT SUBQUERY (dépend de la requête externe)

3, table
table représente le nom de la table et indique quelle table interroger. Bien entendu, il ne s'agit pas nécessairement du nom de la table réelle, il peut s'agir d'un alias de la table ou d'une table temporaire.
4, partitions
partitions représente le concept de partition, ce qui signifie que lors de l'interrogation, si la table correspondante sera partitionnée, alors les informations de partition spécifiques seront affichées ici.
5. type
le type est un attribut essentiel qui doit être maîtrisé. Il indique la méthode actuelle d'accès à la table de la base de données.
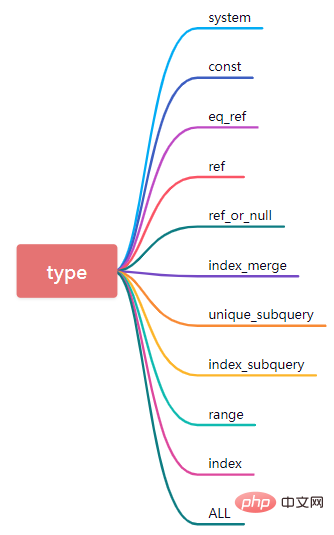
(1)système
La table n'a qu'une seule ligne (équivalente à la table système), la quantité de données est faible et la vitesse de requête est très rapide. System est un cas particulier du type const.
(2) const
Si le type est const, cela signifie que la clé primaire ou l'index unique est atteint lors de l'exécution d'une requête de données. Ce type de requête de données est très rapide.

(3) eq_ref
Dans le processus de requête de données, si l'instruction SQL peut être basée sur l'index clusterisé ou l'index unique de valeur non nulle pour mémoriser les données en cas de connexion à une table, alors le type correspondant à cette heure La valeur sera affichée sous la forme eq_ref.
(4) ref
Si l'index d'accès est un index secondaire et non un index unique lors de la requête de données, la vitesse de requête de test sera très rapide, mais le type est réf. De plus, s'il s'agit d'un index conjoint multi-champs, alors selon le principe de correspondance le plus à gauche, la comparaison d'égalité des champs dans plusieurs colonnes consécutives en commençant par le côté le plus à gauche de l'index conjoint est également un type de référence.

(5) ref_or_null
Ce type de jointure est similaire à ref, sauf que MySQL recherchera en plus les lignes contenant des valeurs NULL.
(7) unique_subquery
L'ensemble des conditions de sous-requête concernant la condition où
(8) index_subquery
est différent de unique_subquery, utilisé pour les index non uniques et peut renvoyer des valeurs en double.
(9)range
Utilisez l'index pour récupérer les données de ligne et récupérez uniquement les données de ligne dans la plage spécifiée. En d'autres termes, les données sont récupérées dans une plage spécifiée pour un champ indexé. Lorsque vous utilisez entre...et, <, >, <=, in et d'autres types de requêtes conditionnelles dans l'instruction Where, le type est range.

(10) index
Index et ALL lisent en fait la table entière. La différence est que l'index lit en parcourant l'arborescence d'index, tandis que ALL lit à partir du disque dur.
(11)all
Parcourez toute la table pour la correspondance des données. Les performances des requêtes de données à l'heure actuelle sont les pires.
6. possible_keys
indique quels index peuvent être sélectionnés par l'optimiseur Mysql, c'est-à-dire quels sont les candidats à l'index.
7, key
L'index réellement sélectionné dans possible_keys
8, key_len
indique la longueur de l'index, et il est lié aux attributs réels du champ et s'il est nul.
9, ref
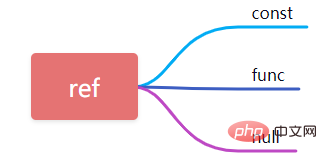
Lors de l'utilisation de champs pour une requête équivalente constante, ref est ici const. Lorsque des expressions ou des fonctions sont utilisées dans les conditions de requête, ref est affiché comme func et les autres sont affichés comme null.
10, lignes
La colonne lignes indique le nombre de lignes que MySQL pense devoir vérifier lors de l'exécution de la requête. Moins il y a de lignes, plus c’est efficace !
11.filtré
filtré Il s'agit d'une valeur en pourcentage, le pourcentage du nombre d'enregistrements qui remplissent les conditions du tableau. Pour faire simple, ce champ représente la proportion des enregistrements restants qui remplissent les conditions après filtrage des données renvoyées par le moteur de stockage.
12. extra
Les informations supplémentaires ne seront pas affichées dans les autres colonnes et seront affichées dans cette colonne.
(1) Utilisation de l'index
Lors de l'exécution d'une requête de données, la base de données utilise un index de couverture, c'est-à-dire que la colonne interrogée est couverte par l'index. En utilisant l'index de couverture, la vitesse de requête sera très rapide. Au lieu d'utiliser select *, utilisez select phone_number, qui utilisera l'index de couverture.

(2) Utilisation de Where
Aucun index disponible n'est trouvé lors de la requête et les données requises sont obtenues via le filtrage des conditions Where. Cependant, il convient de noter que toutes les requêtes avec des instructions Where n'afficheront pas Using Where.

(3) L'utilisation de temporaire
signifie que les résultats de la requête doivent être stockés dans une table temporaire, qui est généralement utilisée lors du tri ou du regroupement des requêtes.
(4) Utilisation du tri de fichiers
Ce type signifie que l'index ne peut pas être utilisé pour terminer l'opération de tri spécifiée, c'est-à-dire que le champ ORDER BY n'a pas réellement d'index, ce type de SQL doit donc être optimisé.
exlpain分析实战
上文中我们阐述了explain在分析SQL语句时,可以通过12个属性来分析SQL的大致执行过程,并以此来判断SQL存在的性能问题。那么接下来我们通过一个实际的例子,来具体看下如何结合explain来实现SQL的性能分析。
其实所谓的Mysql性能问题,大部分都指的是平台出现了慢查询问题。慢查询实际上是可以通过配置进行记录的,把执行时间超过某个设定的阈值的sql都记录下来,当出现问题的时候可以通过记录的慢查询日志进行问题的定位。但是有的时候,出现大量慢查询会导致数据库连接给占满,导致整个平台的出现异常。
实际上我们在产品评价表product_evaluation中是建立了索引的,正常来说应该是可以使用到对应的索引字段进行查询的。但是实际上查询耗时有几十秒的时间,远远超过我们的预期。那我们猜测是不是由于某种原因导致Mysql优化器没有选择对应的索引进行数据检索,最后造成慢查询的发生。到底执行计划是怎样的,还是得借助于explain来看下。

如上文所说,虽然explain有12个字段属性帮助我们进行执行计划的分析,但是实际上常用的核心字段也就几个。我们可以看的出来在possible_key中实际上包含了我们设置的索引的,但是实际上Mysql却选择了PRIMARY作为其实际使用的。那么问题来了,为什么明明设置了索引,但是实际并没有用上,呗Mysql吃了吗?另外为什么之前的业务中没有出现这个问题,而现在出现了?我们需要进行进一步的分析。
我们所建立的idx_evaluation_type实际上是一个二级索引(叶子节点是主键id),对于数千万一张的大表来说,实际上这个二级索引也是非常大的,而且这个字段本身的值就三个,变化不大。因此Mysql的优化器在分析这个SQL的时候发现,如果按照SQL中的索引来获取数据后再根据where条件进行筛选,筛选后的数据还需要回表到聚簇索引中获取实际的数据。
假如通过二级索引筛选出来的数据有几万条,而后还需要进行排序,这些操作都是基于临时磁盘我恩建进行的,Mysql判断这种方式的性能可能会很差,因此优化器放弃了原有的数据查询方式,直接通过主键id对应的聚簇索引来进行数据的获取,因为id本身就是有序的。
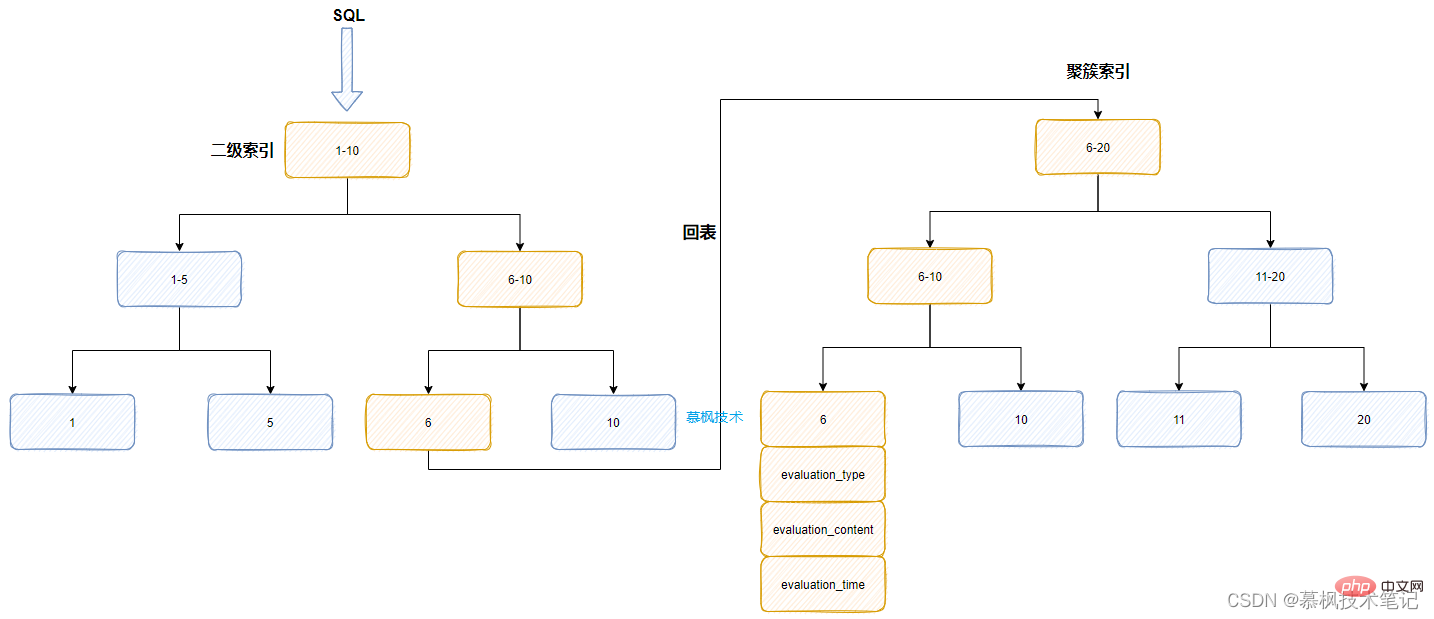
那么知道了查询慢的原因,我们应该怎么进行优化呢?实际上可以在SQL语句中增加force idnex,强制Mysql使用我们设置的二级索引。
SELECT * FROM product_evaluation force index(idx_product_id)WHERE product_id =1 and evaluation_type='GOOD' ORDER BY id desc LIMIT 200
总结
通过上文对于explain使用的介绍,大家在遇到慢SQL问题的时候,可以先通过explain来进行初步的分析,主要明确SQL在Mysql中实际的执行过程是怎样的,如果查询字段没有索引则增加索引,如果有索引就要分析为什么没有用到索引。只要明确具体的执行过程,我们才能确定具体的查询优化方案。
推荐学习:mysql视频教程
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!